

详解英伟达芯片在自动驾驶的软件移植设计开发
电子说
描述
NIVIDIA DRIVE Orin 系列作为一个万用 SOC 芯片,可以用于各种不同的感知和通用计算任务,其优质的大算力、运行性能、完备的兼容性,以及丰富的 I/O 接口,可以减少系统开发的复杂度。这些特性使得 Orin 系列的芯片特别适合应用在自动驾驶系统。
整体上看,Orin系列芯片顶层SOC架构的模块主要由三部分处理单元组成:即 CPU、GPU 和硬件加速器组成。以当前较火的Orin-x作为典型说明英伟达芯片在其软件模块开发中是如何进行调用的。
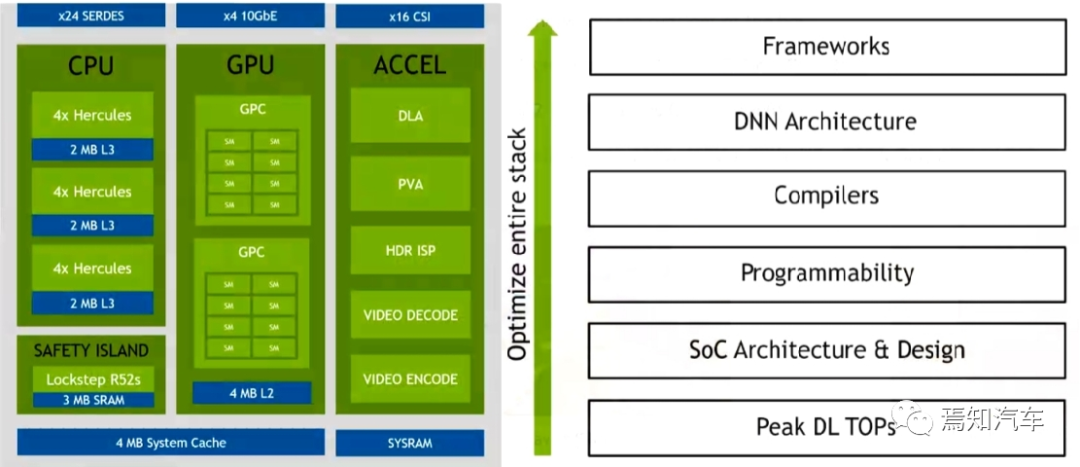
1、CPU:
Orin-x中CPU包括 12 个 Cortex-A78,可以提供通用的目标高速计算兼容性。同时,Arm Cortex R52 基于功能安全设计(FSI),可以提供独立的片上计算资源,这样就可以不用增加额外的 CPU(ASIL D)芯片用来提供功能安全等级。
CPU 族群所支持的特性包括 Debug 调试,电源管理,Arm CoreLink 中断控制器,错误检测与报告。
CPU 需要对芯片进行整体性能监控,每个核中的性能监控单元提供了六个计算单元,每 个单元可以计算处理器中的任何事件。基于 PMUv3 架构上,在每个 Runtime 期间这些计算 单元会收集不同的统计值并运行在处理器和存储系统上。
2、GPU:
NVIDIA Ampere GPU 可以提供先进的并行处理计算架构。开发者可以使用 CUDA 语言进行开发(后续将对CUDA架构进行详细说明),并支持 NVIDIA 中各种不同的工具链(如开发 Tensor Core 和 RT Core 的应用程序接口)。一个深度学习接口优化器和实时运行系统可以传递低延迟和高效输出。Ampere GPU 同时可以提供如下一些的特性来实现对高分辨率、高复杂度的图像处理能力(如实时光流追踪)。
稀疏化:
细粒度结构化稀疏性使吞吐量翻倍,减少对内存消耗。浮点处理能力:每个时钟周期内可实现 2 倍 CUDA 浮点性能。
缓存:
流处理器架构可以增加 L1 高速缓存带宽和共享内存,减少缓存未命中延迟。提升异步计算能力,后 L2 缓存压缩。
3、Domain-Specific:
特定域硬件加速器(DSAs、DLA、PVA)是一组特殊目的硬件引擎,实现计算引擎多任务、高效、低功率等特性。计算机视觉和深度学习簇包括两个主要的引擎:可编程视觉加速器 PVA 和深度学习加速器 DLA(而在最新的中级算力 Orin n 芯片则取消了 DLA 处理器)。
PVA 是第二代 NVIDIA 视觉DSP架构,它是一种特殊应用指令矢量处理器,这种处理器是专门针对计算机视觉、ADAS、ADS、虚拟现实系统。PVA 有一些关键的要素可以很好的适配预测算法领域,且功耗和延迟性都很低。Orin-x需要通过内部的R核(Cortex-R5)子系统可以用于 PVA 控制和任务监控。一个 PVA 簇可以完成如下任务:双向量处理单元(VPU)带有向量核,指令缓存和 3 矢量数据存储单元。每个单元有 7 个可见的插槽,包含可标量和向量指令。此外,每个 VPU 还含有 384 KBytes的3端口存储容量。
DLA 是一个固定的函数引擎,可用于加速卷积神经网络中的推理操作。Orin-x 单独设置了 DLA 用于实现第二代 NVIDIA 的 DLA架构。DLA支持加速 CNN 层的卷积、去卷积、激活、池化、局部归一化、全连接层。最终支持优化结构化稀疏、深度卷积、一个专用的硬件调度器,以最大限度地提高效率。
那么,怎样利用英伟达自身的GPU和CPU上的算力进行有效的计算机视觉开发能力探测呢?
GPU的软件架构
自动驾驶领域使用的 AI 算法多为并行结构。AI 领域中用于图像识别的深度学习、用于决策和推理的机器学习以及超级计算都需要大规模的并行计算,更适合采用 GPU 架构。由于神经网络的分层级数(通常隐藏层的数量越多,神经网络模拟的结果越精确)会很大程度的影响其在预测结果。擅长并行处理的 GPU 可以很好的对神经网络算法进行处理和优化。因为,神经网络中的每个计算都是独立于其他计算的,这意味着任何计算都不依赖于任何其他计算的结果,所有这些独立的计算都可以在 GPU 上并行进行。通常 GPU 上进行的单个卷积计算要比 CPU 慢,但是对于整个任务来说,CPU 几乎是串行处理方式,需要要逐个依次完成,因此,其速度要大大慢于 GPU。因此,卷积运算可以通过使用并行编程方法和GPU来加速。
英伟达通过 CPU+GPU+DPU 形成产品矩阵,全面发力数据中心市场。利用 GPU 在AI 领域的先天优势,英伟达借此切入数据中心市场。针对芯片内部带宽以及系统级互联等 诸多问题,英伟达推出了 Bluefield DPU 和 Grace CPU,提升了整体硬件性能。
对于英伟达的GPU而言,一个 GPC 中有一个光栅引擎(ROP)和 4 个纹理处理集群(TPC),每个引擎可以访问所有的存储。
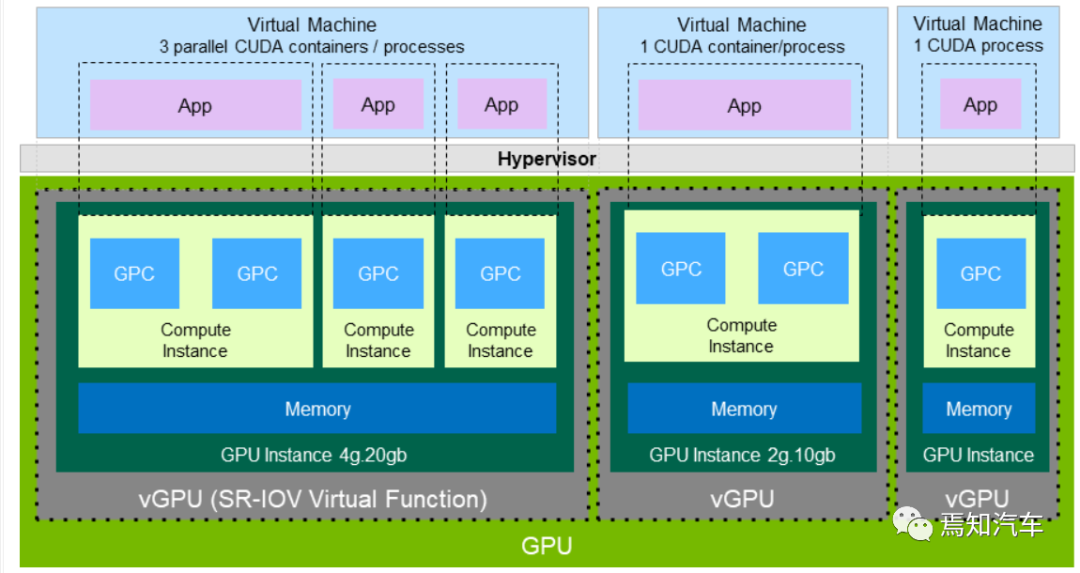
每个 TPC 包含两路流式多媒体处理器(SM),每个 SM 有 128 个 CUDA cores,被分为 4 个单独的处理模块,每个模块都有自己的指令缓冲区、调度程序和张量核心。每个TPC 也包含一个变形引擎、两个纹理单元和两个光线追踪核心(RT Core)。
GPC是一种专门针对硬件模块开发的光栅、阴影、纹理结构和计算的单元。GPU的核心图像处理函数就是在 GPC 中实现的。在 GPC 中,SM 的 CUDA 核可以执行像素级/矢量级/几何阴影的计算。纹理结构单元执行纹理滤波和加载/存储获取、数据保存到存储器。
特殊的函数单元(SFUs)可以处理先验的和图像的内插指令。
Tensor Cores 执行矩阵乘法来极大加速深度学习推理。RTcore 单元通过加速边界体积层次结构(BVH)的遍历和光流追踪过程中的场景几何交叉可以辅助光流追踪性能。
最后,多元引擎处理可以处理顶点提取、镶嵌、视角转换、属性建立和视频流输出。SM几何级、像素级处理执行性能可以确保其高适配性。这就可以很好地用于用户接口和复杂的应用开发,Ampere GPU 的功率也得到了优化,可以确保其在环境提供低功耗下还能保持较高性能。
核心通用编程架构CUDA
CUDA(Compute Unified Device Architecture,统一计算架构) 作为连接 AI 的中心节点,CUDA+GPU 系统极大推动了 AI 领域的发展。搭载英伟达 GPU 硬件的工作站(Workstation)、服务器(Server)和云(Cloud)通过 CUDA软件系统以及开发的 CUDA-XAI 库,为自动驾驶系统 AI 计算所需要的机器学习、深度学习的训练(Train)和推理(Inference)提供了对应的软件工具链,来服务众多的框架、云服务等等,是整个英伟达系列芯片软件开发中必不可少的一环。
CUDA 是一个基于英伟达 GPU 平台上面定制的特殊计算体系/算法,一般只能在英伟达的 GPU 系统上使用。这里从开发者角度我们讲讲在英伟达 Orin 系列芯片中如何在 CUDA架构上进行不同软件级别开发。
1、CUDA 架构及数据处理解析
如下图表示了 CUDA 架构示意图,表示了CPU,GPU,应用程序,CUDA 开发库,运行环境,驱动之间的关系如上图所示。
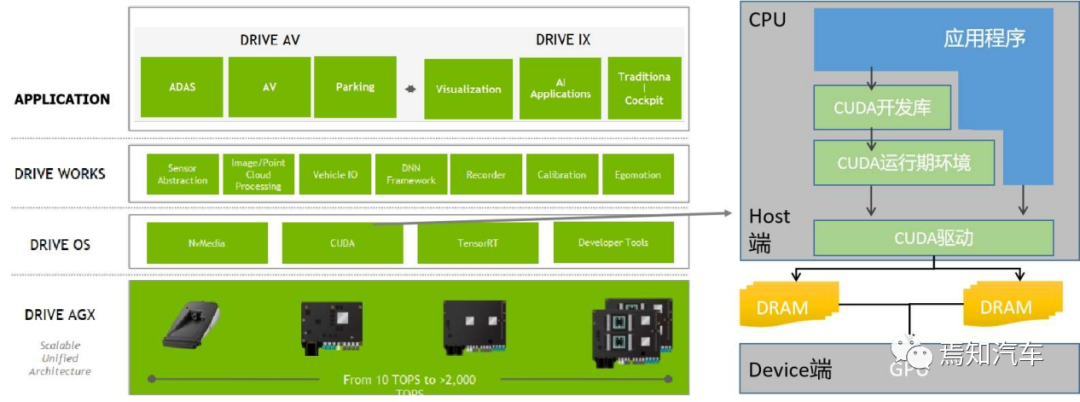
那么,如何在涵盖 CPU 和 GPU 模块中利用 CUDA 本身的编程语言进行开发调用呢?
从CUDA 体系结构的组成来说,它包含了三个部分:开发库、运行期环境和驱动。
“Developer Lib 开发库”是基于 CUDA 技术所提供的应用开发库。例如高度优化的通用数学库,即cuBLAS、cuSolver 和 cuFFT。核心库,例如 Thrust 和 libcu++;通信库, 例如 NCCL 和 NVSHMEM,以及其他可以在其上构建应用程序的包和框架。
“Runtime 运行期环境”提供了应用开发接口和运行期组件,包括基本数据类型的定义和各类计算、类型转换、内存管理、设备访问和执行调度等函数。
“Driver 驱动部分”是 CUDA 使能 GPU 的设备抽象层,提供硬件设备的抽象访问接口。CUDA 提供运行期环境也是通过这一层来实现各种功能的。
目前于 CUDA 开发的应用必须有 NVIDIA CUDA-enable 的硬件支持。对于 CUDA 执行过程而言,CPU 担任的工作是为控制 GPU 执行,调度分配任务,并能做一些简单的计算,而大量需要并行计算的工作都交给 GPU 实现。
在 CUDA 架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片(GPU)上执行的部份。Device 端的程序又称为 "kernel"。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。这里需要注意的是,由于 CPU 存取显存时只能透过 PCI Express 接口,因此速度较慢 (PCI Express x16 的理论带宽是双向各 4GB/s),因此不能经常进行,以免降低效率。
基于以上分析可知,针对大量并行化问题,采用 CUDA 来进行问题处理,可以有效隐藏内存的延迟性 latency,且可以有效利用显示芯片上的大量执行单元,同时处理上千个线程 thread 。因此,如果不能处理大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
对于这一应用瓶颈来说,英伟达也在数据存取上做出了较大的努力提升。一方面,优化的CUDA 改进了 DRAM 的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少 DRAM 的数据传送,更少的依赖 DRAM 的内存带宽。
此外,CUDA 还可以在程序开始时将数据复制进 GPU 显存,然后在 GPU 内进行计算,直到获得需要的数据,再将其复制到系统内存中。为了让研发人员方便使用 GPU 的算力,英伟达不断优化 CUDA 的开发库及驱动系统。操作系统的多任务机制可以同时管理 CUDA 访问 GPU 和图形程序的运行库,其计算特性支持利用 CUDA 直观地编写 GPU 核心程序。
2、CUDA 编程开发
英伟达系列芯片的应用基础是提供一套丰富且成熟的 SDK 和库,可以基于它们构建应用程序。CUDA 这种计算架构通过优化的各类调度算法和软件框架,实际为开发者提供了快速可调用的底层编程代码,可以确保开发者在编程过程中能够最快速最有效的直接调用GPU 并行计算资源,从而最大化提升 GPU 的计算效率,助力英伟达 GPU 方便且高效地发挥其并行计算能力。
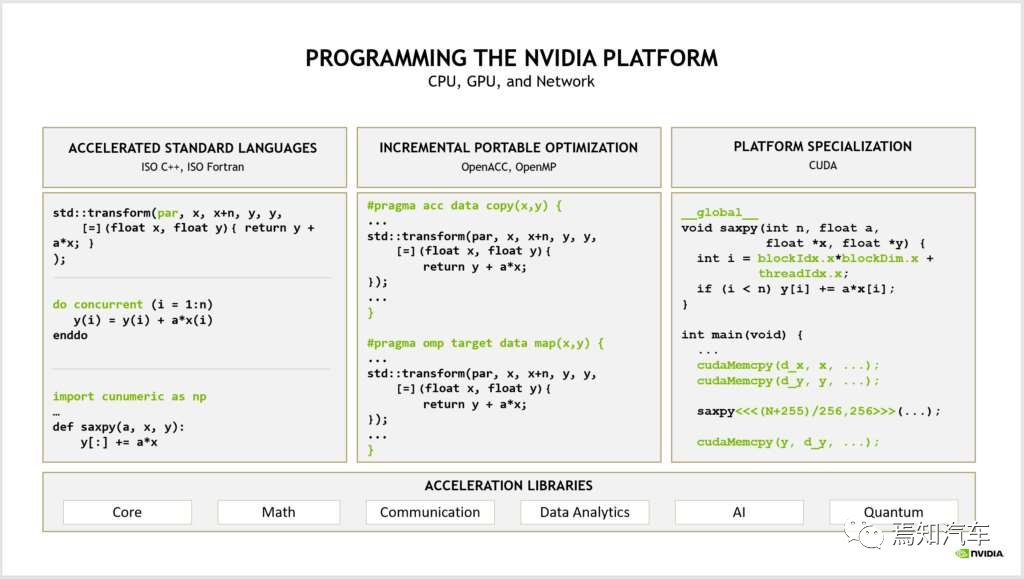
CUDA 是一种类 C 语言,本身也兼容 C 语言,所以适合普通开发者在其上编写和移植自己的代码和算法。总体来讲,英伟达在编程方式上分成了如下三种不同的模式。如下图表示了各种编程语言之间的关系:
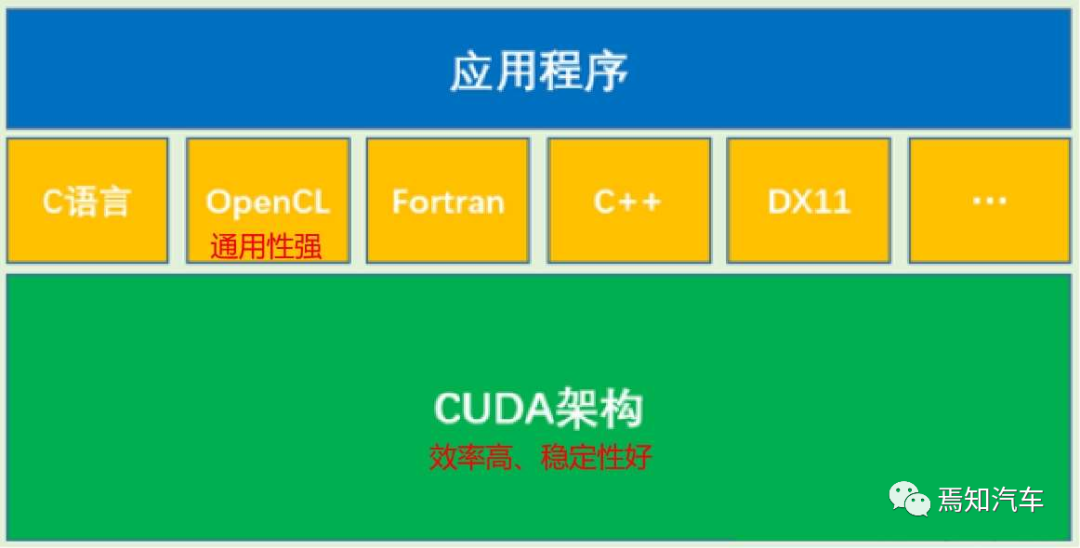
针对文本主题通常采用标准语言并行开发;针对性能优化的平台专用语言,如 C++、Fortran、OpenCL 等;其中,OpenCL 也可以实现对 GPU 计算能力的调用,但由于其通用性较强,整体优化效果不如 CUDA, 在大规模计算中劣势很大。CUDA 架构是 OpenCL 的运行平台之一,OpenCL仅仅是为 CUDA 架构提供了一个可编程的 API 而已。也就是相当于 API 与执行架构之间的关系。
针对如上标准语言和专用语言所定制的编译器指令,可以通过启用增量性能优化来弥合这两种方式之间的差距。从而在性能、生产率和代码可移植性方面进行权衡。
如下图表示了一种典型的 CUDA 架构优化后相对于 CPU、GPU 在软件编程上的性能提升。
为什么CUDA能够起到比CPU和GPU更好的运算效果呢?
实际上是对于同一个计算输入采用的不同计算方法。举个例子,考虑1至100的累加,如果是CPU,最终运算量计算结果则是需要调用执行同一个累加函数100次;而GPU如果并行计算如果有4核,则是4个主线同时运算这个算式,则计算量则是前者的1/4;而CUDA计算模式则可以看成优化的GPU,即在这种常规的累加计算上,也会采用一些“讨巧”的方式进行。比如考虑累加的首尾两侧加起来都是100(比如1+99,2+98,3+97...),因此,只需要考虑这种计算的累加次数就可以直接很快计算出结果了。从这个例子上看,CUDA的计算方式至少可以比单纯地GPU减少一半的计算量。
3、CUDA的典型数学库
类似于CPU编程库,CUDA库作为一系列接口的集合,只需要编写host代码,调用相应API即可实现各种函数功能,这样可以节约很多开发时间。并且CUDA的库都是经过大量的编程能力强的大拿经过不断优化形成的,因此我们完全可以信任这些库能够达到很好的性能。当然,完全依赖于这些库而对CUDA性能优化一无所知也是不行的,我们依然需要手动做一些改进来挖掘出更好的性能。
CUDA上常用的库包括如下几种:
cuSPARSE线性代数库,主要针对稀疏矩阵之类的
cuBLAS是CUDA标准的线性代数库,该库没有专门针对稀疏矩阵的操作
cuFFT傅里叶变换,用于内核加载时机和方式
cuRAND随机数,用于随机数的计算。
cuBLASLt
cuBLASLt 使用新的 FP8 数据类型公开混合精度乘法运算。这些操作还支持 BF16 和 FP16 偏差融合,以及 FP16 偏差与 GELU 激活融合,用于具有 FP8 输入和输出数据类型的 GEMM。
在性能方面,与 A100 上的 BF16 相比,FP8 GEMM 在 H100 PCIe 和 SXM 上的速度分别提高了 3 倍和 4.5 倍。CUDA Math API 提供 FP8 转换以方便使用新的 FP8 矩阵乘法运算。
cuBLAS 12.0 扩展了 API 以支持 64 位整数问题大小、前导维度和向量增量。这些新函数与其对应的 32 位整数函数具有相同的 API,只是它们在名称中具有 _64 后缀并将相应的参数声明为 int64_t。
cublasStatus_t cublasIsamax(cublasHandle_t handle, int n, const float *x, int incx, int *result);
对应的 64 位整数如下:
cublasStatus_t cublasIsamax_64(cublasHandle_t handle, int64_t n, const float *x, int64_t incx, int64_t *result);
cuFFT
在计划初始化期间,cuFFT 执行一系列步骤(包括试探法)是用来确定使用了哪些内核以及内核模块如何加载。从 CUDA 12.0 开始,cuFFT 使用 CUDA 并行线程执行 (PTX) 汇编形式而不是二进制形式交付了大部分内核。
当cuFFT 计划初始化时,cuFFT 内核的 PTX 代码在运行时由 CUDA 设备驱动程序加载并进一步编译为二进制代码。由于新的实施,第一个可用的改进将为 NVIDIA Maxwell、NVIDIA Pascal、NVIDIA Volta 和 NVIDIA Turing 架构启用许多新的加速内核。
cuSPARSE
为了减少稀疏矩阵乘法 (SpGEMM) 所需的工作空间,NVIDIA 发布了两种内存使用率较低的新算法。第一种算法计算中间产物数量的严格界限,而第二种算法允许将计算分成块。这些新算法有利于使用较小内存存储设备的客户。
最新INT8 已支持添加到 cusparseGather、cusparseScatter 和 cusparseCsr2cscEx2几种不同的函数模块中。
最后需要说明的是,最新版本中的CUDA也加入了延迟加载作为其中一部分。随后的 CUDA 版本继续增强和扩展它。从应用程序开发的角度来看,选择延迟加载不需要任何特定的东西。现有的应用程序可以按原样使用延迟加载。延迟加载是一种延迟加载内核和 CPU 端模块直到应用程序需要加载的技术。默认是在第一次初始化库时抢先加载所有模块。这不仅可以显着节省设备和主机内存,还可以缩短算法的端到端执行时间。
总结
本文从英伟达中的几个核心软件模块GPU和CUDA开发角度分析了其在整个软件框架构建,软件算法调度及软件函数构建和应用上进行了详细的分析。重点是可以很好的掌握整个Orin系列的软件架构,与前序文章的硬件架构相呼应。当然,从整个软件开发的完整流程上,本文还只是入门级的说明,对于精细化的开发还是远远不够的。后续文章我们将从操作系统Drive OS/驱动模块Drive Work等角度进行更为详细的分析。
-
高通自动驾驶靠软件开发革新力压英伟达自动驾驶芯片2024-02-20 3712
-
扩充自动驾驶中国团队,英伟达开放上百个职位2023-11-30 1444
-
自动驾驶芯片现状盘点 国产自动驾驶芯片发展面临的机遇和挑战2023-02-21 2345
-
英伟达何以成为车厂自动驾驶开发的首选2022-09-26 4067
-
自动驾驶备受关注 小马智行完成D轮融资 英伟达将量产自动驾驶芯片DRIVE Orin2022-03-30 4076
-
英伟达最新推出的自动驾驶芯片Atlan详解2021-04-19 13250
-
Einride将使用英伟达自动驾驶计算平台2020-12-10 2698
-
安培GPU发布 英伟达自动驾驶芯片算力升级2020-06-05 3806
-
英伟达发布新一代的自动驾驶芯片Orin2019-12-18 7203
-
英伟达DRIVE AGX Xavier开发套件就是一个用于构建自动驾驶系统的平台2019-01-13 7873
-
不惧特斯拉威胁,英伟达研发自动驾驶汽车芯片2018-08-20 3697
-
英伟达CEO称若特斯拉自动驾驶芯片项目失败,愿提供帮助2018-08-17 4229
-
英伟达播种自动驾驶业务 瞄准未来市场2018-05-17 1290
-
AI/自动驾驶领域的巅峰会议—国际AI自动驾驶高峰论坛2017-09-13 7639
全部0条评论

快来发表一下你的评论吧 !
