

使用FPGA进行AI火灾定位-FirAI
可编程逻辑
描述
部署在 FPGA 上加速的 AI 火灾侦查。助力消防人员快速应对火灾事故~
绪论
问题:近年来,不断增加的城市人口、更复杂的人口密集建筑以及与大流行病相关的问题增加了火灾侦查的难度。因此,为了增强消防人员对火灾事件的快速反应,安装视频分析系统,可以及早发现火灾爆发。
目标:解决方案包括建立一个分布式计算机视觉系统,增加建筑物火灾的早期检测。该系统的分布式和模块化特性可以轻松部署,而无需增加更多基础设施。在不增加人力规模的情况下,可以明显增强消防能力。系统通过使用 Xilinx FPGA实现边缘 AI 加速图像处理功能来实现。
开发流程介绍
使用的硬件是 Xilinx Kria KV260,用于加速计算机视觉处理和以太网连接的相机套件。嵌入式软件使用 Vitis AI。在 PC 上,使用现有的火灾探测数据集对自定义 Yolo-V4 模型进行训练。之后,对Xilinx YoloV4 模型进行量化、裁剪和编译 DPU ,最后部署在FPGA上。
PC:设置 SD 卡镜像
首先我们需要为 FPGA Vision AI Starter Kit 准备 SD 卡(至少 32GB)。
这次将使用 Ubuntu 20.04.3 LTS 作为系统。
在 PC 上,下载 Balena Etcher 将其写入 SD 卡。
或者,可以使用下面命令行(警告:请确保系统下/dev/sdb必须是 SD 卡)进行操作:
xzcat ~/Downloads/iot-kria-classic-desktop-2004-x03-20211110-98.img.xz | sudo dd of=/dev/sdb bs=32M
完成后, SD 卡就准备好了,将其插入 开发板上。
设置 Xilinx Ubuntu
将 USB 键盘、USB 鼠标、USB 摄像头、HDMI/DisplayPort 和以太网连接到开发板。
连接电源,将看到 Ubuntu 登录屏幕。
默认用户名:ubuntu密码:ubuntu
启动时,系统ui可能会非常慢,可以运行下面这些命令来禁用一些组件以加快速度。
gsettings set org.gnome.desktop.interface enable-animations false gsettings set org.gnome.shell.extensions.dash-to-dock animate-show-apps false
接下来,调用下面命令将系统更新到最新版本
sudo apt upgrade
早期版本的 Vitis-AI 不支持 Python
安装用于系统管理的 xlnx-config snap 并对其进行配置:
sudo snap install xlnx-config --classic xlnx-config.sysinit
接下来检查设备配置是否工作正常。
sudo xlnx-config --xmutil boardid -b som
安装带有示例的 Smart Vision 应用程序和 Vitis AI 库。(智能视觉应用程序包含我们将重复使用的 DPU 的比特流,库样本稍后也将用于测试我们训练的模型)
sudo xlnx-config --snap --install xlnx-nlp-smartvision sudo snap install xlnx-vai-lib-samples
检查已安装的示例和应用程序
xlnx-vai-lib-samples.info sudo xlnx-config --xmutil listapps
运行上述命令后,就会注意到 DPU 需要 Model Zoo 样本。
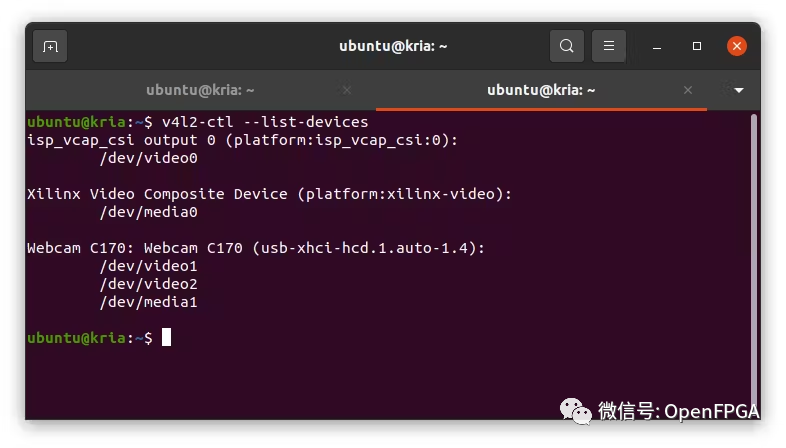
接下俩运行其中一个示例。在运行示例之前,需要将 USB 摄像头连接到开发板并确保系统驱动能检测到视频设备。这次使用的是 Logitech C170,它被挂载到/dev/video1
v4l2-ctl --list-devices
加载并启动智能视觉应用程序。
sudo xlnx-config --xmutil loadapp nlp-smartvision xlnx-nlp-smartvision.nlp-smartvision -u
在运行任何加速器应用程序之前,我们需要先加载 DPU。我们可以简单地调用 smartvision 应用程序,它会为我们加载比特流。或者,可以打包自己的应用程序。
注意:加速器比特流位于/lib/firmware/xilinx/nlp-smartvision/.
由于我们计划是使用YOLOv4框架,所以让我们测试一个模型的例子。有“ yolov4_leaky_spp_m”预训练模型。
sudo xlnx-config --xmutil loadapp nlp-smartvision # the number 1 is because my webcam is on video1 xlnx-vai-lib-samples.test-video yolov4 yolov4_leaky_spp_m 1
上面的命令将在第一次运行时下载模型。模型将被安装到 ~/snap/xlnx-vai-lib-samples/current/models 目录中。
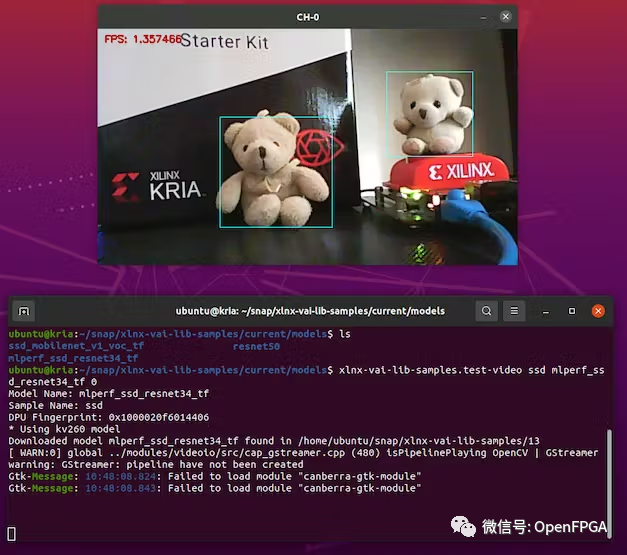
上面测试良好,接下来就可以训练我们自己的模型。
PC:运行 YOLOv4 模型训练
要训练模型,请遵循Xilinx 提供的07-yolov4-tutorial文档。它是为 Vitis v1.3 编写的,但步骤与当前的 Vitis v2.0 完全相同。
我们的应用程序用于检测火灾事件,因此请在下面链接中下载火灾图像开源数据集
我们必须修改此.cfg配置文件以与 Xilinx Zynq Ultrascale+ DPU 兼容
Xilinx 建议文件输入大小为 512x512(或 416x416 以加快推理速度)

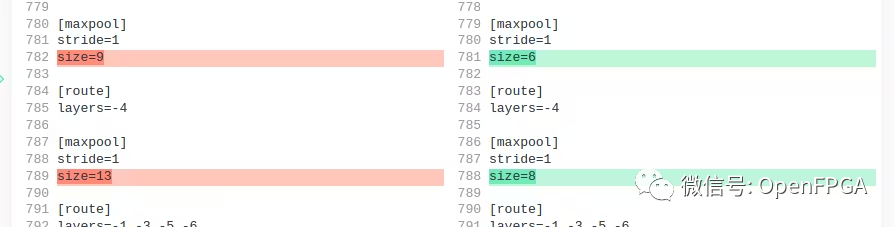
DPU 不支持 MISH 激活层,因此将它们全部替换为 Leaky 激活层

DPU 仅支持最大 SPP maxpool 内核大小为 8。默认设置为 5、9、13。但决定将其更改为 5、6、8。
在 Google Colab 上对其进行了训练。遵循了 YOLOv4 的标准训练过程,没有做太多修改。
在 github 页面中找到带有分步说明的 Jupyter notebook。
下图是损失的进展图。运行了大约 1000 次迭代我觉得这个原型的准确性已经足够好了,但如果可以的话,建议进行几千次迭代训练。
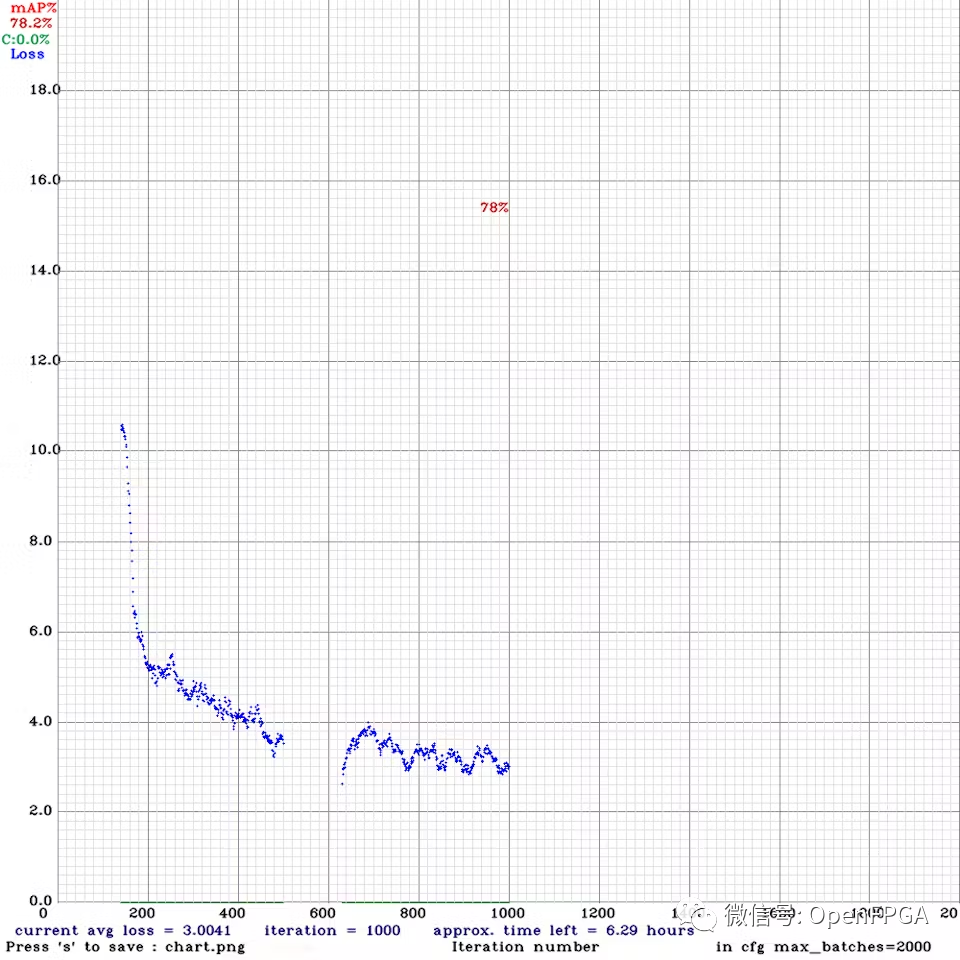
下载最佳权重文件 ( yolov4-fire-xilinx_1000.weights)。在本地运行了 yolov4 推理,一张图像大约需要 20 秒!稍后我们将看到使用 FPGA 可以将其加速到接近实时的速度。
./darknet detector test ../cfg/fire.data ../yolov4-fire.cfg ../yolov4-fire_1000.weights image.jpg -thresh 0.1
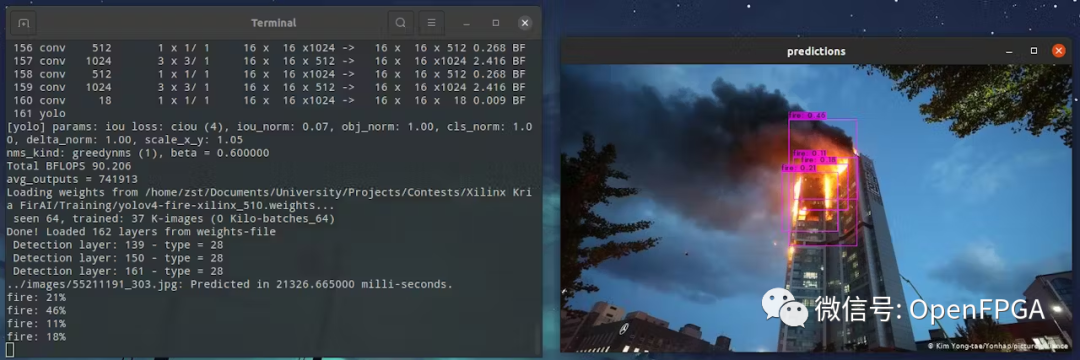
现在有了经过训练的模型,接下来就是将其转换和部署在 FPGA 上。
PC:转换TF模型
下一步是将darknet model转换为frozen tensorflow流图。keras-YOLOv3-model-set 存储库为此提供了一些有用的脚本。我们将运行 Vitis AI 存储库中的一些脚本。
首先安装docker,使用这个命令:
sudo apt install docker.io sudo service docker start sudo chmod 666 /var/run/docker.sock # Update your group membership
拉取 docker 镜像。使用以下命令下载最新的 Vitis AI Docker。请注意,此容器是 CPU 版本。(确保运行Docker的磁盘分区至少有100GB的磁盘空间)
$ docker pull xilinx/vitis-ai-cpu:latest
clone Vitis-AI 文件夹
git clone --recurse-submodules https://github.com/Xilinx/Vitis-AI cd Vitis-AI

启动 Docker
bash -x ./docker_run.sh xilinx/vitis-ai-cpu:latest
进入 docker shell 后,clone教程文件。
> git clone https://github.com/Xilinx/Vitis-AI-Tutorials.git > cd ./Vitis-AI-Tutorials/ > git reset --hard e53cd4e6565cb56fdce2f88ed38942a569849fbd # Tutorial v1.3
现在我们可以从这些目录访问 YOLOv4 教程:
从主机目录:~/Documents/Vitis-AI/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial
从 docker 中:/workspace/Vitis-AI-Tutorials/07-yolov4-tutorial
进入教程文件夹,创建一个名为“ my_models ”的新文件夹并复制这些文件:
训练好的模型权重:yolov4-fire-xilinx_last.weights 训练配置文件:yolov4-fire-xilinx.cfg
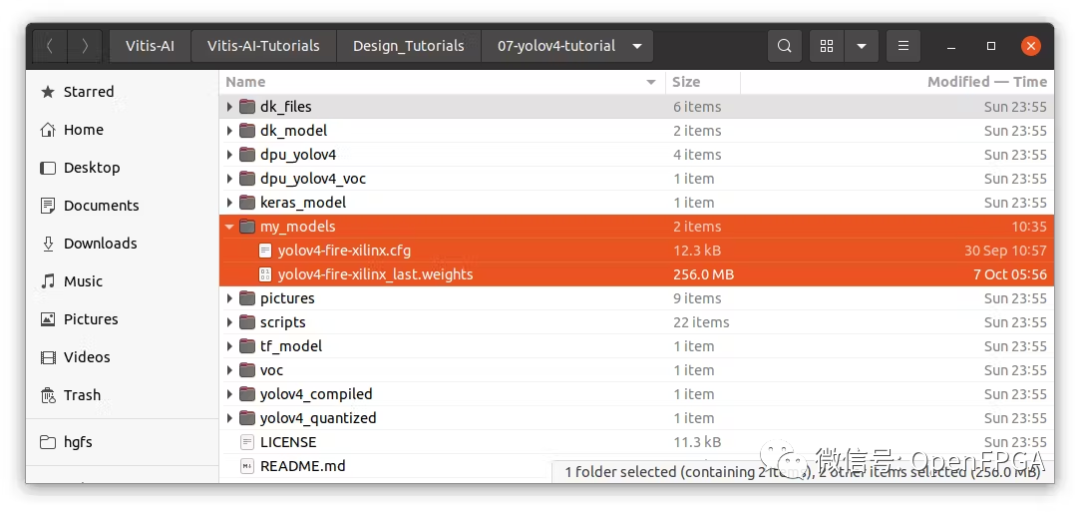
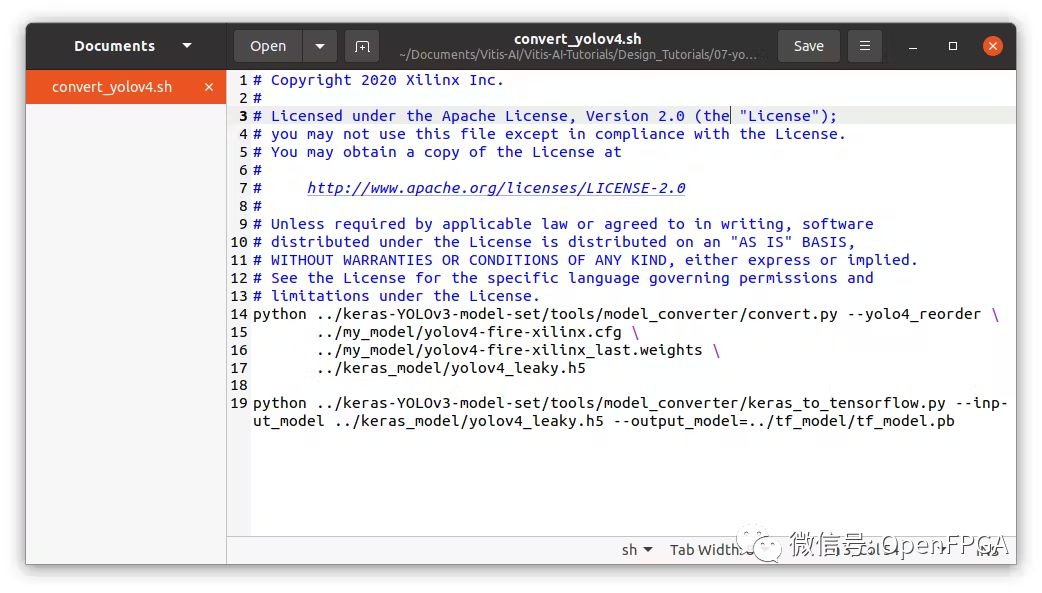
在 scripts 文件夹下,找到convert_yolov4脚本。编辑文件指向我们自己的模型(cfg 和权重文件):
../my_models/yolov4-fire-xilinx.cfg ../my_models/yolov4-fire-xilinx_last.weights
现在回到终端并输入 docker。激活tensorflow环境。我们将开始转换yolo模型的过程
> conda activate vitis-ai-tensorflow > cd /workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/scripts/ > bash convert_yolov4.sh
转换后,现在可以在“keras_model”文件夹中看到 Keras 模型(.h5)。以及“tf_model”文件夹下的frozen model(.pb)。
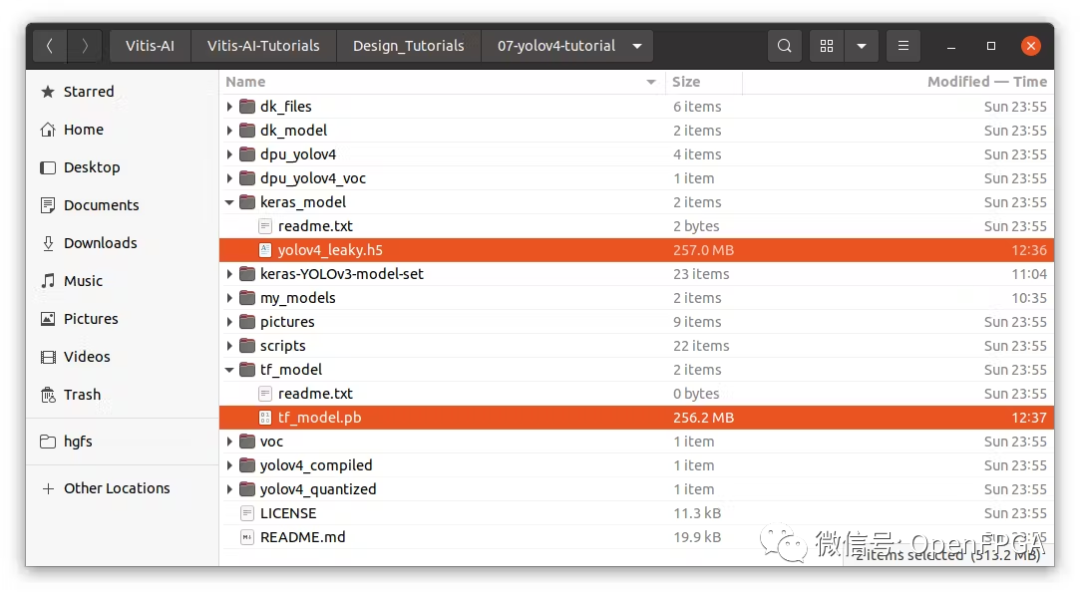
PC:量化模型
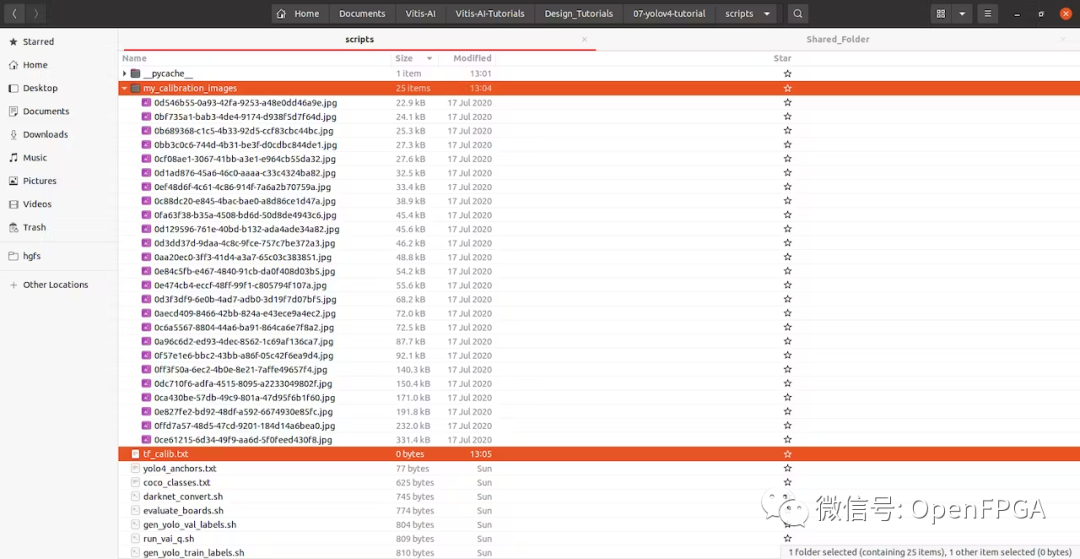
我们需要将部分训练图像复制到文件夹“ yolov4_images ”。这些图像将用于量化期间的校准。
创建一个名为“ my_calibration_images ”的文件夹,并将训练图像的一些随机文件粘贴到那里。然后我们可以列出所有图像的名称到 txt 文件中。
> ls ./my_calibration_images/ > tf_calib.txt
然后编辑yolov4_graph_input_keras_fn.py ,指向这些文件位置。
运行./quantize_yolov4.sh。将在yolov4_quantized目录中生成一个量化图。

接下来在“yolov4_quantized”文件夹中看到量化的frozen model。
PC:编译 xmodel 和 prototxt
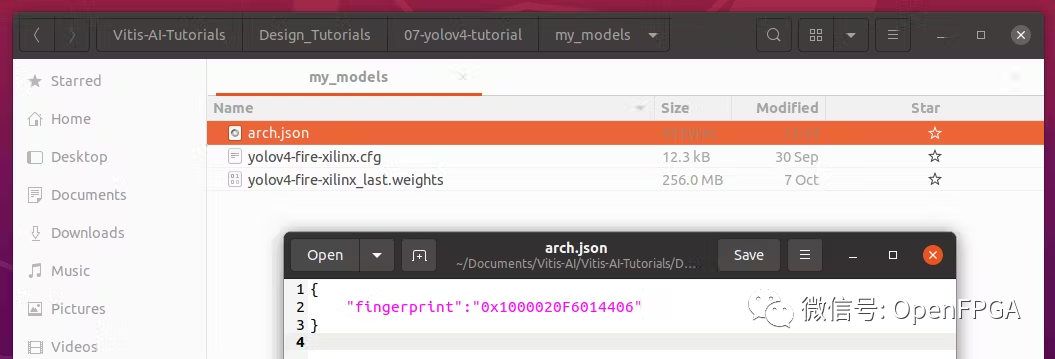
创建用于编译 xmodel 的arch.json ,并将其保存到同一个“ my_models ”文件夹中。
请注意使用我们之前在 FPGA 上看到的相同 DPU。在这种情况下,以下是 FPGA 配置 (Vitis AI 1.3/1.4/2.0)
{
"fingerprint":"0x1000020F6014406"
}
修改compile_yolov4.sh指向我们自己的文件
NET_NAME=dpu_yolov4
ARCH=/workspace/Vitis-AI-Tutorials/Design_Tutorials/07-yolov4-tutorial/my_models/arch.json
vai_c_tensorflow --frozen_pb ../yolov4_quantized/quantize_eval_model.pb
--arch ${ARCH}
--output_dir ../yolov4_compiled/
--net_name ${NET_NAME}
--options "{'mode':'normal','save_kernel':'', 'input_shape':'1,512,512,3'}"
运行编译
> bash -x compile_yolov4.sh
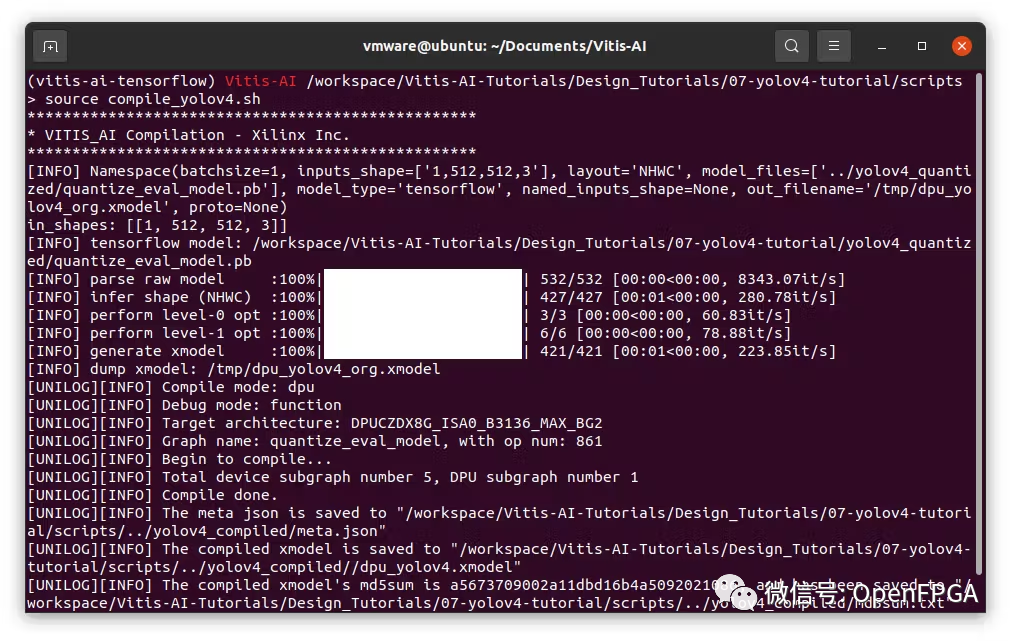
在“yolov4_compiled”文件夹中,将看到 meta.json 和 dpu_yolov4.xmodel。这两个文件构成了可部署模型。将这些文件复制到 FPGA。
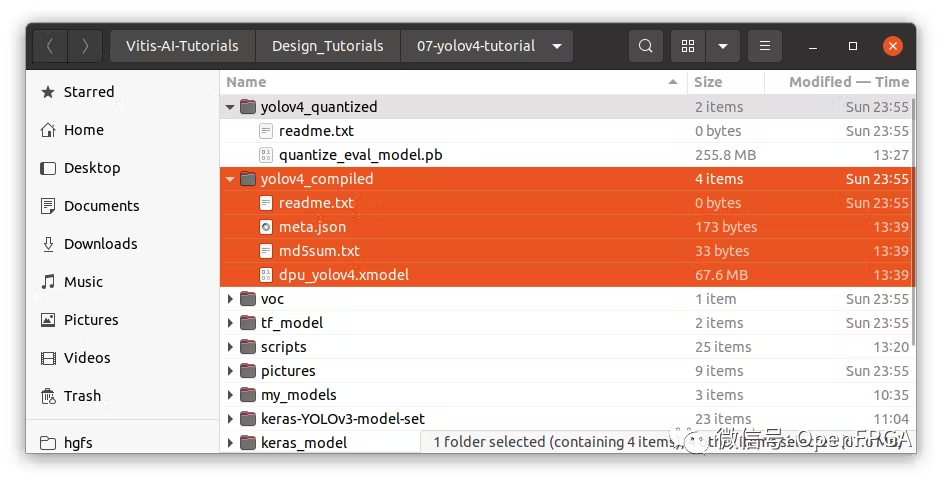
请注意,如果使用官方较旧的指南,能会看到正在使用 *.elf 文件。新指南替换为 *.xmodel 文件
从 Vitis-AI v1.3 开始,该工具不再生成 *.elf 文件,而是 *.xmodel 并且将用于在边缘设备上部署模型。
对于某些应用程序,需要*.prototxt文件和*.xmodel文件。要创建prototxt,我们可以复制示例并进行修改。
根据你的YOLO配置需要遵循的事项:
“biases”:必须与yolo.cfg文件中的“anchors”相同 “num_classes”:必须与 yolo.cfg 文件中的“classes”相同 “layer_name”:必须与 xmodel 文件中的输出相同
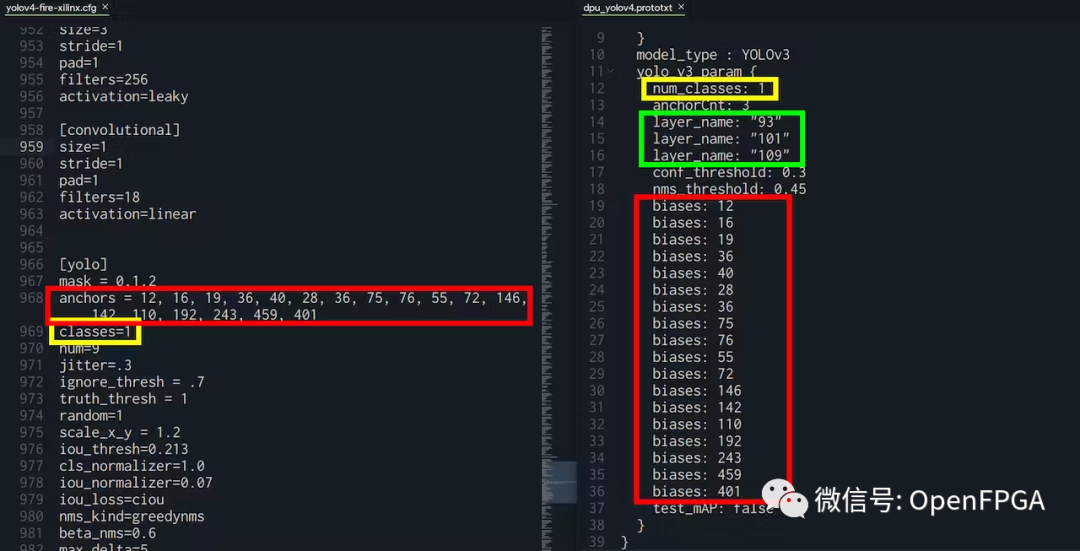
对于 layer_name,可以转到 Netron ( https://netron.app/ ) 并打开 .xmodel 文件。由于 YOLO 模型有 3 个输出,还会看到 3 个结束节点。
对于这些节点中的每一个 (fix2float),都可以从名称中找到编号。
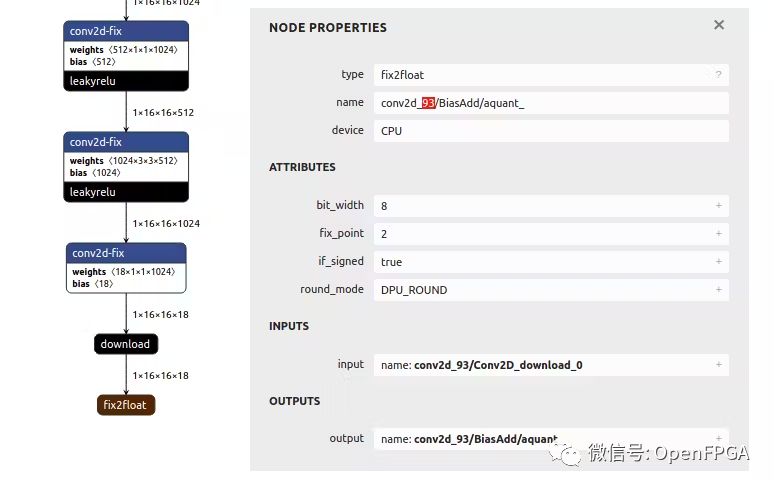
如果在运行模型时可能遇到分段错误,很可能是由于.prototxt文件配置错误。如果是这样,请重新运行这一章节的操作并验证是否正确。
FPGA:在 FPGA Ubuntu 上测试部署
创建一个名为“dpu_yolov4”的文件夹并复制所有模型文件。该应用程序需要这 3 个文件:
meta.json
dpu_yolov4.xmodel
dpu_yolov4.prototxt
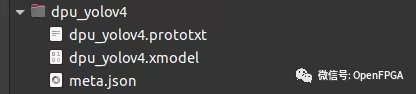
我们可以通过直接从 snap bin 文件夹调用test_video_yolov4可执行文件来测试模型。
> sudo xlnx-config --xmutil loadapp nlp-smartvision # Load the DPU bitstream > cd ~/Documents/ > /snap/xlnx-vai-lib-samples/current/bin/test_video_yolov4 dpu_yolov4 0
就会看到它检测到所有的火。在这种情况下,有多个重叠的框。我们在创建 python 应用程序时会考虑到这一点。
FPGA:Python 应用程序实现
在 Github 页面中,将找到完整应用程序实现。它考虑了重叠框并执行非最大抑制 (NMS) 边界框算法。它还打印边界框的置信度。此外,每个坐标记录在帧中。在现实系统中,这些信息将被发送到服务器并提醒负责人员。
审核编辑:刘清
-
当我问DeepSeek AI爆发时代的FPGA是否重要?答案是......2025-02-19 6558
-
浅谈基于AI的充电桩火灾预警系统的应用展望2024-08-13 1900
-
AI火灾监测报警摄像机2024-03-20 3080
-
使用AI进行早期火灾探测2023-06-09 767
-
基于FPGA 的AI火灾侦查定位解决方案2023-05-29 1062
-
基于FPGA的单目内窥镜定位系统设计2023-02-07 793
-
火灾,不再不可预知2023-01-31 7333
-
使用Xilinx Kria KV260进行AI火灾探测2022-10-27 1438
-
求一种城市公交车火灾快速定位系统的设计方案2021-05-20 1526
-
基于RSSI的定位技术进行了研究2020-08-28 1921
-
通过采用CC2430芯片实现公交火灾快速定位系统设计解决方案2020-02-06 1749
-
FPGA对AI发展有什么影响?2019-10-21 2190
-
基于FPGA的手术导航定位系统2016-05-09 608
-
感温线缆式火灾定位报警控制器的研制2009-08-24 1041
全部0条评论

快来发表一下你的评论吧 !
