

Linux内核模块编程基础知识
嵌入式技术
描述
一、内核简介
内核(Kernel)在计算机科学中是操作系统最基本的部分,主要负责管理系统资源。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并由内核决定一个程序在什么时候对某部分硬件操作多长时间。直接对硬件操作是非常复杂的。所以内核通常提供一种硬件抽象的方法,来完成这些操作。通过进程间通信机制及系统调用,应用进程可间接控制所需的硬件资源(特别是处理器及IO设备)。
二、内核分类
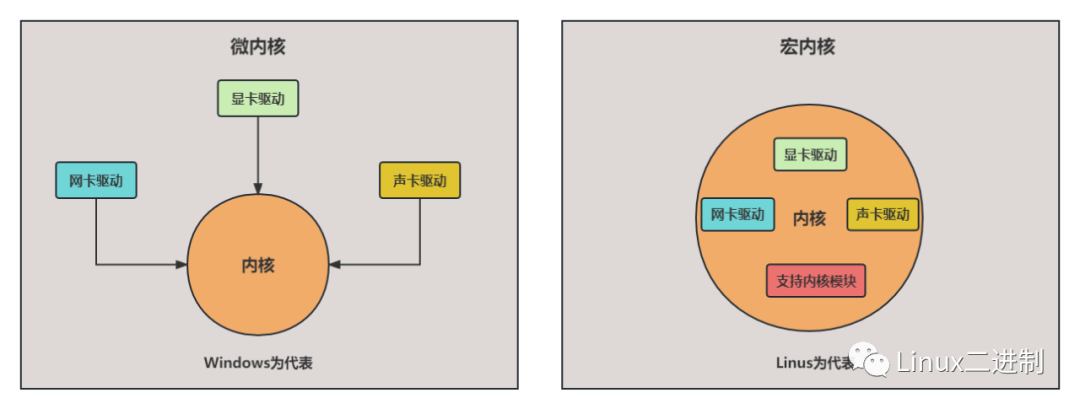
内核在设计上分为宏内核与微内核两大架构。
宏内核:简单来说,就是把很多东西都集成进内核,例如Linux内核,除了最基本的进程、线程管理、内存管理外,文件系统,驱动,网络协议栈等都在内核里面。优点是效率高。缺点是稳定性差,开发过程中的bug经常会导致整个系统挂掉。做驱动开发的应该经常有按电源键强行关机的经历。
微内核:内核中只有最基本的调度、内存管理。驱动、文件系统等都是用户态的守护进程去实现的。优点是超级稳定,驱动等的错误只会导致相应进程死掉,不会导致整个系统都崩溃,做驱动开发时,发现错误,只需要kill掉进程,修正后重启进程就行了,比较方便。缺点是效率低。
三、内核模块及其好处
Linux是一个宏内核,运行在单独的内核地址空间。不过,Linux汲取了微内核的精华:其引以为豪的是模块化设计、抢占式内核、支持内核线程以及动态装载内核模块的能力。不仅如此,Linux还避免其微内核设计上性能损失的缺陷,让所有事情都运行在内核态,直接调用函数,无需消息传递。至今,Linux是模块化的、多线程的以及内核本身可调度的操作系统,实用主义再次占了上风。
模块是具有独立功能的程序,它可以被 单独编译 ,但 不能独立运行 。它在运行时被链接到内核作为内核的一部分在内核空间运行。模块通常由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序或其他内核上层的功能。
内核模块是Linux内核向外部提供的一个插口,其全称为动态可加载内核模块(Loadable Kernel Module,LKM),简称为模块。
同时内核模块的这一特点也有助于减小内核镜像文件的体积,自然也就减少了内核所占的内存空间(因为整个内核镜像将会被加载到内存中运行)。不必把所有的驱动都编译内核,而是以模块的形式单独编译驱动程序,这是基于不是所有的驱动都会同时工作原理。因为不是所有的硬件都要同时接入系统,比如一个无线网卡讨论完内核模块的这些特性后,我们正式开始编写模块程序。
四、内核模块编程基础
众所周知,内核模式下的编程和用户模式下有所不同,会有如下限制条件:
- 不能使用用户模式下的C标准库。
- 不能使用浮点运算,因为linux内核切换模式时不保存处理器的浮点状态。
- 尽可能保持代码的清洁易懂,因为内核调试不方便。
- 模块编程和内核版本密切相连,不同的内核版本,某些函数的函数名会有变化。因此模块编程也可以说是内核编程。
- 只有超级用户才可以运行模块 。
应用程序编程和内核模块编程的对比:
| 应用程序 | 内核模块程序 | |
|---|---|---|
| 使用函数 | libc库 | 内核函数 |
| 运行空间 | 用户空间 | 内核空间 |
| 运行权限 | 普通用户 | 超级用户 |
| 入口函数 | main() | module_init() |
| 出口函数 | exit() | module_exit() |
| 编译工具 | gcc | make |
| 链接工具 | gcc | insmod |
| 运行方式 | 直接运行 | insmod |
| 调试方法 | gdb | kdbug、kdb、kgdb |
五、内核模块代码结构
1、头文件引用
#include < linux/module.h >
#include < linux/kernel.h >
#include < linux/init.h >
编写任何内核模块程序所必须引用的 3 个头文件 :
- module.h包含了对模块结构的定义及模块版本的控制
- kernel.h包含了常用的内核函数
- init.h包含了宏__init和__exit,以及一些其他初始化函数的调用宏。如宏module_init等。宏__init告诉编译程序相关的函数仅用于初始化模块的初始化的宏定义,宏__exit用于可加载模块的卸载清理操作。
2、编写内核模块时必备的两个函数
1)xxx_init():注册函数(名字xxx可任起) 或模块的初始化函数。如:
/* 不加void在调试时会出现报警 */
static int __init myfunc_init( void )
{
printk("Hello, This is my own module…
");
return 0;
}
2)xxx_exit( ):卸载函数(名字xxx可任起) 或模块的退出和清理函数。如:
/* 不加void会出现报警,若改为static int也会报错 , 因为出口函数是不能返回值的 */
static void __exit myfunc_exit( void )
{
printk("Goodbye, uninstall my own module…
");
}
3、加载模块和卸载模块
1) module_init() :向内核注册模块,提供新功能;告诉内核你编写的模块程序从哪里开始执行。
2) module_exit() :注销由模块提供的功能;告诉内核你编写的模块程序从哪里离开。
4、模块许可权限声明
MODULE_LICENSE(“GPL”);
从内核2.4.10开始,动态加载的模块必须通过MODULE_LICENSE宏声明此模块的许可证。否则在动态加载此模块时,会收到内核被污染"module license’unspecified’ taints kernel."的警告。
从Linux内核2.6开始,内核模块的编译采用Kbuild(kernel build)系统。Kbuild系统会两次扫描Linux的Makefile:首先编译系统会读取Linux内核顶层的Makefile,然后根据读到的内容第二次读取Kbuild的Makefile来编译Linux内核或者模块。
Kernel Makefile:Kernel Makefile位于Linux内核源代码的顶层录/usr/src/kernels/xxx/,也叫Top Makefile。这个文件会被首先读取,并根据读到的内容配置编译环境变量。对于内核或驱动开发人员来说,这个文件几乎不用任何修改。
Kbuild Makefile:当Kernel Makefile被解析完成后,Kbuild会读取相关的Kbuild Makefile进行内核或模块的编译。内核及驱动开发人员需要编写这个Kbuild Makefile文件。
六、自定义内核模块
1、选择一个目录,创建Makefile和myownfunc.c文件;
myownfunc.c代码:
/* 源文件myownfunc.c */
#include < linux/module.h >
#include < linux/kernel.h >
#include < linux/init.h >
static int __init myfunc_init(void)
{
printk("Hello,this is my own module!
");
return 0;
}
static void __exit myfunc_exit(void)
{
printk("Goodbye,this is my own clean module!
");
}
module_init(myfunc_init);
module_exit(myfunc_exit);
MODULE_DESCRIPTION("First Personel Module");
MODULE_AUTHOR("Lebron James");
MODULE_LICENSE("GPL");
Makefile代码:
ifneq ($(KERNELRELEASE),)
$(info "2nd")
obj-m:=myownfunc.o
else
KDIR :=/lib/modules/$(shell uname -r)/build
PWD :=$(shell pwd)
all:
$(info "1st")
make -C $(KDIR) M=$(PWD) modules
clean:
rm -f *.ko *.o *.mod.o *.symvers *.cmd *.mod.c *.order *.mod
endif
Makefile解析:
#KERNELRELEASE :在内核源码树的Makefile中定义,在当前的Makefile中,
# 它的值为空。
#$(shell uname-r) :获得当系统的Linux内核版本
#KDIR :指定当前Linux操作系统源代码路径,即编译生成的模块是在当前系统中使用
# 如果想将你写的模块,用在你的开发板上运行的Linux系统中,只需在KDIR变量中指定
# 你开发板Linux系统源码树的路径
#PWD:=$(shell pwd)获得当前待编译模块的源文件路径
2、make编译执行过程分析
1)在模块的源代码目录下执行make,此时,宏“KERNELRELEASE”没有定义,因此进入else分支;
2)记录内核路径KDIR和当前工作目录PWD;
3)因为make后面没有目标,所以make会在Makefile中的第一个不是以.开头的目标作为默认的目标执行,于是all成为make的目标;all:之后的第一个命令$(info “1st”) 类似于printf函数,编译经过此处会打印提示信息。
4)make的第二条命令会执行make -C $(KDIR) M=$(PWD) modules,翻译过来就是
make -C /lib/modules/6.1.0-rc4+/build M=/tmp/29 modules
-C 表示到存放内核源码的目录执行其Makefile
M=$(PWD) 表示返回到当前待编译模块目录
modules 表示编译成模块的意思
之所以这么写是由内核源码树的顶层Makefile告诉我们的,当我们调用Linux内核源码树顶层的Makefile时,找到的是顶层Makefile的“modules”目标。
5)找到modules目标后,接下来Linux源码树的顶层Makeflle就需要知道是将哪些".c"文件编译成模块。谁告诉它呢?是的,待编译模块的Makefile文件。所以接下来就会回调模块的Makefile。需要注意的是,此时KERNELRELEASE已经在Linux内核源码树的顶层Makefile中定义过了,所以此时它获得信息是:
obj-m:=myownfunc.o
obj-m表示会将myownfunc.o目标编译成.ko模块;它告诉Linux源码树顶层Makefile是动态编译(编译成模块)而不是编译进内核(obj-y),Linux源码树顶层Makefile会根据myownfunc.o找到myownfunc.c文件。
6)将模块文件myownfunc.c编译为myownfunc.o,然后再将多个目标链接为.ko
最终编译结果如下:
[root@localhost 29]# make
"1st"
make -C /lib/modules/6.1.0-rc4+/build M=/tmp/29 modules
make[1]: Entering directory `/usr/src/kernels/6.1.0-rc4+'
"2nd"
CC [M] /tmp/29/myownfunc.o
"2nd"
MODPOST /tmp/29/Module.symvers
CC [M] /tmp/29/myownfunc.mod.o
LD [M] /tmp/29/myownfunc.ko
make[1]: Leaving directory `/usr/src/kernels/6.1.0-rc4+'
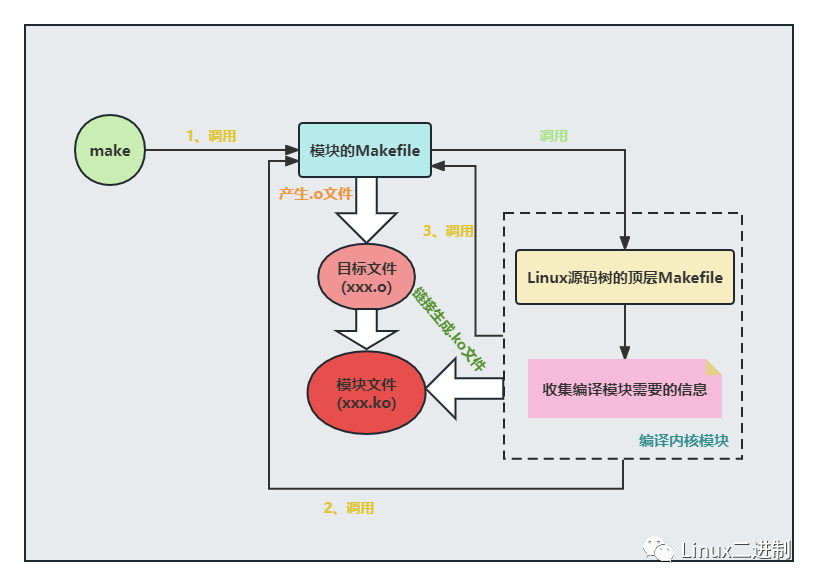
由执行结果可知,待编译模块的Makefile最终被调用了三次
1) 执行命令make调用
2) 被Linux内核源码树的顶层Makefile调用,产生.o文件
3) 被Linux内核源码树顶层Makefile调用,将.o文件链接生成.ko文件
综上,可将Linux模块编译的流程总结如下图:
七、模块加载与卸载
编译好了xxx.ko文件以后,接下来就要考虑如何将ko模块加载到Linux内核以及如何卸载ko模块,让我们学习Linux内核模块加载与卸载。
1、模块加载
insmod /absolute-path/模块名.ko
例如添加上文编译的内核模块:
insmod ./myownfunc.ko
注意:Linux系统中只有超级用户权限才可以添加模块到内核。
modprobe命令也可以实现模块加载到内核,具体差异本文不做详细概述,后续会出专门的推文讲解insmod和modprobe的区别。
2、查看系统中的模块
lsmod 模块名
例如在系统中搜索自己添加的myownfunc模块:
[root@nj-rack01-06 29]# lsmod | grep myownfunc
myownfunc 16384 0
3、卸载模块
rmmod 模块名
例如卸载系统中的myownfunc模块:
rmmod myownfunc
4、查看模块信息
1)查看模块注册的信息
modinfo 模块名.ko
例如查看自己添加的myownfunc模块的注册信息:
[root@nj-rack01-06 29]# modinfo myownfunc.ko
filename: /tmp/29/myownfunc.ko
license: GPL
author: Lebron James
description: First Personel Module
srcversion: 8748FD633F9276BD38A9934
depends:
retpoline: Y
name: myownfunc
vermagic: 6.1.0-rc4+ SMP preempt mod_unload modversions
如上结果所示,modinfo会显示模块的全路径文件名,license信息,作者信息,描述信息,模块名等。
2)查看模块打印的信息
dmesg | tail
例如查看自己添加的myownfunc模块打印信息:

dmesg主要是从Linux内核的ring buffer(环形缓冲区)中读取信息的。
在Linux系统中,所有通过printk打印出来的信息都会送到ring buffer中。我们知道,我们打印出来的信息是需要在控制台设备上显示的。因为此时printk只是把信息输送到ring buffer中,等控制台设备初始化好后,在根据ring buffer中消息的优先级决定是否需要输送到控制台设备上。
如何清空ring buffer呢?
dmesg -c
到此,本文即成功实现了自定义内核模块的加载、卸载以及打印信息的查看。
纸上得来终觉浅,绝知此事要躬行,想学习Linux驱动的朋友赶紧亲自动手试一试吧。
-
RZ/G2L Linux系统如何添加新的内核模块2024-01-04 3393
-
Linux内核模块间通讯方法2023-06-07 3944
-
高效学习Linux内核——内核模块编译2021-09-24 1564
-
嵌入式LINUX系统内核和内核模块调试2021-07-30 2109
-
Asterisk内核模块介绍2021-03-17 1006
-
如何在Petalinux创建Linux内核模块?2021-03-02 5737
-
嵌入式LINUX系统内核和内核模块调试教程2020-11-06 1151
-
Linux 内核模块工作原理及内核模块编译案例2020-09-23 3427
-
Linux驱动编程基础知识讲解2020-03-01 4754
-
什么是 Linux 内核模块?2019-08-09 4160
-
Linux设备驱动程序基础知识的了解2018-11-26 3779
-
Linux内核模块编程必须了解哪些知识?2018-08-24 1371
-
《Linux设备驱动开发详解》第4章、Linux内核模块2017-10-27 1321
-
Linux内核模块程序结构2017-05-27 2857
全部0条评论

快来发表一下你的评论吧 !
