

Verilog FFT设计方案
电子说
描述
FFT(Fast Fourier Transform),快速傅立叶变换,是一种 DFT(离散傅里叶变换)的高效算法。在以时频变换分析为基础的数字处理方法中,有着不可替代的作用。
FFT 原理
◆公式推导
DFT 的运算公式为:
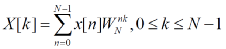
其中,
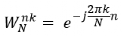
将离散傅里叶变换公式拆分成奇偶项,则前 N/2 个点可以表示为:
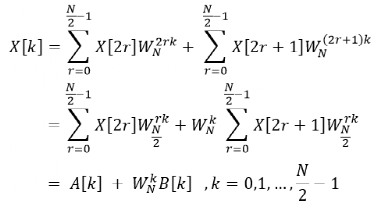
同理,后 N/2 个点可以表示为:
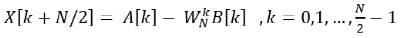
由此可知,后 N/2 个点的值完全可以通过计算前 N/2 个点时的中间过程值确定。对 A[k] 与 B[k] 继续进行奇偶分解,直至变成 2 点的 DFT,这样就可以避免很多的重复计算,实现了快速离散傅里叶变换(FFT)的过程。
◆算法结构
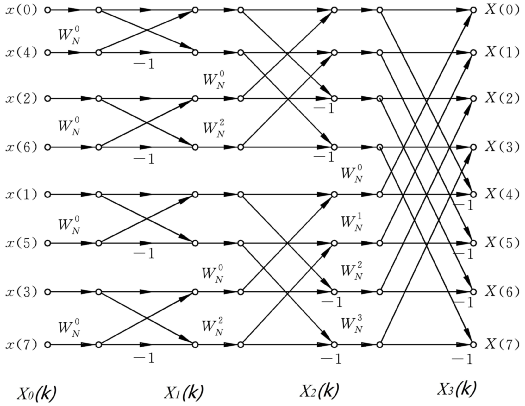
8 点 FFT 计算的结构示意图如下。
由图可知,只需要简单的计算几次乘法和加法,便可完成离散傅里叶变换过程,而不是对每个数据进行繁琐的相乘和累加。
◆重要特性
(1) 级的概念
每分割一次,称为一级运算。
设 FFT 运算点数为 N,共有 M 级运算,则它们满足:
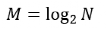
每一级运算的标识为 m = 0, 1, 2, ..., M-1。
为了便于分割计算,FFT 点数 N 的取值经常为 2 的整数次幂。
(2) 蝶形单元
FFT 计算结构由若干个蝶形运算单元组成,每个运算单元示意图如下:
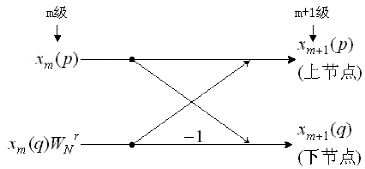
蝶形单元的输入输出满足:
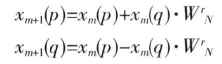
其中,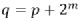 。
。
每一个蝶形单元运算时,进行了一次乘法和两次加法。
每一级中,均有 N/2 个蝶形单元。
故完成一次 FFT 所需要的乘法次数和加法次数分别为:
(3) 组的概念
每一级 N/2 个蝶形单元可分为若干组,每一组有着相同的结构与因子分布。
例如 m=0 时,可以分为 N/2=4 组。
m=1 时,可以分为 N/4=2 组。
m=M-1 时,此时只能分为 1 组。
(4) 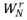 因子分布
因子分布
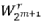 因子存在于 m 级,其中
因子存在于 m 级,其中 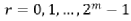 。
。
在 8 点 FFT 第二级运算中,即 m=1 ,蝶形运算因子可以化简为:
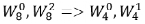
(5) 码位倒置
对于 N=8 点的 FFT 计算,X(0) ~ X(7) 位置对应的 2 进制码为:
X(000), X(001), X(010), X(011), X(100), X(101), X(110), X(111)
将其位置的 2 进制码进行翻转:
X(000), X(100), X(010), X(110), X(001), X(101), X(011), X(111)
此时位置对应的 10 进制为:
X(0), X(4), X(2), X(6), X(1), X(5), X(3), X(7)
恰好对应 FFT 第一级输入数据的顺序。
该特性有利于 FFT 的编程实现。
FFT 设计
◆设计说明
为了利用仿真简单的说明 FFT 的变换过程,数据点数取较小的值 8。
如果数据是串行输入,需要先进行缓存,所以设计时数据输入方式为并行。
数据输入分为实部和虚部共 2 部分,所以计算结果也分为实部和虚部。
设计采用流水结构,暂不考虑资源消耗的问题。
为了使设计结构更加简单,这里做一步妥协,乘法计算直接使用乘号。如果 FFT 设计应用于实际,一定要将乘法结构换成可以流水的乘法器,或使用官方提供的效率较高的乘法器 IP。
◆蝶形单元设计
蝶形单元为定点运算,需要对旋转因子进行定点量化。
借助 matlab 将旋转因子扩大 8192 倍(左移 13 位),可参考附录。
为了防止蝶形运算中的乘法和加法导致位宽逐级增大,每一级运算完成后,要对输出数据进行固定位宽的截位,也可去掉旋转因子倍数增大而带来的影响。
代码如下:
`timescale 1ns/100ps
/**************** butter unit *************************
Xm(p) ------------------------ > Xm+1(p)
- - >
- -
-
- -
- - >
Xm(q) ------------------------ > Xm+1(q)
Wn -1
*//////////////////////////////////////////////////////
module butterfly
(
input clk,
input rstn,
input en,
input signed [23:0] xp_real, // Xm(p)
input signed [23:0] xp_imag,
input signed [23:0] xq_real, // Xm(q)
input signed [23:0] xq_imag,
input signed [15:0] factor_real, // Wnr
input signed [15:0] factor_imag,
output valid,
output signed [23:0] yp_real, //Xm+1(p)
output signed [23:0] yp_imag,
output signed [23:0] yq_real, //Xm+1(q)
output signed [23:0] yq_imag);
reg [4:0] en_r ;
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
en_r <= 'b0 ;
end
else begin
en_r <= {en_r[3:0], en} ;
end
end
//=====================================================//
//(1.0) Xm(q) mutiply and Xm(p) delay
reg signed [39:0] xq_wnr_real0;
reg signed [39:0] xq_wnr_real1;
reg signed [39:0] xq_wnr_imag0;
reg signed [39:0] xq_wnr_imag1;
reg signed [39:0] xp_real_d;
reg signed [39:0] xp_imag_d;
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
xp_real_d <= 'b0;
xp_imag_d <= 'b0;
xq_wnr_real0 <= 'b0;
xq_wnr_real1 <= 'b0;
xq_wnr_imag0 <= 'b0;
xq_wnr_imag1 <= 'b0;
end
else if (en) begin
xq_wnr_real0 <= xq_real * factor_real;
xq_wnr_real1 <= xq_imag * factor_imag;
xq_wnr_imag0 <= xq_real * factor_imag;
xq_wnr_imag1 <= xq_imag * factor_real;
//expanding 8192 times as Wnr
xp_real_d <= {{4{xp_real[23]}}, xp_real[22:0], 13'b0};
xp_imag_d <= {{4{xp_imag[23]}}, xp_imag[22:0], 13'b0};
end
end
//(1.1) get Xm(q) mutiplied-results and Xm(p) delay again
reg signed [39:0] xp_real_d1;
reg signed [39:0] xp_imag_d1;
reg signed [39:0] xq_wnr_real;
reg signed [39:0] xq_wnr_imag;
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
xp_real_d1 <= 'b0;
xp_imag_d1 <= 'b0;
xq_wnr_real <= 'b0 ;
xq_wnr_imag <= 'b0 ;
end
else if (en_r[0]) begin
xp_real_d1 <= xp_real_d;
xp_imag_d1 <= xp_imag_d;
//提前设置好位宽余量,防止数据溢出
xq_wnr_real <= xq_wnr_real0 - xq_wnr_real1 ;
xq_wnr_imag <= xq_wnr_imag0 + xq_wnr_imag1 ;
end
end
//======================================================//
//(2.0) butter results
reg signed [39:0] yp_real_r;
reg signed [39:0] yp_imag_r;
reg signed [39:0] yq_real_r;
reg signed [39:0] yq_imag_r;
always @(posedge clk or negedge rstn) begin
if (!rstn) begin