

GPU Render Engine详细介绍
处理器/DSP
描述
前言
GPU (Graphics Processing Unit)是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图形相关运算工作的微处理器。随着AI兴起,适合并行运算的 GPU 也被广泛应用于训练和推理, 大量的服务器开始搭载 GPU 做计算任务。当前 GPU 包含多个引擎,包含渲染,计算,编解码,显示, DMA(Designated Market Area)等多个硬件模块。每个硬件对应一个或者多个引擎。本文主要介绍 render 引擎, 从 GPU 渲染的硬件单元,到用户态顶点,命令等数据下发给 GPU 硬件执行过程等方面进行详细介绍,帮助大家更好地理解 render 引擎工作流程。(特别声明:本文主要以 Intel GPU 为参考介绍)
名词解析
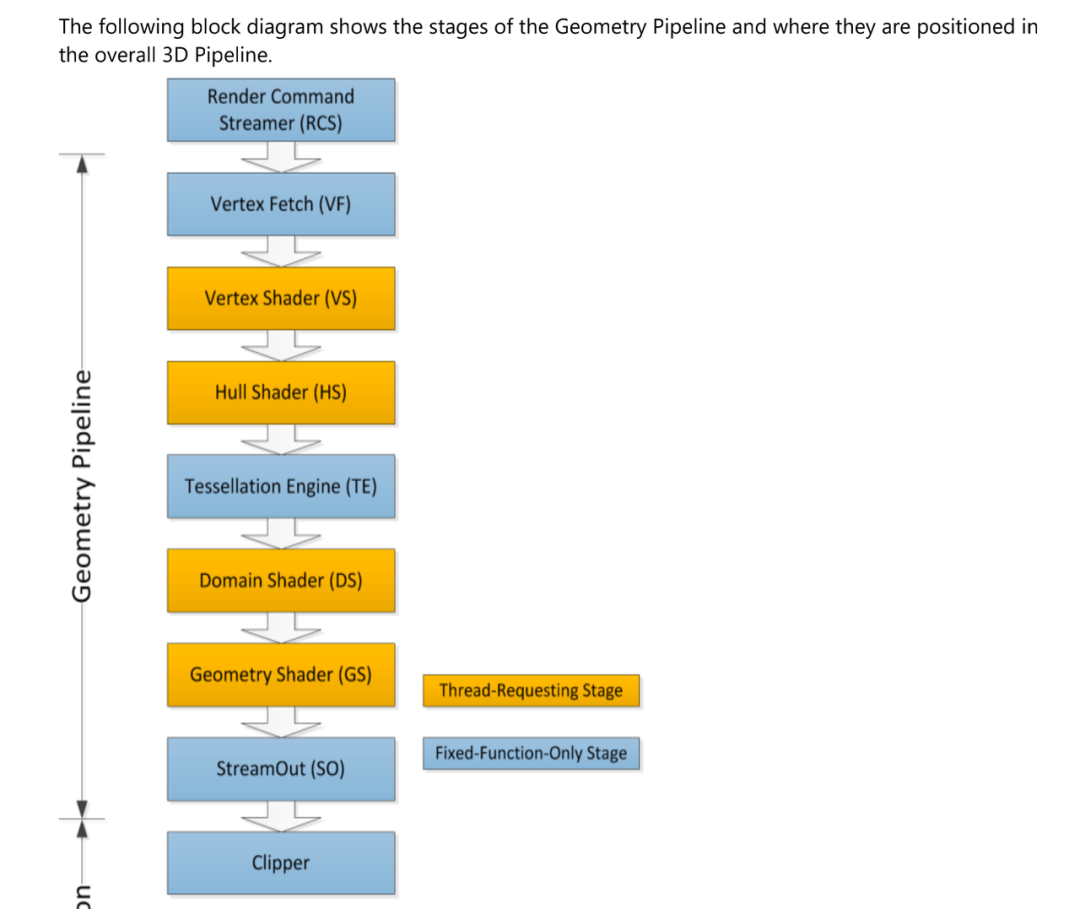
3D Pipeline: 3D 管道是一组以流水线方式排列的固定功能单元,它通过固定函数单元和 EU 线程来处理与 3D 相关的命令。FF(fixed fuction): 具有固定功能的硬件。FF units: 在 GPU 3D Pipeline 中一个固定的功能单元。
FFID: Unique identifier for a fixed function unit.
CS(Command Streamer): 固定功能单元,解析驱动写入到 ring buffer 里的命令,发送到 3D Pipeline 下一级。
VF(Vertex Fetcher): 3D Pipeline 中第一个 FF 固定功能单元,读取内存中的顶点数据,处理后传递给 3D Pipeline 下一个阶段 VS。EU(Excution Unit): 多线程的执行单元,每个 EU 都是一个处理器。
TD(Thread Dispatcher): 功能单元,用来仲裁来自固定函数单元的线程启动请求并在 EU 上实例化线程的功能单元。
Render 引擎介绍
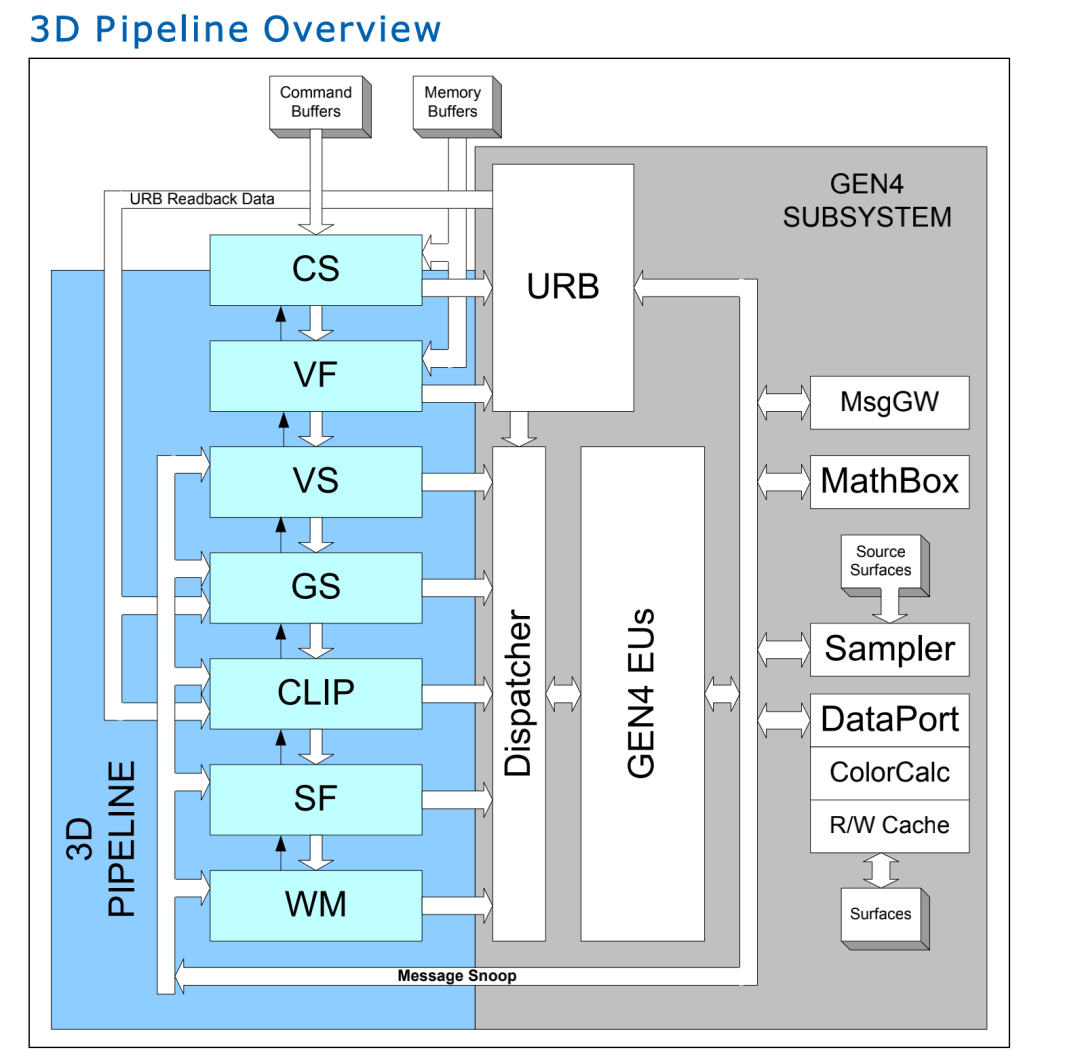
Intel Render 引擎有两种工作模式:一种是 3D 渲染,另一种是 media(编解码相关)模式(计算 GPGPU 模式和media 是同一个)。驱动通过 PIPELINE_SELECT 命令选择 3D/Media 模式:
// 在 mesa 代码中 compute 执行 、 emit_pipeline_select(batch, GPGPU); //在 render 中执行 emit_pipeline_select(batch, _3D);无论哪种工作方式都是用户态驱动和内核态驱动将命令写入到 ring buffer,然后提交给硬件,硬件通过 PIPE_SELECT 命令选择使用指定的 pipeline,然后将用户命令和 buffer 发送硬件。硬件执行命令流程如下图:
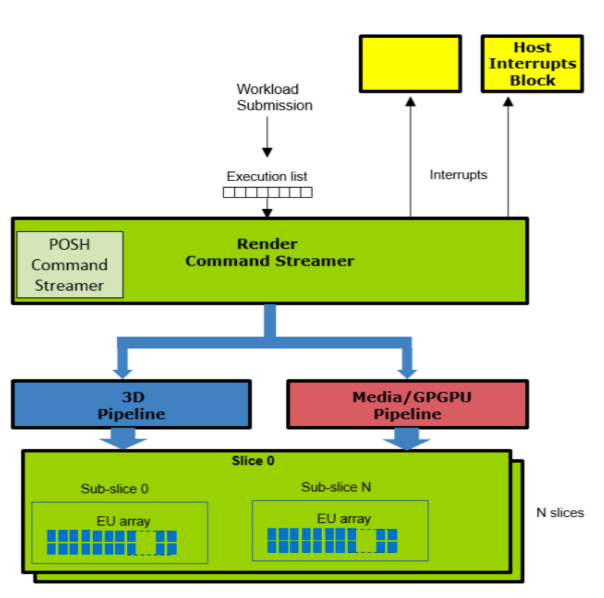
3D pipeline 流程图
上图中黄色的部分,是通过 EU(可以编程的计算单元)实现,在 NVIDIA 中,该硬件类似的功能叫做 CUDA(Compute Unified Device Architecture)。蓝色的部分是通过固定的硬件来实现。所以蓝色部分叫做 FF 固定函数单元。
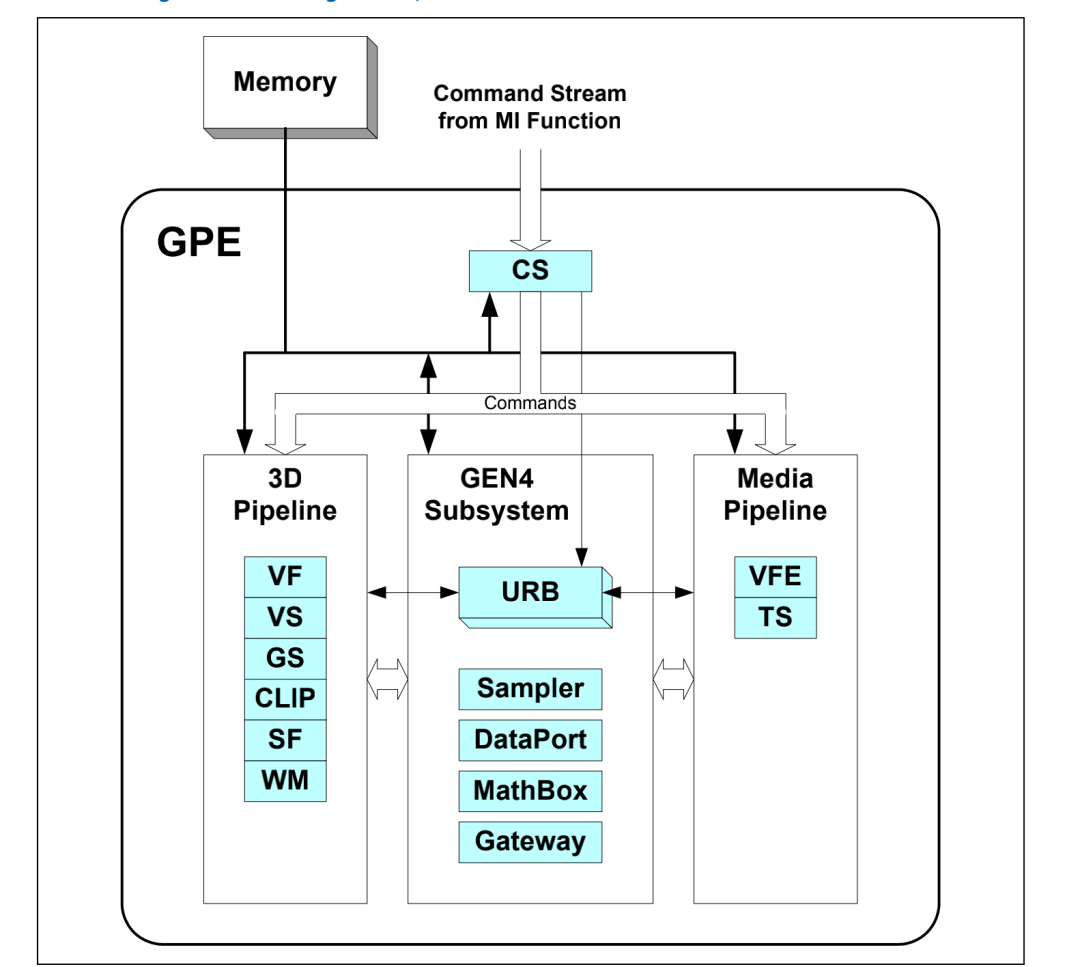
GPU render 引擎结构
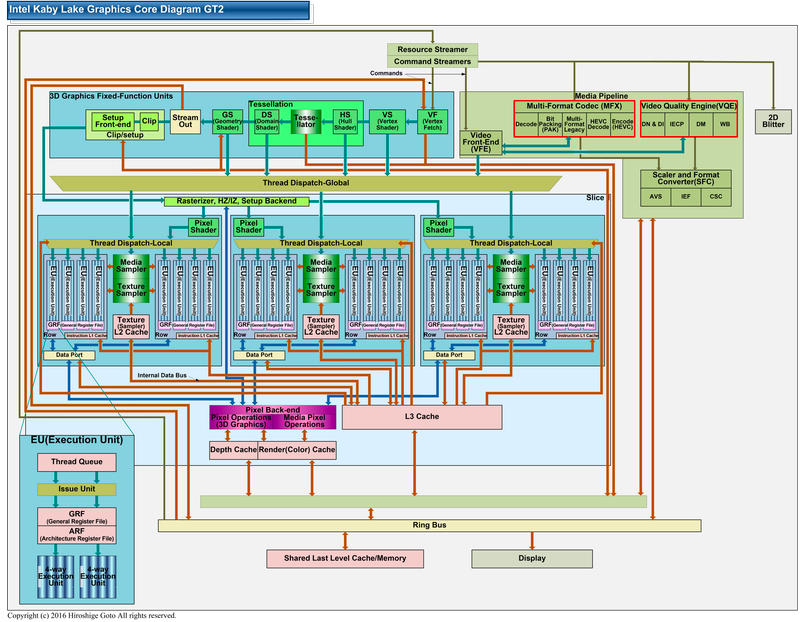
一图胜千言,从上图中可以看到渲染和 media 功能是由 CS、FF 固定函数单元配合 Slice 中 EU、采样器、SliceCommon 硬件等共同完成。上图只展示了一个 slice,真实的 GPU 包含不同数量的 slice。
硬件介绍和分析
Command Streamer
GPU 执行相关的 pipeline 操作需要 CPU 下发命令,CPU 写入命令到一个 buffer 里,该 buffer 一般称为 batch buffer。在驱动里把该 buffer 转换成 ring buffer 或者 batch buffer。
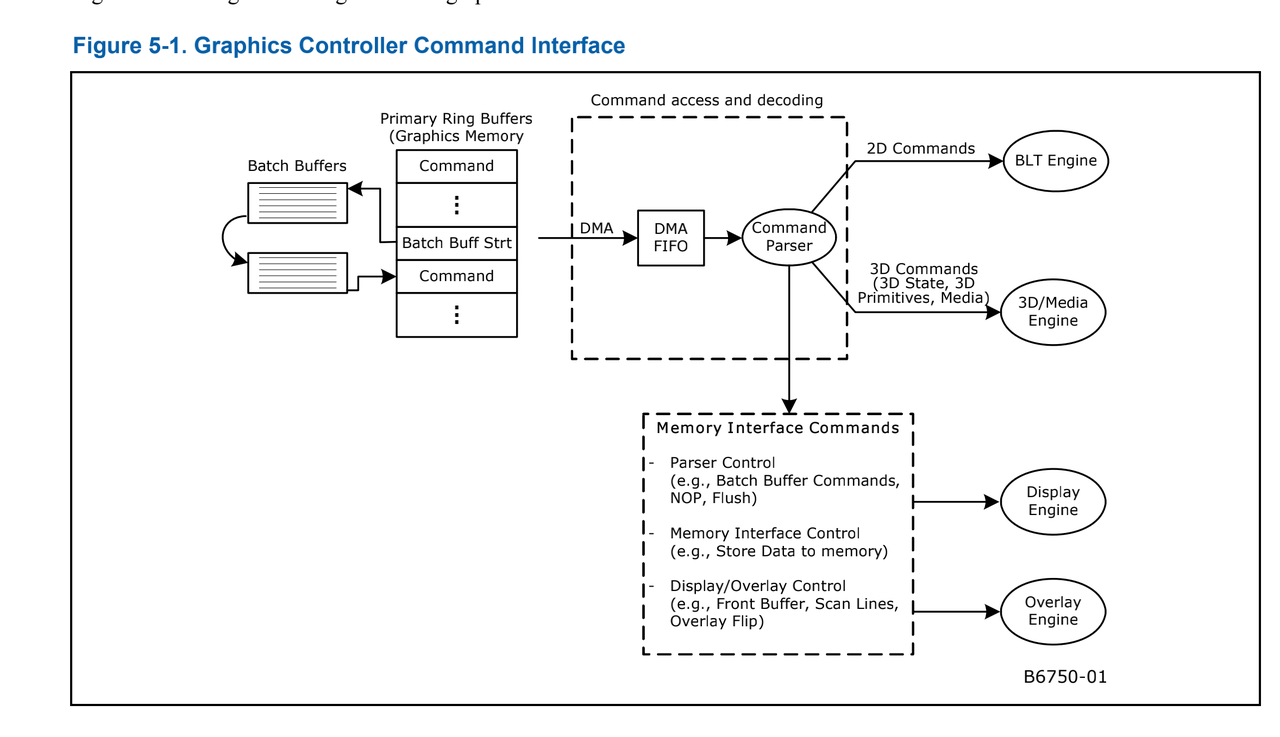 GPU render 相关的命令大体分为以下类型:
GPU render 相关的命令大体分为以下类型:
memory interface: 内存接口命令,对 memory 进行操作的命令。
3D state: 设置 3D pipeline 状态机的命令,例如顶点 surface state 状态下发到 GPU。
pipe Control: 用来设置同步或者并行执行的操作。
3D Primitive 图元装配有关的命令。
命令下发后就需要硬件去解析命令。从上图 3D 引擎的结构中能看到,首先是 Command Streamer 硬件读取 ring buffer 数据中的命令。Command Streamer 是各种引擎的主要接口。每个引擎都有自己的 Command Streamer。 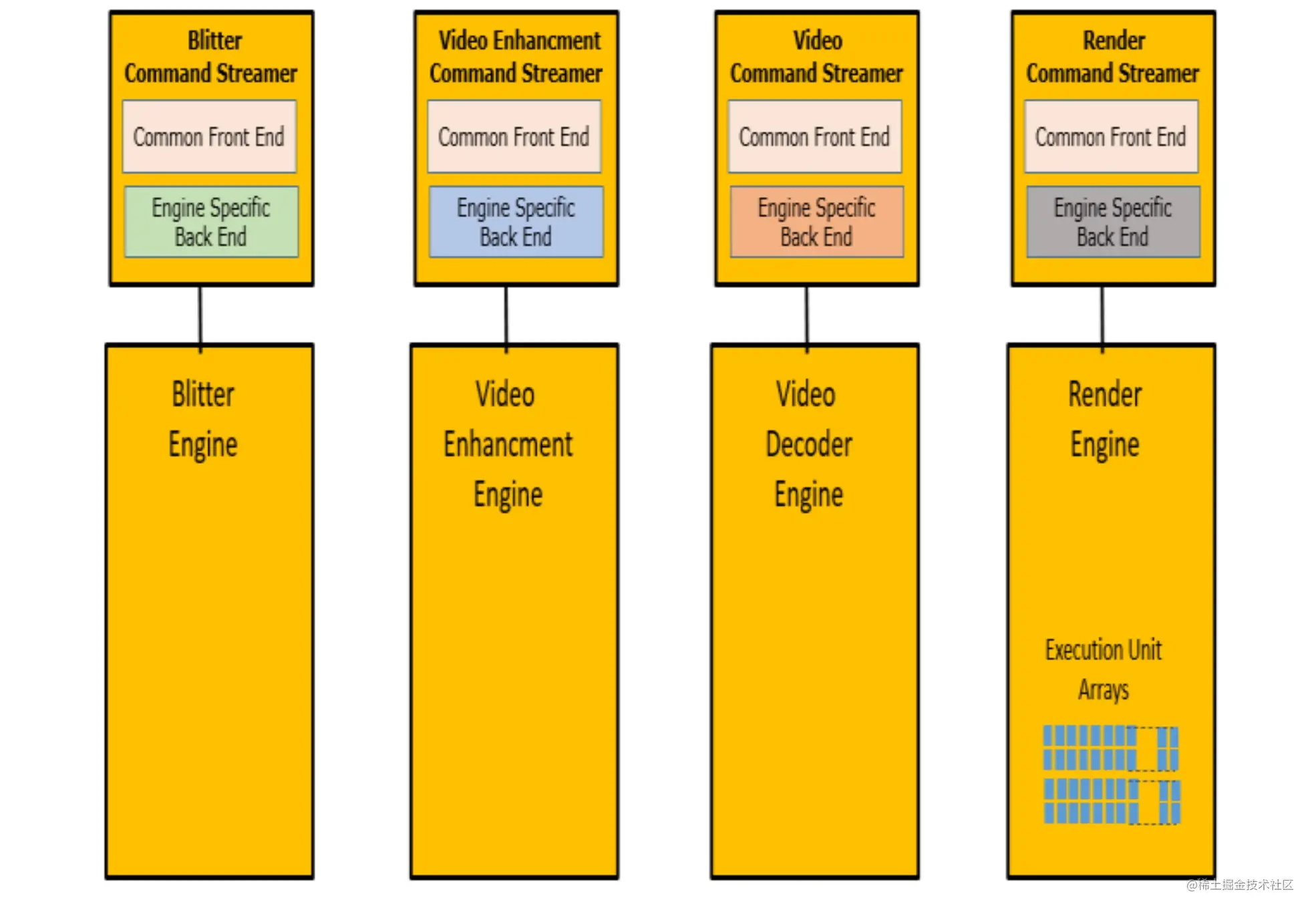
固定函数单元
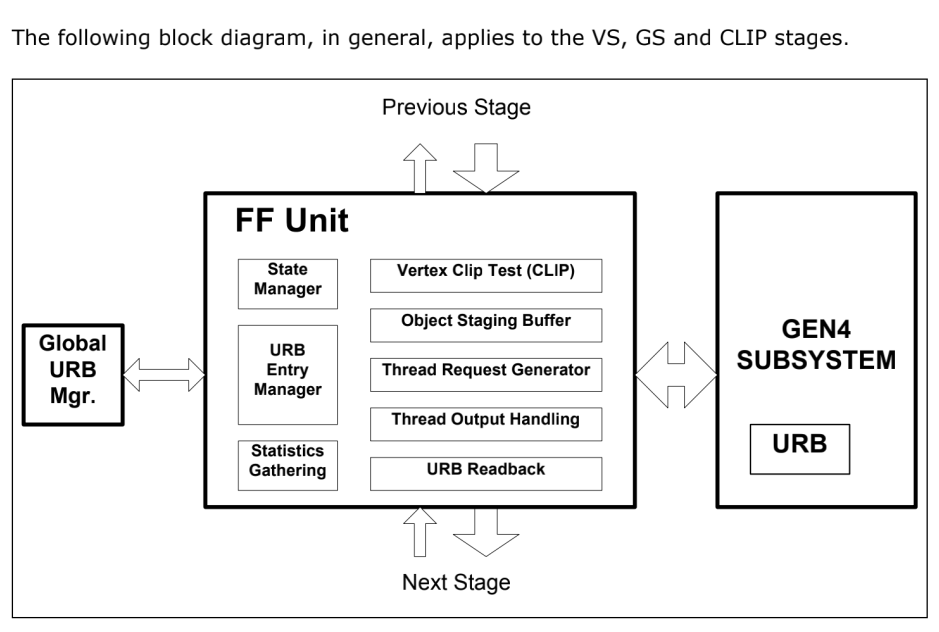 图 Generic 3D FF Unit Block Diagram FF 函数单元的一个主要作用是管理对顶点/像素数据执行大部分处理的 EU 线程。在一般意义上,所包括的关键功能是:
图 Generic 3D FF Unit Block Diagram FF 函数单元的一个主要作用是管理对顶点/像素数据执行大部分处理的 EU 线程。在一般意义上,所包括的关键功能是:
Bypass Mode
URB Entry Management
Thread Initiation Management
Thread Request Data Generation ⎯ Thread Control Information Generation ⎯ Thread Payload Header Generation ⎯ Thread Payload Data Generation
Thread Output Handling
URB Entry Readback
Statistics Gathering
FF 单元有个很重要的功能是完成 Thread Dispatching (thread 调度器)任务, 根据 VS/GS 等等 stage 需求发起不同的 EU thread。FF 单元常用的命令大部分都和线程启动初始化相关。
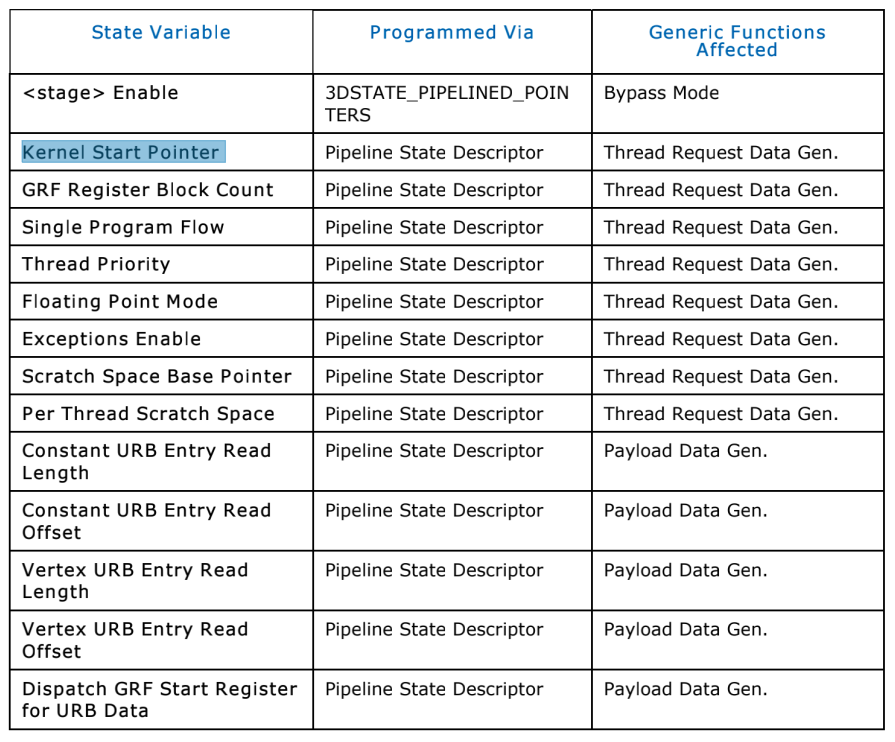
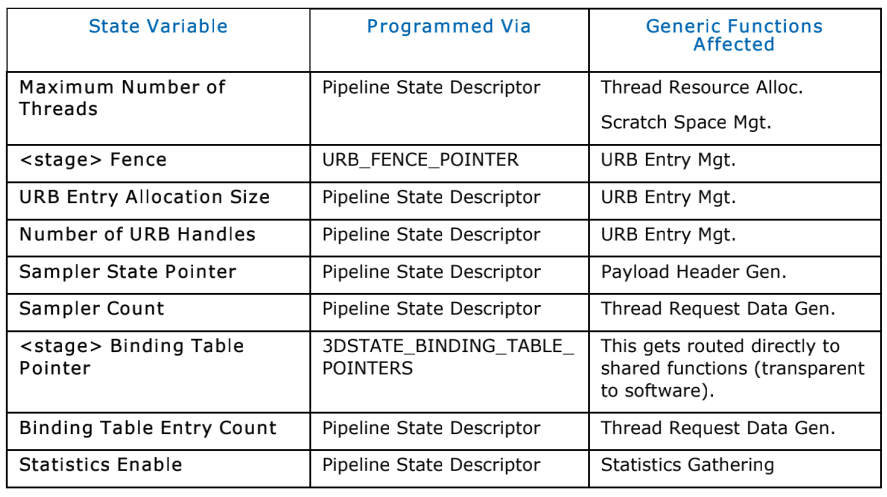
上面的命令都是 thread init 需要,后面是常量包含到 URB thread 运行时候需要读取的数据。
EU(Excution Unit)
EU 的官方解释为:
An EU is a multi-threaded processor within the multi-processor system. Each EU is a fully capable processor containing instruction fetch and decode, register files, source operand swizzle and SIMD ALU, etc. An EU is also referred to as a core
从官方解释也能看出 EU 是个多线程的执行单元,在最近的 gen11/gen12中,每个 EU 都是具有七个线程的多线程 (SMT)。主计算单元由支持 SIMD 的 ALU/FPU 组成。每个硬件线程都有 128 个 32 位宽的通用寄存器 (GRF)。OpenGL 中的 shader 和 OpenCL 中的 kernel 做计算都是由 EU 单元完成。
常用到基本概念
Thread: An instance of a kernel program executed on an EU. The life cycle for a thread starts from the executing the first instruction after being dispatched from Thread Dispatcher to an EU to the execution of the last instruction – a send instruction with EOT that signals the thread termination. Threads in GEN system may be independent from each other or communicate with each other through Message Gateway share function
Thread Dispatcher : Functional unit that arbitrates thread initiation requests from Fixed Functions units and instantiates the threads on EUs.
Thread Payload :Prior to a thread starting execution, some amount of data will be pre-loaded in to the thread’s GRF (starting at r0). This data is typically a combination of control information provided by the spawning entity (FF Unit) and data read from the URB
Thread Identifier : The field within a thread state register (SR0) that identifies which thread slots on an EU a thread occupies. A thread can be uniquely identified by the EUID and TID.
Thread Spawner : The second and the last fixed function stage of the media pipeline that initiates new threads on behalf of generic/media processing.
Unified Return Buffer(URB):The on-chip memory managed/shared by GEN Fixed Functions in order for a thread to return data that will be consumed either by a Fixed Function or other threads.
URB Entry: A logical entity stored in the URB (such as a vertex), referenced via a URB Handle.
URB Entry Allocation Size: Number of URB entries allocated to a Fixed Function unit.
URB Fence:Virtual, movable boundaries between the URB regions owned by each FF unit.
EU 的结构
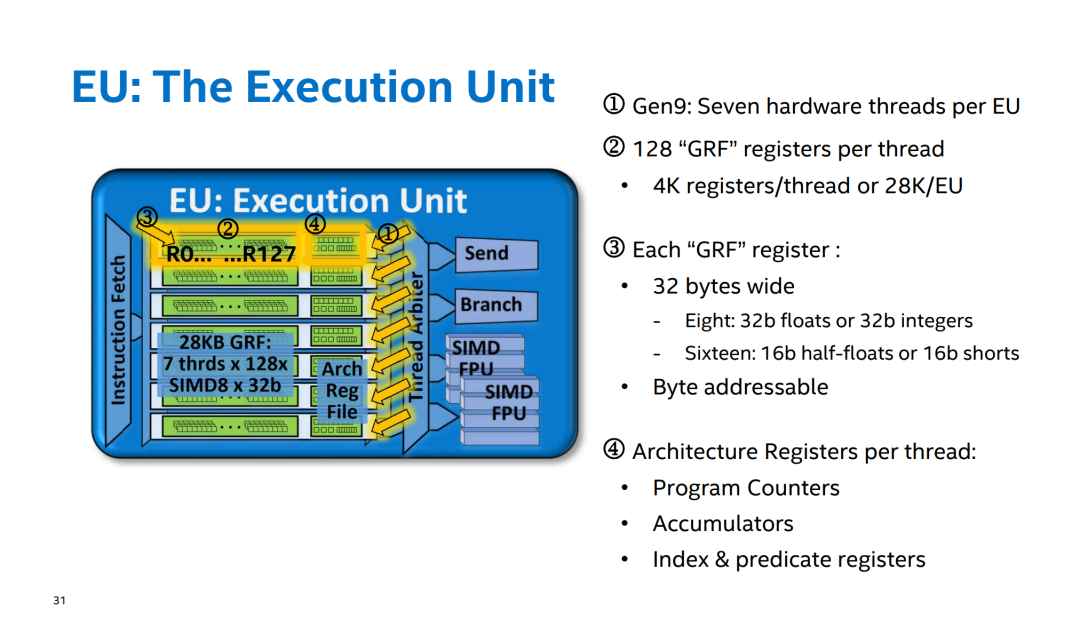
GRF(General Register File)通用寄存器组。ARF(Architecture Register File)体系结构寄存器组。
常用的 ARF 寄存器:
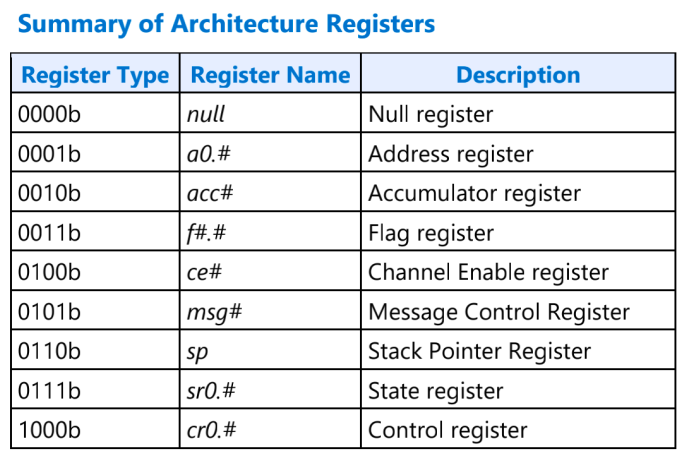
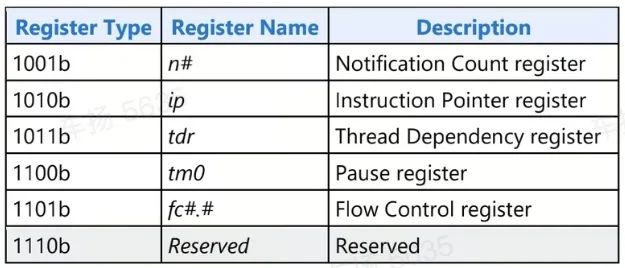
类似 arm 体系结构除了 x0 到 x30 通用寄存器,还有一些 sp,ret ,pc,PSTATE 等特殊寄存器。
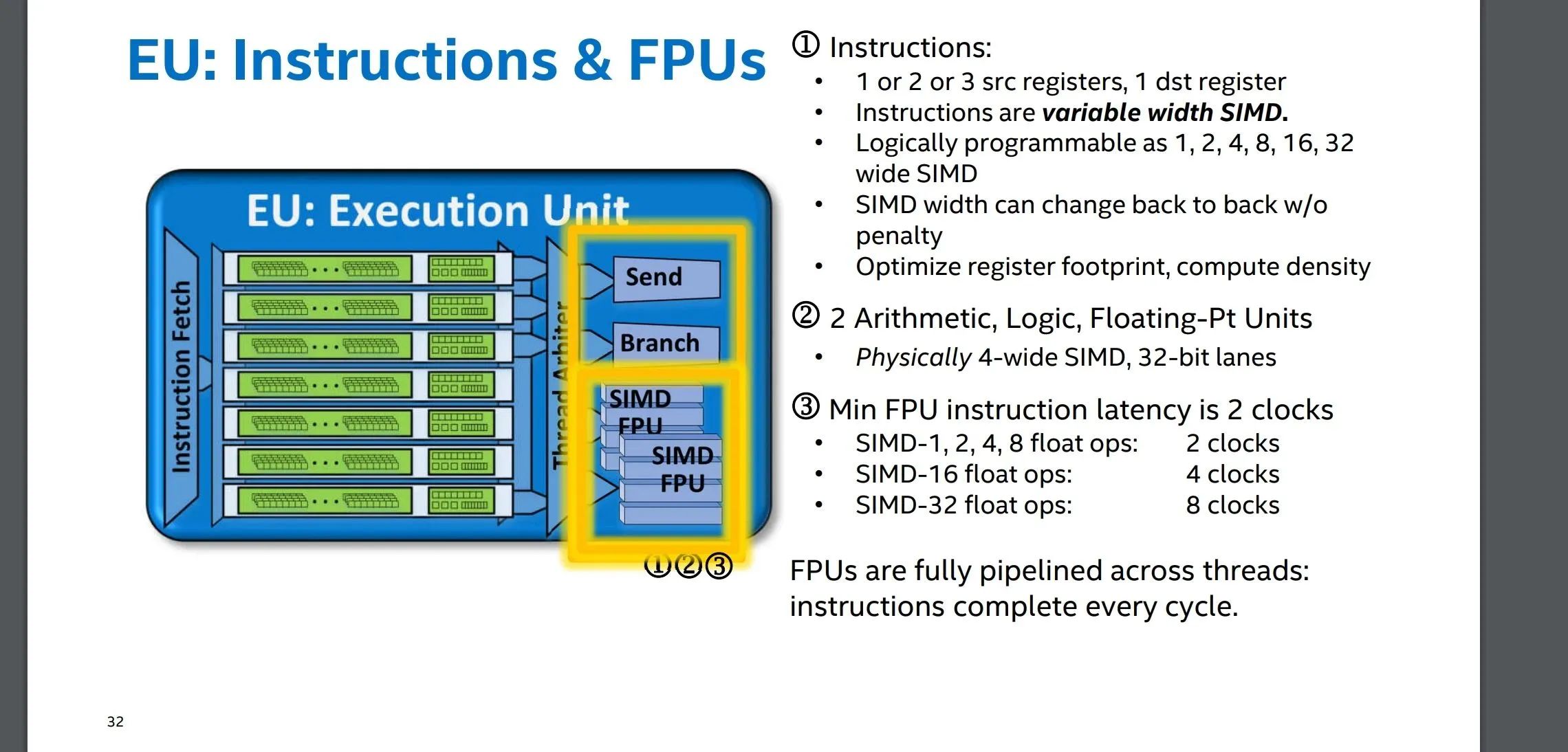
FPU 就是常说的 ALU 算术逻辑运算单元,使用 SIMD 指令实现。包含以下指令:

EU 的寄存器数据存储方式
EU 寄存器不同的数据存储方式 AOS 和 SOA:
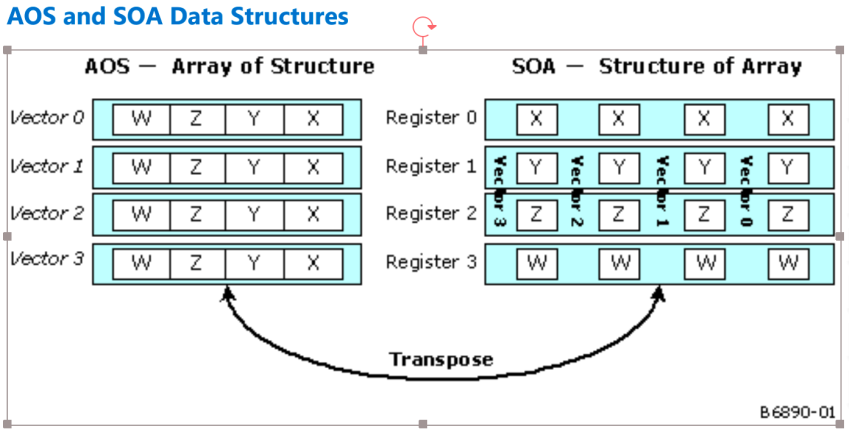 根据 GPU 文档介绍:
根据 GPU 文档介绍:
顶点着色器和几何着色器使用 AOS 方式存储,同时使用 SIMD4x2 and SIMD4 modes 模式操作;
像素着色器使用 SOA 方式 使用 SIMD8/SIMD16 方式操作数据;
在 media 中主要使用 SOA 方式排列,偶尔也有 AOS
SIMDmxn 代表操作向量的大小,n 代表同时有几个在同时进行操作。SIMD4 代表上图中 x、y、z、w 同时操作。
一个 EU 例子:
add dst.xyz src0.yxzw src1.zwxy
用户态对 EU 的使用
OpenGL 程序可以编写 shader(glsl)然后通过 GPU 编译器解析成 GPU 指令,并由 GPU 执行。OpenCL 中可以编写 kernel(OpenCL定义的Kernel语言,基于C99扩展)程序,经过编译到 GPU 上执行。无论 shader 还是 kernel 都在执行时才进行编译。根据不同的 GPU 编译成特定的二进制。在 mesa 中大体过程如下:
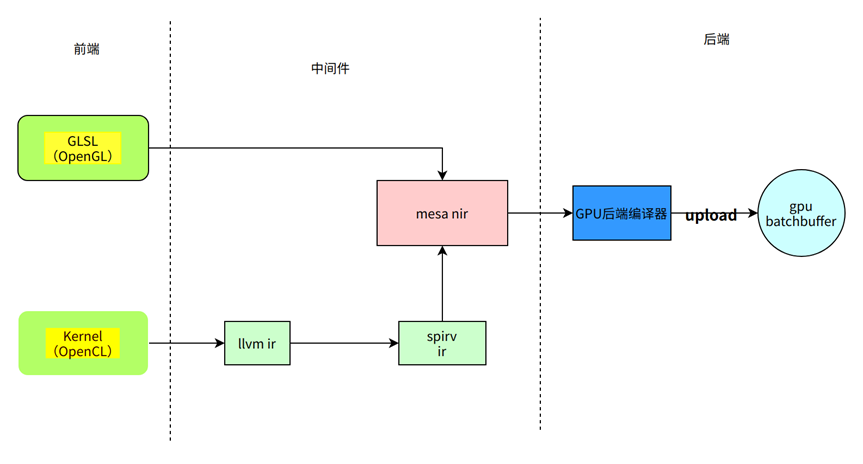
在 mesa 中 OpenCL 和 OpenGL GPU 的编译器都在 mesa/src/目录下,编译完成后根据 vulkan 或者 openGL 分别调用 upload_blorp_shader/iris_blorp_upload_shader 拷贝到 res bo 中(batchbuffer),当 context 被调度执行 会读取 batchbuffer 数据,GPU 加载到 EU 执行。
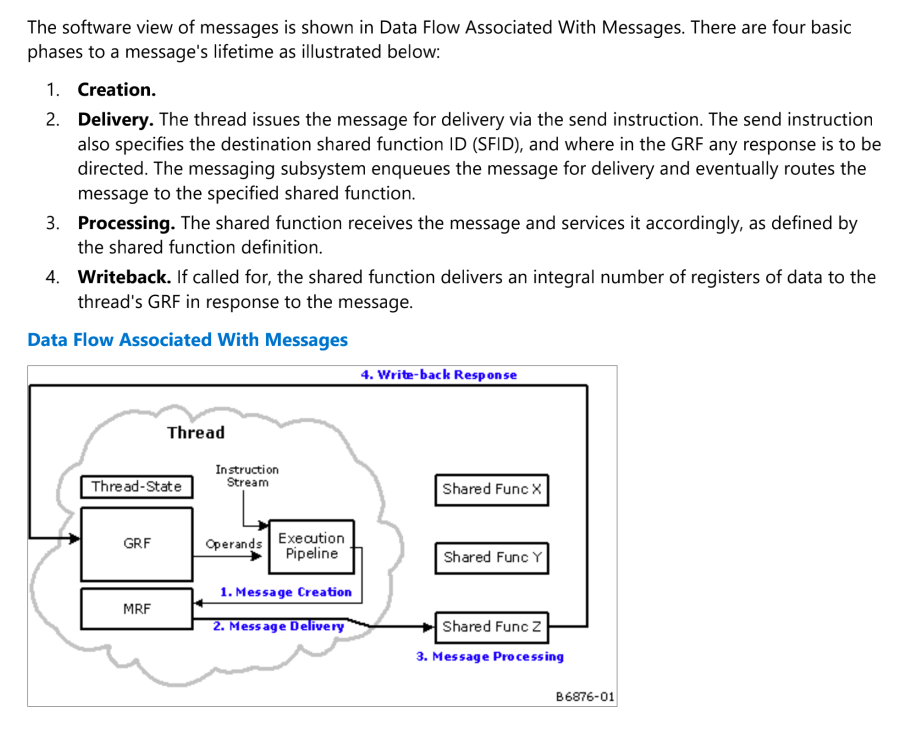
EU 中的 Messages
EU 与共享函数之间以及固定功能管道(不被认为是“子系统”的一部分)以及 EU 与 EU 之间的通信是通过信息包完成的 。
通过发送指令请求消息传输,Messages 分为两大类型:
Message Payload:写入 MRF (Message Register File )寄存器的内容,发送有效的信息。
Associated ("sideband") information :指令中包含的其他信息 具体如下:
Message Descriptor. Specified with the send instruction. Included in the message descriptor is control and routing information such as the target function ID, message payload length, response length, etc. Additional information provided by the send instruction, e.g., the starting destination register number, the execution mask (EMASK), etc. A small subset of Thread State, such as the Thread ID, EUID, etc.
备注:MRF(Message Register File ):只写寄存器,用于在发送前组装消息,并作为发送指令的操作数。每个线程都有专有的 MRF 寄存器组由 16 个寄存器组成,每个寄存器 256 位宽。每个寄存器都有一个专门的状态位用来标记当前寄存器是否是正在发送消息的一部分,即标记是否在使用。对于大多数 Message 第一个寄存器是报文头,其他的寄存器是 data。
一个 Message 的生命周期分为四个阶段:(1)创建 (2)发送 (3)处理 (4)回写。
什么是共享函数?
共享函数是为 EU 提供专门补充功能的硬件单元。一个共享函数是在每个 EU 原有基础功能上的增强,独立的硬件加速。共享函数是作为 EU 以外的独立实体运行,并在各 EU 之间共享。
共享函数的调用是通过称为消息的通信机制实现的。消息由一系列 MRF(Message Register File)定义,这些寄存器保存消息操作数、目标共享函数 ID、需要操作特定函数的编码、目标通用任何回写响应指向的 GRF (General Register File) 。消息通过发送指令在软件控制下发送到共享函数。最常见的共享函数: • Extended Math function • Sampling Engine function • DataPort function • Message Gateway function • Unified Return Buffer (URB) • Thread Spawner (TS)
• Null function
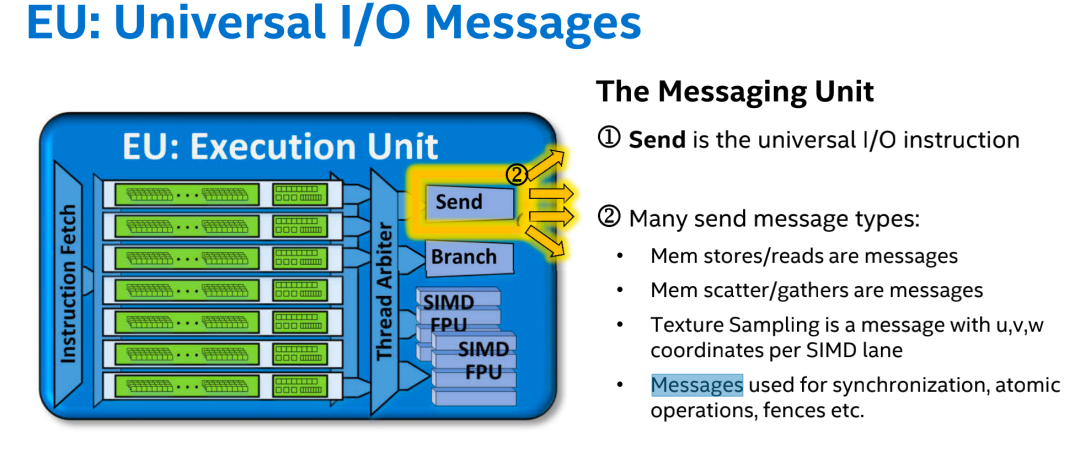 上图为 Send 主要发送 Messages 消息到共享函数,Send 用来发送通用指令,处于 messsage 的发送阶段,message 指令类型: • Mem stores/reads are messages • Mem scatter/gathers are messages • Texture Sampling is a message with u,v,w coordinates per SIMD lane
上图为 Send 主要发送 Messages 消息到共享函数,Send 用来发送通用指令,处于 messsage 的发送阶段,message 指令类型: • Mem stores/reads are messages • Mem scatter/gathers are messages • Texture Sampling is a message with u,v,w coordinates per SIMD lane
• Messages used for synchronization, atomic operations, fences etc.
Unified Return Buffer (URB)
The on-chip memory managed/shared by GEN Fixed Functions in order for a thread to return data that will be consumed either by a Fixed Function or other threads.
统一返回缓冲区(URB)是一种通用的缓冲区,用于在不同的线程之间发送数据,在某些情况下,还可以在线程和固定函数单元之间发送数据(反之亦然)。一个线程 a 通过发送消息来获取 URB。URB 通常以行为颗粒度进行读写。
URB 的空间布局:
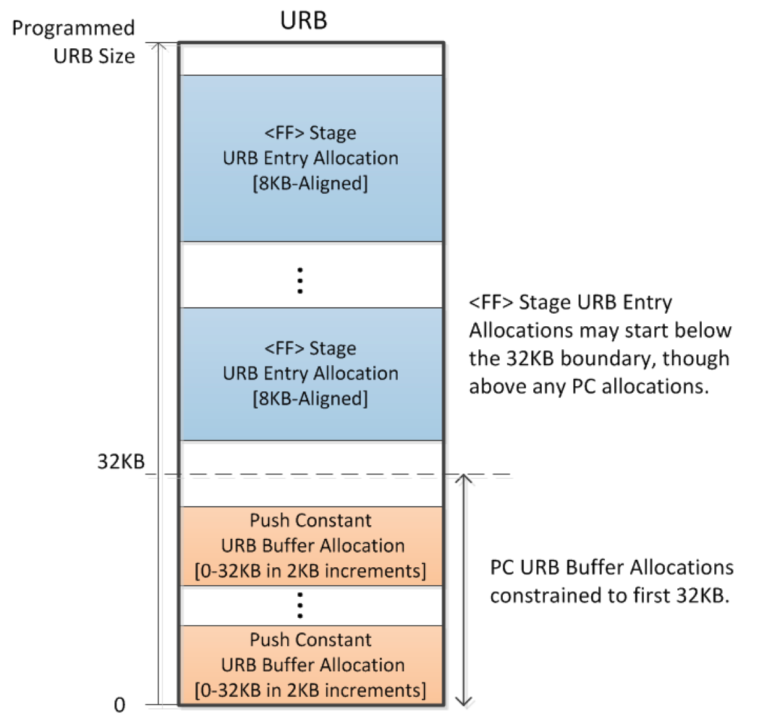
URB entry
URB entry 是 URB 中的一个逻辑实体,由 URB handle 引用,并由若干个连续的行组成。
Constant URB Entries (CURBEs)
EU 中的 thread 在计算时可能会遇到程序里的一些常量 ,EU 可以通过 Dataport 读取内存中的常量数值,但是这会影响性能。为了加速读取常量的速度,GPU 可以把内存数据写入到 URB 中。这样常量可以放入到 URB 中,提高 thread 读取常量的速度。将常量写入线程有效负载的机制叫做 CURBEs。CURBE 是 一个由 command stream 控制的 URB entry,CURBE 是一个特殊的 URB entry。CS 解析到 CONSTANT_BUFFER 命令后会从内存中读取常量数据并写入到 CURBE。
URB 分配
Engine command streamer 通过解析命令来管理 GPU 中的 URB
3D Pipeline 上每个阶段都需要使用 URB, 各个阶段 VF ,VS 等都需要分配自己的 URB。FF 单元将顶点、vertex patch 、constant data 从内存写入到 URB entries 中,可以通过 URB_FENCE 命令用来完成这个任务。每个 stage 都有一个 fence 指针,该指针指向自己使用的 URB 结束位置。上一个 stage fence 指针和自己 fence 指针中间的位置就是使用的 URB 区间。
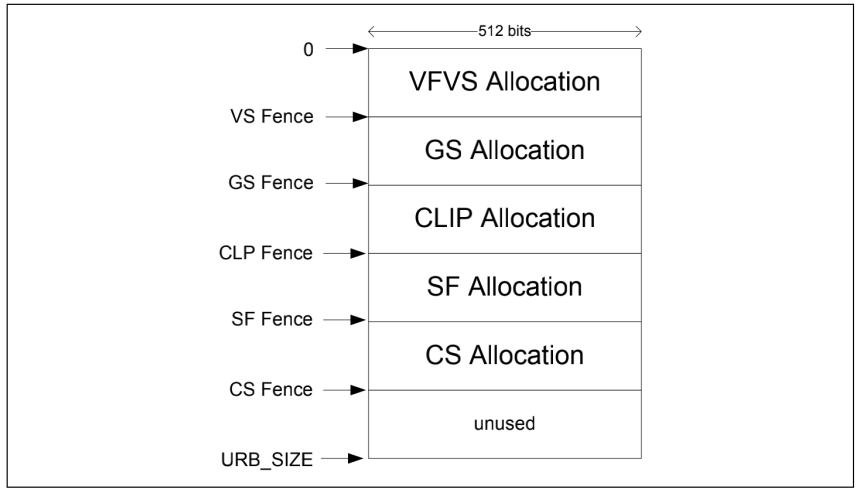
图 URB Allocation - 3D Pipeline
URB 的读写
URB 写入:
CS 会将常用数据写入到 URB 中 Constant URB Entries
Media pipeline Video Front End (VFE) 固定单元将 thread 预加载数据写入到 URB entry 中
3D pipeline Vertex Fetch (VF) 固定函数单元写顶点数据到 URB entry 中
Thread 写数据到到 URB entry
URB 读取:
线程调度器(Thread Dispatcher)是 URB 读取的主要来源。作为生成线程的一部分,管道固定函数为线程调度器提供了许多 URB 句柄、读取偏移量和长度。线程调度器从 URB 中获取指定的数据,并提供预加载到 GRF 寄存器中。
3D 管道的几何着色器(GS)和 Clipper(CLIP)固定函数单元可以读取 URB entry 的选定部分,以提取管道所需的顶点数据。
windows(WM)FF 单元从条带/风扇单元编写的 URB 条目中读取回深度系数。
URB 读写通过 URB 共享函数实现,URB 共享函数通过 URB_WRITE 和 URB_READ message 类型。
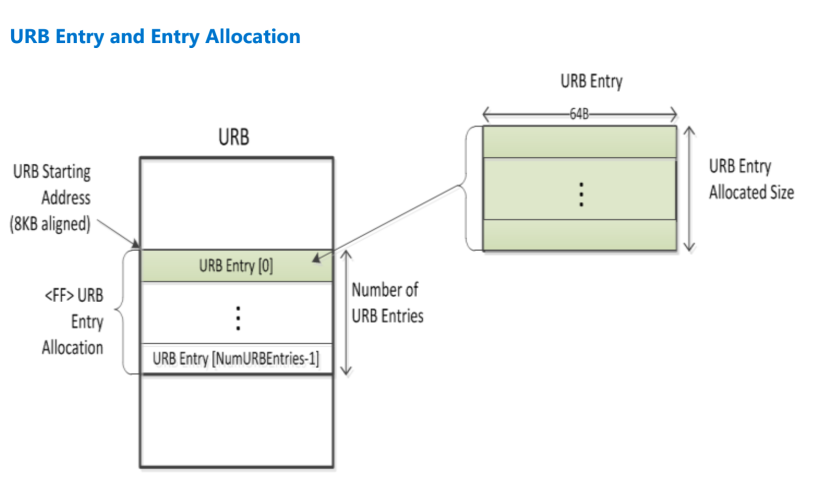
URB Entry
URB Entry 分配从 URBStartAddress 指定的地址开始。
分配的大小由 NumberOfURBEntries 和 URBEntryAllocationSize 决定。
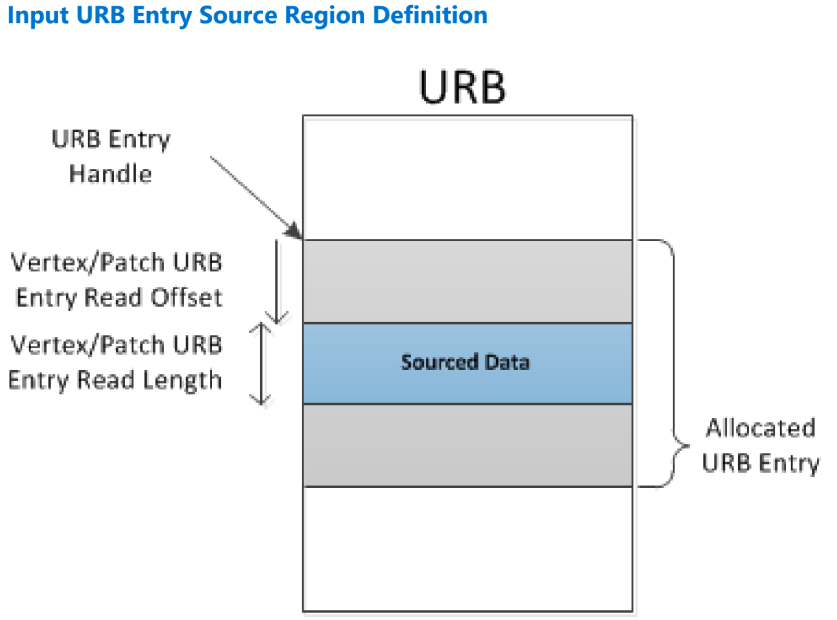
存储顶点的 entry 被称为 Vertex URB Entry,一般来说,顶点数据存储在 URB 中 vertex URB entry(VUEs)中,由 CLIP 线程处理,仅通过 VUE 句柄间接引用。因此,对于大部分顶点数据的内容/格式不暴露于 3D 管道硬件——FF 单元通常只知道数据的句柄和大小。
发起 EU thread
1. Thread Dispatching
当 3D 和 media pipeline 向 subsystem 发送线程启动请求时,线程调度器(Thread Dispatching )接收这些请求。调度程序执行诸如在并发程序之间进行仲裁等任务,将请求的线程分配给 EU 上的硬件线程,在多个线程中分配每个 EU 中的寄存器空间,并使用来自 FF 单元的数据初始化一个线程中的寄存器。
FF 单元会给 thread Dispatching 发送请求,FF 单元收集 thread 启动需要的信息,写入到 URB 中。Thread 启动的时候从 URB 加载到 GRF(General Register File)寄存器。
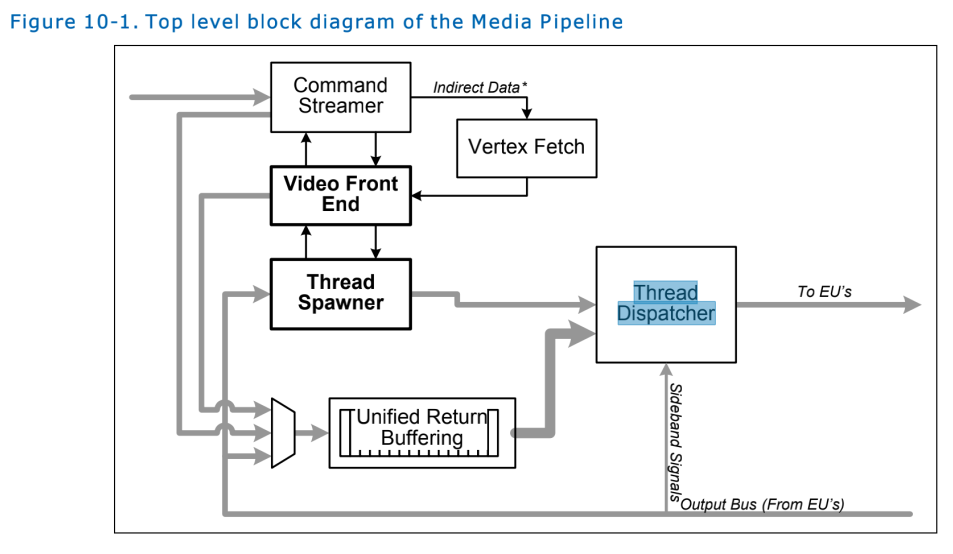
2. Thread Spawner
Media pipeline 有两个固定函数单元,Video Front End (VFE) unit and Thread Spawner (TS) unit。
TS 是 media 功能时候发起一个通用的线程。VFE 解析命令流,然后将线程启动预加载的数据填写到 URB,TS 发起一个新的线程。TS 是 media pipeline 中唯一一个与线程调度器(Thread Dispatching )联系的单元。
3. Thread 启动需要信息
FF 单元确定可以请求一个线程,它就必须收集向线程调度程序提交线程发起所需的所有信息。这些信息可分为几个类别: • Thread Control Information: FF 单元会给 thread Dispatcher 发送 thread 运行的控制信息,包括 Kernel Start Pointer,Binding Table Entry Count 等等。这些信息不是直接发送到 thread payload 中
• Thread Payload Header: GRF 是 EU 的通用寄存器,thread 运行之前需呀讲一些数据预加载到 GRF 中(GRF r0 寄存器寄存器开始)这些数据来自 FF 单元。
此数据分为两部分:固定头部数据和 R+ 头部数据: 固定头部数据:包含了 FF 单元从 FF pipe 获取到的信息,是所有 thread 都用的信息,这里就包含后面。sampler 会用到的 surface state, sampler state 指针等等。  R+ 头部数据 : 包含了 R0 R1 .. 包含了 FF 单元给 thread 传递的参数。R1 等寄存器会包含 URB handle, thread 需要读取/写入 顶点/patch 等数据可以指定 handle 从 URB 中加载 /写入。
R+ 头部数据 : 包含了 R0 R1 .. 包含了 FF 单元给 thread 传递的参数。R1 等寄存器会包含 URB handle, thread 需要读取/写入 顶点/patch 等数据可以指定 handle 从 URB 中加载 /写入。
• Thread Payload Input URB Data: thread 从 URB 加载数据和常量。
对于每个 URB entry,FF 单元将提供一系列 handle、读取偏移量和读取长度。线程调度子系统将读取 URB 的适当 256 bit 位置,并将结果写入顺序 GRF 寄存器(写入 GRF)
 thread 预加载(payload)数据的布局
thread 预加载(payload)数据的布局 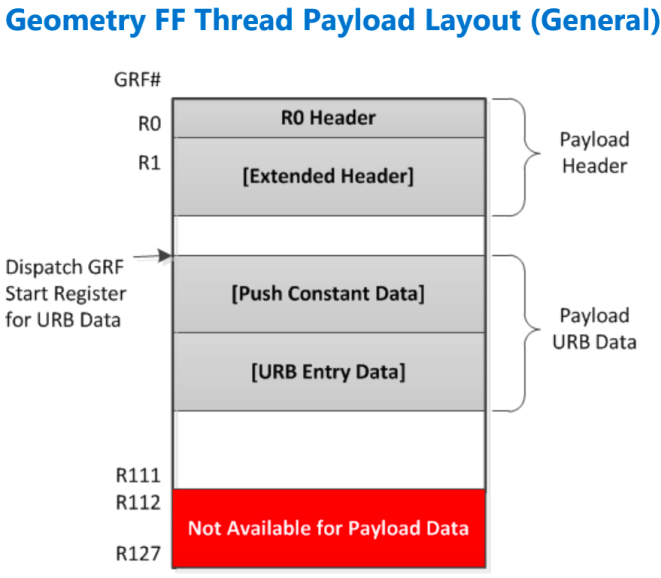
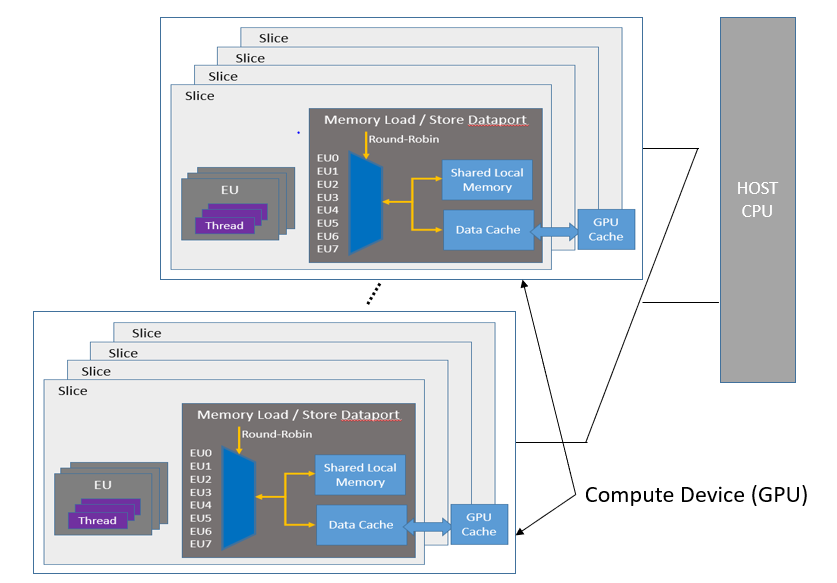
Slice /Sub Slice
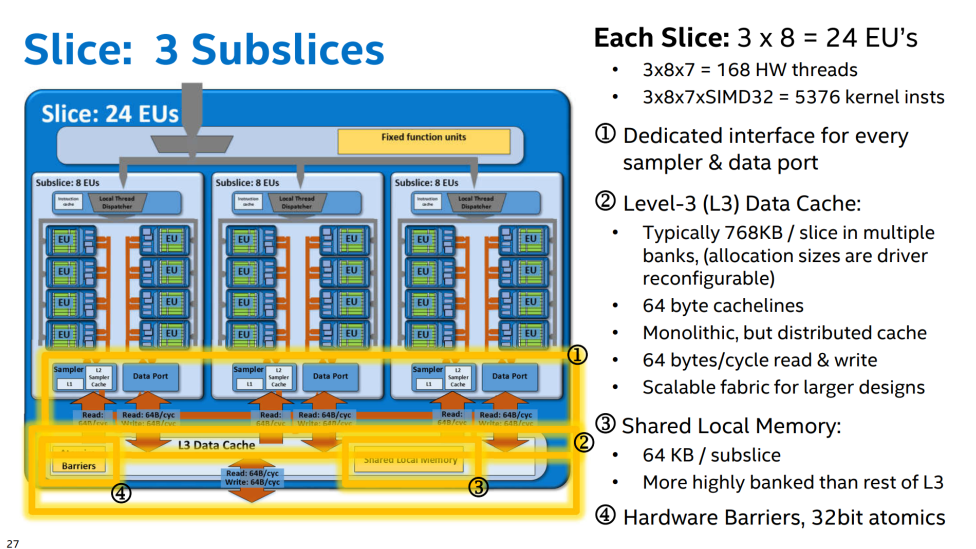
如图 一个 slice 里包含多个 subslice,一个 L3 cache, 一块共享的显存,一个硬件的内存屏障还有固定函数单元(fixed function units)
Pipeline Stage
A abstracted element of the 3D pipeline, providing functions performed by a combination of the corresponding hardware FF unit and the threads spawned by that FF unit.
一个 3D pipeline 有多个阶段:
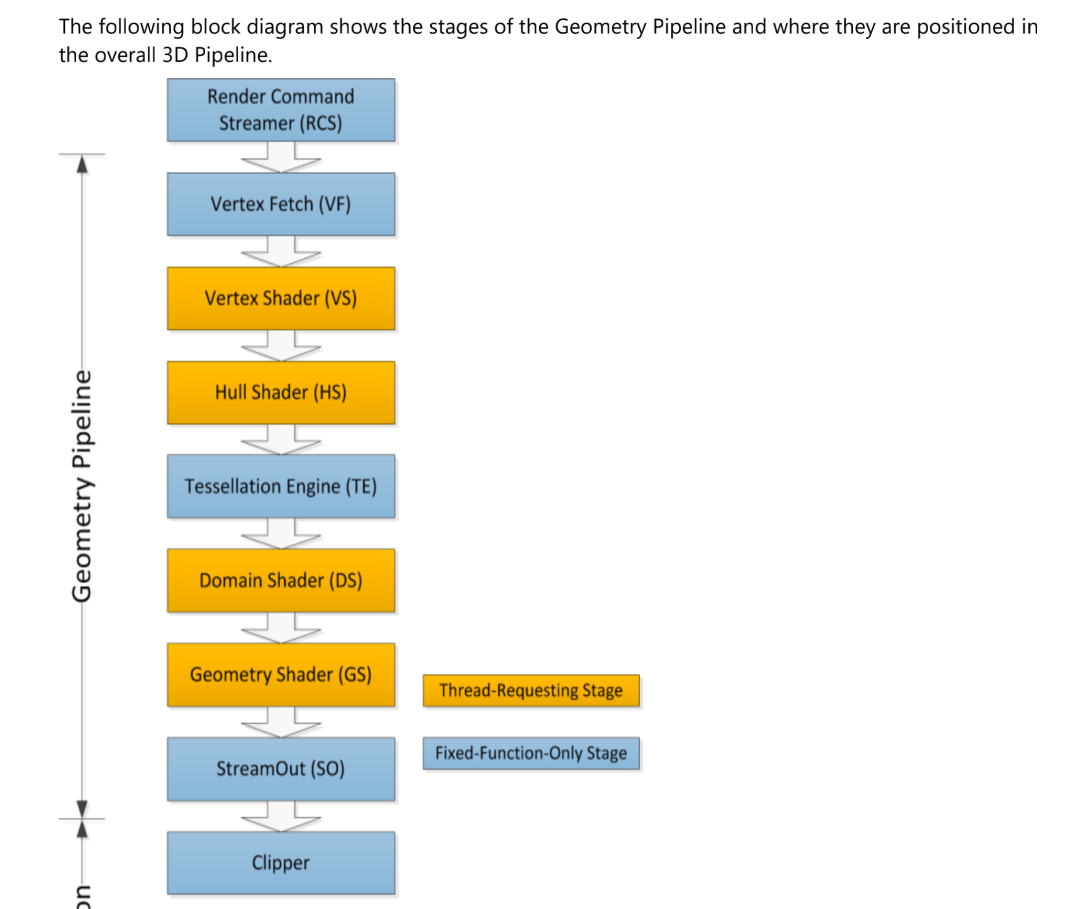
每个阶段通过固定函数单元完成相应的功能,蓝色的框固定函数单元是硬件固定不可更改的功能;
黄色代表可非固定功能,功能由软件编程后经过编译器编译在可编程单元(EU)中执行;
fixed function 现在更像是一个概念不一定需要独立的硬件去实现他的功能。
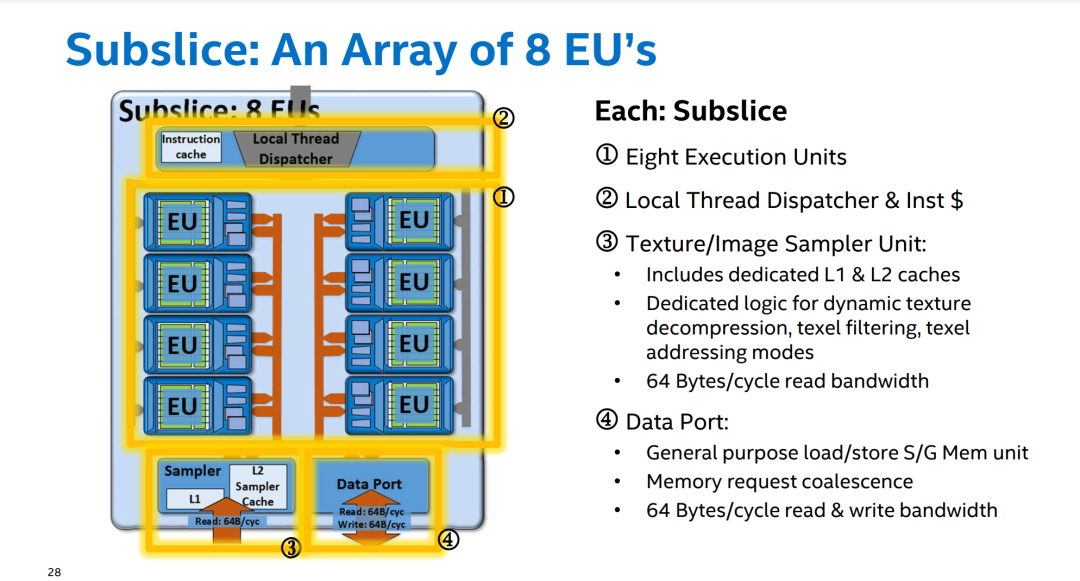
一个 subslice 内包含有多个 EU,一个 Dispatcher,一个 sampler,一个 Data Port。
sampler
3D 采样引擎提供了高级采样和过滤表面的能力。采样引擎功能负责向 EU 提供过滤后的纹理值,以响应采样引擎收到的 message 消息。采样引擎使用 SAMPLER_STATE 来控制滤波模式 、地址控制模式等采样引擎的其他功能。每个消息都传递一个指向 sampler state 的指针。此外,采样引擎使用 SURFACE_STATE 来定义被采样的 suface 属性。这包括 surface 的位置、大小和格式 以及其他属性。
采样引擎的子功能: 
1. sampler 主要流程:
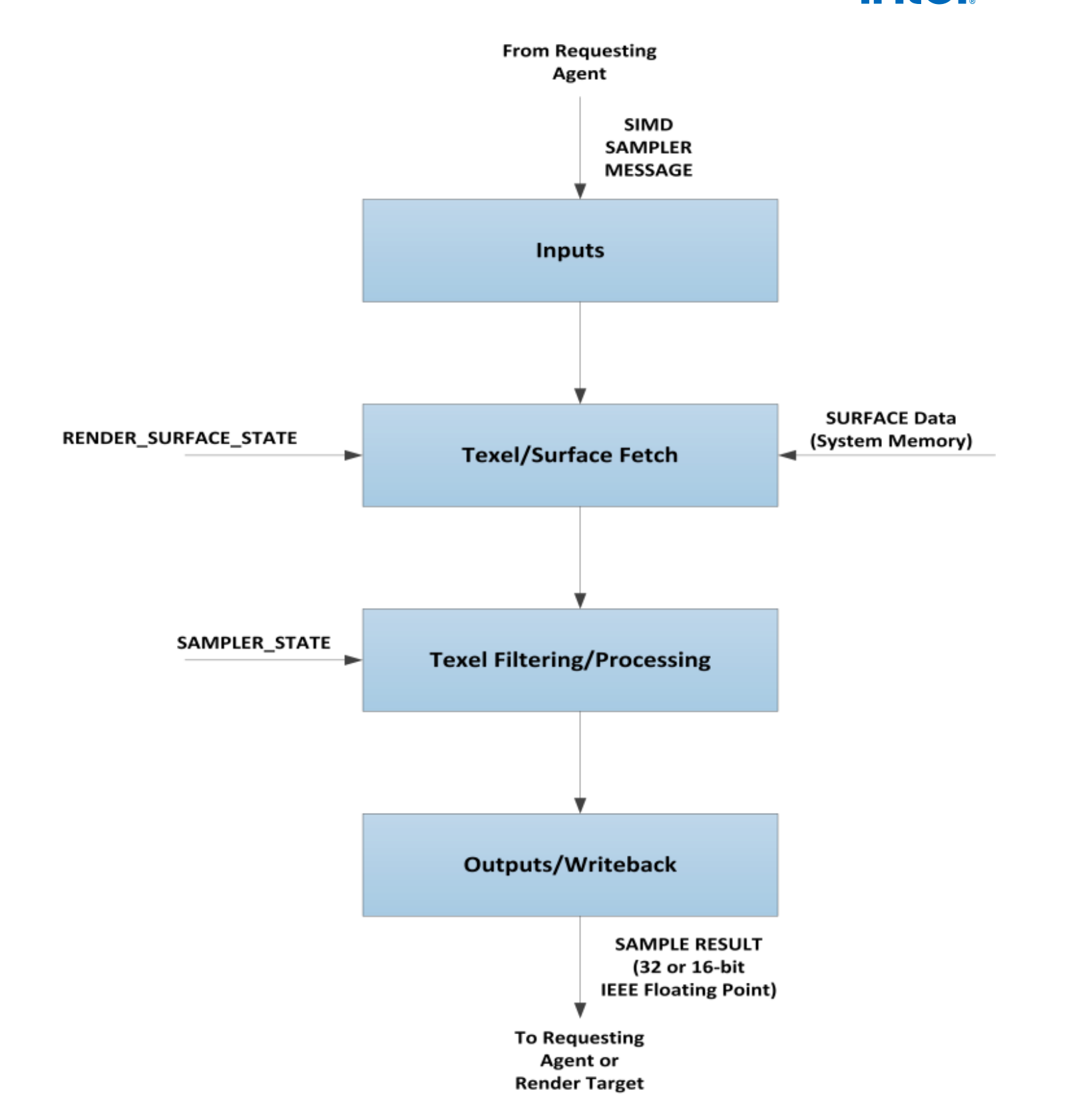
surface:A rendering operand or destination, including textures, buffers, and render targets
Surface state :State associated with a render surface including
进行采样处理需要 surface state objects (RENDER_SURFACE_STATE), surface data,以及 sampler state。采样器通过 surface state objects 来获取 surface 在 system 中地址 以及 surface 的格式。采样器获取到了支持的格式的 surface 就会自动解压。采样器支持的滤波模式有(point, bilinear, trilinear, anisotropic, cube etc.) ,具体处理时根据 SAMPLER_STATE state object 内容来确定使用哪个模式参数。
2. 主要指令
GPU 维护了一个 bind table 表,每种类型的 shader 都有一个绑定表。Send 发送命令到 sampler 时 data 里包含了 bind table 的基地址和表里 entry。通过绑定表找到要使用的 surface state。
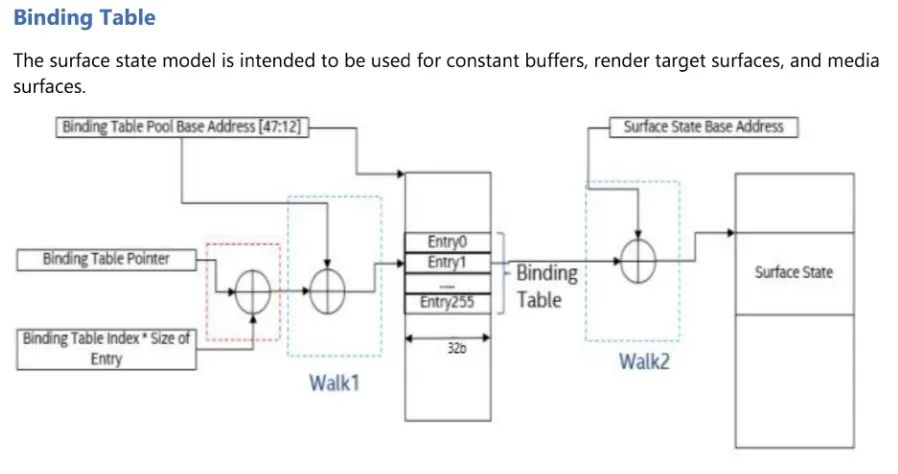
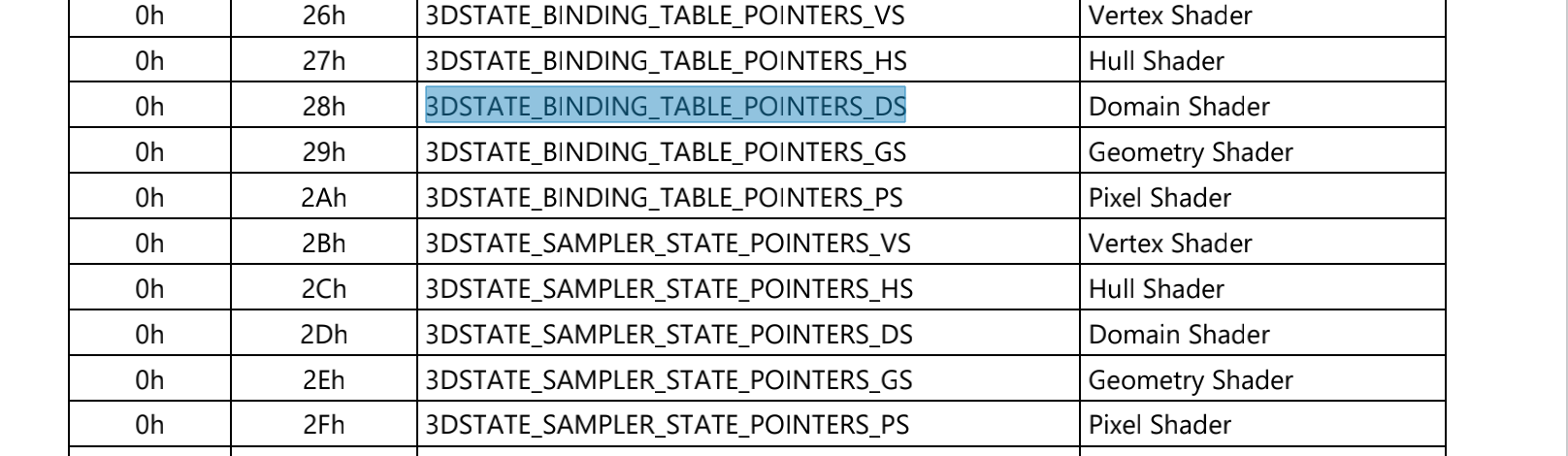
根据 手册每种 shader 都有自己的 BTP,也就是每个 shader 都有一个 bind 表。BTP 是通过 3DSTATE_BINDING_TABLE_POINTERS_XXX 命令指定。
BTPB 通过 3DSTATE_BINDING_TABLE_POOL_ALLOC 命令设置。
Surface State Base address 通过 STATE_BASE_ADDRESS 命令指定。STATE_BASE_ADDRESS 作为一个通用的基地址设置寄存器可以设置多个基地址:
General State Base Address;
Surface State Base Address;
Dynamic State Base Address;
Indirect Object Base Address ;
Instruction Base Address ;
Bindless Surface State Base Address;
Bindless Sampler State Base Address;
sampler state 则是通过 message 消息中包含的 Sampler State Pointer 获取到偏移地址,和 DynamicStateBaseAddress 基地址组合找到位于 system 种的 sampler state。Sampler State Pointer 是通过3DSTATE_SAMPLER_STATE_POINTERS_xx 设置的。

3. Mesa 中的实现
mesa 中设置 surface base addr 是调用的 update_surface_base_address 函数。
在 blorp_emit_surface_states 函数中对调用 blorp_alloc_binding_table 分配新的 bind table 会执行 update_surface_base_address 基地址。
mesa 中的 blorp_emit_surface_states 函数会执行 3DSTATE_BINDING_TABLE_POINTERS_xxx 将每种 shader 设置 BTP,该 BTP 维护在 struct iris_binding_table 中
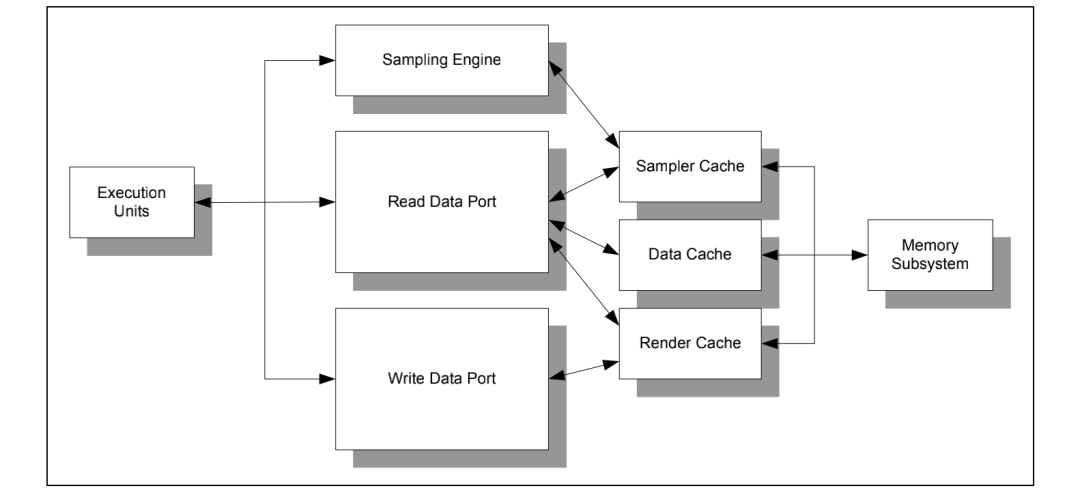
DataPort
采样器只能读取, DataPort 具有读写功能,提供了所有的内存的访问通道。
context
Execlists
Execution-List 是硬件提供的软件接口。SW 通过将要执行的命令填写到 context 对应的 ring buffer 中,然后讲 context 提交给引擎的 Execlist Submit Port (ELSP), dg1 上有两个 ELSP。Execution-List 使用 需要引擎的 GFX_MODE 寄存器设置相应的 enable。
Context state
每个 context 根据其工作负载要求对引擎状态进行编程。硬件执行需要修改的状态称为 context state。每个 congtext 都有自己的 context state。Context state 在执行当前 context ring buffer 的命令时被修改。指定在引擎上运行的所有 context 都具有相同的上下文格式。context 通过 Logical Context Address 指向了存储 context state 的地址。
Logical Context Address
logical context address 是保存硬件信息(context state)的一个全局虚拟地址(GPU 的虚拟地址),GPU context 切换通过 logical context address 来完成 context state 的保存和加载。当调度器通过 Execution-List 提交一个工作负载列表时,命令流媒体硬件一次执行一次 context 切换。引擎通过 logical context address(LRCA)来加载 logical context。
Context state 包含内容
the following sections: • Per-Process HW Status Page (4K) • Ring Context (Ring Buffer Control Registers, Page Directory Pointers, etc.)
• Engine Context ( PipelineState, Non-pipelineState, Statistics, MMIO)
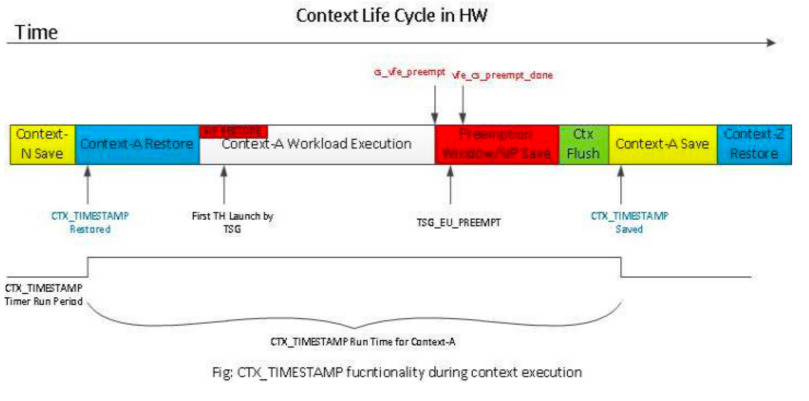
context 的生命周期
Mesa 3D 代码实现分析
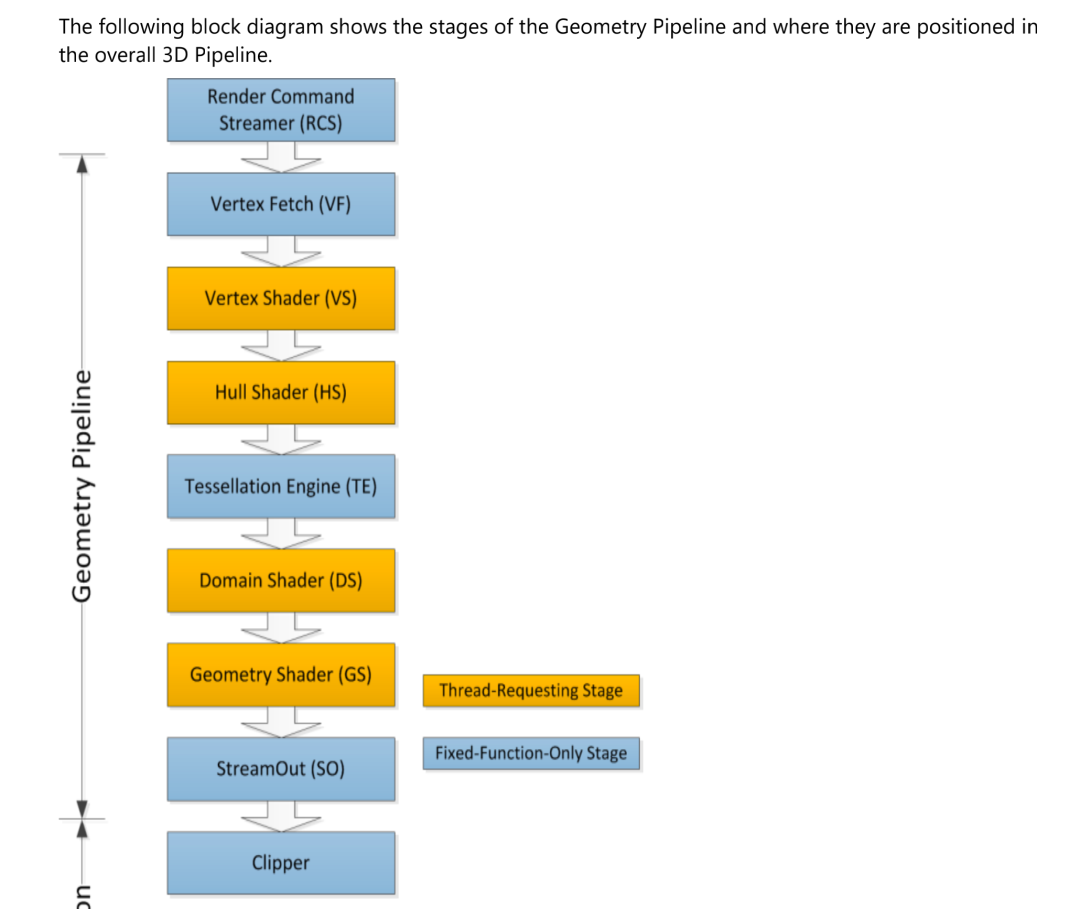
图 渲染pipeline 各阶段
黄色的阶段代表没有固定的硬件来完成这个功能,而是由 CS 中的固定函数单元发起一个 EU thread 来完成功能。也就是黄色的阶段都是可编程的。蓝色的是由固定硬件完成,不可编程。
Vertex Fetch (VF) stage
顶点获取阶段。当 3D Primitive 命令下发后,VF 负责从内存中读取顶点数据,重新格式化它,并将结果写入顶点 URB 条目中。VF 单元会生成 instanceID,VertexID 和 PrimitiveID 这些数据的组合将会写入到 VUE 中。
VF 的数据处理
3D_Primitive 之前要先下发 3D pipeline state 相关的命令,这样 3D_Primitive 解析到后 CS 会让 VF 硬件开始工作去获取数据然后处理数据,从用户的 batchbuffer 3D_Primitive 命令位置反方向解析之前的 3D pipeline 相关命令。STATE_BASE_ADDRESS 命令用于设置基地址,后面下发命令使用 bind table/surface state 地址都与这个基地址有关。在 mesa 中 src/gallium/drivers/iris/iris_bufmgr.h 中有介绍相关的内存分配情况:
/**
* Memory zones. When allocating a buffer, you can request that it is
* placed into a specific region of the virtual address space (PPGTT).
*
* Most buffers can go anywhere (IRIS_MEMZONE_OTHER). Some buffers are
* accessed via an offset from a base address. STATE_BASE_ADDRESS has
* a maximum 4GB size for each region, so we need to restrict those
* buffers to be within 4GB of the base. Each memory zone corresponds
* to a particular base address.
*
* We lay out the virtual address space as follows:
*
* - [0, 4K): Nothing (empty page for null address)
* - [4K, 4G): Shaders (Instruction Base Address)
* - [4G, 8G): Surfaces & Binders (Surface State Base Address, Bindless ...)
* - [8G, 12G): Dynamic (Dynamic State Base Address)
* - [12G, *): Other (everything else in the full 48-bit VMA)
*/
相应的mesa 中将ppgtt使用的虚拟地址也分成了几个zone
enum iris_memory_zone {
IRIS_MEMZONE_SHADER,
IRIS_MEMZONE_BINDER,
IRIS_MEMZONE_SCRATCH,
IRIS_MEMZONE_SURFACE,
IRIS_MEMZONE_DYNAMIC,
IRIS_MEMZONE_OTHER,
IRIS_MEMZONE_BORDER_COLOR_POOL,
};
3D pipeline 状态设置命令
VF 阶段接收来自 CS 单元的 3DPRIMITIVE 命令信息,执行该命令,将生成的顶点数据存储在 URB 中,并将相应的顶点信息包向下传递给其他的管道 stage。在 3D primitives 命令发出之前,要如下命令设置 Pipeline 各种状态: • 3DSTATE_PIPELINED_POINTERS (gen45 后这个命令没了) • 3DSTATE_BINDING_TABLE_POINTERS • 3DSTATE_VERTEX_BUFFERS • 3DSTATE_VERTEX_ELEMENTS • 3DSTATE_INDEX_BUFFERS • 3DSTATE_VF_STATISTICS • 3DSTATE_DRAWING_RECTANGLE • 3DSTATE_CONSTANT_COLOR • 3DSTATE_DEPTH_BUFFER • 3DSTATE_POLY_STIPPLE_OFFSET • 3DSTATE_POLY_STIPPLE_PATTERN • 3DSTATE_LINE_STIPPLE
• 3DSTATE_GLOBAL_DEPTH_OFFSET
和 VF 顶点输入有关的命令有: • 3DSTATE_VERTEX_BUFFERS(顶点 buffer VBO) • 3DSTATE_VERTEX_ELEMENTS(顶点属性配置) • 3DSTATE_INDEX_BUFFERS(索引 buffer EBO)
• 3DPRIMITIVE(图元装配)
• 3DSTATE_VF_STATISTICS(顶点信息统计)
vertex buffer
3DSTATE_VERTEX_BUFFERS 和 3DSTATE_VERTEX_STATE 命令 用来定义存放顶点的 buffer。3D Primitive 中使用的顶点 buffer 大部分来自顶点 buffer。在 OpenGL 中对应的 VBO(Vertex Buffer Object)。
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
// create VBOs
glGenBuffers(1, &vboId); // for vertex buffer
glBindBuffer(GL_ARRAY_BUFFER, vboId);
// copy vertex attribs data to VBO
glBufferSubData(GL_ARRAY_BUFFER, 0, vSize, vertices);//将顶点数据写入到VBO中
VB(vertex buffer)是一个一维结构的数组,其中结构的大小由 VB 的缓冲间距定义。3DPrimitive 对 vertex buffer 的访问有顺序和随机两种方式。当 OpenGL 没有使用顶点 index buffer object(element buffer object)的时候会顺序读.使用 index buffer object 会根据 buffer 指定 index 在 buffer 中随机读取。
3DSTATE_VERTEX_STATE 是用户表示数据缓冲区和实例化数据缓冲区的一个结构,是一个 4 个 Dword 大小的 buffer。一个 3DSTATE_VERTEX_BUFFERS 可以指定多个 3DSTATE_VERTEX_STATE(至少包含一个),最多绑定 33 个 3DSTATE_VERTEX_STATE。
 mesa 中 src/gallium/drivers/iris/iris_state.c 文件用来给 batchbuffer 填充 3D pipeline state 相关的命令。iris_upload_dirty_render_state 函数将 3DSTATE_VERTEX_BUFFERS 写入到 batch buffer 中。
mesa 中 src/gallium/drivers/iris/iris_state.c 文件用来给 batchbuffer 填充 3D pipeline state 相关的命令。iris_upload_dirty_render_state 函数将 3DSTATE_VERTEX_BUFFERS 写入到 batch buffer 中。
const unsigned vb_dwords = GENX(VERTEX_BUFFER_STATE_length);
uint32_t *map =
iris_get_command_space(batch, 4 * (1 + vb_dwords * count));
_iris_pack_command(batch, GENX(3DSTATE_VERTEX_BUFFERS), map, vb) {//写入命令
vb.DWordLength = (vb_dwords * count + 1) - 2;
}
map += 1;
bound = dynamic_bound;
while (bound) {
const int i = u_bit_scan64(&bound);
memcpy(map, genx->vertex_buffers[i].state, //3DSTATE_VERTEX_STATE 数据拷贝到batchbuffer中
sizeof(uint32_t) * vb_dwords);
map += vb_dwords;
}
}
在 opengl 调用 genbuffer 创建 vbo 再写入数据后 mesa 后端 pipe 会调用 pipe->set_vertex_buffers, 调用 iris_set_vertex_buffers 函数将 buffer 的地址 大小等数据 xieru 到 vertex buffer state 结构中。
3DSTATE_VERTEX_BUFFERS 命令写入时候将存储的 vertex buffer state 数据一起写入到 batch buffer 中。
static void
iris_set_vertex_buffers(struct pipe_context *ctx,
unsigned start_slot, unsigned count,
unsigned unbind_num_trailing_slots,
bool take_ownership,
const struct pipe_vertex_buffer *buffers) {
.............省略
iris_pack_state(GENX(VERTEX_BUFFER_STATE), state->state, vb) {
vb.VertexBufferIndex = start_slot + i;
vb.AddressModifyEnable = true;
vb.BufferPitch = buffer->stride;
if (res) {
vb.BufferSize = res->base.b.width0 - (int) buffer->buffer_offset;
vb.BufferStartingAddress =
ro_bo(NULL, res->bo->address + (int) buffer->buffer_offset);
vb.MOCS = iris_mocs(res->bo, &screen->isl_dev,
ISL_SURF_USAGE_VERTEX_BUFFER_BIT);
#if GFX_VER >= 12
vb.L3BypassDisable = true;
#endif
} else {
vb.NullVertexBuffer = true;
vb.MOCS = iris_mocs(NULL, &screen->isl_dev,
ISL_SURF_USAGE_VERTEX_BUFFER_BIT);
}
}
}
.........省略
}
iris_pack_state 宏定义是根据 mesa 中的 xml 生成了,如果不编译源码是没有这个文件的,生成目录 build/src/intel/genxml/gen12_pack.h。
index buffer
3DSTATE_INDEX_BUFFERS 命令用来配置 index buffer 相关 state(address/size 等等)index buffer 在 OpenGL 中也叫做 Element buffer 也就是 EBO(Element buffer object)。
float vertices[] = {
0.5f, 0.5f, 0.0f, // 右上角
0.5f, -0.5f, 0.0f, // 右下角
-0.5f, -0.5f, 0.0f, // 左下角
-0.5f, 0.5f, 0.0f // 左上角
};
unsigned int indices[] = {
0, 1, 3, // 第一个三角形
1, 2, 3 // 第二个三角形
};
glGenBuffers(1, &EBO);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, EBO);
glBufferData(GL_ELEMENT_ARRAY_BUFFER, sizeof(indices), indices, GL_STATIC_DRAW);
EBO 是为了解决一个顶点多次重复调用的问题,可以减少内存的空间浪费,提高执行效率,当重复使用重复顶点时,通过顶点的位置索引来调用顶点。而不是重复调用顶点的数据。
EBO 中存储的内容就是顶点位置的索引 indices,EBO 类似于 VBO,也是在显存中分配的一个 bufer,只不过 EBO 存放的是顶点的索引。GPU 中 index buffer 结构布局按照手册中的 3DSTATE_INDEX_BUFFER_BODY 格式 mesa 中的 iris_upload_render_state 函数将 3DSTATE_INDEX_BUFFERS xieru 到 batch buffer 中。
uint32_t ib_packet[GENX(3DSTATE_INDEX_BUFFER_length)];
iris_pack_command(GENX(3DSTATE_INDEX_BUFFER), ib_packet, ib) {
ib.IndexFormat = draw->index_size >> 1;
ib.MOCS = iris_mocs(bo, &batch->screen->isl_dev,
ISL_SURF_USAGE_INDEX_BUFFER_BIT);
ib.BufferSize = bo->size - offset;
ib.BufferStartingAddress = ro_bo(NULL, bo->address + offset);
#if GFX_VER >= 12
ib.L3BypassDisable = true;
#endif
}
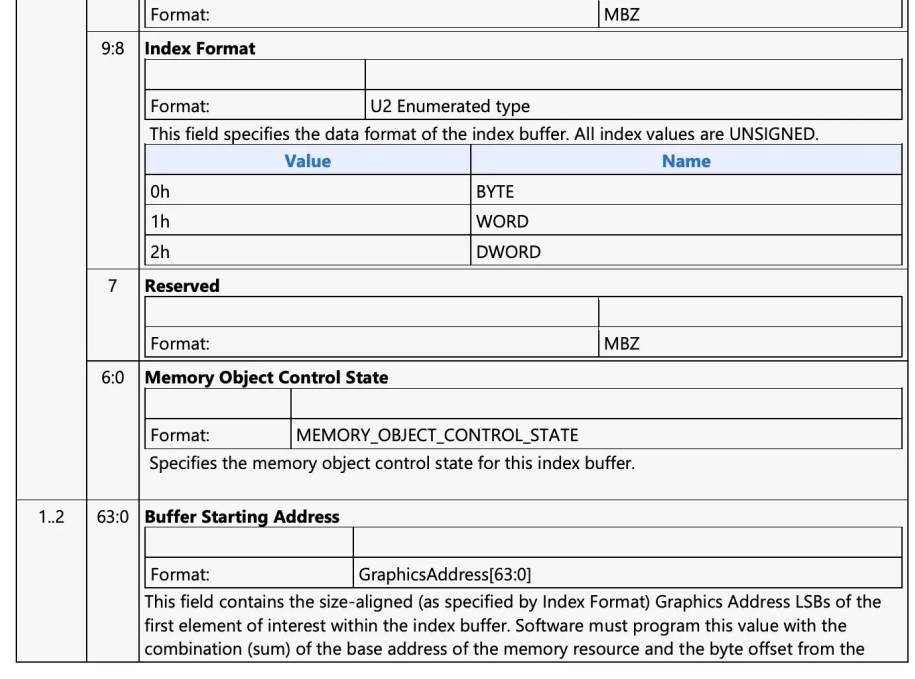
index format 对应的是 opengl 中的索引值的类型:GL_UNSIGNED_BYTE, GL_UNSIGNED_SHORT, or GL_UNSIGNED_INT。
3DSTATE_INDEX_BUFFERS 和 3DSTATE_VERTEX_BUFFERS 都有 bo->address,这个 bo address 并不是 CPU 侧映射的虚拟地址,而是通过上面说的给 ppgtt 使用的虚拟地址。从 mesa 驱动划分的不同 zone 分配出来的。
enum iris_memory_zone {
IRIS_MEMZONE_SHADER,
IRIS_MEMZONE_BINDER,
IRIS_MEMZONE_SCRATCH,
IRIS_MEMZONE_SURFACE,
IRIS_MEMZONE_DYNAMIC,
IRIS_MEMZONE_OTHER,
IRIS_MEMZONE_BORDER_COLOR_POOL,
};
mesa 用户态驱动 bo 的分配必须指定自己使用的 mem zone。
iris_bo_alloc(struct iris_bufmgr *bufmgr,
const char *name,
uint64_t size,
uint32_t alignment,
enum iris_memory_zone memzone,
unsigned flags)
从指定的 zone 分配出来虚拟地址后, 这个虚拟地址写入到 batch 中,根据之前设置的 base 基地址。GPU 驱动会强制使用这个地址做 PPGTT(Per-Process Graphics Translation Table) 的虚拟地址映射。
顶点属性
有了 VBO/EBO 后顶点数据和顶点使用顺序已经有了,VBO 存储顶点数据有不同的格式,GPU 硬件按照什么格式解析 VBO 数据需要告诉 GPU。在 opengl 中 glVertexAttribPointer 和 glvertexattribformat 用来设置 buffer 中顶点数据的解析方式。
// 0. 复制顶点数组到缓冲中供OpenGL使用 glBindBuffer(GL_ARRAY_BUFFER, VBO); glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW); // 1. 设置顶点属性指针 glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0); glEnableVertexAttribArray(0); 来自https://learnopengl-cn.github.io/01%20Getting%20started/04%20Hello%20Triangle/ glVertexAttribPointer`函数的参数非常多,所以我会逐一介绍它们: - 第一个参数指定我们要配置的顶点属性。在顶点着色器中使用`layout(location = 0)`定义了`position`顶点属性的位置值(Location)吗?它可以把顶点属性的位置值设置为`0`。因为我们希望把数据传递到这一个顶点属性中,所以这里我们传入`0`。 - 第二个参数指定顶点属性的大小。顶点属性是一个`vec3`,它由3个值组成,所以大小是3。 - 第三个参数指定数据的类型,这里是`GL_FLOAT`(GLSL中`vec*`都是由浮点数值组成的)。 - 下个参数定义我们是否希望数据被标准化(Normalize)。如果我们设置为`GL_TRUE`,所有数据都会被映射到0(对于有符号型signed数据是-1)到1之间。我们把它设置为`GL_FALSE`。 - 第五个参数叫做步长(Stride),它告诉我们在连续的顶点属性组之间的间隔。由于下个组位置数据在3个`float`之后,我们把步长设置为`3 * sizeof(float)`。要注意的是由于我们知道这个数组是紧密排列的(在两个顶点属性之间没有空隙)我们也可以设置为0来让OpenGL决定具体步长是多少(只有当数值是紧密排列时才可用)。一旦我们有更多的顶点属性,我们就必须更小心地定义每个顶点属性之间的间隔,我们在后面会看到更多的例子(译注: 这个参数的意思简单说就是从这个属性第二次出现的地方到整个数组0位置之间有多少字节)。 - 最后一个参数的类型是`void*`,所以需要我们进行这个奇怪的强制类型转换。它表示位置数据在缓冲中起始位置的偏移量(Offset)。由于位置数据在数组的开头,所以这里是0stride offset 和 stride 配置可以参考:
https://stackoverflow.com/questions/16380005/opengl-3-4-glvertexattribpointer-stride-and-offset-miscalculation
在 GPU 中使用 VERTEX_ELEMENT_STATE 来设置顶点的属性。3DSTATE_VERTEX_ELEMENTS 设置有多少个 VERTEX_ELEMENT_STATE. mesa 代码中通过 struct pipe_vertex_element 结构维护顶点属性
struct pipe_vertex_element
{
/** Offset of this attribute, in bytes, from the start of the vertex */
uint16_t src_offset;
/** Which vertex_buffer (as given to pipe->set_vertex_buffer()) does
* this attribute live in?
*/
uint8_t vertex_buffer_index:7;
/**
* Whether this element refers to a dual-slot vertex shader input.
* The purpose of this field is to do dual-slot lowering when the CSO is
* created instead of during every state change.
*
* It's lowered by util_lower_uint64_vertex_elements.
*/
bool dual_slot:1;
/**
* This has only 8 bits because all vertex formats should be <= 255.
*/
uint8_t src_format; /* low 8 bits of enum pipe_format. */
/** Instance data rate divisor. 0 means this is per-vertex data,
* n means per-instance data used for n consecutive instances (n > 0).
*/
unsigned instance_divisor;
};
pipe->create_vertex_elements_state 来设置顶点属性,intel iris_create_vertex_elements 写 VERTEX_ELEMENT_STATE
iris_pack_state(GENX(VERTEX_ELEMENT_STATE), ve_pack_dest, ve) {
ve.EdgeFlagEnable = false;
ve.VertexBufferIndex = state[i].vertex_buffer_index;
ve.Valid = true;
ve.SourceElementOffset = state[i].src_offset;
ve.SourceElementFormat = fmt.fmt;
ve.Component0Control = comp[0];
ve.Component1Control = comp[1];
ve.Component2Control = comp[2];
ve.Component3Control = comp[3];
}
顶点数据处理
3DPrimitive 命令下发后,根据 batch buffer 配置的顶点 buffer 地址,格式,index 等信息 GPU 处理顶点数据,将顶点数据处理 生成 vertexid ,vertexindex 等后写入到 URB 中,生成独一的 URB handle, VS 通过 URB handle 配合 shader 处理数据。3DPRIMITIVE 命令指定数据格式:
iris_emit_cmd(batch, GENX(3DPRIMITIVE), prim) {
prim.VertexAccessType = draw->index_size > 0 ? RANDOM : SEQUENTIAL;/是否存在index buffer 存在就是随机读取
prim.PredicateEnable = use_predicate;
if (indirect) {
prim.IndirectParameterEnable = true;
} else {
prim.StartInstanceLocation = draw->start_instance;
prim.InstanceCount = draw->instance_count;
prim.VertexCountPerInstance = sc->count;
prim.StartVertexLocation = sc->start;//对应opengl 中glDrawArrays 的start
if (draw->index_size) {
prim.BaseVertexLocation += sc->index_bias;//顶点的固定偏移,类似于glDraw[Range]Elements{,BaseVertex}" api 指定BaseVertex
}
}
}
顶点数据的读取写入 URE 大体流程
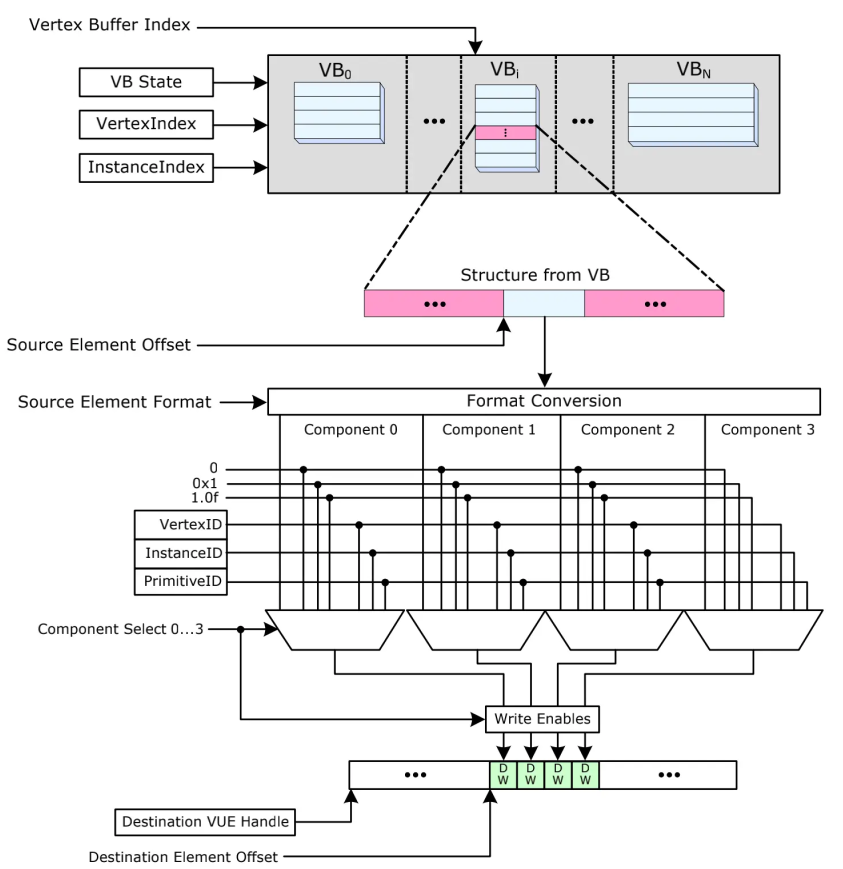
3D Primitives 处理顶点数据伪代码(来自 gen4 手册)

vertexloop 会计算当前的 VERTEXID,顺序读写生成 VERTEXID 伪代码:
VertexIndex = StartVertexLocation + VertexNumber VertexID = VertexNumber
随机读写伪代码:
IBIndex = StartVertexLocation + VertexNumber VertexID = IB[IBIndex] if (VertexID == ‘all ones’) CutFlag = 1 else VertexIndex = VertexID + BaseVertexLocation CutFlag = 0 endif相比顺序读写,随机读写是从 index buffer 查找顶点的位置,所以多了个 index buffer 的过程。
PrimitiveID 是每个 PrimitiveI type 每个的 id,下图比较形象
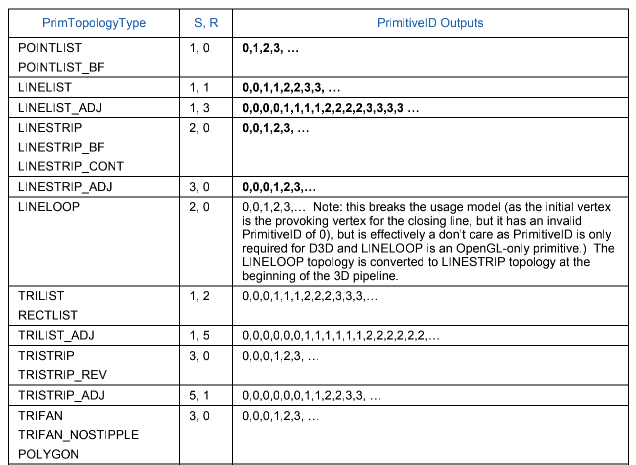
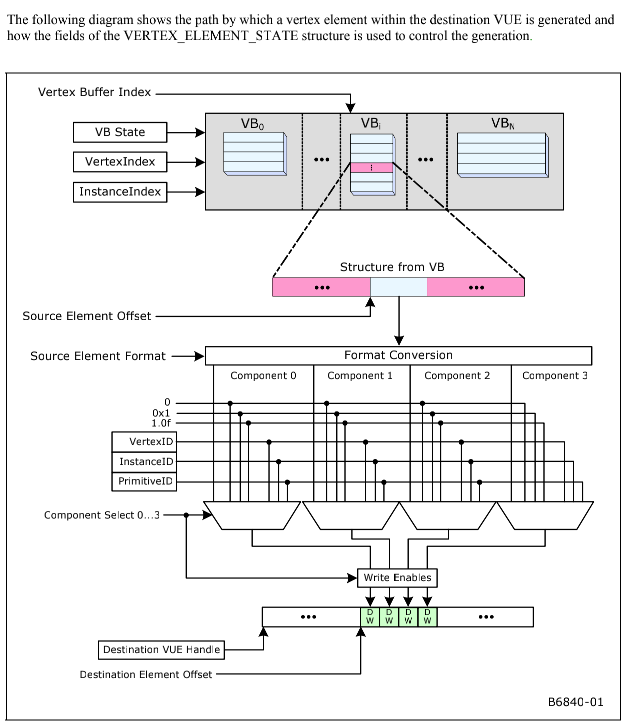
Vertexid, PrimitiveID,顶点数据的格式转换,最后生成 vue handle 给 VS 阶段使用。
Vertex Shader (VS) Stage
VF 处理完成顶点数据后传输到 pipeline 下个 stage VS。VS 通过 URB handle 读取 shader 需要的数据,发起 EU 上的线程执行 shader。发起 thread 是通过 Thread Dispatcher 完成. shader 编译器会根据 shader 的内容生成使用的常量 buffer,使用的 surface,采样器等信息。这些 state 通过 3DSTATE_XX 命令下发下去。VS 使用 3DSTATE_VS。
这些信息通过 3DSTATE_VS 命令下发给 GPU,在 mesa /src/gallium/drivers/iris/iris_state.c 下发所有和 state 相关的信息。
#define INIT_THREAD_DISPATCH_FIELDS(pkt, prefix, stage)
pkt.KernelStartPointer = KSP(shader);
pkt.BindingTableEntryCount = shader->bt.size_bytes / 4;
pkt.FloatingPointMode = prog_data->use_alt_mode;
pkt.DispatchGRFStartRegisterForURBData =
prog_data->dispatch_grf_start_reg;
pkt.prefix##URBEntryReadLength = vue_prog_data->urb_read_length;
pkt.prefix##URBEntryReadOffset = 0;
pkt.StatisticsEnable = true;
pkt.Enable = true;
if (prog_data->total_scratch) {
struct iris_bo *bo =
iris_get_scratch_space(ice, prog_data->total_scratch, stage);
uint32_t scratch_addr = bo->gtt_offset;
pkt.PerThreadScratchSpace = ffs(prog_data->total_scratch) - 11;
pkt.ScratchSpaceBasePointer = rw_bo(NULL, scratch_addr,
IRIS_DOMAIN_NONE);
}
/**
* Encode most of 3DSTATE_VS based on the compiled shader.
*/
static void
iris_store_vs_state(struct iris_context *ice,
const struct gen_device_info *devinfo,
struct iris_compiled_shader *shader)
{
struct brw_stage_prog_data *prog_data = shader->prog_data;
struct brw_vue_prog_data *vue_prog_data = (void *) prog_data;
iris_pack_command(GENX(3DSTATE_VS), shader->derived_data, vs) {
INIT_THREAD_DISPATCH_FIELDS(vs, Vertex, MESA_SHADER_VERTEX);
vs.MaximumNumberofThreads = devinfo->max_vs_threads - 1;
vs.SIMD8DispatchEnable = true;
vs.UserClipDistanceCullTestEnableBitmask =
vue_prog_data->cull_distance_mask;
}
}

采样器 state/table 的创建
在 GPU 中每个 shader stage 都有自己的 sampler state 表,然后通过 3DSTATE_SAMPLER_STATE_POINTERS_XX 设置到硬件。
Mesa gallium 分为前端和后端。OpenGL 后端实现都是基于 pipe 结构调用硬件驱动。ctx->pipe->create_sampler_states//创建一个基于硬件支持的 sample state 结构 ctx->pipe->bind_sampler_states //将创建的 sample state 结构和 VS/FS 等阶段绑定
OpenGL 中纹理采样器的使用
void glGenSamplers (GLsizei count, GLuint *samplers); void glSamplerParameteri (GLuint sampler, GLenum pname, GLint param); void glSamplerParameterf (GLuint sampler, GLenum pname, GLfloat param); void glBindSampler(GLuint unit, GLuint sampler);
mesa 中维护的 sampler 结构
gl_sampler_object 转换成pipe_sampler_state,然后update_shader_samplers—>cso_set_samplers-> cso_single_sampler->cso_single_sampler->pipe->create_sampler_states ->iris_create_sampler_state最后调用intel 驱动iris_create_sampler_state 将数据写入到硬件支持的buffer里。
mesa中通过cso_single_sampler_done函数将sampler state和3d pipeline stage 绑定
void
cso_single_sampler_done(struct cso_context *ctx,
enum pipe_shader_type shader_stage)
{
struct sampler_info *info = &ctx->samplers[shader_stage];
if (ctx->max_sampler_seen == -1)
return;
ctx->pipe->bind_sampler_states(ctx->pipe, shader_stage, 0,
ctx->max_sampler_seen + 1,
info->samplers);
ctx->max_sampler_seen = -1;
}
最后 iris_upload_sampler_states 函数中会分配一个 sampler_table 的 bo,然后将 sample state 数据拷贝到 bo 中,然后通过 3DSTATE_SAMPLER_STATE_POINTERS_VS 命令下发到 GPU。
Sampler State TABLE
sampler state 则是通过 message 消息中包含的 Sampler State Pointer 获取到偏移地址,和 DynamicStateBaseAddress 基地址组合找到位于 system 种的 sampler state。Sampler State Pointer 是通过 3DSTATE_SAMPLER_STATE_POINTERS_xx 设置的。
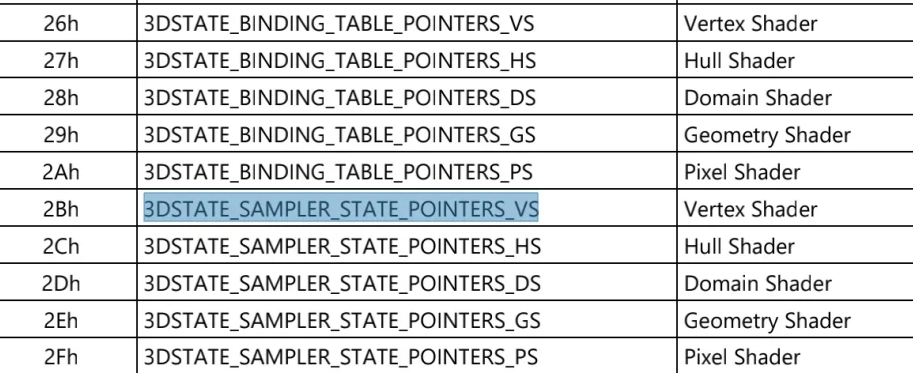
for (int stage = 0; stage <= MESA_SHADER_FRAGMENT; stage++) {
if (!(stage_dirty & (IRIS_STAGE_DIRTY_SAMPLER_STATES_VS << stage)) ||
!ice->shaders.prog[stage])
continue;
iris_upload_sampler_states(ice, stage); //更新sampler state 到sampler_table中
struct iris_shader_state *shs = &ice->state.shaders[stage];
struct pipe_resource *res = shs->sampler_table.res;
if (res)
iris_use_pinned_bo(batch, iris_resource_bo(res), false,
IRIS_DOMAIN_NONE);
iris_emit_cmd(batch, GENX(3DSTATE_SAMPLER_STATE_POINTERS_VS), ptr) {
ptr._3DCommandSubOpcode = 43 + stage;
ptr.PointertoVSSamplerState = shs->sampler_table.offset;
}
}
Mesa gallium 分为前端和后端。Opengl 后端实现都是基于 pipe 结构调用硬件用户态驱动。
ctx->pipe->create_sampler_states //创建一个基于硬件支持的 sample state 结构
ctx->pipe->bind_sampler_states // 将 sample state 结构和 VS FS 等 state 阶段绑定
glGenSamplers 会创建一个采样器 glBindSampler 绑定一个采样器 glSamplerParameter 设置采样器参数等等 api 会在 mesa 创建由khronos.org OpenGL 定义的ARB_sampler_objects 结构体并且设置相关的参数。在 draw 时候调用 update_shader_samplers, 在 update 中 st_convert_sampler(函数将
gl_sampler_object 转换成 pipe_sampler_state,然后 update_shader_samplers—>cso_set_samplers-> cso_single_sampler->cso_single_sampler->pipe->create_sampler_states ->iris_create_sampler_state, 最后调用驱动 iris_create_sampler_state 将数据写入到硬件支持的 SAMPLER_STATE 格式 buffer 里。
iris_create_sampler_state(struct pipe_context *ctx,
const struct pipe_sampler_state *state)
{
struct iris_sampler_state *cso = CALLOC_STRUCT(iris_sampler_state);
......
float min_lod = state->min_lod;
unsigned mag_img_filter = state->mag_img_filter;
// XXX: explain this code ported from ilo...I don't get it at all...
if (state->min_mip_filter == PIPE_TEX_MIPFILTER_NONE &&
state->min_lod > 0.0f) {
min_lod = 0.0f;
mag_img_filter = state->min_img_filter;
}
iris_pack_state(GENX(SAMPLER_STATE), cso->sampler_state, samp) {
samp.TCXAddressControlMode = wrap_s;
samp.TCYAddressControlMode = wrap_t;
samp.TCZAddressControlMode = wrap_r;
samp.CubeSurfaceControlMode = state->seamless_cube_map;
samp.NonnormalizedCoordinateEnable = !state->normalized_coords;
samp.MinModeFilter = state->min_img_filter;
samp.MagModeFilter = mag_img_filter;
samp.MipModeFilter = translate_mip_filter(state->min_mip_filter);
samp.MaximumAnisotropy = RATIO21;
if (state->max_anisotropy >= 2) {
if (state->min_img_filter == PIPE_TEX_FILTER_LINEAR) {
samp.MinModeFilter = MAPFILTER_ANISOTROPIC;
samp.AnisotropicAlgorithm = EWAApproximation;
}
if (state->mag_img_filter == PIPE_TEX_FILTER_LINEAR)
samp.MagModeFilter = MAPFILTER_ANISOTROPIC;
samp.MaximumAnisotropy =
MIN2((state->max_anisotropy - 2) / 2, RATIO161);
}
}
在 cso_set_samplers 函数中分配的 sampler 结构指针赋值给了 ctx 的 samplers 中
cso_single_sampler(struct cso_context *ctx, enum pipe_shader_type shader_stage,
unsigned idx, const struct pipe_sampler_state *templ)
{
if (templ) {
unsigned key_size = sizeof(struct pipe_sampler_state);
unsigned hash_key = cso_construct_key((void*)templ, key_size);
struct cso_sampler *cso;
struct cso_hash_iter iter =
cso_find_state_template(ctx->cache,
hash_key, CSO_SAMPLER,
(void *) templ, key_size);
if (cso_hash_iter_is_null(iter)) {
cso = MALLOC(sizeof(struct cso_sampler));
if (!cso)
return;
memcpy(&cso->state, templ, sizeof(*templ));
cso->data = ctx->pipe->create_sampler_state(ctx->pipe, &cso->state);
cso->delete_state =
(cso_state_callback) ctx->pipe->delete_sampler_state;
cso->context = ctx->pipe;
cso->hash_key = hash_key;
iter = cso_insert_state(ctx->cache, hash_key, CSO_SAMPLER, cso);
if (cso_hash_iter_is_null(iter)) {
FREE(cso);
return;
}
}
else {
cso = cso_hash_iter_data(iter);
}
ctx->samplers[shader_stage].cso_samplers[idx] = cso;
ctx->samplers[shader_stage].samplers[idx] = cso->data;
ctx->max_sampler_seen = MAX2(ctx->max_sampler_seen, (int)idx);
}
}
将 create sample 创建的 state 发动给驱动, 和 stage 绑定
/**
* Send staged sampler state to the driver.
*/
void
cso_single_sampler_done(struct cso_context *ctx,
enum pipe_shader_type shader_stage)
{
struct sampler_info *info = &ctx->samplers[shader_stage];
if (ctx->max_sampler_seen == -1)
return;
ctx->pipe->bind_sampler_states(ctx->pipe, shader_stage, 0,
ctx->max_sampler_seen + 1,
info->samplers);
ctx->max_sampler_seen = -1;
}
/**
* The pipe->bind_sampler_states() driver hook.
*/
static void
iris_bind_sampler_states(struct pipe_context *ctx,
enum pipe_shader_type p_stage,
unsigned start, unsigned count,
void **states)
{
struct iris_context *ice = (struct iris_context *) ctx;
gl_shader_stage stage = stage_from_pipe(p_stage);
struct iris_shader_state *shs = &ice->state.shaders[stage];
assert(start + count <= IRIS_MAX_TEXTURE_SAMPLERS);
bool dirty = false;
for (int i = 0; i < count; i++) {
if (shs->samplers[start + i] != states[i]) {
shs->samplers[start + i] = states[i];
dirty = true;
}
}
if (dirty)
ice->state.stage_dirty |= IRIS_STAGE_DIRTY_SAMPLER_STATES_VS << stage;
}
最后 iris_upload_sampler_states 函数中会分配一个 sampler_table 的 bo,然后将 sample state 数据拷贝到 bo 中,然后通过 3DSTATE_SAMPLER_STATE_POINTERS_VS 命令下发到 GPU。
STATE BIND TABLE
opengl 使用的纹理,image 等在驱动中都是以 surface 来表示。suface state 保存了地址 属性等信息。state binder table 里 entry 存放了 surface state。每个 shader stage 都有自己的 state binder table,使用 3DSTATE_BINDING_TABLE_POINTERS_XX 命令配置到 GPU。
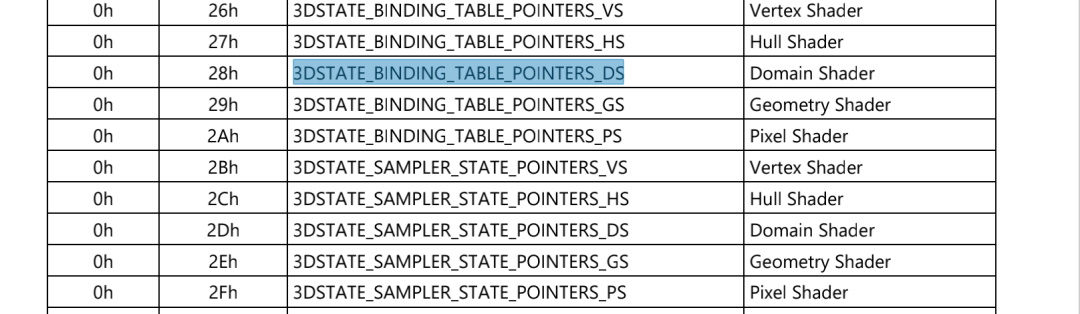
for (int stage = 0; stage <= MESA_SHADER_FRAGMENT; stage++) {
/* Gen9 requires 3DSTATE_BINDING_TABLE_POINTERS_XS to be re-emitted
* in order to commit constants. TODO: Investigate "Disable Gather
* at Set Shader" to go back to legacy mode...
*/
if (stage_dirty & ((IRIS_STAGE_DIRTY_BINDINGS_VS |
(GEN_GEN == 9 ? IRIS_STAGE_DIRTY_CONSTANTS_VS : 0))
<< stage)) {
iris_emit_cmd(batch, GENX(3DSTATE_BINDING_TABLE_POINTERS_VS), ptr) {
ptr._3DCommandSubOpcode = 38 + stage;
ptr.PointertoVSBindingTable = binder->bt_offset[stage];
}
}
}
binder->bt_offset[stage] 是各个 state 的状态表。bt_offset 是保存的地址。在 mesa 中将 ppgtt 使用的虚拟地址都叫做 offset。mesa 通过 heap 分配出这个虚拟地址,然后通过 exec2 下发给驱动,驱动不修改该虚拟地址并强制建立映射关系。
State Bind Table 初始化
OpenGL 创建 context 会调用 iris_create_context,初始化 context 时调用 iris_init_binder 分配一块 bo,用来做 state bind table 的 buffer。
binder_realloc(struct iris_context *ice)
{
struct iris_screen *screen = (void *) ice->ctx.screen;
struct iris_bufmgr *bufmgr = screen->bufmgr;
struct iris_binder *binder = &ice->state.binder;
uint64_t next_address = IRIS_MEMZONE_BINDER_START;
if (binder->bo) {
/* Place the new binder just after the old binder, unless we've hit the
* end of the memory zone...then wrap around to the start again.
*/
next_address = binder->bo->gtt_offset + IRIS_BINDER_SIZE;
if (next_address >= IRIS_MEMZONE_SURFACE_START)
next_address = IRIS_MEMZONE_BINDER_START;
iris_bo_unreference(binder->bo);
}
binder->bo =
iris_bo_alloc(bufmgr, "binder",
IRIS_BINDER_SIZE, IRIS_MEMZONE_BINDER, 0);
binder->bo->gtt_offset = next_address;
binder->map = iris_bo_map(NULL, binder->bo, MAP_WRITE);
binder->insert_point = INIT_INSERT_POINT;
}
填充 state bind table
state bind table 中放的是 OpenGL 使用的各种 surface 的 state,mesa 中 iris_setup_binding_table 是 GPU 通过编译 shader 判断需要有多少 surface 在 shader 中使用, 然后计算出每种 surface state 的大小。在 mesa iris_populate_binding_table 函数中往前面分配的 bind buffer 中 填写数据 。
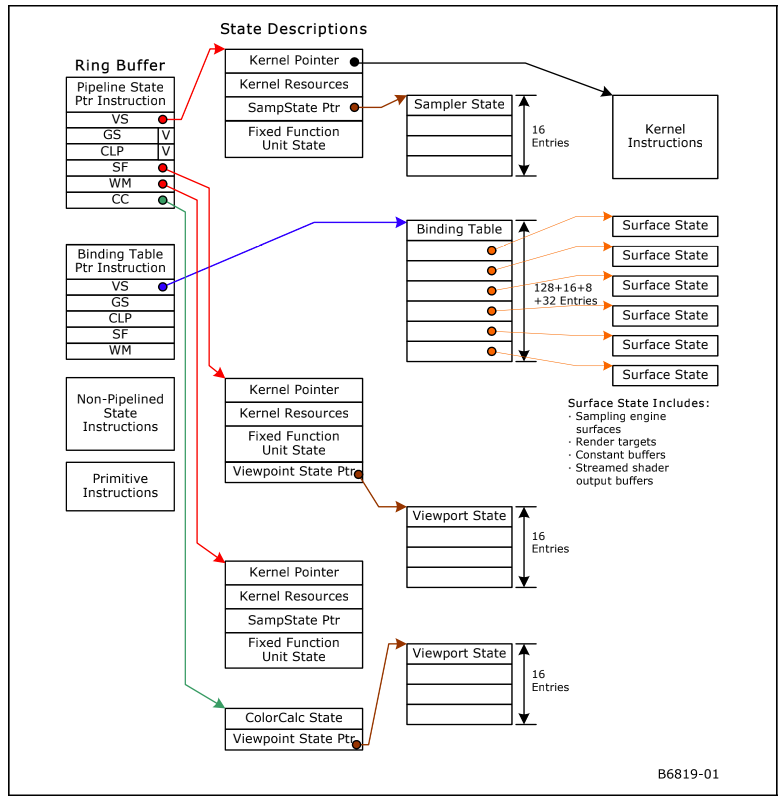
总体 kernel Pointer/ sampler state/bind table 使用如下图:
审核编辑:汤梓红
-
《CST Studio Suite 2024 GPU加速计算指南》2024-12-16 11958
-
Emulex Engine XE601 I/O控制器产品介绍2023-08-23 620
-
新版RT-Thread GUI Engine在哪?RT-Thread GUI Engine找不到2022-10-21 1428
-
Anchore Engine Docker镜像安全服务2022-05-07 706
-
camera_engine_rkisp和camera_engine_rkaiq的区别2022-03-24 6084
-
5种GPU虚拟化技术的详细资料讲解2021-02-08 10807
-
XS GPU系统产品介绍2021-02-01 1990
-
GPU服务器的详细介绍和工作原理说明2020-11-28 8585
-
新唐科技NANO120 IoT-Engine主板介绍2020-02-05 2110
-
Linux DMA Engine框架的介绍2018-11-23 7290
-
ArcGIS Runtime和ArcGIS Engine、ArcGIS Server的比较_arcgis desktop、arcgis engine和arcgis server三者之间有什么区别2018-01-16 6448
-
什么是强制gpu渲染_强制渲染gpu有什么用2018-01-05 9129
-
gpu_gpu是什么意思2011-12-21 12016
-
Map Service Engine Based On We2010-07-23 585
全部0条评论

快来发表一下你的评论吧 !
