

基于几何变换器的2D-to-BEV视图转换学习
汽车电子
描述
BEV感知是自动驾驶的重要趋势。常规的自动驾驶算法方法基于在前视图或透视图中执行检测、分割、跟踪,而在BEV中可表示周围场景,相对而言更加直观,并且在BEV中表示目标对于后续模块最为理想。此项研究提出了一种新的BEV学习机制:几何导向核变换器(Geometry-guided Kernel Transformer )。GKT利用几何先验来引导变换器聚焦于区分区域,并展开内核特征以生成BEV表示。
研究背景
对于多视图相机系统,难点在于,如何将2D图像表示转换为BEV表示。根据几何信息是否明确用于特征变换,现有的方法可分基于几何的逐点变换和无几何的全局变换两大类。
基于几何体的逐点变换下图所示,利用可用的对应关系,2D特征被投影到3D空间并形成BEV表示。
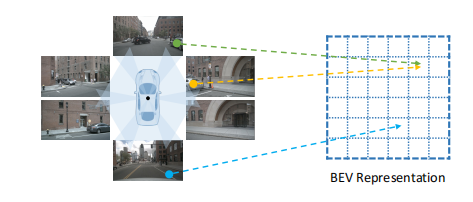
然而,此方法过于依赖于校准参数。正在行驶中的汽车外部环境复杂,摄像机可能在运行时偏离校准位置,这将使系统出现误差。此外,逐点复杂且耗时高,难以再实际环境中应用。
全局变换方法考虑了2D图像和BEV视图之间的完全相关性。这种方法受相机偏差影响较小。但这也带来了问题:全局变换所需的算力与图像的像素的数量成比例。并且,该模型必须从所有视图中全局地挖掘出判别信息,这导致图像的收敛过程变的更难。

在本研究中,研究人员提出了一种新的2D到BEV变换机制,以达到更高的效率和鲁棒性,该算法称为Geometry-guided Kernel Transformer(GKT)。该方法利用粗略的相机参数,投影BEV位置,以获得多视图和多尺度特征地图中的2D位置。然后,模型在先前位置周围展开Kh×Kw内核特征,并使BEV算法与相应的展开特征交互以生成BEV视图。
实施途径
GKT利用几何深度学习来引导转换器聚焦于重点区域,展开核心特征用于生成BEV视图。拟建GKT的框架如下图所示。该图上半部分表示了几何信息用于引导变换器聚焦在多视图图像中的先前区域。下部分为展开先前区域的核心特征,它们与BEV查询交互以生成BEV表示。在此方法中,共享的卷积神经网络从环绕视图中提取视图特征,BEV空间被均匀的划分为网格,每个网格对应一个3D坐标。

为了快速进行判断,研究引入了不同的索引方法,以摆脱相机在运行时对校准参数的依赖。通过对比Im2col,网格采样,LUT索引三种方法,确定了LUT索引可使GKT实现更高的FPS。在此方法中,每个BEV网格的核心区域都是固定的,可以在脱机时进行预先计算。在运行时,系统可从LUT中获得每个BEV查询的对应像素索引,并通过索引更快速的获得特征。

测试
该算法再nuScenes数据集上进行训练,并在val数据集上进行评估。在下图中,比较了在两种设置下GKT和其他基于BEV的方法下的车辆地图视图分割效率。测试采用了1×7卷积来捕获水平图像信息,然后在GKT中应用有效的7×1内核来进行2D到BEV视图转换。

在测试中,GKT展示出了很高的鲁棒性。与逐点变换相比,GKT只将相机参数作为指导,而非完全依赖。当相机偏离时,相应的,内核区域会移动,但仍然可以覆盖目标。由于变换器的排列位置不变的,而是根据偏移量动态的生成核心区域的关注权重,所以GKT可以始终聚焦于目标,从而减少相机偏差的影响。
同时,GKT具有很高的效率。利用所提出的LUT索引,可以在运行时消除了逐点变换所需的2D-3D映射操作,使正向过程紧凑而快速。与全局变换相比,GKT只关注几何引导的核区域,避免了全局交互。相较而言,GKT所需的假设过程更少,收敛过程更快。
因此,GKT综合了逐点变换和全局变换的优势,从而实现了高效和高鲁棒性的2D到BEV视图学习。在nuScenes数据集上的测试也表明GKT非常高效,使用3090 GPU运行可达到72.3 FPS,使用2080ti GPU运行可达到45.6 FPS,其FPS低于目前所有方法。
-
无桥PFC变换器综述2025-03-13 703
-
阻抗变换器的参数K1和K2是什么2024-08-28 2783
-
DCDC变换器的原理2021-12-28 2287
-
.基本DC-DC变换器开关电源学习笔记2021-10-29 3438
-
负阻抗变换器实验教程2021-06-08 1050
-
Buck变换器的工作原理与设计的学习课件免费下载2020-12-07 1652
-
谐振变换器到底是什么及理想和非理想buck变换器的模型介绍2020-11-07 12076
-
直流变换器的学习教程免费下载2020-07-14 1253
-
电阻电路的等效变换学习课件免费下载2020-03-11 1218
-
LLC变换器设计要素(资料下载)2016-01-19 4101
-
Gabor变换学习笔记2015-02-12 10848
-
U/F变换器和F/U变换器2011-11-10 3925
-
阻抗变换器电路2010-01-11 6384
-
负阻抗变换器2008-12-11 1677
全部0条评论

快来发表一下你的评论吧 !
