

深入浅出解析JVM中的Safepoint
描述
1
初识Safepoint-GC中的Safepoint
最早接触JVM中的安全点概念是在读《深入理解Java虚拟机》那本书垃圾回收器章节的内容时。相信大部分人也一样,都是通过这样的方式第一次对安全点有了初步认识。不妨,先复习一下《深入理解Java虚拟机》书中安全点那一章节的内容。
书中是在讲解垃圾收集器-垃圾收集算法的章节引入安全点的介绍,为了快速准确地完成GC Roots枚举,避免为每条指令都生成对应的OopMap造成大量存储空间的浪费,只在“特定的位置”生成对应的OopMap,这些位置被称为安全点。然后,书中提到了安全点位置的选择标准是:是否能让程序长时间执行;所以会在方法调用、循环跳转、异常跳转等处才会产生安全点。
书中还提到了JVM如何在GC时让用户线程在最近的安全点处停顿下来:抢先式中断和主动式中断。抢先式中断不需要线程的执行代码主动去配合,在GC发生时,系统首先把所有用户线程全部中断,如果发现有用户线程中断的地方不在安全点上,就恢复这条线程执行,让它一会再重新中断,直到跑到安全点上。而主动式中断的思想是当GC需要中断线程时,不直接对线程操作,仅仅简单地设置一个标志位,各个线程执行过程时不停地主动去轮询这个标志,一旦发现中断标志为真就自己在最近的安全点上主动中断挂起。现在基本上所有虚拟机实现都采用主动式中断方式来暂停线程响应GC事件。
总结一下初识安全点学到的知识点:
JVM GC时需要让用户线程在安全点处停顿下来(Stop The World)
JVM会在方法调用、循环跳转、异常跳转等处放置安全点
JVM通过主动中断方式到达全局STW:设置一个标志位,各个线程执行过程时不停地主动去轮询这个标志,一旦发现中断标志为真就自己在最近的安全点上主动中断挂起。
以上基本上就是《深入理解Java虚拟机》这本书对JVM安全点的所有介绍了,当时觉得安全点还是很好理解,认为安全点就是在垃圾回收时为了STW而设计的。
后来发现,经过一些线上问题和网上看到有关安全点有趣的示例,发现安全点其实也不简单,不只有GC才会用到安全点;简单的代码如果写的不当,安全点也会带来一些莫名其妙的问题;其在JVM内部的实现以及JIT对它的优化,也经常让人摸不着头脑。本文尝试在初识安全点后已知知识点的基础上,通过一段简单的示例代码,多问几个为什么,来进一步更全面的了解一下安全点。
2
通过一段示例代码深入剖析Safepoint
2.1 示例代码
这段示例代码可直接复制到本地运行,本文所有对示例代码的运行环境都是jdk 1.8。
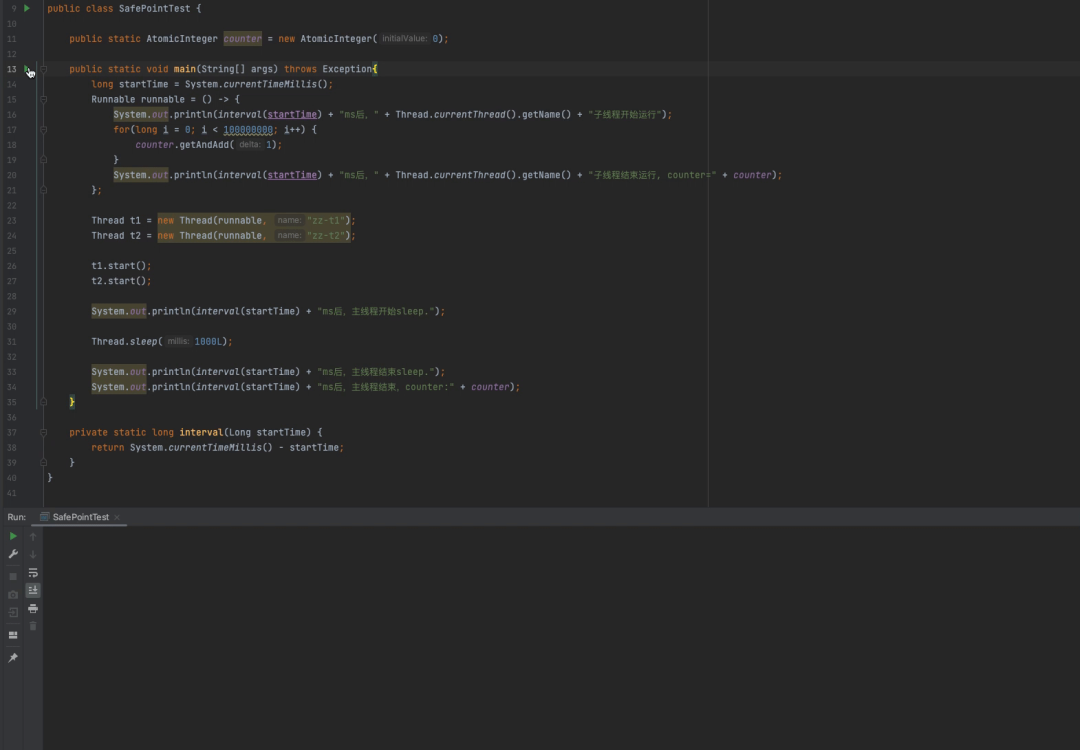
public class SafePointTest {
public static AtomicInteger counter = new AtomicInteger(0);
public static void main(String[] args) throws Exception{
long startTime = System.currentTimeMillis();
Runnable runnable = () -> {
System.out.println(interval(startTime) + "ms后," + Thread.currentThread().getName() + "子线程开始运行");
for(int i = 0; i < 100000000; i++) {
counter.getAndAdd(1);
}
System.out.println(interval(startTime) + "ms后," + Thread.currentThread().getName() + "子线程结束运行, counter=" + counter);
};
Thread t1 = new Thread(runnable, "zz-t1");
Thread t2 = new Thread(runnable, "zz-t2");
t1.start();
t2.start();
System.out.println(interval(startTime) + "ms后,主线程开始sleep.");
Thread.sleep(1000L);
System.out.println(interval(startTime) + "ms后,主线程结束sleep.");
System.out.println(interval(startTime) + "ms后,主线程结束,counter:" + counter);
}
private static long interval(Long startTime) {
return System.currentTimeMillis() - startTime;
}
}
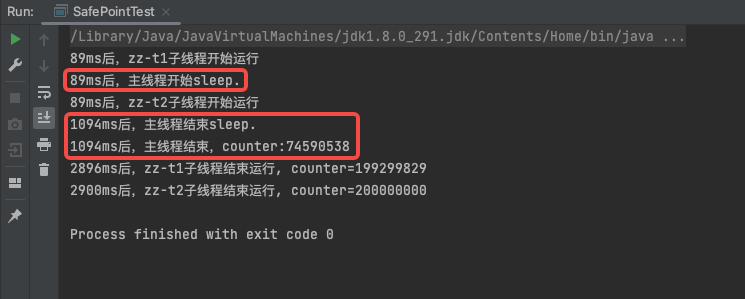
示例代码中主线程启动两个子线程,然后主线程睡眠1s,通过打印时间来观察主线程和子线程的执行情况。 按道理来说这里主线程和两个子线程独立并发,没有任何显性的依赖,主线程的执行是不会受子线程影响的:主线程睡眠结束后会直接结束。但是执行结果却和期望不一样。 执行结果如下方动图展示:
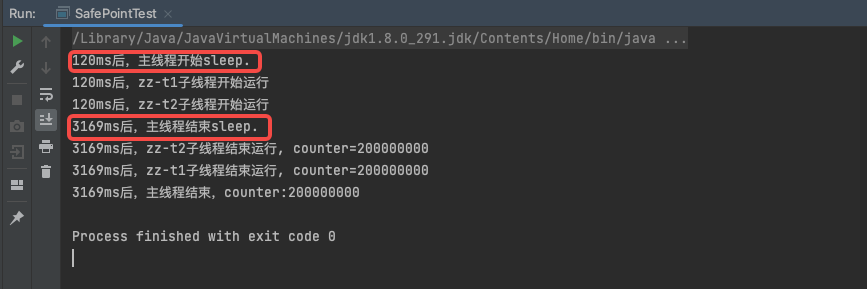
从执行结果看,主线程在启动两个线程后进入睡眠状态,代码中指定睡眠时间为1s,但是主线程却在3s多之后才睡眠结束。是什么导致了主线程睡过头了呢,从结果来看主线程睡觉结束时间和子线程结束时间是一致的。所以,我们有理由怀疑主线程没有按时提前结束应该是被两个子线程阻塞了。
2.2 先给结论
由于VMThread的某些操作需要STW,主线程在sleep结束前进入了JVM全局安全点,然后主线程要等待其他线程全部进入安全点,所以主线程被长时间没有进入安全点的其他线程给阻塞了。
2.3 验证结论
添加JVM打印安全点日志参数-XX:+PrintSafepointStatistics后再执行上面的实例代码,结果如下截图:
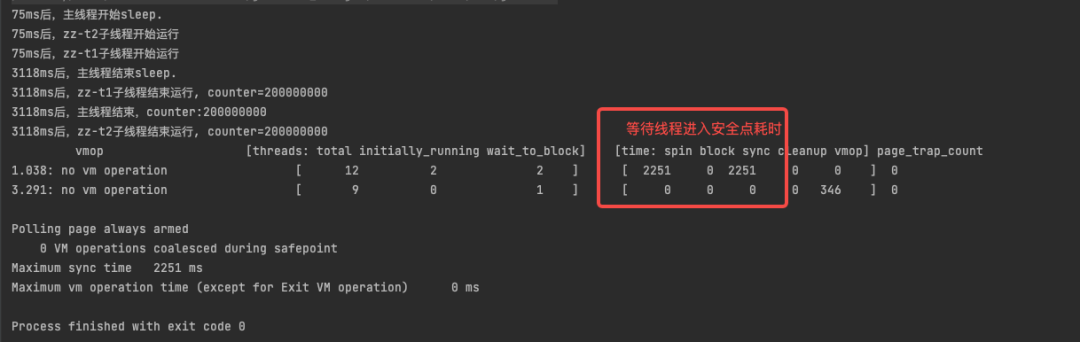
可以从安全点日志中看到,JVM想要执行no vm operation,这个操作需要线程进入安全点,整个期间有12个线程,正在运行的线程有两个,需要等待这两个线程进入安全点,等待耗时2251ms。
加上 -XX:+SafepointTimeout 和-XX:SafepointTimeoutDelay=2000 参数后执行代码可以进一步看等待哪两个线程进入安全点。
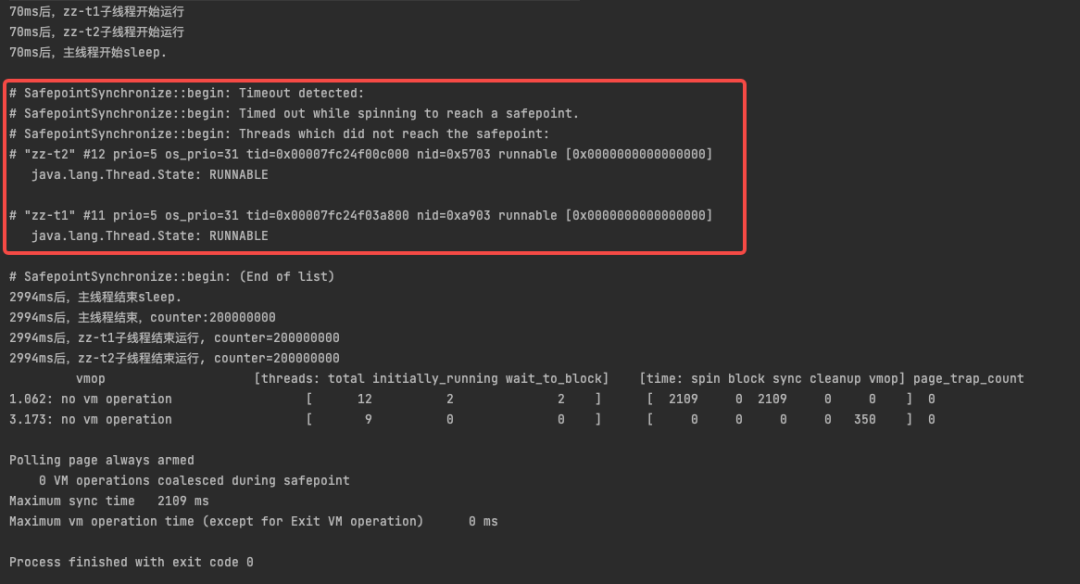
果然和猜测的一样,没有到达安全点的两个线程正是示例代码中定义的zz-t1和zz-t2线程。
2.4 为什么
到这里这个示例的执行结果的原因已经有了结论并且得到了验证,基本上已经知其然了。但是如果深入思考一下,初识安全点时学到的知识点还不能解释,所以为了知其所以然,这里提了几个为什么。
(1)为什么会进入安全点
换句话问,是什么触发了进入安全点?
由初识安全点得到的基础知识知道进入安全点需要两个条件:
JVM操作设置了主动中断标志
运行的代码中存在安全点
首先想到的是GC触发JVM设置主动中断标志,加上 -XX:-PrintGC再执行示例代码并没有打印 GC 日志,可以排除掉GC。
既然不是GC,还是再回到安全点日志上寻找线索吧,发现有个vmop(虚拟机操作类型):no vm operation,关于no vm operation,网上有大神通过解析JVM源码得到了结论,这里不对JVM源码展开做详细解读,直接给结论:
在 JVM 正常运行的时候,如果设置了进入安全点的间隔,就会隔一段时间判断是否有代码缓存要清理,如果有,会进入安全点。这个触发条件不是 VM 操作,所以会将 _vmop_type 设置成-1,输出日志的时候打印对应的 「no vm operation」,也就是我们看到的安全点日志。
在 VM 操作为空的情况下,只要满足以下 3 个条件,也是会进入安全点的:
1、VMThread 处于正常运行状态
2、设置了进入安全点的间隔时间
3、SafepointALot 是否为 true 或者是否需要清理
用 Java -XX:+UnlockDiagnosticVMOptions -XX:+PrintFlagsFinal 2>&1 | grep Safepoint 命令查看 JVM 关于安全点的默认参数:
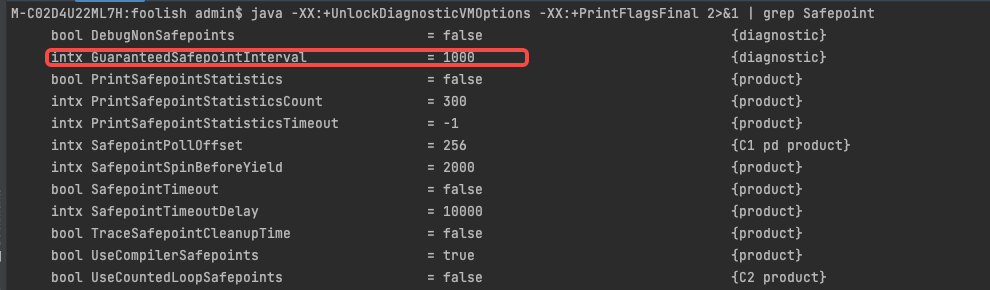
发现 GuaranteedSafepointInterval 默认设置成了 1 秒,每隔1s就会尝试进入安全点。
那么,修改GuaranteedSafepointInterval参数值,看看是否能阻止进入安全点。
GuaranteedSafepointInterval参数是JVM诊断参数,修改这个参数的值,需要配合-XX:+UnlockDiagnosticVMOptions一起使用。
另外不建议在线上对这个参数的值做修改。
关闭定时进入安全点
通过 -XX:GuaranteedSafepointInterval = 0 关闭定时进入安全点,看看代码运行结果是怎么样的
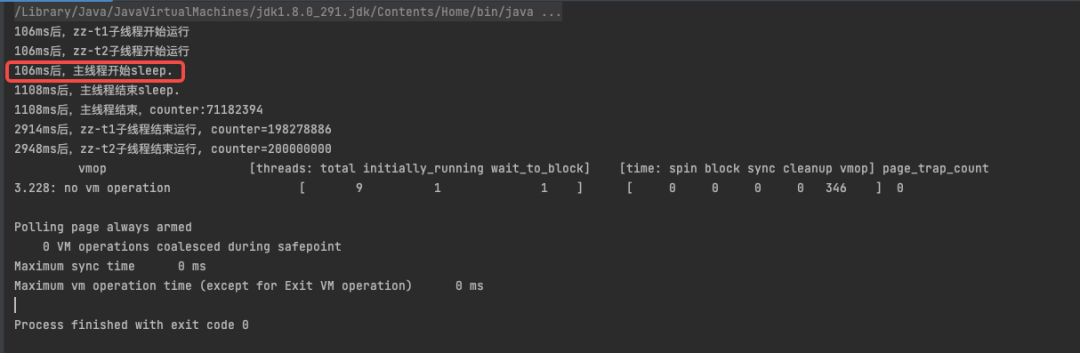
由运行结果可以看出,关闭定时进入安全点后,主线程睡眠1s后正常结束,不受其他线程阻塞。从安全点日志看,之前等待进入安全点的两个线程也没有了。
调大定时进入安全点间隔时间
由打印的执行结果可以看到子线程运行时间是3s多,如果把进入安全点间隔时间调整为5s,即在子线程结束之后再尝试进入安全点是不是也能避免等待子线程进入安全点呢? 修改参数-XX:GuaranteedSafepointInterval = 5000 调整安全点间隔时间再次执行结果:
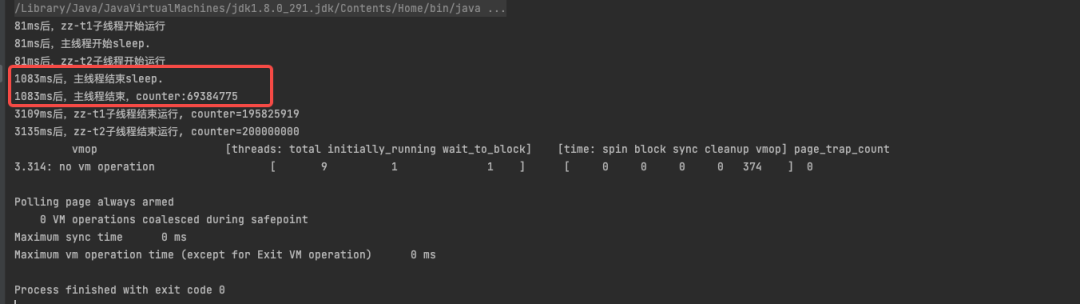
从执行结果可以看出,调大安全点间隔时间和关闭定时进入安全点的效果是一样的,也可以避免等待子线程进入安全点的。
(2)主线程是在哪里进入的安全点
从示例代码在默认JVM参数执行结果看,主线程睡眠时间超过了3s,事实上主线程是在Thread.sleep()方法内部进入安全点。这里对JVM 安全点实现的源码简单做一下分析:
Safepoint实现源代码:Safepoint.cpp
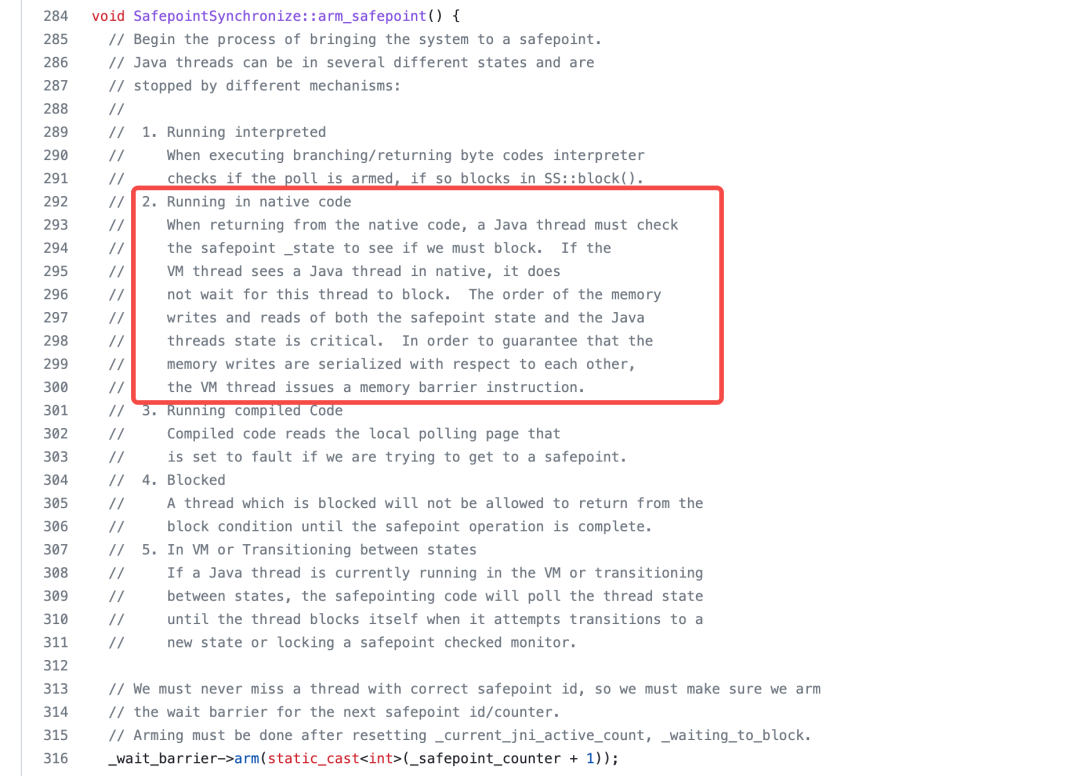
读源码太费劲,看注释吧,所幸从注释中也能找到答案。上面截图的注释说在程序进入 Safepoint 的时候,Java 线程可能正处于的五种不同的状态,针对不同的状态的不同处理机制。假设现在有一个操作触发了某个 VM 线程所有线程需要进入 SafePoint,如果其他线程现在:
运行字节码:运行字节码时,解释器会看线程是否被标记为 poll armed,如果是,VM 线程调用 SafepointSynchronize::block(JavaThread *thread)进行 block。
运行 native 代码:当运行 native 代码时,VM 线程略过这个线程,但是给这个线程设置 poll armed,让它在执行完 native 代码之后,它会检查是否 poll armed,如果还需要停在 SafePoint,则直接 block。
运行 JIT 编译好的代码:由于运行的是编译好的机器码,直接查看本地 local polling page 是否为脏,如果为脏则需要 block。这个特性是在 Java 10 引入的 JEP 312: Thread-Local Handshakes 之后,才是只用检查本地 local polling page 是否为脏就可以了。
处于 BLOCK 状态:在需要所有线程需要进入 SafePoint 的操作完成之前,不许离开 BLOCK 状态
处于线程切换状态或者处于 VM 运行状态:会一直轮询线程状态直到线程处于阻塞状态(线程肯定会变成上面说的那四种状态,变成哪个都会 block 住)。
再看一下Thread.sleep方法的声明,就和上面Safepoint.cpp源码注释截图红框对上了,Thread.sleep正是一个native方法。

Thread.sleep(0)在RocketMQ中的妙用
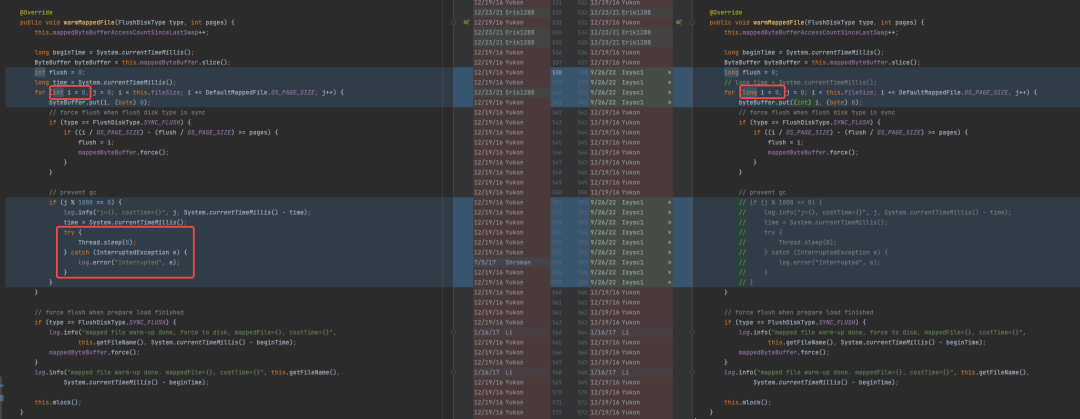
上面这段代码是RocketMQ的一段代码,16年最早版本的实现for循环内每循环1000次会调用一次Thread.sleep(0),这貌似是一段无用的代码,作者真实的目的是为了在这里放置一个安全点,避免for循环运行时间过长导致系统长时间SWT。从代码的变更记录看,22年9月份有人对这段代码换了一种写法:把for循环变量类型定义成long型,同时注释掉了循环内部Thread.sleep(0)代码,为什么可以这样写以及为什么要这样写这里先按下不表。
(3)子线程为什么无法进入安全点
现在已经知道了主线程为什么进入会进入安全点,以及主线程在哪里进入的安全点,按照已知知识点JVM会在循环跳转处和方法调用处放置安全点,为什么子线程没有进入安全点?
可数循环和不可数循环
JVM为了避免安全点过多带来过重的负担,对循环有一项优化措施,认为循环次数较少的话,执行时间应该不会太长,所以使用int类型和范围更小的数据类型作为索引值的循环默认是不会被放置安全点的。这种循环被称为可数循环,相对应的,使用long或者范围更大的数据类型作为索引值的循环就被称为不可数循环,将被放置安全点。
在示例代码中,子线程的循环索引值数据类型是int,也就是可数循环,所以JVM没有在循环跳转处放置安全点。
把循环索引值数据类型改成long型,循环成为不可数循环,就能够成功在循环跳转处放置安全点,避免子线程长时间无法进入安全点阻塞主线程。
从上面的执行结果可以看到,把循环索引值数据类型改成long型,主线程在睡眠1s之后立即结束了睡眠,并没有等待子线程的执行。
到这里,也就知道为什么上面贴的RocketMQ大那段代码,把循环索引值数据类型改成long型可以替换循环内部Thread.Sleep(0)达到放置安全点的目的了。
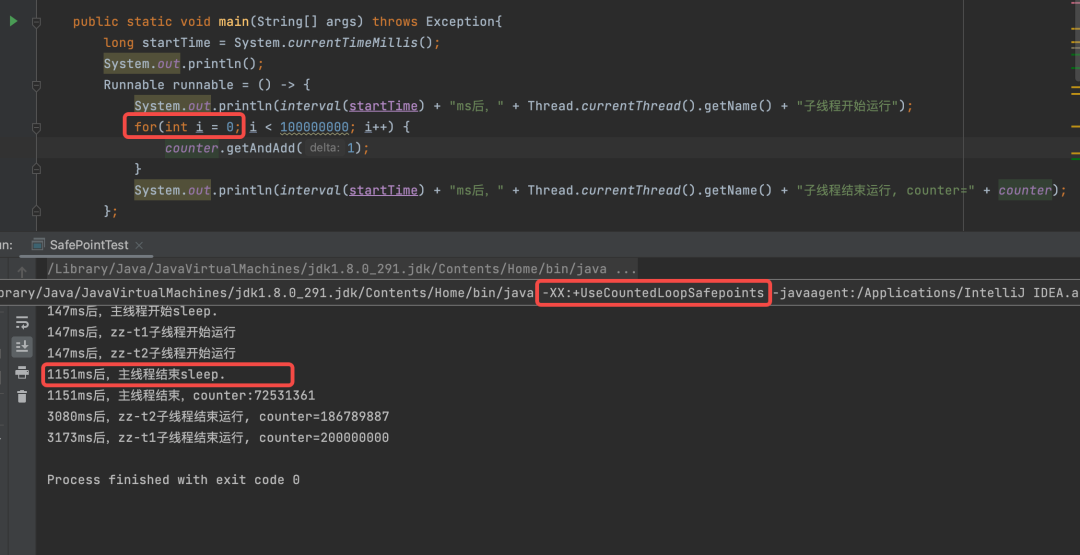
其实,还可以通过-XX:+UseCountedLoopSafepoints参数关闭JVM 对可数循环放置安全点的优化。下面的执行结果可以看出,添加了-XX:+UseCountedLoopSafepoints参数后,也能让运行结果到达预期。
还有一个疑惑
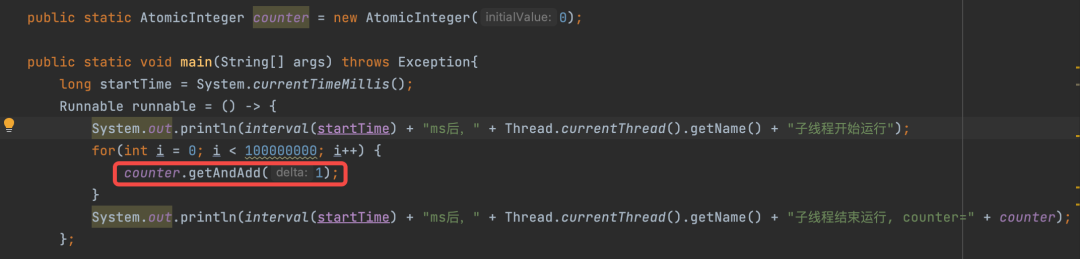
仔细看实例代码,发现子线程循环体内调用了AtomicInteger类的getAndAdd方法,再深入看jdk getAndAdd方法的实现,发现底层是调用了sun.misc.Unsafe#getIntVolatile 这个方法和Thread.sleep方法一样,也是一个native方法,为什么这里没有进入像Thread.sleep方法一样进入安全点?
是的,好可怕,确实被优化了,被 JIT给优化了。为了验证是被JIT优化了,可以用
-Djava.compiler=NONE关闭JIT然后看一下运行结果。
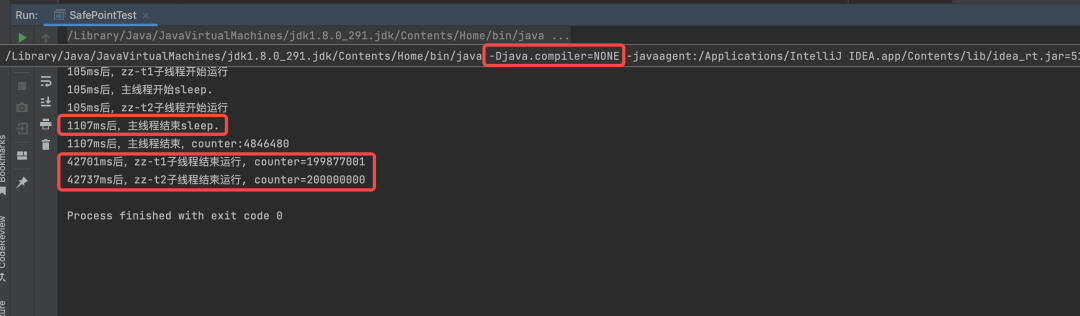
从运行结果看,关闭了JIT优化后,主线程确实在睡眠1s后立即结束了,不过子线程运行的时间比JIT优化开启时多了不少。所以,JIT还是能够带来一定的性能优化的,有时也会带来一些奇怪的现象。
3
更全面的安全点定义
区别于初识安全点的时候局限于GC中的安全点概念,这里给安全点一个比较全面的定义:
Safepoint 可以理解成是在代码执行过程中的一些特殊位置,当线程执行到这些位置的时候,线程可以暂停。在 SafePoint 保存了其他位置没有的一些当前线程的运行信息,供其他线程读取。这些信息包括:线程上下文的任何信息,例如对象或者非对象的内部指针等等。我们一般这么理解 SafePoint,就是线程只有运行到了 SafePoint 的位置,他的一切状态信息,才是确定的,也只有这个时候,才知道这个线程用了哪些内存,没有用哪些;并且,只有线程处于 SafePoint 位置,这时候对 JVM的堆栈信息进行修改,例如回收某一部分不用的内存,线程才会感知到,之后继续运行,每个线程都有一份自己的内存使用快照,这时候其他线程对于内存使用的修改,线程就不知道了,只有再进行到 SafePoint 的时候,才会感知。
4
什么时候会进入Safepoint
当VM Thread需要做vm 操作时会让线程进入安全点,vm操作类型有很多,可以参考VM_OP_ENUM源码 vmOperations.hpp。下面是几种经常发生的进入Safepoint的情形:
(1)GC:由于需要每个线程的对象使用信息,以及回收一些对象,释放某些堆内存或者直接内存,所以需要 进入Safepoint来 Stop the world;
(2)定时进入 SafePoint:每经过-XX:GuaranteedSafepointInterval 配置的时间,都会让所有线程进入 Safepoint,一旦所有线程都进入,立刻从 Safepoint 恢复。这个定时主要是为了一些没必要立刻 Stop the world 的任务执行,可以设置-XX:GuaranteedSafepointInterval=0关闭这个定时。
(3)由于 jstack,jmap 和 jstat 等命令,会导致 Stop the world:这种命令都需要采集堆栈信息,所以需要所有线程进入 Safepoint 并暂停。
(4)偏向锁取消:锁大部分情况是没有竞争的(某个同步块大多数情况都不会出现多线程同时竞争锁),所以可以通过偏向来提高性能。即在无竞争时,之前获得锁的线程再次获得锁时,会判断是否偏向锁指向我,那么该线程将不用再次获得锁,直接就可以进入同步块。但是高并发的情况下,偏向锁会经常失效,导致需要取消偏向锁,取消偏向锁的时候,需要 Stop the world,因为要获取每个线程使用锁的状态以及运行状态。
(5)Java Instrument 导致的 Agent 加载以及类的重定义:由于涉及到类重定义,需要修改栈上和这个类相关的信息,所以需要 Stop the world
(6)Java Code Cache相关:当发生 JIT 编译优化或者去优化,需要 OSR 或者 Bailout 或者清理代码缓存的时候,由于需要读取线程执行的方法以及改变线程执行的方法,所以需要 Stop the world
5
避免Safepoint副作用
Safepoint在一定程度上是可以理解成是为了让所有用户线程停顿(Stop The World)而设计的。STW对应用系统来说是一件很可怕的事情,JVM不论是在GC还是在其他的VM操作上都在努力避免STW和减少STW时间。
安全点最主要的副作用就是可能导致STW时间过长,应该极力避免这点副作用。
对第一个进入安全点的线程来说,STW是从它进入安全点开始的,如果有某个线程一直无法进入安全点就会导致进入安全点的时间一直处于等待状态,进而导致STW的时间过长。所以,应避免线程执行过长无法进入安全点的情况。
可数循环体内执行时间过长以及JIT优化导致无法进入安全点的问题是最常见的无法进入安全点的情况。在写大循环的时候可以把循环索引值数据类型定义成long。
在高并发应用中,偏向锁并不能带来性能提升,反而因为偏向锁取消带来了很多没必要的某些线程进入安全点 。所以建议关闭:-XX:-UseBiasedLocking。
jstack,jmap 和 jstat 等命令,也会导致进入安全点。所以,生产环境应该关闭Thead dump的开关,避免dump时间过长导致应用STW时间过长。
审核编辑:刘清
-
深入浅出数字信号处理2018-12-07 826
-
深入浅出Android—Android开发经典教材2017-10-24 1441
-
深入浅出谈多层面板布线技巧2016-12-13 742
-
深入浅出软件加密技术2016-09-24 3634
-
深入浅出数据分析2016-01-15 747
-
深入浅出安防视频监控系统2014-05-22 4606
-
深入浅出Android2012-08-20 3165
-
HDMI技术深入浅出2012-08-19 4651
-
深入浅出ARM72012-08-18 5342
-
深入浅出玩转FPGA2012-07-21 4539
-
深入浅出AVR2012-07-15 13538
-
深入浅出AVR(傻孩子)2012-06-29 8989
-
深入浅出matlab2008-06-18 1101
全部0条评论

快来发表一下你的评论吧 !
