

人工智能领域的梯度学习研究
人工智能
描述
图灵奖得主 Geoffrey Hinton 等研究者让前向梯度学习变得实用了。
我们知道,在人工智能领域里,反向传播是个最基本的概念。
反向传播(Backpropagation,BP)是一种与最优化方法(如梯度下降)结合使用的,用来训练人工神经网络的常见方法。该方法计算对网络中所有权重计算损失函数的梯度。这个梯度会反馈给最优化方法,用来更新权值以最小化损失函数。
简而言之,BP 的核心思路其实就是负反馈,我们试图用这种方式实现神经网络系统面对给定目标的自动迭代、校准。随着算力、数据和更多技术改进的提升,在 AI 领域人们使用反向传播训练的多层神经网络在部分任务上已经足以与人类竞争。
很多人把这项技术的发现归功于深度学习先驱、2019 年图灵奖得主 Geoffrey Hinton,但 Hinton 本人表示,自己的贡献在于明确提出了反向传播可以学习有趣的内部表征,并让这一想法推广开来:「我通过让神经网络学习词向量表征,使之基于之前词的向量表征预测序列中的下一个词实现了这一点。」
其例证在于 Nature 1986 年发表的论文《Learning representations by back-propagating errors》上。

无论如何,反向传播技术推动了现代深度学习的发展。但曾被冠以「反向传播之父」的 Geoffrey Hinton,近年来却经常表示自己在构思下一代神经网络,他对于反向传播「非常怀疑」,并提出「应该抛弃它并重新开始」。
可以说自 2017 年起,Hinton 就已开始寻找新的方向。机器之心先前曾介绍 Hinton 在前向 - 前向网络方面的思考(近万人围观 Hinton 最新演讲:前向 - 前向神经网络训练算法,论文已公开)。
最近,我们又看到了重要的进展。近日,由 Mengye Ren、Simon Kornblith、Renjie Liao、Geoffrey Hinton 完成的论文被工智能顶会 ICLR 2023 接收。
前向梯度学习通常用于计算含有噪声的方向梯度,是一种符合生物学机制、可替代反向传播的深度神经网络学习方法。然而,当要学习的参数量很大时,标准的前向梯度算法会出现较大的方差。
基于此,图灵奖得主 Geoffrey Hinton 等研究者提出了一系列新架构和算法改进,使得前向梯度学习对标准深度学习基准测试任务具有实用性。

论文链接:https://arxiv.org/abs/2210.03310
GitHub 链接:https://github.com/google-research/google-research/tree/master/local_forward_gradient
该研究表明,通过将扰动(perturbation)应用于激活而不是权重,可以显著减少前向梯度估计器的方差。研究团队通过引入大量局部贪心损失函数(每个损失函数只涉及少量可学习参数)和更适合局部学习的新架构 LocalMixer(受 MLPMixer 启发),进一步提高了前向梯度的可扩展性。该研究提出的方法在 MNIST 和 CIFAR-10 上与反向传播性能相当,并且明显优于之前 ImageNet 上的无反向传播算法。
当前,大多数深度神经网络都使用反向传播算法(Werbos, 1974; LeCun, 1985; Rumelhart et al., 1986)进行训练,该算法通过从损失函数向每一层反向传播误差信号来有效地计算权重参数的梯度。尽管人工神经网络最初受到生物神经元的启发,但反向传播一直被认为不符合生物学机理,因为大脑不会形成对称的反向连接或执行同步计算。从工程的角度讲,反向传播与大规模模型的并行性不兼容,并且限制了潜在的硬件设计。这些问题表明我们需要一种截然不同的深度网络学习算法。
Hinton 等研究者重新审视了权重扰动的替代方法 —— 活动扰动(activity perturbation,Le Cun et al., 1988; Widrow & Lehr, 1990; Fiete & Seung, 2006),探索了该方法对视觉任务训练的普遍适用性。
该研究表明:活动扰动能比权重扰动产生方差更低的梯度估计,并且能够为该研究提出的算法提供基于连续时间速率(continuous-time rate-based)的解释。
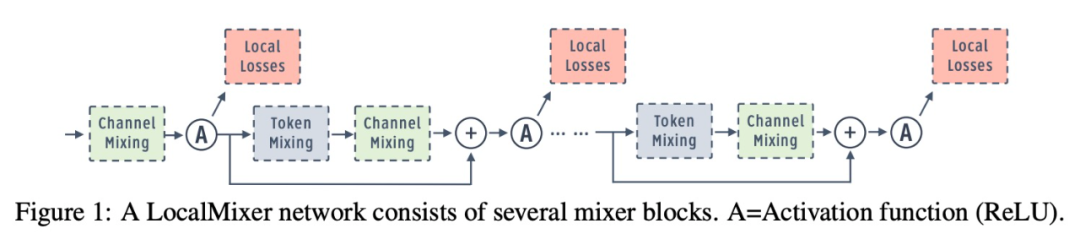
研究团队通过设计具有大量局部贪心损失函数的架构,解决了前向梯度学习的可扩展性问题,其中将网络隔离为局部模块,从而减少了每个损失函数的可学习参数量。与仅沿深度维度添加局部损失的先前工作不同,该研究发现 patch-wise 和 channel-group-wise 损失函数也非常关键。最后,受 MLPMixer (Tolstikhin et al., 2021) 的启发,该研究设计了一个名为 LocalMixer 的网络。LocalMixer 具有线性 token 混合层和分组通道(channel),以更好地与局部学习兼容。
该研究在监督和自监督图像分类问题上评估了其局部贪婪前向梯度算法。在 MNIST 和 CIFAR-10 上,该研究提出的学习算法性与反向传播性能相当,而在 ImageNet 上,其性能明显优于其他使用不对称前向和后向权重的方案。虽然该研究提出的算法在更大规模的问题上还达不到反向传播算法的性能,但局部损失函数设计可能是生物学上合理的学习算法,也将成为下一代模型并行计算的关键因素。
该研究分析了前向梯度估计器的期望和方差的特性,并将分析重点放在了权重矩阵的梯度上,具体的理论分析结果如下表 1 所示,批大小为 N 时,独立扰动(independent perturbation)可以将方差减少为 1/N,而共享扰动(shared perturbation)具有由平方梯度范数支配的常数方差项。然而,当执行独立的权重扰动时,矩阵乘法不能进行批处理,因为每个样本的激活向量都要与不同的权重矩阵相乘。相比之下,独立的活动扰动算法允许批量矩阵乘法。

与权重扰动相比,活动扰动的方差更小,因为扰动元素的数量是输出单元的数量,而不是整个权重矩阵的大小。活动扰动的唯一缺点是存储中间激活需要一定量的内存。
此外,该研究发现在具有 ReLU 激活的网络中,可以利用 ReLU 稀疏性来进一步减少方差,因为未激活的单元梯度为零,因此不应该扰动这些单元。
用局部损失函数进行扩展
由于扰动学习可能会遭受「维数灾难」:方差随着扰动维数的增加而增加,并且深度网络中通常有数百万个参数同时发生变化。限制可学习维度数量的一种方法是将网络划分为子模块,每个子模块都有一个单独的损失函数。因此,该研究通过增加局部损失函数的数量来抑制方差,具体包括:
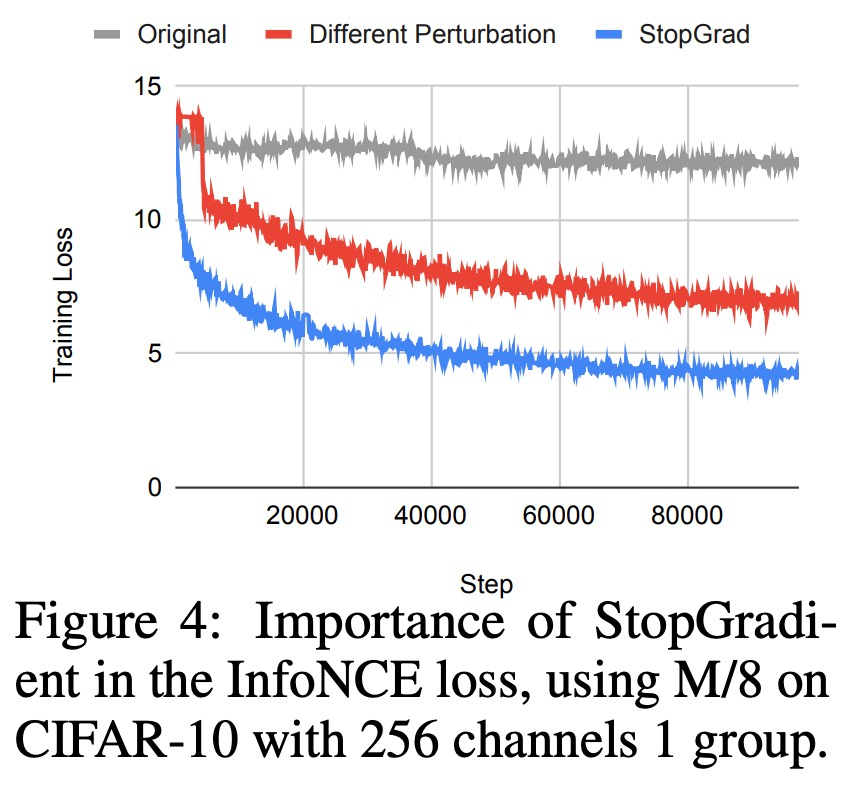
1)Blockwise 损失。首先,该研究将网络深度划分为多个模块。每个模块由几个层组成,在每个模块的末端计算一个损失函数,该损失函数用于更新该模块中的参数。这种方法相当于在模块之间添加了一个「停止梯度(stop gradient)」算子,Belilovsky et al. (2019) 和 Löwe et al. (2019) 曾探索过这种局部贪心损失函数。
2)patchwise 损失。图像等感官输入信号具有空间维度。该研究沿着这些空间维度,逐块应用单独的损失。在 Vision Transformer 架构中(Vaswani et al., 2017; Dosovitskiy et al., 2021),每个空间标记代表图像中的一个 patch。在现代深度网络中,每个空间位置的参数通常是共享的,以提高数据效率并降低内存带宽利用率。虽然简单的权重共享在生物学上是不合理的,但该研究仍然在这项工作中考虑共享权重。通过在 patch 之间添加知识蒸馏 (Hinton et al., 2015) 损失来模拟权重共享的效果是可能的。
3) Groupwise 损失。最后,该研究转向通道(channel)维度。为了创建多个损失,该研究将通道分成多个组,每个组都附加到一个损失函数(Patel et al., 2022)。为了防止组之间相互通信,通道仅连接同一组内的其他通道。
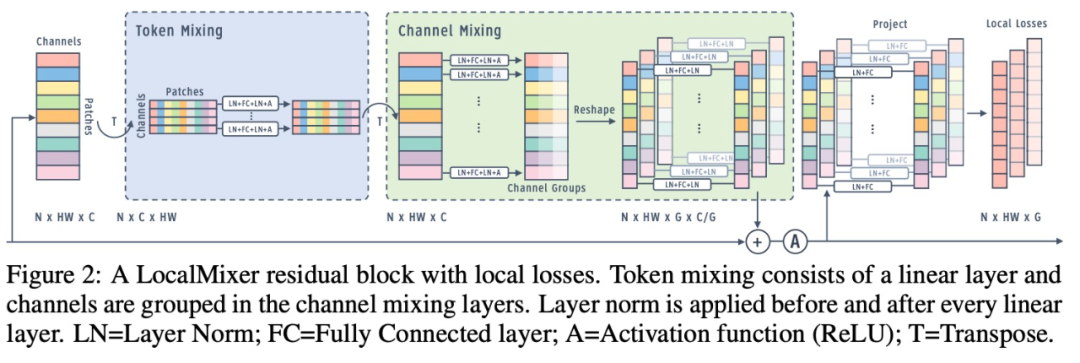
具有局部损失的 LocalMixer 残差块。
特征聚合器
简单地将损失分别应用于空间和通道维度,会带来次优性能,因为每个维度仅包含局部信息。对于分类等标准任务的损失,模型需要输入的全局视图来做出决策。标准架构通过在最终分类层之前执行全局平均池化层,来获得此全局视图。因此,该研究探索了在局部损失函数之前聚合来自其他组和空间块的信息的策略。
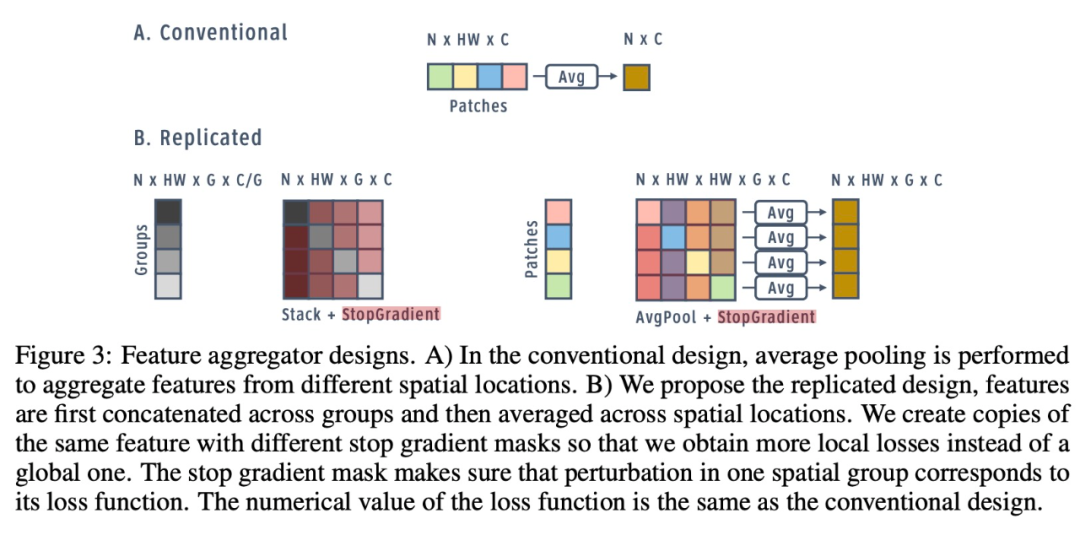
特征聚合器设计。
实现
网络架构:该研究提出了更适合局部学习的 LocalMixer 架构。它的灵感来自 MLPMixer (Tolstikhin et al., 2021),它由全连接网络和残差块组成。该研究利用全连接网络,使每个空间块在不干扰其他 patch 的情况下执行计算,这更符合局部学习目标。图 1 显示了高级架构,图 2 显示了一个残差块的详细图。
归一化。在跨不同张量维度的神经网络中执行归一化的方法有很多种(Krizhevsky et al., 2012; Ioffe & Szegedy, 2015; Ba et al., 2016; Ren et al., 2017; Wu & He, 2018)。该研究选择了层归一化的局部变体,它在每个局部空间特征块内进行归一化(Ren et al., 2017)。对于分组的线性层,每组单独进行归一化(Wu & He, 2018)。
该研究通过实验发现这种局部归一化在对比学习中表现更好,并且与监督学习中的层归一化大致相同。局部归一化在生物学上也更合理,因为它不执行全局通信。
通常,归一化层放置在线性层之后。在 MLPMixer(Tolstikhin et al., 2021)中,层归一化被放置在每个残差块的开头。该研究发现最好在每个线性层之前和之后放置归一化,如图 2 所示。实验结果表明,这种设计选择对反向传播没有太大影响,但它允许前向梯度学习更快地学习并实现更低的训练错误。
有效实施复制损失。由于特征聚合和复制损失的设计,组(groups)的简单实现在内存消耗和计算方面可能非常低效。然而,每个空间组实际上计算相同的聚合特征和损失函数。这意味着在执行反向传播和正向梯度时,可以跨损失函数共享大部分计算。该研究实现了自定义 JAX JVP/VJP 函数(Bradbury et al., 2018)并观察到显著的内存节省和复制损失的计算速度提升,否则这在现代硬件上运行是不可行的,结果如下图所示。
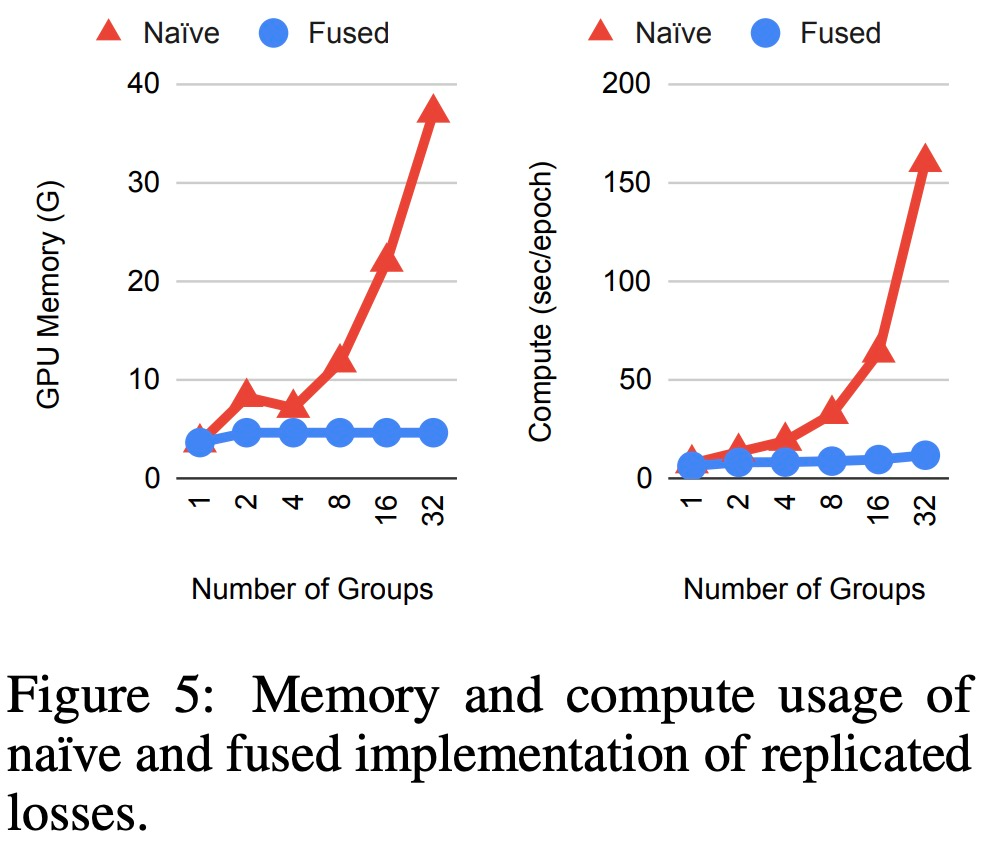
复制损失的简单和融合实现时,内存和计算使用情况。
实验
该研究将提出的算法与包括反向传播、反馈对齐和其他前向梯度全局变体在内的替代方案进行比较。反向传播是生物学上难以置信的神谕,因为它计算的是真实梯度,而该方法计算的是噪声梯度。反馈对齐通过使用一组随机向后权重来计算近似梯度。
各项实验的结果如下:
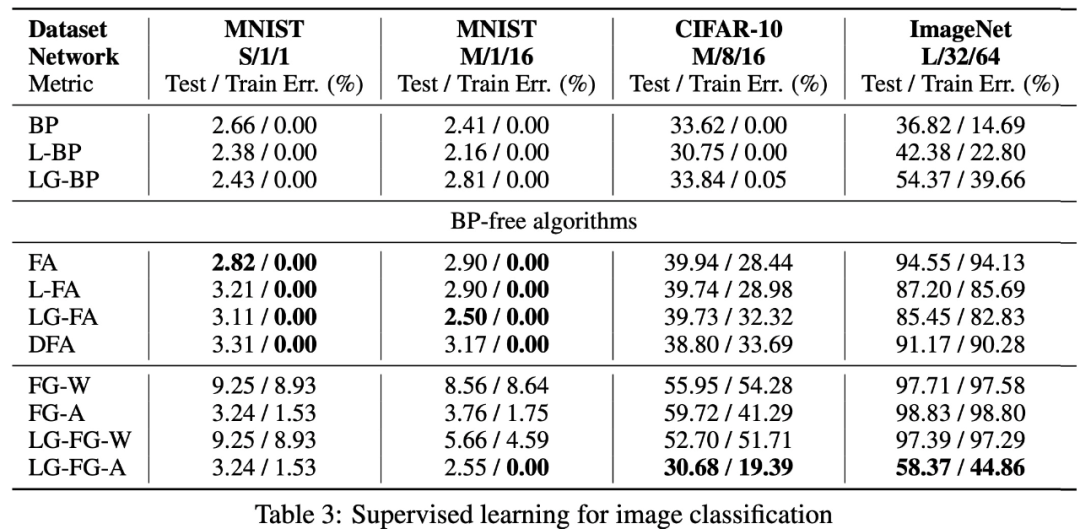
图像分类自监督学习。
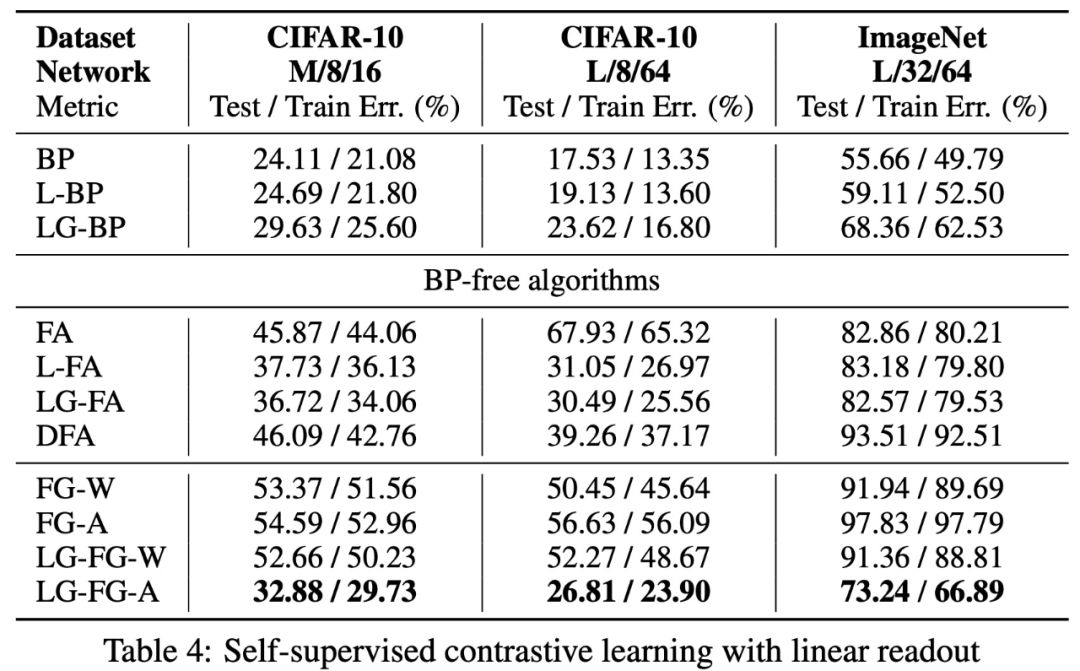
有线性 readout 的自监督对比学习。
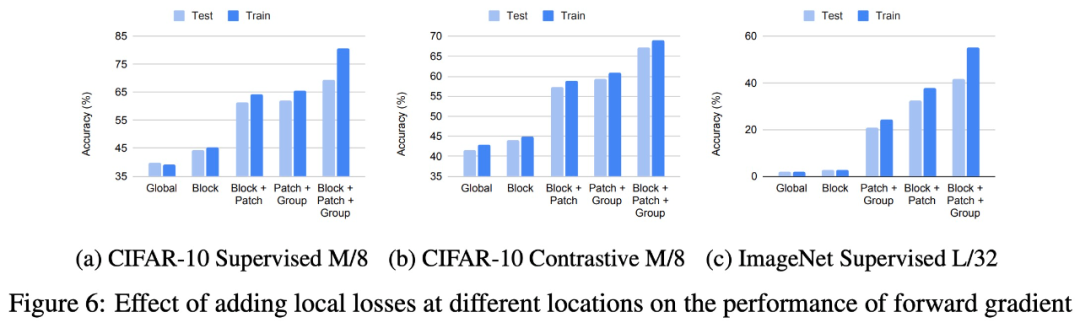
在不同位置添加局部损失对前向梯度性能的影响。
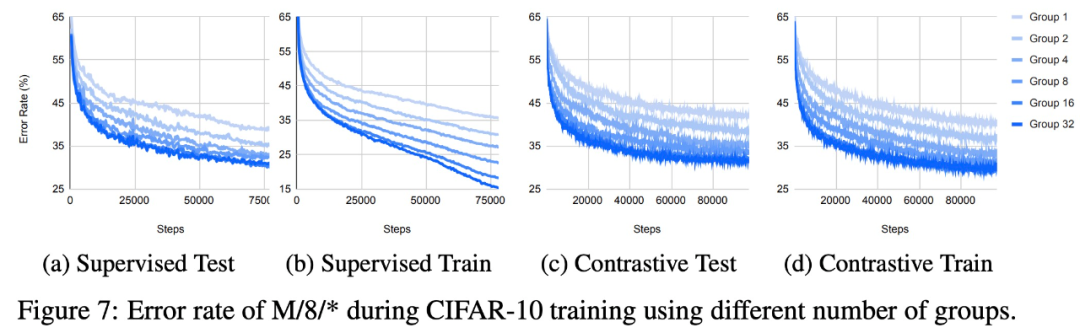
使用不同数量组时,在 CIFAR-10 上训练时 M/8/* 的错误率。
总结
人们通常认为基于扰动的学习无法扩展到大型深度网络。该研究表明,这在某种程度上是正确的,因为梯度估计方差随着扰动隐藏维度的数量而增长,并且对共享权重扰动而言甚至更遭。
但乐观的是,该研究表明大量的局部贪心损失可以帮助更好地推进梯度学习规模,探索了 blockwise、patchwise 以及 groupwise 以及这三者组合的局部损失,在一个较大的网络中总共有四分之一的损失,表现最好。局部活动扰动前向梯度在更大的网络上比以前的无反向传播算法表现更好。局部损失的想法为不同的损失设计开辟了机会,并阐明了如何在大脑和替代计算设备中寻找生物学上合理的学习算法。
编辑:黄飞
-
《AI for Science:人工智能驱动科学创新》第一章人工智能驱动的科学创新学习心得2024-10-14 1745
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2386
-
什么是人工智能、机器学习、深度学习和自然语言处理?2022-03-22 4713
-
物联网人工智能是什么?2021-09-09 5355
-
中国人工智能的现状与未来2021-07-27 6732
-
人工智能在英语教育领域2020-12-14 2424
-
人工智能的应用领域有哪些?2020-10-23 5156
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5903
-
初学AI人工智能需要哪些技术?这几本书为你解答2019-01-21 9784
-
人工智能和机器学习的前世今生2018-08-27 3601
-
人工智能就业前景2018-03-29 8434
-
从入门到研究,人工智能领域最值得一读的10本资料(附下载)2017-10-12 7868
-
菜鸟如何学习人工智能2016-06-03 11785
-
人工智能是什么?2015-09-16 6449
全部0条评论

快来发表一下你的评论吧 !
