

使用单卡高效微调bloom-7b1,效果惊艳
描述
在文章Firefly(流萤): 中文对话式大语言模型、中文对话式大语言模型Firefly-2b6开源,使用210万训练数据中,我们介绍了关于Firefly(流萤)模型的工作。对大模型进行全量参数微调需要大量GPU资源,所以我们通过对Bloom进行词表裁剪,在4*32G的显卡上,勉强训练起了2.6B的firefly模型。
在本文中,我们将介绍QLoRA,由华盛顿大学提出的一种高效微调大模型的方法,可在单张A100上对LLaMA-65B进行微调。在论文中,作者的实验表明使用QLoRA微调的LLaMA-65B,可达到ChatGPT性能水平的99.3%(由GPT-4进行评价),并且QLoRA的性能可以逼近全量参数微调。作者做了丰富的实验证明这一结论。

在本文中我们将对QLoRA的基本原理进行介绍,并且在Firefly项目中进行实践。我们在bloom-7b1的基础上,使用QLoRA进行中文指令微调,获得firefly-7b1-qlora-v0.1模型,具有不错的效果,生成效果见第三章。QLoRA确实是一种高效训练、效果优秀、值得尝试和深入研究的方法。
论文地址:
https://arxiv.org/pdf/2305.14314.pdf
项目代码:
https://github.com/yangjianxin1/Firefly
模型权重:
https://huggingface.co/YeungNLP/firefly-7b1-qlora-v0.1
01
QLoRA简介
本章节主要对LoRA与QLoRA进行介绍,如读者已了解本章节的内容,可直接跳过,阅读项目实践部分。
LoRA简介
在介绍QLoRA之前,简单回顾一下LoRA。LoRA的本质是在原模型的基础上插入若干新的参数,称之为adapter。在训练时,冻结原始模型的参数,只更新adapter的参数。对于不同的基座模型,adapter的参数量一般为几百万~几千万。
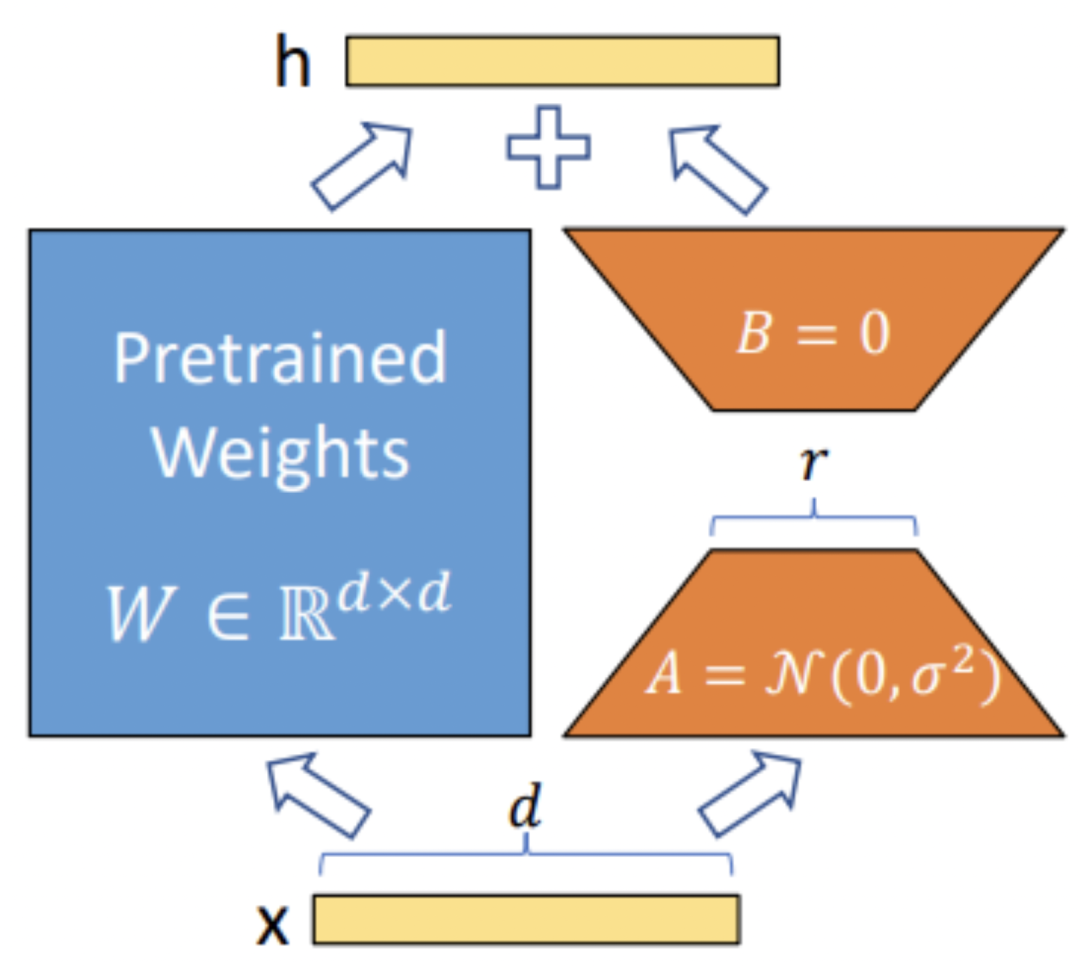
LoRA的优势在于能够使用较少的GPU资源,在下游任务中对大模型进行微调。在开源社区中,开发者们使用LoRA对Stable Diffusion进行微调,取得了非常不错的效果。随着ChatGPT的火爆,也涌现出了许多使用LoRA对LLM进行指令微调的工作。
此前,我们也实践过使用LoRA对LLM进行指令微调,虽然未进行定量分析,但主观感受LoRA比全量微调还是有一定的差距。实践下来,我们发现LoRA微调中存在以下三个痛点:
-
参数空间小:LoRA中参与训练的参数量较少,解空间较小,效果相比全量微调有一定的差距。
-
微调大模型成本高:对于上百亿参数量的模型,LoRA微调的成本还是很高。
-
精度损失:针对第二点,可以采用int8或int4量化,进一步对模型基座的参数进行压缩。但是又会引发精度损失的问题,降低模型性能。
QLoRA简介
接下来便引入今天的主角QLoRA。整篇论文读下来,我们认为QLoRA中比较重要的几个做法如下:
-
4-bit NormalFloat:提出一种理论最优的4-bit的量化数据类型,优于当前普遍使用的FP4与Int4。
-
Double Quantization:相比于当前的模型量化方法,更加节省显存空间。每个参数平均节省0.37bit,对于65B的LLaMA模型,大约能节省3GB显存空间。
-
Paged Optimizers:使用NVIDIA统一内存来避免在处理小批量的长序列时出现的梯度检查点内存峰值。
-
增加Adapter:4-bit的NormalFloat与Double Quantization,节省了很多空间,但带来了性能损失,作者通过插入更多adapter来弥补这种性能损失。在LoRA中,一般会选择在query和value的全连接层处插入adapter。而QLoRA则在所有全连接层处都插入了adapter,增加了训练参数,弥补精度带来的性能损失。
通过上述优化,只需要41G显存即可微调LLaMA-65B模型。甚至可以直接使用一张1080Ti来微调LLaMA-13B,手中的旧卡又可以继续发挥余热了。
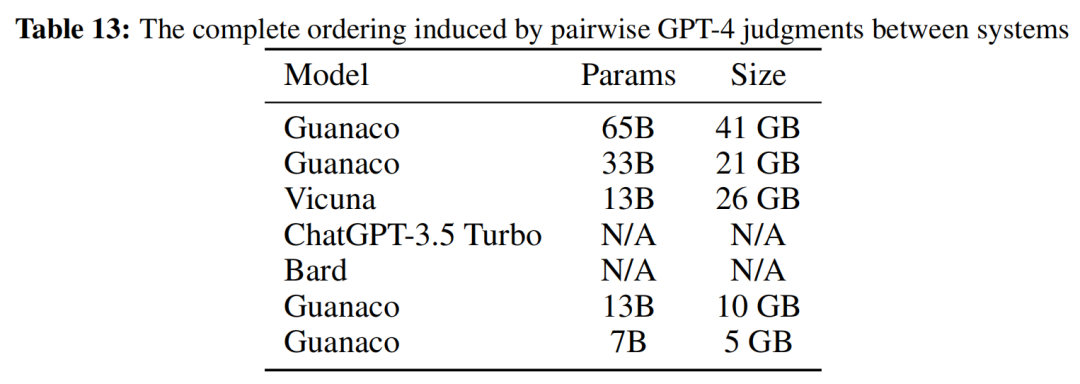
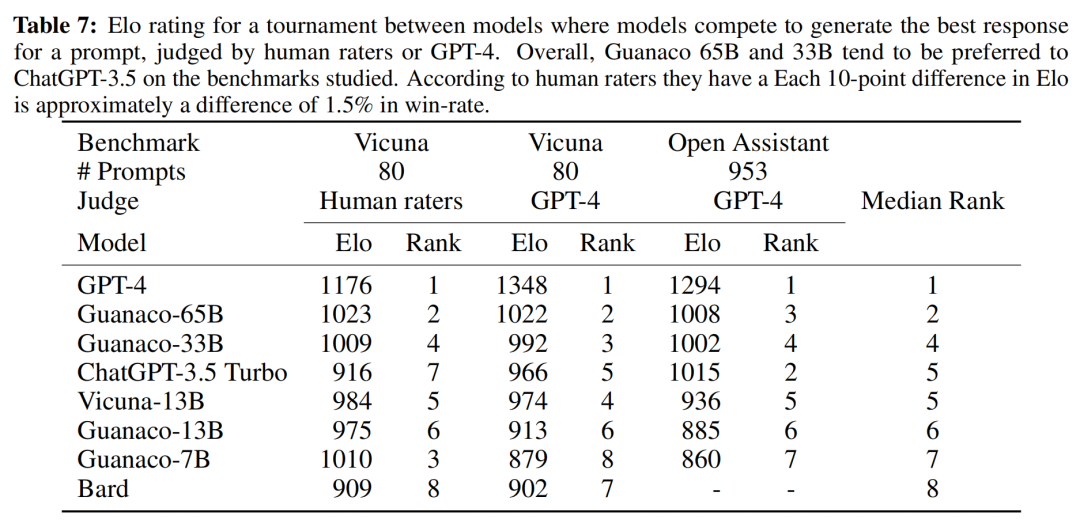
作者使用GPT4对各个模型进行评价,结果显示,使用QLoRA在OASST1数据集上微调得到的Guanaco-65B模型达到了ChatGPT的99.3%的性能。
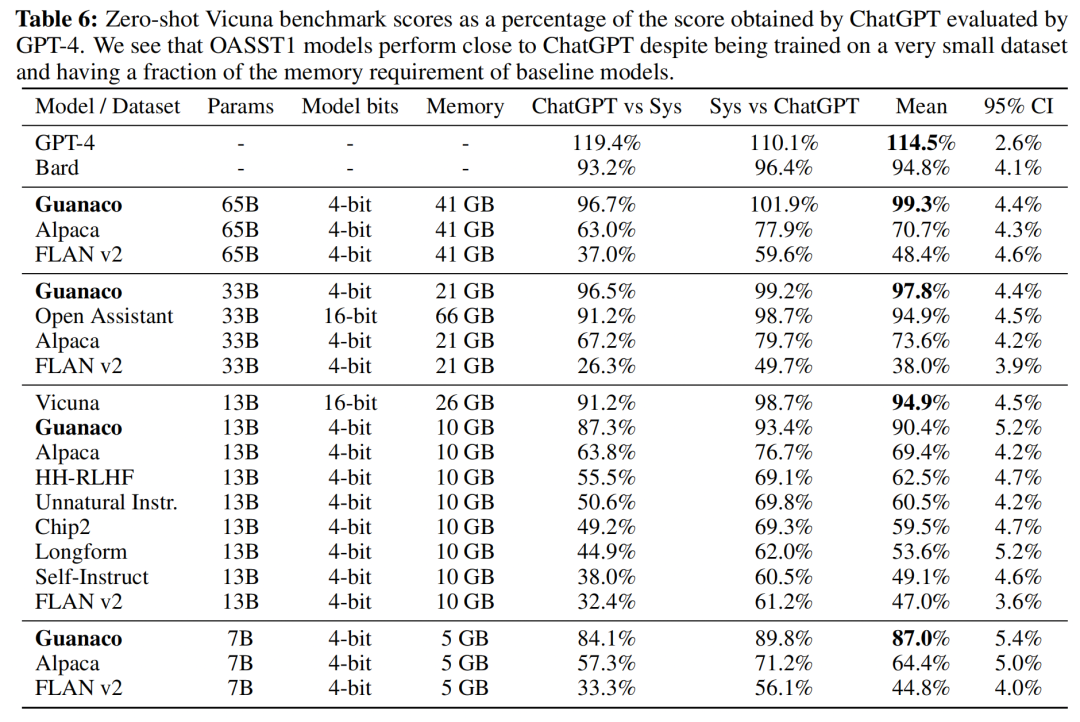
作者进一步采用了Elo等级分制度对各个模型进行评价,裁判为人类或者GPT-4。结果显示Guanaco-65B和Guanaco-33B均优于ChatGPT-3.5。
实验分析
QLoRA方法是否有用,其与全量参数微调的差距有多大?作者使用LLaMA-7B和Alpaca数据集进行了实验。下图结果表明,通过插入更多的adapter,能够弥补QLoRA量化带来的性能损失,复现全量参数微调的效果。
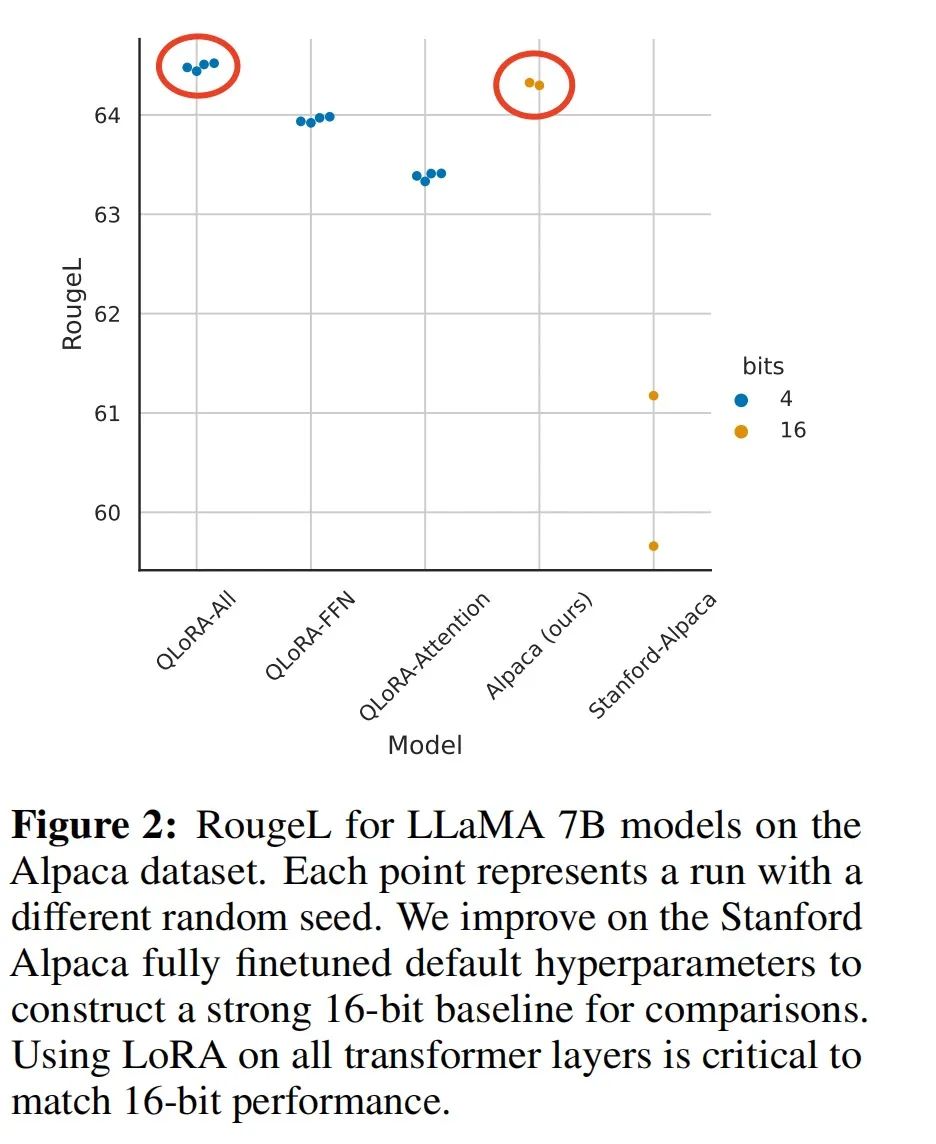
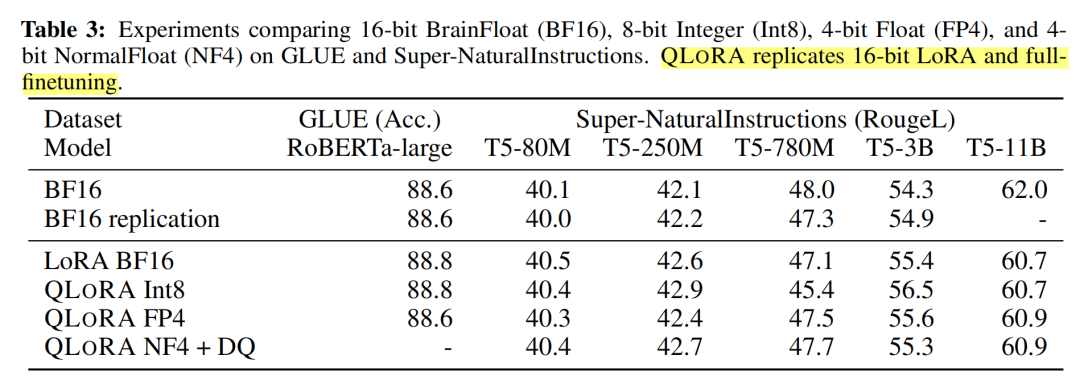
除此之外,作者还将QLoRA应用于RoBERTA和T5,评测其在GLUE和Super-NaturalInstructions数据集上的表现。从下表中可以看到,QLoRA+NF4+DQ基本上复现了BF16全量微调的实验指标。
下表中LoRA+BF16基本上也复现了BF16全量微调的实验指标,如果作者能加上LoRA+FP4或者LoRA+int4的实验结果,则可以更清晰地展现LoRA与QLoRA的性能差异。
在指令微调阶段,数据质量和数据数量,哪一个更重要?作者使用三种不同的训练集,每个数据集分别使用5万、10万、15万的数据量进行训练。对于下表,纵向来看,随着数据量的增加,指标并没有明显的提升,说明数据量不是关键因素。横向来看,对于不同的数据集,指标差距甚大,说明数据质量更关键。
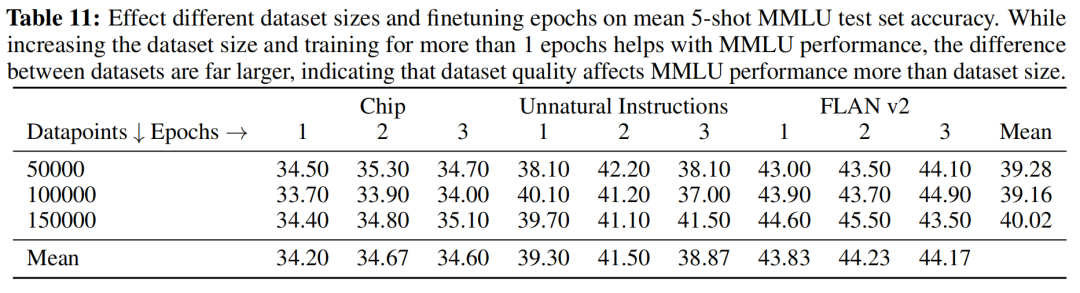
值得一提的是,在论文中,作者仅使用了9千多条OASST1的数据训练得到Guanaco-65B,这进一步验证了,数据质量远比数量重要,模型的知识来源于预训练阶段。
模型的知识来源于预训练阶段,指令微调目的是和人类指令进行对齐。在指令微调阶段,数据的质量与丰富度,远比数量更重要。这是最近一段时间,开源社区以及各个论文强调的一个结论,在我们的实践中也深有体会。
02
项目实践
在本项目中,我们使用bloom-7b1作为基座模型。数据集为moss-003-sft-no-tools,这是由MOSS项目开源的中文指令微调数据集,我们随机抽取了29万条作为训练数据,训练得到firefly-7b1-qlora-v0.1。
训练时,我们将多轮对话拼接成如下格式,然后进行tokenize。
<s>input1s>target1s>input2s>target2s>...
我们在一张32G显卡上使用QLoRA进行训练,在所有全连接层处都插入adapter,最终参与训练的参数量超过1亿,相当于一个bert-base的参数量。训练时只计算target部分的损失函数。
训练超参数如下所示:
| max length | 1024 |
| lr_scheduler_type | cosine |
| batch size | 16 |
| lr | 2e-4 |
| warmup step | 3000 |
| optimizer | paged_adamw_32bit |
| training step | 18万 |
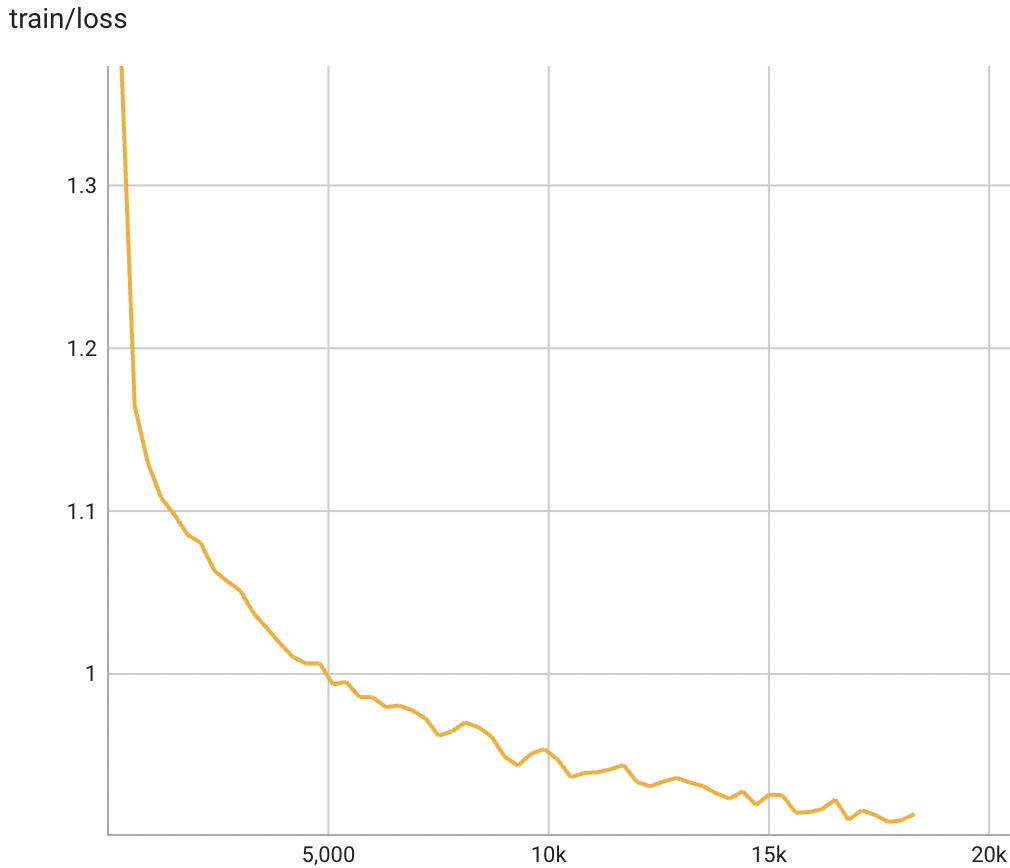
模型的训练损失的变化趋势如下图所示:
firefly-7b1-qlora-v0.1的使用方式如下:
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer, LlamaTokenizer, BitsAndBytesConfig
import torch
model_name = 'bigscience/bloom-7b1'
adapter_name = 'YeungNLP/firefly-7b1-qlora-v0.1'
device = 'cuda'
input_pattern = '{}'
model = AutoModelForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map='auto'
)
model = PeftModel.from_pretrained(model, adapter_name)
model.eval()
model = model.to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
text = input('User:')
while True:
text = input_pattern.format(text)
input_ids = tokenizer(text, return_tensors="pt").input_ids
input_ids = input_ids.to(device)
outputs = model.generate(input_ids=input_ids, max_new_tokens=250, do_sample=True, top_p=0.75, temperature=0.35,
repetition_penalty=1.2, eos_token_id=tokenizer.eos_token_id)
rets = tokenizer.batch_decode(outputs)
output = rets[0].strip().replace(text, "").replace('', "")
print("Firefly:{}".format(output))
text = input('User:')
03
生成效果
下面的样例均为firefly-7b1-qlora-v0.1模型所生成,未经修改,仅供参考。
多轮对话
对话示例1:

对话示例2:

邮件生成



商品文案生成


医疗问答


创意性写作





其他例子




04
结语
在本文中,我们介绍了QLoRA的基本原理,以及论文中一些比较重要的实验结论。并且使用QLoRA对bloom-7b1模型进行中文指令微调,获得了非常不错的效果。
从firefly-7b1-qlora-v0.1的生成效果来看,虽然没有做定量的评测(对LLM做评测确实比较困难),但就生成效果来看,丝毫不逊色于全量微调的firefly-2b6-v2。
一些碎碎念:
-
论文中表明QLoRA能够媲美全量参数微调的效果,虽然可能需要更丰富、多角度的实验进行验证,但如果【增大基座模型的参数量+QLoRA】能够优于【全量微调较小的模型】,也是非常有意义的。
-
对基座模型进行量化压缩,通过增加adapter来弥补量化导致性能损失,是一个非常不错的idea,论文中的实验也证实了这一点。并且从我们的实践效果看来,确实惊艳,效果远胜LoRA。
-
最后,如果你手边的训练资源不足,QLoRA非常值得一试。
-
AI大模型微调企业项目实战课2026-04-16 930
-
红米 Note (4G单卡版)刷机教程2015-08-25 4723
-
信源定位方案中基于Bloom Filter存储的概率日志记录2010-02-10 637
-
多圈微调线绕电位器2009-08-21 2305
-
7B04-1:4频道7B系列烘焙计划2021-05-18 664
-
ASEMI整流桥B1 THRU B7数据手册2022-08-05 1360
-
ASEMI整流桥B1 THRU B7规格书2022-08-10 1164
-
iPhone都能微调大模型了嘛2023-06-02 1613
-
多任务微调框架MFTCoder详细技术解读2023-11-17 2314
-
大模型单卡的正确使用步骤2024-07-05 1702
-
chatglm2-6b在P40上做LORA微调2024-08-13 1678
-
具有载波聚合的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc2025-04-11 169
-
带增益的 RX 分集 FEM(B3、B39、B1、B40、B41 和 B7) skyworksinc2025-06-19 334
-
带增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc2025-06-27 180
-
Vishay Sfernice TS7密封型表面贴装微调电位器技术解析2025-11-12 1072
全部0条评论

快来发表一下你的评论吧 !
