

从大模型中蒸馏脚本知识用于约束语言规划
描述
为了实现日常目标,人们通常会根据逐步指令来计划自己的行动。这些指令被发现是目标导向的脚本,包括一组达成目标的原型事件序列。为了实现目标(例如制作蛋糕),通常需要按照某些指令步骤进行,例如收集材料,预热烤箱等。这种逐步脚本的规划会朝着复杂目标的推理链条进行。因此,规划自动化意味着在各个领域中实现更智能和合理的人工智能系统,例如可执行的机器人系统和用于问题解决的推理系统。
最近的研究表明,语言模型(LMs)可以用于计划脚本。先前的工作已经表明,大型语言模型(LLMs),例如GPT-3、InstructGPT和PaLM,可以以零/少量示例的方式有效地将目标分解为过程步骤。为了训练专业模型,研究人员提出了自动理解和生成脚本知识的数据集。但是,先前的工作主要关注于针对典型活动的抽象目标进行规划。针对具有特定约束条件(例如糖尿病患者)目标的规划仍然未得到充分研究。
本文介绍了复旦大学知识工场实验室的最新研究论文《Distilling Script Knowledge from Large Language Models for Constrained Language Planning》,该文已经被自然语言处理顶会ACL 2023作为主会长文录用。本文工作关注约束语言规划的问题,将语言规划推向了更具体的目标。论文作者评估了LLMs的少量示例约束语言规划能力,并为LLMs开发了一种超生成然后过滤的方法,使准确性提高了26%。基于本文的方法,作者还使用LLMs生成了一个约束语言规划的高质量脚本数据集(CoScript)。利用CoScript,可为专业化和小型模型提供具有约束语言规划能力的能力,其性能可媲美LLMs。

一、研究背景
为了实现日常目标,人们通常会根据逐步指令来计划自己的行动。这些指令被发现是目标导向的脚本,包括一组达成目标的原型事件序列。为了实现目标(例如制作蛋糕),通常需要按照某些指令步骤进行,例如收集材料,预热烤箱等。这种逐步脚本的规划会朝着复杂目标的推理链条进行。因此,规划自动化意味着在各个领域中实现更智能和合理的人工智能系统,例如可执行的机器人系统和用于问题解决的推理系统。

图1:InstructGPT生成了一系列“为糖尿病患者做蛋糕”的目标规划步骤
最近的研究表明,语言模型(LMs)可以用于计划脚本。先前的工作已经表明,大型语言模型(LLMs),例如GPT-3、InstructGPT和PaLM,可以以零/少量示例的方式有效地将目标分解为过程步骤。为了训练专业模型,研究人员提出了自动理解和生成脚本知识的数据集。但是,先前的工作主要关注于针对典型活动的抽象目标进行规划。针对具有特定约束条件(例如糖尿病患者)的目标的规划仍然未得到充分研究。
二、基于大规模语言模型的限制约束语言规划
在本文中,作者定义了约束语言规划问题,该问题对规划目标施加不同的约束。例如,抽象目标(制作蛋糕)可以由具有多方面约束的不同现实特定目标所继承。蛋糕可以用1)不同的配料(例如巧克力或香草);2)各种工具(例如使用微波炉或烤箱);或3)不同的用途(例如用于婚礼或生日派对)来制作。
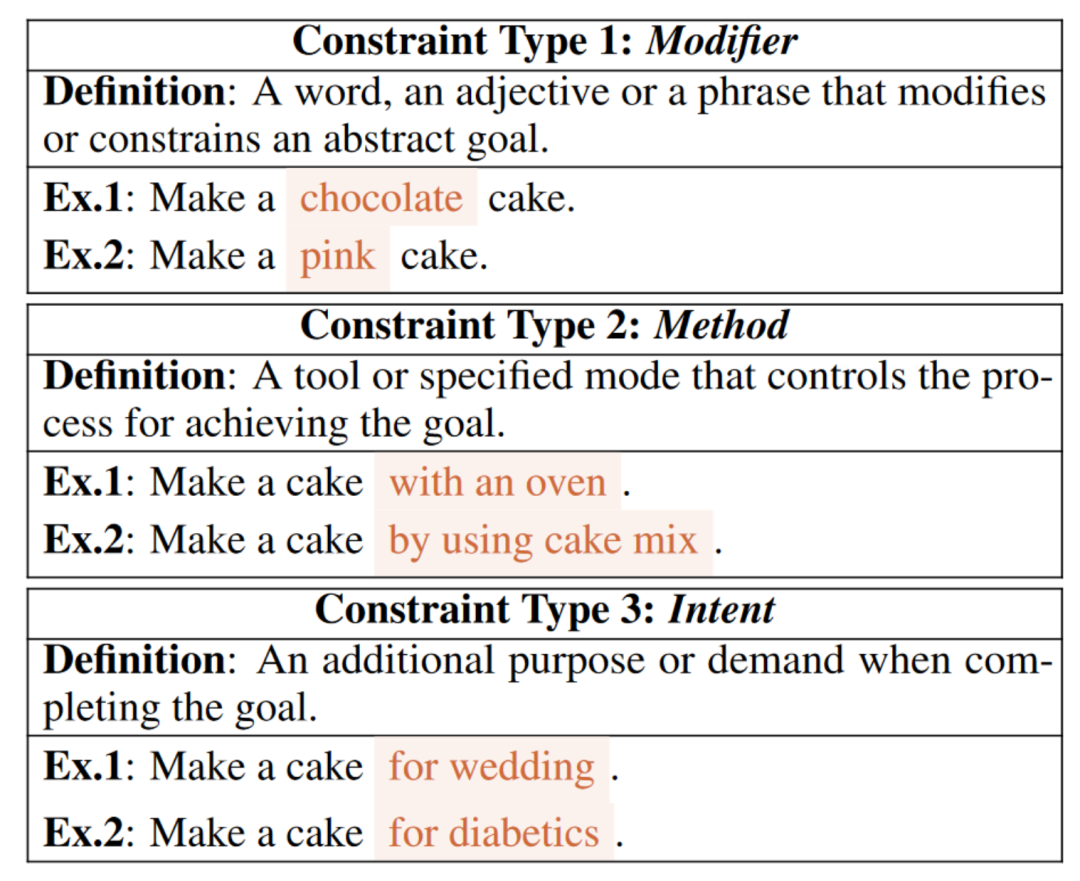
表1:促进特定目标新实例生成的三种约束类型及其定义
一个好的规划者应编写合理并忠实于约束的脚本。为此,作者探究了LLMs是否会忠实于约束地进行规划。由于没有特定目标的数据集支持本文的研究,必须首先获取这些目标。如表1所述,作者使用InstructGPT对抽象目标进行了多方面约束的人在环数据采集进行扩展。首先,作者手动准备了一个示例池,从中使用约束从抽象目标中推导出具体目标。每个示例都附带有一个约束类型(即修饰符、方法或意图),并包含多个约束和特定目标,以便InstructGPT为一个抽象目标生成多个具体目标。
接下来,作者枚举wikiHow的每个抽象目标,以确保数据多样性。然后,从池中随机抽取约束类型的多个示例。最后,将任务提示、示例和抽象目标输入InstructGPT中,以完成具体目标。表2(I)中的一个示例显示了InstructGPT针对抽象目标(“制作蛋糕”)和约束类型修饰符以及一些示例生成了约束“巧克力”和“香草”,并完成了特定目标(“制作巧克力蛋糕”和“制作香草蛋糕”)。获取带有约束的具体目标后,可以测试LLM实现这些目标的能力。

表2: InstructGPT的提示示例,用于通过上下文学习生成特定目标和脚本。生成的文本已经被突出显示
表3报告了结果的整体准确度,从中可以发现:1)总体而言,所有基准模型在特定目标的规划上都取得了不令人满意的结果,其中InstructGPT表现最佳。“让我们一步一步思考”并不能帮助太多;2)从wikiHow检索不会导致所需的脚本。
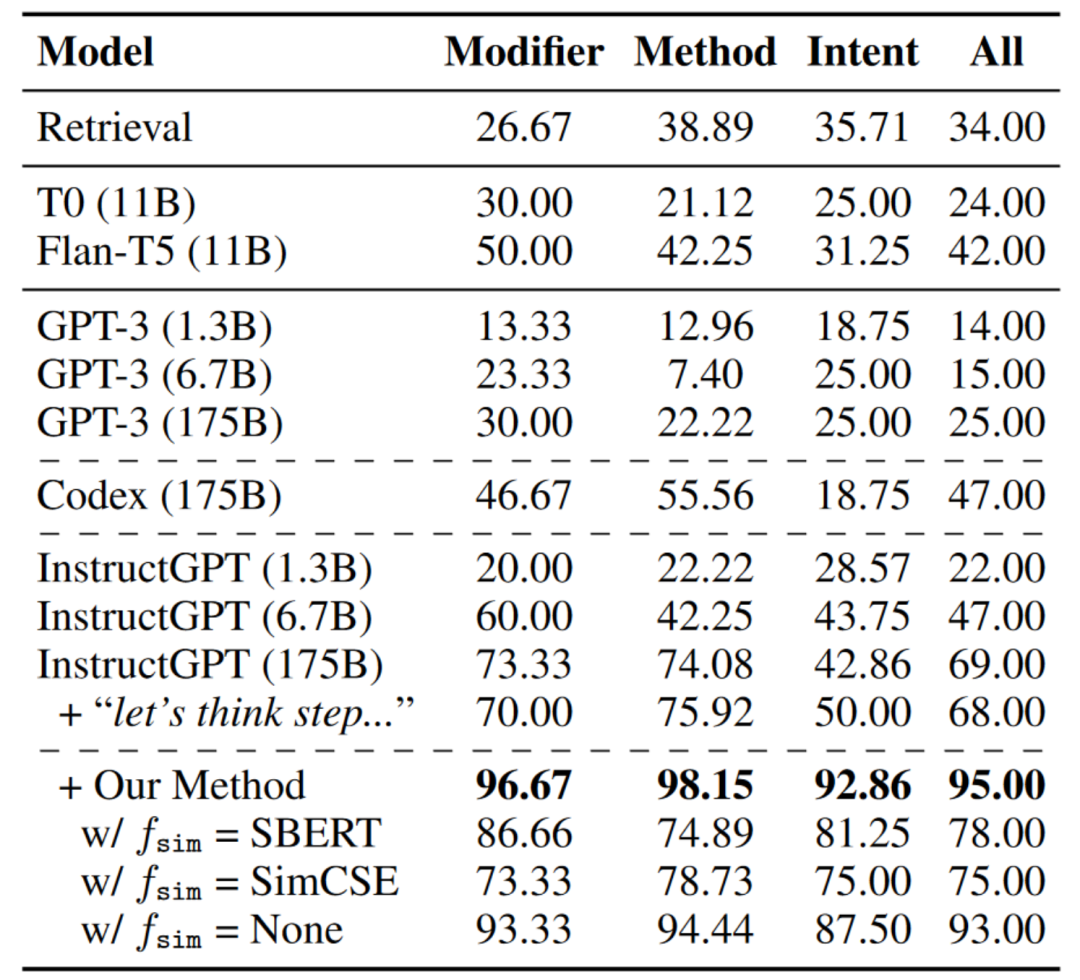
表3:不同约束类型的生成脚本准确率(%),通过人工评估得出。
为了回应本文方法的动机,作者进行了详细的分析,以研究为何LLM会失败。图3的结果表明:1)生成的脚本的语义完整性是可以接受的,但约束的忠实度无法保证;2)本文的方法在语义完整性和约束忠实度方面都极大地提高了规划质量。
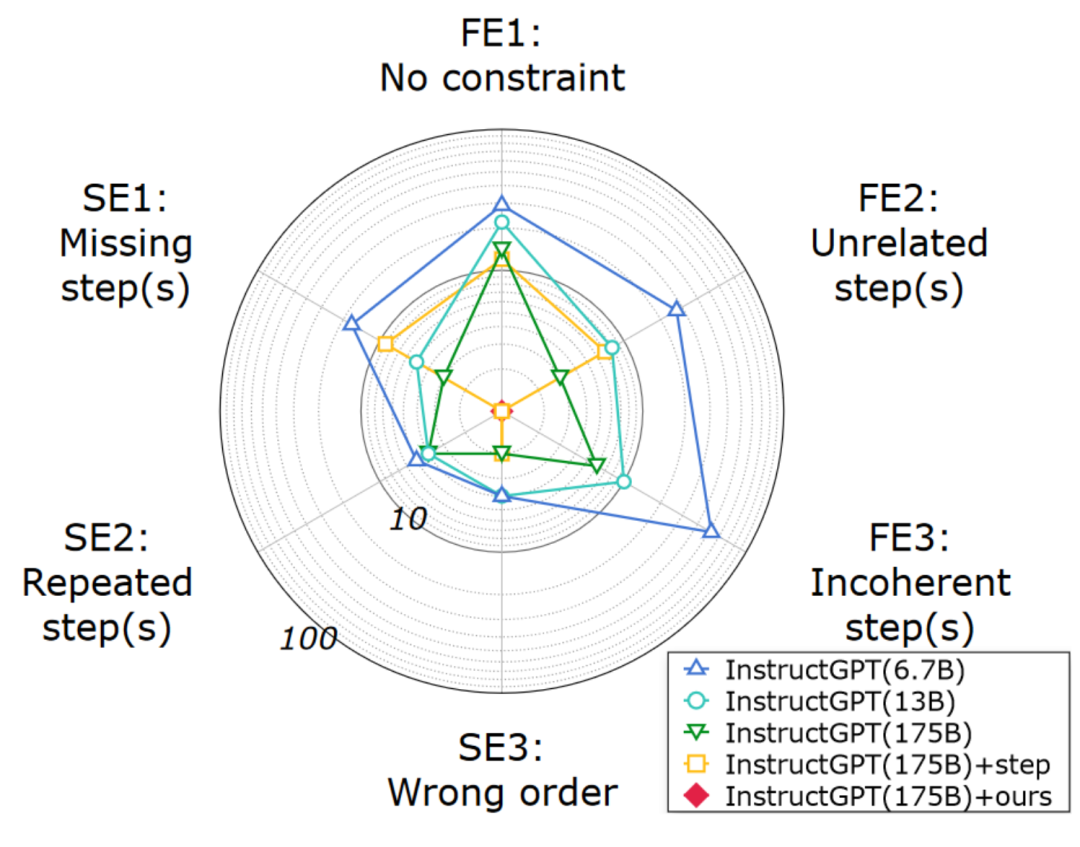
图2:通过人工评估生成的脚本的错误
因此,作者采用了过度生成然后过滤的思路来提高生成质量。正如图3所示,作者从InstructGPT中过度生成K个样本,然后开发一个过滤模型来选择忠实的脚本。由于语言表达方式多样,作者依赖于目标和脚本之间的语义相似性进行过滤,而不是规则和模式(即,必须在脚本中出现约束词)。
作者首先收集了一组目标,包括所求目标作为正样本以及从相同的抽象目标生成的其他目标作为负样本。然后,将脚本和目标转换为InstructGPT嵌入,并计算余弦相似性作为相似性分数来衡量语义相似性。此外,作者奖励明确包含目标约束关键字的脚本,只有所求目标在目标集合得分最高时才会保留该脚本。
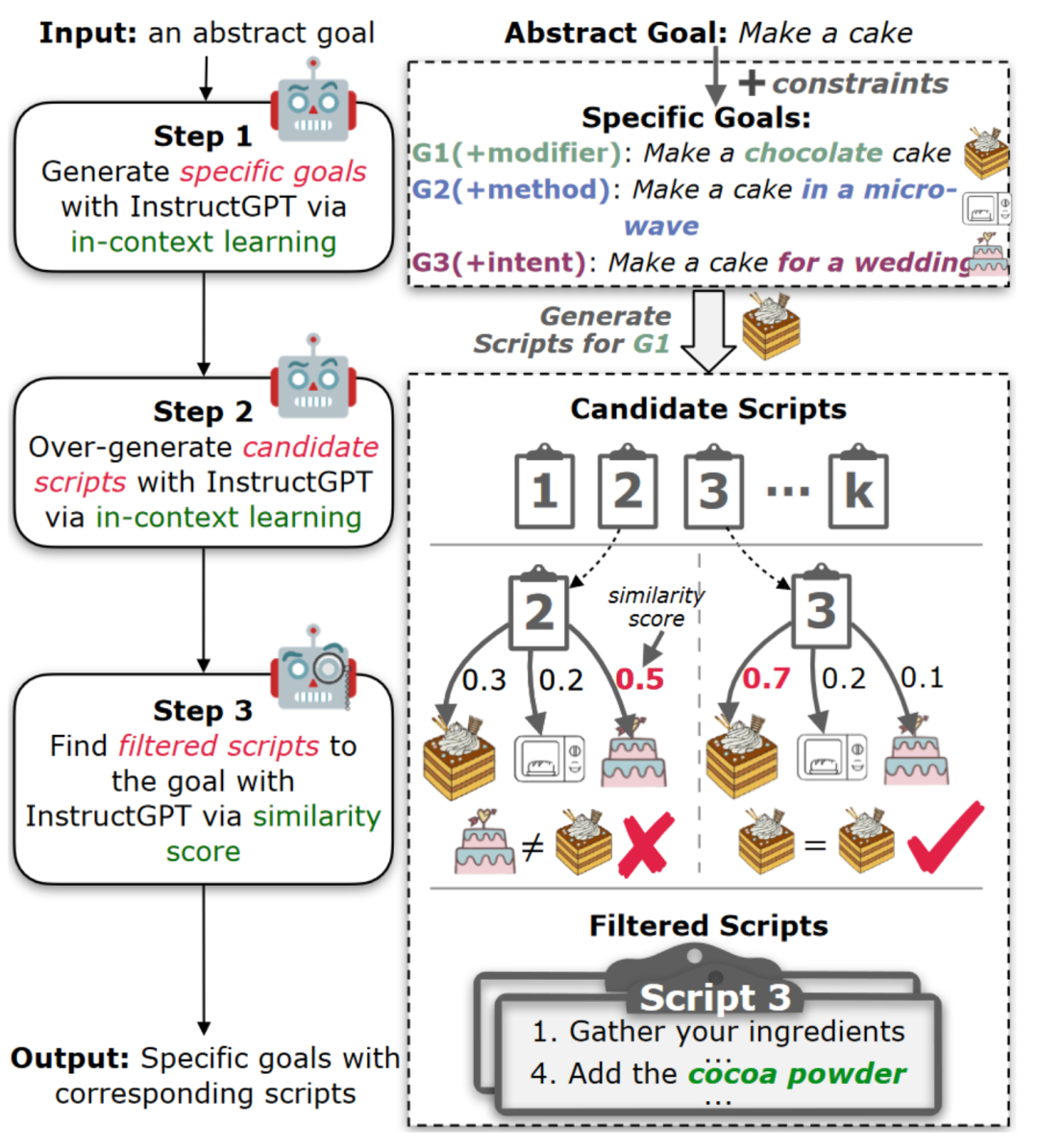
图3:使用InstructGPT生成具体目标并使用超生成-过滤框架进行目标规划的工作流程。
结果如表3所示。使用本文的方法,InstructGPT可以大幅提高脚本的质量。将相似度函数替换为来自其他预训练模型的嵌入会导致性能下降。
三、从大模型中获取脚本知识
LLMs成本高,需为更小、专业化模型添加语言规划能力。为实现此目标,创建数据集是必要步骤,但以前的数据集不支持特定目标的规划,手动注释成本高。为此,作者使用符号知识蒸馏从LLMs中提取受限制的语言规划数据集。作者使用超生成-过滤框架为受限制的语言规划脚本数据集CoScript构建了高质量的具体目标和脚本,总共生成了55,000个具体目标和相应的脚本。
作者还随机选择2,000个数据作为验证集,3,000个数据作为测试集。为确保验证集和测试集的质量,作者要求众包工作者查找和修正不正确的样本。通过收集这5,000个样本的注释数据进行错误识别,估计出具体目标的准确率为97.80%,受限脚本生成的准确率为94.98%,与表3中的结果一致。
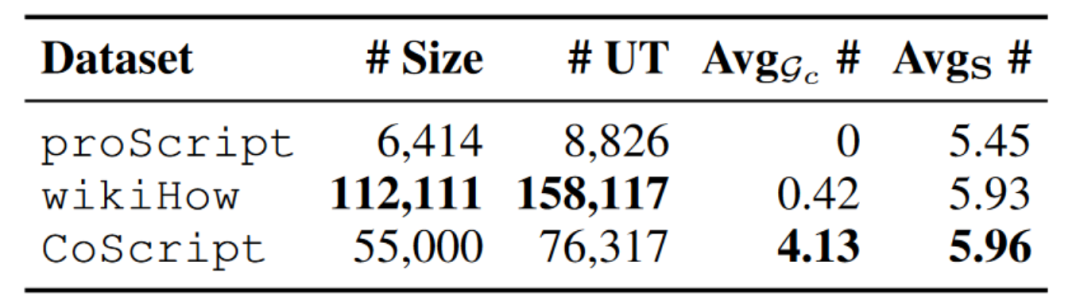
表4:Coscript和之前数据集的对比
并与其他数据集进行了比较,如表4所示,发现CoScript比proScript规模更大,具有更多的脚本和更高的每个脚本步骤数,并且CoScript具有高度的词汇多样性。
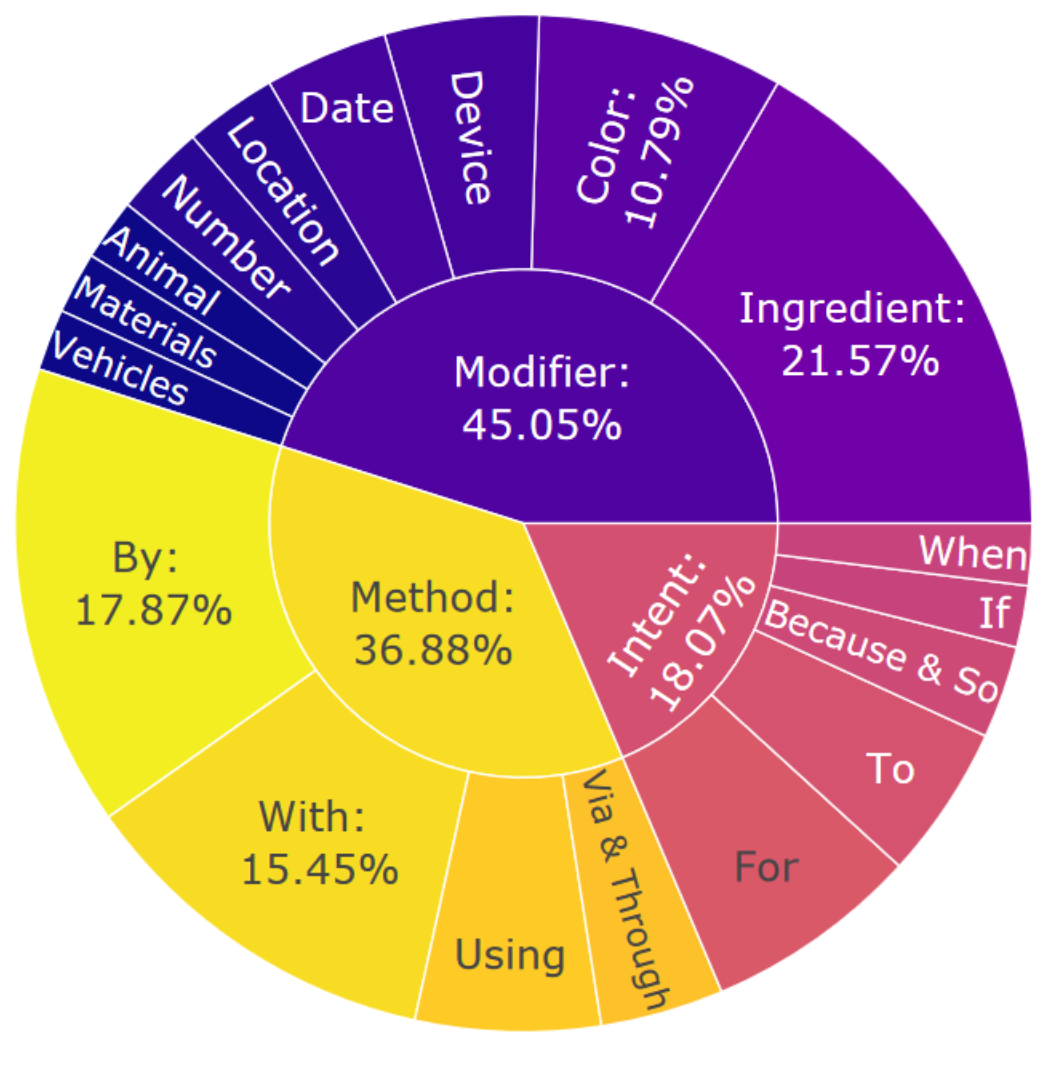
图4:CoScript的约束分布
图4显示了CoScript的约束分布,发现CoScript在生成的具体目标中显示出高度的异质性和多元化。有趣的是,InstructGPT倾向于以“if”或“when”这样的词语开始假设性约束(例如,“如果有人对乳糖不耐受,则制作蛋糕”),这表明未来在语言规划中进行反事实推理的研究潜力。
四、小模型的约束规划能力
有了CoScript,可以为受限制的语言规划训练更小但更专业化的模型。表5显示了在wikiHow和CoScript上训练的模型的比较。一般而言,CoScript训练的LMs表现优于wikiHow。T5在忠实度上优于GPT-2,可能是由于其编码器-解码器框架更擅长处理输入信息。然而,在其他文本生成指标上,GPT-2优于T5。这可能是因为CoScript是从InstructGPT蒸馏而来,导致数据分布存在偏差,偏向于仅解码的因果语言模型,例如GPT系列。而且我们发现使用检索示例来增强模型可以提高语义完整性。
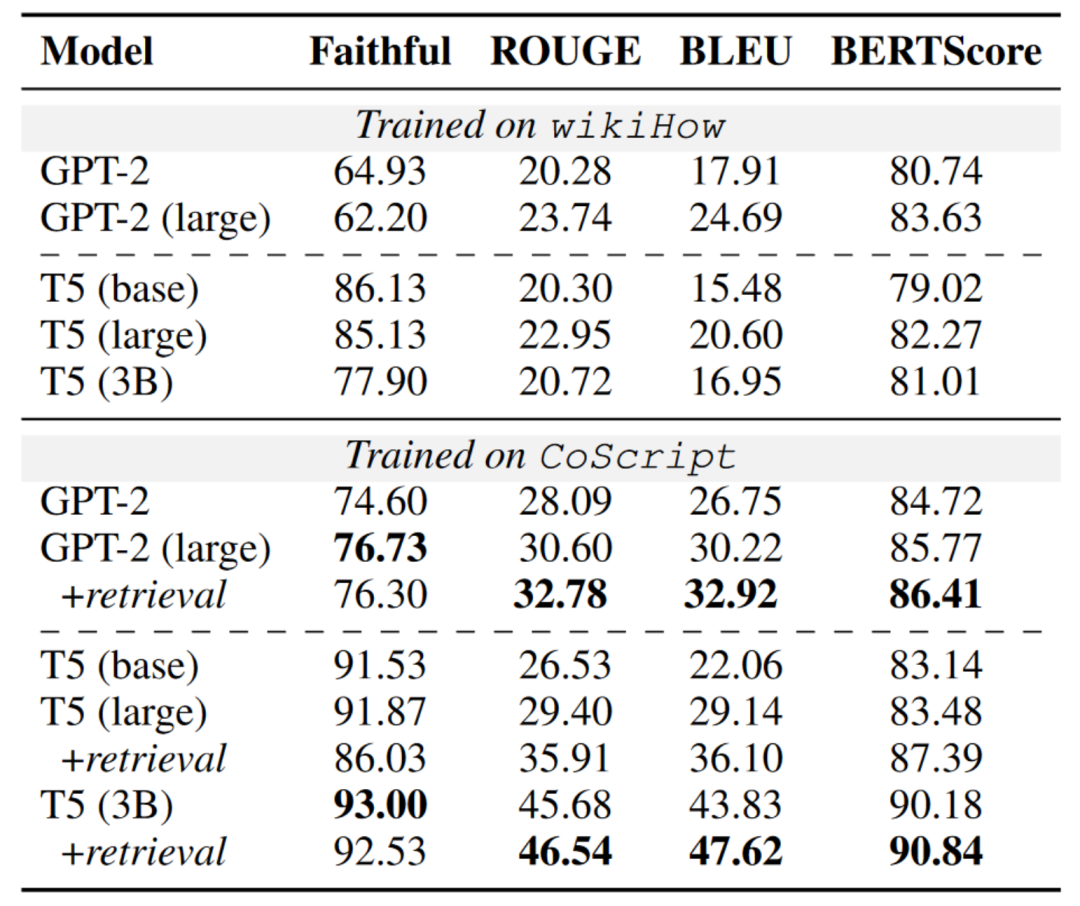
表5:不同训练集上模型的总体脚本生成性能。请注意,所有模型的测试集相同。
作者进一步在CoScript和wikiHow上微调T5(3B),以生成§4.4中保留在训练集之外的具体目标的脚本。表7显示,使用检索增强微调的T5可以生成比表3中大多数LLMs质量更高的脚本,这表明当适当地在适当的数据集上进行训练时,较小的模型也可以超越较大的模型。
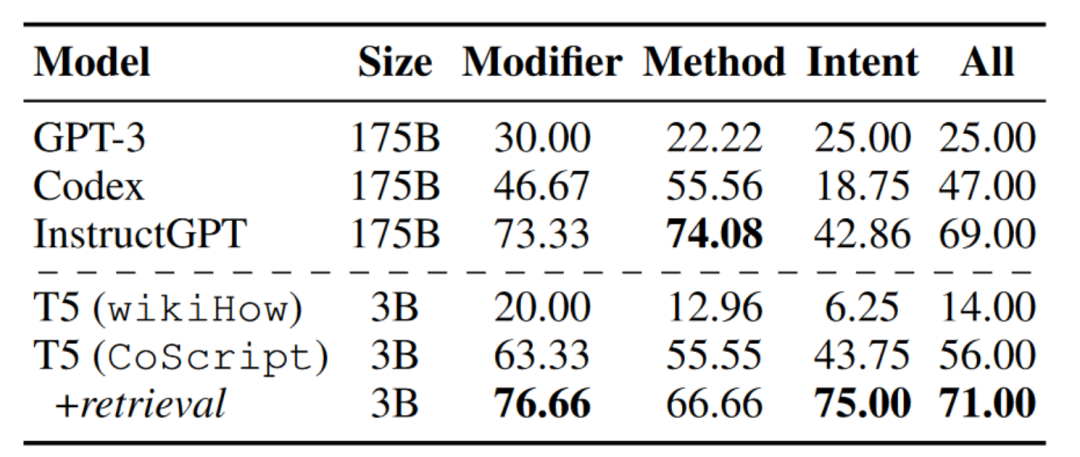
表6:不同模型生成的脚本准确率(%)。我们在wikiHow和CoScript上微调了T5(3B),同时通过少样本上下文学习来部署LLMs。
五、总 结
本文旨在定义在特定约束条件下朝着特定目标进行规划。本文作者提出了一种更好的提示方法,用以改进LLMs的受约束语言规划能力,并从LLMs中提炼出了一个新的数据集(CoScript)。实验表明,本文的方法提高了LLMs针对特定目标的规划质量,而在CoScript上训练的较小模型甚至优于LLMs。希望CoScript数据集能成为推进更加复杂和多样化目标和约束条件下的语言规划研究的宝贵资源。
审核编辑:刘清
-
一文详解知识增强的语言预训练模型2022-04-02 11093
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1387
-
【大语言模型:原理与工程实践】大语言模型的应用2024-05-07 1313
-
有用于调试的MCU Xpresso IDE调试脚本语言吗?2023-04-20 627
-
深度学习:知识蒸馏的全过程2021-01-07 7101
-
如何向大规模预训练语言模型中融入知识?2021-06-23 6326
-
若干蒸馏方法之间的细节以及差异2022-05-12 2529
-
关于快速知识蒸馏的视觉框架2022-08-31 1787
-
用于NAT的选择性知识蒸馏框架2022-12-06 1572
-
如何度量知识蒸馏中不同数据增强方法的好坏?2023-02-25 1915
-
如何将ChatGPT的能力蒸馏到另一个大模型2023-06-12 3291
-
TPAMI 2023 | 用于视觉识别的相互对比学习在线知识蒸馏2023-09-19 2827
-
任意模型都能蒸馏!华为诺亚提出异构模型的知识蒸馏方法2023-11-01 2536
-
脚本语言和编程语言的区别2023-11-22 4578
-
摩尔线程宣布成功部署DeepSeek蒸馏模型推理服务2025-02-06 1554
全部0条评论

快来发表一下你的评论吧 !
