

对偶支持向量机DSVM
电子说
描述
1
Motivation of Dual SVM
首先,我们回顾一下,对于非线性SVM,我们通常可以使用非线性变换将变量从x域转换到z域中。然后,在z域中,根据上一节课的内容,使用线性SVM解决问题即可。上一节课我们说过,使用SVM得到large-margin,减少了有效的VC Dimension,限制了模型复杂度;另一方面,使用特征转换,目的是让模型更复杂,减小Ein。
所以说,非线性SVM是把这两者目的结合起来,平衡这两者的关系。那么,特征转换下,求解QP问题在z域中的维度设为d^+1,如果模型越复杂,则d^+1越大,相应求解这个QP问题也变得很困难。当d^无限大的时候,问题将会变得难以求解,那么有没有什么办法可以解决这个问题呢?一种方法就是使SVM的求解过程不依赖d^,这就是我们本节课所要讨论的主要内容。

比较一下,我们上一节课所讲的Original SVM二次规划问题的变量个数是d^+1,有N个限制条件;而本节课,我们把问题转化为对偶问题(’Equivalent’ SVM),同样是二次规划,只不过变量个数变成N个,有N+1个限制条件。这种对偶SVM的好处就是问题只跟N有关,与d^无关,这样就不存在上文提到的当d^无限大时难以求解的情况。

如何把问题转化为对偶问题(’Equivalent’ SVM),其中的数学推导非常复杂,本文不做详细数学论证,但是会从概念和原理上进行简单的推导。

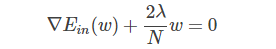
所以,在regularization问题中,λ是已知常量,求解过程变得容易。那么,对于dual SVM问题,同样可以引入λ,将条件问题转换为非条件问题,只不过λ是未知参数,且个数是N,需要对其进行求解。


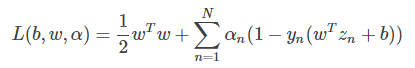
这个函数右边第一项是SVM的目标,第二项是SVM的条件和拉格朗日因子αn的乘积。我们把这个函数称为拉格朗日函数,其中包含三个参数:b,w,αn。

下面,我们利用拉格朗日函数,把SVM构造成一个非条件问题:


2
Lagrange Dual SVM
现在,我们已经将SVM问题转化为与拉格朗日因子αn有关的最大最小值形式。已知αn≥0,那么对于任何固定的α′,且αn′≥0,一定有如下不等式成立:
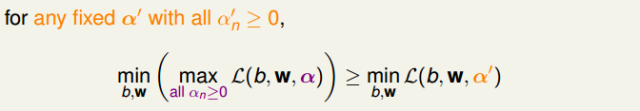
对上述不等式右边取最大值,不等式同样成立:

上述不等式表明,我们对SVM的min和max做了对调,满足这样的关系,这叫做Lagrange dual problem。不等式右边是SVM问题的下界,我们接下来的目的就是求出这个下界。
已知≥是一种弱对偶关系,在二次规划QP问题中,如果满足以下三个条件:
- 函数是凸的(convex primal)
- 函数有解(feasible primal)
- 条件是线性的(linear constraints)
那么,上述不等式关系就变成强对偶关系,≥变成=,即一定存在满足条件的解(b,w,α),使等式左边和右边都成立,SVM的解就转化为右边的形式。
经过推导,SVM对偶问题的解已经转化为无条件形式:
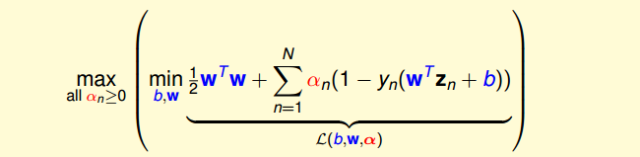
其中,上式括号里面的是对拉格朗日函数L(b,w,α)计算最小值。那么根据梯度下降算法思想:最小值位置满足梯度为零。首先,令L(b,w,α)对参数b的梯度为零:
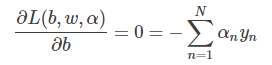

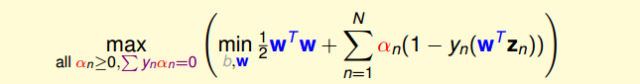
这样,SVM表达式消去了b,问题化简了一些。然后,再根据最小值思想,令L(b,w,α)对参数w的梯度为零:
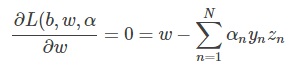
即得到:
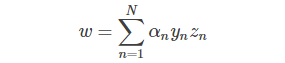

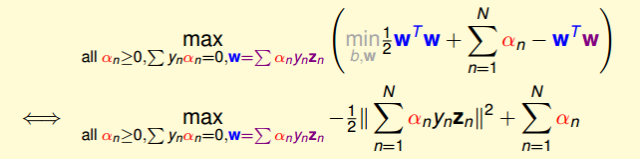
这样,SVM表达式消去了w,问题更加简化了。这时候的条件有3个:
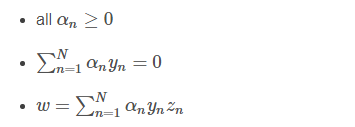

总结一下,SVM最佳化形式转化为只与αn有关:
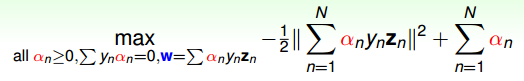
其中,满足最佳化的条件称之为Karush-Kuhn-Tucker(KKT):

在下一部分中,我们将利用KKT条件来计算最优化问题中的α,进而得到b和w。
3
Solving Dual SVM
上面我们已经得到了dual SVM的简化版了,接下来,我们继续对它进行一些优化。首先,将max问题转化为min问题,再做一些条件整理和推导,得到:

显然,这是一个convex的QP问题,且有N个变量αn,限制条件有N+1个。则根据上一节课讲的QP解法,找到Q,p,A,c对应的值,用软件工具包进行求解即可。






4
Messages behind Dual SVM
回忆一下,上一节课中,我们把位于分类线边界上的点称为support vector(candidates)。本节课前面介绍了αn>0的点一定落在分类线边界上,这些点称之为support vector(注意没有candidates)。也就是说分类线上的点不一定都是支持向量,但是满足αn>0的点,一定是支持向量。

SV只由αn>0的点决定,根据上一部分推导的w和b的计算公式,我们发现,w和b仅由SV即αn>0的点决定,简化了计算量。这跟我们上一节课介绍的分类线只由“胖”边界上的点所决定是一个道理。也就是说,样本点可以分成两类:一类是support vectors,通过support vectors可以求得fattest hyperplane;另一类不是support vectors,对我们求得fattest hyperplane没有影响。

回过头来,我们来比较一下SVM和PLA的w公式:


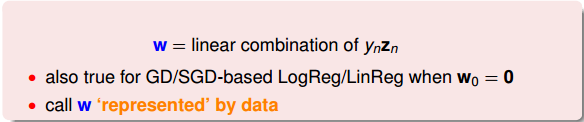
总结一下,本节课和上节课主要介绍了两种形式的SVM,一种是Primal Hard-Margin SVM,另一种是Dual Hard_Margin SVM。Primal Hard-Margin SVM有d^+1个参数,有N个限制条件。当d^+1很大时,求解困难。而Dual Hard_Margin SVM有N个参数,有N+1个限制条件。当数据量N很大时,也同样会增大计算难度。两种形式都能得到w和b,求得fattest hyperplane。通常情况下,如果N不是很大,一般使用Dual SVM来解决问题。



5
Summary
本节课主要介绍了SVM的另一种形式:Dual SVM。我们这样做的出发点是为了移除计算过程对d^的依赖。Dual SVM的推导过程是通过引入拉格朗日因子α,将SVM转化为新的非条件形式。然后,利用QP,得到最佳解的拉格朗日因子α。再通过KKT条件,计算得到对应的w和b。最终求得fattest hyperplane。
-
基于支持向量机的预测函数控制2009-03-17 834
-
特征加权支持向量机2009-11-21 632
-
基于改进支持向量机的货币识别研究2009-12-14 615
-
基于支持向量机(SVM)的工业过程辨识2012-03-30 1032
-
基于标准支持向量机的阵列波束优化及实现2017-11-10 991
-
模糊支持向量机的改进方法2017-11-29 916
-
基于向量机随机投影特征降维分类下降解决方案2017-12-01 1538
-
多分类孪生支持向量机研究进展2017-12-19 975
-
基于支持向量机的测深激光信号处理2017-12-21 1057
-
支持向量机的故障预测模型2017-12-29 1224
-
关于支持向量机(SVMs)2018-04-02 4785
-
什么是支持向量机 什么是支持向量2020-01-28 23209
-
支持向量机(核函数的定义)2023-05-20 1994
-
支持向量机(原问题和对偶问题)2023-05-25 2661
-
支持向量机(兵王问题描述)2023-06-09 3545
全部0条评论

快来发表一下你的评论吧 !
