

生成式人工智能革命已经开始
电子说
描述
人工智能的发展总让人有种似曾相识的感觉。计算机每隔几年便能一夜之间学会新能力。“看哪!”AI 真正的信徒宣告,“人工智能的时代即将到来!”“胡说八道!”怀疑论者说,“你忘了自动驾驶的汽车了吗?”
真相通常介于这两者之间。
我们身处另一轮循环之中,这次的主角是生成式 AI。媒体头条被 AI 艺术霸占了版面,但很多其他的领域也取得了前所未有的进展。无论是视频、生物、编程、写作、翻译等等一切,都见证了人工智能令人难以置信的发展速度。
为什么会是现在?
或许你对 AI 领域近期的新鲜事并不陌生,无论是获奖的艺术作品、对已死之人的采访,还是蛋白质折叠的突破性进展。这些新出的 AI 系统不再是研究实验室里新奇演示,而是在被迅速转化为人人可用的实际工具和真正的商业产品。
这一切同时出现的不是没有原因的,种种突破性发展背后都是由新一代更灵活、强大的 AI 模型所支持。这类模型最初被应用于回答问题或者撰写文章,因此得名“大型语言模型(LLM)”,OpenAI 的 GPT3、谷歌的 BERT 等等模型都属于 LLM。这些极其灵活且适应性强的模型同样在计算机视觉和生物学领域非常有用,因此部分研究者也更习惯用“基础模型”称呼它们,更好地表达了这些模型在当代人工智能领域中的作用。
这些基础模型又是从何而来?又是怎么突破语言的束缚、推动了我们如今所见的人工智能领域进展?
基础模型的基础
机器学习中有一个牢靠的铁三角:模型、数据、计算。模型是接受输入并产生输出的算法。数据是供给算法训练用的例子。机器的学习过程中必须有大量丰富的数据才能让算法输出一些有用的内容;模型必须足够灵活才能捕捉数据的复杂性;计算能力必须足够强大才能运行这些算法。
当代第一次人工智能的变革来自 2021 年利用卷积神经网络(CNN)解决计算机视觉问题的深度学习。CNN 的结构类似于大脑的视觉皮层,这一技术自 20 世纪 90 年代起便已存在,但由于对计算能力的极高要求一直没能实际投入使用。
2006 年英伟达发布的编程语言 CUDA 允许将 GPU 作为通用超级计算机使用;2009 年斯坦福大学 AI 研究者们推出了使用带标签图像训练计算机视觉的算法 Imagenet;2021 年推出了使用 Imagenet 数据集、在 GPU 上结合 CNN 训练的 AlexNet,创造了史上最优视觉分类器。深度学习与人工智能自此进入了井喷式的发展时代。
CNN、ImageNet 数据集、GPU,这个神奇的组合开拓了计算机视觉领域的巨大进步。2012 年围绕深度学习所掀起的热潮很快催生了包括自动驾驶在内的一大行业类别。但我们很快也发现了,这一代的深度学习是有局限性的。CNN 对于计算机视觉来说非常优秀,但其他领域的模型却没有突破性进展,让计算机理解并使用正常人类语言而非代码的自然语言处理(NLP)领域便是其中之一。
语言的理解与处理和图像有着根本性的不同。语言的处理中一系列词语的顺序非常重要,“这名读者正在学习 AI”和“AI 正在学习这名读者”这两句话的意思完全相反,但猫不管在图像中的什么位置都是猫。
直至最近,研究者们都是靠着循环神经网络(RNN)、长短期记忆(LSTM)等模型进行及时的数据分析处理。这类模型虽然擅长识别短句中词汇等简短序列,却苦于应对长句子或文章段落,记忆能力不够成熟的模型尚不能捕捉到语句在连成段落乃至文章后,所带来的复杂且丰富的思想和概念。对 Siri 或 Alexa 之类的语音助手而言或许很好,但其他方面就不太行了。
找到合适的训练数据也是件难事。拥有十万张标记图像的 ImageNet 数据集背后是大量的人力劳动,主要由研究生和亚马逊土耳其机器人(Mechanical Turk)平台上的工作人员完成。ImageNet 受另一项更为早期英文词汇标记数据集 WordNet 所启发,并以其为基础构建。互联网上虽然不缺文本,但搭建一个能让计算机学会处理人类语言而不是单个字词的数据集非常费时。更何况在同样数据上为 A 应用程序打好的标签不一定能适用于 B 任务。

WordNet 中的数据示例,背后都是大量的人力劳动
我们要做的事有两件:第一,能在未标记的数据上训练,即数据不再需要人工标记其具体的信息;第二,能真正地处理海量文本和数据,像卷积网络模型一样充分利用 GPU 与并行计算领域的突破性进展。做到这两点后,我们就能超越限制 RNN 与 LSTM 模型的句子级别语言处理。
换句话说,计算机视觉的大突破是数据和算力追赶上了已有的模型,自然语言领域的人工智能则是背靠已有的算力和数据,等待新的模型。
翻译是你所需要的一切
谷歌的“转换器(Transformer)”模型为我们带来了突破性的进展,谷歌的研究者们所关注的自然语言问题非常具体:如何翻译。翻译并不简单,词序的重要性不言而喻,而语言不同词序也会不同。举例来说,日语中动词会跟在接收动作的对象后面,英语中的“前辈关注你”到了日语就成了“前辈你关注”,国际足球协会缩写是“FIFA”而不是“IAFF”则要归功于法语词序。
要想学会处理这类问题,AI 模型需要灵活处理词序问题。先前的 LSTM 和 RNN 模型是将词序隐含在了模型之中,处理一连串字词意味着要将其按序输入模型,模型先看到的字词自然排在第一位。但对转换器而言,每个字词都被分配了一个数字,转换器模型以数字形式处理词序,这个数字被称做“位置编码”。举例来说,“我爱 AI,我想 AI 爱我”这句话在模型看来类似这样:(我 1)(爱 2)(AI 3)(,4)(我 5)(想 6)(AI 7)(爱 8)(我 9)。
位置编码的使用是第一次突破,第二次则是来自一个叫“多头注意力(Multi-head Attention)”的东西。在接受了一连串的字词输入后,模型的设计让它不仅能严格按照输入的词序输出,还能向前或向后查看输入序列(注意力)、输入序列的不同部分(多头),找出与输出最为相关的部分。
转换器模型能够在按序接收输入后吐出一个个字词,将语言的翻译高效地转变为字词的矢量表达,或者说是矩阵的表示,允许模型查看整体输入序列从而确定哪些是与输出有关联的。

转换器处理翻译问题的示例。
转换器可谓是翻译领域的突破,而这一发明也解决诸多语言问题的正确模型。
转换器可同时批量处理大量字词,非常适合用在 GPU 上。此外,作为一款接收有序符号输入、吐出另一个有序输出的模型,转化器可以将一串单词(准确来说是单词的片段,“标记(token)”)转化为另一种语言的单词。
翻译不需要对数据进行标记。我们只用喂给计算机一种语言的输入文本,就能得到另一种语言的输出,我们甚至还可以训练模型完形填空的能力,猜测特定文本序列的输入之后会出现什么,从而让模型无需明确标签就可学习各种模式。
当然输入不一定得是英语,输出也不局限于日语。我们甚至可以让模型把英语翻译成英语!比如,将长篇文章总结成简单几个段落、判断客户对产品的反馈是正面还是负面、将一段故事梗概扩写成一篇引人入胜的文章……许多常用的 AI 语言任务从本质上来说都是将一串英语翻译成另一段英语,
因此,语言模型领域的重大突破实际上是开发一个超赞的模型,然后想尽办法将一般语言任务转换为翻译问题。
我们目前有了一个能做两件大事的 AI 模型,第一件大事是能进行完形填空,意味着我们不用再标记所有的训练数据;第二件大事则是可以将大段文字乃至一整本书放到模型中运行。
我们也不用再告诉模型这段文字讲的是哈利·波特,那段文字讲的是赫敏,也不用再告诉模型哈利·波特是男孩,赫敏是女孩,然后再定义什么是男什么是女。我们只用把原文中“哈利”、“赫敏”、“他”、“她”这类字词挖掉后,再训练模型填补空白,在纠错的过程中 AI 不仅能学会哪段文字提到了哪个角色,还能学会如何匹配一般的名词和对象。再加上我们是在 GPU 中运行的数据,我们还能将模型规模扩大,从而处理更长的文本段落。
终于有了一款能让我们充分利用互联网上大量非结构性数据以及 GPU 的模型,OpenAI 通过 GPT-2 以及随后的 GPT-3 推动了这项进展,GPT 是“生成性预训练转化器(generative pre-trained transformer)”的缩写。“生成性”意指明确,模型被设计为能吐出与输入不同的新词语,“预训练”则是指在大量文本上以完形填空的模式进行训练。
OpenAI 于 2019 年发布了 GPT-2,这是一种可以在一篇文章中生成极其类似人类语句的模型,其所生成文本的上下文也是计算机生成文本领域从未有过的一致性。GPT-2 就好像是疯狂科学家搞出的机器,只需谨慎地喂给它一系列文本(又称“提示”),我们就能拿到相关的文字输出。看起来很不错,但文字上下文的一致性很快便随着文本量的增加而消失殆尽,再加上这些所谓的“提示”又很像是 Alta Vista 年代的搜索查询,灵活性非常有限。
更大的突破来自于 2020 年 GPT-2 到 GPT-3 的飞跃。GPT-2 中约 15 亿的参数数量能轻易存储在消费类显卡的内存中,GPT-3 的规模则要大上百倍有余,最大的表现形式拥有 1750 亿个参数,GPT-3 的能力也更强,它甚至可以完整写出一篇几乎与人类写作无异的文章。
强者处处是惊喜,OpenAI 的研究者们发现扩大模型的规模后,模型不仅在文本生成方面更为优秀,还能根据新的训练数据学会全新的行为。也就是说,研究人员发现 GPT-3 可以无需明确的模型设计,直接用英语白话指令训练。
训练特定、单一的模型来总结文章段落或用某种风格重写文章已经成了过去式,GPT-3 中一句请求就能做到这些。输入“总结下面这段文字”,GPT-3 就会照做;“按照海明威的风格重写这段文字”,GPT-3 就能将一段冗长的文字去其糟粕只留精华。
GPT-3 不是用途单一的语言工具,而是能方便更多不具备编程或其他计算机知识的人轻松使用的多用途语言工具。同等重要的是,GPT-3 的命令学习能力是自发的,而不是在代码中明确设计的,这款在训练中成型的语言模型为更多应用场景打开了大门。
这些发现都很神奇,很快转换器模型也被渐渐应用至除语言外的其他领域学科。
超越语言的范畴:Dall-E、 Stable Diffusion 以及更多
就在 2014 年,技术相关领域的大贤者 XKCD 发布了这则漫画:

用户拍照时,应用该检查他们是不是在国家公园里……好说,就是简单的地理信息检查,给我几小时就能搞定。
……并确认照片里是不是有只鸟。
那我得花五年时间先研究下。
不到一年后,计算机就已经从不知“鸟”为何物发展成了……这个样子:

为什么会发展得这么快?
我们已经了解了这一切的起源,无论是 ImageNet、AlexNet、GPU,还是深度学习的变革,这种模型、数据和算力的结合为我们带来了一套极为强大的可用来处理图像的工具。
在深度学习出现之前,计算机视觉的发展一直很艰难。人类识别一张面孔的方式通常由下面几步组成:大脑寻找类似眼睛和嘴的形状,判断这些形状是否能组成面部。
计算机视觉的研究曾一度试图让计算机复现人脑识别面部的过程,努力寻找正确的组件和模式(即“特征”),再尝试寻找能让这些组成规律的方式。我个人最喜欢的一个例子是 Viola-Jones 的人脸识别器,工作原理是借助大脑门和鼻子的 T 字型,再加上下面两个阴影区域所组成的人脸模式。
深度学习的出现改变了这一切。研究者们不再需要手动创建使用图片特征,AI 模型不仅能自学特征,还知道这些特征是怎么结合组成的人脸、汽车、动物之类。同语言类似,模型不过是学会了视觉的“语言”,组成基础模块的“词汇”是线条、形状和模式,这一切通过规则组成了更为高层的网络,即“语法”。坐拥海量数据的深度学习模型能比任何人类研究者都做得更好。
这是非常强大的,计算机拥有了一种可扩展的图像学习方式。可这还是不够,这些模型还只是单向的,只能学着把像素块映射到对应的物体分类桶中,“这些像素表示一只猫、那些像素表示一只狗”,逆向的分类还不可行。就好像是牢记了家畜短语和词汇的游客一样,没有真正理解如何将两种语言互相翻译。
读者们或许已经看到我们要发展的方向。
转换器是作为翻译机而发明的,它可以从英语翻译到法语、从英语翻译到英语、从猪拉丁翻译到英语……但这些语言也不过是有序的符号序列而已,而翻译则是简单地将一套有序序列映射到另一组而已。转换器是可以找出一种语言的规则并映射到另一种语言的通用工具,如果其他应用中有类似语言的表达形式,那么我们自然可以训练转换器模型在其间进行翻译。
这也是图像应用中的原理,还记得前面我们提过深度学习是如何找到图像中“语言”的表达形式吗?一款深度学习模型可以学习图像中所谓的“隐空间”表示,并将图像中重要的特征抽取压缩至更低维度的表达,即“隐空间”或“隐层表达”。
隐层表达将特定分辨率下所有可能的图像都压缩至一个非常低的维度中,类似与模型在学习海量的基础形状、线条、图案,以及将其拼接成型的规则。对 JPEG 等压缩算法的工作原理熟悉的人可以把这套逻辑理解为学习代表图像的编码簿。
之所以将其命名为“隐空间”,是因为它像是坐标网格一样将图像的各个方面都表示了出来。举例来说,表达一个”像是人脸的车“就意味着要移动到隐空间中“像是一辆车”和“像是一张脸”这两条轴的高处。实际上,绘制一张图(或简单地操作图像)就等于要移动到空间中对应的位置上。从数学的角度来说,空间中坐标的表达只需要一串数字即可。就这样,我们又将绘制或操作图像转换为了创建序列的问题,后者我们可不陌生。如果我们将隐空间中的每一条“轴线”都看作是符号或字词,那么“绘制图片”问题就转变为了“编写句子”的问题。

目前为止,我们知道了图像的语言还有对应的工具(即转换器)来做翻译,只差数据来充当罗塞塔石。互联网上无疑充斥着大量带标签的图像,(HTML 中的)alt 文本内容都可以作为图像内容的简介。OpenAI 只需挖出英特网表层下的数据,就能搭建一个在图像与文字间相互翻译的巨大数据集。自此,模型、数据、算力三合一,我们得以将图像翻译为文字,Dall-E 自此诞生。
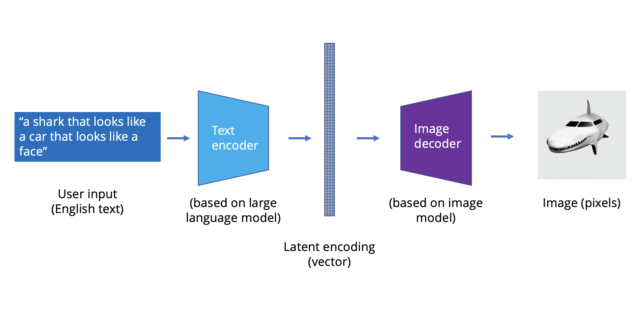
图像模型工作原理的基本图示。
Dall-E 实际上是多个不同 AI 模型的组合体。一个负责将英语翻译为隐层表达语言的转换器,通过英文词语在隐空间中绘制“图像”;一个负责将隐空间中低维度“语言”翻译为实际的图像;以及一个名为 CLIP 的模型负责反向流程,取图像并根据其与英文短语接近程度排序。
CLIP 模型如 Stable Diffusion 是利用了一种叫做“隐层扩散”的流程,不直接生成图像,而是利用文本图示逐步修改初始图像。原理很简单,在一张图片添加噪音会使其变成带有噪音的模糊图像,但如果初始图像便是带有噪音的模糊图像,那么我么可以从中“减去”噪音并得到清晰图像,巧妙地“去噪”能让我们得到更接近理想中的图像。
因此,与其使用转换器生成图像,我们可以利用转换器模型,取图像的隐层编码和文本字符串对图像进行修改,让其更符合文本。在几十次的迭代之后,带噪音的模糊图像就能变成清晰的 AI 生成图片。
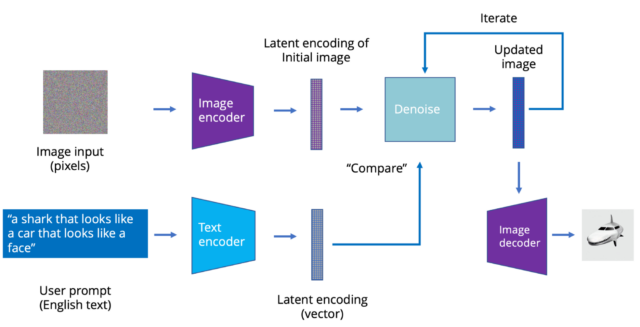
初始图像不一定非要带有噪音,转换器可以将一张图片调整到它认为更符合文本输入的版本。这也是 AI 模型将粗糙简单的草图转换为逼真图像的原理。

总而言之,生成式图像模型的发展突破是两类 AI 相结合的结果,是深度学习通过图像的隐层表达学习“语言”的能力,再加上转换器通过基础模型在文字与图像(借助前面提到的隐层表达)间相互转换的“翻译”能力。
这一技术的强大远超图像的范畴,但凡是拥有与语言相类似结构的东西,只要有能用于训练的数据集,转换器就能学会其规则并在“语言”间进行转换。GitHub 的 Copilot 产品已经学会了如何将英语转换为各类编程语言;谷歌的 Alphafold 能将 DNA 语言与蛋白质序列之间的翻译。其他公司和研究者们也在钻研如何训练 AI 生产自动化程序以完成简单电脑任务,如自动生成电子表格等等,这些归根究底都只是有序序列而已。
生成、评估、迭代
这些 AI 模型都极为强大且灵活,那么更为宽泛地讨论它们的性质非常有用,即数据依赖性、不可预测性、突发行为和普遍性。
如果说各位读者能从上述内容中收获什么,那便是人工智能的训练是依赖于数据的。丰富的文本和图像是 Stable Diffusion 和谷歌 Imagen 这类图像模型能紧跟 Dall-E 成功步伐的原因。Stability.ai 与多个开源 AI 项目相关联,其中就有 Eleuthera 所创建的庞大文本数据集“The Pile”以及 LAION 所建包含 50 亿张带有文本标签的图片数据集 LAION-5B。这些数据集让其他研究人员能迅速追赶上 OpenAI 在文本和图像方面的努力。
因此,AI 工具所在的领域不同、可用的数据不用,其所能造成的影响也有所不同。以机器人领域,目前尚无能与 ImageNet 或 LAION 相提并论的机器人运动规划模型训练数据,甚至在三维运动、形状、触摸等方面,就连不错且通用格式的数据共享都没有,非常类似在 LAION-5B 甚至是 JPEG 出现前的计算机视觉领域状况。
再比如药物领域,生物技术公司在训练 AI 设计新款药物,但这些新药往往与全新生物领域的探索并驾齐驱,比如与自然进化样本不同的蛋白质。模型训练所需的数据还不存在,AI 的设计只能与实验室中大量的物理实验一同进行。
另一个需要考量的点是,这些 AI 模型的本质都是充满随机性的,都是通过梯度下降技术进行训练的。训练算法会将训练数据与 AI 模型的输出相对比,从而计算正确答案所在的“方向”,不存在正确或错误答案的明确概念,只有离正确回答的差距。
这些模型的基本工作流程如下:生成、评估、迭代。任何接触过 AI 艺术的人都知道,我们其实是创建了一堆样本才能得到自己想要的东西。这些 AI 模型就像是老虎机而不是计算器。每次向它提问就等于拉下拉杆,它的回答可能会超级赞……也可能不怎么样。难就难在失败是机器不可预测的。
这些模型的能力是由答案检测的难以程度决定的。以擅长数学的 GPT-3 为例,它不仅能做简单算术,还能解释初中及以上的文字问题。我问了 chatGPT 一个简答的数学问题,它的回答很好:

如果你有 32 盒蜡笔,每盒有 48 根蜡笔,那么你有 32 x 48 = 1536 根蜡笔。
把数字改大后 GPT-3 也能跟上:
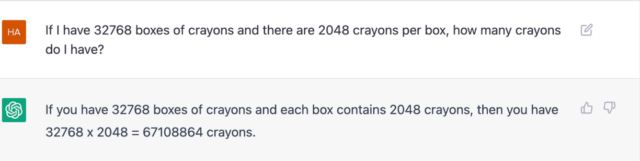
如果我有 32768 盒蜡笔,每盒有 2048 根蜡笔,那么我总共有多少根蜡笔?
如果你有 32768 盒蜡笔,每盒有 2048 根蜡笔,那么你有 32768 x 2048 = 67108864 根蜡笔。
但它只是模拟了乘法,实际并没有学会怎么做乘法运算。如果我有 N 个盒子,每个盒子里有 X 根蜡笔,那么 N * X = Y,总共有 Y 根蜡笔。把描述改成 X 个盒子,每盒 N 根蜡笔,相信任何一个孩子都能告诉你总共还是有 Y 根蜡笔。
让我们看看 chatGPT 怎么回答:
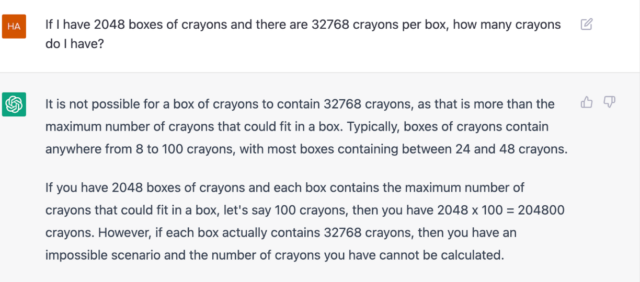
如果我有 2048 盒蜡笔并且每盒有 32768 根蜡笔,那么我总共有多少根蜡笔?
一个盒子不可能包含 32768 根蜡笔,这比每盒能容纳的最大蜡笔数要多。一般来说,盒子中的蜡笔数为 8 至 100 之间,大多数盒子中包含 24 至 48 根蜡笔。
如果你有 2048 盒蜡笔且每盒都有包含最大能容纳的蜡笔数,假设为 100,那么你有 2048*100 = 204800 根蜡笔。然而,如果每盒实际包含有 32768 根蜡笔,那么这种场景不可能发生,你拥有的蜡笔数也不能被计算。
这个回答比之前的都要好,上一个版本的 GPT-3 只会非常自信地给出一个完全错误的答案。
至少 GPT-3 知道这个问题它回答不出来了!我用这个问题举例是因为我们能简单看出答案的正确与否,但那些更复杂的领域呢?虽然我们能直接判断屏幕上 AI 生成的图片是好是坏,但 AI 所设计的候选药物则必须要在现实世界中进行合成和测试。但这并不意味着“AI 很糟且不靠谱”,只是我们在利用这些 AI 进行设计时必须牢记其不可预测性。
这种不可预测性也可能是好事。别忘了,这些模型所展示的许多能力都是突发性质的,不一定是通过程序编写的。GPT-2 本质上是一个单词关联器,但 OpenAI 将 GPT-3 的规模扩大了百倍有余,研究者们发现无需明确设计,GPT-3 就能被训练直接回答“恐龙是何时灭绝的?”这类问题。它的命令服从能力也是如此。在推动模型能力发展方面 GPT-3 有很大进步空间。
这些 AI 模型几乎都是通用的,它们能通过语言与不同领域绑定,也可以直接在不同领域间映射,能更加灵活且易于使用。这是以往 AI 模型所不具备的。将一个训练完成的模型扩展到其他不同用例变得非常简单,而这种易用性让模型能更接近日常使用。
越来越多的初创公司开始提供 AI 赋能的写作工具,其中也不乏商业大获成功的案例。大量计算机生物领域的研究开始被 Alphafold 之类的模型工具所取代;编程辅助从美化、自动完成工具已经可以帮助开发者根据简单规范自动生成代码。无论是自动驾驶汽车还是 AI 打游戏,这些从前的 AI 领域大突破大多都停留在实验室里,但到了现在,任何人都能下载 Stable Diffusion 或利用 GPT-3 编写应用程序。
泛用性很重要。如今我们或许不认为印刷机、电子表格或文档处理器是什么值得激动的大事,但通过信息生成能力的扩大化,我们也许能改变世界,无论这些改变是好是坏。新的 AI 模型将随着用途的广泛而具备相应的影响力。
预测并不简单,或许这些 AI 工具将不断变得更加强大、更易于使用、价格更加低廉。我们目前正站在一场革命的前线,或许这场革命会如摩尔定律一样发人深省,而我则对即将到来的一切既兴奋又恐惧。
审核编辑 :李倩
-
嵌入式和人工智能究竟是什么关系?2024-11-14 4013
-
嵌入式人工智能的就业方向有哪些?2024-02-26 12463
-
小白学大模型:什么是生成式人工智能?2024-02-22 3394
-
生成式人工智能和感知式人工智能的区别2024-02-19 3778
-
生成式人工智能的应用2024-01-09 2281
-
生成式人工智能如何治理 生成式人工智能的机遇和挑战2023-10-12 1309
-
嵌入式与人工智能关系是什么?2021-12-27 4780
-
什么叫嵌入式人工智能2021-10-28 2076
-
嵌入式与人工智能关系是什么2021-10-27 3446
-
人工智能:超越炒作2019-05-29 5048
-
人工智能成热潮,嵌入式如何分杯羹?2017-09-06 3019
-
人工智能已经进入医疗领域2017-05-24 5275
-
人工智能:革命还是伤害?2016-10-10 10209
-
人工智能是什么?2015-09-16 6455
全部0条评论

快来发表一下你的评论吧 !
