

Co-SLAM: 联合坐标和稀疏参数编码的神经实时SLAM
描述
如需进一步精通激光-视觉-IMU-GPS融合SLAM算法,也可以关注我们下面的课程:
本文提出了Co-SLAM,一种基于混合表示的神经RGB-D SLAM系统,可以实时执行鲁棒的相机跟踪和高保真的表面重建。Co-SLAM将场景表示为多分辨率哈希网格,以利用其高收敛速度和表示高频局部特征的能力。此外,Co-SLAM结合了one-blob编码,以促进未观察区域的表面一致性和补全。这种联合参数坐标编码通过将快速收敛和表面孔填充这两方面的优点结合起来,实现了实时性和鲁棒性。此外,我们的射线采样策略允许Co-SLAM在所有关键帧上执行全局BA,而不是像其它的神经SLAM方法那样需要关键帧选择来维持少量活动关键帧。实验结果表明,Co-SLAM以10-17Hz的频率运行,并在各种数据集和基准(ScanNet, TUM, Replica, Synthetic RGBD)中获得了最先进的场景重建结果,并具有竞争力的跟踪性能。
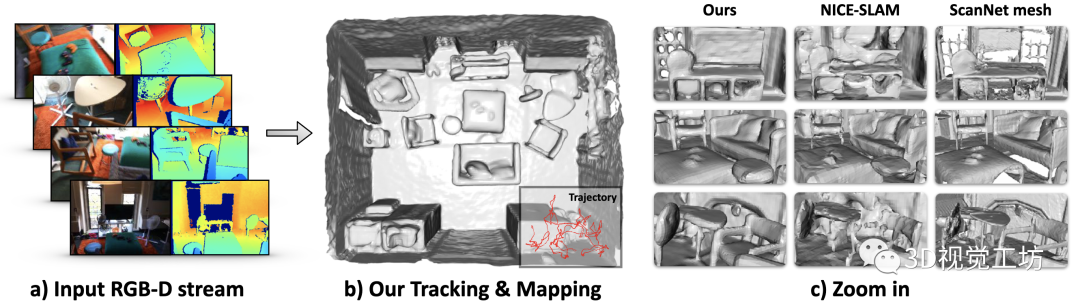
1 引言
联合相机实时跟踪和基于RGB-D传感器的稠密表面重建是几十年来计算机视觉和机器人技术的核心问题。传统的SLAM解决方案可以稳健地跟踪相机的位置,同时将深度和/或颜色测量融合到一个单一的高保真地图中。然而,它们依赖于手工的损失项,而没有利用数据驱动的先验。
最近,人们的注意力转向了基于学习的模型,这种模型可以利用神经网络架构的能力,直接从数据中学习平滑性和一致性先验。基于坐标的网络可能已经成为最流行的表示方式,因为它们可以通过训练来预测场景中任何点的几何和外观属性,直接从图像中进行自监督。最著名的例子是神经辐射场(Neural Radiance Fields, NeRF),它在神经网络的权重中编码场景密度和颜色。与体绘制相结合,NeRF被训练为重新合成输入图像,并具有显著的泛化到附近未见过的视图的能力。
基于坐标的网络将输入点坐标嵌入到高维空间,使用正弦或其他频率嵌入,使它们能够捕捉高频细节,这对高保真几何重建至关重要。平滑性和一致性先验被编码在MLP权值中,为序列跟踪和建图提供了良好的选择。然而,基于MLP的方法的缺点是需要很长的训练时间(有时是几个小时)来学习单个场景。因此,最近建立在具有频率嵌入的坐标网络上的具有实时能力的SLAM系统,如iMAP,需要采用稀疏射线采样和减少跟踪迭代的策略来维持交互操作。这是以在重建过程中丢失细节(被过度平滑)和在相机跟踪中潜在的误差为代价的。
可优化的特征网格,也被称为参数嵌入,最近已经成为单片MLP的一种强大的场景表示替代方案,因为它们能够表示高保真的局部特征,并且具有极快的收敛速度(快几个数量级)。最近的研究集中在这些参数嵌入的稀疏替代方案上,如八叉树、三平面、哈希网格或稀疏体素网格,以提高稠密网格的存储效率。虽然这些表示可以快速训练,非常适合实时操作,但它们从根本上缺乏MLP固有的平滑性和一致性先验,在没有观察到的区域难以填补孔洞。NICE-SLAM是一个基于多分辨率特征网格的SLAM方法的最新例子。虽然它没有过于平滑,能捕捉到局部细节(如图2所示),但它不能进行补孔,补孔可能会导致相机位姿估计出现漂移。
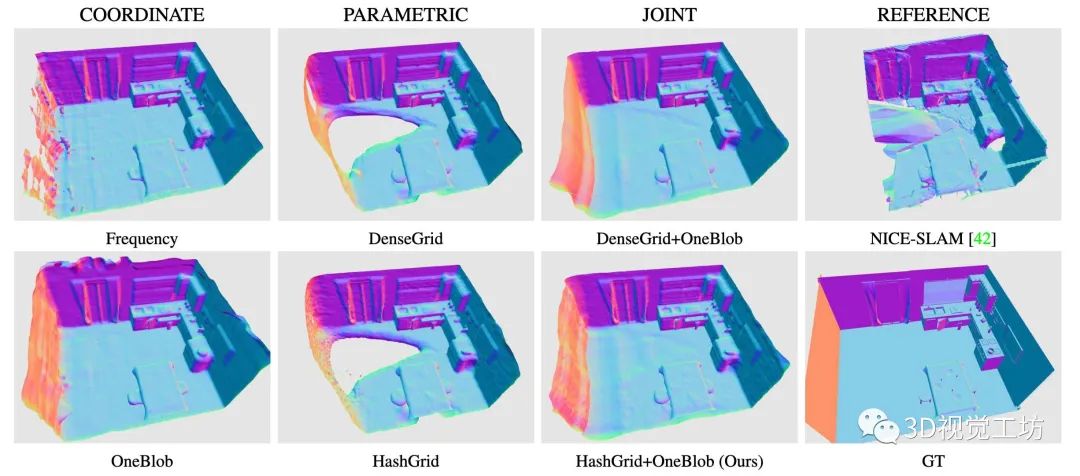
图2:不同编码对补全的影响。基于坐标的编码实现了空洞填充,但需要较长的训练时间。参数编码允许快速训练,但无法补全未观察到的区域。联合坐标和参数编码(Ours)允许流畅地补全场景和快速训练。NICE-SLAM[42]使用稠密参数编码。
本文的主要贡献如下:
为输入点设计一个联合坐标和稀疏网格编码,将两者的优点结合到实时SLAM框架中。一方面,坐标编码提供的平滑性和一致性先验(本文使用one-blob编码),另一方面,稀疏特征编码(本文使用哈希网格)的优化速度和局部细节,能得到更鲁棒的相机跟踪和高保真建图,更好的补全和孔洞填充。
到目前为止,所有的神经SLAM系统都使用从所选关键帧的一个非常小的子集中采样的光线来执行BA。将优化限制在非常少的视点数量会降低相机跟踪的鲁棒性,并由于需要关键帧选择策略而增加计算量。相反,Co-SLAM执行全局BA,从所有过去的关键帧中采样光线,这在位姿估计的鲁棒性和性能上得到了重要的提高。此外,我们还证明了我们的BA优化需要NICE-SLAM的一小部分迭代就能获得类似的误差。在实践中,Co-SLAM在保持实时性能的前提下,实现了相机跟踪和三维重建的SOTA性能。
Co-SLAM在Replica和Synthetic RGB-D数据集上运行速度为15-17Hz,在ScanNet和TUM场景上运行速度为12-13Hz,比NICE-SLAM (0.1-1Hz)和iMAP快。我们对各种数据集(Replica,Synthetic RGBD,ScanNet,TUM)进行了广泛的评估,在重建方面我们优于NICE-SLAM和iMAP,实现了更好的或至少相当的跟踪精度。
2 方法
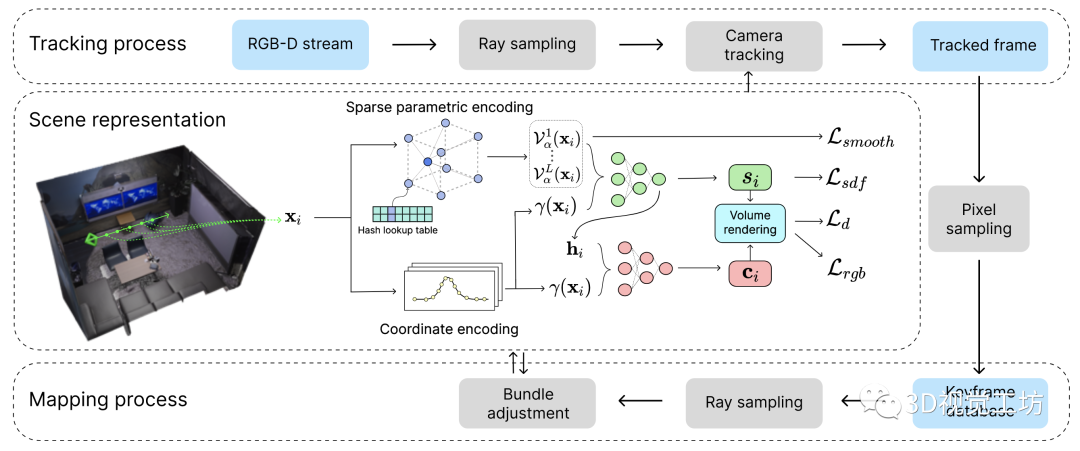
图3:Co-SLAM概览。1)场景表示: 使用新的联合坐标+参数编码,输入坐标通过两个浅MLP映射到RGB和SDF值。2)跟踪: 通过最小化损失来优化每帧相机的位姿。3)建图: 用从所有帧采样的射线进行全局BA,联合优化场景表示和相机位姿。
图3为Co-SLAM的概览。给定已知相机内参的输入RGB-D流,通过联合优化摄像机姿态和神经场景表示,进行稠密建图和跟踪。具体来说,我们的隐式表示将世界坐标映射为颜色和截断符号距离(TSDF) 值:

与大多数SLAM系统类似,该过程分为跟踪和建图。
通过在第一帧上运行几个训练迭代来执行初始化。
对于后续的每一帧,首先优化相机位姿,并使用简单的恒速运动模型进行初始化。然后对一小部分像素/光线进行采样,并将其复制到全局像素集。
每次建图迭代中,对从全局像素集随机采样的一组像素执行全局BA,以联合优化场景表示和所有相机位姿。
2.1 联合坐标和参数编码
由于MLP固有的一致性和光滑性,基于坐标的表示法实现了高保真场景重建。然而,当这些方法在顺序设置中进行优化时,往往会遭遇缓慢的收敛和灾难性的遗忘。相反,基于参数编码的方法提高了计算效率,但在空洞填充和光滑性方面存在不足。由于速度和一致性对于真实世界的SLAM系统来说都是至关重要的,我们提出了一种结合了两者的优点的联合坐标和参数编码:采用坐标编码来表示场景,而使用稀疏参数编码来加速训练。
具体地,使用One-blob编码[16],而不是将空间坐标嵌入多个频带。场景表示采用基于多分辨率哈希的特征栅格[15],每个层次的空间分辨率在最粗分辨率和最细分辨率之间逐级设置。通过三线性插值法查询每个采样点处的特征向量。几何解码器输出预测的SDF值和特征向量:
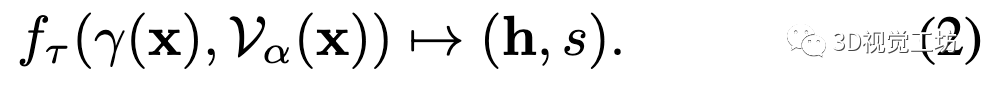
最后,颜色MLP预测RGB值:
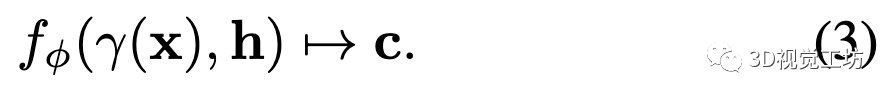
这里的是可学习的参数。在基于哈希的多分辨率特征网格表示中加入One-blob编码,可实现快速收敛、高效的内存使用和在线SLAM所需的空洞填充。
2.2 深度和颜色渲染
和iMAP, NICE-SLAM一样,我们通过沿采样光线积分预测值来渲染深度和颜色。具体地说,给定相机原点和光线方向,我们均匀采样个点,深度值为和预测颜色, 并将颜色和深度渲染为
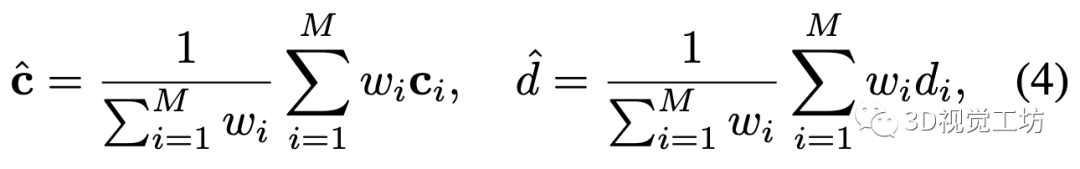
其中,是沿光线计算的权重。
需要转换函数来将预测的SDF 转换为权重。本文不采用NeuS中提出的渲染方程,而是遵循文献[1]中简单的钟形模型,通过将两个Sigmoid函数相乘来直接计算权重:
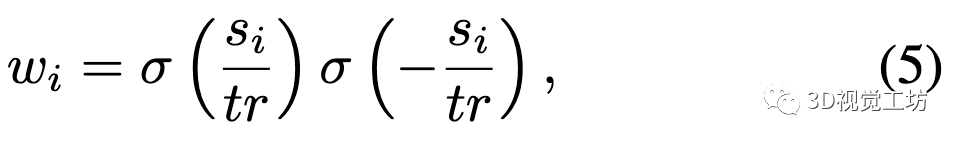
其中,是截断距离。
深度引导的采样:对于沿每条光线的采样,我们观察到重要性采样没有显示出显著的改进,同时减慢了跟踪和建图的速度。相反,我们使用深度引导的采样:除了在和边界之间均匀采样的点外,对于具有有效深度测量的光线,进一步在范围内均匀采样个近表面点,其中是小的偏移量。
2.3 跟踪与BA
目标函数:跟踪和BA是通过最小化关于可学习参数和相机参数的目标函数进行的。颜色和深度的渲染损失是渲染结果与观测的2范数误差:
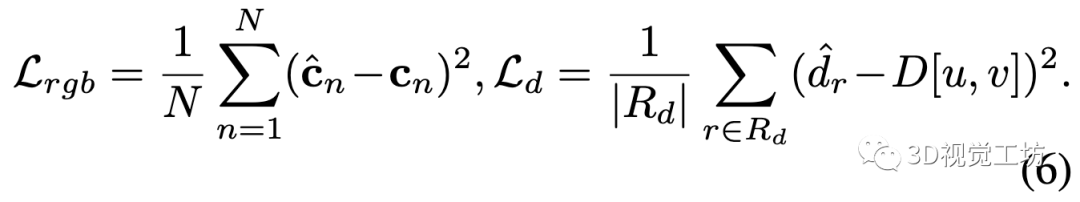
其中,是具有有效深度测量的射线集,是图像平面上的相应像素。
为了获得精确、平滑的细节几何重建,我们还应用了近似SDF和特征平滑损失。
具体地说,对于截断区域内的样本,即处的点,我们使用采样点与其观测深度值之间的距离作为用于监督的真实SDF值的近似值:
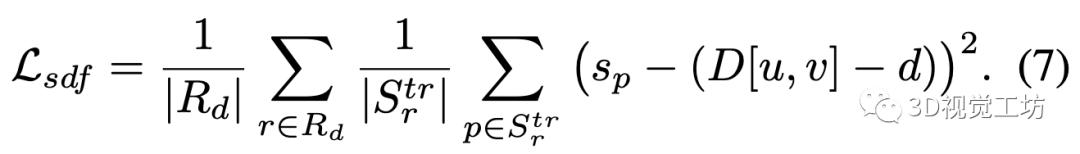
对于远离曲面的点(),我们应用自由空间损失,强制SDF预测为截断距离:
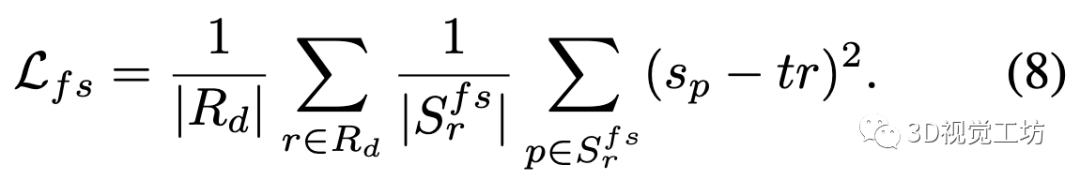
为了防止因未观察到的自由空间区域中的哈希冲突而引起噪声重建,我们对插值的特征执行额外的正则化:
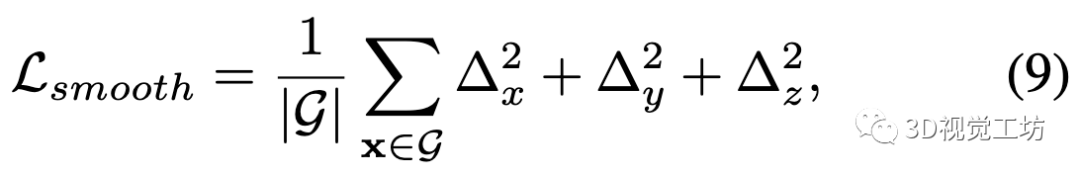
其中表示哈希网格上沿三个维度的相邻采样顶点之间的特征度量差。由于在整个特征网格上进行正则化对于实时建图在计算上是不可行的,所以我们在每次迭代中只在一个小的随机区域执行它。
相机跟踪:在每一帧跟踪相机到世界的变换矩阵。当新的帧到来时,首先使用恒速假设来初始化当前帧的位姿:
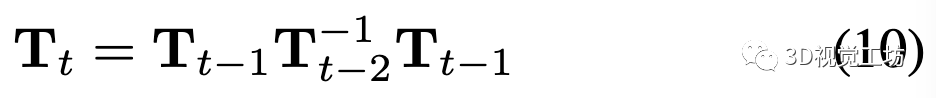
然后,我们选择当前帧内的个像素,并通过最小化相对于相机参数的目标函数来迭代地优化位姿。
BA:在神经SLAM中,BA通常包括关键帧选择以及相机位姿和场景表示的联合优化。传统的稠密视觉SLAM方法需要保存关键帧(KF)图像,因为损失是在所有像素上稠密地构建的。相比之下,正如iMAP首次展示的那样,神经SLAM的优势是BA可以处理稀疏的采样射线集。这是因为使用神经网络将场景表示为隐式场。然而,iMAP和NICE-SLAM没有充分利用这一点,它们仍然存储遵循传统SLAM范式的完整关键帧图像,并依赖于关键帧选择(例如信息增益、视觉重叠)来对一小部分关键帧(通常少于10个)执行联合优化。
Co-SLAM更进了一步,不再需要存储完整的关键帧图像或选择关键帧。相反,我们只存储像素的子集(约5%)来表示每个关键帧。这使我们能够更频繁地插入新关键帧,并维护更大的关键帧数据库。对于联合优化,我们从全局关键帧列表中随机采样总数为的光线,以优化场景表示和相机位姿。联合优化是以交替的方式执行的。具体地说,我们首先对场景表示进行步优化,并使用相机参数{xi_t}上的累积梯度更新相机位姿。由于每个相机位姿只使用6个参数,因此该方法可以在几乎不增加梯度积累的额外计算量的情况下提高相机位姿优化的鲁棒性。
3 实验
3.1 实验设定
数据集:我们在四个不同的数据集的各种场景上对Co-SLAM进行了评估。在iMAP和NICE-SLAM的基础上,我们对8个合成场景的重建质量进行了定量评估。我们还对NeuralRGBD的7个合成场景进行了评估,其仿真了有噪声的深度图。
对于位姿估计,我们评估了ScanNet的6个场景(真实位姿从BundleFusion获得)和TUM RGB-D数据集的3个场景(真实位姿由运动捕捉系统提供)的结果。
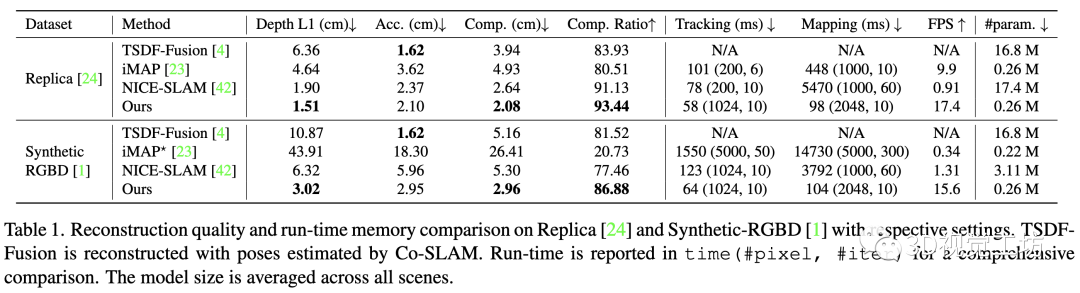
评价指标:我们使用Depth L1(cm)、Accuracy(cm)、Completion(cm)和Completion ratio(%)来评估重建质量,阈值为5cm。遵循NICE-SLAM,我们删除了任何相机截锥体之外的未观察到的区域。此外,我们还执行了额外的网格剔除,以删除相机锥体内但目标场景外的噪声点。我们观察到,加上这种网格剔除策略,所有方法都获得了性能提升(详见补充资料)。对于相机跟踪的评估,采用ATE RMSE(cm)。
基线:我们考虑iMAP和NICE-SLAM作为衡量重建质量和相机跟踪的主要基准。为了进行公平的比较,使用与Co-SLAM相同的网格剔除策略对iMAP和NICE-SLAM进行了评估。请注意,iMAP表示由NICE-SLAM作者发布的iMAP的重新实现,它比原始实现慢得多。为了研究真实数据集上精度和帧率之间的权衡,报告了我们方法的两个版本的结果:Ours指的是我们提出的方法(实现实时操作),而Ours表明我们的方法运行了两倍的跟踪迭代。
实现细节:我们在配备3.60 GHz Intel Core i7-12700K CPU和NVIDIA RTX 3090ti GPU的台式PC上运行Co-SLAM。对于默认设置(Ours)在Replica数据集上以17FPS运行的实验,我们使用像素,10次迭代进行跟踪,并使用每5帧5%的像素进行全局BA。我们沿每条相机光线采样个规则点和个深度点,cm。有关所有数据集的更多具体设置,请参阅补充资料。
3.2 跟踪与重建评估
Replica数据集

本文的方法实现了更快更好的重建结果。iMAP在未观察到的区域实现了看似合理的补全,但结果过于平滑,而NICE-SLAM保留了更多的重建细节,但结果包含一些伪影(例如床边的地板、椅子的靠背)。Co-SLAM方法成功地保留了这两种方法的优点,实现了一致的补全和高保真的重建结果
NeuralRGBD中的Synthetic RGBD数据集:包含许多薄结构,并仿真了实际深度传感器测量中存在的噪声。我们的方法明显优于基线方法(见表1),同时仍在实时运行(15FPS)。

总体而言,Co-SLAM可以捕捉到精细的细节(例如酒瓶、椅子腿等)并产生完整而流畅的重建。NICE-SLAM产生的重建细节较少且噪音较大,并且无法执行空洞填充,而iMAP在某些情况下跟踪丢失了。
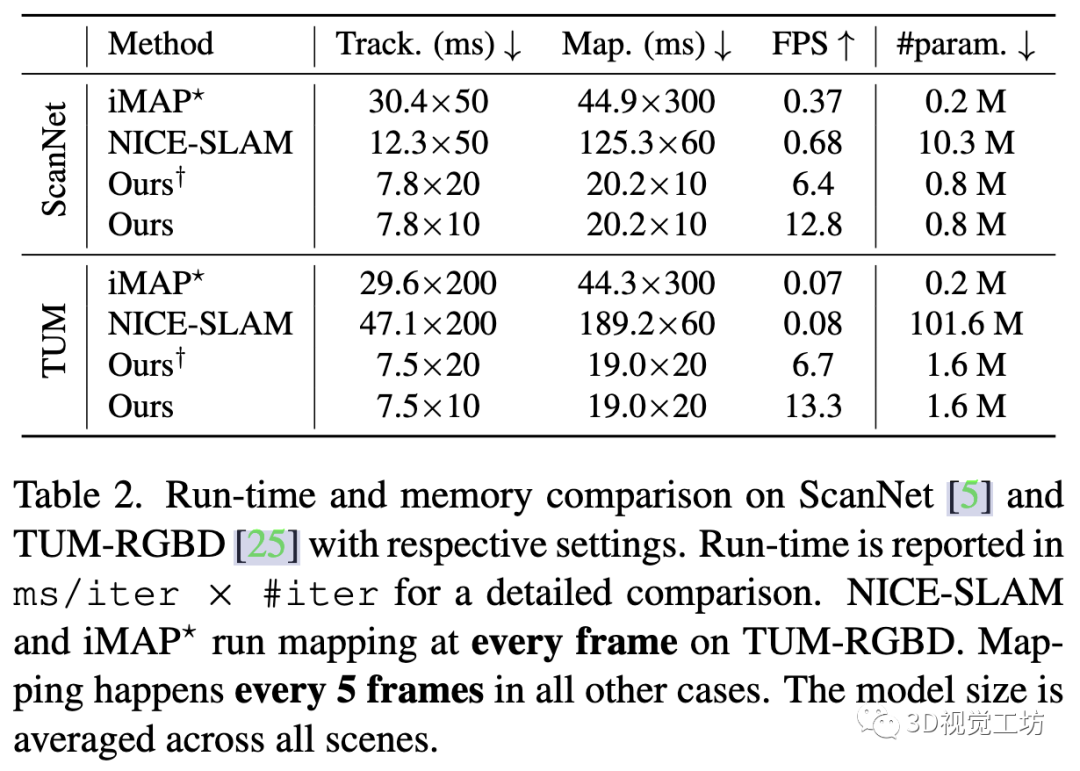
ScanNet数据集:在来自ScanNet的6个真实序列上评估了Co-SLAM的相机跟踪精度。绝对轨迹误差(ATE)是通过比较预测轨迹和真实轨迹(由BundleFusion生成)获得的。
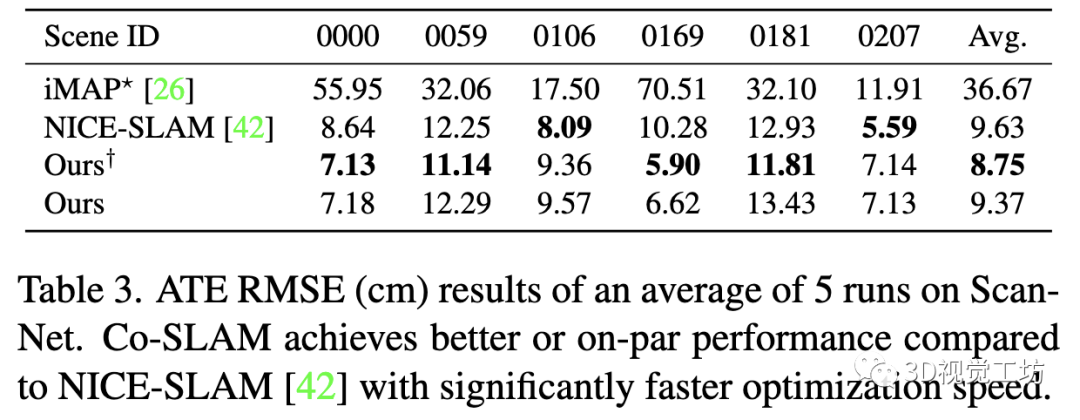
表3表明,与NICE-SLAM相比,在运行频率为6−12 Hz时,我们的方法获得了更好的跟踪结果,跟踪和建图迭代次数更少(见表2)。

图6显示,Co-SLAM以更平滑的结果和更精细的细节实现了更好的重建质量(例如,自行车)。
TUM数据集:进一步评估了在TUM数据集上的跟踪精度。
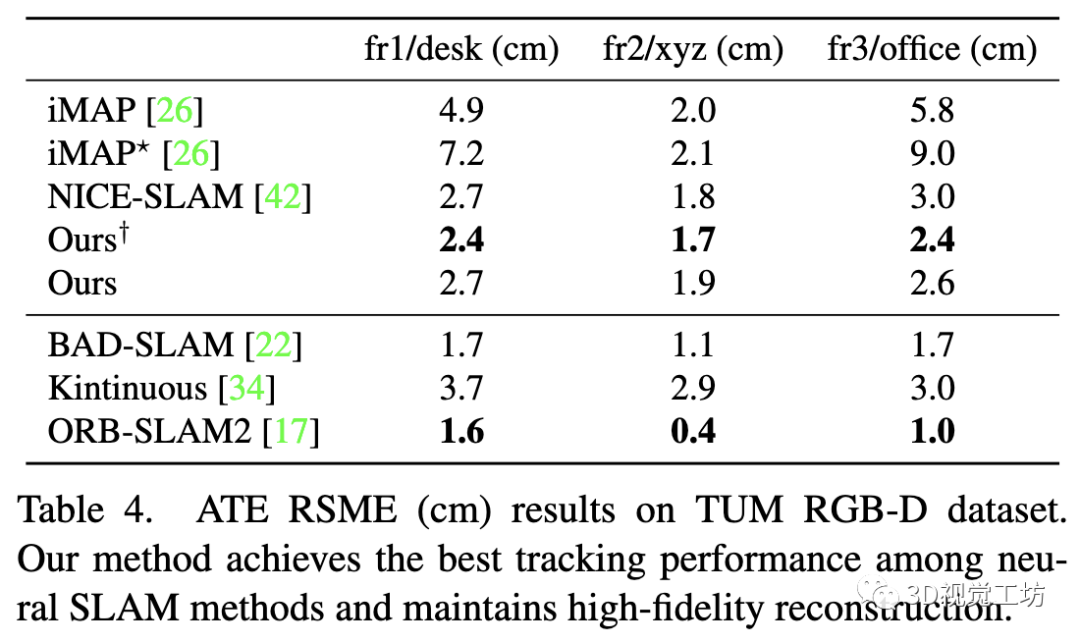
如表4所示,我们的方法在13FPS下获得了具有竞争力的跟踪性能。通过增加跟踪迭代次数(Ours),我们的方法在神经SLAM方法中获得了最好的跟踪性能,速度降为6.7Hz。虽然Co-SLAM算法仍然不能超越传统的SLAM方法,但它缩小了神经网络和传统方法之间的跟踪性能差距,同时提高了重建的保真度和完整性。
3.3 性能分析
运行时间和内存分析:在我们的默认设置(Ours)下,Co-SLAM可以在配备3.60 GHz Intel Core i7-12700K CPU和NVIDIA RTX 3090ti GPU的台式PC上以15Hz以上的频率运行。在更有挑战性的场景例如ScanNet和TUM数据集上,Co-SLAM仍可实现5−13Hz的运行时间。
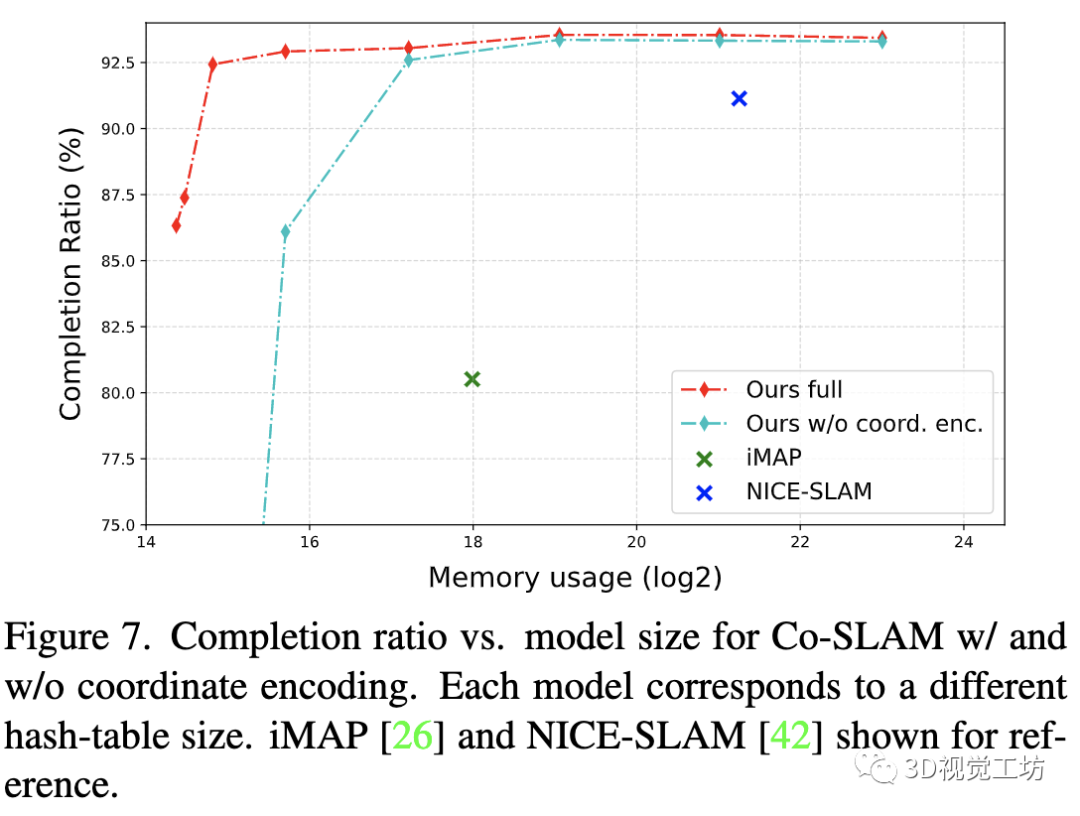
图7展示了重建质量关于内存使用的关系。由于稀疏的参数编码,我们的方法比NICE-SLAM需要显著更少的内存,同时能实时运行并获得准确的重建结果。令人惊讶的是,我们发现,在进一步压缩内存占用(增加哈希冲突的可能性)的情况下,Co-SLAM的性能仍然优于iMAP,这表明我们的联合编码提高了单一编码的表示能力。请注意,此图为了说明,我们在整个哈希编码中使用相同的空间分辨率。理想情况下,可以进一步降低空间分辨率以最小化哈希冲突并获得更好的重建质量。
场景补全:图2展示了在小场景上使用不同编码策略的空洞填充的图示。基于坐标编码的方法以较长的训练时间为代价来实现看似合理的补全,而基于参数编码的方法由于其局部性而在空洞填充方面失败。通过应用我们新的联合编码,我们观察到Co-SLAM可以实现平滑的空洞填充且保持精细的结构。
3.4 消融实验
联合坐标和参数编码的有效性:
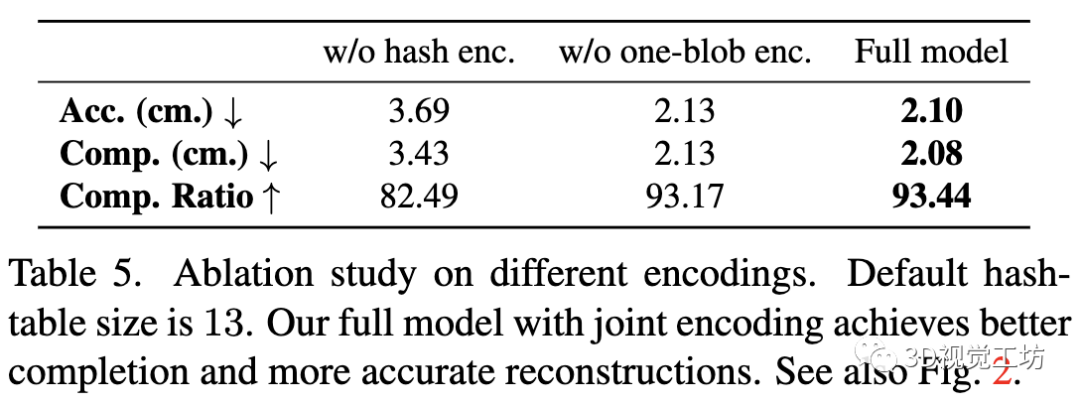
我们的完整模型比使用单一编码(仅使用one-blob或仅使用哈希编码)具有更高的准确率和更好的完整性。此外,图7说明当压缩了哈希查找表的大小时,具有完整编码的模型比只有哈希编码的模型更鲁棒。
全局BA的有效性:

表6显示了我们的SLAM方法在使用不同BA策略的6个ScanNet场景上的平均ATE:
(w/o BA):纯跟踪;
(LBA):使用来自10个局部关键帧的光线的BA,类似于NICE-SLAM策略;
(GBA-10):仅使用从所有过去关键帧中随机选择的10个关键帧的光线的BA;
(GBA):Co-SLAM的全局BA策略。我们观察到,使用来自少量(10)关键帧(LBA和GBA-10)的光线会导致较高的ATE误差。但是,当从整个序列(GBA-10)而不是局部(LBA)中选择关键帧时,标准差会大大降低。对所有关键帧的光线进行采样(GBA)是整体最佳的策略,即使所有方法对总光线数(2048)进行采样时也是如此。
4 总结
本文提出了一种稠密实时神经RGB-D SLAM系统Co-SLAM。实验结果表明,采用坐标和参数联合编码与微小MLP作为场景表示,并用全局BA进行训练,在合理的空洞填充和高效的内存使用下,实现了高保真的建图和精确的跟踪。
局限性:Co-SLAM依赖于RGB-D传感器的输入,因此对光照变化和不准确的深度测量很敏感。信息引导的像素采样策略可以进一步减少像素数,提高跟踪速度,而不是随机采样关键帧像素。引入回环检测可能会带来进一步的改进。
审核编辑 :李倩
-
SLAM技术的应用及发展现状2018-12-06 15565
-
视觉SLAM笔记总结2020-07-17 2838
-
SLAM技术目前主要应用在哪些领域2020-12-01 3355
-
激光SLAM与视觉SLAM有什么区别?2021-07-05 4737
-
SLAM的相关知识点分享2021-08-30 2194
-
激光SLAM和视觉VSLAM的分析比较2021-11-10 5335
-
高仙SLAM具体的技术是什么?SLAM2.0有哪些优势?2018-05-15 10106
-
什么是SLAM技术?SLAM技术的工作原理2021-01-22 22467
-
机器人主流定位技术:激光SLAM与视觉SLAM谁更胜一筹2020-12-26 2803
-
SLAM的原理 手持SLAM的优缺点讲解2022-12-27 7195
-
用于SLAM的神经隐含可扩展编码2023-01-30 1636
-
用于神经场SLAM的矢量化对象建图2023-06-15 1899
-
slam技术研究现状 SLAM技术开发和应用挑战2023-08-01 2085
-
视觉SLAM是什么?视觉SLAM的工作原理 视觉SLAM框架解读2023-09-05 5899
-
自动驾驶中如何将稀疏地图与视觉SLAM相结合?2025-10-28 913
全部0条评论

快来发表一下你的评论吧 !
