

Rocksdb原理简介
电子说
描述
Rocksdb作为当下nosql中性能的代表被各个存储组件(mysql、tikv、pmdk、bluestore)作为存储引擎底座,其基于LSM tree的核心存储结构(将随机写通过数据结构转化为顺序写)来提供高性能的写吞吐时保证了读性能。同时大量的并发性配置来降低compaction的影响。
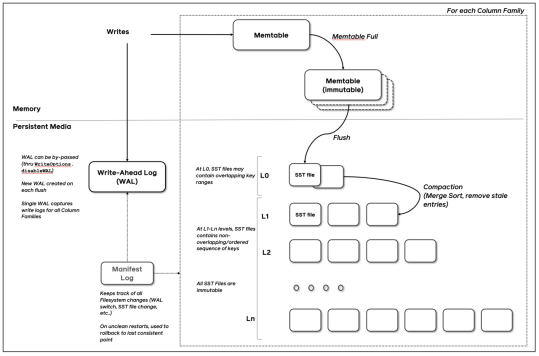
涉及到的几个核心文件:
WAL
WriteAheadLog,rocksdb的日志,保存memtable中的信息。当memtable转化为immutable memtable并且Flush到L0层之后,之前WAL的会被清理,即于删除DB目录下的log文件。
在RocksDB中每一次数据的更新都会涉及到两个结构,一个是内存中的memtable(后续会刷新到磁盘成为SST),第二个是WAL。
WAL主要的功能是当RocksDB异常退出后,能够恢复出错前的内存中(memtable)数据,因此RocksDB默认是每次用户写都会刷新数据到WAL。每次当当前WAL对应的内存数据(memtable)刷新到磁盘之后,都会新建一个WAL。
所有的WAL文件都是保存在WAL目录(options.wal_dir),为了保证数据的状态,所有的WAL文件的名字都是按照顺序的(log_number)。
MANIFEST
在RocksDB中MANIFEST保存了存储引擎的内部的一些状态元数据,简单来说当系统异常重启,或者程序异常被退出之后,RocksDB需要有一种机制能够恢复到一个一致性的状态, 而这个一致性的状态就是靠MANIFEST来保证的.
MANIFEST在RocksDB中是一个单独的文件,而这个文件所保存的数据基本是来自于VersionEdit这个结构.
MANIFEST包含了两个文件,一个log文件一个包含最新MANIFEST文件名的文件,Manifest的log文件名是这样 MANIFEST-(seq number),这个seq会一直增长.只有当 超过了指定的大小之后,MANIFEST会刷新一个新的文件,当新的文件刷新到磁盘(并且文件名更新)之后,老的文件会被删除掉。这里可以认为每一次MANIFEST的更新都代表一次snapshot。
CURRENT
记录当前最新的MANIFEST文件编号
Memtable
常驻于内存中,在WAL写之后,记录具体的key-value数据。在RocksDB中,每个ColumnFamily都有自己的Memtable,Column Family之间互不影响。而在RocksDB中Memtable有多种实现,SkipList/HashSkipList/HashLinkList/Vector,默认的实现为SkipList(只有skiplist可以并发插入)。memtable大小以及个数可以由指定的参数进行控制:
write_buffer_size表示memtable的大小
max_write_buffer_number表示内存中最多可以同时存在多少个memtable的个数
Immutable memtable
当memtable被写满之后会生成一个新的memtable继续接受IO,旧的memtable就会变成immutable memtable,为只读的状态,且开始由后台线程Flush到磁盘的L0层sst。
SST
核心key-value的存储文件,比如DB目录下的000023.sst文件。默认分为L0~L7层,当满足一定条件时(本层sst总大小超过配置大小、WAL文件超过一定值)后台开启compaction任务,从当前层和下一层选取若干sst,做合并,并写入新的sst文件。
CcolumnFamily
RocksDB 3.0中加入了Column Family特性,加入这个特性之后,每一个KV对都会关联一个Column Family,其中默认的Column Family是 "default"。Column Family主要是提供给RocksDB一个逻辑的分区。
从实现上来看不同的Column Family共享WAL,而都有自己的memtable和SST,同时拥有自己的配置。这就意味着我们可以快速方便的设置不同的属性的Column Family以及快速删除对应的Column Family。
但是因为Column Family共享WAL,可能会咬住WAL,让WAL快速增长从而触发memtable的强制Flush。
-
DAC简介2021-08-09 1571
-
FPGA简介2022-02-23 1195
-
NoOs简介2022-03-01 1472
-
电感元件简介与展望2009-11-20 559
-
手机简介2009-12-19 883
-
Windows CE简介、特点及应用2010-01-11 5072
-
ISE10.1使用简介2016-02-18 1881
-
Proteus示波器简介2016-03-22 1734
-
【RocksDB】TransactionDB源码分析2018-07-23 2198
-
看图了解RocksDB2018-11-15 577
-
POE简介2022-11-01 706
-
FST 简介2022-11-14 504
-
KIOXIA推出全新开源软件,提升RocksDB中闪存存储的寿命和性能2025-10-13 596
全部0条评论

快来发表一下你的评论吧 !
