

Cortex-M核心寄存器和位域
描述
我相信昨天的文章你一定大饱眼福了,没关系,接下来的更精彩,也会对C语言有个全新的理解。
今天这个文件属于CM3核心定义:有CMSIS核心的所有结构和符号
Cortex-M核心寄存器和位域,Cortex-M核心外设基址。
今天的对象在这里
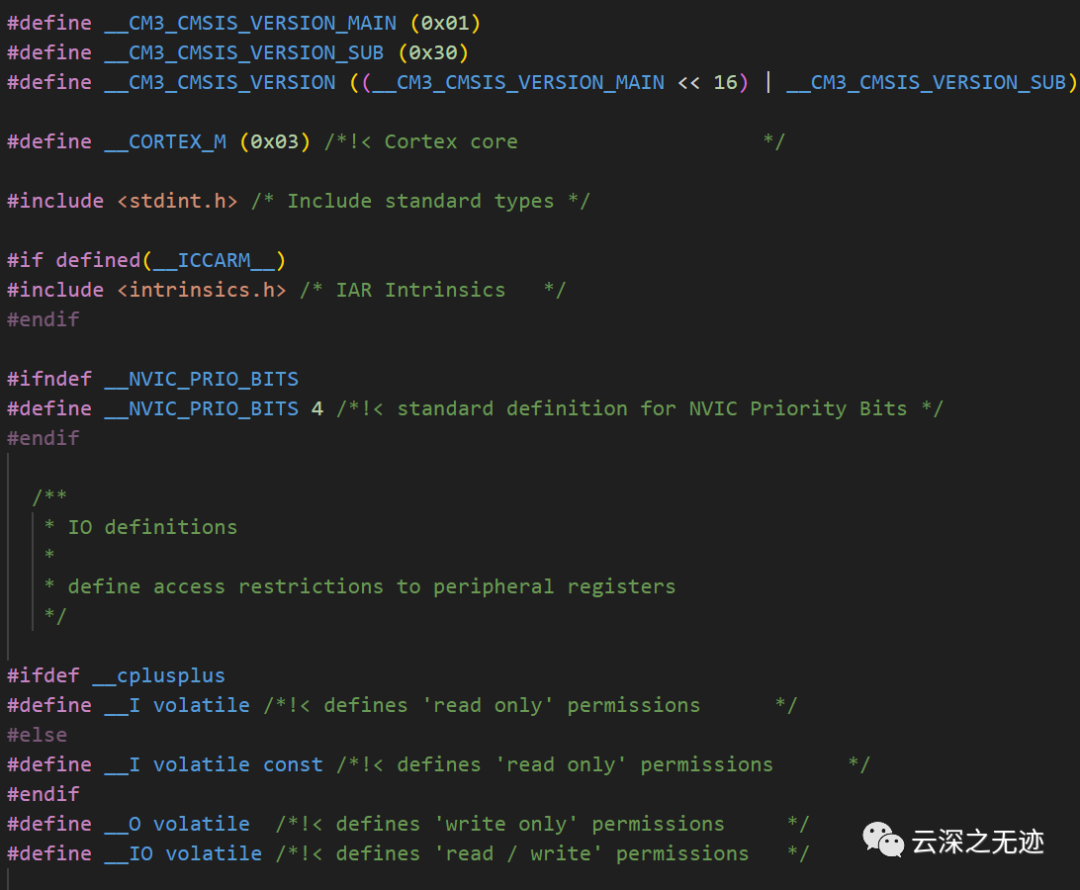
先看h文件的前面几行
根据前面三行宏定义,最终计算出的CMSIS HAL库完整版本号为:__CM3_CMSIS_VERSION = (0x01 << 16) | 0x30 = 0x010030所以,完整的版本号为0x010030。
其中:__CM3_CMSIS_VERSION_MAIN = 0x01,主版本号为0x01__CM3_CMSIS_VERSION_SUB = 0x30,子版本号为0x30通过左移16位实现主版本号 occupies 的高16位,子版本号占低16位,然后按位或生成完整32位的版本号0x010030。
这个32位版本号包含了CMSIS HAL库的主版本号与子版本号信息,通过该版本号,根据这三行宏定义,可以知道当前使用的CMSIS HAL库的版本号为0x010030。其中高16位0x01表示主版本号,低16位0x30表示子版本号。
0x010030
= 0x01 * (2^16) + 0x30 * (2^0)
= 1 * 65536 + 48 * 1
= 65536 + 48
= 65680
这是转成10进制的数字。
其中,主版本号0x01对应的10进制数为1,子版本号0x30对应的10进制数为48。
通过将主版本号的值×2^16,子版本号的值×2^0相加,我们可以得出CMSIS HAL库完整版本号对应的10进制数65680。
这个10进制数同样包含了主版本号1和子版本号48的信息,我们可以清楚知道当前使用的CMSIS HAL库版本号为1.48。
1代表主版本号,48代表子版本号,两者组合即为完整版本号1.48。
所以,总结来说,CMSIS-HAL库的版本号0x010030
可以表示为:
Hex: 0x010030
Decimal: 65680
Version: 1.48
那不免有疑问,明明可以直接10进制文件的,为啥这么复杂呢?让我来斗胆的分析一下。
主要有以下几个考虑因素:
1. 兼容性:使用位运算生成的版本号格式0x010030与CMSIS HAL库一致,这样可以最大限度保证与库的兼容性。
2. 扩展性:使用位运算,主版本号占高16位,子版本号占低16位,这样主版本号可以扩展到65536,子版本号也有很高扩展空间,更利于版本的长期维护与扩展。
3. 信息包含:32位的版本号可以同时包含主版本号与子版本号,一目了然,这个信息直接清楚可见。如果只使用1.48形式,无法同时看到主子版本号的值,信息表达不够直接。
4. 处理方便:位运算生成的版本号可以通过简单的移位与位运算提取主版本号与子版本号的值,这在编程处理时比较方便。
5. 标准形式:0x开头的十六进制数是MCU编程中常用的标准表达形式,使用起来比较习惯。
所以,总体来说,虽然直接使用1.48的形式更简单直观,但使用位运算生成0x010030格式的版本号,可以在兼容性、扩展性、信息包含以及处理方便性等方面获得优势,也符合编程习惯的标准表达形式。考虑到CMSIS HAL库作为MCU的底层支撑库,需要长期维护与迭代,所以选择使用位运算生成版本号格式可以获得更多优点,这可能也是CMSIS HAL库设计者选择这种版本号格式的主要考量因素。
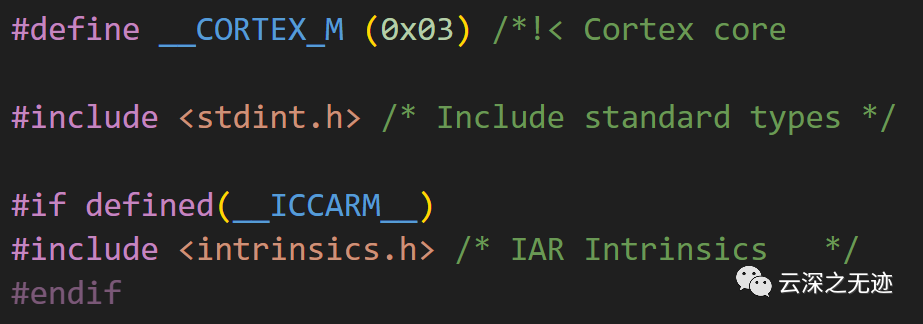
接下来看这个
这段代码主要完成了MCU内核类型与数据类型的定义。
__CORTEX_M (0x03) 此宏定义指定了内核类型为Cortex-M3,其十六进制值为0x03。
#include 此行包含stdint.h头文件,用于定义标准数据类型,如Uint8_t、int32_t等。
#if defined(__ICCARM__) 此行条件判断是否使用IAR编译器,如果使用则包含intrinsics.h头文件。
#include 此行包含intrinsics.h头文件,该头文件定义了IAR C/C++编译器的内嵌汇编指令。
所以,这段代码主要完成了两方面的工作:
1. 通过__CORTEX_M宏定义指定了MCU使用的内核类型为Cortex-M3。2. 包含stdint.h头文件,定义了标准的数据类型,用于MCU开发时使用。
3. 如果使用IAR编译器,则额外包含intrinsics.h头文件,可以使用IAR编译器提供的内嵌汇编指令。
这段简短的代码定义和包含了MCU开发最基础的信息:
1. 内核类型:我们知道目标MCU使用的内核是Cortex-M3。
2. 数据类型:通过stdint.h我们可以使用标准的数据类型,如Uint32_t等。
3. 如果使用IAR编译器,可以使用内嵌汇编指令来优化程序。
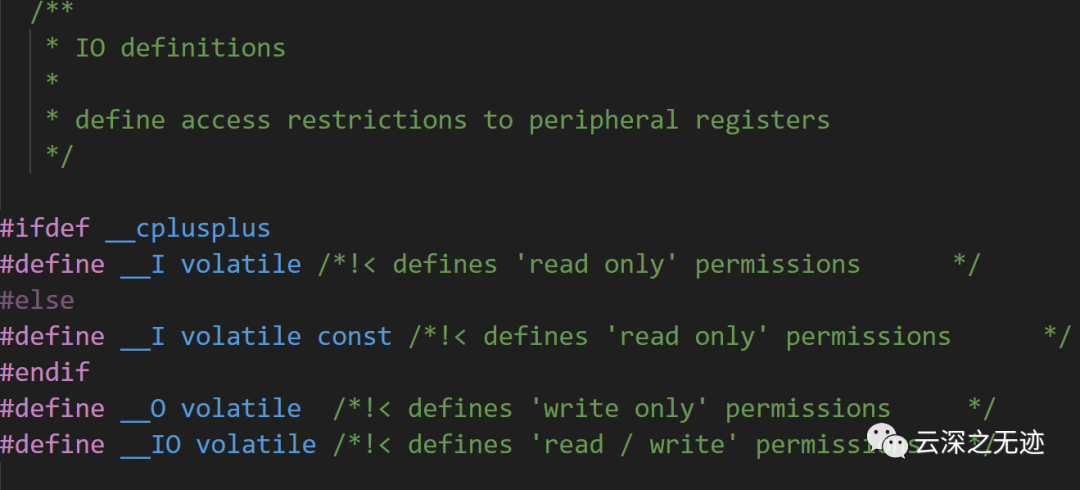
这几个macro是频繁出现的,细说一下
这段代码主要定义了中断优先级位数和IO操作权限。
#ifndef __NVIC_PRIO_BITS
#define __NVIC_PRIO_BITS 4
#endif
这两行定义了中断优先级位数为4,如果__NVIC_PRIO_BITS未定义,则进行定义,否则忽略。
#ifdef __cplusplus
#define __I volatile
#else
#define __I volatile const
#endif
这几行判断是否使用C++编译器,如果使用C++编译器,__I定义为volatile,否则定义为volatile const,表示只读属性。
#define __O volatile
此行定义__O为volatile,表示只写属性。
#define __IO volatile
此行定义__IO为volatile,表示读写属性。
所以,这段代码主要完成了:
1. 如果__NVIC_PRIO_BITS未定义,则定义中断优先级位数为4。否则忽略。
2. 根据编译器选择定义只读属性__I为volatile或volatile const。
3. 定义只写属性__O为volatile。
4. 定义读写属性__IO为volatile。
5. 这四个属性主要用于定义外设寄存器的访问权限,以确保编译器不会对访问的代码作优化,影响读取的准确性。
也就是说,这段代码为寄存器的访问屏蔽了编译器的优化,在编译过程中让编译器明确区分:
这是一个只读寄存器,值可能会被其他因素改变,读取时总是获取最新值。
这是一个只写寄存器,每次写入的值必须被外设接收。
这个寄存器是可读写的,读取与写入都必须准确地映射到外设。这样可以最大限度地确保我们的程序以预期的方式使用这些寄存器,也不会因为编译器的优化而导致意外的结果。
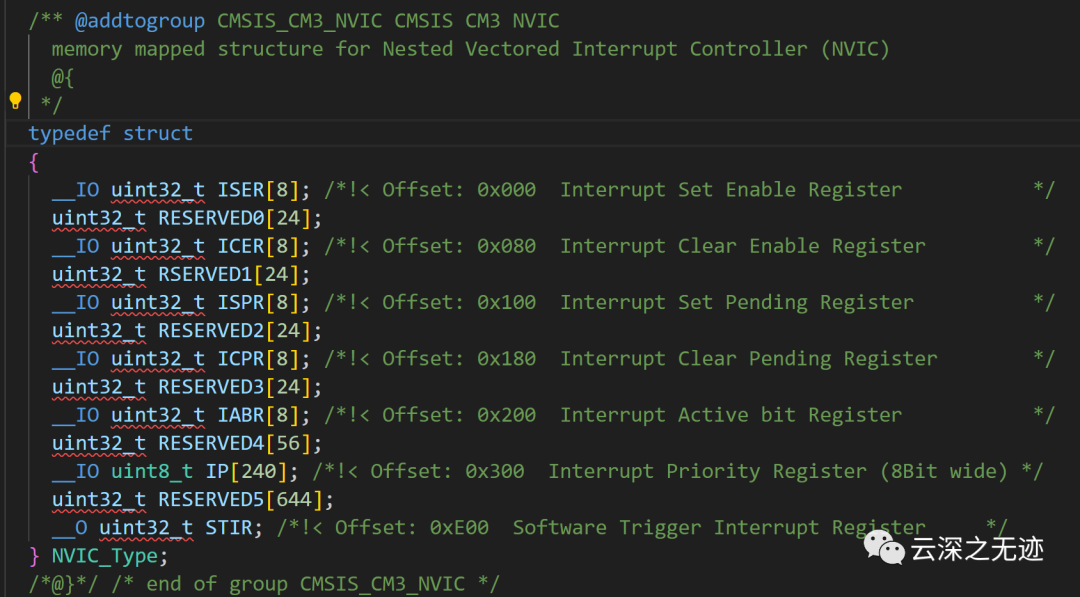
接下来我们看这个,知识点有点密集

中断到中断向量的映射
显示了中断(或IRQ号)如何映射到中断寄存器和相应的CMSIS变量(每个中断有一位)。
这段代码定义了NVIC_Type结构体,用于表示NVIC(嵌套向量中断控制器)的控制与状态寄存器。
NVIC_Type结构体包含以下成员:
__IO uint32_t ISER[8]; 中断使能置位寄存器,用于使能中断,数组8个成员对应NVIC的8个中断组。
__IO uint32_t ICER[8]; 中断清除使能寄存器,用于禁止中断,数组8个成员对应NVIC的8个中断组。
__IO uint32_t ISPR[8]; 中断待处理置位寄存器,用于置位某中断的待处理标志,数组8个成员对应NVIC的8个中断组。
__IO uint32_t ICPR[8]; 中断待处理清除寄存器,用于清除某中断的待处理标志,数组8个成员对应NVIC的8个中断组。
__IO uint32_t IABR[8]; 中断激活寄存器,指示哪些中断被激活,数组8个成员对应NVIC的8个中断组。
__IO uint8_t IP[240]; 中断优先级寄存器,设置优先级,共240个成员,每个成员1字节,对应MCU中的240个中断优先级设置。
__O uint32_t STIR; 软件触发中断寄存器,用于软件触发指定的中断。
所以,这个结构体包含了NVIC所有的控制与状态寄存器,通过这些寄存器,我们可以完成:
1. 中断使能与失能设置。
2. 中断待处理标志的置位与清除。
3. 检测哪些中断被激活。
4. 设置各个中断的优先级。
5. 软件触发某个指定的中断。
简单来说,这个结构体高度抽象和集成地代表了NVIC及其所有的功能与控制寄存器,使用时直接通过相应的成员来操作寄存器。
这个NVIC_Type结构体代表的不是某个具体的存储区域,而是概念性地将NVIC所有的寄存器集成在一个结构体中,以方便我们管理和访问这些寄存器。
结构体中的每个成员,如__IO uint32_t ISER[8]都代表NVIC中的一个实际的32位寄存器。
这些寄存器的地址在MCU的外设地址映射中已经固定,结构体将它们逻辑上集成在一起,方便我们按功能管理和访问。
所以,当我们需要操作NVIC使能某个中断时,只需要像下面这样使用ISER成员:
NVIC->ISER[2] |= (1 << 5); // 使能中断组2中的第6个中 这行代码通过NVIC结构体操作寄存器,而ISER[2]则映射到NVIC使能寄存器组2实际的物理地址。
在MDK或IAR等IDE中,这些寄存器的具体地址将在外设地址映射Memap窗口中显示。
例如,ISER[2]可能映射到0xE000E200这样的实际地址,这个地址上的32位寄存器包含对应的位用于使能第6个中断。
所以,总结来说:
1. NVIC_Type 结构体逻辑上将NVIC的所有寄存器集成在一起,方便管理和访问,但本身不代表实际的存储区域。
2. 结构体中的每个成员代表NVIC中的一个实际物理寄存器,映射到固定的地址。
3. 我们通过结构体操作这些寄存器,然后编译器会将其映射到实际的物理地址上。
4. 这些寄存器的具体地址将在MCU的外设地址映射中指定,我们可以在IDE的Memap窗口中查看。
5. 所以结构体更像是一个逻辑上的抽象,将NVIC的寄存器方便地集成在一起,在程序中按功能管理和访问。
 更多详细的内容得看这个
更多详细的内容得看这个

嵌套中断矢量控制器
Cortex-M3 NVIC寄存器的CMSIS映射为了提高软件效率,CMSIS简化了NVIC寄存器的表示。
在CMSIS中:Set-enable, Clear-enable, Set-pending, Clear-pending和Active Bit寄存器映射到32位整数数组,因此:
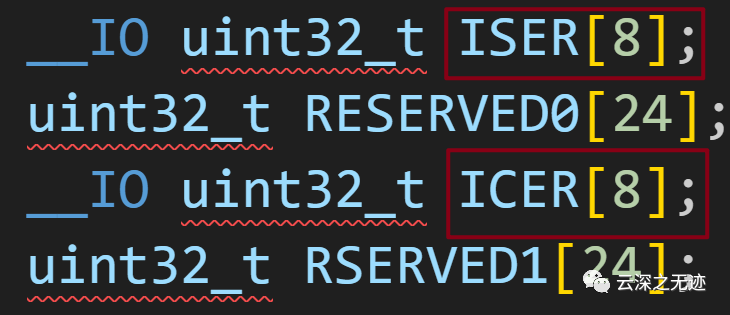
看这个IS,IC,下面就不放了
数组ISER[O] ~ ISER[2]对应寄存器ISERO-ISER2,
数组ICER[O] ~ ICER[2]对应寄存器ICERO-ICER2,
数组ISPR[0] ~ ISPR[2]对应寄存器ISPRO-ISPR2,
数组ICPR[O] ~ ICPR[2]对应寄存器ICPRO-ICPR2,
数组IABR[O] ~ IABR[2]对应寄存器IABRO-IABR2。
中断优先级寄存器的8位字段映射到一个8位整数数组,因此数组IP[O]到IP[67]对应于寄存器IPRO-IPR67,数组]条目IP[n]保持中断n的中断优先级。
CMSIS提供线程安全的代码,提供对中断优先级寄存器的原子访问。
我继续说更多的细节,__IO uint32_t ISER[8];比如这种写法前面的__IO 是干嘛用的?我来解释一下,看不懂的应该是没学过C。
__IO的定义如下:
#define __IO volatile
它被定义为volatile,意味着ISER[8]成员所代表的寄存器是一个读写寄存器。
所以,__IO的作用是:
1.通知编译器ISER[8]成员所对应寄存器的读写属性,是可读可写的。
2.阻止编译器对读写这些寄存器的代码做优化。因为这些寄存器的值可能会被其他因素改变,每次读写的值必须准确对应于寄存器的当前值。如果不使用__IO对其进行修饰,编译器在编译过程中可能会对访问这些寄存器的代码作优化,这会导致我们读到的值不是寄存器的真实值,产生意外的后果。
所以,__IO关键字通过定义为volatile,告诉编译器:
1. ISER[8]成员代表的寄存器是可读可写的。
2. 每次读取该寄存器必须从外设获取最新值,写入时必须将新值准确写入外设。
3. 编译器在编译过程中不得对其进行任何优化。
简单来说,__IO关键字修饰uint32_t ISER[8]成员,目的是通知编译器其对应的寄存器属性和访问要求,进而阻止编译器的优化,确保我们的程序以预期的方式正确访问这些寄存器。这有利于我们编写的代码正常工作,不会因为编译器的优化引入意外的副作用,访问寄存器时总是获取最新的准确值。
说完了吗?还没有,我还想bibi几句:
在C语言中,__IO这样在标识符(如结构体成员名)前面加上的关键字被称为修饰符(qualifier)。修饰符的作用是为标识符添加某种属性或额外的语义。__IO 就是一个典型的修饰符例子,它被用来表示标识符代表的是一个读写寄存器,并禁止编译器对其优化。
所以,__IO 在这里相当于一个寄存器的修饰符,为其添加读写以及volatile 的属性。
在C语言中,常见的修饰符还有:
1.const:常量修饰符,用于表示标识符是一个常量。
2.volatile:指示值可能会被其他因素改变的修饰符,告诉编译器每次读取该值必须重新从内存中获取。
3.restrict:表示某指针是唯一访问某块内存的手段,可以用来提高效率。
4.inline:表示该函数是内联函数,由编译器直接将函数体插入调用处。
5. extern:表示该标识符(如变量或函数)的定义在其他地方,extern int a;
所以,总结来说:
1.修饰符是放在标识符(如变量名、函数名、结构体成员名)前面的关键字。2.修饰符的作用是为标识符添加某种属性或语义。
3.__IO 是作为寄存器修饰符使用的,表示寄存器是可读写的,并禁止编译器对其优化。
4.const、volatile、restrict、inline、extern都是常见的修饰符,用来表示常量性、值变化、函数内联等属性。
5.使用修饰符可以为程序添加重要的额外信息,引导编译器作出正确的处理。
再扩展一些,这个东西可以在函数上面用吗?我这里先喷,以前不懂这个群里面问半天,结果都鸡儿半桶水,让我写什么程序自己实验,真心累啊。
在C语言中修饰符也可以用于修饰函数。
常见的用于修饰函数的修饰符有:
1. inline:表示该函数是内联函数,主要作用是鼓励编译器将函数体直接插入所有调用点,以减少函数调用的开销。
2. extern:表示该函数的定义在其他地方,用于函数前向声明。例如: inline void func1() { ... } // 内联函数
extern void func2(); // 函数前向声明
void func2() { ... } // 函数定义 在这个例子中:
func1被inline修饰,表示其是一个内联函数,编译器可以选择将其函数体插入调用处。
func2首先被extern修饰,进行前向声明,然后给出函数定义。
另外,static、volatile 等修饰符也可以用于修饰函数,区别如下:
static:static修饰的函数只在定义它的文件内可见,表示私有函数。
volatile:volatile修饰的函数其地址可能改变,每次调用时必须从内存中获取最新地址。
主要用于嵌入式中断函数等。所以,总结来说:
1.C语言中的修饰符不仅可以用于修饰变量,也可以用于修饰函数。
2.常见的用于修饰函数的修饰符有inline、extern、static、volatile等。3.inline表示内联函数,extern表示函数前向声明,static表示私有函数,volatile表示地址可能改变的函数。
4.使用修饰符可以为函数添加额外的属性和语义,引导编译器生成我们期望的代码,这在优化程序性能方面具有很好的作用。
那我在这个函数前面就放一个用宏定义的修饰符,宏什么都不定义。这个会报错了,一定要记住程序是最确定的东西。
#define __MY_MODIFIER
__MY_MODIFIER void func() { ... }
这里的__MY_MODIFIER宏未进行任何定义,所以编译器并不知道它表示什么属性或语义。在编译这个代码时,编译器会报类似下面的错误:undefined identifier '__MY_MODIFIER'这是因为编译器并不识别__MY_MODIFIER这个未定义标识符,所以不明白它作为函数修饰符的作用,这会导致编译错误。要使用我们自己定义的修饰符,需要为其给出明确的定义,例如:
#define __MY_MODIFIER static
__MY_MODIFIER void func() { ... }
这里我们定义__MY_MODIFIER为static,这样编译器就能理解其作用,并将func函数定义为静态的。所以,总结来说:1. 若要使用自定义的修饰符,必须为其给出明确的定义,否则编译器无法理解其作用,会报错。2.自定义修饰符的定义可以通过#define来实现,例如#define __MY_MODIFIER static。 3. 定义后,修饰符可以用于修饰变量、函数等,编译器会根据其定义来理解其修饰的作用。4. 未定义的修饰符会导致编译错误,因为编译器不知道如何处理这个未知的标识符。 5. 自定义修饰符的一个重要应用就是,当标准修饰符无法满足需要时,我们可以定义自己的修饰符来扩展语言和表达程序语义。

对于这个中断的寄存器就是这些,不要陷入太深,继续往下看
系统控制块(SCB)系统控制块(System control block, SCB)提供系统实现信息和系统控制。这包括系统异常的配置、控制和报告。
Cortex-M3 SCB寄存器的CMSIS映射为了提高软件效率,CMSIS简化了SCB寄存器的表示。
在CMSIS中,字节数组SHP[0]到SHP[12]对应寄存器SHPR1-SHPR3。
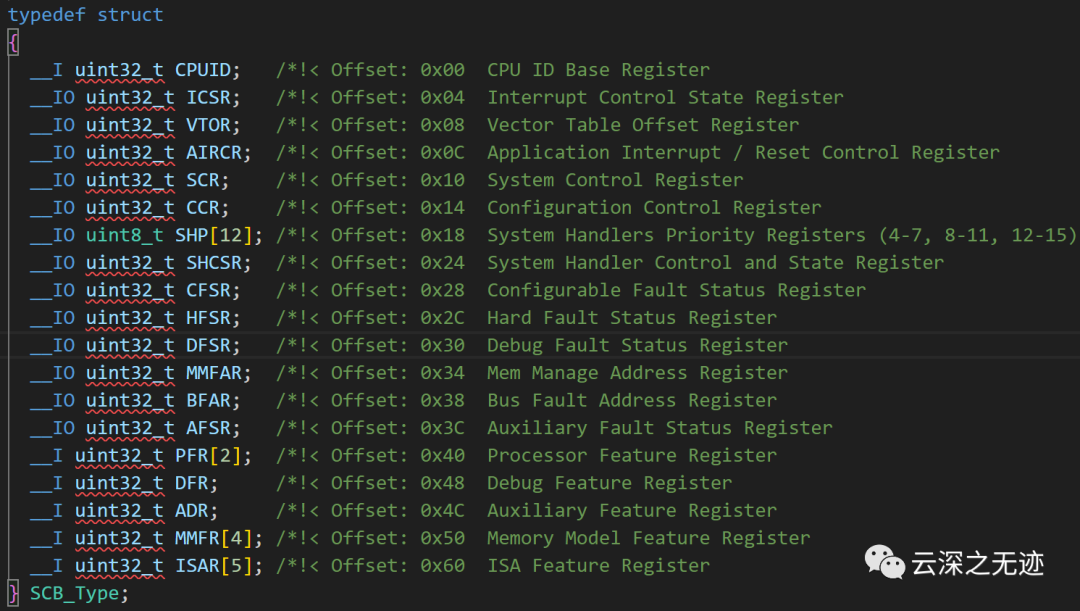
接着就是这个了
这个结构体定义了SCB(系统控制块)的寄存器集。SCB模块是Cortex-M内核的一部分,用于系统控制与配置。
SCB_Type 结构体包含以下主要成员:
__I uint32_t CPUID; CPUID寄存器,包含设备ID和修订信息。
__IO uint32_t ICSR; 中断控制状态寄存器,用于中断使能、优先级设置和挂起状态控制。
__IO uint32_t VTOR; 向量表偏移寄存器,配置中断/异常向量表的位置和偏移。
__IO uint32_t AIRCR; 应用中断/复位控制寄存器,用于配置中断优先级组和系统复位。
__IO uint32_t SCR; 系统控制寄存器,用于配置中断优先级组、SLEEPDEEP位等。
__IO uint32_t CCR; 配置控制寄存器,用于配置存储器mapped模式和无效指令报告位。
__IO uint8_t SHP[12]; 系统句柄程序优先级寄存器,设置不同异常的优先级。
__IO uint32_t SHCSR; 系统句柄控制和状态寄存器,报告不同异常的挂起和激活状态。
CFSR、HFSR、DFSR; 可配置故障状态寄存器,用于报告各种故障和异常的状态。
MMFAR、BFAR;内存错误和总线故障地址寄存器,报告相关故障的地址。PFR、DFR、ADR; 寄存器用于报告处理器特征、调试功和辅助功能。MMFR、ISAR; 寄存器用于报告内存模型和指令集架构的特征。
所以,SCB_Type结构体包含SCB模块所有的控制/状态寄存器和ID寄存器,通过这些寄存器我们可以完成:
1. 中断控制(使能/禁止)和优先级设置。
2. 配置向量表位置和系统复位。
3. 设置不同异常的优先级别。
4. 获取设备ID、内核修订版本以及各种特征信息。
5. 获取并处理不同类型的故障和异常。
6. 配置系统控制位,如SLEEPDEEP。
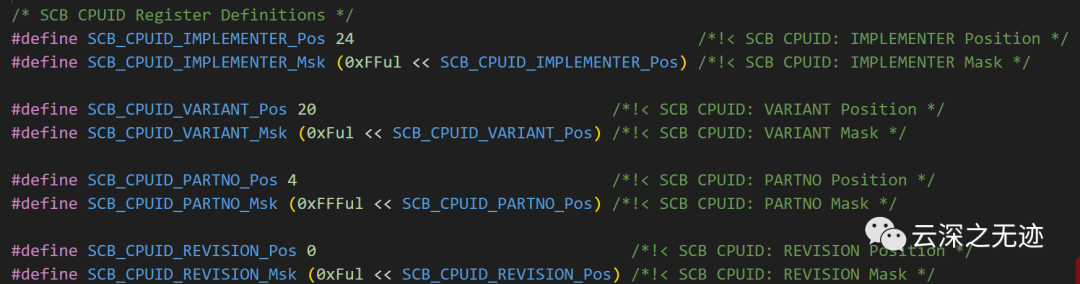
接下来定义的是这样的东西,本来这种细节的东西就不写了,但是为了精通这个小目标是要写的。
上面这个代码可能看起来有点懵逼,这里其实都是底层的寄存器,不妨去看看这个:
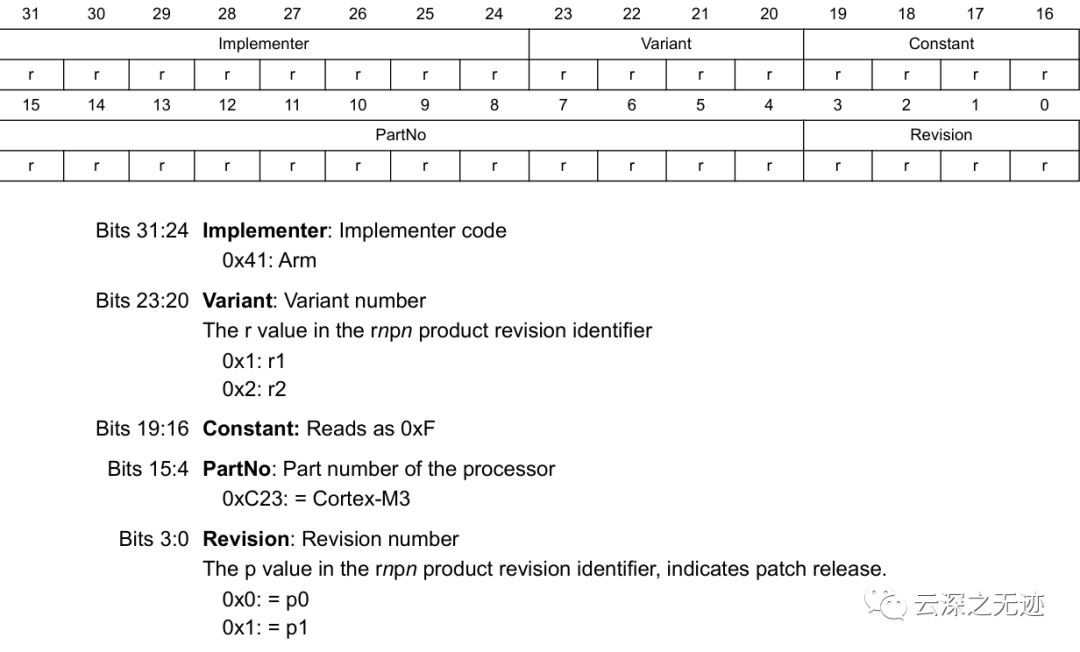 这个就是对应的寄存器布局,我们只是想知道里面是啥而已
这个就是对应的寄存器布局,我们只是想知道里面是啥而已
这些宏定义用于读取SCB->CPUID寄存器中的设备ID和修订信息。其中:SCB_CPUID_IMPLEMENTER_Pos和SCB_CPUID_IMPLEMENTER_Msk用于读取IMPLEMENTER字段,该字段包含CPU的制造商ID。SCB_CPUID_VARIANT_Pos和SCB_CPUID_VARIANT_Msk用于读取VARIANT字段,该字段包含CPU的变体编号。SCB_CPUID_PARTNO_Pos和SCB_CPUID_PARTNO_Msk用于读取PARTNO字段,该字段包含CPU的具体型号。SCB_CPUID_REVISION_Pos和SCB_CPUID_REVISION_Msk用于读取REVISION字段,该字段包含CPU的修订版本。所以,通过这些宏,我们可以从SCB->CPUID寄存器中提取关键的设备信息:制造商ID:
uint32_t implementer = (SCB->CPUID & SCB_CPUID_IMPLEMENTER_Msk) >> SCB_CPUID_IMPLEMENTER_Pos;
变体编号:
uint32_t variant = (SCB->CPUID & SCB_CPUID_VARIANT_Msk) >> SCB_CPUID_VARIANT_Pos;
CPU型号:
uint32_t partNo = (SCB->CPUID & SCB_CPUID_PARTNO_Msk) >> SCB_CPUID_PARTNO_Pos;
CPU修订版本:
uint32_t revision = (SCB->CPUID & SCB_CPUID_REVISION_Msk) >> SCB_CPUID_REVISION_Pos;
ARM Cortex-M内核的CPUID寄存器包含这些关键字段,方便识别和区分不同的芯片,并获取其精确的型号与修订信息。宏定义极大地简化提取这些信息的过程,只需要通过位域操作和移位就可以获得所需要的ID参数,这在很大程度上增强了代码的可读性。

不在乎含义,在乎写法,接下来看写法
SCB_CPUID_IMPLEMENTER_Pos代表:
IMPLEMENTER字段在CPUID寄存器中的起始位置(偏移),其值为24。
SCB_CPUID_IMPLEMENTER_Msk代表:
IMPLEMENTER字段的掩码,通过将0xFF左移24位得到,其值为0xFF000000。所以,要读取IMPLEMENTER字段,我们可以像下面这样使用这两个宏:
uint32_t implementer = (SCB->CPUID & SCB_CPUID_IMPLEMENTER_Msk) >> SCB_CPUID_IMPLEMENTER_Pos;
该语句通过与SCB_CPUID_IMPLEMENTER_Msk的位与操作获取IMPLEMENTER字段,然后右移SCB_CPUID_IMPLEMENTER_Pos(24)位,将其移到最低8位,obtaining the implementer code.
例如,如果CPUID的值为0x410FC241,那么:SCB->CPUID = 0x410FC241
SCB_CPUID_IMPLEMENTER_Msk = 0xFF000000
通过与操作:0x410FC241 & 0xFF000000 = 0x41000000
右移24位:0x41000000 >> 24 = 0x41 = 65(十进制)所以,IMPLEMENTER字段的值为65(十进制),表示CPU的制造商是ARM。位域操作通过掩码获取目标字段,位移则将其移到需要的位置。
位域和位移都是位运算的概念,用于在二进制位级别操作和访问数据。位域操作用于在一个数据域(如寄存器)的不同位上访问多个字段。它通过掩码来选择和操作目标字段中的位。
常用的位域操作有:与(&):如果两个操作数的对应比特位都是1,则该位的结果为1,否则为0。用于选取目标字段。或(|):只要两个操作数的对应比特位有一个为1,则该位的结果为1。用于修改或设置字段的值。非(~) :反转操作数的每一位,0变1,1变0。用于对字段取反。
位移则用于将数据的位向左或向右移动给定的位数,实际上是在给定方向上对数据的表示形式进行扩展或截断。
按方向分为:左移(<<):向左移动,低位补0,用于扩展数据类型或实现乘法。右移(>>):向右移动,根据数据类型,高位或补0或补符号位,用于缩小数据类型或实现除法。
所以,要访问SCB->CPUID寄存器的不同字段,我们可以:1.使用与操作和掩码获取目标字段,例如用SCB_CPUID_IMPLEMENTER_Msk获取IMPLEMENTER字段。2.必要时使用位移将字段移到需要的位置,例如用SCB_CPUID_IMPLEMENTER_Pos右移24位将IMPLEMENTER移到低8位。3.组合位域操作读取和修改字段。例如用或操作将某位设置为1,用与操作清0某位。
例如,要读取CPUID的IMPLEMENTER字段:
uint32_t implementer = (SCB->CPUID & SCB_CPUID_IMPLEMENTER_Msk) >> SCB_CPUID_IMPLEMENTER_Pos;
要设置CPUID的REVISION字段的第3位:
SCB->CPUID |= (1 << 3); // 用或操作将第3位设置为1
要清CPUID的VARIANT字段的低4位:
SCB->CPUID &= ~((0xF) << SCB_CPUID_VARIANT_Pos); // 用与操作和反码清除低4位
继续放大镜看这个代码,我们看这个1ul的定义方式:

1ul
1ul是一个无符号长整型(unsigned long)常量,其值为1。在C语言中,整型常量的默认类型为int,但可以通过后缀来指定不同的类型。常见的后缀有:无符号(unsigned):- u或U:无符号整型,如1u
- ul或UL:无符号长整型,如1ul长整型(long):- l或L:长整型,如1l无符号长整型(unsigned long):- ul或UL:无符号长整型,如1ul大小写无关,所以1u、1ul、1U和1UL都是等价的。
使用这些后缀的主要目的是为了在某些情况下指定常量的精确类型,避免由默认类型带来的怪异行为。例如,在32位系统上,int和unsigned int都是32位,所以1和1u的值相同。
但long可能是32位,而unsigned long是64位,所以1l和1ul的值会不同。所以,当我们需要一个无符号的32/64位整型常量时,就可以使用1u或1ul来指定其精确类型,这可以避免一些潜在的问题。
另外,这些后缀也常用于定义寄存器和位域的掩码常量,例如:
#define UART_DATA_MASK 0xFFul // 8位无符号数据掩码 #define UART_PARITY_MASK 0x01ul // 1位无符号奇偶校验位掩码
这里使用ul是为了确保掩码常量被定义为32位,与寄存器大小一致。所以,总结来说:1. 1ul是一个无符号长整型常量,其值为1。2. 后缀u、ul、U和UL用于定义无符号整型和无符号长整型常量。3. 使用这些后缀可以指定常量的精确类型,避免默认类型带来的问题。4. 这些后缀常用于定义寄存器和位域的掩码常量,确保其大小与目标寄存器一致。
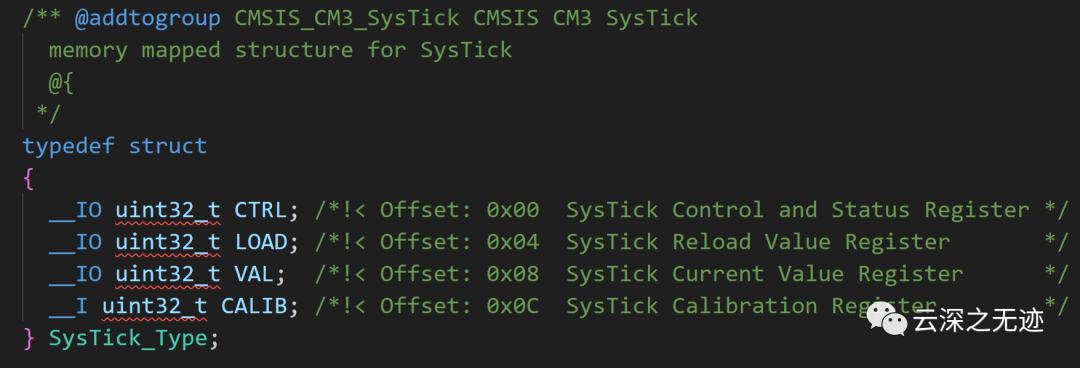
这个结构体定义了SysTick定时器的寄存器集。SysTick是Cortex-M内核的一部分,用于生成定时中断和延时。
SysTick_Type结构体包含以下成员:
__IO uint32_t CTRL; SysTick控制和状态寄存器,用于使能SysTick定时器,选择时钟源和计数模式。
__IO uint32_t LOAD; SysTick重载值寄存器,设置SysTick定时器的重载值,该值决定定时周期。
__IO uint32_t VAL; SysTick当前值寄存器,在运行过程中存储SysTick定时器的当前值。
__I uint32_t CALIB; SysTick校准值寄存器,提供设备特定的时钟频率信息,用于计算延时。
所以,通过这个结构体,我们可以访问SysTick定时器的所有控制/状态寄存器和校准寄存器,并完成:
1. 使能或关闭SysTick定时器。
2. 选择SysTick的时钟源,如内核时钟AHB或外部参考时钟。
3. 选择递减计数模式或递增计数模式。
4.设置SysTick定时器的重载值,配置其定时周期。
5.读取当前的计数值VAL。
6.获取设备的时钟频率信息CALIB,用于生成精确延时。
7.SysTick定时器溢出时产生中断,所以也用作系统的节拍定时器。
SysTicktimer(STK)处理器有一个24位系统计时器SysTick,它从重新加载值开始计数到零,在下一个时钟边缘重新加载(封装到)LOAD寄存器中的值,然后在随后的时钟上计数。当处理器停止调试时,计数器不会减少。
再详细一些介绍这个:
1.最大计数值为24位,所以最大延时为16777216个时钟周期。
2.可以选择内核时钟AHB或外部参考时钟作为时钟源。
3.可以选择递增计数模式或递减计数模式。
4.重载值寄存器LOAD用于设置定时周期,每次定时器溢出时重新装载该值。
5.当前值寄存器VAL存储定时器的实时计数值。
6.定时器溢出时触发SysTick异常请求,可以配置为产生中断。
7.时钟频率预分频因子固定为8,不可配置。
8. 中断优先级固定为最低级别,仅可屏蔽但不可修改。
9.包含一设备特定的校准寄存器,提供系统时钟频率信息,用于实现准确延时。基
于以上特性,我们可以这样配置和使用SysTick定时器:
1.使能SysTick定时器,选择AHB时钟源。
2.配置 SysTick_LOAD寄存器为重载值(如1000),每1000个时钟周期产生一个中断。
3.等待SysTick定时器中断,并在中断服务程序内进行任务调度或其他定时任务。
4.获取SysTick_CALIB的值,例如0x0320,表明每个时钟周期大约为30.5us。
5.要延时100ms,计算需要的时钟周期数:100ms / 30.5us = 3276。写入SysTick_LOAD,使能定时器。
6.等待SysTick定时器中断,表示延时完成。
所以,SysTick模块为Cortex-M3内核提供了一个简单而高效的定时器,可用于RTOS的任务调度、软件延时和其他定时事件。它的24位计数器和微秒级精度可以满足大多数应用的需要。
和其它的定时器外设比较有什么区别?
SysTick定时器有以下主要用途:
1.提供系统节拍定时器,用于RTOS的任务调度。RTOS可以配置SysTick产生中断,并在中断处理程序中进行任务切换。
2.实现软件延时。我们可以根据SysTick的定时周期计算需要的计数值来生成所需延时。
3.其他定时事件。SysTick定时器可以用于系统的各种定时任务,如定时监测、看门狗喂狗等。
与其他定时器外设相比,SysTick定时器有以下区别:
1.SysTick定时器是Cortex-M内核的一部分,而其他定时器属于MCU的外设。所以SysTick定时器更轻量,通用性更强。
2.SysTick定时器的时钟源只能选择内核时钟或外部参考时钟,而其他定时器通常有更多时钟源选择。
3.SysTick定时器的计数器只有24位,范围更小。其他定时器的计数器可以达32位或更高。
4.SysTick定时器的中断优先级固定为最低,无法配置。其他定时器的中断通常可以配置优先级。
5.SysTick定时器只有比较基本的控制寄存器,更简单。其他定时器通常具有更丰富的控制与配置选项。
6.SysTick定时器的溢出事件只能产生中断,无法产生DMA请求等。部分定时器可以通过多种方式响应溢出事件。
让我来说下这个计数模式:
递增计数模式和递减计数模式是定时器的两种不同的计数方式:
递增计数模式:定时器的计数器从初始值(通常为0)开始递增,当计数器达到重载值时,定时器溢出。然后计数器重载为初始值,重新开始递增。如果配置为产生中断,则在计数器达到重载值时触发中断。
例如,如果初始值为0,重载值为100,则计数序列为:
0, 1, 2, 3, ... 98, 99, 100 - 触发中断 - 0, 1, 2, 3 ...
递减计数模式:
定时器的计数器从重载值开始递减,当计数器达到0时,定时器溢出。然后计数器重载为重载值,重新开始递减。如果配置为产生中断,则在计数器达到0时触发中断。
例如,如果重载值为100,则计数序列为:
100, 99, 98, 97 ... 3, 2, 1, 0 - 触发中断 - 100, 99, 98 ...
所以,主要差异在于计数器的初始值和溢出条件不同:
递增模式:
初始值:通常为0
溢出条件:计数器达到重载值
递减模式:
初始值:等于重载值
溢出条件:计数器达到0
让我们来探究一下这个设计意图,就是定时器的设计意图。
1.适应开发者的习惯。有的开发者更习惯从0开始递增计数,有的更习惯从最大值开始递减计数,所以提供两种模式以满足不同习惯。
2.方便实现定时器的溢出中断。无论是递增模式从0溢出到重载值,还是递减模式从重载值溢出到0,都可以很简单地通过比较计数器与重载值/0来检测溢出事件并产生中断。
3.扩展定时范围。24位的定时器,递增模式下最大延时为2^24个周期,若选择递减模式,最大延时可扩展为2^24 + 重载值个周期,所以可获得较大的定时范围。
4. 不同模式下的溢出事件可用于不同用途。例如,可以选择递增模式用于周期性中断,而选择递减模式用于超时检测。两种事件可以同时使用,扩展定时器的应用。
5. 简化硬件设计。提供两种模式而非只有一种,可以在软件中通过配置来选择模式,而不需要硬件支持两套完全不同的定时与计数逻辑,简化了定时器模块的设计。
接下来说这个设计上面的简便性,这个就比较深奥了,之后我如果把玩FPGA我会写详细的。
如果SysTick定时器仅支持递增模式或递减模式中的一种,则其硬件结构可以简单设计为:
- 24位计数器寄存器
- 24位重载寄存器
- 比较逻辑,比较计数器与重载寄存器,产生溢出事件
但是,为了支持两种模式,SysTick定时器的硬件结构可以设计为:
- 24位计数器寄存器
- 24位重载寄存器
- 1位递增/递减模式选择位
- 比较逻辑,当模式选择位选择递增模式时,比较计数器与重载寄存,当选择递减模式时, 比较计数器与0,以产生溢出事件。
可以看到,仅添加一个1位的模式选择逻辑,SysTick定时器就可以支持两种模式,而不需要实现两套完全独立的计数/比较逻辑。在软件层面,我们只需要设置MODE位为0选择递增模式,设置为1选择递减模式,然后处理溢出事件中断即可。
硬件层面已经为两种模式实现了统一的定时逻辑。可以想象,如果定时器需要同时支持4种或更多种模式,仅靠硬件实现各自独立的定时机制会变得非常复杂。
而采用类似SysTick的方式,通过软件配置选择定时模式,硬件只需实现一套相对通用的定时机制,这无疑可以大大简化定时器模块的设计。
-
Cortex-M产品的特色2025-11-26 231
-
Cortex-M位带操作的原理2023-10-24 1955
-
深入理解Cortex-M内存管理(Keil)2023-04-27 8134
-
如何使用Ozone分析Cortex-M故障?2022-09-23 3543
-
如何利用C语言的位域操作去实现对寄存器每一位的控制2022-02-25 793
-
Cortex-M3寄存器等基础知识2022-02-08 922
-
Cortex-M系列MCU错误追踪库有何作用2022-01-25 1053
-
Cortex-M3 内部寄存器2021-11-26 891
-
Cortex-M 系列处理特点和区别详解2021-01-14 3561
-
如何选择正确的Cortex-M处理器?2020-10-22 2455
-
米尔科技Cortex-M Prototyping System +介绍2019-11-14 2897
-
关于Cortex-M 调试应用的介绍2018-07-10 3194
-
为什么说Cortex-M是低功耗应用的首选2017-07-28 4088
-
32位寄存器,32位寄存器是什么意思2010-03-08 18041
全部0条评论

快来发表一下你的评论吧 !
