

嵌入式技术数据结构中常见的树有哪些?
嵌入式技术
描述
哈夫曼树(Huffman Tree)
哈夫曼树,又被称为最优二叉树,属于带权值二叉树的一种。它的真实节点全部分布在叶子节点中,是各种可能的组合中 WPL 值最小的形式。组合形式可能不唯一,但 WPL 值一定为最小。
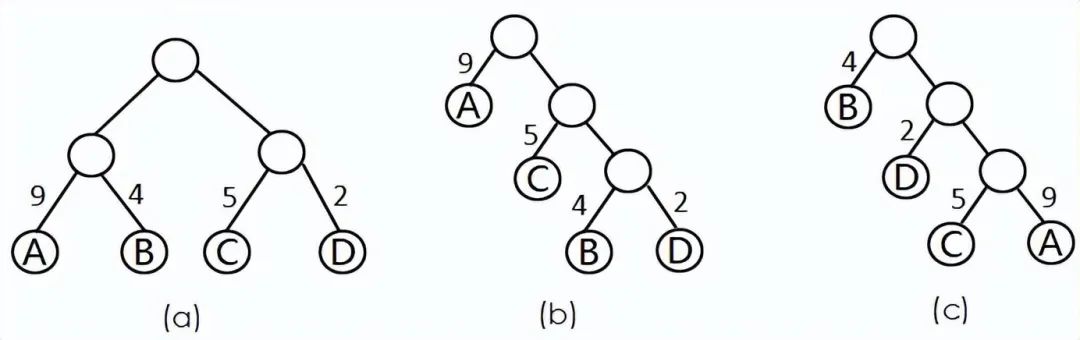
介绍一下 WPL(Weighted Path Length),也就是 带权路径长度,说简单一些就是【节点到根节点的路径长度 * 该节点的权值】。说白了就是权值越大的节点,离根节点越近就对了。 WPL_A = 9x2+4x2+5x2+2x2 = 40
WPL_B = 9x1+5x2+4x3+2x3 = 37
WPL_C = 4x1+2x2+5x3+9x3 = 50 看一下上面这张图和三个对应的 WPL 的值,很明显可以看出来(b)是[9,4,5,2]这几个节点对应的哈夫曼树(的一种表现形式)。我们刚才也提了,哈夫曼树组成的形式可能不唯一,就比如说把(b)镜像过来看,也是哈夫曼树。 哈夫曼树的应用中,最有名的就是哈夫曼编码了。通过这种编码方式,可以使得整体编码的长度最短。还需要说明的是,它是一种前缀编码,任何一个编码值,都不会为其他编码值的前缀(最左子串)。 在 NLP(自然语言处理)领域划时代之作—— word2vec 的过程中,也通过哈夫曼树结构来加速查询高频词语,有兴趣的朋友可以了解一下。
最小生成树(Minimum Spanning Tree)
最小生成树,虽然叫做“树”,但是它更多地出现在“图”相关的知识中,描述的是将一个有权图,转化成 所有节点均可连通,并且连接两边的权值之和最小的树形结构。提到这个,就肯定要说一下大名鼎鼎的 Prim 算法 和 Kruskal 算法,这两种算法分别是从 随机顶点的角度 和 权值最小的边的角度 出发,一步一步地选出适合的边,然后最终形成一颗包含全部 n 个节点和 n-1 条边的最小生成树。
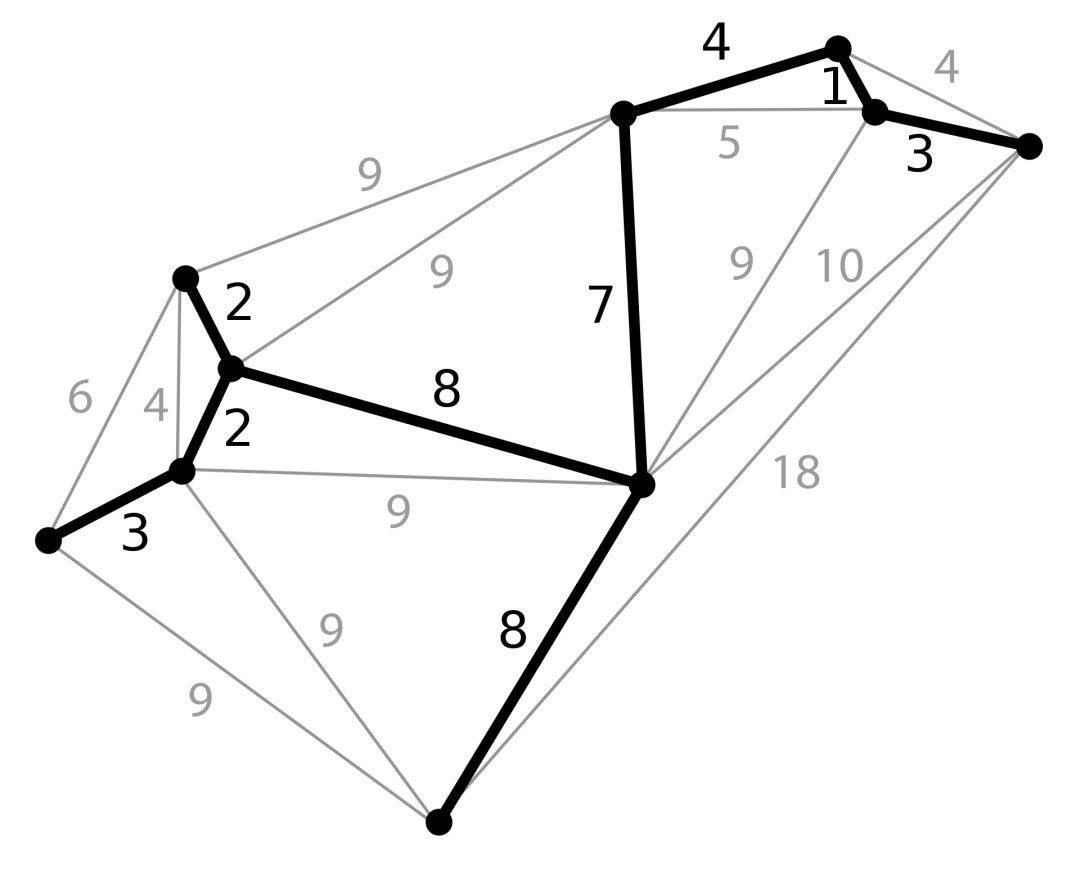
这方面比较经典的应用,就比如多个城市之间建铁路,要求每个城市都连通、并且铁路距离总和最小这种问题。后来我想想,送外卖的时候兴许也能用到这个方法,该为 35 岁之后的职业生涯提前规划起来了。
线段树(Segment Tree)
线段树,是一种特殊的平衡二叉查找树,每个叶子节点表示一个真实的节点信息。而路径上所有的非叶子节点,用来表示它包含的各层级子节点的范围,并用于标记这个范围内的一些信息,比如范围内的 max 值或 sum 值等。 线段树可以较好地兼顾区间插入新数据和单点数据修改的逻辑。当更新叶子节点内容的时候,只要更新该节点对应路径上的节点信息即可。主要用于一些对范围查询有很高要求的场景。
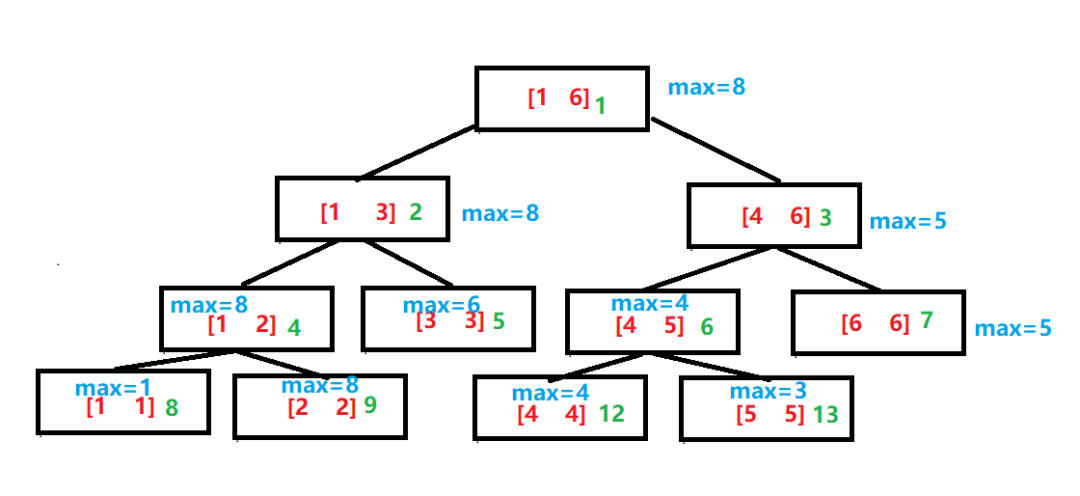
值得一提的是,线段树可以通过一个一维数组来表示,如上图中绿色数字所示(其中 10、11 为空缺信息)。还需要说明的一点是,类似的概念还有区间树,也有人将这两个概念画了等号,大家自行了解分辨。
伸展树(Splay Tree)
伸展树是一颗非平衡二叉搜索树。它的设计思路是基于一种假设:最频繁被查询的信息,它(和它附近的节点)在下次查询的时候更可能被查到。所以,通过 Splay Tree 查询的时候,会随着被查询的信息,反复调整树本身的结构,从而将经常被查询到的节点,放到 root 附近。这样就可能会加速查询的效率。 这个乍一听,有点像 LRU 或者 LFU 类似的结构,但又有所不同。首先,Splay Tree 中会保留所有的节点信息,不存在过期(或超限)销毁的情况。还有一点就是它并不是被查到之后立即置顶,会有一些其他的综合考量(比如,每次最多进行两次 n 次旋转)。
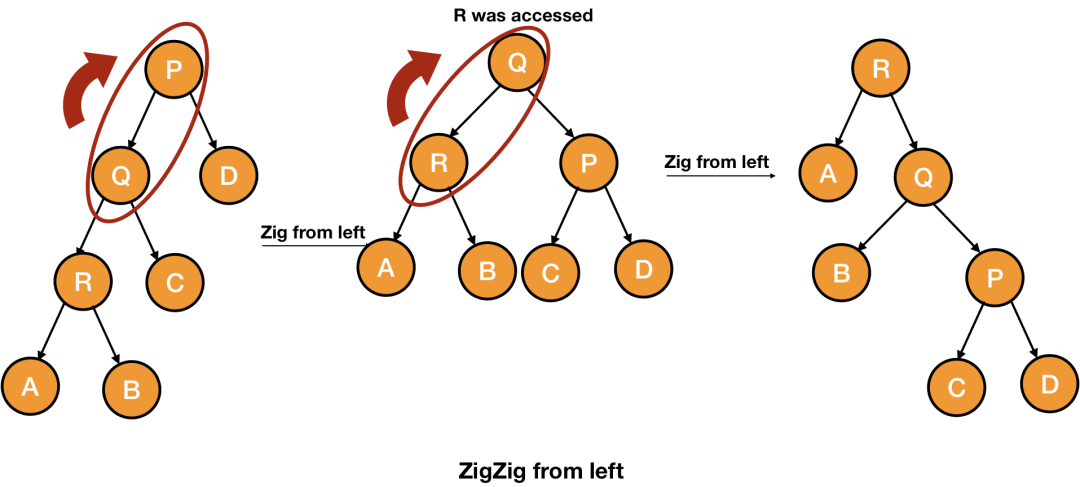
看一下上面这张图吧,它模拟的是(频繁)查询 R 的时候,Splay Tree 的变化情况。说白了就是把 R 节点放到根节点的位置,下次查起来就方便多了。Splay Tree 比较适合做缓存,特别是在热点数据相对集中的情况下,查询效率很高。举个应用的例子吧:我们常用的输入法,当你输入完拼音之后,会根据你的之前的选择情况,优先出现某些词语。但很多情况下,又不会直接把你上次选择的词语直接置顶,这就可以理解为是参考了伸展树的思路(当今输入法的排序,实际更多的应该是用 AI 算法是做概率预测,而非单纯的 Splay Tree)。
数据库领域
数据库中非常核心的一个部分,就是索引结构的设计——这几乎决定了数据库的应用领域。而索引结构的设计,又是数据结构和算法的“重灾区”。下面我们就来列举几种数据库领域中,常见的树结构。
B 树
传统的二叉树中,每个节点中包含一个信息,这样如果节点数比较多,路径就会很深。路径深了,对应的问题就是查询的过程中,需要经过更多的节点,从而造成性能下降。基于此,B 树诞生了。 B 树也属于一种自然平衡树。内部通过分裂机制,能够保持数据的有序。它的单个节点中可以保存 2~4 个信息。单个节点内部有序,节点之间信息的间隔,可以作为划分下面部分的依据。
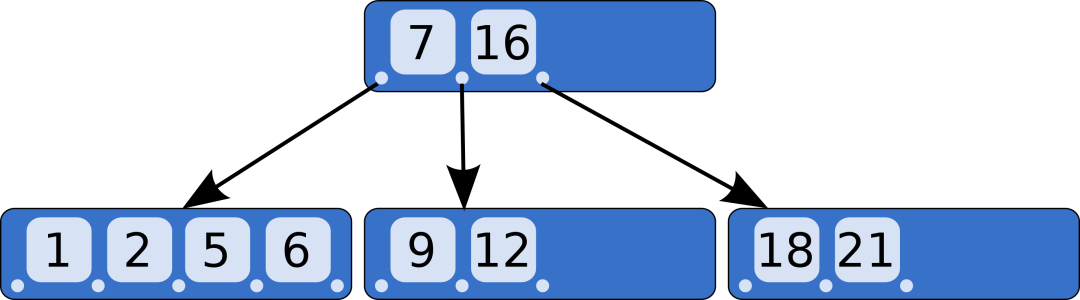
看上面这张图,树中一共有 10 个人信息,按照红黑树的形式存储,最长的路径应该是 4。而通过 B 树进行存储,就会显得“矮胖”了,对应的跨节点查询次数也就缩短了。 B 树比较适合于单点查询的场景,比较常见的应用就是 MongoDB 了。当然了,B 树也有一些不适合的场景,比如所有节点都放在磁盘上,则读写性能相对差;再比如说,如果我想查 5~9 范围内的所有数据,用 B 树是不是就需要在 3 个节点中反复横跳?
B+树
B+树就是为了解决上面抛出的两个问题而设计的。与 B 树相同的是,B+树的节点中也包含了多个信息。但相比于 B 树,B+树做了一些改动:非叶子节点中仅保留数据之间的相对关系,而所有的真实信息均包含在叶子节点中。这样的话,相对关系信息就可以放到内存中,而将所有节点信息(可以认为量较大)保留在磁盘中。
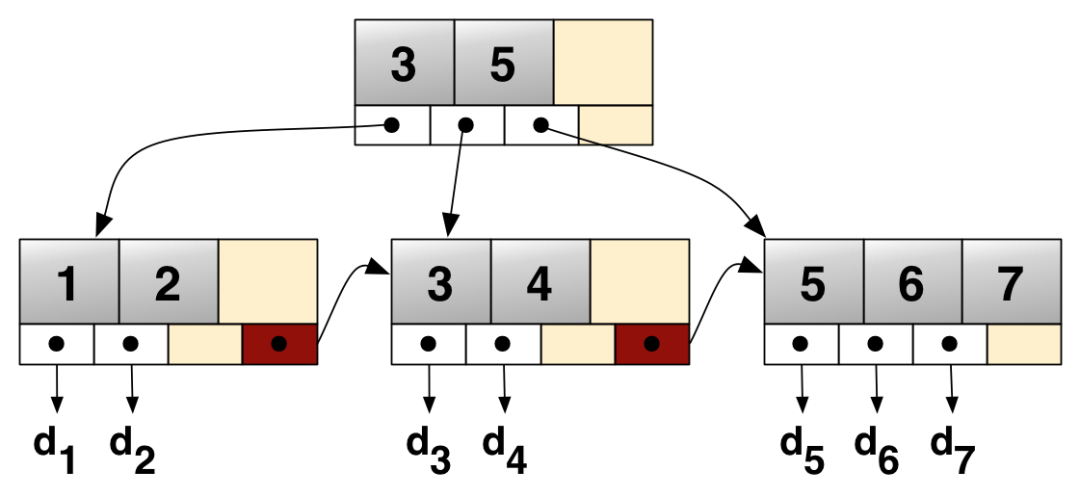
每次查询,通过相对关系,在内存中就可以快速的定位到具体的节点信息,从而减少磁盘的 IO 次数。这样做还有一个好处,可以通过一条“线”将所有叶子节点串联起来,从而方便做范围查询。大名鼎鼎的 Mysql 的存储引擎 InnoDB,使用的就是这种思路。 不知道有没有朋友跟我一样,在很长的一段时间内,把数据库索引和 B+树画上了等号。其实不然,不同应用领域的数据库,有着不同的索引结构。B+树的信息存放在磁盘中,且属于非顺序写入,所以查询性能很高,但写入的性能偏低。在大数据存储和日志服务等需要频繁写入操作的领域,就有些不合适了——这就要引出我们接下来的话题了。 日志结构化合并树(Log Structured Merge Tree) 多年前,谷歌在发大据领域发表了Big Table相关论文,LSM 树是其中的实现思路。我第一次听说 LSM Tree,是有幸跟一位 HBase 领域的资深大佬一起喝茶的时候。当时我红着脸表示,只听说过其中的一部分。
与其说它是一种数据结构,其实它更像是基于此思想而衍生出的一系列算法操作的集合。它描述了将实时产生的大批量信息在内存中排序、更新,然后按批次顺序写入磁盘固化、合并的流程,从而兼顾了大批量数据的高效写入存储和范围查询等使用场景。 我们刚才提到,B+树结构的存储索引并不适合在频繁写入的场景,其中一个很重要的原因就是因为它属于非顺序写入。而针对传统磁盘来说,由于扇区物理结构轮转,顺序写入的性能远好于非顺序写入。
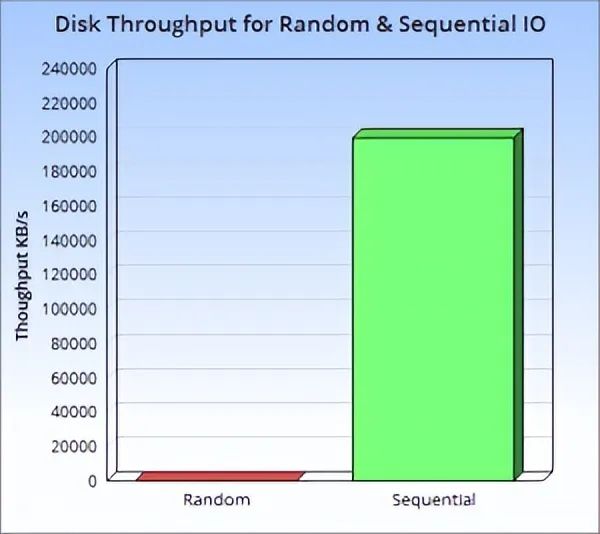
•随机写入磁盘慢了咋办?
将非顺序的信息在内存中攒成有序的一批信息(Segment),然后一次性写入磁盘不就好了么。 •攒批的时候,数据丢失或者进程崩溃了咋办?
提前把数据写到一个本地日志文件(WAL 机制)里做备胎(不对,是备份)不就好了。
•需要在批量数据中做范围查找了咋办? 在内存中记录每个 Segment(默认有序)的起止范围,每次查询的时候仅查询范围内的 Segment 不就好了。
•数据量太大,磁盘中的 Segment 太多,影响查询性能了咋办?
当每个 Segment 大到一定的程度的时候,把几个 Segment 做归并排序,然后合并到一个大的 Segment 里不就好了么。
•写入数据之后,想删除咋办?
根据 key 找到最后一次写入的信息,打上墓碑记号。查询到的时候,返回“这个真没有”不就好了么。
•墓碑记号太多,占用大量内存,咋办?
•单点信息查询,数据太多,而且经常 miss,咋办?•范围查询,不好确认从哪个 Segment 开始,咋办?•...
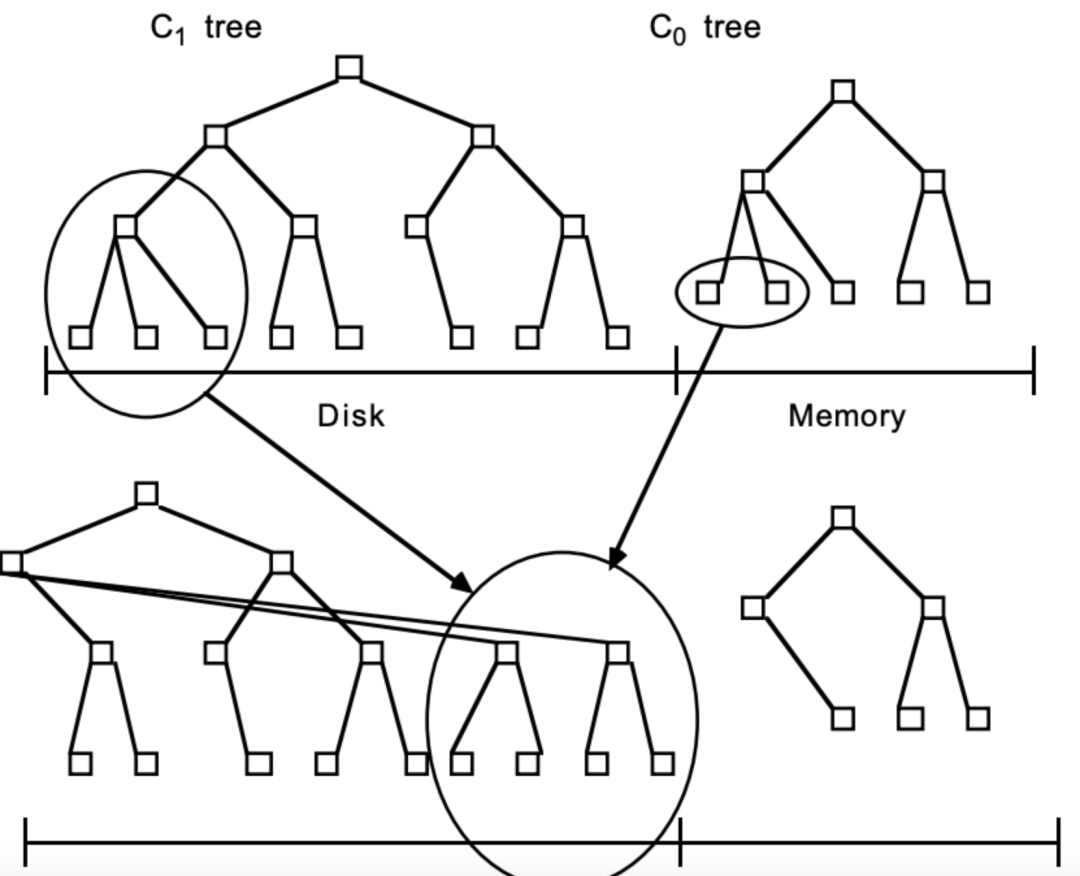
随着大数据的爆火,LSM Tree 被广泛用于 KV 型数据库和 OLAP 场景中,比如纯序员熟悉(拼写方式)的 HBase、Cassandra、LevelDB 等。相关领域的实际问题太多了,同样的,解法也很多。有兴趣的朋友可以深入了解一下。
编辑:黄飞
-
嵌入式常用数据结构------队列操作简介2016-06-17 5325
-
【下载】《嵌入式系统软件设计中的数据结构》2017-11-30 28407
-
嵌入式系统软件设计中的数据结构].(陆玲,周航慈)2018-02-21 5528
-
常见的数据结构2020-05-10 2775
-
嵌入式测控系统中常见的数字滤波算法有哪些?2021-04-12 1439
-
盘点生活中常见的三相异步电机2021-09-06 2382
-
嵌入式系统的数据结构与算法的资料汇总2021-11-16 1171
-
嵌入式软件C语言编程是否需要数据结构2021-12-15 1096
-
数据结构与算法在嵌入式系统中有何作用2021-12-21 904
-
嵌入式软件开发数据结构的工作流程是怎样的2021-12-24 2810
-
嵌入式系统软件设计中的数据结构2009-03-28 1301
-
新数据结构“树”的详细介绍2021-05-25 3218
-
数据结构字典树的实现2021-09-07 2965
-
Linux内核代码中常用的数据结构有哪些?2023-07-20 1129
-
嵌入式常用数据结构有哪些2024-09-02 2042
全部0条评论

快来发表一下你的评论吧 !
