

什么是RoCE?如何实现RoCE?
电子说
描述
RoCE全称RDMA over Converged Ethernet,是基于融合以太网的RDMA,那什么是RDMA?在了解RoCE之前先了解下RDMA技术。
1 、什么是 RDMA ?
RDMA(Remote Direct Memory Access), 全称远程内存直接访问技术,是一种数据传输技术。 允许在计算机之间实现高性能、低延迟、高吞吐量的数据传输,由网络适配器直接处理主机内存之间的数据传输,以大大减少了CPU在数据传输过程中的参与**(即从一个主机或服务器的内存直接访问另一个主机或服务器的内存,这个过程无需使用** CPU )。 RDMA最早在Infiniband传输网络上实现,技术先进,但是价格高昂(只有Mellanox和Intel供应商提供全套网络解决方案),后来业界厂家把RDMA移植到传统Ethernet以太网上,降低了RDMA的使用成本,推动了RDMA技术普及。
我们知道,传统应用要发送数据,需要通过OS封装TCP/IP,然后依次经过主缓存、网卡缓存,再发出去。这个过程存在2个限制:1)TCP/IP协议栈处理会带来数10微秒的 时延 。TCP协议栈在接收发送报文时,内核需要做多次上下文的切换,每次切换需要耗费5-10微秒。另外还需要至少三次的数据拷贝和依赖CPU进行协议工作,这导致仅仅协议上处理就会带来数10微秒的固定时延,协议栈时延成为最明显的瓶颈。;2)TCP协议栈处理导致服务器CPU负载居高不下。除了固定时延较长的问题,TCP/IP网络需要主机CPU多次参与协议的内存拷贝,网络规模越大,网络带宽越高,CPU在收发数据时的调度负担越大,导致CPU 持续高负载 。
在数据中心内部,超大规模分布式计算存储资源之间,如果使用传统的TCP/IP进行网络互连,将占用系统大量的计算资源,造成****IO 瓶颈,无法满足更高吞吐,更低时延的网络需求。 RDMA****是一种高带宽、低延迟、低CPU消耗的网络互联技术,克服了传统TCP/IP网络的高时延、高CPU负载等困难。
为了更形象的理解RDMA和TCP技术的区别。传统的TCP/IP方式,可比作为人工收费一样需要取卡,人工核实,手动缴费,找零钱等等才能完成汽车上下高速。在车辆很多的情况下就会出现排队的情况,很浪费时间。而RDMA则像是 ETC ,跳过人工取卡,收费等步骤,直接刷卡,极速通过。既节省了时间,又节省了人力。
RDMA相比TCP/IP,既降低了对计算资源的占用,又提升了数据的传输速率。RDMA的内核旁路机制允许应用与网卡之间的直接数据读写,这样可以将服务器内的数据传输时延降低到接近1微秒。同时,RDMA的内存零拷贝机制允许接收端直接从发送端的内存读取数据,极大地减少了CPU的负担,提高了CPU的利用率。使用RDMA的好处包括:
1 )内存零拷贝( Zero Copy ) :RDMA应用程序可以绕过内核网络栈直接进行数据传输,不需要再将数据从应用程序的用户态内存空间拷贝到内核网络栈内存空间。
2 )内核旁路( Kernel bypass ) :RDMA应用程序可以直接在用户态发起数据传输,不需要在内核态与用户态之间做上下文切换。
3 ) CPU 减负( CPU offload ) :RDMA可以直接访问远程主机内存,不需要消耗远程主机中的任何CPU,这样远端主机的CPU可以专注自己的业务,避免其cache被干扰并充满大量被访问的内存内容。
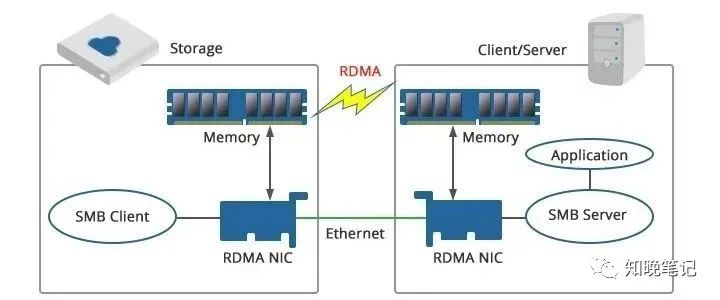
例如上图,使用RDMA可以简单理解为利用相关的硬件和网络技术,服务器1的网卡可以直接读写服务器2的内存,最终达到高带宽、低延迟和低资源利用率的效果。因此,RDMA可以简单理解为利用相关的硬件和网络技术,服务器的 网卡之间可以直接读内存 ,最终达到高带宽、低延迟和低资源利用率的效果。应用程序不需要参与数据传输过程,只需要指定内存读写地址,开启传输并等待传输完成即可
2 、什么是 RoCE ?
RoCE全称是RDMA over Converged Ethernet(以太网上的RDMA),是在InfiniBand Trade Association(IBTA)标准中定义的网络协议,允许通过以太网络使用 RDMA 。即****RoCE 允许在以太网上实现高性能、低延迟、高吞吐量的数据传输,不需要使用特殊的网络硬件设备,只需要通过标准化的以太网设备就可以实现,大大降低了成本 (可以通过支持RDMA的以太网适配器和交换机实现高性能、低延迟、高吞吐量的数据传输,无需在传输过程中频繁地进行CPU参与)。RoCE技术遵循与InfinBand相同的传输机制,允许网络适配器直接访问主机内存,从而大大降低了延迟,并提高了吞吐量。
目前, 大致有三类RDMA网络,分别是Infiniband(IB),internet Wide Area RDMA Protocol(iWARP)和RDMA over Converged Ethernet(RoCE) 。其中,Infiniband是一种专为RDMA设计的网络,从硬件级别保证可靠传输 ,而RoCE 和 iWARP都是基于以太网的RDMA技术,支持相应的verbs接口。如下:
- InfiniBand:设计之初就考虑了 RDMA,重新设计了物理链路层、网络层、传输层,从硬件级别,保证可靠传输,提供更高的带宽和更低的时延。但是成本高,需要支持IB网卡和交换机。
- iWARP:基于TCP的RDMA网络,利用TCP达到可靠传输。相比RoCE,在大型组网的情况下,iWARP的大量TCP连接会占用大量的内存资源,对系统规格要求更高。可以使用普通的以太网交换机,但是需要支持iWARP的网卡。
- RoCE:基于 Ethernet的RDMA,RoCEv1版本基于网络链路层,无法跨网段,基本无应用。RoCEv2基于UDP,可以跨网段具有良好的扩展性,而且可以做到吞吐,时延相对性能较好,所以是大规模被采用的方案。RoCE消耗的资源比 iWARP 少,支持的特性比 iWARP 多。可以使用普通的以太网交换机,避免了使用高成本的Infiniband网络设备,可以降低成本,但是需要支持RoCE的网卡。

RoCE协议存在RoCEv1和RoCEv2两个版本,这取决于所使用的网络适配器或网卡。从 2010 年开始,RMDA 开始引起越来越多的关注,当时IBTA发布了第一个在融合以太网 (RoCE) 上运行 RMDA 的规范。然而,最初的规范将 RoCE 部署限制在单个第 2 层域,因为 RoCE 封装帧没有路由功能。2014 年,IBTA 发布了 RoCEv2,它更新了最初的 RoCE 规范以支持跨第 3 层网络的路由,使其更适合超大规模数据中心网络和企业数据中心等。
RoCEv1
2010年4月,IBTA发布了RoCE,此标准是作为Infiniband Architecture Specification的附加件发布的,所以也称为IBoE(InfiniBand over Ethernet)。这时的RoCE标准是在以太链路层之上用IB网络层代替了TCP/IP网络层,所以不支持IP路由功能。RoCE V1协议在以太层的typeID是0x8915。
在RoCE中,infiniband的链路层协议头被去掉,用来表示地址的GUID被转换成以太网的MAC。Infiniband依赖于无损的物理传输,RoCE也同样依赖于无损的以太传输,这一要求会给以太网的部署带来了成本和管理上的开销。
以太网的无损传输必须依靠L2的QoS支持,比如PFC(Priority Flow Control),接收端在buffer池超过阈值时会向发送方发出pause帧,发送方MAC层在收到pause帧后,自动降低发送速率。这一要求,意味着整个传输环节上的所有节点包括end、switch、router,都必须全部支持L2 QoS,否则链路上的PFC就不能在两端发挥有效作用。
RoCEv2
由于RoCEv1的数据帧不带IP头部,所以只能在L2子网内通信。为了解决此问题,IBTA于2014年提出了RoCE V2,RoCEv2扩展了RoCEv1,通过改变数据包封装,将GRH(Global Routing Header)换成UDP header + IP header,RoCE v2现在可以跨L2和L3网络使用。
针对RoCE v1和RoCE v2,以下两点值得注意:
- RoCE v1(Layer 2)运作在Ehternet Link Layer(Layer 2)所以Ethertype 0x8915,所以正常的Frame大小为1500 bytes,而Jumbo Frame则是9000 bytes。
- RoCE v2(Layer 3)运作在UDP/IPv4或UDP/IPv6之上(Layer 3),采用UDP Port 4791进行传输。因为 RoCE v2的封包是在 Layer 3上可进行路由,所以有时又会称为Routable RoCE或简称RRoCE。
RoCE,无损先行
由于RDMA要求承载网络无丢包,否则效率就会急剧下降,所以RoCE技术如果选用以太网进行承载,就需要通过PFC,ECN以及DCQCN等技术对传统以太网络改造,打造无损以太网络,以确保零丢包。
PFC:基于优先级的流量控制。PFC为多种类型的流量提供基于每跳优先级的流量控制。设备在转发报文时,通过在优先级映射表中查找报文的优先级,将报文分配到队列中进行调度和转发。当802.1p优先级报文的发送速率超过接收速率且接收端的数据缓存空间不足时,接收端向发送端发送PFC暂停帧。当发送端收到 PFC 暂停帧时,发送端停止发送具有指定 802.1p 优先级的报文,直到发送端收到 PFC XON 帧或老化定时器超时。配置PFC时,特定类型报文的拥塞不影响其他类型报文的正常转发,
ECN:显式拥塞通知。ECN 定义了基于 IP 层和传输层的流量控制和端到端拥塞通知机制。当设备拥塞时,ECN 会在数据包的 IP 头中标记 ECN 字段。接收端发送拥塞通知包(CNP)通知发送端放慢发送速度。ECN 实现端到端的拥塞管理,减少拥塞的扩散和加剧。
DCQCN(Data Center Quantized Congestion Notification):目前在RoCEv2网络种使用最广泛的拥塞控制算法。融合了QCN算法和DCTCP算法,需要数据中心交换机支持WRED和ECN。DCQCN可以提供较好的公平性,实现高带宽利用率,保证低的队列缓存占用率和较少的队列缓存抖动情况。
为什么RoCE是目前主流的RDMA协议?
RDMA最早在Infiniband传输网络上实现,技术先进,但是价格高昂,后来业界厂家把RDMA移植到传统Ethernet以太网上,降低了RDMA的使用成本,推动了RDMA技术普及。在Ethernet以太网上,根据协议栈融合度的差异,分为iWARP和RoCE两种技术,而RoCE又包括RoCEv1和RoCEv2 两个版本 (RoCEv2的最大改进是支持IP 路由 ) ,各RDMA网络协议栈的对比如下图所示。
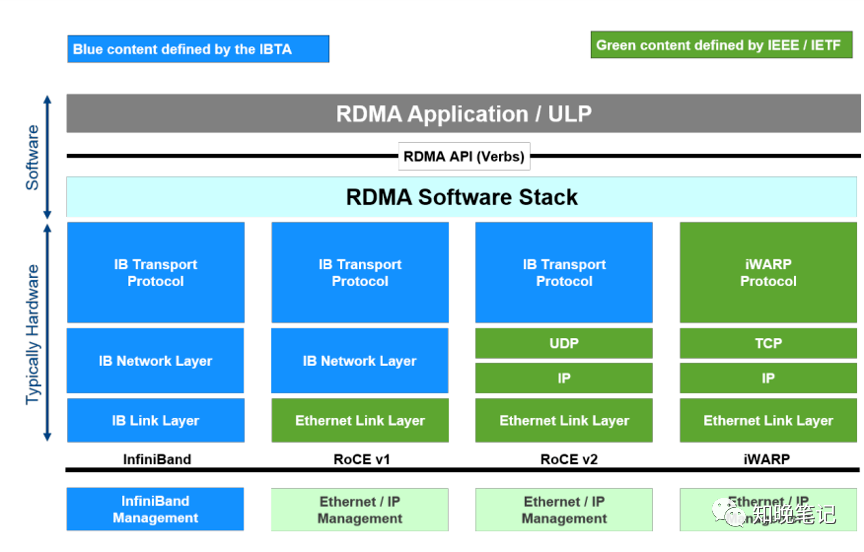
1)iWARP,iWARP协议栈相比其他两者更为复杂,并且由于TCP的限制,只能支持可靠传输。所以iWARP的发展不如RoCE和Infiniband。
2)Infiniband协议本身定义了一套全新的层次架构,从链路层到传输层,都无法与现有的以太网设备兼容。举例来看,如果某个数据中心因为性能瓶颈,想要把数据交换方式从以太网切换到Infiniband技术,那么需要购买全套的Infiniband设备,包括网卡、线缆、交换机和路由器等等,成本太高
3)RoCE协议的优势在这里就很明显了,用户从以太网切换到RoCE只需要购买支持RoCE 的网卡就可以了 ( 只需网卡是支持 RoCE ),其他网络设备都是兼容的。所以RoCE相比于Infiniband****主要优势在于成本更低。
3 、如何实现 RoCE ?
实现RoCE,可以安装支持****RoCE 的网卡或卡驱动程序 。所有以太网NIC都需要RoCE网络适配器卡。RoCE驱动程序在Red Hat、Linux、Microsoft Windows和其他常见操作系统中使用。RoCE有两种可用方式:对于网络交换机,可以选择使用支持PFC(优先流控制)操作系统的交换机;对于机架服务器或主机,需要使用网卡。使用RoCE的好处:
1)低CPU占用率:访问远程交换机或服务器的内存,无需消耗远程服务器上的CPU周期,从而可以充分利用可用带宽和更高的可伸缩性。
2)零复制:向远程缓冲区发送数据和接收数据。
3)高效:由于RoCE改善了延迟和吞吐量,网络性能得到了很大提高。
4)节省成本:借助RoCE,无需购买新设备或更换以太网基础设施即可处理大量数据,从而大大节省了公司的资本支出。使用IB必须是支持IB的一整套设备。
-
RDMA设计44:RoCE v2原语功能验证与分析2026-02-25 558
-
RDMA设计37:RoCE v2 子系统模型设计2026-02-06 2392
-
RDMA设计29:RoCE v2 发送及接收模块设计22026-01-26 944
-
RDMA设计28:RoCE v2 发送及接收模块设计2026-01-25 893
-
RDMA设计19:RoCE v2 发送及接收模块设计2026-01-06 2682
-
RDMA设计5:RoCE V2 IP架构2025-11-25 920
-
如何实现高效的RoCE网卡状态采集与监控?2025-10-29 1376
-
如何实现 RoCE 配置的自动同步(基础篇) - DCBX协议2025-10-09 1342
-
RoCE与IB对比分析(一):协议栈层级篇2024-11-15 4120
-
深度解读RoCE v2的核心技术原理2024-04-29 8733
-
RoCE Linux版本说明2023-07-31 567
-
Linux RoCE发行说明2023-07-28 459
-
什么是RDMA?什么是RoCE网络技术?2023-07-24 9942
-
在ZTR无配置大规模中实现的缩放零接触RoCE技术2022-04-14 4688
全部0条评论

快来发表一下你的评论吧 !
