

为什么Chiplets对处理器的未来如此重要?
处理器/DSP
描述
Chiplets的主导地位才刚刚开始。
Chiplets已经使用了几十年,但它们之前一直被用于少量特殊的用途。现在,它们处于技术的最前沿,全世界有数百万人在台式电脑、工作站和服务器中使用它们。 处理器行业领导者利用Chiplets重新站在了创新的最前沿,可以预见未来Chiplets将成为计算世界的标准之一。因此,有必要了解Chiplets以及它们如此重要的确切原因。
什么是Chiplets?
Chiplets是分隔式的处理器。不是将每个部分合并到一个芯片中(被称为单片机的方法),而是将特定的部分作为独立的芯片来制造。
然后,这些独立的芯片通过一个复杂的连接系统被安装在一起,成为一个单一的封装。 这种安排使能够让使用最新的制造方法的部件尺寸缩小,提高了工艺的效率,使其能够装入更多的部件。
芯片中不能明显缩小或不需要缩小的部分可以用更旧的、更经济的方法生产。
虽然制造这种处理器的过程很复杂,但总体成本通常较低。此外,它为处理器公司提供了一个更易于管理的途径来扩大其产品范围。
为了充分理解为什么处理器制造商转向芯片,我们必须首先深入了解这些设备是如何制造的。
CPU和GPU开始时是由超纯硅制成的大圆盘,通常直径略小于12英寸(300毫米),厚度为0.04英寸(1毫米)。
这块硅片经历了一系列复杂的步骤,形成了不同材料的多层--绝缘体、电介质和金属。这些层的图案是通过一种叫做光刻的工艺创建的,在这种工艺中,紫外线通过放大的图案(掩膜)照射,随后通过透镜缩小到所需的尺寸。该图案以设定的间隔在晶圆表面重复出现,每一个都将最终成为一个处理器。
由于芯片是长方形的,而晶圆是圆形的,图案必须与圆盘的周边重叠。这些重叠的部分最终会被丢弃,因为它们是无功能的。
一旦完成,将使用应用于每个芯片的探针对晶圆进行测试。电检结果告知工程师关于处理器的质量与一长串标准的关系。这个初始阶段被称为芯片分选,有助于确定处理器的 "等级"。
例如,如果该芯片打算成为一个CPU,那么每个部分都应该正确运作,在特定的电压下在设定的时钟速度范围内运行。然后根据这些测试结果对每个晶圆部分进行分类。
完成后,晶圆被切割成单独的碎片,或称 "模具",可供使用。然后,这些模具被安装在一个基板上,类似于一个专门的主板。
处理器经过进一步的包装(例如,用散热器),然后就可以进行销售了。整个过程可能需要数周的制造时间,台积电和三星等公司对每个晶圆收取高额费用,根据所使用的工艺节点,费用在3000至20000美元之间。 "工艺节点 "(Process node)是用来描述整个制造系统的术语。历史上,它们是以晶体管的栅极长度命名的。
然而,随着制造技术的改进,允许越来越小的组件,命名不再遵循芯片的物理方面,现在它只是一个营销工具。然而,每一个新的工艺节点都会带来比前者更多的好处。
它的生产成本可能更低,在相同的时钟速度下消耗更少的功率(或者相反),或者具有更高的密度。后者衡量的是在一个给定的芯片区域内可以容纳多少元件。
在下图中,你可以看到这些年来GPU(你在PC中发现的最大和最复杂的芯片)的发展情况。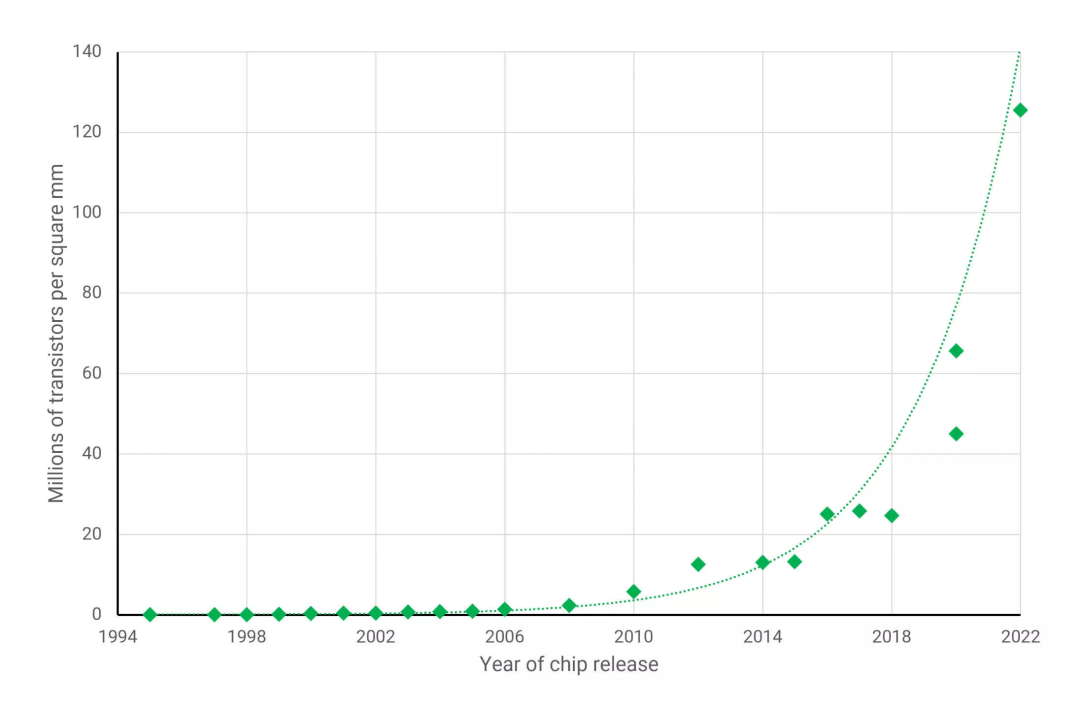
工艺节点的改进为工程师提供了提高其产品能力和性能的手段,而不必使用大而昂贵的芯片。
然而,上图只说明了部分情况,因为不是处理器的每个方面都能从这些进步中受益。芯片内的电路可以被分配到以下几大类中的一类:
(1)逻辑,处理数据、数学和决策;
(2)存储器,通常是SRAM,用于存储逻辑的数据;
(3)模拟 ,管理芯片和其他设备之间信号的电路。
当逻辑电路随着工艺节点技术的每一次重大进步而继续缩小时,模拟电路几乎没有变化,SRAM也开始达到极限。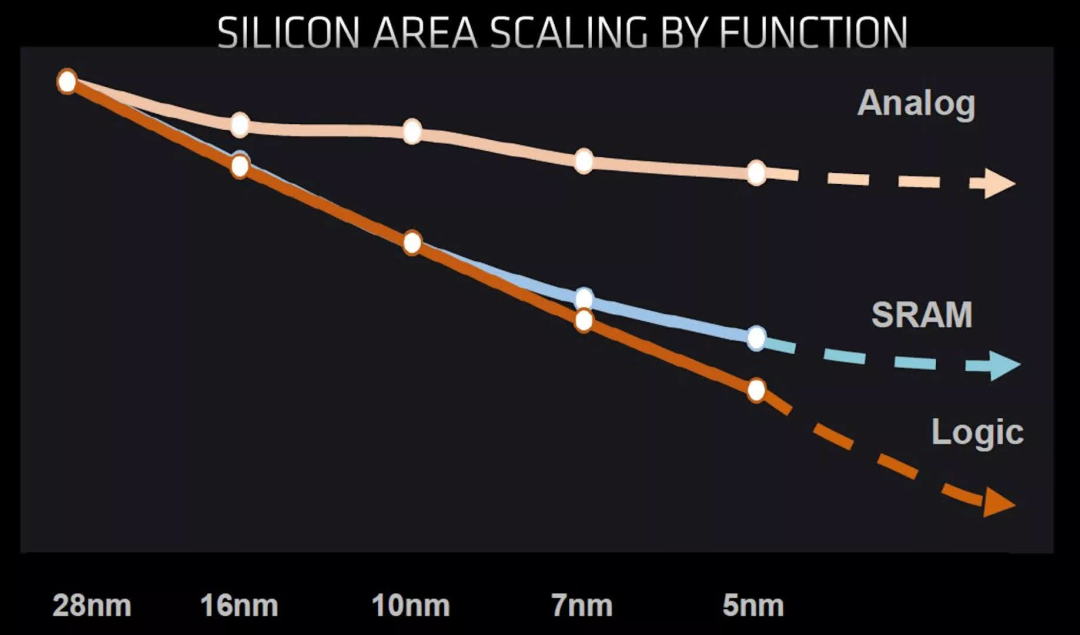
虽然逻辑仍然构成了芯片的最大部分,但今天的CPU和GPU中的SRAM数量在近年来有了显著增长。
例如,AMD在其Radeon VII显卡中使用的Vega 20芯片的L1和L2缓存合计为5MB。仅仅两代GPU之后,Navi 21就有超过130MB的各种缓存--比Vega 20多了25倍,令人瞩目。
可以预期,随着新一代处理器的开发,这些水平将继续提高,但由于存储器的规模没有像逻辑那样缩小,在同一工艺节点上制造所有电路的成本效益将越来越低。
在一个理想的世界里,人们在设计芯片时,模拟部分在最大和最便宜的节点上制造,SRAM部分在更小的节点上制造,而逻辑部分则保留给绝对尖端的技术。
不幸的是,这在实践中是无法实现的。然而,存在一种替代方法。
分而治之
早在1995年,英特尔推出了其原始P5处理器的继任者--奔腾II。它与当时的常规产品不同的是,在塑料外壳下有一块电路板,里面有两个芯片:主芯片,包含所有的处理逻辑和模拟系统,以及一个或两个独立的SRAM模块,作为二级缓存。
英特尔公司生产主芯片,但缓存来自其他公司。在20世纪90年代中后期,这将成为台式电脑的相当标准,直到半导体制造技术改进到可以将逻辑、内存和模拟全部集成到同一芯片中。
虽然英特尔继续尝试在同一封装中使用多个芯片,但它在很大程度上坚持了所谓的处理器单片(monolithic)方法(即一个芯片用于一切)。
对于大多数处理器来说,不需要超过一个芯片,因为制造技术已经足够熟练(而且价格低廉),可以保持简单直接。然而,其他公司对遵循多芯片方法更感兴趣,最引人注目的是IBM。2004年,IBM提供了8芯片版本的POWER4服务器CPU,它由四个处理器和四个缓存模块组成,都安装在同一个机身内(称为多芯片模块或MCM方法)。
大约在这个时候,"异质集成"一词开始出现,部分原因是DARPA(国防高级研究计划局)所做的研究工作。异质集成的目的是将处理系统的各个部分分开,在最适合每个部分的节点上单独制造,然后将它们合并到同一个包中。 今天,这被称为系统级封装(SiP),从一开始就是为智能手表配备芯片的标准方法。
例如,第1代的Apple Watch在单一结构中装有一个CPU、一些DRAM和NAND闪存、多个控制器和其他组件。
通过将不同的系统全部放在单个芯片上(称为片上系统或SoC),可以实现类似的效果。但是,这种方法不允许利用不同的节点价格,也不能以这种方式制造每个组件。
对于技术供应商来说,对利基产品使用异构集成是一回事,但将其用于其大部分产品组合则是另一回事。这正是AMD对其处理器系列所做的。2017年,这家半导体巨头以单芯片Ryzen桌面CPU的形式发布了其Zen架构。几个月后,两条多芯片产品线Threadripper和EPYC首次亮相,后者拥有多达四个芯片。
随着两年后Zen 2的推出,AMD完全接受了异质集成,MCM,SiP 。他们将大部分模拟系统移出处理器,并将它们放入单独的芯片中。这些是在更简单、更便宜的工艺节点上制造的,而更高级的流程节点则用于剩余的逻辑和缓存。 自此,Chiplets成为流行。
越小越好
为了准确理解AMD为什么选择这个方向,我们来看看下面的图片。它展示了Ryzen 5系列的两款CPU,左边是采用所谓Zen+架构的2600,右边是由Zen 2驱动的3600。两种型号的散热器都已被拆除,照片是用红外相机拍摄的。2600的单芯片容纳了八个核心,尽管其中两个核心在这个特定的模型中被禁用。
这也是3600的情况,但在这里我们可以看到,封装中有两个模具--顶部的Core Complex Die(CCD),容纳了核心和缓存,底部的Input/Output Die(IOD)包含所有控制器(用于内存、PCI Express、USB等)和物理接口。 由于这两颗Ryzen CPU都适用于同一个主板插座,这两张图片基本上是按比例绘制的。
从表面上看,3600的两个芯片似乎比2600的单个芯片有更大的综合面积,但外表可能是欺骗性的。 如果我们直接比较包含核心的芯片,很明显可以看到旧型号中模拟电路所占用的空间(围绕着金色的核心和缓存的蓝绿颜色)。然而,在Zen 2 CCD中,用于模拟系统的芯片面积很少;它几乎完全由逻辑和SRAM组成。
Zen+芯片的面积为213平方毫米,由GlobalFoundries使用其12纳米工艺节点制造。对于Zen 2,AMD保留了GlobalFoundries对125平方毫米IOD的服务,但在73平方毫米的CCD上使用了台积电的N7节点。
Zen+ (上)vs Zen 2 CCD (下) 较新型号的芯片的综合面积更小,而且它还拥有两倍的L3缓存,支持更快的内存和PCI Express。然而,Chiplets方法最好的部分是,CCD的紧凑尺寸使AMD有可能将另一个CCD装入包装。这一发展催生了Ryzen 9系列,为台式电脑提供12和16核型号。更重要的是,通过使用两个较小的芯片而不是一个大的芯片,每个晶圆可能会产生更多的芯片。
就Zen 2 CCD而言,一块12英寸(300毫米)的晶圆可以比Zen+型号多生产85%的芯片。 从晶圆上取下的切片越小,就越不可能发现制造缺陷(因为它们往往是随机分布在光盘上的),所以考虑到所有这些,Chiplets不仅使AMD有能力扩大其产品组合,而且成本效益更高。相同的CCD可用于多个型号,每个晶圆可生产数百个。 但是,如果这种设计选择如此有优势,为什么英特尔不这样做呢?为什么我们没有看到它被用于其他处理器,如GPU?
跟随潮流
为了解决第一个问题,英特尔确实在采用全芯片路线,而且它的下一个消费者CPU架构(Meteor Lake)也将这样做。英特尔的方法有些独特,让我们来看看它与AMD的方法有何不同。 这一代处理器使用 "区块(tile)"一词而不是 "芯片",将以前的单片式设计分割成四个独立的芯片:(1)计算区块:包含所有的内核和二级缓存;(2)GFX区块:容纳集成GPU;(3)SOC区块:整合了L3高速缓存、PCI Express和其他控制器;(4)IO区块:容纳内存和其他设备的物理接口。
在SOC和其他三个区块之间存在高速、低延迟的连接,并且所有这些区块都与另一个被称为插板的芯片相连。这个插板为每个芯片提供电源,并包含它们之间的导线。然后,插板和四块区块被安装到另一块板上,以便将整个组件封装起来。
与英特尔不同,AMD不使用任何特殊的安装模具,而是有自己独特的连接系统,被称为Infinity Fabric,以处理芯片数据交易。电源传输通过一个相当标准的封装运行,而且AMD还使用较少的芯片。那么,为什么英特尔的设计是这样的呢? AMD的方法的一个挑战是,它不太适合超移动、低功耗领域。
这就是为什么AMD在该领域仍然使用单片式CPU。英特尔的设计允许他们混合和匹配不同的区块以满足特定的需求。例如,经济型笔记本电脑的预算型号可以到处使用小得多的芯片,而AMD只有一种尺寸的芯片用于每种用途。 英特尔系统的缺点是生产复杂且昂贵,尽管现在预测这将如何影响零售价格还为时尚早。然而,两家CPU公司都完全致力于芯片的概念。一旦制造链的每一部分都围绕它进行设计,成本就会降低。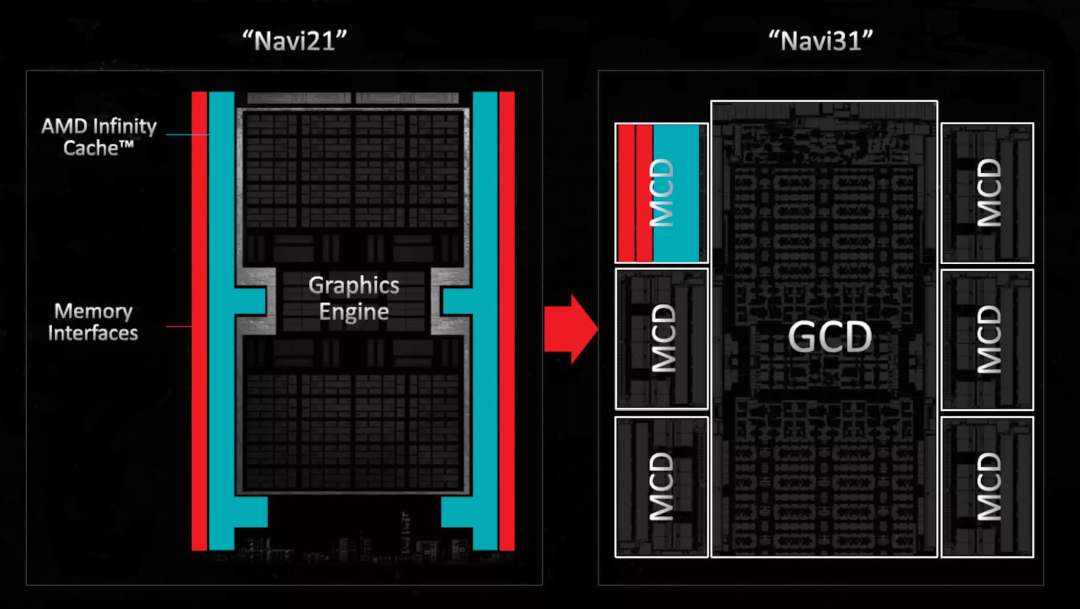
关于GPU,与芯片的其他部分相比,它们包含的模拟电路相对较少,但里面的SRAM数量正在稳步增加。
这就是为什么AMD将其芯片知识应用于其最新的Radeon 7000系列,Radeon RX 7900 GPU包括多个芯片--一个用于核心和二级缓存的大芯片,以及五六个Chiplets,每个芯片包含一片L3缓存和一个内存控制器。
通过将这些部件移出主芯片,工程师们能够大大增加逻辑数量,而不需要使用最新的工艺节点来控制芯片尺寸。然而,这一变化并没有增强图形组合的广度,尽管它可能确实有助于改善整体成本。
目前,英特尔和英伟达在其GPU设计方面没有显示出跟随AMD的迹象。
两家公司都使用台积电承担所有的制造任务,似乎满足于生产极其庞大的芯片,将成本转嫁给消费者。
随着图形领域的收入稳步下降,可能会在未来几年内看到每个GPU供应商都采用同样的路线。
用Chiplets实现摩尔定律
尽管在半导体制造方面取得了巨大的技术进步,但每个部件可以缩小的程度是有明确限制的。为了继续提高芯片的性能,工程师们基本上有两个途径:增加更多的逻辑,用必要的内存来支持它,以及提高内部时钟速度。关于后者,一般的CPU在这方面已经多年没有明显的变化了。
AMD的FX-9590处理器,从2013年开始,在某些工作负载中可以达到5GHz,而其当前型号的最高时钟速度是5.7GHz(Ryzen 9 7950X)。
英特尔最近推出了酷睿i9-13900KS,在合适的条件下能够达到6GHz,但其大多数型号的时钟速度与AMD的相近。 然而,改变的是电路和SRAM的数量。前面提到的FX-9590有8个核心(和8个线程)和8MB的L3缓存,而7950X3D拥有16个核心、32个线程和128MB的L3缓存。
英特尔的CPU在核心和SRAM方面也有类似的扩展。 Nvidia的第一个统一着色器GPU,即2006年的G80,由6.81亿个晶体管、128个内核和96 kB的二级缓存组成,其芯片面积为484 mm2。快进到2022年,当AD102推出时,它现在由763亿个晶体管、18432个内核和98304 kB的二级缓存组成,芯片面积为608 mm2。
1965年,飞兆半导体公司的联合创始人戈登·摩尔(Gordon Moore)观察到,在芯片制造的早期,在固定的最低生产成本下,芯片内的元件密度每年都在翻番。这一观察被称为摩尔定律,后来根据制造趋势,被解释为 "芯片中的晶体管数量每两年翻一番"。
近六十年来,摩尔定律一直是对半导体行业发展进程的合理准确描述。CPU和GPU在逻辑和内存方面的巨大进步是通过工艺节点的不断改进实现的,这些年来,组件变得越来越小。然而,这种趋势不可能永远持续下去,无论出现什么新技术。
像AMD和英特尔这样的公司并没有等待这个极限的到来,而是转向了Chiplets,探索它们的各种组合方式,以继续在创造更强大的处理器方面取得进展。
几十年后的今天,普通的个人电脑可能是由手掌大小的CPU和GPU组成的,但是剥开散热片,你会发现有许多微小的芯片--不是三四个,而是几十个,都巧妙地拼接和堆叠在一起。
Chiplets的主导地位才刚刚开始。
审核编辑:刘清
-
手机厂商为何对研发处理器如此执着2015-10-13 1131
-
多核处理器设计九大要素2011-04-13 3330
-
专用处理器,未来电机驱动的主流2015-12-31 5335
-
多核处理器的优点2019-06-20 5158
-
ARM与Intel处理器之间有什么区别?2019-10-14 3362
-
请问为什么RF值如此重要?2021-04-20 1729
-
请问处理器扩展性有什么重要之处?2021-06-17 1220
-
为什么leakage power如此重要2021-10-25 2589
-
什么是微处理器2009-06-17 2046
-
手机的处理器和内存哪个更重要2020-05-25 6917
-
EDA行业与微处理器设计共同面临的挑战2022-04-12 2373
-
嵌入式微处理器有哪几类 嵌入式微处理器包含哪些重要参数2024-05-04 2069
-
处理器的定义和种类2024-05-12 8481
-
为什么GPU对AI如此重要?2024-05-17 2187
-
微处理器在人工智能方面的应用2024-08-22 2383
全部0条评论

快来发表一下你的评论吧 !
