

英特尔如何玩转Chiplet?
处理器/DSP
描述
在英特尔最近的 DCAI 网络研讨会上,公司执行副总裁 Sandra Rivera 透露了英特尔第五代至强可扩展处理器 Emerald Rapids 的外观。英特尔已决定通过仅使用 2 个大die设计 Emerald Rapids (EMR) 来回溯一代小芯片(chiplet)。
它的前一代产品 Sapphire Rapids (SPR) 有 4 个较小的die。与直觉相反,英特尔将其最高核心数配置中的小芯片数量从 4 个减少到 2 个。这会让大多数人摸不着头脑,因为包括英特尔在内的每个人都在谈论使用更小的die来分解小芯片以提高产量和扩展性能。
本文中,我们将更深入地了解英特尔对 Emerald Rapids (EMR) 所做的具体更改。我们将查看我们创建的平面图,详细说明工作负载性能、成本比较以及与 AMD 的竞争环境。此外,我们将详细介绍 Sapphire Rapids 发生的巨大变化,但大多数人都忽视了这一变化。
Emerald Rapids的变化
英特尔这一代产品最大的变体 EMR-XCC,将核心数从 SPR 上的 60 个增加到 64 个。然而,封装上共有 66 个物理内核,它们被分类以提高良率。英特尔并不打算像他们对 60 核 SPR 所做的那样,将完全启用的 66 核 EMR SKU 产品化。EMR 结合了两个 33 核die,而 SPR 使用四个 15 核die。
另一个主要变化是英特尔显著增加了共享 L3 缓存,从 SPR 上的每个内核 1.875MB 到 EMR 上高达 5MB 的每个内核!这意味着高端 SKU 在所有内核中都配备了 320MB 的共享 L3 缓存,是 SPR 提供的最大值的 2.84 倍。Local Snoop Filters 和 Remote Snoop Filters 也相应增加,以适应大型 L3 缓存的增加(LSF – 3.75MB/核心,RSF – 1MB/核心)。
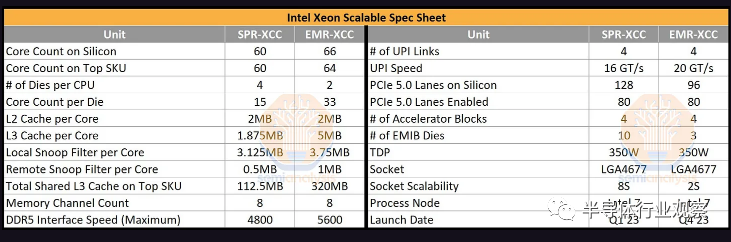
DDR5 内存支持已从 4800 MT/s 增加到 5600 MT/s。插槽间通信(inter-socket)的 UPI 速度已从 16 GT/s 升级到 20 GT/s。奇怪的是,尽管插槽间速度更高,但支持的插槽总数从 8 个减少到 2 个。这样做可能是为了加快上市时间,因为它只影响 AMD 无论如何都没有参与竞争的一小部分市场。所有这些都与同一 LGA 4677 Socket E1 上的现有“Eagle Stream”平台直接兼容。PCIe 通道数保持不变,尽管最终添加了 CXL 分叉支持,这对 Sapphire Rapids 来说是一个痛处。
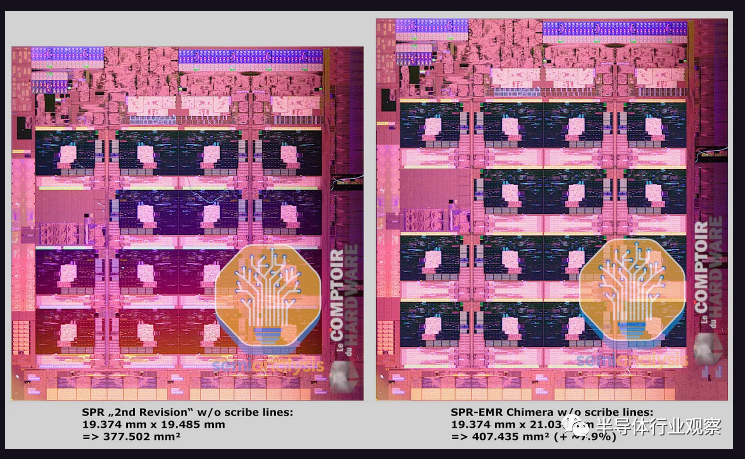
仔细观察封装,我们注意到英特尔能够将更多内核和更多缓存塞入比 SPR 更小的区域!包括划线(scribe lines)在内,两个 763.03 平方毫米的裸片总面积为 1,526.05 平方毫米,而 SPR 使用四个 393.88 平方毫米的裸片,总面积为 1,575.52 平方毫米。EMR 缩小了 3.14%,但印刷内核(printed cores )增加了 10%,L3 缓存增加了 2.84 倍。这一令人印象深刻的壮举部分是通过减少小芯片的数量实现的。当然,还有其他因素在起作用,有助于减少 EMR 的面积。
在为 EMR 画平面图模型时,我们发现不可能将必要的功能塞进一个足够小的区域以匹配 Intel 所揭示的内容。我们使用 SPR 中的组件作为参考,但它最终变得太大了。这是因为英特尔优化了其物理设计,使一些功能更加紧凑和面积效率更高,从而进一步缩小面积。更重要的是,这不是英特尔第一次改变物理设计以节省面积。
Sapphire Rapids的die微缩
尽管没有太多公开讨论,英特尔还在生产 E5 步进过程中最黑暗的日子里对 Sapphire Rapids 进行了彻底的重新设计。信不信由你,Sapphire Rapids 小芯片有两种不同的物理设计和芯片尺寸。
Raja Koduri 在 2021 年架构日展示了更大、更早的 SPR 版本,并且还出现在第三方拆解的早期工程样本的第中。更小、更新的SPR变体在 Vision 2022 上展示,它被最终生产 SKU 使用。
英特尔展示了两个版本的 SPR 的晶圆。较早的修订版每个晶圆有 137 个裸片,而最终版本有 148 个。这需要一直回到芯片的平面规划和物理设计。一个主要的好处是,它通过在每个晶圆上多制造 8% 的裸片,改善了 Sapphire Rapids 的成本结构。
在长期提出期间所做的大量硅修改中,我们发现英特尔改变了核心和外围的物理设计和布局,以实现 5.7% 的面积减少。I/O 区域(North Cap)已重新实现,die高度减少了 0.46 毫米。I/O 块之间的水平间距也得到了优化,die宽度节省了 0.46 毫米。容纳 CPU 核心、高速缓存和内存控制器的网状区块区域也必须缩小 3.43% 的面积以适应更紧凑的布局规划,同时调整减少 CPU 核心宽度和tile间距。
一般来说,设计团队在发布前为同一产品制作 2 种不同布局和裸片尺寸的情况很少见,因为上市时间至关重要。也许 Sapphire Rapids 的多次延误给了他们足够的时间来寻求额外的面积节省。如果它是按照最初的 2021 年目标推出的,我们可能不会看到这个较小的修订版,至少在最初是这样。
同样,英特尔对 EMR 应用了相同的布局优化原则,特别是在容纳巨大的 L3 时。在这里,我们展示了对核心和mesh tile进行更改的模型,包括在核心上方明显更高的 SRAM 部分,以容纳额外的 L3 缓存和 Snoop Filters。这样一来,每个核心tile的面积增加了 11.8%。得益于 SRAM 物理设计的优化,英特尔能够容纳 3200 KB 以上的 L3 缓存以及更大的 LSF,并通过仅增加 1.41 mm² 来将 RSF 翻倍。
Emerald Rapids 的平面图
以下是 EMR-XCC 的平面布置图。在两个die中,66 核加上 I/O 部分在 7x14 网状互连网络上捆绑在一起。

在中间,网状网络在 EMIB 上跨越片外边界(off-chip boundary) 7 次。这与 SPR 上跨四个芯片的 8x12 网格和 20 个芯片外交叉点形成对比。此拓扑更改的影响将在下面的性能部分中介绍。
从上面显示的布局中,我们可以看出,尽管这两个小芯片非常相似,但它们实际上使用了不同的流片和掩模组,英特尔再次像 SPR 那样使用镜像芯片。使用旋转 180 度的相同裸片将使掩模组要求减半,但会使跨 EMIB 的多裸片结构 IO 复杂化。

说到 EMIB,硅桥( silicon bridges)的数量从 10 个大幅减少到 3 个,中间的硅桥更宽以适应 3 个网格柱。奇数个网格列也出现在单片版本的 SPR上,这也可能是他们必须对die进行镜像的部分原因,因为旋转会干扰对齐并使导线交叉复杂化。
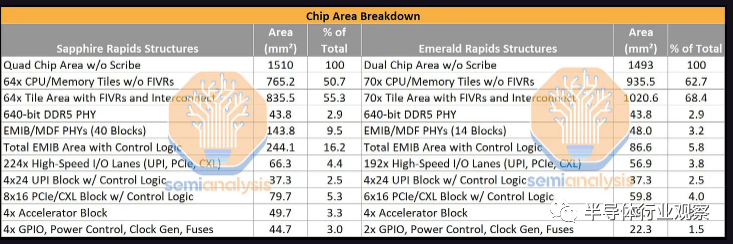
通过这种新布局,我们可以看到小芯片重新聚合的真正好处。用于小芯片接口的总面积百分比从 SPR 上的总die面积的 16.2% 变为 EMR 上的仅 5.8%。或者,我们可以查看核心区域利用率,即总die面积中有多少用于计算核心和缓存。这从 SPR 的50.67% 上升到 EMR 的好得多的 62.65%。这一收益的部分原因还在于 EMR 上较少的物理 IO,因为 SPR 具有更多的 PCIe 通道,这些通道仅在单插槽工作站段上启用。
如果您的良率很好,为什么在可以使用更少、更大的裸片时浪费冗余 IO 和小芯片互连的面积?英特尔传奇的 10nm 工艺从 2017 年的以来已经走了很长一段路,现在在其更名后的intel 7 形式中取得了相当不错的成绩。
成本,不是你想的那样
所有这些关于布局优化和在更小的总硅面积中塞入更多内核和缓存的讨论会让您相信 EMR 的制造成本低于 SPR。事实并非如此。
从根本上说,大矩形不能整齐地放在圆形晶圆上。回到每个晶圆的裸片总数,我们估计 EMR-XCC 晶圆布局与 SPR-MCC 相匹配,这意味着每个晶圆有 68 个裸片。假设完美的良率和芯片可回收性,EMR 只能在每个晶圆上制造 34 个 CPU,低于每个 SPR 晶圆上的 37 个 CPU。一旦将完美良率以外的任何因素考虑在内,EMR 的情况就会变得更糟,这表明使用更大die的劣势。
尽管每个 CPU 使用的硅面积较少,但 EMR 实际上的生产成本高于 SPR。
公平地说,如果我们要将布局更改的好处与成本隔离开来,我们应该将 EMR 与每核 5MB L3 的假设 SPR 进行比较。对于这个 4 小芯片变体,根据这个更高的理论芯片的面积估计导致每个晶圆有 136 个总die或每个晶圆有 34 个 CPU,使其与实际的 2 小芯片设计相同。此外,将 EMIB 芯片的数量从 10 个减少到 3 个肯定会提高 2-chiplet 解决方案的封装成本和产量。
那么,如果布局变化和小芯片减少对降低成本没有帮助,那么 EMR 的主要驱动因素是什么?
审核编辑:刘清
-
#高通 #英特尔 #Elite 高通X Elite芯片或终结苹果、英特尔的芯片王朝深圳市浮思特科技有限公司 2023-10-27
-
有高手破解了英特尔倍频吗2010-12-22 2779
-
英特尔转型移动领域难言乐观2012-11-07 3423
-
英特尔多款平板电脑CPU将于明年推出2013-12-19 4056
-
产业风暴,英特尔能否扳倒ARM?2016-09-26 4944
-
【AD新闻】英特尔解读全球晶体管密度最高的制程工艺2017-09-22 3278
-
启用英特尔Optane被视为“1.8TB硬盘+英特尔Optane”是什么原因?2018-10-31 6031
-
英特尔爱迪生闪存失败2018-11-02 5366
-
为什么选择加入英特尔?2019-07-25 5385
-
苹果放弃未来在iPhone上使用英特尔5G基带芯片 精选资料推荐2021-07-23 3056
-
介绍英特尔®分布式OpenVINO™工具包2021-07-26 1854
-
英特尔重新思考解决芯片短缺的常用基板2022-06-20 7036
-
Chiplet使英特尔PSG能够为其FPGA添加许多新功能2023-08-24 2159
-
英特尔发布全球首款基于UCIe连接的Chiplet(小芯片)处理器2023-09-22 1526
-
英特尔推出集成光学计算互联OCI Chiplet芯片2024-06-28 4200
全部0条评论

快来发表一下你的评论吧 !
