

Lua5.4源码剖析—性能优化与原理分析
电子说
描述
测试设备
1)本文中的数据是基于我的个人电脑MacBookPro:4核2.2GHz的i7处理器;
2)在时间的测量上,为了能精确到毫秒级别,我使用了Lua自带的os.clock()函数,它返回的是一个浮点数,单位是秒数,乘1000就是对应的毫秒数,本文测试数据均以毫秒为单位。另外本文为了放大不同写法数据的性能差异,在样例比较中,通常会循环执行较多的次数来累计总的消耗进行比较。
3星优化
推荐程度:极力推荐,使用简单,且优化收益明显,每个Lua使用者都应该遵循。
1)全类型通用CPU优化——高频访问的对象,应先赋值给一个local变量再进行访问
测试样例 :用循环模拟高频访问,每轮循环中访问调用math.random函数,用它来创建一个随机数。
备注 :这里的对象,是Lua的所有类型,包括Booeal、Number、Table、Function、Thread等等。
错误写法 :
for i = 1, 1000000 do local randomVal = math.random(0, 10000)end
正确写法(把函数math.random赋值给local变量) :
local random = math.randomfor i = 1, 1000000 do local randomVal = random(0, 10000)end
测试样例及性能差异(循环100 0000次消耗):
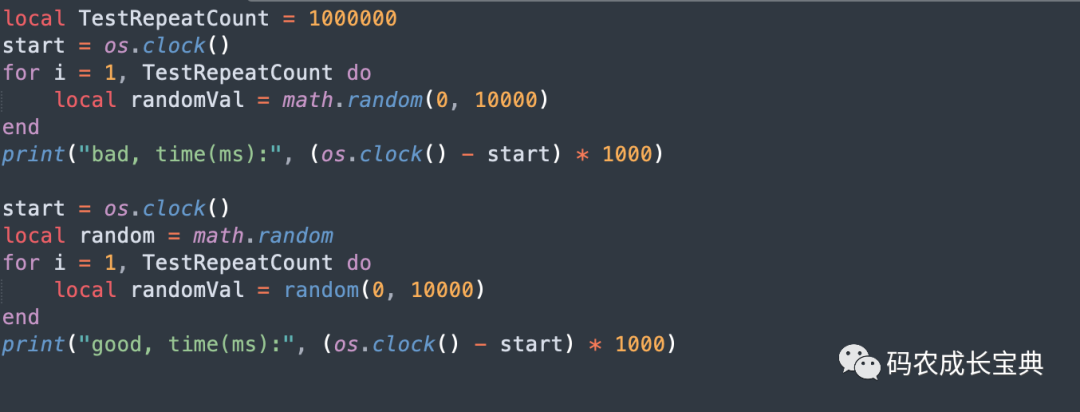
结果(耗时减少14毫秒):

原理分析 :
非local局部变量,即UpValue(全局变量其实也是记录在名为_ENV的第一个Table类型的UpValue中)的访问通常需要更多的指令操作,如果对应的UpValue是个Table的话,还需要进入Table的复杂的数据查询流程。而local变量的访问,只需要一条简单寄存器读取指令,所以能节省出数据查询带来的性能开销。
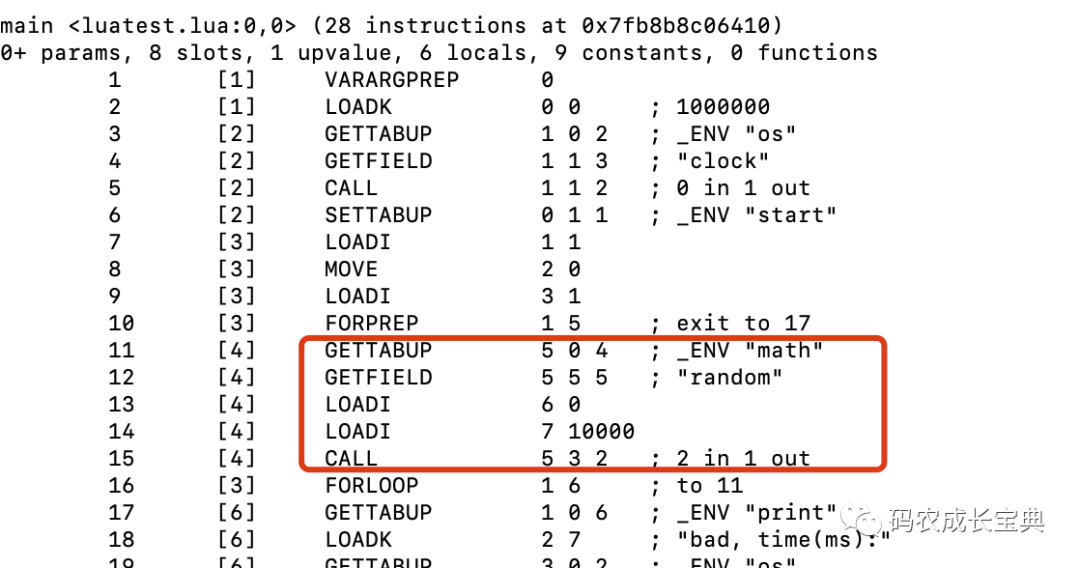
OpCode对比 :
错误写法:每次循环需要执行下面5条指令:
正确写法:每次循环只需要执行下面4条指令操作,原本复杂的函数从Table中查询定位的操作,替换成了简单的OP_MOVE寄存器赋值操作: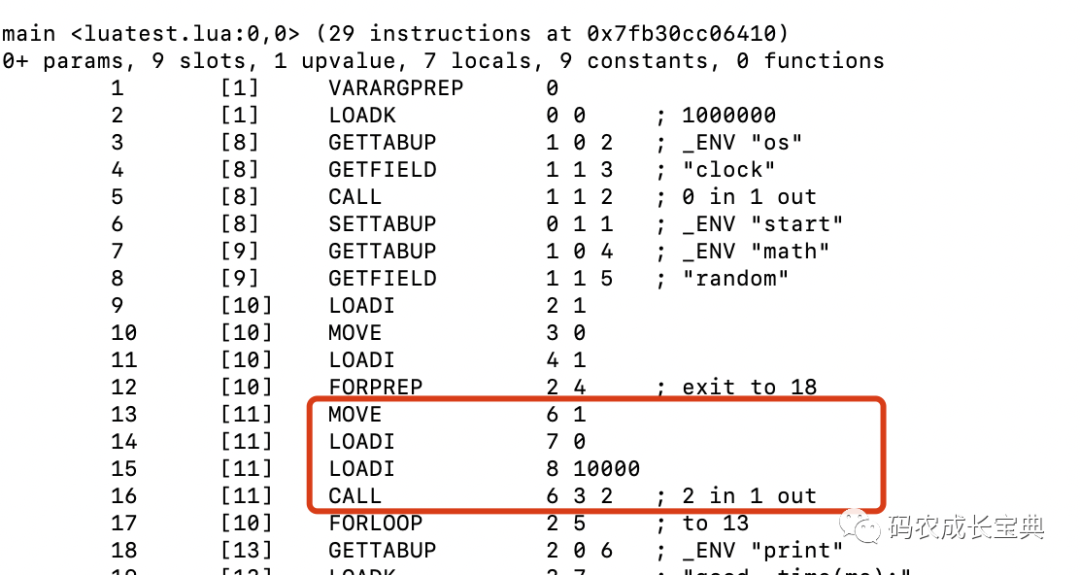
2)String类型CPU与内存优化——要拼接的字符串如果比较多,应使用table.conat函数
测试样例 :多次循环,每次拼接一个0到10000范围的随机数到目标字符串上。
错误写法 :
local random = math.randomlocal sumStr = ""for i = 1, 10000 dosumStr = sumStr .. tostring(random(0, 10000))end
正确写法 :
local random = math.randomlocal sumStr = ""local concat_list = {}for i = 1, 10000 dotable.insert(concat_list, tostring(random(0, 10000)))end
测试样例及性能差异(循环1 0000次消耗):
由于本样例会产生临时内存数据,我们统计时间消耗的时候要把GC的时间也算上,所以都先调用了collectgarbage("collect")进行强制的GC。
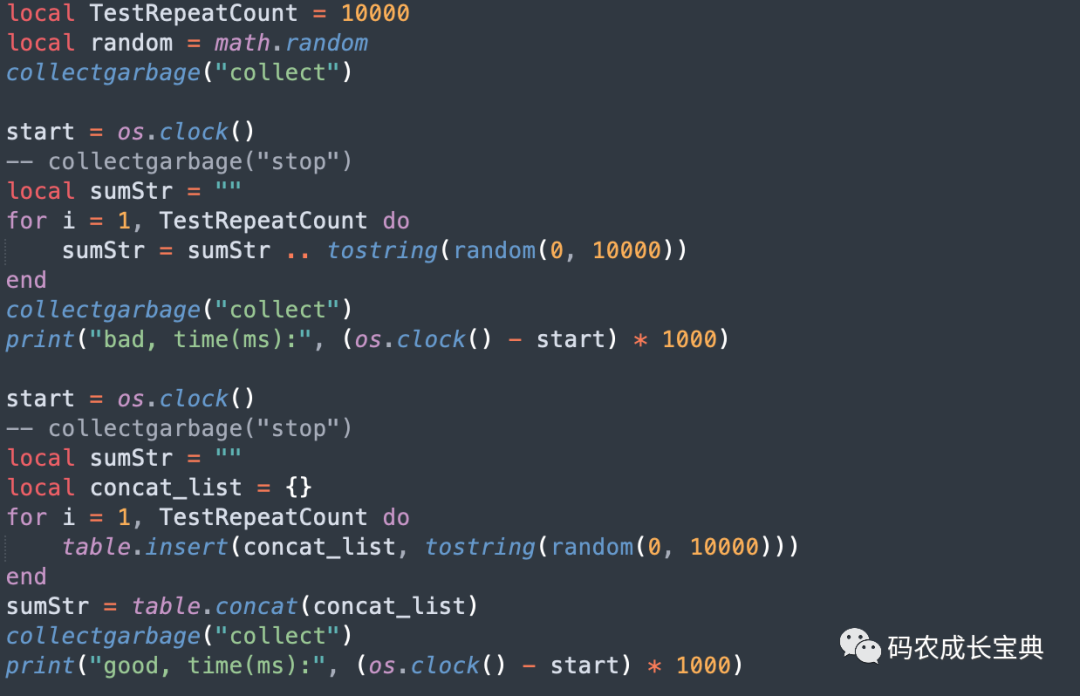
结果(循环中允许自动GC,节省18毫秒) :

特殊情况 :
若在两种写法的开头都加上collectgarbage("stop"),即把上述代码注释部分取消,在循环中就不会自动触发GC,有些开发者会控制GC时机,例如只在Loading过场的时候调用GC,所以实际中会有这种情况出现。
我们之前学习Lua字符串源码的时候知道,字符串的使用是有自动的缓存机制的,当前已经缓存住的未被GC的字符串越多,后续字符串的查询效率越低下,此时运算结果如下(循环中不自动GC,错误写法时间消耗大增,正确写法节省100毫秒):
另外,在循环中可自动GC的情况下,把测试次数由10000乘以10改成100000次时,正确写法时间消耗几乎成比例增长10倍,而错误写法则会随着拼接后的字符串越来越长,时间消耗指数性急剧上升,增长了50倍:
源码分析 :
每次有两个字符串使用".."连接符进行拼接的时候,会生成一个新的中间字符串,随着拼接的字符串长度越长,内存占用与CPU消耗越大。在上述测试样例中,我们只需要最终所有字符串的拼接结果,这些中间产物其实对我们是没有意义的;而table.concat函数则是可以一次性拼接table中所有的字符串,无中间产物,所以会对内存与CPU有较大的优化。
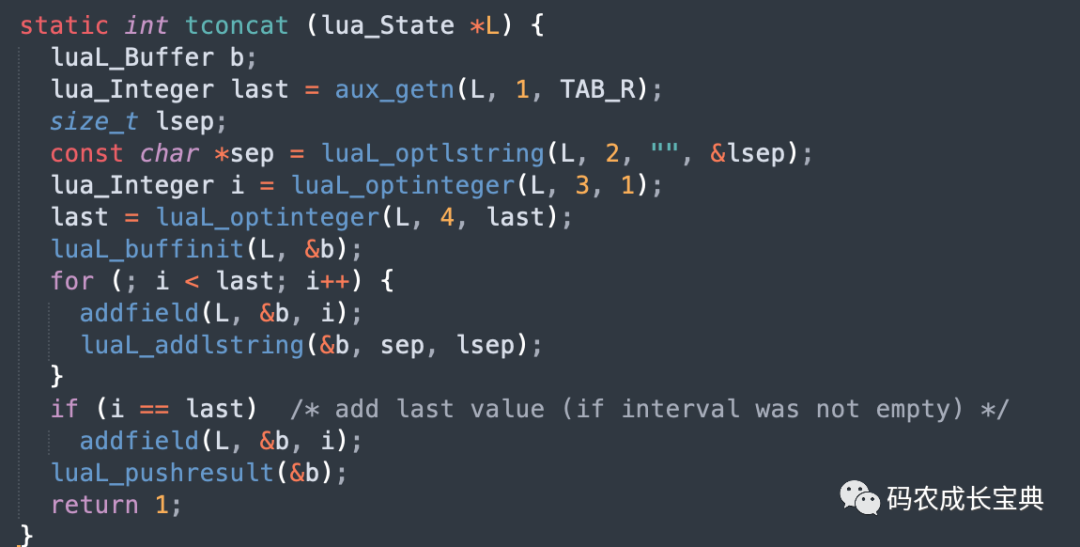
table.concat函数的实现如下,会先创建一个缓存区,把所有字符串都放到缓冲区中,放入缓冲区的时候虽然也可能触发缓冲区扩容,但比起".."连接符每次创建一个新的字符串消耗要小很多,然后拼接完成后返回仅仅一个新的字符串:
不适用的场景:
要拼接的字符串数量较少、长度较短,此时可能创建并GC回收一个Table的消耗会比直接用".."更大。
3)String类型CPU与内存优化——使用".."连接符拼接字符串应尽可能一次性把更多的待拼接的子字符串都写上
测试样例 :把数字0到5拼接成"012345"。
错误写法1 :
**
local sumStr = "0"sumStr = sumStr .. "1"sumStr = sumStr .. "2"sumStr = sumStr .. "3"sumStr = sumStr .. "4"sumStr = sumStr .. "5"
**
错误写法2(加括号其实跟独立一行运算效果差不多,只是节省了一个赋值操作的OpCode) :
local sumStr = (((("0" .. "1") .. "2") .. "3") .. "4") .. "5"正确写法 :
local sumStr = "0" .. "1" .. "2" .. "3" .. "4" .. "5"测试样例及性能差异(循环100 0000次消耗):
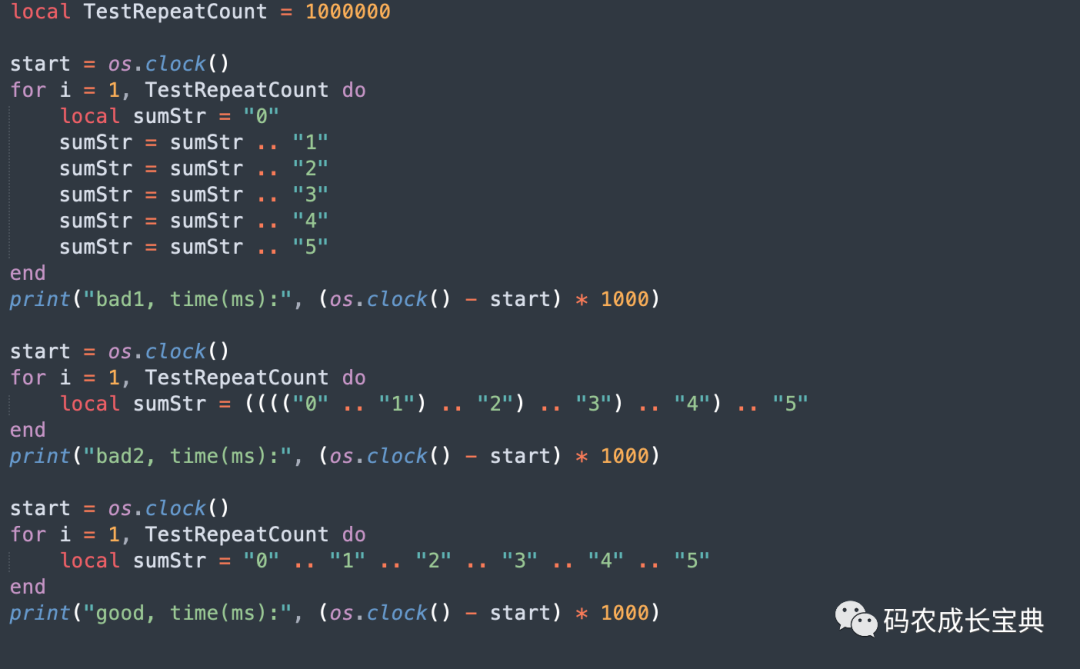
结果(耗时减少了100多毫秒,同时运算中内存占用也会大幅减少):

原理分析: ".."连接符号对应的OpCode为OP_CONCAT,它的功能不仅仅是连接两个字符串,而是会把以".."连接符号相邻的所有字符串结合为一个操作批次,把它们一次性连接起来,同时也会避免产生中间连接临时字串符。
由于字符串缓存机制的存在,在上述错误写法1、2中,会产生无用中间字符串产物:"01","012","0123","0124";它们会导致内存的上升和加重后续GC的工作量。而正确写法则只会产生最终"012345"这仅仅一个字符串。
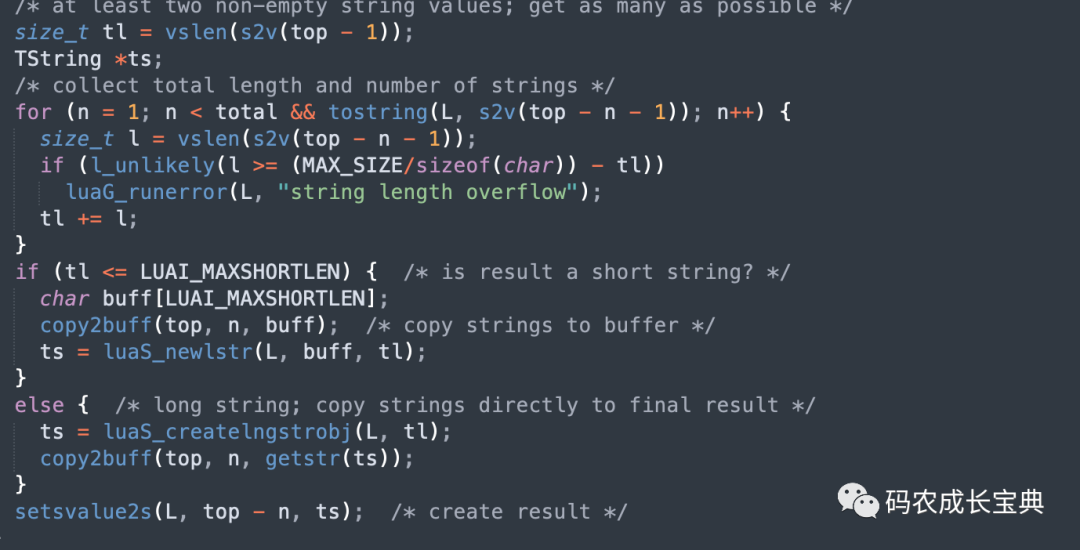
OP_CONCAT实现核心逻辑如下,会先计算出结果字符串长度,然后一次性创建出对应大小的字符串缓冲区,把所有子串放进去,然后返回仅仅一个新的字符串:
OpCode对比:
错误写法2:
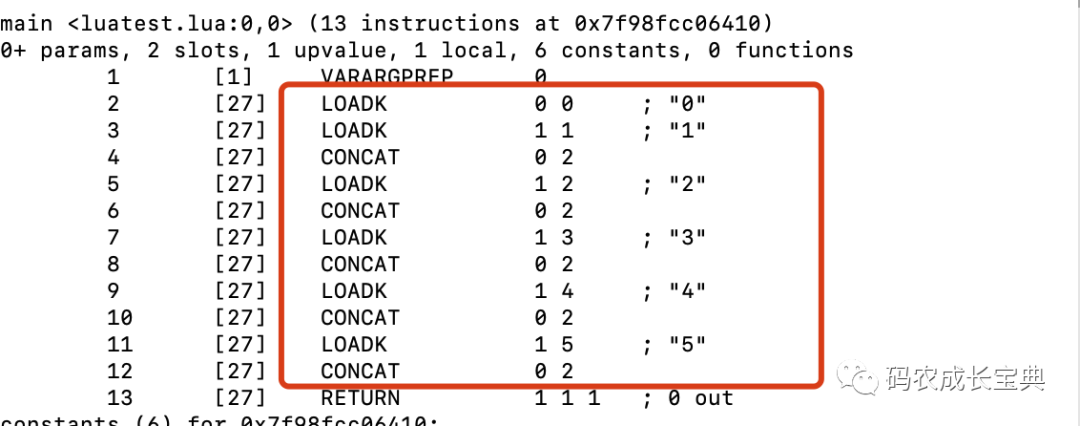
正确写法(一条OP_CONCAT就可以完成所有拼接操作):
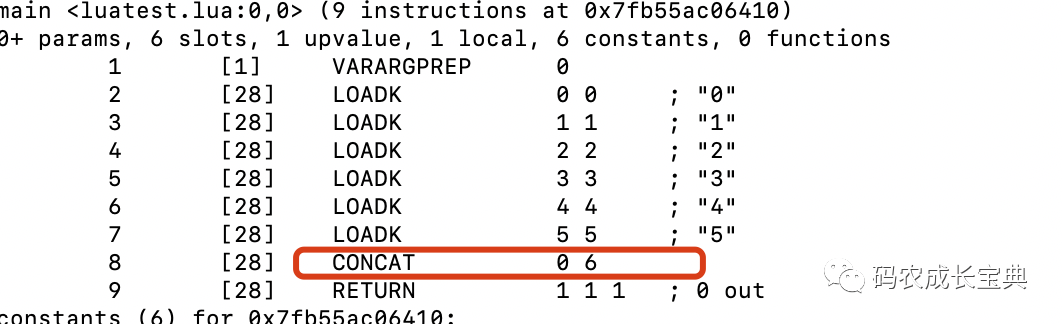
4)Table类型CPU优化——尽量在table构造时完成数据初始化
测试样例 :创建一个初始值为1, 2, 3的Table;
错误写法:
local t = {}t[1] = 1t[2] = 2t[3] = 3
正确写法:
local t = {1, 2, 3}测试样例及性能差异(循环10 0000次消耗):
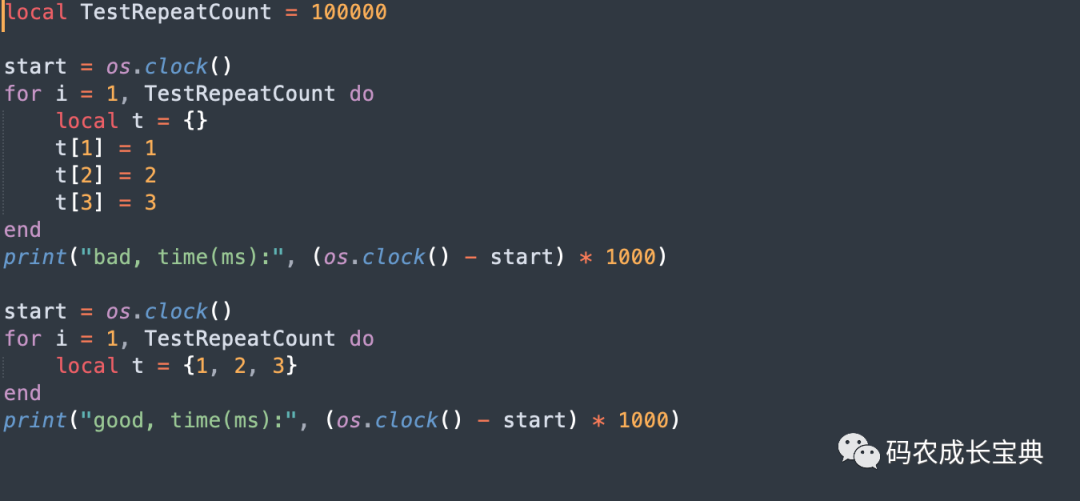
结果(节省35毫秒):

原理分析:
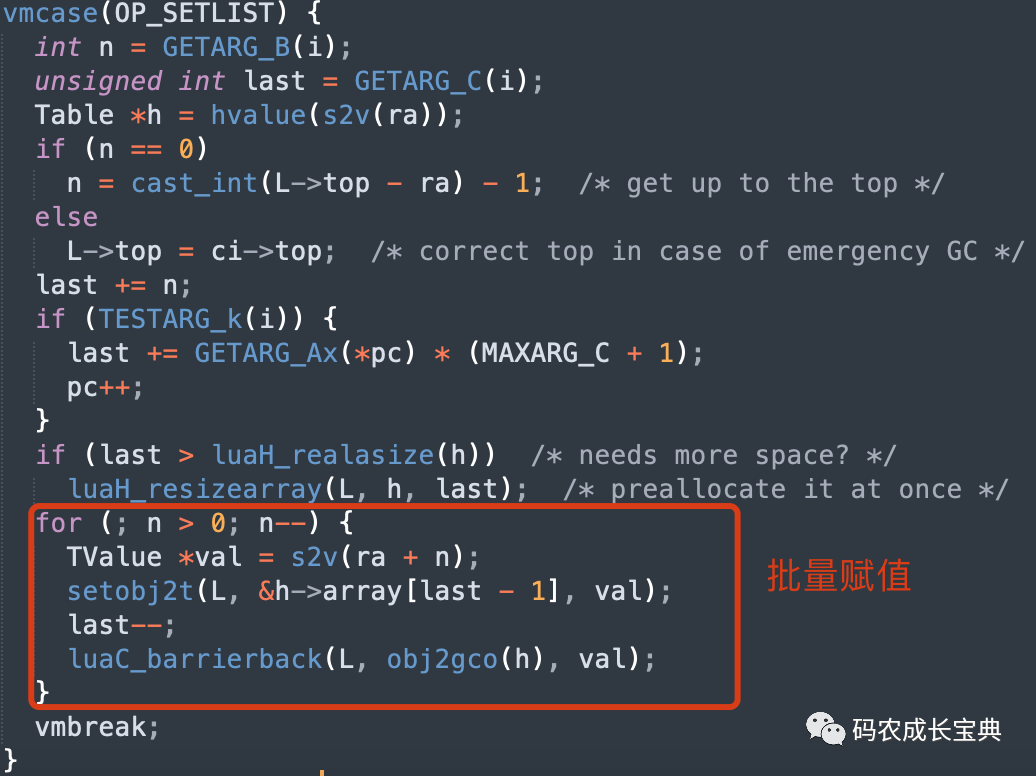
Table在使用"{}"列表形式进行赋值的时候,会把其中数组部分的所有数据合并成一条OP_SETLIST指令(哈希部分无法通过此方式优化),在里面批量一次性完成所有数组元素的赋值。而使用t[i]=value的形式进行赋值,则每次都会调用一条OpCode,会生成更多的OpCode指令。
OP_SETLIST实现如下:
OpCode对比:
错误写法:
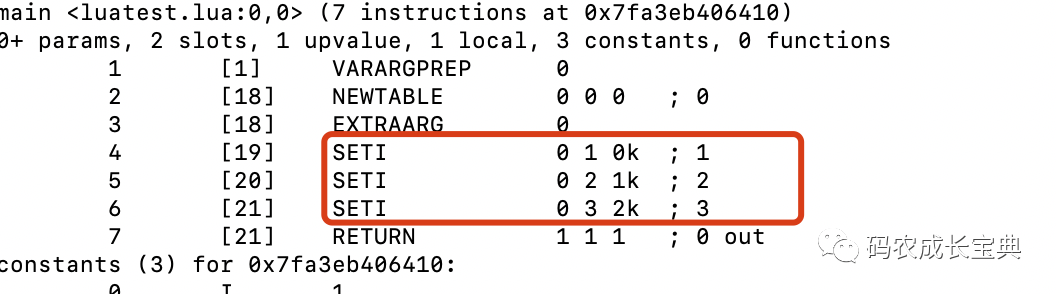
正确写法(生成的OpCode的数量虽然更多了,但OP_LOADI的消耗远比上面的OP_SETI要小):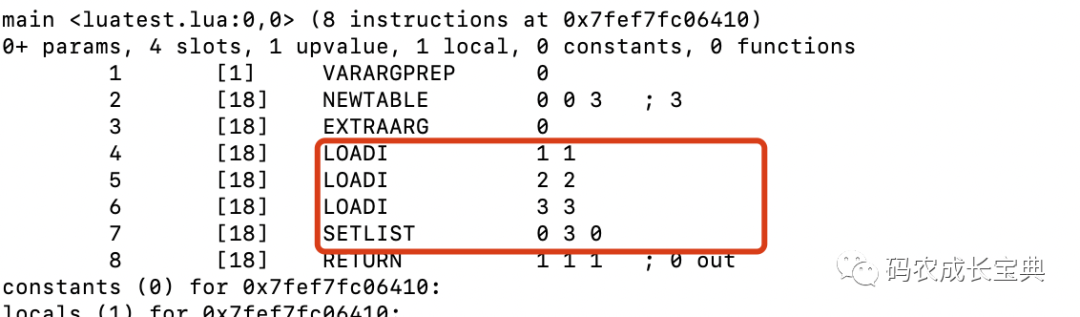
5)Table类型内存优化——Table关联到类似excel的只读数据表时,频繁出现的复杂类型数据可以单独定义为一个local变量进行复用
测试样例 :4条射线,射线用Table进行表示,它有一个起点坐标和一个方向;多数时候起点为(0, 0, 0)坐标。
错误写法:
local Ray1 = {origin = {x = 0, y = 0, z = 0},direction = {x = 1, y = 0, z = 0},}local Ray2 = {origin = {x = 0, y = 0, z = 0},direction = {x = -1, y = 0, z = 0},}local Ray3 = {origin = {x = 1, y = 0, z = 0},direction = {x = 1, y = 0, z = 0},}local Ray4 = {origin = {x = 1, y = 0, z = 0},direction = {x = -1, y = 0, z = 0},}
正确写法:
local x0_y0_z0 = {x = 0, y = 0, z = 0}local x1_y0_z0 = {x = 1, y = 0, z = 0}local xn1_y0_z0 = {x = -1, y = 0, z = 0}local Ray1 = {origin = x0_y0_z0,direction = x1_y0_z0,}local Ray2 = {origin = x0_y0_z0,direction = xn1_y0_z0,}local Ray3 = {origin = x1_y0_z0,direction = x1_y0_z0,}local Ray4 = {origin = x1_y0_z0,direction = xn1_y0_z0,}
原理分析:
正确写法在数据赋值的时候效率也会更高,不过该优化更多的是针对内存。被复用的复杂结构对象单独定义,然后用到的每个对象实例只存储它的一个引用,避免了重复的数据定义,能极大降低内存占用。
6)Table类型内存优化——Table关联到类似excel的只读数据表时,默认值的查询可以使用元表和__index元方法
测试样例 :班级内部有一个学生信息表,学生有姓名,年龄,年级。该界学生默认且最多都是12岁,上6年级。本例班级中有3名学生,其中2名学生信息都与默认值一致,另外一名年纪与默认值不一致。
错误写法:
local Students1 = {name = "小明",age = 12,grade = 6}local Students2 = {name = "小红",age = 12,grade = 6}local Students3 = {name = "小刚",-- 小刚年纪比同一届的其它同学大一点点age = 13,grade = 6}
正确写法:
local StudentsDefault = {__index = {age = 12,grade = 6}}local Students1 = {name = "小明",}setmetatable(Students1, StudentsDefault)local Students2 = {name = "小红",}setmetatable(Students2, StudentsDefault)local Students3 = {name = "小刚",-- 小刚年纪比同一届的其它同学大一点点age = 13,}setmetatable(Students3, StudentsDefault)
原理分析:
把所有对象的字段默认值独立出来进行定义,不用每个对象都定义一堆相同的字段,当字段与默认值不一致时才需要重新定义,减少了重复数据的内存占用。当对一个对象实例查询其字段数据的时候,若字段未定义,则代表该字段没有或者采用了默认值,此时会通过元方法__index在默认值元表对象中进行查询,以多一层的数据查询性能开销换来内存的大幅减少。
7)Function类型 内存、堆栈优化—— 函数递归调用时尽量使用尾调用的方式
测试样例 :以函数递归的方式求1,2,...到n的和。
错误写法:
local function BadRecursionFunc(n)if n > 1 thenreturn n + BadRecursionFunc(n - 1)endreturn 0end
正确写法:
local function GoodRecursionFunc(sum, n)if n > 1 thenreturn GoodRecursionFunc(sum + n, n - 1)endreturn sum, 0end
当n为10 0000:
结果如下(节省14毫秒):

当n为100 0000:
错误写法会直接报错,Lua运行堆栈溢出了:

而正确写法能正常运算出结果,消耗为26毫秒:

原理分析:
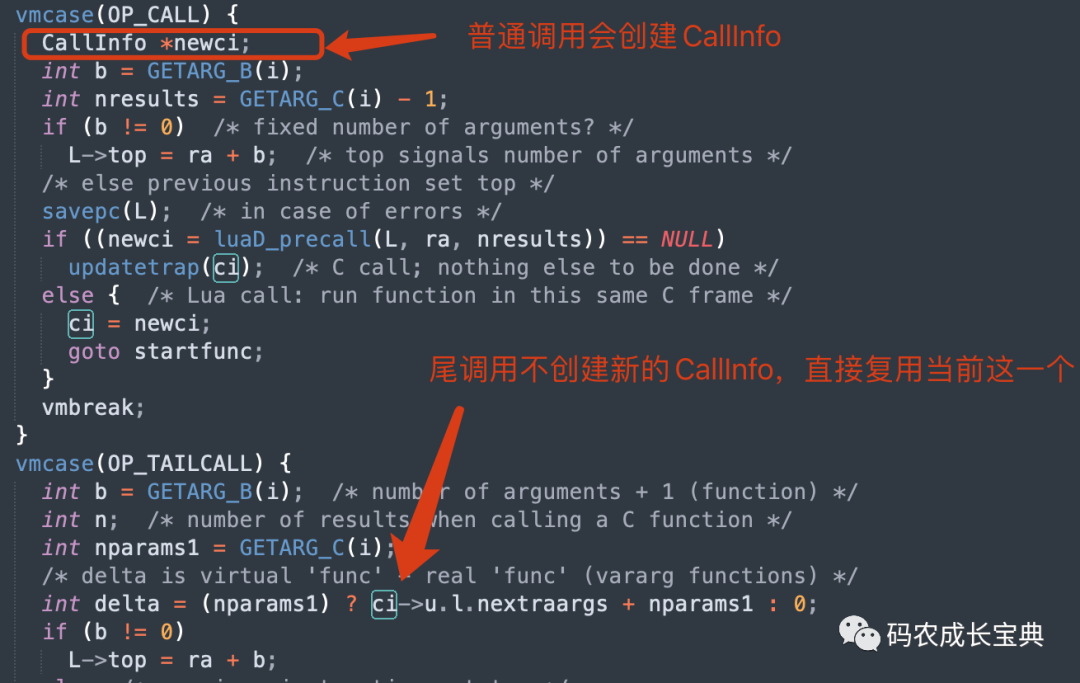
Lua的函数调用在return 的时候,若直接单纯调用另外一个函数,则会使用尾调用的方式,在尾调用模式下,会复用之前的CallInfo与函数堆栈。所以无论样例中的n多大、递归层次多深,都不会造成堆栈溢出。
OpCode实现对比,OP_CALL为普通函数调用,会创建CallInfo;OP_TAILCALL为尾调用,直接复用CallInfo:
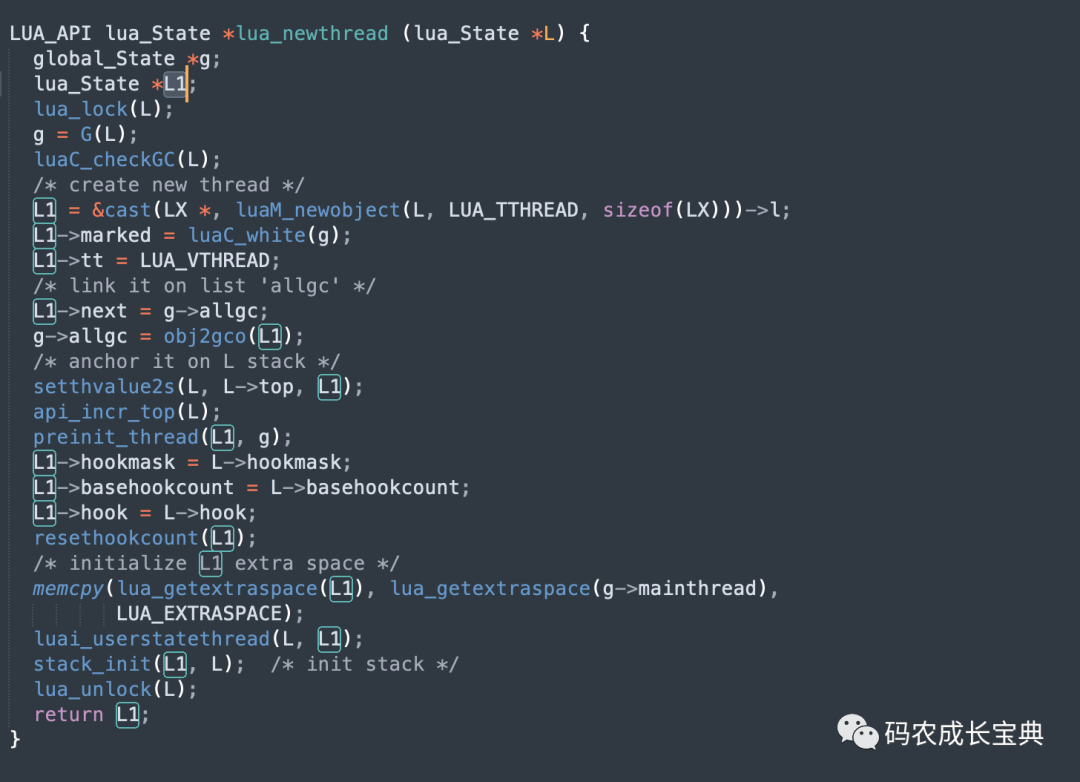
8)Thread类型CPU、内存优化——不需要多个协程并行运行时,尽量复用同一个协程,协程的创建与销毁开销较大
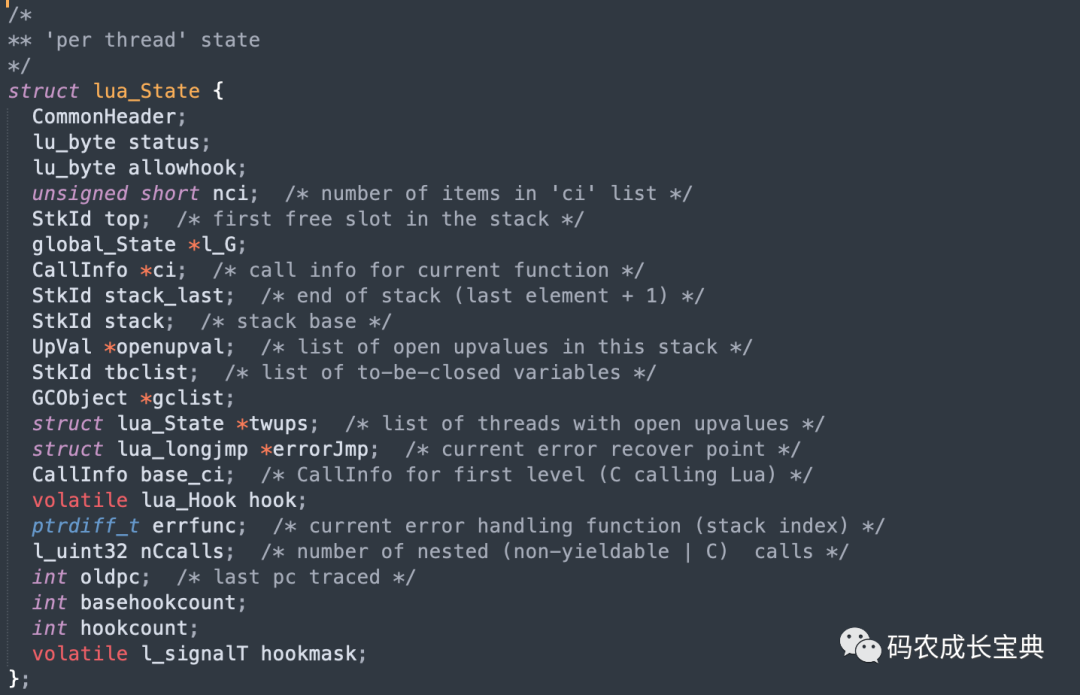
Lua中Thread类型其实就是协程(Coroutine),每一个协程的创建都会创建一个lua_State对象,该对象字段繁多,初始化或者销毁逻辑复杂,定义如下图:
测试样例 :用协程执行3个不同的函数,但不要求它们同时并行执行。
错误写法:
local function func1()endlocal function func2()endlocal function func3()endlocal ff = coroutine.wrap(func1)f()f = coroutine.wrap(func2)f()f = coroutine.wrap(func3)f()
正确写法(复用同一个协程,下面的co变量):
local function func1()endlocal function func2()endlocal function func3()endlocal co = coroutine.create(function(f)while(f) dof = coroutine.yield(f())endend)coroutine.resume(co, func1)coroutine.resume(co, func2)coroutine.resume(co, func3)
测试样例及性能差异(循环1 0000次消耗):
结果(节省18毫秒):

原理分析:
每一个协程的创建都会创建出一个lua_State对象,如上面的定义,它字段繁多,而且逻辑复杂,创建与销毁的开销极大。协程创建的时候最终会创建Thread类型对象,源码实现如下,会创建一个lua_State:
所以通过特定的写法重复使用同一个协程能极大优化性能与内存。
2星优化
推荐程度:较为推荐,使用简单,但优化收益一般。
1)Table类型CPU优化——数据插入尽量使用t[key]=value的方式而不使用table.insert函数
测试样例 :把1到1000000之间的数字插入到table中。
错误写法:
local t = {}
local table_insert_func = table.insert
for i = 1, 1000000 do
table_insert_func(t, i)
end
正确写法:
local t = {}for i = 1, 1000000 dot[i] = iend
测试样例及性能差异(循环100 0000次消耗):
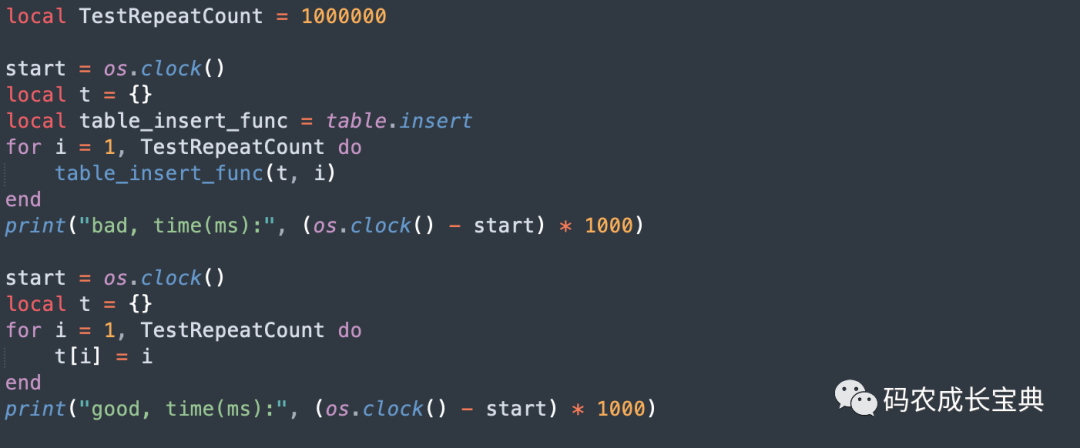
结果(节省40毫秒):

原理分析:
通过t[integer_key]=value或者t[string_key]=value的方式插入数据,只会生成OP_SETI或者OP_SETFIELD一条OpCode,会直接往Table的数组或哈希表部分插入数据;而通过table.insert函数插入数据,会多出以下这堆逻辑:1)table.insert这一个函数的查询定位(上述样例中使用local缓存优化了);
2)暂不考虑table.insert函数的逻辑,单纯函数的调用就会有创建CallInfo,参数准备,返回处理等固定开销;3)table.insert函数对参数的判断与table类型对象的获取与转化;4)为了在table的最尾端插入数据,需要计算table当前的数组部分长度;
OpCode对比:
错误写法(table.insert):

正确写法(t[i]=value):

明显使用t[key]=value方式插入数据能减少较多的指令或逻辑,对CPU优化有一定效果。
1星优化
推荐程度:一般推荐,某种程度上来说属于吹毛求疵,有一定优化收益,但可能影响可读性、或者需要特定场景配合实现。
1)全类型通用CPU优化——变量尽量在定义的同时完成赋值
测试样例: 把变量a初始化为一个整数。
错误写法:
local aa = 1
正确写法:
local a = 1测试样例及性能差异(循环100 0000次消耗):

结果(耗时减少了2毫秒):

原理分析:
错误写法中第一行的local a其实与local a = nil是等价的,底层会生成OP_LOADNIL这条OpCode,来创建出一个nil对象,第二行则又调用了另一条OpCode完成真正赋值;而正确写法中则会省略掉第一条的OP_LOADNIL。
OpCode对比:
错误写法(2条OpCode,分别对应nil类型的创建与整数的加载赋值):

正确写法(只生成一条整数加载的OpCode):

2)Nil类型CPU优化——nil对象在定义的时候尽量相邻,中间不要穿插其它对象
测试样例 :定义6个变量,其中3个为nil,3个为整数100。
错误写法:
local a = nillocal b = 100local c = nillocal d = 100local e = nillocal f = 100
正确写法(把nil的赋值排在相邻的位置):
local a = nillocal c = nillocal e = nillocal b = 100local d = 100local f = 100
测试样例及性能差异(循环100 0000次消耗):
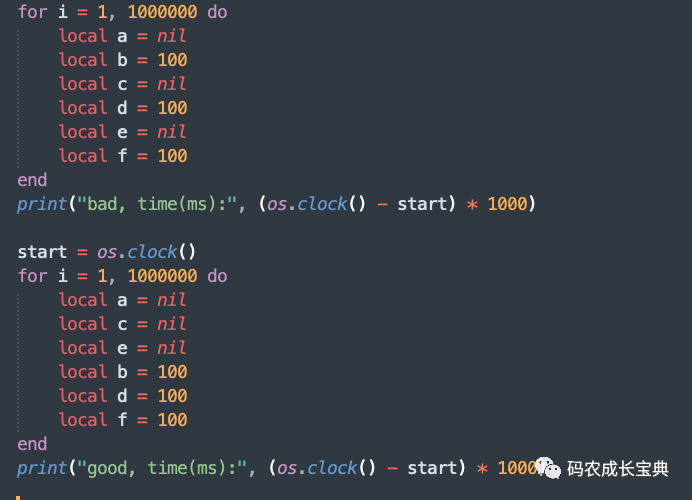
结果(耗时减少了4毫秒):

原理分析:
赋值或者加载一个nil对象的OpCode为OP_LOADNIL,它支持把栈上面连续的一定数量的对象都设置为nil。若中间被隔开了,则后面的调用需要重新生成OP_LOADNIL。
OP_LOADNIL实现:
OpCode对比:
错误写法:
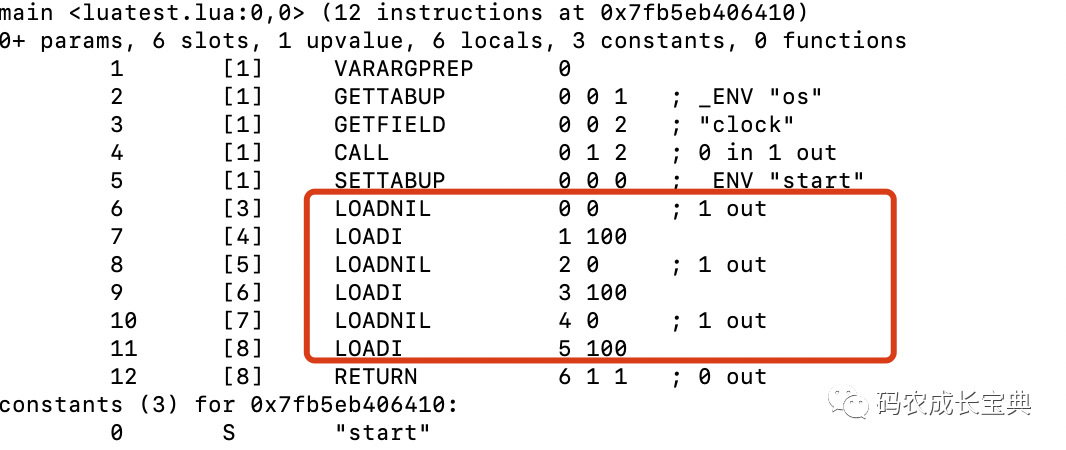
正确写法(3条OP_LOADNIL合成了一条):
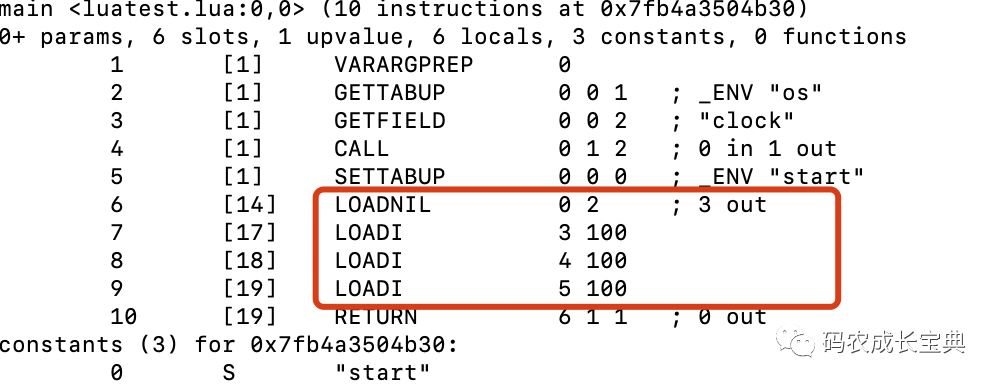
3)Function类型CPU优化——不返回多余的返回值
测试样例 :外部对函数进行调用,只请求获取第一个返回值。
错误写法(返回了多余的对象):
local function BadRetFunc()local value1 = 1local value2 = 2local value3 = 3local value4 = 4local value5 = 5return value1, value2, value3, value4, value5endlocal ret = BadRetFunc()
正确写法(外部调用者需要多少个返回值就返回多少个):
local function GoodRetFunc()local value1 = 1local value2 = 2local value3 = 3local value4 = 4local value5 = 5return value1endlocal ret = GoodRetFunc()
测试样例及性能差异(循环100 0000次消耗):
结果(节省12毫秒):

原理分析:
函数返回对应的OpCode为OP_RETURN0,OP_RETURN1,OP_RETURN。它们的逻辑复杂度由小到大,消耗由小到大。返回值的增加一方面导致了调用更复杂的return的OpCode;另一方面则是调用这些return的OpCode之前,Lua需要先把所有返回值获取并放到栈的顶部,会多执行一些赋值操作。
OpCode对比:
错误写法(多了一些OP_MOVE指令的调用,另外return的OpCode为最复杂的OP_RETURN):
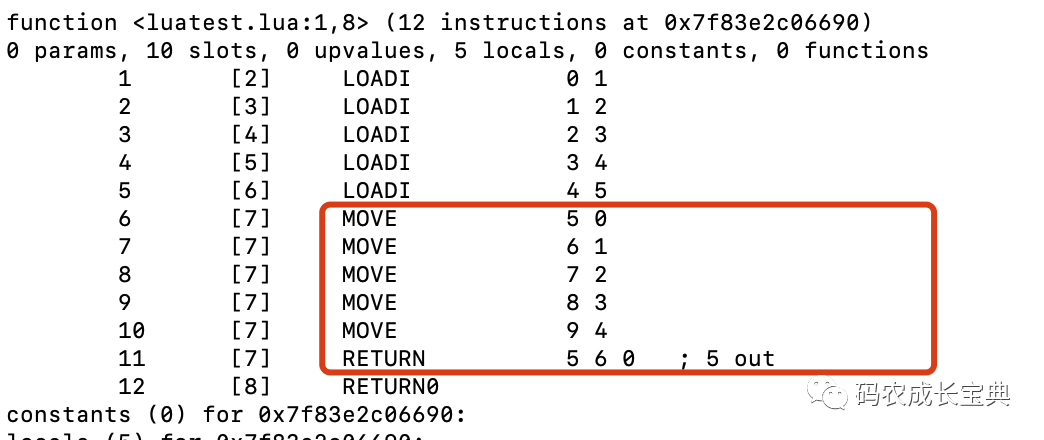
正确写法(只调用了一条更简单的return的OpCode,只需要一个返回值的OP_RETURN1):

0星优化
推荐程度:无效优化,不会带来任何性能提升,也不会有性能下降,通常使用这种写法是为了更好的代码可读性。
1)全类型通用 可读性优化—— for循环的终止条件不需要提前缓存
测试样例 :for循环,结束条件需要复杂的才能计算出来,为一个复杂函数的返回值。
错误写法:
local function ComplexGetCount()for i = 1, 100 dolocal r = math.random()endreturn 100endlocal len = ComplexGetCount()for j = 1, len doend
正确写法(不需要刻意缓存循环终止条件):
local function ComplexGetCount()for i = 1, 100 dolocal r = math.random()endreturn 100endfor j = 1, ComplexGetCount() doend
测试样例及性能差异(循环1 0000次消耗):
结果(消耗是一样的):

原理分析:
有很多一些编程语言的循环语句中,会把结束条件视作一个动态的值,每轮循环结束会重新计算该值,然后再判断循环是否终止。而在Lua中,循环表达式的终止条件是循环开始前就计算好了,只会计算一次,循环的过程中不会再被改变。
所以如果你觉得提前把循环结束条件计算出来,意图在每轮循环中避免重复计算,那么这个操作在Lua中是多余没有意义的,因为Lua语言本身就帮你做了这件事情。不过也正因如此,在Lua中无法在for 循环中动态修改循环结束条件控件循环次数。
OpCode对比:
正确写法(循环体内不会再有计算结束条件表达式的操作了):
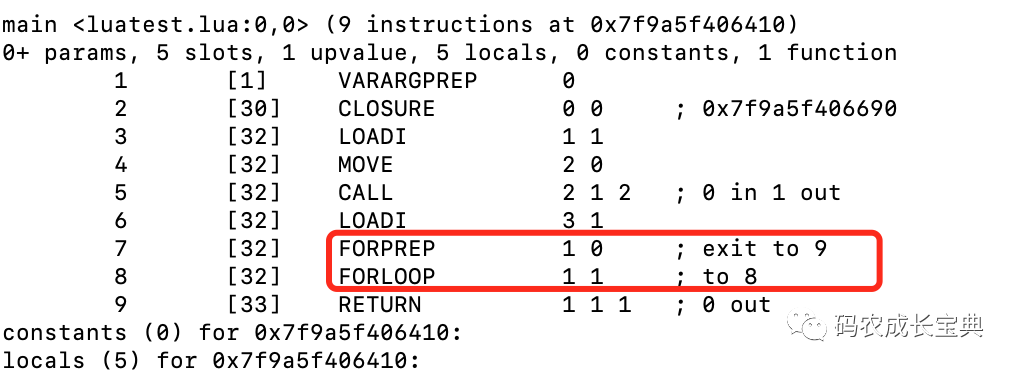
2)Nil类型可读性优化——初始化的时候显示赋值和隐式赋值效果一样
测试样例 :定义一个nil类型变量a。
写法1:
local a = nil写法2(一些人以为的更好的写法):
local a
原理分析: 无效优化,上面两种写法在底层实现中是完全一模一样的。两种写法最终都只是生成一条OP_LOADNIL的OpCode,写法1并不会因为多了赋值符号就额外多生成其它的OpCode。
总结
本文我们从源码虚拟机层面上对Lua语言多数较为有效的优化手段进行了一个学习。
-
Faster Transformer v2.1版本源码解读2023-09-19 2853
-
C++与lua联合编程2026-04-19 1377
-
PIC16LF1939的代码性能分析2020-03-10 1457
-
AN0004—AT32 性能优化2020-08-15 2033
-
重定义lua中文件操作的底层函数2021-08-20 1175
-
《现代CPU性能分析与优化》收到书了2023-04-17 1172
-
《现代CPU性能分析与优化》---精简的优化书2023-04-18 1324
-
《现代CPU性能分析与优化》--读书心得笔记2023-04-24 1144
-
使用Arm Streamline分析树莓派的性能2023-08-29 537
-
源码级和算法级的功耗测试与优化2010-03-13 1609
-
STL源码剖析的PDF电子书免费下载2020-06-29 2106
-
Faster Transformer v1.0源码详解2023-09-08 2389
-
【串口屏LUA教程】lua基础学习(借鉴)2021-04-29 1094
-
GPRS的性能分析及优化2023-11-17 406
-
探索BTH50015 - 1LUA:高效智能高侧功率开关的技术剖析2025-12-18 817
全部0条评论

快来发表一下你的评论吧 !
