

自动驾驶高精地图生成技术大揭秘
汽车电子
描述
01 背景
目前学术界和工业界(尤其自动驾驶公司)均开始研究HD地图生成,也有一些公开的学术数据集以及非常多的学术工作,此外各家自动驾驶公司也在AIDAY上公开分享技术方案。从这些公开信息来看,也观察到了一些行业趋势,例如在线建图、图像BEV感知、点图融合以及车道线矢量拓扑建模等。本文将对相关的学术工作和自动驾驶公司的技术方案进行解读,以及谈谈个人的一些思考。
02 学术数据集
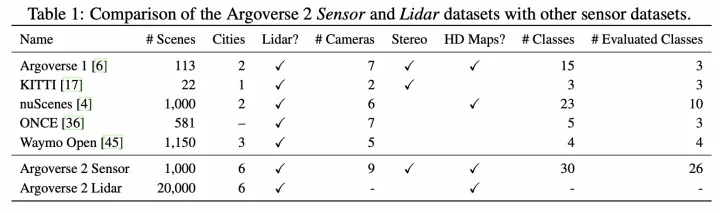 学术数据集对比 目前含HD地图的学术数据集包括:nuScenes【1】以及Argoverse2【2】。着重介绍下Argoverse2数据集,该数据集包含信息非常丰富:
学术数据集对比 目前含HD地图的学术数据集包括:nuScenes【1】以及Argoverse2【2】。着重介绍下Argoverse2数据集,该数据集包含信息非常丰富:
包括车道线、道路边界、人行横道、停止线等静态地图要素,其中几何均用3D坐标表示,并且同时包含了实物车道线和虚拟车道线;
提供了密集的地面高度图(30cm),通过地面高度可以仅保留地面的点云,便于处理地面上的地图要素;
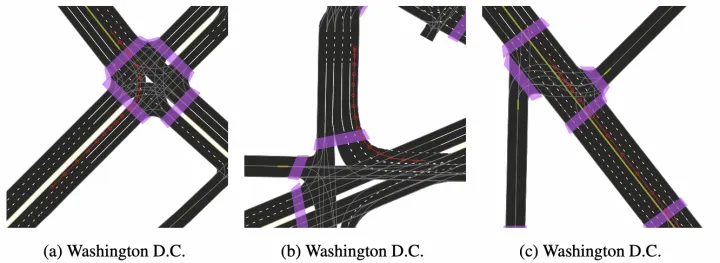 Argoverse2的HD地图
Argoverse2的HD地图
03 学术工作
该领域目前是自动驾驶公司的关注重点,因此相关学术工作基本都来自高校和车企合作,目前已经公开的论文,包括理想、地平线和毫末智行等车企。 而这些学术工作的技术方案整体可以概括为两部分:(1)BEV特征生成(2)地图要素建模。 04 BEV特征生成
在BEV空间进行在线建图,已经是目前学术界和业界的统一认识,其优势主要包括:
减少车辆俯仰颠簸导致的内外八字抖动,适合车道线这种同时在道路中间以及两边存在的物体;
远近检测结果分布均匀,适合车道线这种细长物体;
便于多相机和时序融合,适合车道线这种可能在单帧遮挡看不见或单视角相机下拍摄不全的物体;
而在如何生成BEV特征上,不同论文的方法有些许区别。 HDMapNet【3】(来自清华和理想),采用了点图融合方式生成BEV特征,其中点云分支使用PointPillar【4】+PointNet【5】方式提取特征,图像分支则使用MLP方式实现PV2BEV转换,即将PV空间到BEV空间的变换看作变换矩阵参数,并通过MLP去学习(拟合)该参数。 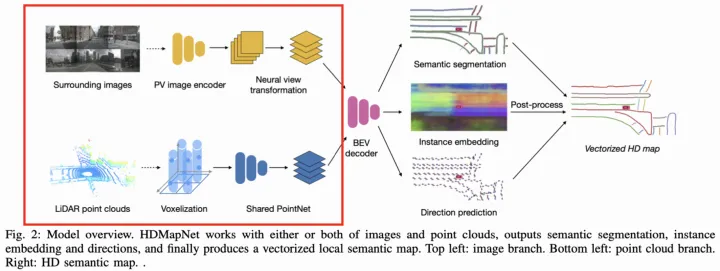 HDMapNet架构图 其中环视图像经过PV2BEV转换,实现了不同视角相机的图像特征融合。
HDMapNet架构图 其中环视图像经过PV2BEV转换,实现了不同视角相机的图像特征融合。 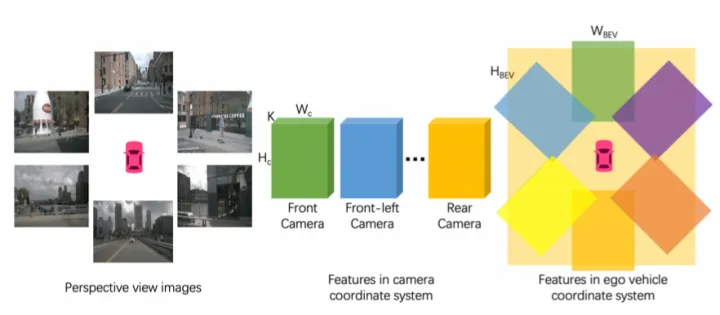 HDMapNet的环视相机特征融合 VectorMapNet【6】是HDMapNet的后续工作(来自清华和理想),同样采用了点图融合方式生成BEV特征,区别在于对图像分支采用IPM+高度插值方式实现PV2BEV转换。IPM是传统的PV2BEV转换方法,但需要满足地面高度平坦的假设。现实中,该假设通常较难满足,因此该工作假设了4个不同地面高度下(-1m,0m,1m,2m)的BEV空间,分别将图像特征经过IPM投影到这些BEV空间上,然后将这些特征concatenate起来得到最终的BEV特征。
HDMapNet的环视相机特征融合 VectorMapNet【6】是HDMapNet的后续工作(来自清华和理想),同样采用了点图融合方式生成BEV特征,区别在于对图像分支采用IPM+高度插值方式实现PV2BEV转换。IPM是传统的PV2BEV转换方法,但需要满足地面高度平坦的假设。现实中,该假设通常较难满足,因此该工作假设了4个不同地面高度下(-1m,0m,1m,2m)的BEV空间,分别将图像特征经过IPM投影到这些BEV空间上,然后将这些特征concatenate起来得到最终的BEV特征。 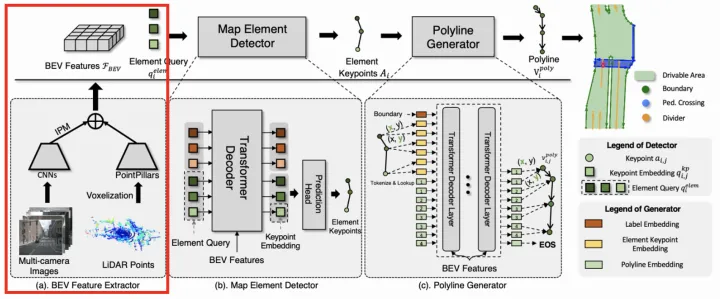 VectorMapNet架构图 MapTR【7】(来自地平线)则是只采用了图像分支生成BEV特征,利用他们之前提出的GKT【8】实现PV2BEV转换。对于BEV Query,先通过相机内外参确定在图像的先验位置,并且提取附近的Kh×Kw核区域特征,然后和BEV Query做Cross-Attention得到BEV特征。
VectorMapNet架构图 MapTR【7】(来自地平线)则是只采用了图像分支生成BEV特征,利用他们之前提出的GKT【8】实现PV2BEV转换。对于BEV Query,先通过相机内外参确定在图像的先验位置,并且提取附近的Kh×Kw核区域特征,然后和BEV Query做Cross-Attention得到BEV特征。 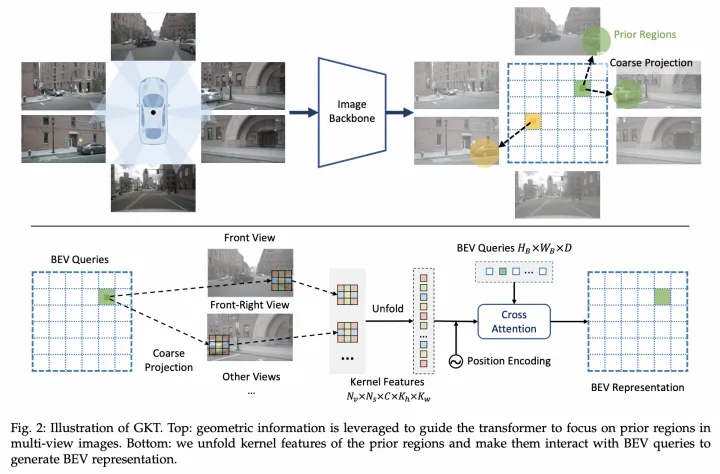 GKT架构图 SuperFusion【9】(来自毫末智行)提出了长距离的车道拓扑生成方案,并且相应地采用多层级的点云和图像特征融合来生成BEV特征(类似CaDDN【14】将深度图分布和图像特征外积得到视椎体特征,再通过voxel pooling方式生成BEV特征)。其中点云分支提取特征方式和HDMapNet一致,而图像分支则基于深度估计实现PV2BEV转换。
GKT架构图 SuperFusion【9】(来自毫末智行)提出了长距离的车道拓扑生成方案,并且相应地采用多层级的点云和图像特征融合来生成BEV特征(类似CaDDN【14】将深度图分布和图像特征外积得到视椎体特征,再通过voxel pooling方式生成BEV特征)。其中点云分支提取特征方式和HDMapNet一致,而图像分支则基于深度估计实现PV2BEV转换。 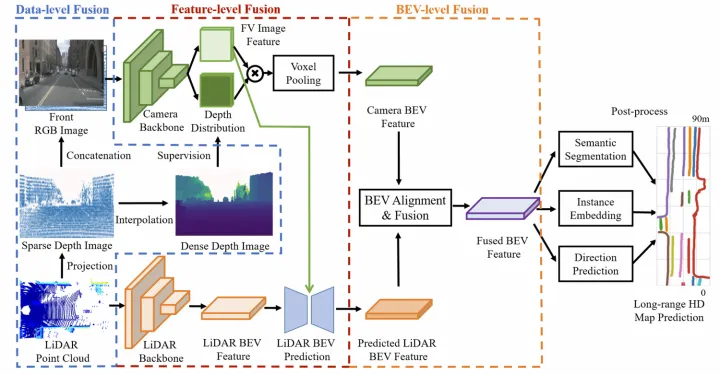 SuperFusion架构图 其多层级的点图特征融合,包括data-level,feature-level以及bev-level:
SuperFusion架构图 其多层级的点图特征融合,包括data-level,feature-level以及bev-level:
Data-level特征融合:将点云投影到图像平面得到sparse深度图,然后通过深度补全得到dense深度图,再将sparse深度图和原图concatenate,并用dense深度图进行监督训练;
Feature-level特征融合:点云特征包含距离近,而图像特征包含距离远,提出了一种图像引导的点云BEV特征生成方式,即将FV图像特征作为K和V,将点云的BEV特征作为Q去和图像特征做cross-attention得到新的BEV特征,并经过一系列卷积操作得到最终的点云BEV特征;
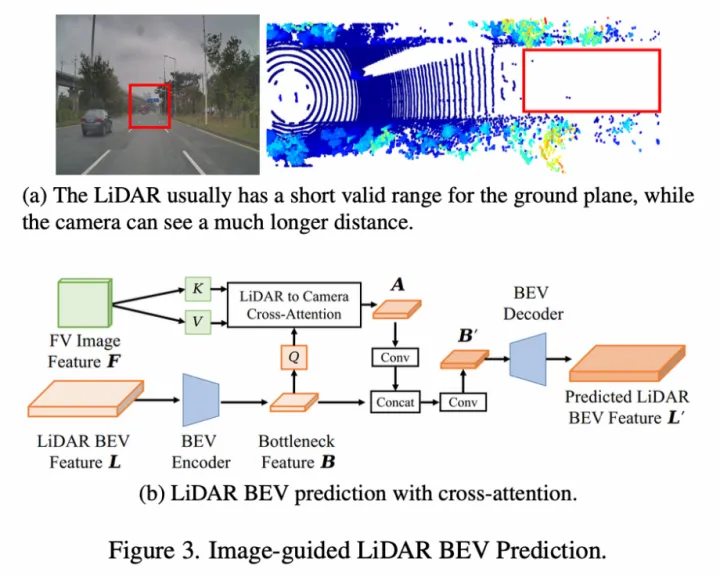 SuperFusion的Feature-level特征融合
SuperFusion的Feature-level特征融合
BEV-level特征融合:由于深度估计误差和相机内外参误差,直接concatenate图像和点云的BEV特征会存在特征不对齐问题。提出了一种BEV对齐方法,即将图像和点云BEV特征先concat后学习flow field,然后将该flow field用于图像BEV特征的warp(根据每个点的flow field进行双线性插值),从而生成对齐后的图像BEV特征;
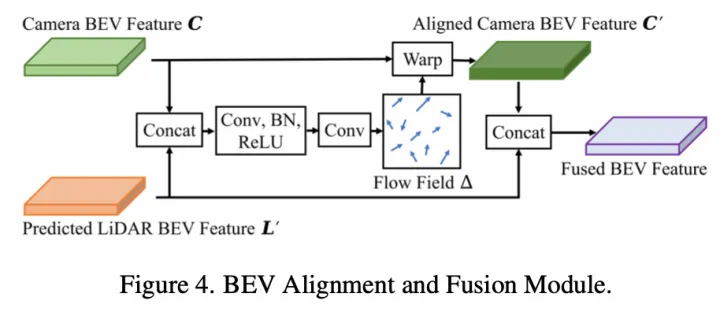 SuperFusion的BEV-level特征融合 05 地图要素建模
SuperFusion的BEV-level特征融合 05 地图要素建模
关于地图要素的建模方式,目前学术界趋势是由像素到矢量点的逐渐转变,主要考虑是有序矢量点集可以统一表达地图要素以及拓扑连接关系。
HDMapNet采用像素方式建模车道线,引入语义分割、实例Embedding以及方向预测head分别学习车道线的语义像素位置、实例信息以及方向,并通过复杂的后处理(先采用DBSCAN对实例Embedding进行聚类,再采用NMS去除重复实例,最后通过预测的方向迭代地连接pixel),从而实现最终的车道线矢量化表达。 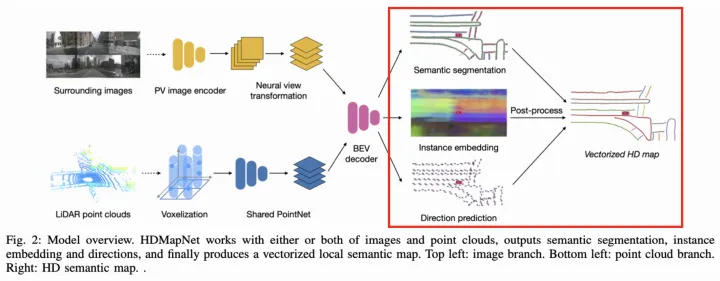 HDMapNet架构图 VectorMapNet采用矢量点方式建模车道线,并拆解成Element检测阶段和Polyline生成阶段。
HDMapNet架构图 VectorMapNet采用矢量点方式建模车道线,并拆解成Element检测阶段和Polyline生成阶段。 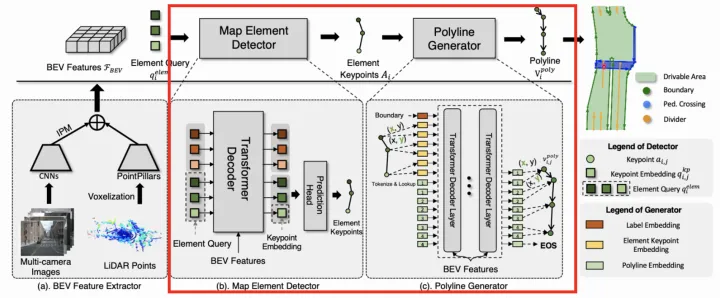 VectorMapNet架构图 Element检测阶段的目标是检测并分类全部的Map Element,采用了DETR【11】这种set prediction方式,即引入可学习的Element Query学习Map Element的关键点位置和类别。作者尝试了多种定义关键点的方式,最终Bounding Box方式最优。
VectorMapNet架构图 Element检测阶段的目标是检测并分类全部的Map Element,采用了DETR【11】这种set prediction方式,即引入可学习的Element Query学习Map Element的关键点位置和类别。作者尝试了多种定义关键点的方式,最终Bounding Box方式最优。  关键点表示方式 Polyline生成阶段的目标是基于第一阶段输出的Map Element的类别和关键点,进一步生成Map Element的完整几何形状。将Polyline Generator建模成条件联合概率分布,并转换成一系列的顶点坐标的条件分布乘积,如下:
关键点表示方式 Polyline生成阶段的目标是基于第一阶段输出的Map Element的类别和关键点,进一步生成Map Element的完整几何形状。将Polyline Generator建模成条件联合概率分布,并转换成一系列的顶点坐标的条件分布乘积,如下: 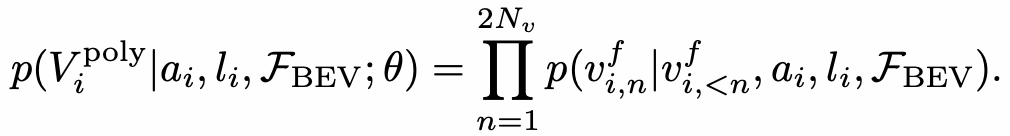 Polyline Generator建模 进而使用自回归网络对该分布进行建模,即在每个步骤都会预测下一个顶点坐标的分布参数,并预测End of Sequence token (EOS) 来终止序列生成。整个网络结构采用普通的Transformer结构,每根线的关键点坐标和类标签被token化,并作为Transformer解码器的query输入,然后将一系列顶点token迭代地输入到Transformer解码器中,并和BEV特征做cross-attention,从而解码出线的多个顶点。 MapTR同样采用矢量点方式建模车道线,提出了等效排列建模方式来消除矢量点连接关系的歧义问题,并且相应地设计了Instance Query和Point Query进行分层二分图匹配,用于灵活地编码结构化的地图信息,最终实现端到端车道线拓扑生成。
Polyline Generator建模 进而使用自回归网络对该分布进行建模,即在每个步骤都会预测下一个顶点坐标的分布参数,并预测End of Sequence token (EOS) 来终止序列生成。整个网络结构采用普通的Transformer结构,每根线的关键点坐标和类标签被token化,并作为Transformer解码器的query输入,然后将一系列顶点token迭代地输入到Transformer解码器中,并和BEV特征做cross-attention,从而解码出线的多个顶点。 MapTR同样采用矢量点方式建模车道线,提出了等效排列建模方式来消除矢量点连接关系的歧义问题,并且相应地设计了Instance Query和Point Query进行分层二分图匹配,用于灵活地编码结构化的地图信息,最终实现端到端车道线拓扑生成。 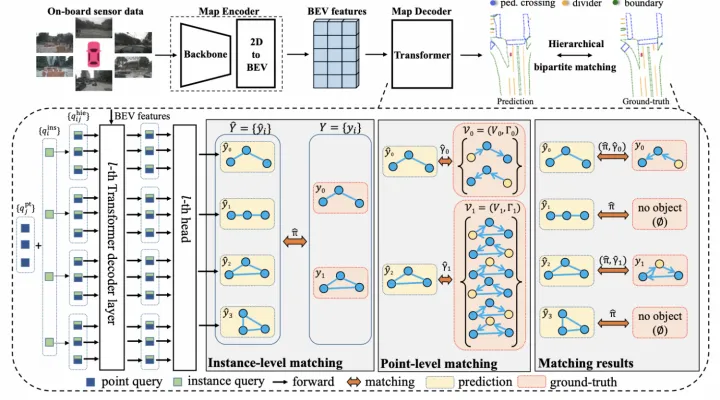 MapTR架构图 等效排列建模就是将地图要素的所有可能点集排列方式作为一组,模型在学习过程中可以任意匹配其中一种排列真值,从而避免了固定排列的点集强加给模型监督会导致和其他等效排列相矛盾,最终阻碍模型学习的问题。
MapTR架构图 等效排列建模就是将地图要素的所有可能点集排列方式作为一组,模型在学习过程中可以任意匹配其中一种排列真值,从而避免了固定排列的点集强加给模型监督会导致和其他等效排列相矛盾,最终阻碍模型学习的问题。 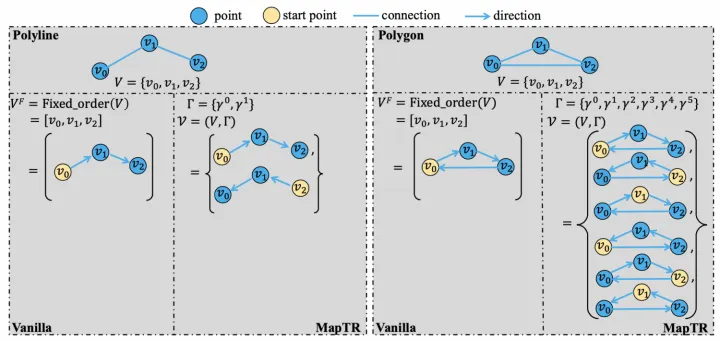 等效排列建模 分层二分图匹配则同样借鉴了DETR这种set prediction方式,同时引入了Instance Query预测地图要素实例,以及Point Query预测矢量点,因此匹配过程也包括了Instance-level匹配和Point-level匹配。匹配代价中,位置匹配代价是关键,采用了Point2Point方式,即先找到最佳的点到点匹配,并将所有点对的Manhattan距离相加,作为两个点集的位置匹配代价,该代价同时用在Instance-level和Point-level匹配上。此外,还引入了Cosine相似度来计算Edge Direction损失,用于学习矢量点的连接关系。
等效排列建模 分层二分图匹配则同样借鉴了DETR这种set prediction方式,同时引入了Instance Query预测地图要素实例,以及Point Query预测矢量点,因此匹配过程也包括了Instance-level匹配和Point-level匹配。匹配代价中,位置匹配代价是关键,采用了Point2Point方式,即先找到最佳的点到点匹配,并将所有点对的Manhattan距离相加,作为两个点集的位置匹配代价,该代价同时用在Instance-level和Point-level匹配上。此外,还引入了Cosine相似度来计算Edge Direction损失,用于学习矢量点的连接关系。 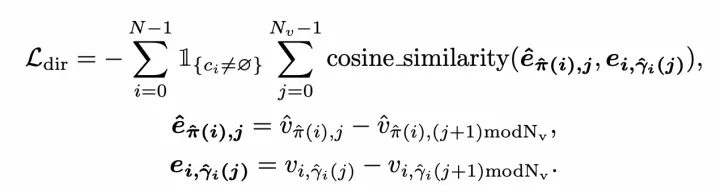 Edge Direction损失 SuperFusion则和HDMapNet一样,采用像素方式建模车道线,方法完全一致。
Edge Direction损失 SuperFusion则和HDMapNet一样,采用像素方式建模车道线,方法完全一致。
实验结果
06 实验结果
目前实验效果最好的是MapTR方法,仅通过图像源即可超过其他方法的点图融合效果,指标和可视化结果如下:
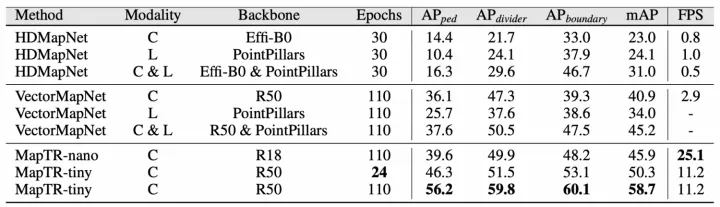 MapTR实验结果
MapTR实验结果

MapTR可视化 另外有趣的一个实验是,VectorMapNet和SuperFusion均验证了引入该车道线拓扑后对轨迹预测的影响,也说明了在线建图的价值,如下: 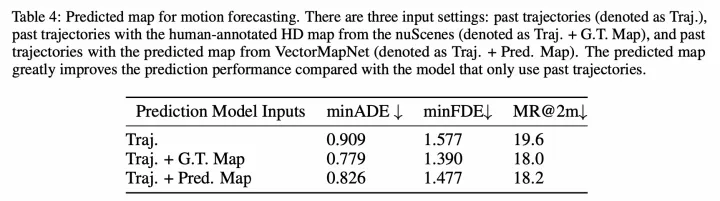 轨迹预测结果
轨迹预测结果 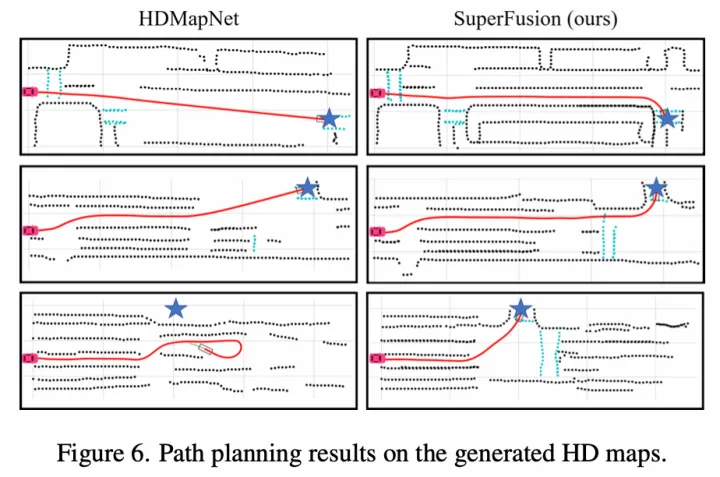 轨迹预测可视化
轨迹预测可视化
07 业界工作
NO.1 特斯拉
特斯拉在AIDAY2022中着重介绍了车道拓扑生成技术方案。借鉴语言模型中的Transformer decoder开发了Vector Lane模块,通过序列的方式自回归地输出结果。整体思路是将车道线相关信息,包括车道线节点位置、车道线节点属性(起点,中间点,终点等)、分叉点、汇合点、以及车道线样条曲线几何参数进行编码,做成类似语言模型中单词token的编码,然后利用时序处理办法进行处理,将这种表示看成“Language of Lanes”。 AIDAY2022, https://www.youtube.com/watch?v=ODSJsviD_SU&t=10531s 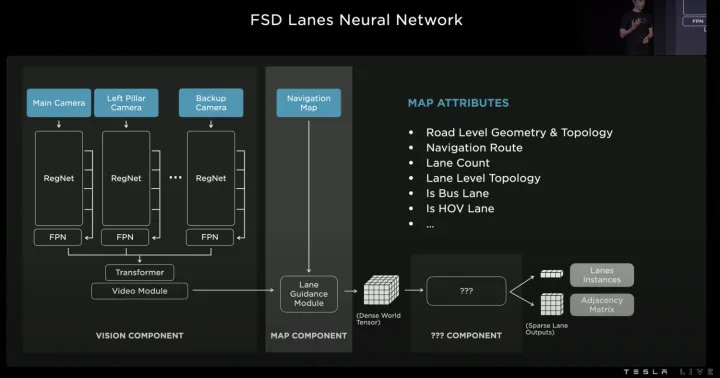 Vector Lane模块 其中BEV特征(Dense World Tensor)不仅包括视觉图像特征,还引入了低精度地图中关于车道线几何/拓扑关系的信息、车道线数量、宽度、以及特殊车道属性等信息的编码特征,这些信息提供了非常有用的先验信息,在生成车道线几何拓扑时很有帮助,尤其是生成无油漆区域的虚拟车道线。 自回归方式生成车道线几何拓扑的详细过程如下:
Vector Lane模块 其中BEV特征(Dense World Tensor)不仅包括视觉图像特征,还引入了低精度地图中关于车道线几何/拓扑关系的信息、车道线数量、宽度、以及特殊车道属性等信息的编码特征,这些信息提供了非常有用的先验信息,在生成车道线几何拓扑时很有帮助,尤其是生成无油漆区域的虚拟车道线。 自回归方式生成车道线几何拓扑的详细过程如下:
先选取一个生成顺序(如从左到右,从上到下)对空间进行离散化(tokenization),然后就可以用Vector Lane模块预测一系列的离散token,即车道线节点。考虑到计算效率,采用了Coarse to Fine方式预测,即先预测一个节点的粗略位置的(index:18),然后再预测其精确位置(index:31),如下:
 预测节点
预测节点
接着再预测节点的语义信息,例如该节点是车道线起点,于是预测“Start”,因为是“Start”点,所以分叉/合并/曲率参数无需预测,输出None。
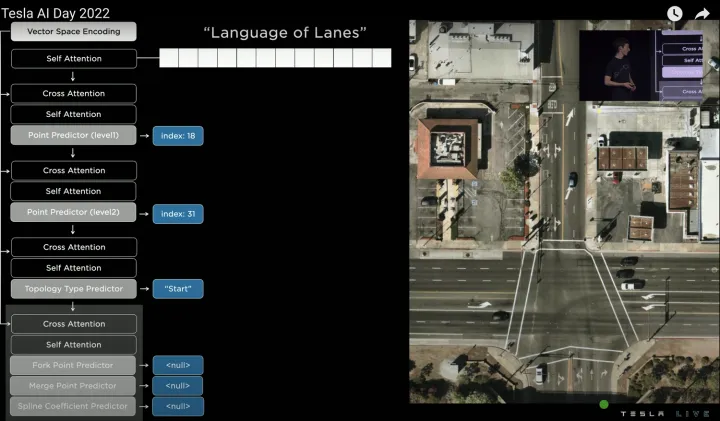 预测节点的语义信息
预测节点的语义信息
然后所有预测结果接MLP层输出维度一致的Embedding,并将所有的Embedding相连得到车道线节点的最终特征,即输出第一个word(绿色点),如下:
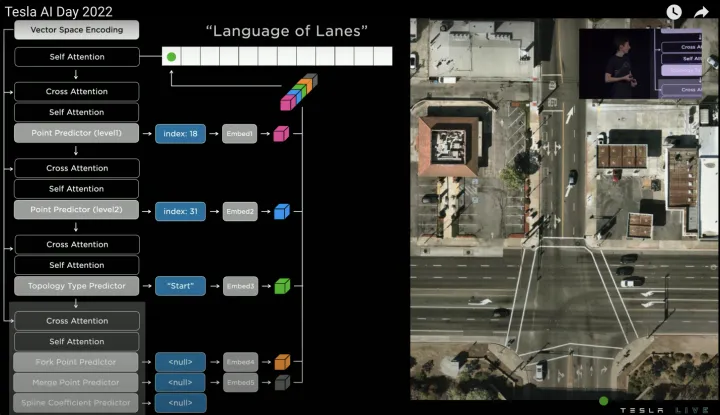 节点特征整合
节点特征整合
接着将第一个word输入给Self Attention模块,得到新的Query,然后和Vector Space Encoding生成的Value和Key进行Cross Attention,预测第二个word(黄色点),整体过程和预测第一个word相同,只是第二个word的语义是“Continue”(代表延续点),分叉/合并预测结果仍为None,曲率参数则需要预测(根据不同曲线方程建模,例如三次多项式曲线或贝塞尔曲线等),如下:
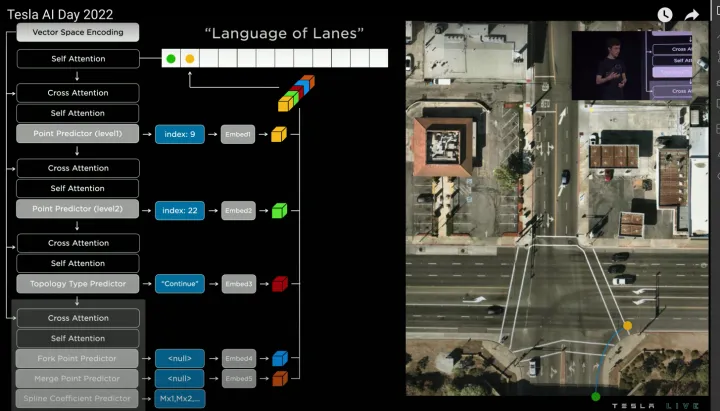 迭代预测第二个节点
迭代预测第二个节点
接着同样方式预测第三个word(紫色点),如下:
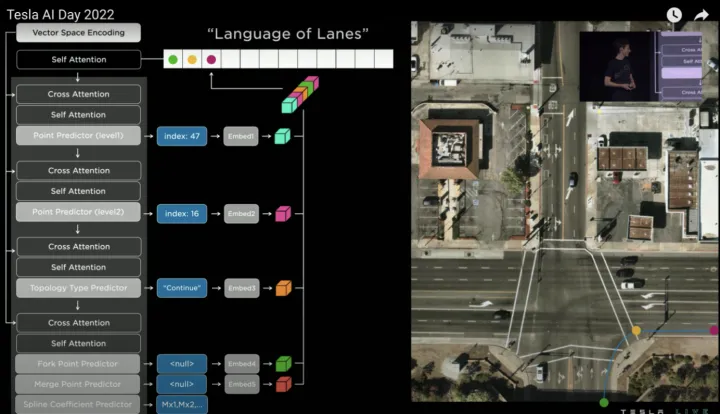 迭代预测第三个节点
迭代预测第三个节点
然后回到起始点继续预测,得到第四个word(蓝色点),该word和也是和第一个word相连,所以语义预测为“Fork”(合并点),如下:
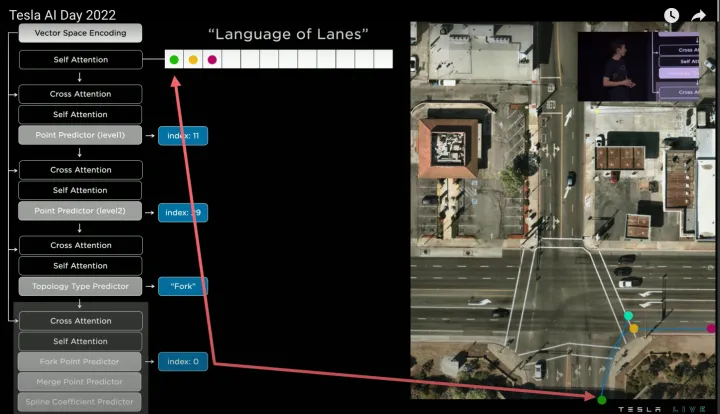 迭代预测第四个节点
迭代预测第四个节点
进一步输入前序所有word,预测第五个word,该word的语义预测为“End of sentence”(终止点),代表从最初的第一个word出发的所有车道线已经预测完成。
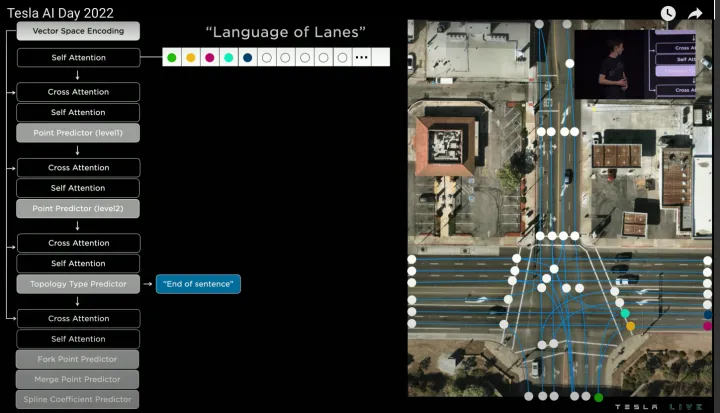 迭代预测第五个节点
迭代预测第五个节点
由此遍历所有起始点,即可生成完整的车道线拓扑,如下:
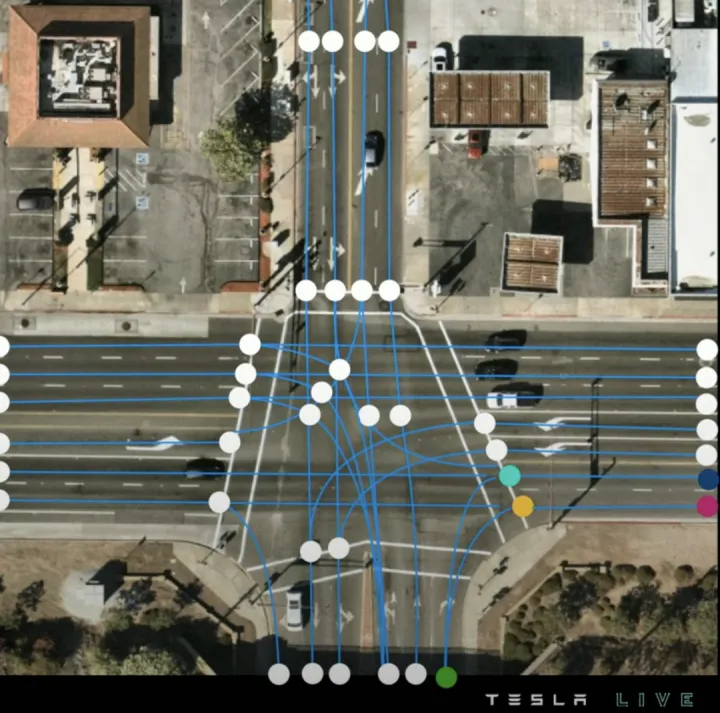 车道线拓扑
车道线拓扑  在线建图可视化 NO.2 百度
在线建图可视化 NO.2 百度
百度在ApolloDay2022上也介绍了生成在线地图的技术方案,可以概述为以下几点:
ApolloDay2022,
https://www.apollo.auto/apolloday/#video
点图融合,图像分支基于Transformer实现PV2BEV空间转换;
Query-based的set-prediction,引入Instance query、Point query以及Stuff query同时学习地图要素实例、矢量点以及可行驶区域分割等;
高精地图(精度)和众源地图(规模和鲜度)多源融合;
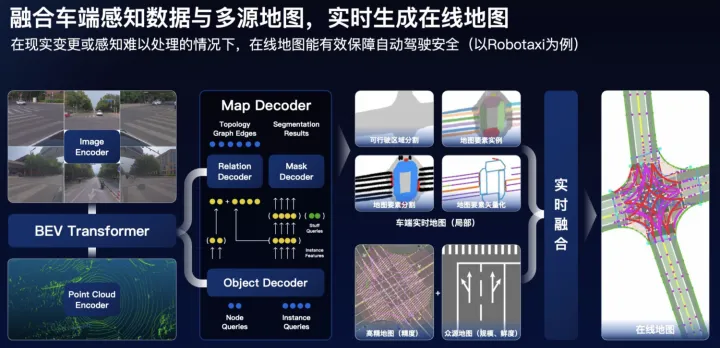 在线建图架构图
在线建图架构图 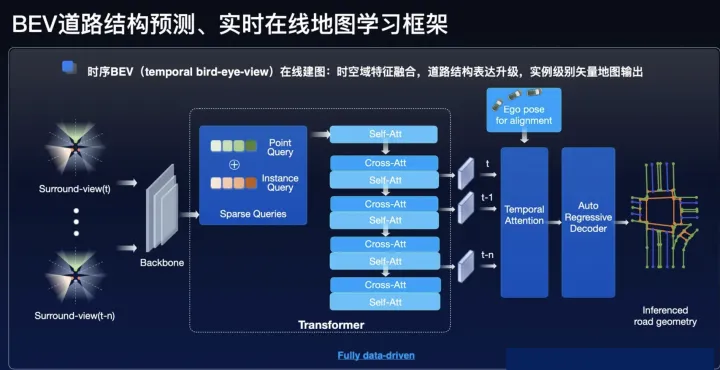 在线建图架构图 NO.3 毫末智行
在线建图架构图 NO.3 毫末智行
毫末智行是一家重感知轻地图的公司,因此也在毫末智行AI DAY上着重介绍了在线建图方案,可以概述为以下几点:
毫末智行AI DAY,
https://mp.weixin.qq.com/s/bwdSkns_TP4xE1xg32Qb6g
点图融合,图像分支基于Transformer实现PV2BEV空间转换;
实物车道线检测+虚拟车道线拓扑,实物车道线检测的Head采用HDMapNet方式生成,虚拟车道线拓扑则是以SD地图作为引导信息,结合BEV特征和实物车道线结果,使用自回归编解码网络,解码为结构化的拓扑点序列,实现车道拓扑预测;
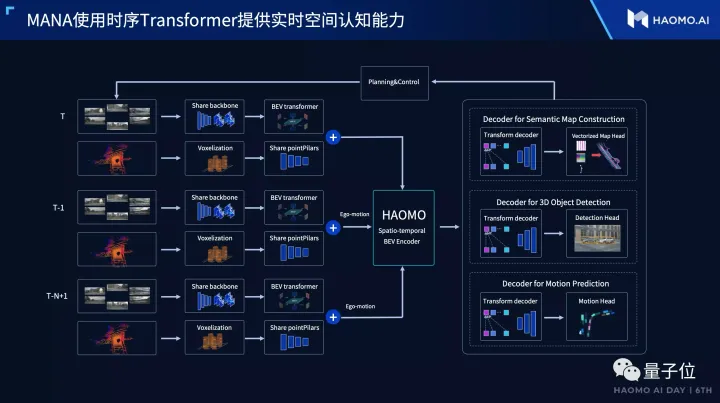 实物车道线检测
实物车道线检测 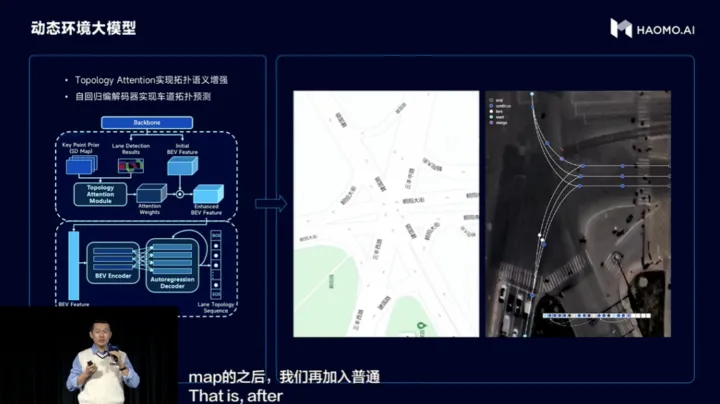 虚拟车道线拓扑生成
虚拟车道线拓扑生成
NO.4 地平线
地平线也在分享中也介绍了其在线建图方案。
https://mp.weixin.qq.com/s/HrI6Nx7IefvRFULe_KUzJA
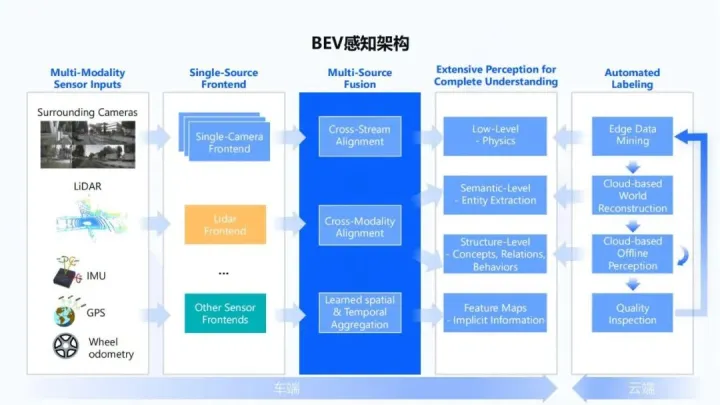 BEV感知架构 通过六个图像传感摄像头的输入,得到全局BEV语义感知结果,这更多是感知看得见的内容,如下图所示:
BEV感知架构 通过六个图像传感摄像头的输入,得到全局BEV语义感知结果,这更多是感知看得见的内容,如下图所示: 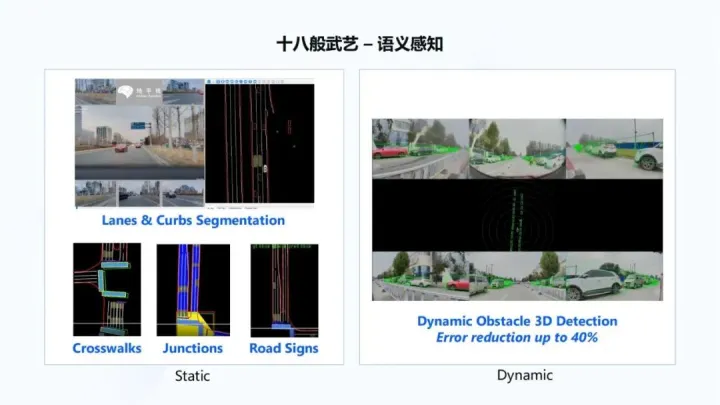 语义感知 再通过引入时序信息,将想象力引入到 BEV感知中,从而感知看不见的内容,如下右图所示,感知逐渐扩展自己对于周边车道线、道路以及连接关系的理解,这个过程一边在做感知,一边在做建图,也叫做online maps。
语义感知 再通过引入时序信息,将想象力引入到 BEV感知中,从而感知看不见的内容,如下右图所示,感知逐渐扩展自己对于周边车道线、道路以及连接关系的理解,这个过程一边在做感知,一边在做建图,也叫做online maps。 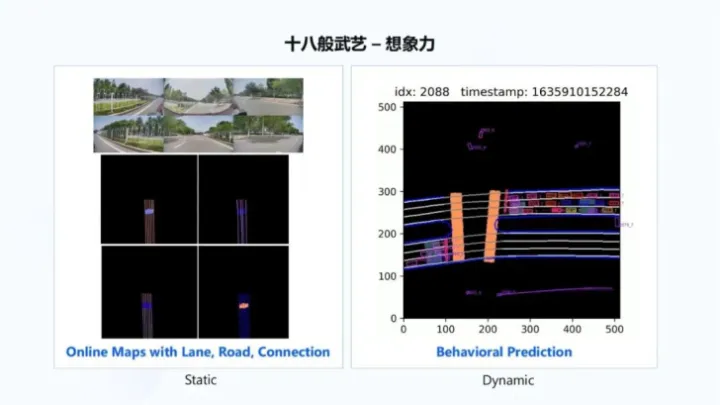 超视距感知
超视距感知
NO.5 小鹏
小鹏汽车目前推出了全新一代的感知架构XNet,结合全车传感器,对于静态环境有了非常强的感知,可以实时生成“高精地图”。核心是通过Transformer实现多传感器、多相机、时序多帧的特征融合。
XNet:https://mp.weixin.qq.com/s/zOWoawMiaPPqF2SpOus5YQ 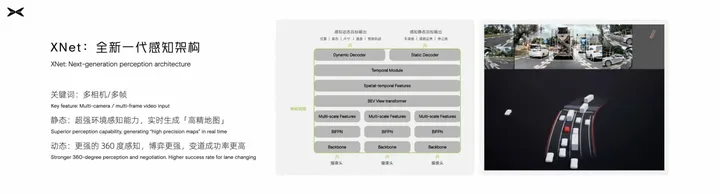 XNet架构图 08 思考
XNet架构图 08 思考
抛开技术外,我还想聊聊对图商的”离线高精地图“和自动驾驶公司的”在线地图“的认识。 地图是自动驾驶的一个非常重要模块,自动驾驶不能脱离地图,因为自动驾驶是运行在规则约束的交通系统下,无法摆脱这套规则的约束,而地图恰恰是这套规则系统表达的很好载体,一个完整的地图不仅包括各种地图要素,还包括各种交通规则,例如该车道能否掉头、该红绿灯作用在哪个车道等。
因此,图商凭借在SD地图制作经验(交通规则理解),均开展了”离线高精地图“制作,包括高德地图、百度地图、腾讯地图、四维图新等。而图商制作”离线高精地图“的逻辑是,建立统一的、大而全的高精地图标准,同时服务于市场上的多家自动驾驶公司。但不同的自动驾驶公司的自身自动驾驶能力差异非常大,对高精地图的需求也不同,这就导致”离线高精地图“越来越复杂,图商的采集和制作成本也越来越高。正因为成本高,高精地图的覆盖率低和鲜度差的问题也始终未被解决,这是每个图商都需要面对的紧迫问题。尽管也有一些众包更新的解决方案,但实际得到大规模应用的并不多。
而自动驾驶又需要高覆盖、高鲜度的高精地图,于是自动驾驶公司开始研究如何“在线建图”这个课题了。“在线建图”的关键在于“图”,在我看来,这个“图”已经不是“离线高精地图”的“图”了,因为自动驾驶公司的“在线建图”是根据自身的自动驾驶能力调整的,在“离线高精地图”中的冗余信息都可以舍弃,甚至是常说的精度要求(“离线高精地图”一般要求5cm精度)。而恰恰因为对“图”进行了简化,所以自动驾驶公司的”在线地图“才有了可行性。通过”在线地图“,在“离线高精地图”覆盖范围内实现地图更新,在“离线高精地图”覆盖范围外生成自己可用的地图,可能会有一些自动驾驶功能的降级,这个边界仍在摸索中。
不过,测绘资质和法规变化可能会促使一种新的图商和自动驾驶公司的高精地图生产合作模式,即自动驾驶公司提供智能车数据 + 图商提供高精地图制作能力的生态闭环。2022年下半年,国家和地方密集出台了一系列高精度地图相关法律,例如:《关于促进智能网联汽车发展维护测绘地理信息安全的通知》、《关于做好智能网联汽车高精度地图应用试点有关工作的通知》等。
这些法律文件明确界定了智能网联汽车和测绘的关系,即智能网联汽车在运行过程中(包括卖出的车)对数据的操作即为测绘,并且自动驾驶公司是测绘活动的行为主体。从规定来看,自动驾驶公司的“在线地图”是明确的测绘行为,而想要合法测绘,必须拥有导航电子地图制作的甲级资质,而获得资质的途径可以是直接申请(太难申请,并且不是一劳永逸,可能在复审换证环节被撤销企业资质)、间接收购(风险高)、以及与图商合作。由此来看,自动驾驶公司和图商合作的生态闭环可能是唯一解法。那么,自动驾驶公司的智能车数据提供给图商进行地图数据生产是否合法呢?在《上海市智能网联汽车高精度地图管理试点规定》中,明确规定“鼓励具有导航电子地图制作测绘资质的单位,在确保数据安全、处理好知识产权等关系的前提下,探索以众源方式采集测绘地理信息数据,运用实时加密传输及实时安全审校等技术手段,制作和更新高精度地图。” 目前,腾讯地图已官宣与蔚来宣布达成深度合作,打造智能驾驶地图、车载服务平台等,当然这可能更多是投资关系促使。如何真正实现高精地图生产的生态闭环,可能是图商未来的破局关键。
编辑:黄飞
-
从《自动驾驶地图数据规范》聊高精地图在自动驾驶中的重要性2025-01-05 3276
-
自动驾驶汽车的定位技术2019-05-09 3539
-
自动驾驶系统设计及应用的相关资料分享2021-08-30 2473
-
自动驾驶的核心基础在高精3D地图2018-02-25 1828
-
高精3D地图是自动驾驶技术的基石 测绘地图技术的重要性何在2018-03-02 7807
-
自动驾驶技术最新进展:自动驾驶系统与高精地图关系2019-01-19 5705
-
高精地图在自动驾驶中的应用详细资料分析2019-05-12 5869
-
自动驾驶语义高精地图的层级实现2019-05-23 4746
-
百度高精地图获ASPICE认证,助力全球自动驾驶发展2019-11-29 3973
-
随着5G以及自动驾驶技术的进步,高精地图技术也越发受到重视2020-12-16 2733
-
为什么自动驾驶汽车离不开高精地图2021-11-16 3610
-
解读自动驾驶车辆专用高精地图的魔力2021-12-21 2786
-
高精自动驾驶中的地图匹配定位技术2023-06-07 845
-
国内首个L3级自动驾驶之城诞生,高精定位和高精地图成为关键支撑2022-08-11 1512
-
自动驾驶仿真测试实践:高精地图仿真2024-06-13 2339
全部0条评论

快来发表一下你的评论吧 !
