

10张图带你轻松理解关系型数据库系统的工作原理
电子说
描述
什么是索引
索引是一种帮助减少数据查询时间的数据结构。索引在实现这一目标时,需要付出存储、内存和保持更新(较慢的写入速度)的额外成本,这使得我们可以跳过检查每一行表的繁琐任务。
就像书后面的索引页一样,它可以帮助你找到正确的一页。
为什么需要索引
小量的数据是易于管理的(比如一个小班级的出勤表), 但是, 当数据规模变得更大时(比如一个大城市的出生登记), 事情就不那么容易了。之前能够很快执行的操作都开始变得缓慢。
想象一下,如果你需要在一页 A4 纸的名单上上找到某个信息,与需要在上千页的名单中找到它,你的查询策略会有何变化。
无论你想到的查询策略是什么,几乎总会有某个数据库在某个特定的时间点用到了和你相似的策略,因为随着它们的发展,他们需要收集和存储的数据会逐渐变得庞大,最终必将遇到上述的问题。
因此,我们需要索引来帮助我们尽可能快地获得我们需要的相关数据。
索引是如何工作的?
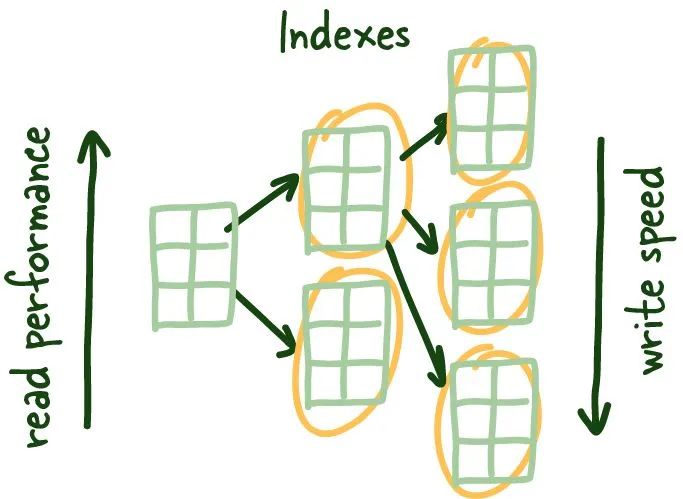
一般而言,索引越多读取性能越好,但这是以写性能的降低为代价的,因为你需要保持对索引的更新
其中一个方案是根据查询方式来维护数据存储逻辑。比如你需要通过姓名来查询某个名单,那就将名单按照姓名进行排序。但这个策略有许多问题需要考虑:
- 如果我有多种查询方式呢? 比如,既有用姓名查询也有用身份证查询。
- 如果有新数据的写入, 写入速度会受到多大的影响?
- 如何处理数据的更新呢?
- 所有的数据操作的复杂度是什么样的呢?
无论你的原始策略是什么,肯定都需要一种维护数据顺序的方式以便获取相关的无序数据。
如下表中的例子,几乎不需要什么时间,我们就可以通过扫描整个表将查询到我们想要的数据。
+─────+─────────+──────────────+
| id | name | city |
+─────+─────────+──────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
+─────+─────────+──────────────+
加入存储的数据规模无法全部存放到内存,或者需要很长的时间才能将数据从磁盘加载到内存呢?如下表中,数据分散在磁盘中,无法完全加载到内存。
+──────────+─────────+───────────────────+
| id | name | city |
+──────────+─────────+───────────────────+
| 1 | Mahdi | Ottawa |
| 2 | Elon | Mars |
| 3 | Jeff | Orbit |
| 4 | Klay | Oakland |
| 5 | Lebron | Los Angeles |
| ... | ... | ... |
| 1000000 | Steph | San Francisco |
| 1001000 | Linus | Portland |
+───────+─────────+──────────────────────+
大部分 R&D 立刻想到了,我们需要字典(hash表)以及一种可以不需要扫描磁盘直接定位到正在查询的指定行的手段。
索引叶子节点提供指定列到索引的映射,它能够存储符合条件的行所在的位置。

RowIDs indexes mapping to table data
这些索引叶子节点是索引列和相应行在磁盘上的位置之间的映射。它提供了一种通过索引列来快速获取指定行的方法。扫描索引的速度会更快,因为它是你要搜索的列的紧凑表示(更少的字节)。它为你节省了读取一堆块来寻找所需数据的时间,而且更便于缓存,进一步加快了整个过程的速度。
这些索引的叶子节点是统一大小的,我们在每个块中尽可能多地存储这些叶子节点。由于这种结构需要对数据进行排序(逻辑上,而不是磁盘上的物理排序),我们需要解决必须快速添加和删除数据的问题。通常我们用一个双向链表来解决这个问题。
这里的好处有两个:它允许我们向前和向后读取索引叶子节点,并在我们删除或添加新行时快速重建索引结构,因为我们只是在修改指针。
由于这些叶子节点在磁盘上并不是按顺序排列的,我们需要一种方法来获得正确的索引叶子节点。
平衡树(B-Tree)

B树 VS B+树
❝「B树 VS B+树」
B+树主要区别是,不在中间节点存储任何数据。所有的数据引用都链接到叶子节点上,这样可以更好地缓存树状结构(中间节点数据规模小更便于缓存索引信息)。
其次,B+树叶子节点是链接的,所以如果你需要做索引扫描,你可以简单的线性遍历,而不是向上和向下遍历整个树,从磁盘上加载更多的索引数据。
❞
在关系型数据库中,B+树的结构如下图:

数据库中的B+树
什么是事务
事务是数据库操作的基本单位,它要么完全成功要么完全失败,不可能存在部分成功部分失败的情况。
数据不一致
在不同数据隔离级别中可能会出现一些数据不一致现象,了解这些现象对于调试你的系统以及了解你的系统能够容忍什么样的不一致是至关重要的。
不可重复读(Non-repeatable reads)

不可重复读
如上图所示,如果你在事务中的两次后续读取之间不能获得一致的数据视图,就会发生不可重复的读取。在特定的模式下,数据库的并发操作可能会出现你刚读的值被修改,导致不可重复的读取。
脏读(Dirty reads)

脏读
类似地,当你执行了一次读取,另一个事务更新了同一行,但没有提交工作,你执行了另一次读取,你可以访问未提交的(脏)值(这不是一个持久的状态变化,与数据库的状态不一致), 就会发生脏读取。
幻读(Phantom reads)

幻读
幻象读取是另一种已提交的数据不一致现象,他常发生在处理数据统计的场景。例如,你在一个特定的事务中两次计算客户的总数。在两次连续的读取之间,另一个客户注册或删除了他们的账户(已提交),如果你的数据库不支持这些事务的范围锁,这将导致你得到两个不同的值。
隔离级别

SQL标准的四种隔离级别
SQL标准定义了4个标准隔离级别,这些级别可以而且应该被全局配置(如果我们不能可靠地知道隔离级别,就会发生一些奇怪的问题)。
可重复读(REPEATABLE READ)
在这个隔离级别下,确保在一个事务中多次读取同一数据时,得到的结果是一致的。
这意味着事务在开始时会创建一个一致的快照,然后在事务结束之前,其他事务对数据的修改不会影响该事务的读取结果。
在可重复读级别下,解决了不可重复读的问题,但可能出现幻读问题。
串行化(SERIALIZABLE)
这是最高的隔离级别,它确保事务之间的并发执行就像是顺序执行一样。
在这个级别下,事务串行执行,避免了脏读、不可重复读和幻读的问题。
虽然序列化提供了最高的数据一致性,但也牺牲了并发性能,因为事务必须依次执行,不能并行处理。
读提交(READ COMMITTED)
在这个隔离级别下,一个事务只能读取到已经提交的数据。这意味着脏读的问题被解决了,因为事务只能看到其他事务已经提交的数据。
然而,在这个级别下,可能会出现不可重复读问题。
读未提交
在这个隔离级别下,一个事务可以读取到另一个事务尚未提交的数据。这意味着一个事务可能会读取到脏数据(未经提交的数据),即脏读。
这个级别提供了最低的隔离性,允许并发事务之间产生相互干扰。
-
关系型数据库和非关系型区别2025-01-10 1917
-
恒讯科技分析:跨境电商网站有哪些数据库系统是推荐使用的?2024-08-12 1794
-
数据库原理的关系代数详细讲解2019-10-31 1844
-
数据库系统原理与应用教程之关系数据库的详细资料说明2019-10-24 1639
-
数据库系统的基础知识点详细概述2019-10-10 1442
-
关系数据库系统的特点2019-02-22 9313
-
数据库系统概论之如何进行关系查询处理和查询优化2018-11-15 1334
-
ch1 数据库系统概论2016-05-18 705
-
数据库系统辅助测试工具2013-09-25 725
-
DCS仿真系统的内存-关系型数据库系统的构成2009-09-07 1514
-
什么是关系型数据库2009-06-17 9401
-
DCS组态软件实时数据库系统的设计2009-03-14 976
-
Oracle数据库系统应用实例集锦与编程2008-09-27 932
全部0条评论

快来发表一下你的评论吧 !
