

 Micrium全家桶之uC-FS: 0x02 NAND FTL算法原理详解
Micrium全家桶之uC-FS: 0x02 NAND FTL算法原理详解
描述
Micrium全家桶之uC-FS: 0x02 NAND FTL算法原理详解 (qq.com)
前言
uC-FS的NAND驱动实现基于一篇论文:《KAST: K-Associative Sector Translation for NAND Flash Memory in Real-Time Systems》所以有必要先介绍下该论文的内容,以便后面理解代码的实现。
物理地址和逻辑地址的映射
NAND的特点是写数据前必须擦除,即擦除后数据为1,写只能由1写为0.擦除单位为块,写数据单位为页,对于SLC块一般由64个PAGE组成,而PAGE一般大小是2KB。
FTL管理物理地址和逻辑地址的映射,根据管理的颗粒度,可以分为块(BLOCK)级别的映射,和页(PAGE)级别的映射。前者更新数据以块为单位,后者以页为单位。
对于块级别的管理,哪怕是只更新块的一个PAGE的数据,所有属于该块的不需要修改的PAGE数据和需要修改的PAGE的数据都需要重新写入一个新开辟出来的物理块中。使得管理成本变高。
为了获得更高的性能,一般页级别的管理用的更多。
假设一个块由64个页组成。开始时逻辑页地址为0的PAGE,映射到第二个物理块的第一个PAGE,其页物理地址为64.那么当需要更新逻辑地址为0的PAGE时,只需要将更新的内容写入第65个物理PAGE,将映射表的对应关系,由逻辑PAGE地址为0映射原来的物理PAGE地址64,改为映射物理PAGE地址65。因为NAND是块擦除,PAGE编程,所以块擦除后后面的PAGE写不再需要擦除。后续再继续更新逻辑PAGE地址0的时候,再往后映射到66等等,直到最后映射到第127个物理页。此时再更新逻辑PAGE0时则需要将第二个物理块的内容复制到新开辟的块中了,然后将该物理块擦除又可以作为新的更新块使用。注:上述的物理块2即为更新块或者LOG块, 可以看出基于页的管理擦除次数远低于基于块的管理,后者每更新一个PAGE都需要擦除一个块然后写一个块,而前者擦除次数大大减少。
基于PAGE管理的缺点是需要更大的映射表缓存,因为颗粒度变小了,一个PAGE就需要一个映射项,这对于嵌入式领域尤其是资源受限的场景是一个限制。
块回收
以上举例的是基于更新块,LOG的方式,即更新一个逻辑PAGE的内容不是直接修改其对应的物理PAGE的内容,而是将其内容写入一个更新块的某个PAGE,然后修改其映射关系,直到更新块写完或者更新块不够用了,然后将更新块的内容写入一个新开辟的块,修改映射关系,此时原来的块就是无效的了。随着修改的增多无效块越来越多,无法开辟新的块了此时就需要回收无效块。
需要注意的是上述无效块中可能有一部分PAGE是包含有效数据一部分是无效数据的,所以如果需要回收,需要将其有效数据复制到新开辟的块中,然后擦除该无效块,此时该块就可以作为后续开辟块使用了。上述回收工作需要遍历所有块的所有PAGE是一个非常耗时的过程,并且时间是波动的,且波动很大,这种波动是不适合嵌入式场景的,尤其是实时系统的。
混合管理
综合块管理的性能低,管理消耗大,需要缓存低;页管理的需要缓存大,性能高,管理消耗低的优缺点,混合管理方式是一个妥协或者综合的方式。
很多领域在面对矛盾的时候解决办法就是综合,妥协取中间,这也契合中庸的哲学思想。
这种综合的方式
将物理块分为数据块DATA BLOCK和日志块LOG BLOCK,日志块称为LOG BUFFER,基于该方式的FTL即称为log buffer-based FTL。所谓的综合或者混合即LOG BLOCK采用PAGE级别的管理,而DATA BLOCK采用块级别的管理。LOG BLOCK的最大数量决定了PAGE级别映射表的大小。当有写更新请求时,先将更新数据写入LOG BLOCK原来旧的DATA BLOCK的数据设置为无效,如果LOG块写满且没有空闲的LOG块时则需要将LOG块的有效内容(注意LOG块中不一定全部是有效数据)移动到空闲的DATA块中,然后擦除LOG块以便后面继续作为LOG BUFFER使用。上述过程即称为块合并block merge。
block merge是基于LOG块的,只有LOG块写满且无LOG块可用时才会执行merge,所以其比基于PAGE的管理的垃圾回收消耗低很多,而又不需要太大的映射表缓存(因为基于PAGE管理的LOG块数量不多),所以更适合于嵌入式系统。
块关联映射block associative mapping (BAST Block Associative Sector Translation )
一个LOG块只关联一个DATA块,即只有同一个DATA块的PAGE数据可以写入同一个LOG块。
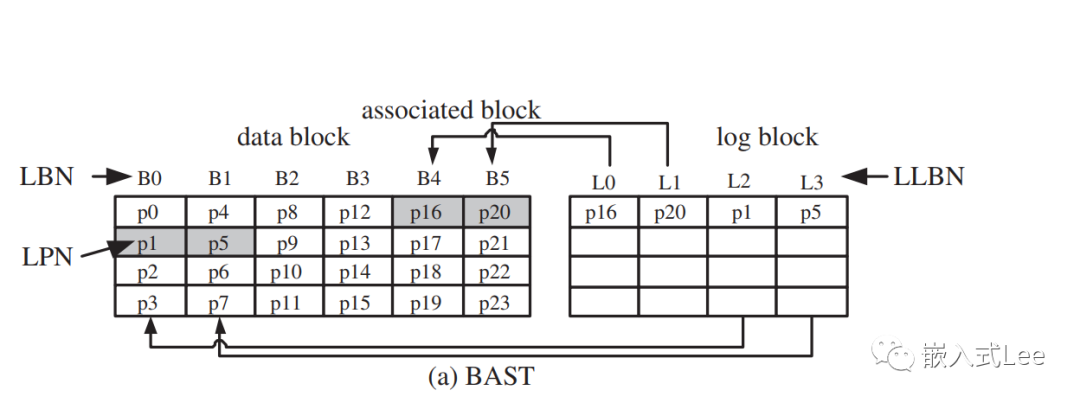
如上图LLBN表示LOG块逻辑地址,这里有4个LOG块分别是L0~L3
LBN表示DATA块逻辑地址,这里有6个DATA块,分别是B0~B5
LPN表示PAGE逻辑地址
每个块有4个PAGE。
当PAGE有更新时,将PAGE数据写入LOG块,同时将DATA块中的PAGE置为无效(灰色部分)
假设按照p16 p20 p1 p5的次序更新,最开始更新p16时将p16写入L0,设置B4中的p16无效,然后更新p20,此时L0中已经有关联的B4的数据了,由于一个LOG块只能关联一个DATA块,所以p20不能写入L0,只能找后续的写入L1,后面的p1写入L2,p5写入L3也是同样的道理。此时如果继续有B2和B3的PAGE需要更新,而此时4个LOG块都关联了非B2和B3的块,此时就需要merge LOG块,释放LOG块来关联新的B2和B3的修改。
如果数据更新是随机的,那么BAST性能会比较差,因为这会导致频繁的MERGE操作,因为一个LOG块只能映射一个DATA块,随机的多个DATA块更新很快就使得LOG块不够用需要MERGE。这即所谓的LOG块抖动问题log block thrashing problem。
同时上述过程可以看到每次LOG块MERGE时只有一个PAGE有效,剩余的3个PAGE是空的,所以空间利用率很低。
全关联映射fully associative mapping (FAST Fully Associative SectorTranslation )
一个LOG块可关联任意的DATA块,一个LOG块可以写入任意DATA块的数据。
该方式可以解决BAST的LOG块抖动问题。

如上图所示一个LOG块可以关联任意的DATA块,所以只有一个LOG块的所有PAGE写满才会执行MERGE,所以大大减少了MERGE操作。
PAGE按更新次序依次写入LOG块,而不管它来自于哪个DATA块,这可以解决LOG块抖动问题。
上述示例的是按照p0, p4, p8, p12, p16, p20,p1, p5 的更新次序,先写满L0,然后写满L1,此时都还不需要进行MERGE,而如果是BAST从p16开始就需要merge了。
特别的FAST会使用一个sequential log block (SLB) 块。该块只关联一个DATA块,且该块内的PAGE按照in-place scheme 机制写(按照PAGE的逻辑地址顺序和偏移依次对应写),所以SLB可以采用switch merge 和 partial merge方式。
然而FAST也有缺点,即一个LOG块可以关联任意的DATA块,所以MERGE操作消耗非常大,比如上述的L0关联了4个DATA块,所以MERGE时需要更新4个BLOCK的数据,需要擦除4个块,每个块有4个PAGE所以需要拷贝4次PAGE,一共需要拷贝4x4=16个PAGE。而BAST只关联一个DATA BLOCK没有这个问题。
定义DATA块关联到LOG块L的集合A(L),A(L)中元素的个数表示L的关联性,表示为k(L)
所以LOG块的MERGE消耗是
N · k(L) · Ccopy + (k(L) + 1) · Cerase
擦除次数是k(L) + 1,所有关联的DATA块需要擦除,还有LOG块也需要擦除。
复制次数是N · k(L),N是每个块的PAGE数,k(L)个DATA块即k(L)*N
k(l)最大即为块中PAGE数N。所以最坏的merge时间是N^2Ccopy +(N +1)Cerase。
由于N的变化范围很大,比如SLC一般是一个块是64个PAGE,MLC是128个PAGE所以k(L)变化很大,所以上述公式计算出来的最好和最坏情况差别很大,也就是程序运行时间抖动很大,不适合嵌入式系统使用。
组关联映射set associative mapping (SAST Set Associative Sector
Translation )
一组LOG块可以关联一组DATA块的PAGE。
N个LOG块只能用于K个DATA块,即N:K log block mapping 。
所以LOG块最大的块关联度是k。

如上图所示是
2:3 mapping SAST 2个LOG块最多只能关联3个DATA块。
所以SAST是BAST和FAST的中间妥协版本,可以综合优化但是不能完全解决两者的问题。
MERGE
前面提到的LOG块的MERGE分为三种
full merge,
Partial **merge ** , switch merge
Partial merge即LOG块中只有部分PAGE,这些PAGE是按照逻辑PAGE的次序和偏移对应的,还有一些间隙此时需要从DATA块中复制这些间隙PAGE,然后和LOG块中的内容一起写入新的DATA块。
switch merge即LOG块中已经是和一个DATA块对应的序列PAGE,且写满,可以直接变为DATA块。
Partial merge 和switch merge 只有LOG块内的PAGE是按照逻辑PAGE地址对应的PAGE偏移顺序写入时才有可能,这种方式称为in-place机制。
KAST:K-associative mapping
BAST的MERGE太频繁性能差,而FAST则是MERGE不频繁但是每次MERGE的时间差异很大,都有缺点。所以都不适合嵌入式系统。
此时我们又要用到中庸思想了,本论文提出的K-associative mapping即类似于FAST,但是限制其关联度,以减少最坏情况的消耗。
KAST整体架构
有以下特征
l减少LOG的关联度,不同的LBNs 更新尽可能对应不同的LOG块,类似于BAST。
lLOG块最多只关联K个DATA块。保证 k(L) ≤ K,通过控制参数K控制最坏的MERGE时间
l包含多个SLBs ,不同于FAST只有一个SLB。SLBs的个数通过参数配置。
如果没有后续的顺序写入请求,则可以将SLB更改为随机日志块(RLB),这里是一个很重要的思想,即动态变化,不死板,既然后面没有连续的PAGE写入了,就认为是随机写,就把他作为RLB块来用,这种思想值得借鉴,即走一步看一步,结合实际情况进行决定。
SAST也是通过将K个数据块与日志块集相关联,使日志块的块关联性低于K,通过对数据块和日志块进行分组,SAST可以在无形中解决块抖动问题。
但KAST不将数据块和日志块分组,只是限制LOG块的最大关联度,这是不同点。
此外,KAST试图通过在不同的日志块之间分配不同LBN上的写请求来最小化每个日志块L的k(L)的值

如上是一个kAST的示例
写序列p0, p4, p8, p12, p16, p20,p1, p5 ,KAST为不同的数据块分配写请求。
首先,页面p0、p4、p8和p12被写入不同的日志块,这是尽可能减少LOG块关联的DATA块数的思想。
然后p16和p20没办法只能关联到L0和L1增加这两个LOG块的关联度,注意这里是分配到L0和L1而不是都分配到L0,同样是上述尽可能减少LOG块关联的DATA块数的思想。
最后,页p1和p5被写入日志块L0和L1,因为p1所在的DATA块已经有p0在L0中了,所以p1放在 L0中不增加日志块的关联性,同样是上述的思想。
总之一句话即尽可能减少LOG块的关联性,即减小 k ( L ) 。只有LOG快不够了再去考虑增加LOG块的关联度。作为一种特殊情况,SLB只与一个数据块相关联。当日志块被分配时,它被确定为SLB或RLB。
以下是LOG块的状态机
F , S Ri 状态分别表示空闲SLB,和i关联度的RLB。
初始化状态是F,即LOG块是空闲的没有关联数据。

F状态可变为S或者R1状态,
Ri状态写PAGE,如果该PAGE已经属于之前关联的块了则不增加关联度,状态不变,否则关联度增加,变为Ri+1状态。
如果SLB状态写PAGE,维持其次序,则SLB状态S也不改变。
Ri+1也可以变为Ri状态,如果对应的PAGE写到了其他的LOG块,本LOG块的PAGE设置为了无效。
只有在SLB的一小部分被有效数据占用的情况下,SLB才能变为状态为R1或R2的RLB。
partial 或switch merge 操作将SLB日志块改变为F状态,
full merge 操作将RLB改变为F状态,Ri状态的RLB full merge消耗为N · i · Ccopy + (i + 1) · Cerase.
写LOG BUFFER
当一个PAGE需要写入LOG BUFFER时,需要查找LOG块中有空闲空间的写入,如果找不到则需要进行log block merge操作,这个过程比较复杂,如下
首先查找是否有RLB,这个RLB中已经有了待写入PAGE对应的DATA块的其他PAGE,如果有则可以将PAGE写入该RLB而不增加关联度,如下图的(b)。
如果这个PAGE在DATA块中的偏移是0,可以将这个块写入SLB的第一个PAGE,因为我们猜测后续可能是连续的序列操作,这样可以都放入一个SLB可以使用部分或者switch merge。如果后面不是序列写也没关系,可以再变为RLB,如下图的(c)。。
那么如果以上两个条件都满足呢? 这时我们先按照(b)Append的策略写入RLB而先不去搜索SLB。
然后再单独分配一个SLB。
直到后续后面RLB中的PAGE又有需要更新时,再将RLB中的PAGE序列写入SLB中,将RLB中的PAGE设置为无效,如下图(d)
开始时(a)->更新p0->p0放入RLB中->更新p1 p5->将p0 p1 p5按照page序号偏移写入SLB->从DATA块中复制未更新的p2 p3 p4到SLB中补齐。
以上的思想是猜测更新块的第一个PAGE时可能不是随机写,后面可能有连续次序更新所以使用SLB。

如果需要更新的PAGE所在的块已经和一个SLB关联,则需要将这个PAGE写入这个SLB。如果这个写不需要破坏SLB中原来PAGE的次序则可以直接写入。
如果写入这个PAGE和原来SLB中已有的PAGE中间有一个小间隙,则可以直接写入,如下图(b),原来SLB中有p0 p1 p2更新p5则可以直接写入该SLB,中间p3 p4需要padding。
而如果上述间隙比较大,或者SLB中已经有了相应的PAGE,如下图SLB中已经有了p0 p1 p2 此时认为后面间隙比较大,或者已经有了p0 p1 p2 p5,此时要更新p5,p5已经在SLB中了,这两种情况都又有两种策略
第一种是使用partial merge,先将SLB merge到DATA块, merge同时更新p5到DATA块.
间隙的p3 p4 p6 p7需要从DATA块中拷贝出来,一并merge到新的DATA块中,如下图(c)。
还有一种策略,如(d)将p5添加到SLB中,此时p5和前面的p0~p1不属于同一个DATA块则增加了关联度。只有当SLB中free page比较多时采用后者,因为这种情况我们猜测后续的序列更新的概率很小。此外,既然SLB中有很多空闲页面,那么最好继续使用,而不是执行部分合并。

如果找不到上述LOG块,即更新的PAGE所在的DATA块已经和LOG关联,那么就只能增加LOG块的关联度。
下一步进行时先检查是否有SLB已经完成的(即已经按序列写满),如果有则擦除这个SLB对应的DATA块,将这个SLB变为DATA块,即switch merge。
由于交换机合并没有页面复制开销,因此利用它比增加任何其他日志块的块关联性更好。
如果PAGE的偏移是0,则跳过上述处理,直接先merge一个LOG块,作为新SLB使用。
上述处理实际是选择要牺牲掉哪一个LOG块RLB去进行MERGE,RLB的关联度比较低,且空闲PAGE较多的有线选择。这是出于平衡LOG块的关联度和空闲PAGE数。只要LOG块的关联度小于我们设置的K则可以增加其关联度。
即使有一个SLB,待更新PAGE的DATA块和该SLB无关联,如果该SLB的空闲PAGE比较多,我们依然可以将该PAGE写入该SLB,增加了关联度,但是降低了MERGE频率,因为可能很长时间都不需要MERGE。此时SLB变为了RLB。
如果没有LOG块的关联度小于K且有空闲块,则无法将PAGE写入LOG块。
第三步则是MERGE LOG块以或者空闲LOG块。
首先考虑的是否有SLB可以partial merge的。如果SLB中有许多空闲PAGE,我们先不执行partial merge,继续保持SLB,延迟SLB的partial merge,我们可以将它用于未来的后续更新请求。
然后考虑的是MERGE RLB的MERGE消耗最小,空闲PAGE最小的,消耗的大小由关联度来确定。MERGE一个LOG块之后就有空闲的LOG块继续使用了。
总结
本文对uC-FS的NAND驱动所基于的算法论文进行了详解,对算法有了一个整体的了解。算法到代码的实现还有一个很复杂的过程,需要考虑各种细节,所以以上只是一个整体概览。后面我们会继续分析其代码的实现细节。
审核编辑:汤梓红
-
新紫光集团三大领域全家桶正式发布2026-05-15 465
-
TAS5717驱动在调试tas5717的时候, 0X02寄存器报错02是什么原因导致的?2024-10-30 311
-
调试TAS5729MD时,读Error Status Register (0x02) 返回值 02,写入02 00均不能清除怎么处理?2024-10-11 328
-
stm32f427 OTG_FS端点是否可以配置端点地址,比如0x0a等等?2024-05-11 367
-
ad7124的ID读出来是0X02对吗?2023-12-13 702
-
Micrium全家桶之uC-FS: 0x01 NAND FTL2023-06-08 7492
-
讲讲Micrium全家桶的uC-CRC算法2023-05-04 1987
-
相比React全家桶选择Vue2有何优劣?2020-06-01 1326
-
嵌入式文件系统µC/FS的日志使用2019-09-19 2677
-
MPU6050中DMP中断配置为什么会配置成0x02?2019-05-10 2795
-
AD2S1210故障寄存器0x02问题:相位误差超过锁相范围2019-02-12 3825
-
fx2lp时钟设置CPUCS=0x02对SimcDelt有影响吗2018-09-14 1707
-
请问ad7124的ID读出来是0X02对吗?2018-08-15 4203
全部0条评论

快来发表一下你的评论吧 !
