

从双目标定到立体匹配:Python实践指南
描述
立体匹配是计算机视觉中的一个重要领域,旨在将从不同角度拍摄的图像匹配起来,以创建类似人类视觉的3D效果。实现立体匹配的过程需要涉及许多步骤,包括双目标定、立体校正、视差计算等。在这篇文章中,将介绍如何使用Python实现立体匹配的基本步骤和技巧。
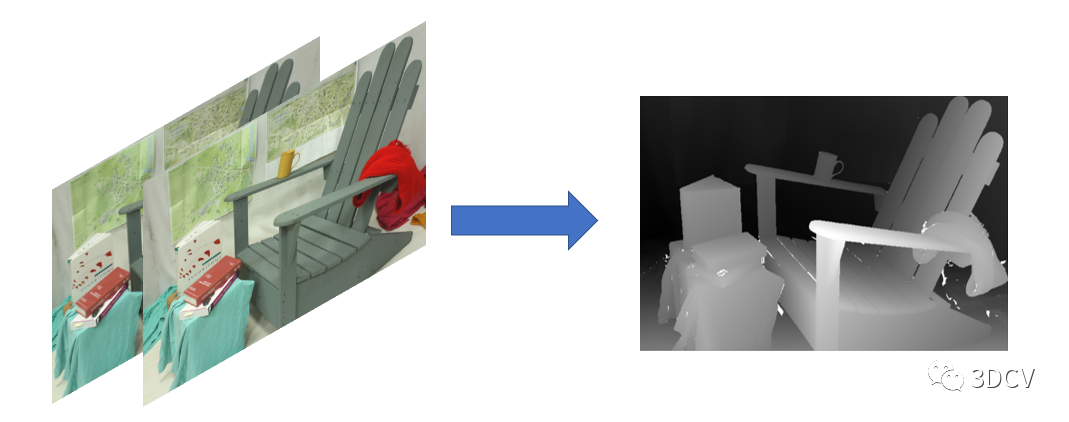
下面的代码实现了从相机标定到立体匹配的完整流程,下面将分别介绍各个函数的参数和输出。
标定
首先,该程序需要用到以下库:
numpy
cv2 (OpenCV)
os
在程序开头,需要定义一些变量来存储标定图片的路径、棋盘格参数、角点坐标等等。具体介绍如下:
path_left = "./data/left/"
path_right = "./data/right/"
path_left和path_right是左右相机标定图片文件夹的路径。
CHESSBOARD_SIZE = (8, 11)
CHESSBOARD_SQUARE_SIZE = 15 # mm
CHESSBOARD_SIZE是棋盘格内部角点的行列数,CHESSBOARD_SQUARE_SIZE是棋盘格内部每个小正方形的大小(单位为毫米)。
objp = np.zeros((CHESSBOARD_SIZE[0] * CHESSBOARD_SIZE[1], 3), np.float32)
objp[:, :2] = np.mgrid[0:CHESSBOARD_SIZE[0], 0:CHESSBOARD_SIZE[1]].T.reshape(-1, 2) * CHESSBOARD_SQUARE_SIZE
objp是物理坐标系下每个角点的三维坐标,即棋盘格的位置。该变量在后续的相机标定以及立体匹配中都会被用到。
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
criteria是角点检测的终止准则,一般都使用这个默认值。
img_list_left = sorted(os.listdir(path_left))
img_list_right = sorted(os.listdir(path_right))
img_list_left和img_list_right分别是左、右图像的文件名列表,使用os.listdir()函数获取。
obj_points = []
img_points_left = []
img_points_right = []
obj_points、img_points_left和img_points_right分别是存储每个标定图片对应的物理坐标系下的角点坐标、左相机的像素坐标和右相机的像素坐标。这些变量同样在后续的相机标定和立体匹配中用到。
接下来,程序读取标定图片并检测角点。对于每幅图片,程序执行以下操作:
img_l = cv2.imread(path_left + img_list_left[i])
img_r = cv2.imread(path_right + img_list_right[i])
gray_l = cv2.cvtColor(img_l, cv2.COLOR_BGR2GRAY)
gray_r = cv2.cvtColor(img_r, cv2.COLOR_BGR2GRAY)
首先读取左右图像,然后将它们转换为灰度图像。
ret_l, corners_l = cv2.findChessboardCorners(gray_l, CHESSBOARD_SIZE, None)
ret_r, corners_r = cv2.findChessboardCorners(gray_r, CHESSBOARD_SIZE, None)
通过OpenCV的cv2.findChessboardCorners()函数检测左右图像上的棋盘格角点。这个函数的参数包括:
image:需要检测角点的灰度图像。patternSize:内部角点的行列数,即(CHESSBOARD_SIZE[1]-1, CHESSBOARD_SIZE[0]-1)。corners:用于存储检测到的角点坐标的数组。如果检测失败,则该参数为空(None)。flags:检测时使用的可选标志。这个函数的返回值包括:
ret:一个布尔值,用于指示检测是否成功。如果检测成功,则为True,否则为False。corners:用于存储检测到的角点坐标的数组。接下来是亚像素级别的角点检测。
cv2.cornerSubPix(gray_l, corners_l, (11, 11), (-1, -1), criteria)
cv2.cornerSubPix(gray_r, corners_r, (11, 11), (-1, -1), criteria)
这里使用了OpenCV的cv2.cornerSubPix()函数来进行亚像素级别的角点检测。这个函数的参数包括:
image:输入的灰度图像。
corners:用于存储检测到的角点坐标的数组。
winSize:每次迭代中搜索窗口的大小,即每个像素周围的搜索范围大小。通常为11x11。
zeroZone:死区大小,表示怎样的对称性(如果有的话)不考虑。通常为(-1,-1)。
criteria:定义迭代停止的误差范围、迭代次数等标准,和以上的criteria一样。
img_points_left.append(corners_l)
img_points_right.append(corners_r)
如果检测到了左右图像上的角点,则将这些角点的坐标存储到img_points_left和img_points_right中。
cv2.drawChessboardCorners(img_l, CHESSBOARD_SIZE, corners_l, ret_l)
cv2.imshow("Chessboard Corners - Left", cv2.resize(img_l,(img_l.shape[1]//2,img_l.shape[0]//2)))
cv2.waitKey(50)
cv2.drawChessboardCorners(img_r, CHESSBOARD_SIZE, corners_r, ret_r)
cv2.imshow("Chessboard Corners - Right", cv2.resize(img_r,(img_r.shape[1]//2,img_r.shape[0]//2)))
cv2.waitKey(50)
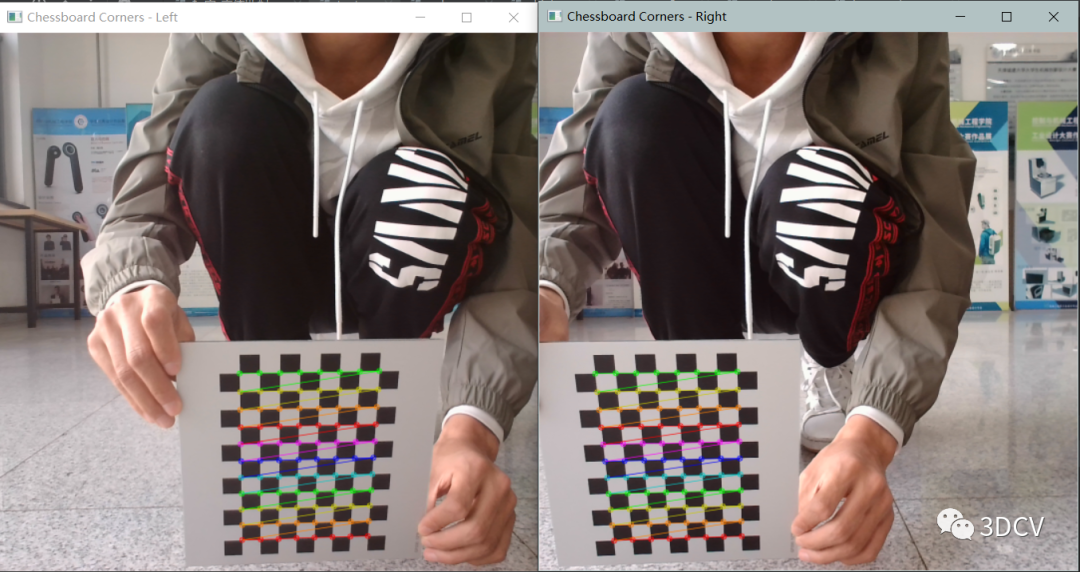 在图片上标出检测到的角点,并在窗口中显示。这里使用了cv2.drawChessboardCorners()函数,该函数的参数包括:
在图片上标出检测到的角点,并在窗口中显示。这里使用了cv2.drawChessboardCorners()函数,该函数的参数包括:
img:需要标定角点的图像。patternSize:内部角点的行列数,即(CHESSBOARD_SIZE[1]-1, CHESSBOARD_SIZE[0]-1)。
corners:存储检测到的角点坐标的数组。patternfound:检测到角点的标记,即ret。
程序接下来对双目摄像机进行标定。
ret_l, mtx_l, dist_l, rvecs_l, tvecs_l = cv2.calibrateCamera(obj_points, img_points_left, gray_l.shape[::-1],None,None)
ret_r, mtx_r, dist_r, rvecs_r, tvecs_r = cv2.calibrateCamera(obj_points, img_points_right, gray_r.shape[::-1],None,None)
flags = 0
flags |= cv2.CALIB_FIX_INTRINSIC
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
ret, M1, d1, M2, d2, R, T, E, F = cv2.stereoCalibrate(
obj_points, img_points_left, img_points_right,
mtx_l, dist_l, mtx_r, dist_r,
gray_l.shape[::-1], criteria=criteria, flags=flags)
这段代码首先对左右相机进行单独标定:
ret_l, mtx_l, dist_l, rvecs_l, tvecs_l = cv2.calibrateCamera(obj_points, img_points_left, gray_l.shape[::-1],None,None)
ret_r, mtx_r, dist_r, rvecs_r, tvecs_r = cv2.calibrateCamera(obj_points, img_points_right, gray_r.shape[::-1],None,None)
这里使用了OpenCV的cv2.calibrateCamera()函数对左右相机进行标定。这个函数的参数包括:
objectPoints:每幅标定图片对应的物理坐标系下的角点坐标。
imagePoints:每幅标定图片上检测到的像素坐标。
imageSize:标定图片的尺寸。
cameraMatrix:用于存储标定结果的内参数矩阵。
distCoeffs:用于存储标定结果的畸变系数。
rvecs:每幅标定图片的外参数矩阵中的旋转向量。
tvecs:每幅标定图片的外参数矩阵中的平移向量。
这个函数的返回值包括:
ret:一个标志位,表示标定是否成功。
cameraMatrix:用于存储标定结果的内参数矩阵。
distCoeffs:用于存储标定结果的畸变系数。
rvecs:每幅标定图片的外参数矩阵中的旋转向量。
tvecs:每幅标定图片的外参数矩阵中的平移向量。
然后对双目摄像机进行标定:
flags = 0
flags |= cv2.CALIB_FIX_INTRINSIC
criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)
ret, M1, d1, M2, d2, R, T, E, F = cv2.stereoCalibrate(
obj_points, img_points_left, img_points_right,
mtx_l, dist_l, mtx_r, dist_r,
gray_l.shape[::-1], criteria=criteria, flags=flags)
这里使用了OpenCV的cv2.stereoCalibrate()函数进行双目摄像机标定。这个函数的参数包括:
objectPoints:每幅标定图片对应的物理坐标系下的角点坐标。
imagePoints1:每幅标定图片的左相机上检测到的像素坐标。
imagePoints2:每幅标定图片的右相机上检测到的像素坐标。
cameraMatrix1:左相机的内参数矩阵。
distCoeffs1:左相机的畸变系数。
cameraMatrix2:右相机的内参数矩阵。
distCoeffs2:右相机的畸变系数。
imageSize:标定图片的尺寸。
criteria:定义迭代停止的误差范围、迭代次数等标准。
flags:标定的可选标志。
这个函数的返回值包括:
ret:一个标志,表示标定是否成功。
cameraMatrix1:左相机的内参数矩阵。
distCoeffs1:左相机的畸变系数。
cameraMatrix2:右相机的内参数矩阵。
distCoeffs2:右相机的畸变系数。
R:旋转矩阵。
T:平移向量。
E:本质矩阵。
F:基础矩阵。
立体匹配
通过图像标定得到的参数进行立体匹配的整个流程,如下:
首先,我们需要读取左右两张图像:
img_left = cv2.imread("./left.png")
img_right = cv2.imread("./right.png")
其中,"./left.png" 和 "./right.png" 是放置左右图像的路径。这两幅图像是未经校正和矫正的图像。
接下来,通过图像标定得到相机的参数,根据得到的参数,将图像进行去畸变:
img_left_undistort = cv2.undistort(img_left, M1, d1)
img_right_undistort = cv2.undistort(img_right, M2, d2)
在上述代码中,M1、M2、d1、d2 是从双目相机标定中获得的参数。去畸变后的图像 img_left_undistort 和 img_right_undistort 可供之后的操作使用。
然后,进行极线校正,以实现左右图像在几何上的一致性:
R1, R2, P1, P2, Q, roi1, roi2 = cv2.stereoRectify(M1, d1, M2, d2, (width, height), R, T, alpha=1)
map1x, map1y = cv2.initUndistortRectifyMap(M1, d1, R1, P1, (width, height), cv2.CV_32FC1)
map2x, map2y = cv2.initUndistortRectifyMap(M2, d2, R2, P2, (width, height), cv2.CV_32FC1)
img_left_rectified = cv2.remap(img_left_undistort, map1x, map1y, cv2.INTER_LINEAR)
img_right_rectified = cv2.remap(img_right_undistort, map2x, map2y, cv2.INTER_LINEAR)
其中,R、T 是双目相机标定得到的旋转和平移矩阵, (width, height)是左右图像的尺寸。R1、R2 是左右图像的旋转矩阵,P1、P2 是左右图像的投影矩阵,Q 是视差转换矩阵,roi1、roi2 是矫正后的图像中可以使用的区域。
然后,将左右图像拼接在一起以方便观察:
img_stereo = cv2.hconcat([img_left_rectified, img_right_rectified])

接下来,需要计算视差图:
minDisparity = 0
numDisparities = 256
blockSize = 9
P1 = 1200
P2 = 4800
disp12MaxDiff = 10
preFilterCap = 63
uniquenessRatio = 5
speckleWindowSize = 100
speckleRange = 32
sgbm = cv2.StereoSGBM_create(minDisparity=minDisparity, numDisparities=numDisparities, blockSize=blockSize,
P1=P1, P2=P2, disp12MaxDiff=disp12MaxDiff, preFilterCap=preFilterCap,
uniquenessRatio=uniquenessRatio, speckleWindowSize=speckleWindowSize,
speckleRange=speckleRange, mode=cv2.STEREO_SGBM_MODE_SGBM_3WAY)
disparity = sgbm.compute(img_left_rectified,img_right_rectified)
上面的代码块定义了使用的视差算法的参数,并使用了 SGBM(Semi Global Block Matching)算法计算了原始的视差图。注意,由于使用的是16位的 SGBM 输出,因此需要将它除以16。 接下来,可以对视差图进行 WLS 滤波,减少视差空洞:
接下来,可以对视差图进行 WLS 滤波,减少视差空洞:
# 定义 WLS 滤波参数
lambda_val = 4000
sigma_val = 1.5
# 运行 WLS 滤波
wls_filter = cv2.ximgproc.createDisparityWLSFilterGeneric(False)
wls_filter.setLambda(lambda_val)
wls_filter.setSigmaColor(sigma_val)
filtered_disp = wls_filter.filter(disparity, img_left_rectified, None, img_right_rectified)
filtered_disp_nor = cv2.normalize(filtered_disp, filtered_disp, alpha=0, beta=255, norm_type=cv2.NORM_MINMAX, dtype=cv2.CV_8U)
上述代码块中,WLS 滤波为视差图降噪,并进行平滑处理。这里使用了 cv2.ximgproc.createDisparityWLSFilterGeneric 函数,创建一个生成 WLS 滤波器的对象 wls_filter,然后设置了滤波参数 lambda_val 和 sigma_val。filtered_disp 是经过滤波后的视差图。filtered_disp_nor 是经过归一化处理后的、用于显示的视差图。
最后,可以在窗口中显示原始视差图、预处理后的 WLS 滤波器的视差图:
cv2.imshow("disparity", cv2.resize(disparity_nor,(disparity_nor.shape[1]//2,disparity_nor.shape[0]//2)))
cv2.imshow("filtered_disparity", cv2.resize(filtered_disp_nor,(filtered_disp_nor.shape[1]//2,filtered_disp_nor.shape[0]//2)))
cv2.waitKey()
cv2.destroyAllWindows()

-
双目立体匹配的四个步骤2023-06-28 2364
-
相机之间为什么要进行双目标定呢?2022-12-28 3948
-
双目标定是什么?为什么要进行双目标定?2021-07-04 12976
-
融合边缘特征的立体匹配算法Edge-Gray2021-04-29 1275
-
一种基于PatchMatch的半全局双目立体匹配算法2021-04-20 975
-
双目立体计算机视觉的立体匹配研究综述2021-04-12 1386
-
双目立体匹配的四个步骤解析2020-08-31 6513
-
立体匹配SAD算法原理2019-06-05 2874
-
基于HALCON的双目是相机立体视觉系统标定2017-11-06 1832
-
基于颜色调整的立体匹配改进算法2017-11-02 730
-
一种快速双目立体匹配方法_梅金燕2017-03-19 927
-
维视双目产品在高校科研应用中的实例及优点分析2016-01-19 2925
-
双目立体视觉原理大揭秘(一)2013-11-21 3318
-
双目视觉立体匹配算法研究2010-08-14 1469
全部0条评论

快来发表一下你的评论吧 !
