

探索ChatGPT的信息抽取能力
描述
信息抽取(IE)旨在从非结构化文本中抽取出结构化信息,该结果可以直接影响很多下游子任务,比如问答和知识图谱构建。因此,探索ChatGPT的信息抽取能力在一定程度上能反映出ChatGPT生成回复时对任务指令理解的性能。

论文:Is Information Extraction Solved by ChatGPT? An Analysis of Performance, Evaluation Criteria, Robustness and Errors
地址:https://arxiv.org/pdf/2305.14450.pdf
代码:https://github.com/RidongHan/Evaluation-of-ChatGPT-on-Information-Extraction
本文将从性能、评估标准、鲁棒性和错误类型四个角度对ChatGPT在信息抽取任务上的能力进行评估。
实验
实验设置
任务和数据集
本文的实验采用4类常见的信息抽取任务,包括命名实体识别(NER),关系抽取(RE),事件抽取(EE)和基于方面的情感分析(ABSA),它们一共包含14类子任务。
对于NER任务,采用的数据集包括CoNLL03、FewNERD、ACE04、ACE05-Ent和GENIA。
对于RE任务,采用的数据集包括CCoNLL04、NYT-multi、TACRED和SemEval 2010。
对于EE任务,采用的数据集包括CACE05-Evt、ACE05+、CASIE和Commodity News EE。
对于ABSA任务,采用的数据集包括D17、D19、D20a和D20b,均从SemEval Challenges获取。
实验结果
1、性能
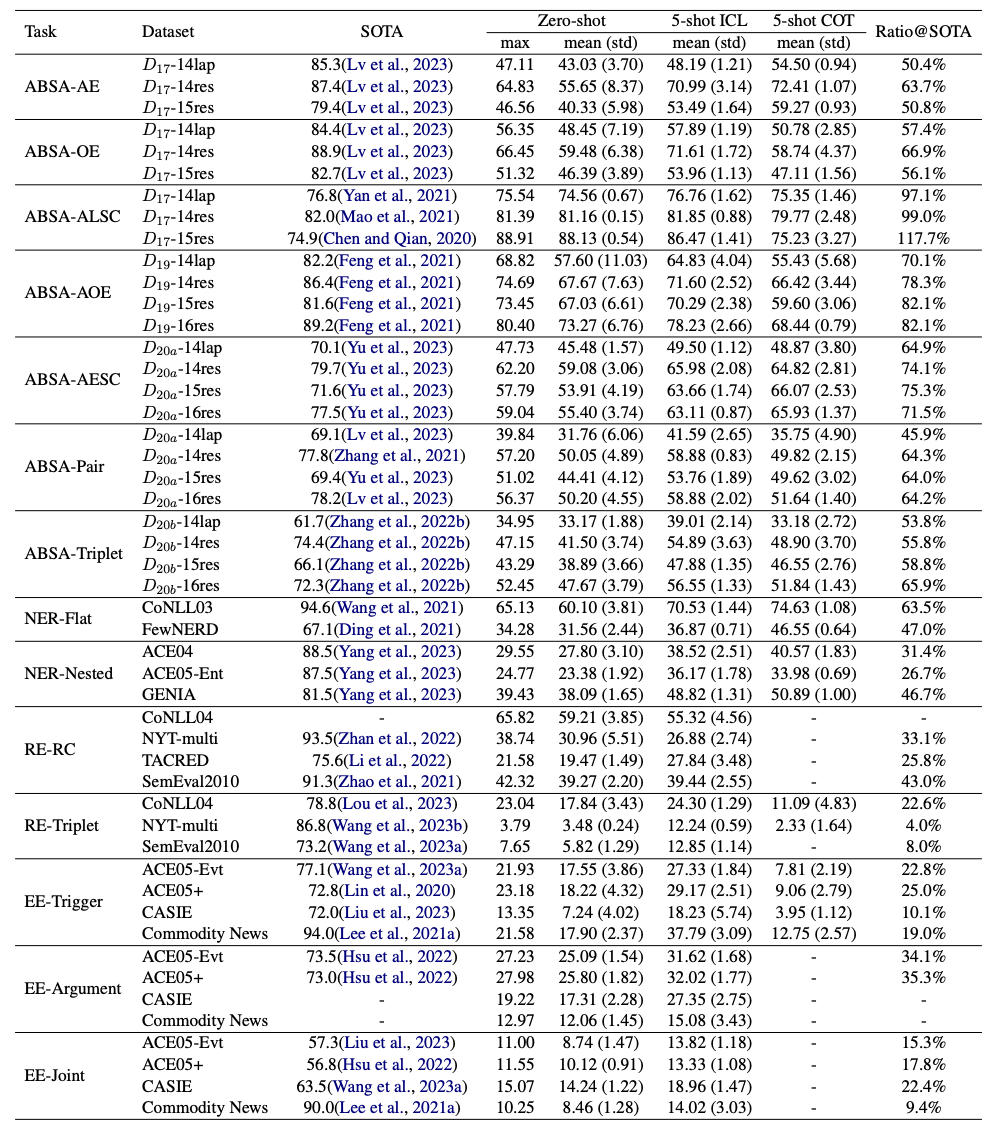
从上图结果可以明显看出:
(1)ChatGPT和SOTA方法之间存在显著的性能差距;
(2)任务的难度越大,性能差距越大;
(3)任务场景越复杂,性能差距越大;
(4)在一些简单的情况下,ChatGPT可以达到或超过SOTA方法的性能;
(5)使用few-shot ICL提示通常有显著提升(约3.0~13.0的F1值),但仍明显落后于SOTA结果;
(6)与few-shot ICL提示相比,few-shot COT提示的使用不能保证进一步的增益,有时它比few-shot ICR提示的性能更差。
2、对性能gap的思考
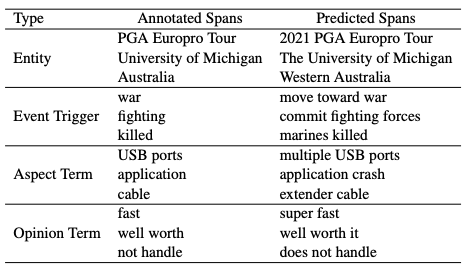
通过人工检查ChatGPT的回复,发现ChatGPT倾向于识别比标注的跨度更长的sapn,以更接近人类的偏好。因此,之前的硬匹配(hard-matching)策略可能不适合如ChatGPT的LLM,所以本文提出了一种软匹配(soft-matching)策略,算法流程如下。

该算法表明,只要生成和span和标记的span存在包含关系且达到相似度的阈值,则认为结果正确。通过软匹配策略,对重新评估ChatGPT的IE性能,得到的结果如下。
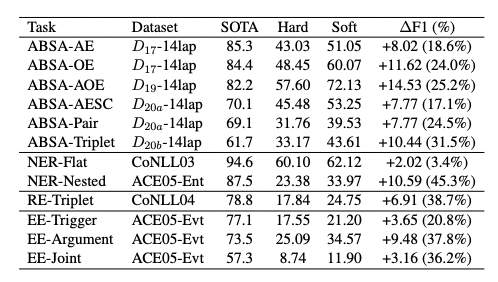
从上图可以看出,软匹配策略带来一致且显著的性能增益(F1值高达14.53),简单子任务的提升更明显。同时,虽然软匹配策略带来性能提升,但仍然没有达到SOTA水平。
3、鲁棒性分析
(1)无效输出
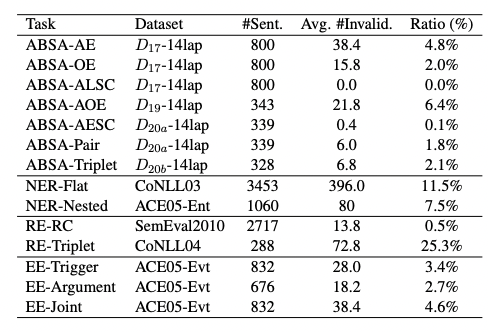
在大多数情况下,ChatGPT很少输出无效回复。然而在RE-Triplet子任务中,无效回复占比高达25.3%。一个原因可能这个子任务更加与众不同。
(2)无关上下文
由于ChatGPT对不同的提示非常敏感,本文研究了无关上下文对ChatGPT在所有IE子任务上性能的影响。主要通过在输入文本前后随机插入一段无关文本来修改zero-shot提示的“输入文本”部分,无关文本不包含要提取的目标信息span,结果如图所示。
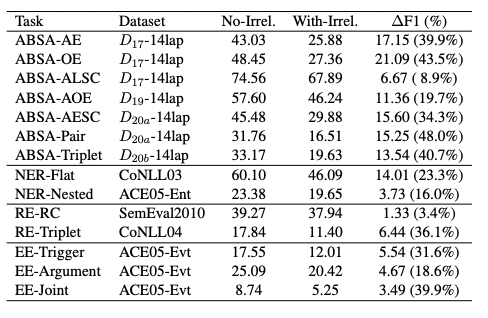
可以看出,当随机添加无关上下文时,大多数子任务的性能都会显著下降(最高可达48.0%)。ABSA-ALSC和RE-RC子任务的性能下降较小,这是因为它们基于给定的方面项或实体对进行分类,受到无关上下文的影响较小。因此,ChatGPT对无关上下文非常敏感,这会显著降低IE任务的性能。
(3)目标类型的频率
真实世界的数据通常为长尾分布,导致模型在尾部类型上的表现比在头部类型上差得多。本文研究了“目标类型的频率”对ChatGPT在所有IE子任务中的性能的影响,结果如图所示。
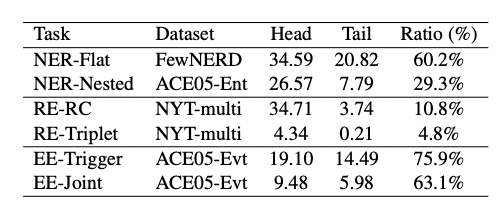
可以看出,尾部类型的性能明显不如头部类型,仅高达头部类型的75.9%。在一些子任务上,比如RE-RC和RE-Triplet,尾部类型的性能甚至低于头部类型性能的15%,所以ChatGPT也面临长尾问题的困扰。
(4)其他
本文探讨了ChatGPT是否可以区分RE-RC子任务中两个实体的主客观顺序。由于大多数关系类型都是非对称的,因此两个实体的顺序非常关键。对于非对称关系类型的每个实例,交换实体的顺序并检测预测结果的变化,结果如图所示。
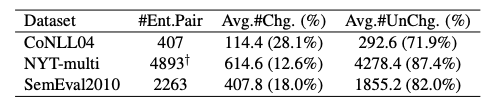
可以看到,交换顺序后大多数预测结果(超过70%)与交换前保持不变。因此对于RE-RC子任务,ChatGPT对实体的顺序不敏感,而且无法准确理解实体的主客体关系。
4、错误类型分析
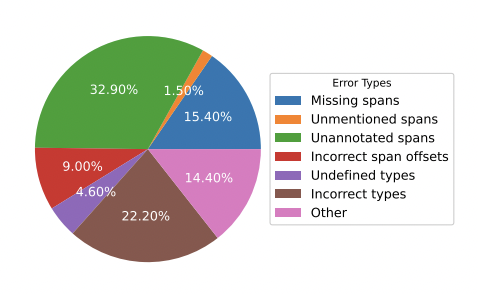
从图中可以看出,“Unannotated spans”、“Incorrect types”和“Missing spans”是三种主要的错误类型,占70%以上。特别是,几乎三分之一的错误是“Unannotated spans”的错误,这也引发了对标注数据质量的担忧。
总结
本文从性能、评估标准、鲁棒性和错误类型四个角度评估了ChatGPT的信息抽取能力,结论如下:
性能 本文评估了ChatGPT在zero-shot、few-shot和chain-of-thought场景下的17个数据集和14个IE子任务上的性能,发现ChatGPT和SOTA结果之间存在巨大的性能差距。
评估标准 本文重新审视了性能差距,发现硬匹配策略不适合评估ChatGPT,因为ChatGPT会产生human-like的回复,并提出软匹配策略,以更准确地评估ChatGPT的性能。
鲁棒性 本文从四个角度分析了ChatGPT对14个子任务的鲁棒性,包括无效输出、无关上下文、目标类型的频率和错误类型并得出以下结论:1)ChatGPT很少输出无效响应;2)无关上下文和长尾目标类型极大地影响了ChatGPT的性能;3)ChatGPT不能很好地理解RE任务中的主客体关系。
错误类型 通过人工检查,本文分析了ChatGPT的错误,总结出7种类型,包括Missing spans、Unmentioned spans、Unannotated spans、Incorrect span offsets、Undefined types、Incorrect types和other。发现“Unannotated spans”是最主要的错误类型。这引发了大家对之前标注数据质量的担心,同时也表明利用ChatGPT标记数据的可能性。
审核编辑 :李倩
-
文本信息抽取的分阶段详细介绍2019-09-16 2330
-
科技大厂竞逐AIGC,中国的ChatGPT在哪?2023-03-03 2364
-
基于子树广度的Web信息抽取2009-03-28 465
-
基于重复模式的自动Web信息抽取2009-04-10 519
-
基于XML的WEB信息抽取模型设计2009-12-22 594
-
基于WebHarvest的健康领域Web信息抽取方法2017-12-26 924
-
节点属性的海量Web信息抽取方法2018-02-06 1021
-
了解信息抽取必须要知道关系抽取2021-04-15 2927
-
基于篇章信息和Bi-GRU的事件抽取综述2021-04-23 1357
-
开放域信息抽取和文本知识结构化的3篇论文详细解析2021-04-26 3736
-
面向知识图谱的信息抽取2022-03-22 1617
-
如何统一各种信息抽取任务的输入和输出2022-09-20 2277
-
10分钟教你如何ChatGPT最详细注册教程2023-02-08 11150
-
微信接入ChatGPT 利用ChatGPT的对话能力2023-02-13 1213
-
ChatGPT Plus怎么支付 开通ChatGPT plus有什么功能?2023-10-10 6393
全部0条评论

快来发表一下你的评论吧 !
