

ARM Cortex-M4内核架构概述
ARM
描述
1、什么是ARM Cortex-M处理器
1.1、Cortex-M3和Cortex-M4处理器
Cortex-M3(2005年发布)和Cortex-M4(2010年发布)处理器是ARM公司设计的处理器。
Cortex-M3和Cortex-M4处理器使用32位架构,寄存器组中断内部寄存器、数据以及总线接口都是32位。Cortex-M处理器使用的指令集架构(ISA)是Thumb ISA(是一种RISC(精简指令集)),其基于Thumb-2技术并同时支持16位和32位指令。
主要有以下特点:
- 三级流水线:取指、译码、执行。
- 哈佛总线架构,即具有统一的存储器空间:指令和地址总线使用相同的地址空间。
- 32位寻址,支持4GB存储器空间
- 有名为NVIC(嵌套向量中断控制器)的中断控制器,支持最多240个中断请求和8-256个中断优先级。
- 支持多种OS特性,如节拍定时器(systick)、影子栈指针(双栈指针:MSP/PSP)。
- 休眠模式和多种低功耗特性。
- 支持可选的MPU(存储器保护单元),提供了存储器的访问权限控制。
- 支持两个特定存储区域的位段访问
Cortex-M3和M4处理器提供了多种指令:
- 普通数据处理,包括硬件除法指令。
- 存储器访问指令,支持8位、16位、32位、64位数据,以及其他可传输多个32位数据的指令。
- 位域处理指令。
- 乘累加(MAC)以及饱和指令。
- 用于跳转、条件跳转以及函数调用的指令
- 用于系统控制、支持OS等的指令。
另外,M4处理器还支持:
- 单指令多数据(SIMD)指令。
- 其他快速MAC和乘法指令。
- 饱和运算指令。
- 可选的单精度浮点指令。
1.2、Cortex-M处理器家族
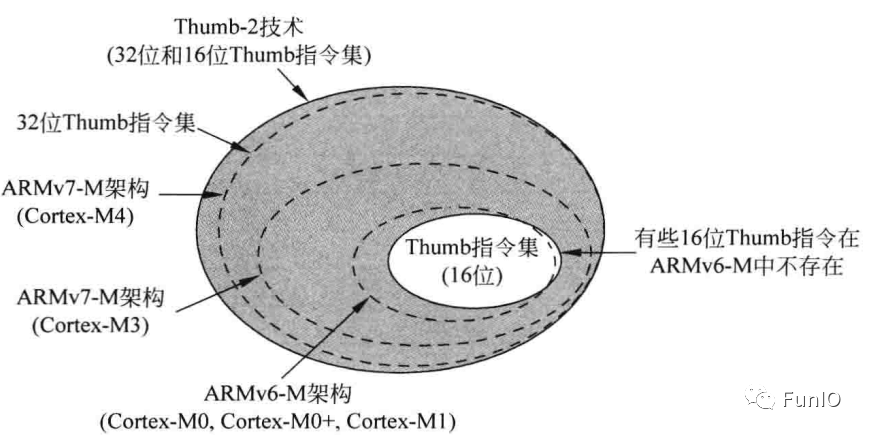
Cortex-M3和Cortex-M4处理器基于ARMv7-M架构。Cortex-M4处理器具有SIMD、快速MAC以及饱和指令,可以执行一些数组信号处理程序。
Cortex-M0、Cortex-M0+和Cortex-M1基于ARMv6-M架构。Cortex-M1是专门为FPGA应用设计的。
Cortex-M33基于ARMv8-M架构。添加了trustzone等安全组件。
1.3、处理器和微控制器的区别
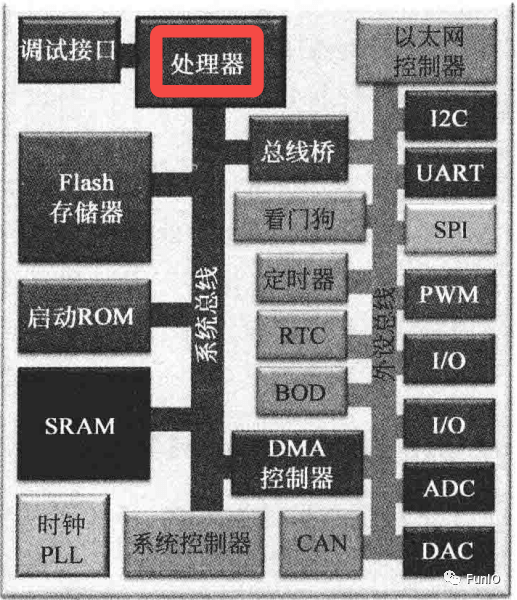
在一个典型的微控制器设计中,处理器只会占芯片中的一小块区域。其他部分为存储器、时钟生成(如PLL)和分配逻辑、系统总线以及外设等(I/O接口单元、通信接口、定时器、ADC、DAC等硬件单元)。微控制器供应商(比如ST、TI、NXP)选择Cortex-M处理器作为它们的CPU,添加上述的其他功能单元,最终成为一个微控制器。如下图:
1.4、ARM处理器的发展
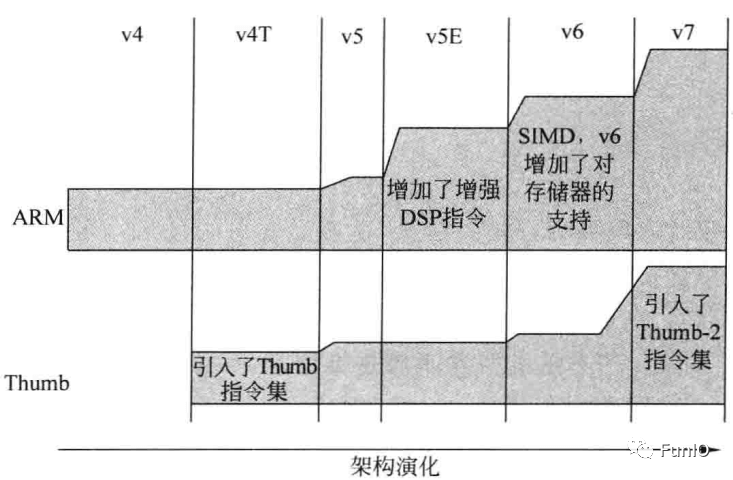
Cortex-M3处理器发布之前,ARM处理器已经有了许多种,比如ARM7、ARM9、ARM11。它们支持两套指令集:32位的ARM指令集和16位的Thumb指令集。
目前Cortex处理器系列包括三类:
- Cortex-A用于高性能的开发应用平台。
- Cortex-R用于需要实时性能的高端嵌入式系统。
- Cortex-M用于嵌入式微控制器系统 。
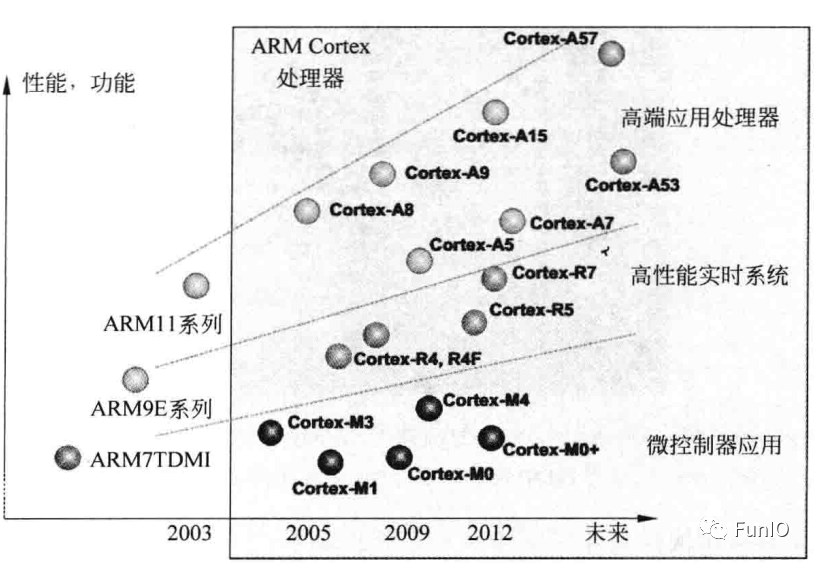
- Cortex-A :需要处理高端嵌入式系统(OS,如iOS、Android、Linux以及Windows)等复杂应用的应用处理器,需要强大的处理能力、支持存储器管理单元(MMU)等虚拟存储器系统、可选的增强Java支持和安全的程序运行环境。实际产品包括高端智能手机、平板电脑、电视以及服务器等。
- Cortex-R :实时、高性能的处理器,面向较高端的实时市场,其应用包括硬盘控制器、移动通信的基带控制器以及汽车系统。强大的处理能力和高可靠性非常关键,低中断等待和确定性也非常重要。
- Cortex-M :面向微控制器和混合信号设计等小型应用,注重低成本、低功耗、耗能效率和低中断等。
1.5、Thumb ISA的架构版本
2、软件开发流程

3、技术综述
3.1、Cortex-M3和M4处理器一般信息
3.1.1 处理器类型
Cortex-M3和M4为32位RISC(精简指令集)处理器,其具有:
- 32位寄存器
- 32位内部数据通路
- 32位总线接口
Cortex-M3和M4具有三级流水线,基于哈佛总线架构(另一个是普林斯顿架构),取指和数据访问可以同时执行。存储器系统使用32位寻址,地址最大空间是4GB。存储器空间包括程序代码、数据、外设以及处理器内部的调试支持部件。
Cortex-M刺激器基于一种加载—存储架构。比如要增加SRAM中存储的数据值,处理器需要一条指令从SRAM中读出数据,将其放到处理器的寄存器中,然后使用第二条指令增加寄存器中的值,最后使用第三条指令将其写回存储器。
3.1.2 指令集
Cortex-M处理器使用的指令集为Thumb-2,它运行16位和32位指令的混合使用,以获得更高的代码密度和效率。
经典的ARM处理器(比如ARM7)具有两种操作状态:32位的ARM状态和16位的Thumb状态。在ARM状态,指令是32位的,内核能够以很高的性能执行所有支持的指令;而对于Thumb状态,指令是16位的,可以得到很好地代码密度,bugThumb指令不具有ARM指令所有功能,要完成特定的操作可能需要更多的指令。如下图。对于经典的ARM处理器,中断处理会进入ARM状态。
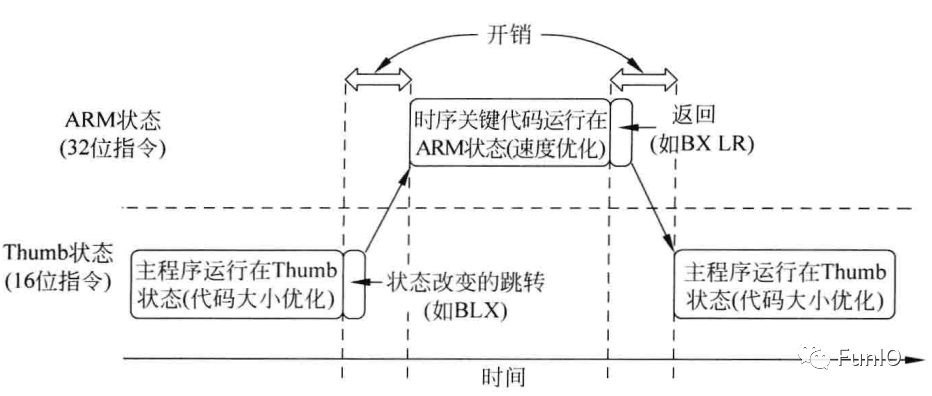
随着Thumb-2技术的引入,Thumb指令被扩展为支持16位和32位两种解码方式,无需在两个不同操作状态切换就可以满足所有的处理需求。
3.1.3 模块框图
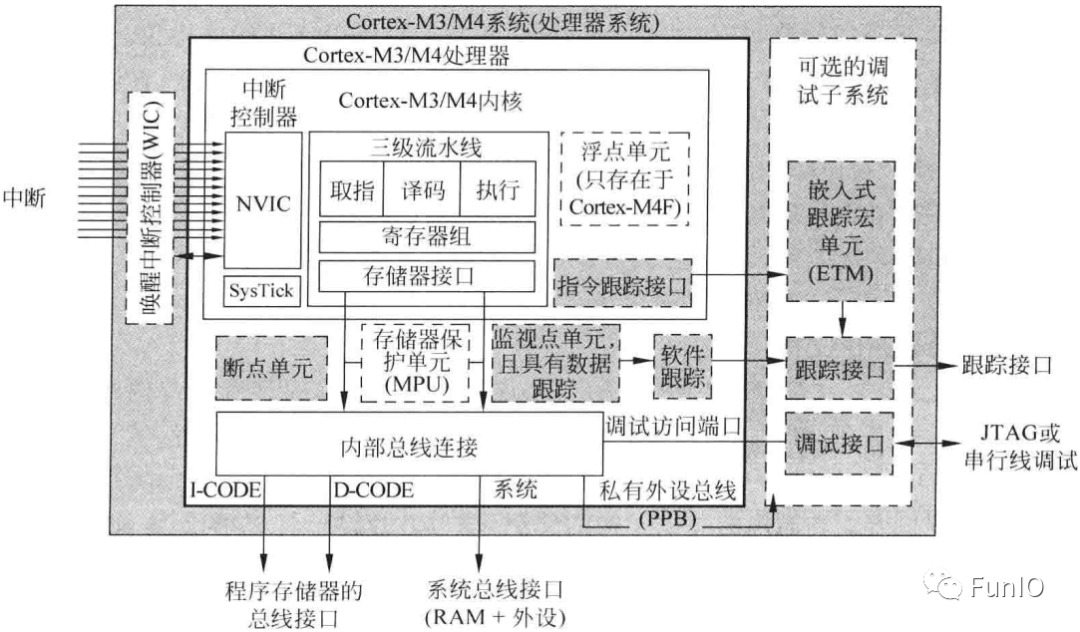
3.1.4 存储器系统
Cortex-M3和M4处理器本身不包含存储器,它们具有通用的片上总线接口,供应商可以将它们自己的存储器系统添加到系统中。如下部件:
- 程序存储器,一般是Flash
- 数据存储器,一般是SRAM
- 外设
Cortex-M3和M4处理器主要使用的总线接口协议是AHB Lite(高级高性能总线),用于程序存储器和系统总线接口。高级外设总线(APB)接口为处理器使用的另外一种总线协议。
3.1.5 中断和异常支持
Cortex-M3和M4处理器中存在一个嵌套向量中断控制器(NVIC)。它是可编程的且其寄存器经过了存储器映射。它的地址固定,编程模型对于所有的Cortex-M处理器都是一致的。
除了外设和其他外部输入中断,NVIC还支持多个系统异常,包括NMI(不可屏蔽中断)等。供应商决定实际支持的可编程中断优先级的数量。
4、架构
4.1 编程模型
4.1.1 操作模式
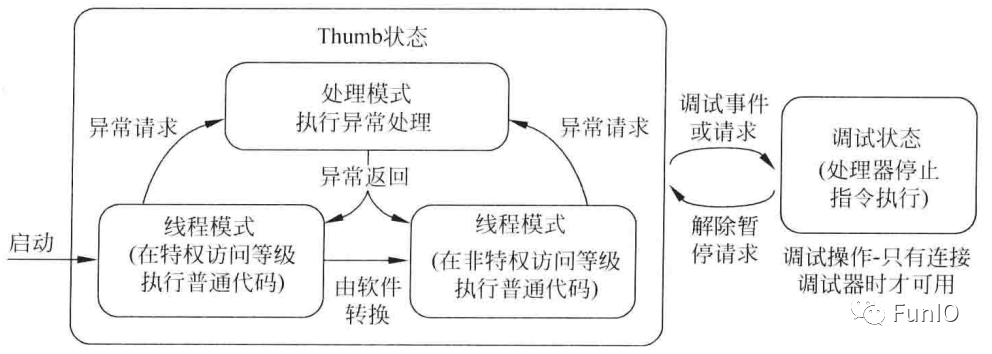
图4.1 操作状态和模式
- 处理模式(Handler):执行ISR等异常处理。此模式下,处理器总是具有特权访问等级。
- 线程模式:在执行普通的应用程序代码时,处理器可以处于特权访问等级,也可处于非特权访问等级。实际的访问等级由特殊寄存器(CONTROL)控制。
软件可以将处理器从特权线程模式切换到非特权线程模式,但无法将自身从非特权切换到特权模式,必须要借助异常机制才可以。
区分特权和非特权访问等级,设计人员可以提供对关键区域访问的保护机制及基本的安全模型,这样有助于开发健壮的嵌入式系统。例如,系统中可能包含运行在特权访问等级的OS内核,以及运行在非特权访问等级的应用程序。还可以通过MPU设置存储器访问权限避免应用任务破坏OS内核以及其他任务使用的存储器和外设。若应用任务崩溃,剩下的任务和OS内核可以继续运行。
几乎所有的NVIC寄存器支持特权访问。
4.1.2 寄存器
寄存器组有16个寄存器,其中13个位32位通用目的寄存器,其他3个有特殊用途,如图:
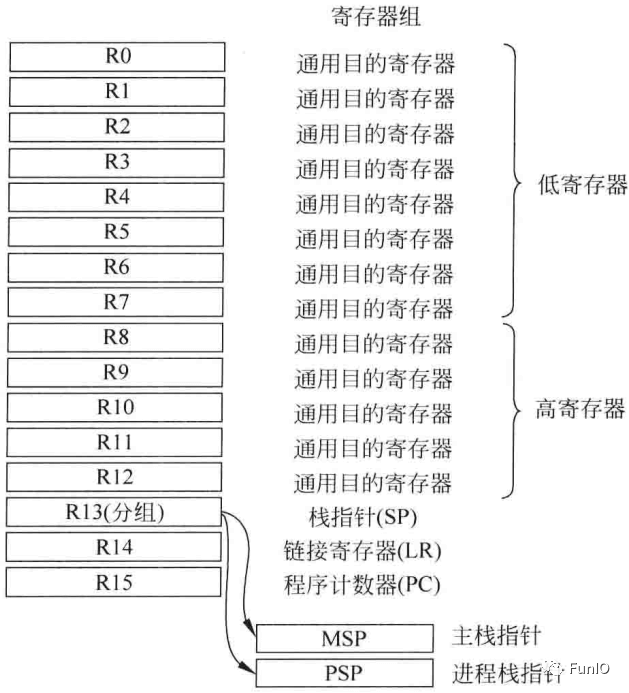
图4.2 寄存器组中的寄存器
- R0 - R12
前8个(R0 - R7)是低寄存器。许多16位指令只能访问低寄存器。高寄存器(R8 - R12)可以用于32位指令和几个16位指令。R0 - R12初始值未定义。 - R13(SP)
R13为栈指针,可通过PUSH和POP指令实现栈存储的访问。存在2个栈指针:主栈指针(MSP)为默认的栈指针,在复位或处理器在处理模式时使用;另一个为进程栈指针(PSP),只能用于线程模式。栈指针的选择由特殊寄存器(CONTROL)决定。MSP和PSP都是32位的,不过栈指针的最低两位总是0。PUSH和POP总是32位的,32位字对齐。 - R14(LR)
R14配称为链接寄存器,用于函数或子程序调用时返回地址的保存。在异常处理器件,LR会自动更新为特殊的EXC_RETURN(异常返回)数值,该值会在异常处理结束时触发异常返回。有些跳转/调用操作需要将LR(或正使用的任何寄存器)的第0位置1表示Thumb状态。 - R15(PC)
R15是程序计数器。
4.1.3 特殊寄存器
除了寄存器组中的寄存器外,处理器还存在多个特殊寄存器,如下图:
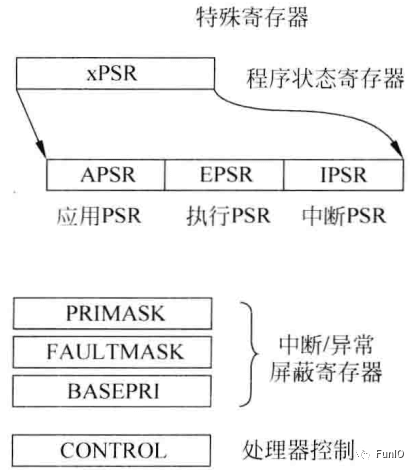
图4.3 特殊功能寄存器
特殊寄存器未经过存储器映射,可以使用MSR和MRS等特殊寄存器访问指令访问。
MRS < reg >, < special_reg > ; 将特殊寄存器读入寄存器
MSR < special_reg >, < reg > ; 写入特殊寄存器
- 程序状态寄存器
程序状态寄存器包括以下三个状态寄存器:
- 应用PSR(APSR)
- 执行PSR(EPSR)
- 中断PSR(IPSR)
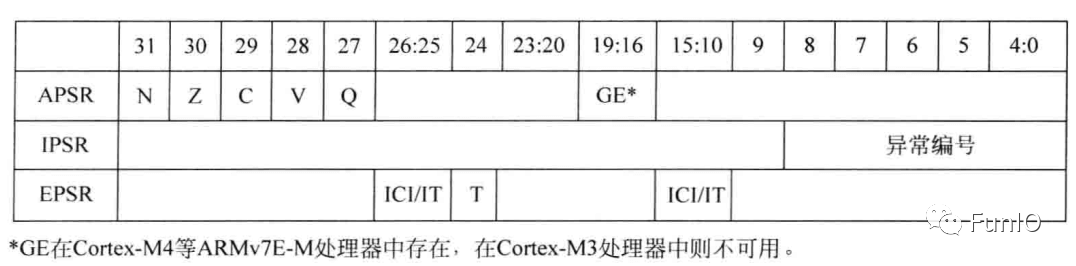
图4.4 APSR、IPSR和EPSR
- PRIMASK、FAULTMASK和BASEPRI寄存器
PRIMASK、FAULTMASK和BASEPRI寄存器都用于异常或中断屏蔽,每个异常都具有一个优先级,数值小的优先级高。这些特殊寄存器可基于优先级屏蔽异常,只有在特权访问等级才可对其访问。这些寄存器编程模型如下:
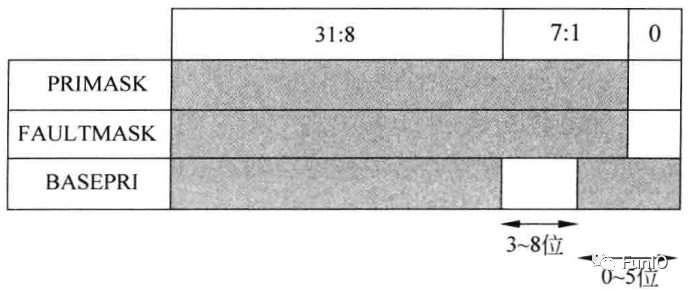
图4.5 PRIMASK、FAULTMASK和PRIMASK寄存器
- PRIMASK置位时,会阻止NMI和HardFault异常之外的所有异常。最常见用途是在时间要求很严格的进程中禁止所有中断,在该进程完成后,需要将其清除重新使能中断。
- FAULTMASK和PRIMASK非常类似,不过它还能屏蔽HardFault异常。错误处理代码可以使用FAULTMASK以免在错误处理期间引发其他错误。FAULTMASK在异常返回自动清除。
- BASEPRI会根据优先级屏蔽中断。它的宽度取决于实际芯片实现的优先级数量,大多数有8个或16个可编程优先级,对应的宽度为3位或4位。BASEPRI为0时不起作用,非0时,会屏蔽具有相同或更低优先级的异常。
CMSIS-Core提供了多个C函数可以访问它们。
x = _get_BASEPRI(); // 读BASEPRI寄存器
x = _get_PRIMASK(); // 读PRIMASK寄存器
x = _get_FAULTMASK(); // 读FAULTMASK寄存器
_set_BASEPRI(x); // 设置BASEPRI寄存器的新值
_set_PRIMASK(x); // 设置PRIMASK寄存器的新值
_set_FAULTMASK(x); // 设置FAULTMASK寄存器的新值
_disable_irq(); // 设置PRIMASK,禁止IRQ
_ensable_irq(); // 清除PRIMASK,使能IRQ
还可以用汇编代码访问这些异常屏蔽寄存器:
MRS r0, BASEPRI; 将BASEPRI寄存器读入 R0
MRS r0, PRIMASK; 将PRIMASK寄存器读入 R0
MRS r0, FAULTMASK; 将FAULTMASK寄存器读入 R0
MRS BASEPRI, r0 ; 将R0 写入 BASEPRI寄存器
MRS PRIMASK, r0 ; 将R0 写入 PRIMASK寄存器
MRS FAULTMASK, r0 ; 将R0 写入 FAULTMASK寄存器
另外,还可以利用修改处理器状态(CPS)指令:
CPSIE i ;使能中断(清除PRIMASK)
CPSID i ;禁止中断(设置PRIMASK)
CPSIE f ;使能中断(清除FAULTMASK)
CPSID f ;禁止中断(设置FAULTMASK)
- CONTROL寄存器
CONTROL寄存器(如下图)定义了:
- 栈指针的选择(MSP/PSP)
- 线程模式的访问等级(特权/非特权)
CONTROL寄存器只能在特权访问等级修改,读操作在特权和非特权都可以。
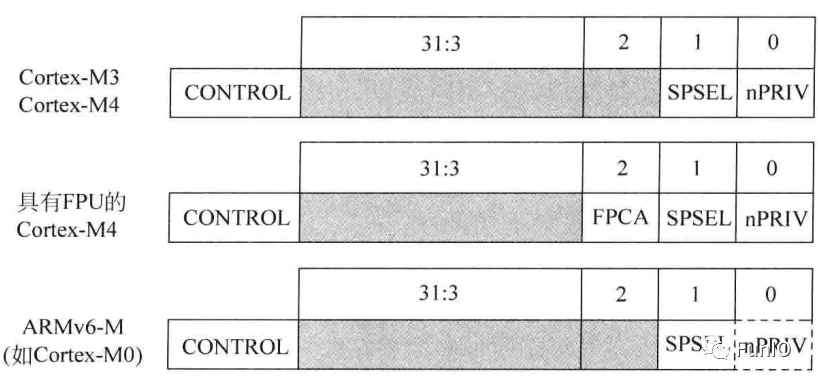
图4.6 Cortex-M3、Cortex-M4和具有FPU的Cortex-M4中的CONTROL寄存器
表4.1 CONTROL寄存器中的位域

复位后,CONTROL寄存器默认为0,意味着此时处理器处于特权访问权限的线程模式并使用MSP。通过写CONTROL寄存器,特权线程模式的程序可以切换栈指针或进入非特权访问等级。不过nPRIV置位后,运行在线程模式的程序不能访问CONTROL寄存器了。即运行在非特权等级的程序无法切换回特权等级,这就提供了一个基本的安全模型;若有必要将处理器在线程模式切换回特权等级,则需要异常机制。在异常处理期间清除nPRIV位,回到线程模式后,处理器就会进入特权等级。
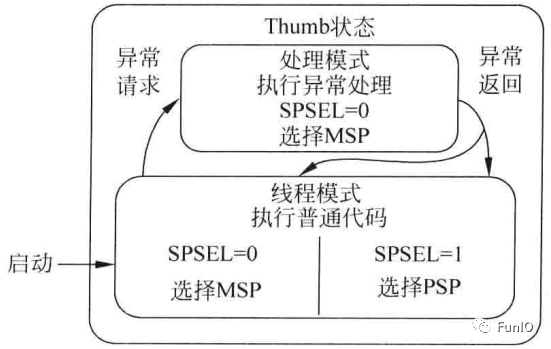
图4.7 栈指针选择
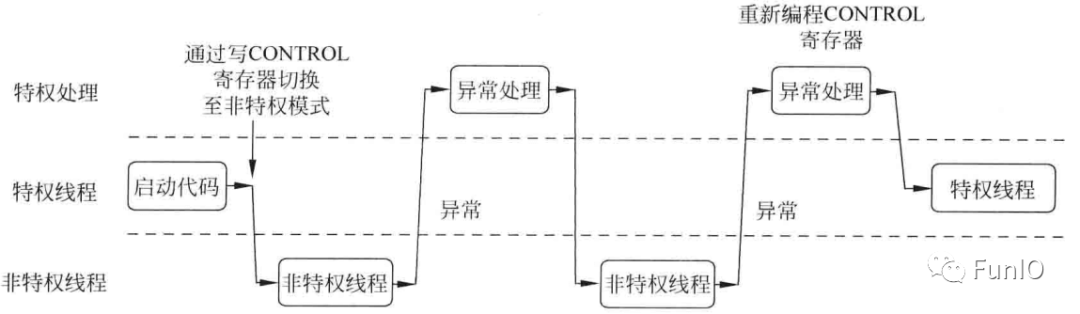
图4.8 特权线程模式和非特权线程模式间的切换
4.1.4 浮点寄存器
Cortex-M4有可选的浮点单元,提供了浮点数据处理用的一些寄存器以及浮点状态和控制寄存器(FPSCR)
- S0 - S31和D0 - D15
- 浮点状态和控制寄存器(FPSCR)
4.2 存储器系统
4.2.1 存储器映射
Cortex-M处理器的4GB地址空间被划分了多个存储器区域,如下图。区域根据各自用法划分,主要用于:
- 程序代码访问(如CODE区域)
- 数据访问(如SRAM区域)
- 外设(如外设区域)
- 处理器的内部控制和调试部件(如私有外设总线)
架构的这种安排具有很大的灵活性,存储器区域可用于其他目的。例如,程序即可以在CODE区域执行,也可以在SRAM区域执行,而且微控制器也可以在CODE区域加入SRAM。
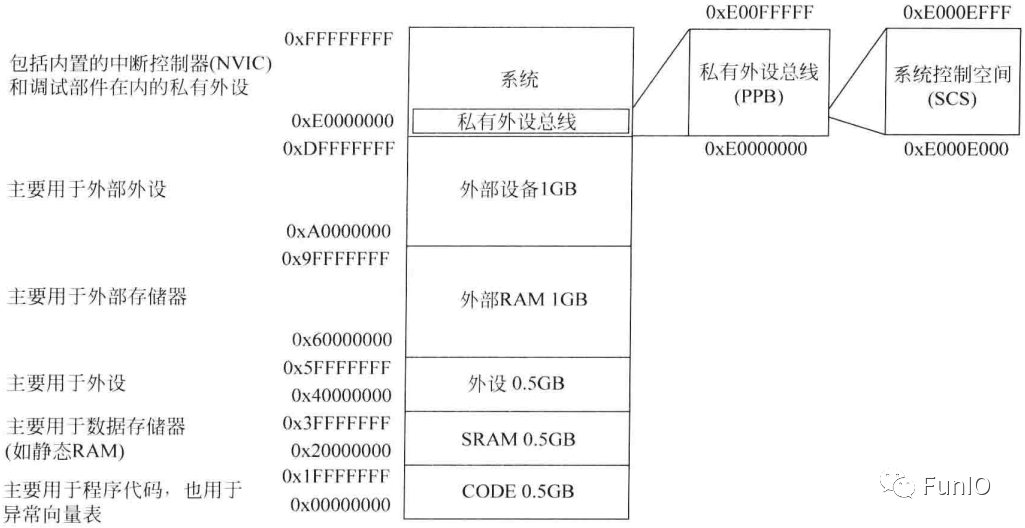
图4.9 存储器映射
4.2.2 栈存储
在栈这种存储器机制中,存储器的一部分可被用作后进先出的数据存储缓冲。ARM处理器将系统主存储器用于栈空间操作,使用PUSH和POP。每次PUSH和POP操作后,栈指针会自动调整。
栈可用于:
- 当正在执行的函数需要使用寄存器进行数据处理时,临时存储数据的初始值。这些数据在函数结束时可恢复回去
- 往函数或子程序传递信息,即函数调用的参数传递
- 用于存储局部变量
- 在中断等异常产生时保存处理器状态和寄存器数值
Cortex-M处理器使用的栈模型是“满递减”。处理器启动后,SP被设置为栈存储空间最后的位置。每次PUSH操作,处理器先减小SP的值,然后将数据存储在SP指向的存储器位置。对于POP操作,SP指向的存储器位置数据被读出,然后SP的值自动减小。
PUSH和POP指令最常见的用法是,在执行函数调用时保存寄存器组中的内容,函数调用结束时通过POP恢复它们的值。
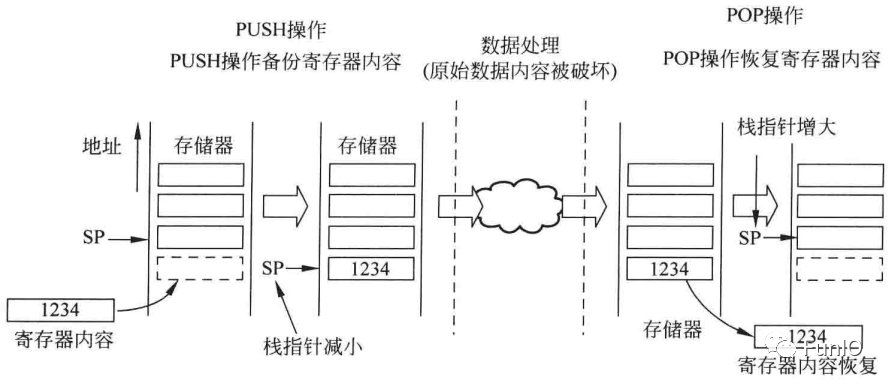
图4.10 栈的PUSH和POP
若嵌入式系统中包含OS,通常会将应用任务和内核所用的栈空间分离开来,因此PSP会被用到,在异常入口和出口时会发生SP切换,如下图。
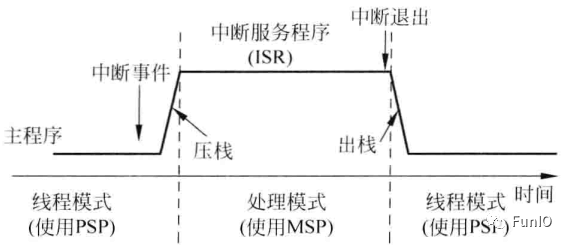
图4.11 SPSEL=1,线程等级使用进程栈而异常处理使用主栈
尽管同一时间内只有一个SP可见,如果当前处于特权等级,可以用PSR和MRS指令访问隐藏的SP。
4.3 异常和中断
4.3.1 什么是异常
Cortex-M处理器有多个异常源,如图:
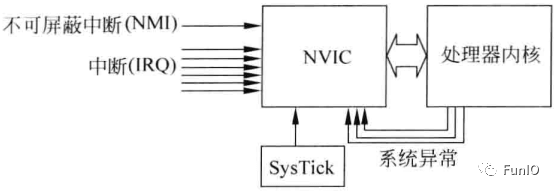
图4.12 各种异常源
- NVIC处理异常 。NVIC可以处理多个中断请求(IRQ)和一个不可屏蔽中断(NMI)请求,IRQ一般由片上外设或外部中断输入通过I/O端口产生,NMI可用于看门狗或掉电检测。处理器内部有个名为SysTick的定时器,可以产生周期性的定时中断请求,可用于OS计时。
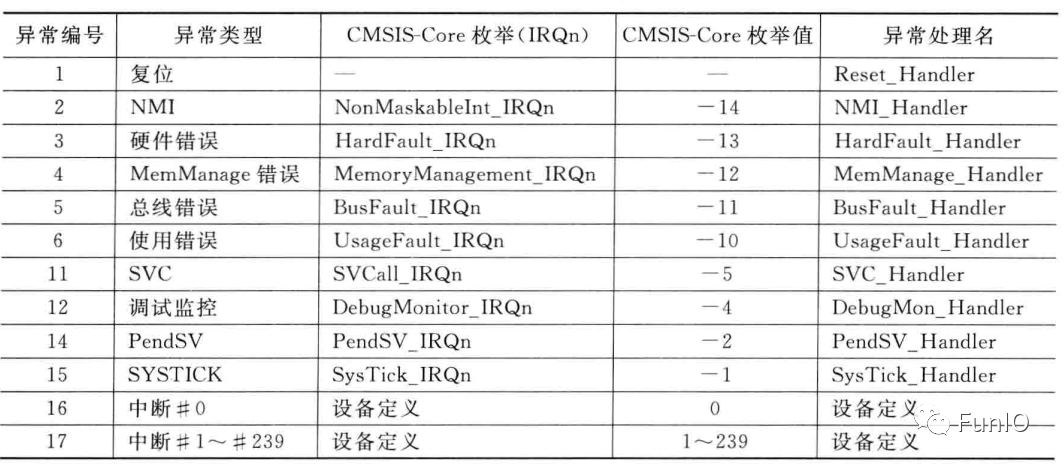
- 处理器自身也是一个异常事件源,包括表示系统错误状态的错误事件以及软件产生、支持OS操作的异常。异常类型如下表:
表4.2 异常类型
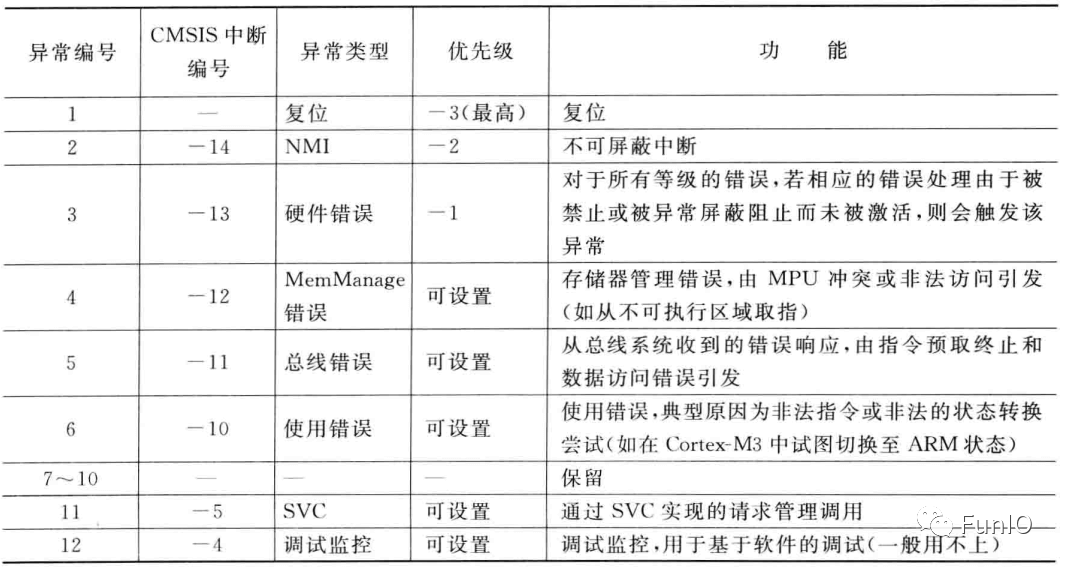

每个异常源都有一个异常编号,编号1-15为系统异常,16及其之上的则用于中断。Cortex-M4和M4在设计上最多240个中断输入,不过实际实现的中断数量要小得多,一般在16-100之间。
4.3.2 NVIC
NVIC处理异常和中断配置、优先级以及中断屏蔽。NVIC具有以下特性:
- 灵活的异常和中断管理
- 支持嵌套异常/中断
- 向量化的异常/中断入口
- 中断屏蔽
4.3.3 向量表
当异常事件产生且被处理器内核接受后,相应的异常处理就会执行。向量表是可以重定位的,由NVIC中的名为向量表偏移寄存器(VTOR)控制。复位后默认为0,向量表则位于地址0x0处。
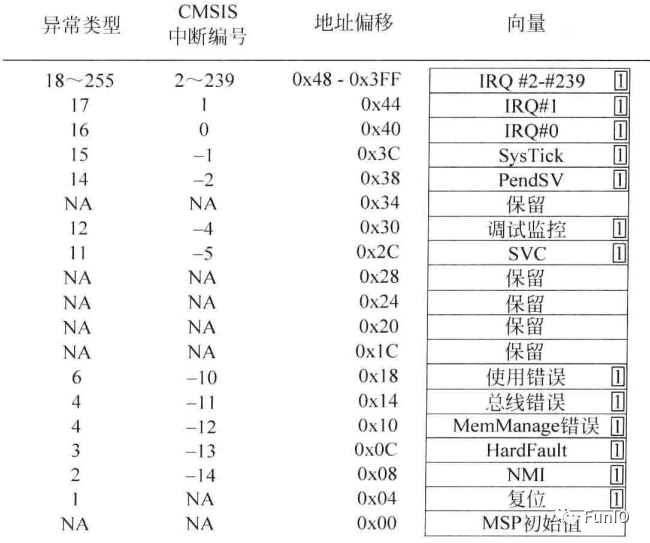
图4.13 异常类型(异常向量的最低位应该置1,表示Thumb状态)
4.3.4 错误处理
Cortex-M3和M4处理器中有几个异常为错误处理异常。处理器检测到错误时,触发错误异常,错误包括执行未定义的指令以及总线错误、对存储器访问返回错误等。
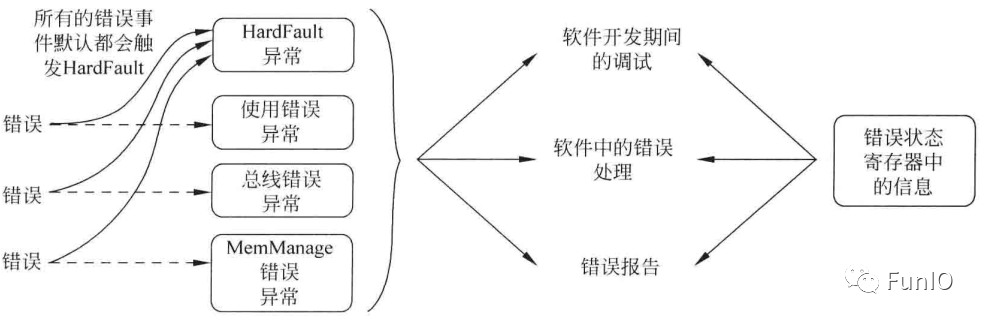
图4.14 错误异常的使用
总线错误、使用错误以及存储器管理错误默认是禁止的,且所有的错误事件都会触发HardFault异常(总是使能)。但这些配置是可编程的。
4.4 复位和复位流程
对于典型的Cortex-M处理器,复位类型由三种:
- 上电复位。复位微控制器的所有部分,包括处理器、调试支持部件和外设等。
- 系统复位。只会复位处理器和外设,不包括调试支持部件。
- 处理器复位。只复位处理器
在复位后以及处理器开始执行程序之前,Cortex-M处理器会从存储器中读出头两个字,如下图。向量表位于存储器的开头部分,它的头两个字为MSP的初始值和代表复位除了起始地址的复位向量。处理器读出这两个字会将其赋值给MSP和PC。
MSP的设置非常必要。因为在复位的很多时间内有产生NMI或HardFault的可能,在异常处理前将处理器状态压栈时需要栈存储和MSP。
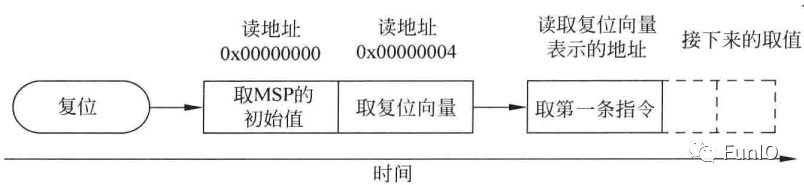
图4.15 复位流程

图4.16 栈指针初始值和程序计数器初始值示例
5 存储器系统
5.1 存储器映射
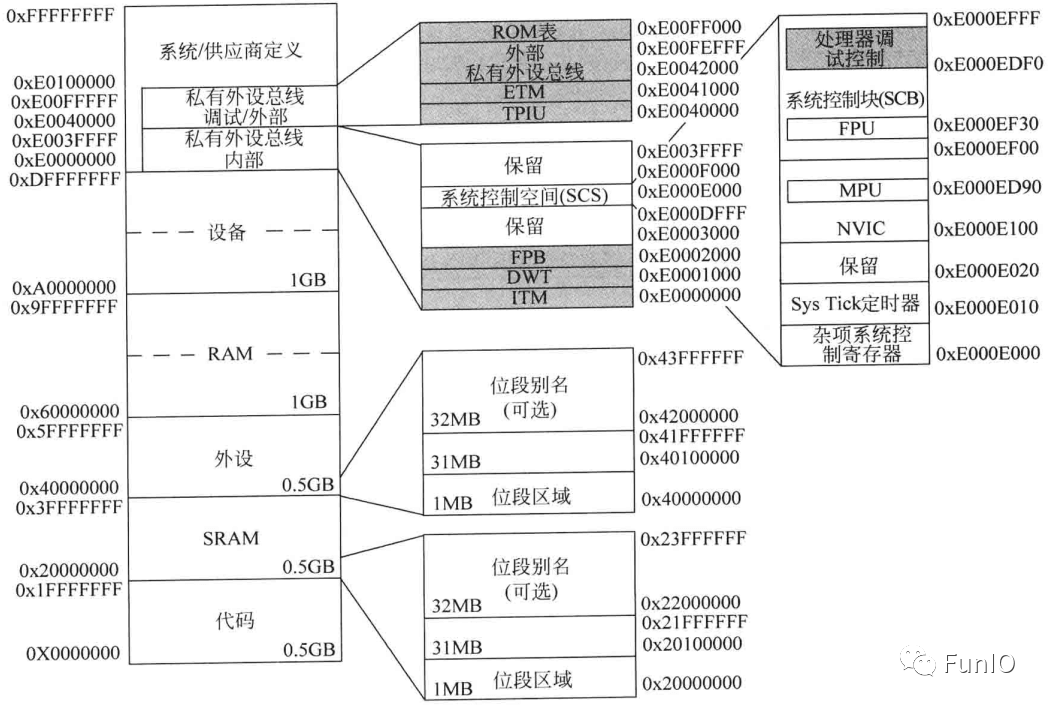
图5.1 Cortex-M3和Cortex-M4处理器预定义的存储器映射(阴影部分的部件用于调试)
5.2 连接处理器到存储器和外设
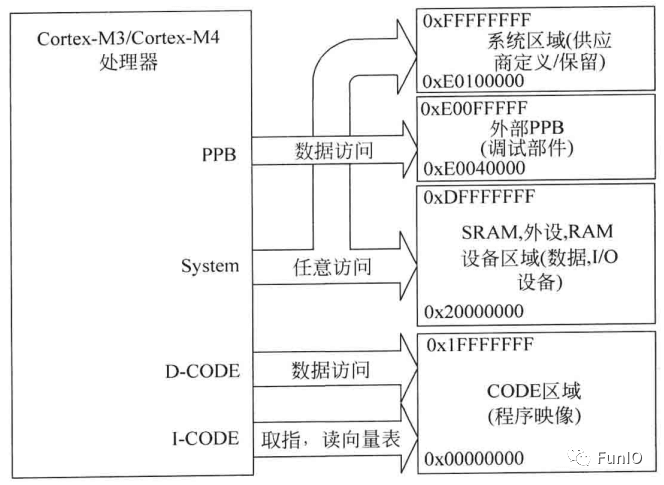
图5.2 不同存储区域的多个总线接口
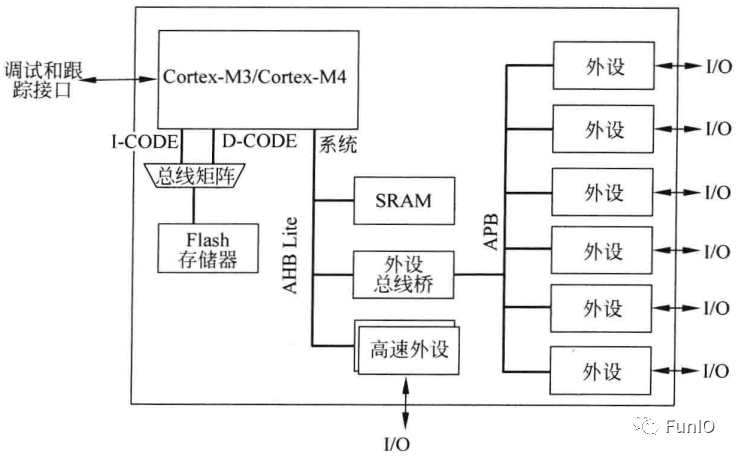
图5.3 基于Cortex-M3或Cortex-M4的简单系统
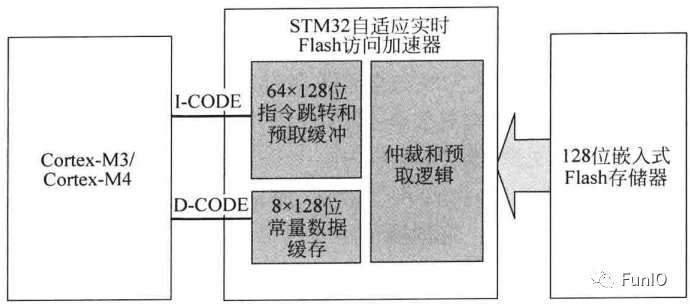
图5.4 STM32F4的Flash访问加速器示意图
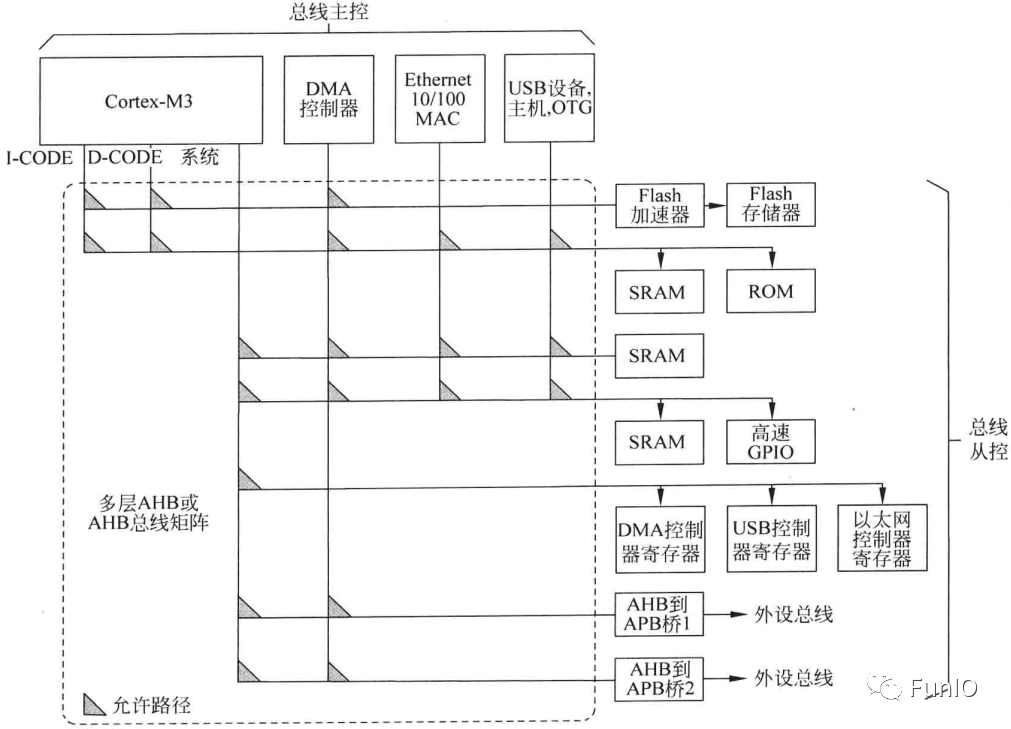
图5.5 多层AHB示例(NXP LPC1700)
5.3 位段操作
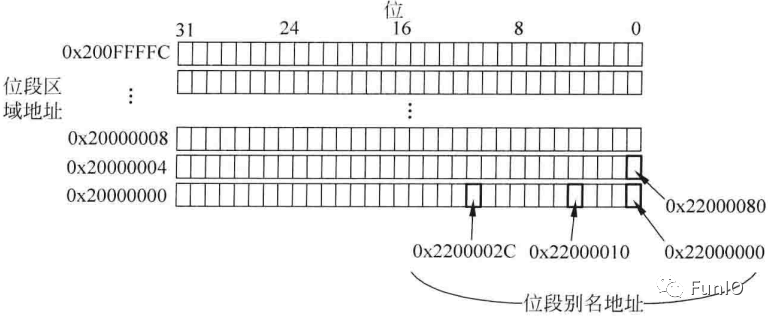
图5.6 通过位段别名对位段区域进行位访问(SRAM区域)
5.4 存储器屏障
存储器屏障指令ISB、DSB、DMB
5.5 微控制器中的存储器系统
许多微控制器设备,设计中还集成了其他存储器系统特性。例如:
- BootLoader
- 存储器重映射
- 存储器别名
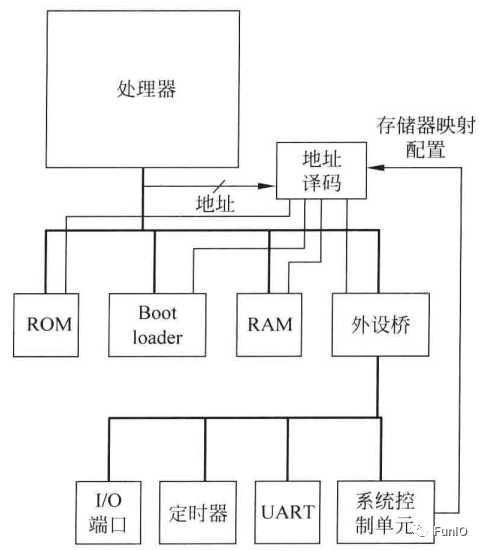
图5.7 具有可配置存储器映射的简单存储器系统
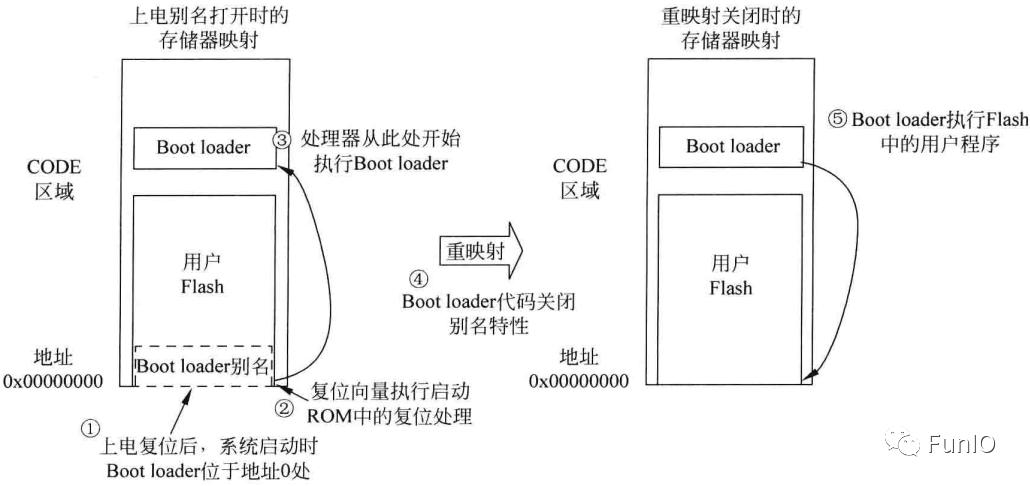
图5.8 具有bootloader的系统的存储器重映射示例
6 异常和中断
6.1 异常和中断简介
典型的Cortex-M4微控制器中,NVIC接收多个中断源产生的中断请求,如图
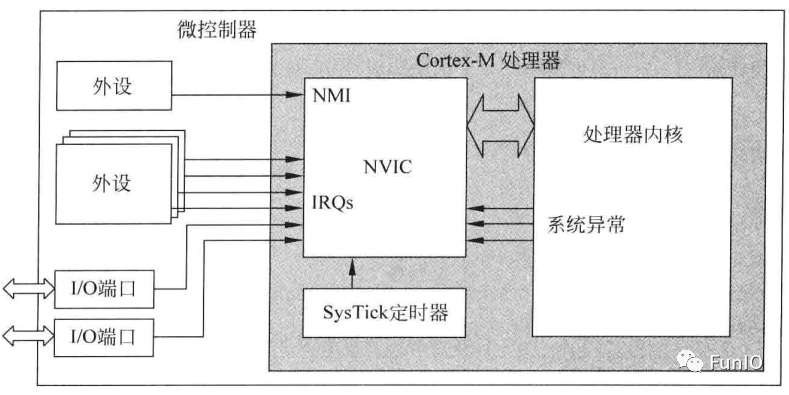
图6.1 典型微控制器中的各种异常源
Cortex-M3和Cortex-M4的NVIC最多支持240个IRQ、1个NMI、1个SysTick及多个系统异常。多数中断由定时器、I/O端口和通信接口(UART、I2C)等外设产生。中断还可利用软件生成。
为了继续执行被中断的程序,异常流程需要利用一些手段保护被中断程序的状态,这样在异常处理完成后还可以恢复。一般这个过程可以由硬件机制实现,也可以由硬件和软件操作共同完成。对于Cortex-M4处理器,当异常被接受后,有些寄存器被字段保存到栈中,返回时自动恢复。
6.2 异常类型
编号1-15的为系统异常,16及以上为中断输入。包括中断在内的多数异常,具有可编程的优先级,一些系统异常则有固定的优先级。
不同的Cortex-M4微控制器的中断源编号(1-240)可能会不同,优先级也可能有差异。
异常类型1-15为系统异常,如表7.1。类型16及以上为外部中断输入,如表7.2。
表6.1 系统异常列表
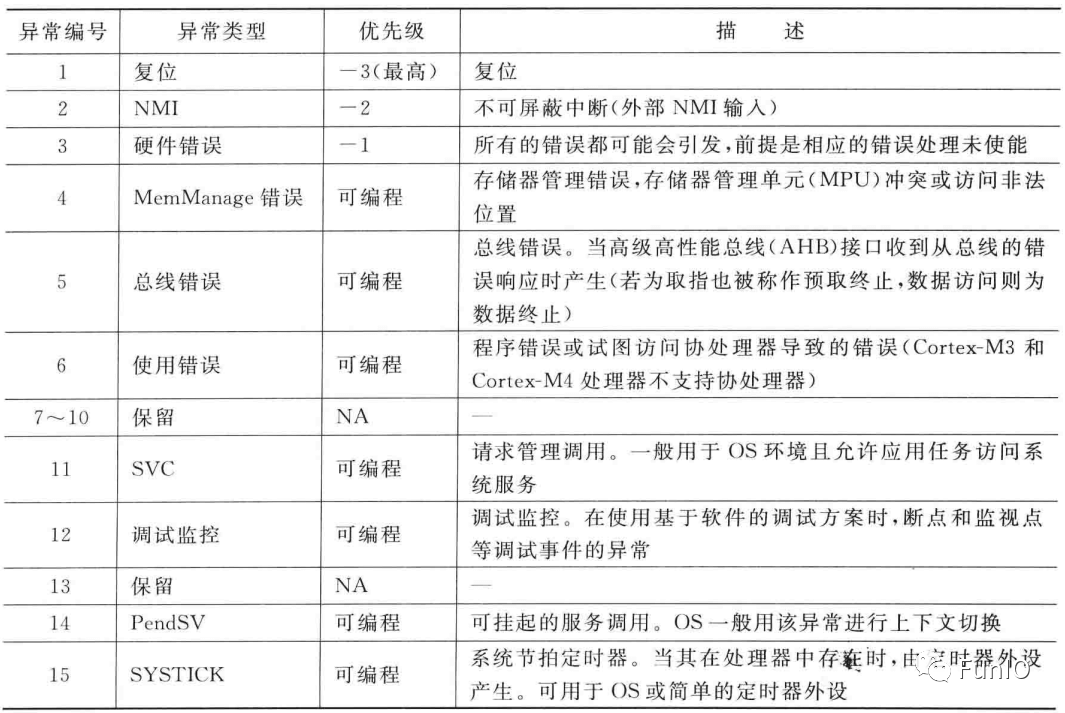
表6.2 中断列表

CMSIS-Core定义了系统异常处理的名称
表6.3 CMSIS-Core异常定义
优先级的优先级配置寄存器可被分为两部分。上半部分(左边的位)为抢占优先级,下半部分(右边的位)为子优先级,如下
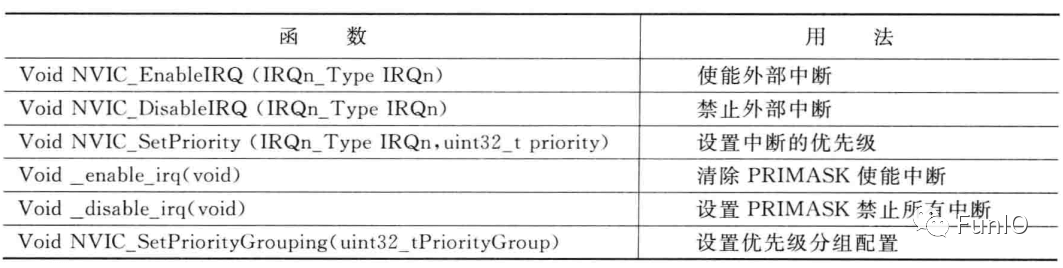
表6.4 常用的基本中断控制CMSIS-Core函数
6.4 优先级定义
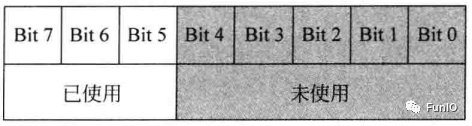
图6.2 3位优先级寄存器(8个可编程优先级)
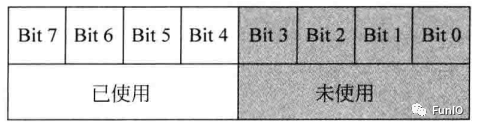
图6.3 4位优先级寄存器(16个可编程优先级)
8位寄存器被分为两个部分:抢占优先级和子优先级。利用系统控制块(SCB)中的一个名为优先级分组的配置寄存器,每个具有可编程优先级的优先级配置寄存器可被分为两部分。上半部分(左边的位)为抢占优先级,下半部分(右边的位)为子优先级,如下
表6.5 不同优先级分组下优先级寄存器中的抢占优先级和子优先级域定义
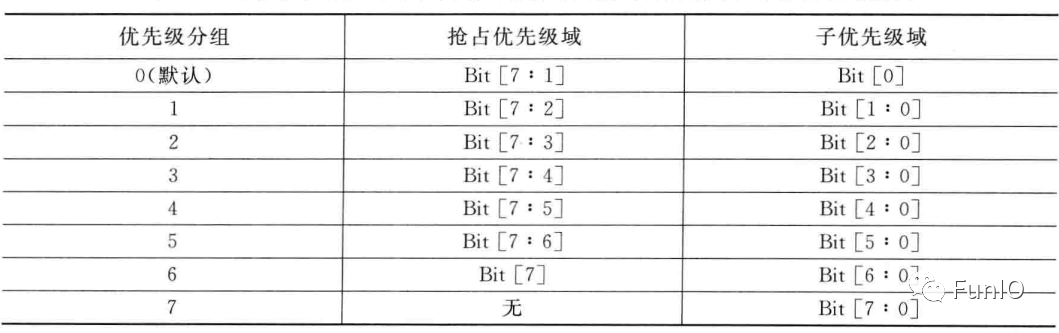
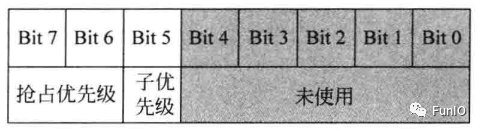
图6.4 3位优先级寄存器中优先级分组为5时的域定义
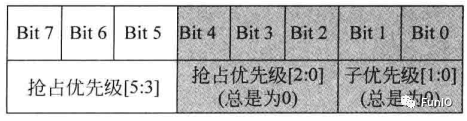
图6.5 3位优先级寄存器中优先级分组为1时的域定义

图6.6 8位优先级寄存器中优先级分组为0时的域定义
6.5 向量表和向量表重定位
当Cortex-M处理器接受某异常请求后,处理器要确定该异常处理的起始地址。该信息位于存储器内的向量表中,默认从地址0开始,向量地址则为异常编号乘4,如图

图6.7 向量表
7 深入了解异常处理
7.1 C实现的异常处理
对于Cortex-M处理器,可以将异常处理或ISR实现为普通的C函数。为了详细了解这种机制,看一下C函数在ARM架构上如何工作。
用于ARM架构的C编译器遵循ARM的一个名为AAPCS(ARM架构过程调用标准)的规范。根据这份标准,C函数可以修改R0-R3、R12、R14以及PSR。若C函数需要调用R4-R11,应该将这些寄存器保存到栈中,且在函数结束前将他们恢复,如图。
R0-R3、R12、R14以及PSR被称为“调用者保存寄存器”。R4-R11被称为“被调用者保存寄存器”,被调用的子程序或函数需要确保这些寄存器在函数结束时不会发送变化。这些寄存器的值可能会在函数执行过程中变化,不过需要在函数退出前将他们恢复。一般,函数调用R0-R3作为输入参数,R0用作返回结果。若返回值是64位,则R1也会用于返回结果。
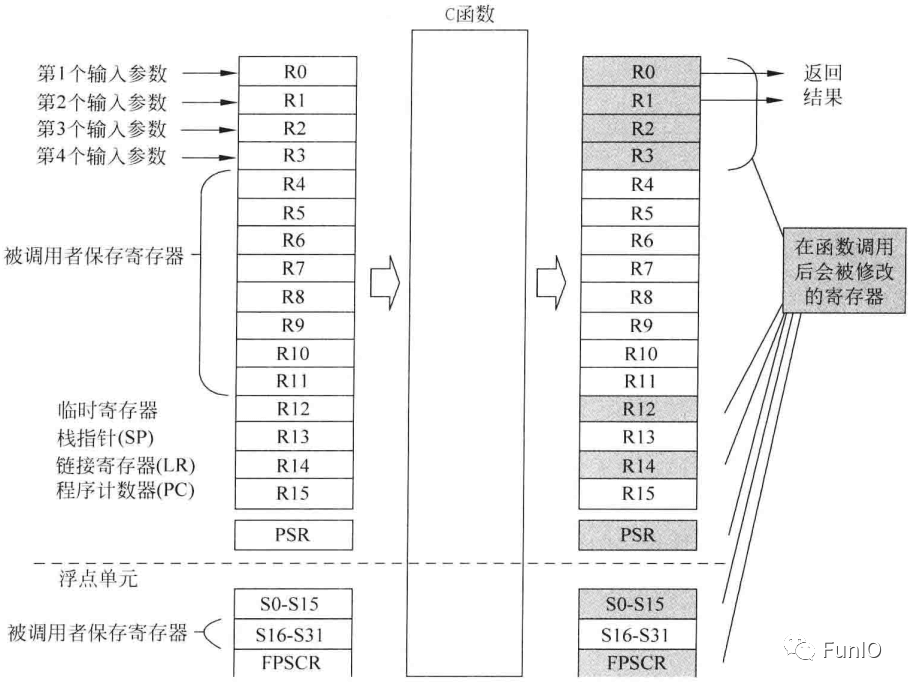
图7.1 AAPCS规定的函数调用中的寄存器使用
要使C函数可以用作异常处理,异常机制需要在异常入口处自动保存R0-R3、R12、R14以及PSR,并在异常退出时将他们恢复,这些要由刺激器硬件控制。
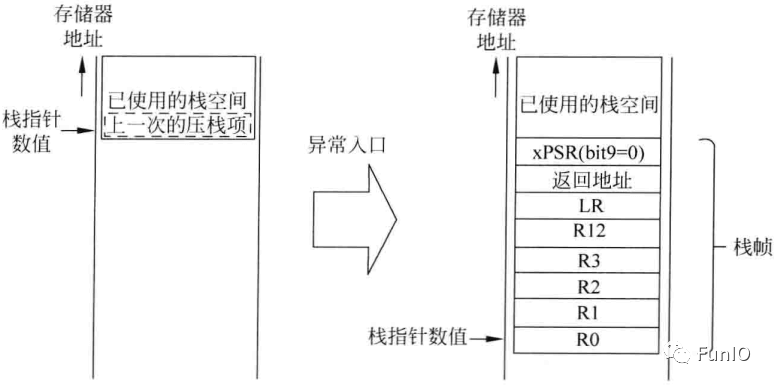
图7.2 在不需要或禁止双字栈对齐时,Cortex-M3或Cortex-M4(无浮点)处理器的异常栈帧
7.1.1 EXC_RETURN
处理器进入异常处理或ISR时,LR的值会被更新为EXC_RETURN的值。当利用BX、POP或存储器加载指令(LDR或LDM)被加载到PC中时,该数值用于触发异常返回机制。
表7.1 EXC_RETURN的位域
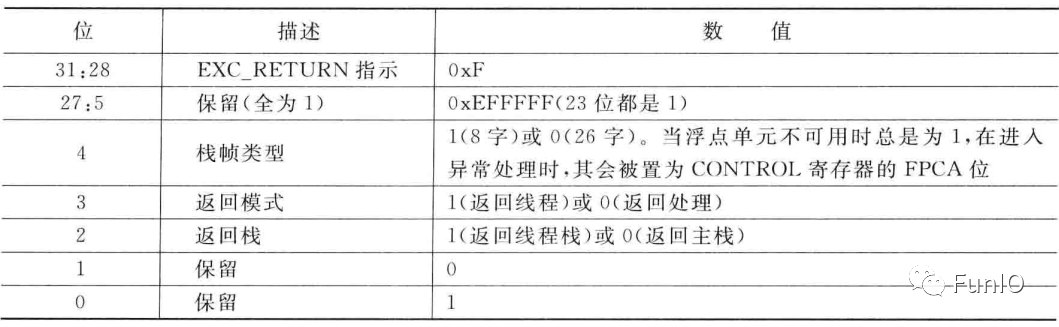
表7.2 EXC_RETURN的合法值

7.2 异常流程
7.2.1 异常进入和压栈
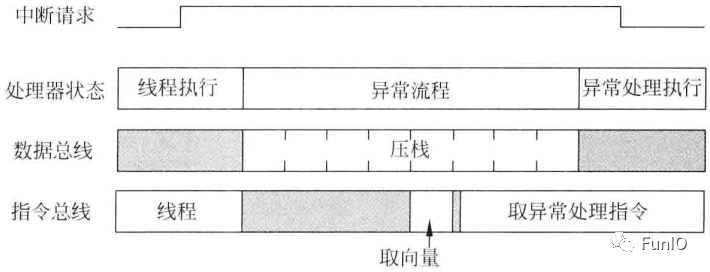
图7.3 压栈和取向量

图7.4 Cortex-M3处理器的AHB Lite总线上的压栈流程
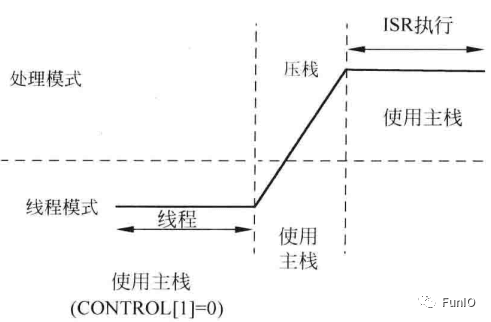
图7.5 使用主栈的线程模式的异常栈帧
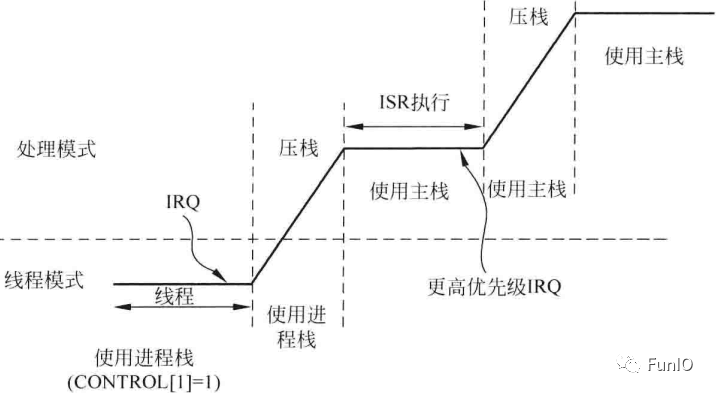
图7.6 使用进程栈的线程模式的异常栈帧,以及使用主栈的嵌套中断压栈
7.2.2 异常返回和出栈
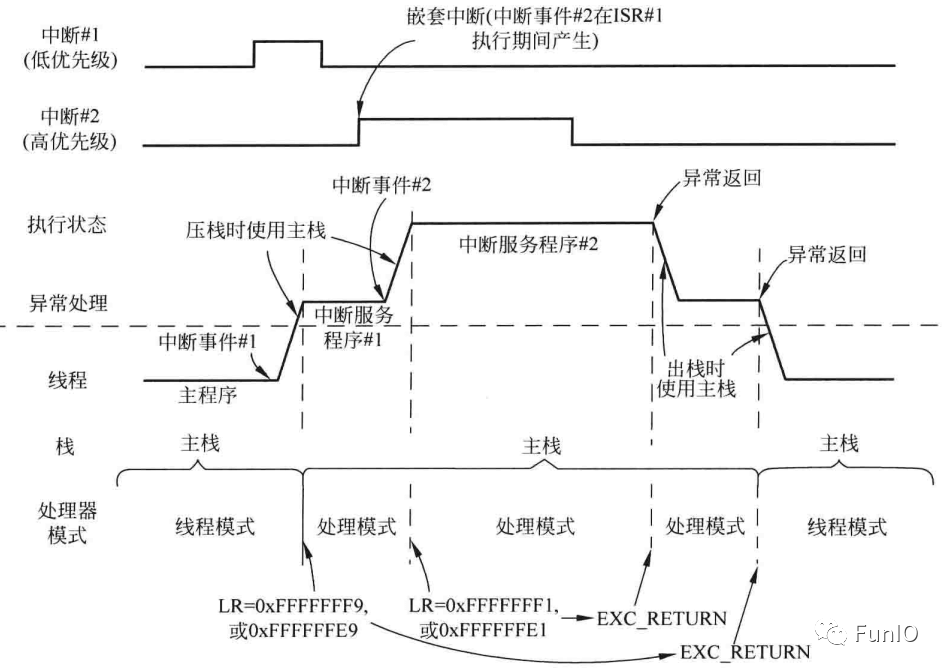
图7.7 LR在异常时被设置为EXC_RETURN(线程模式使用主栈)
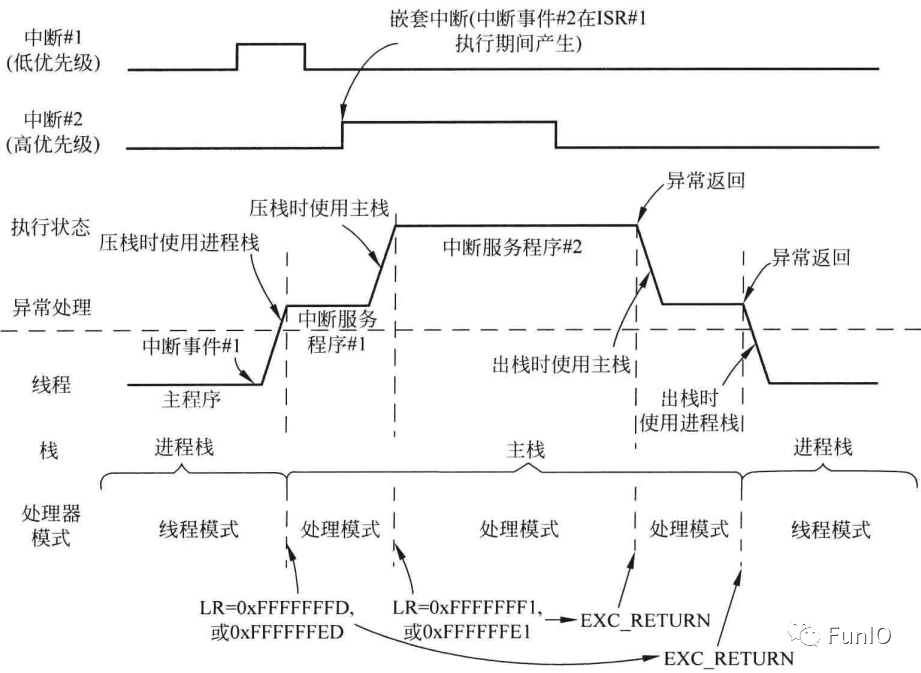
图7.8 LR在异常时被设置为EXC_RETURN(线程模式使用进程栈)
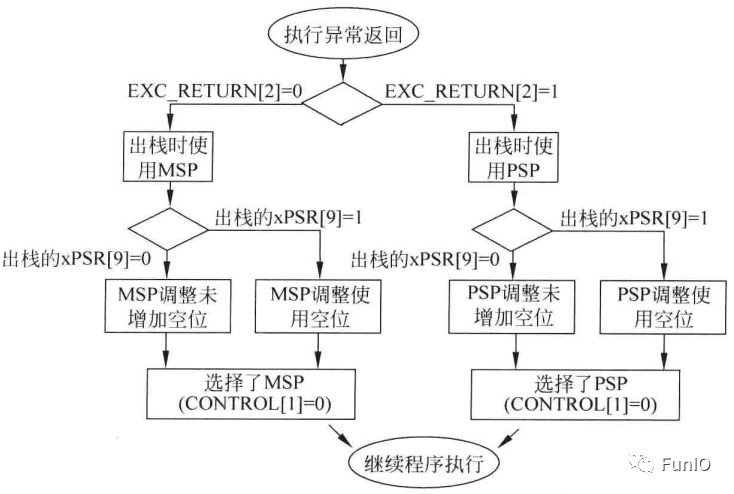
图7.9 出栈操作
7.3 中断等待和异常处理优化
7.3.1 什么是中断等待
7.3.2 末尾连锁
若某个异常产生时处理器正在处理另一个具有相同或更高优先级的异常,该异常会进入挂起状态。在处理器执行完当前的异常处理后,它可以继续执行挂起的异常/中断请求。处理器不会从栈中恢复寄存器(出栈)然后在将它们存入栈中(压栈),而是跳过出栈和压栈过程并尽快进入挂起异常的中断处理,如图。对于无状态等待的存储器系统,末尾连锁的中断等待时间仅为6个时钟周期。
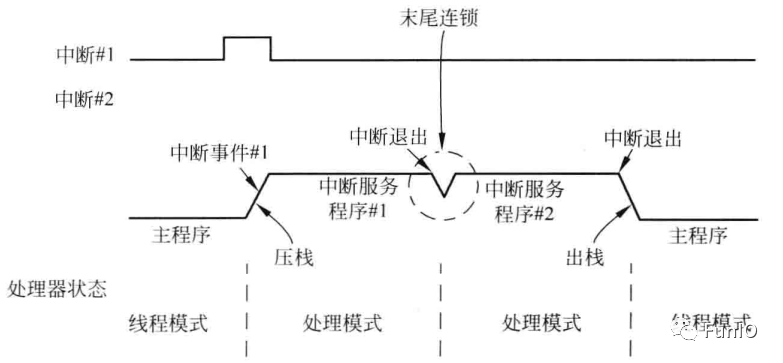
图7.10 末尾连锁
7.3.3 延迟到达
当异常产生时,处理器会接受异常请求并开始压栈操作。若压栈期间产生了另外一个更高优先级的异常,则更高优先级的后到异常会先得到服务。
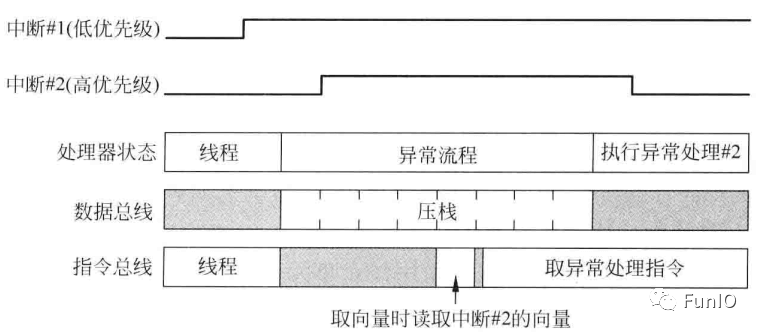
图7.11 延迟到达异常行为
7.3.4 出栈抢占
若某个异常请求在另外一个刚完成的异常处理出栈期间产生,则处理器会舍弃出栈操作且开始取向量以及下一个异常服务的命令。该优化成为出栈抢占。
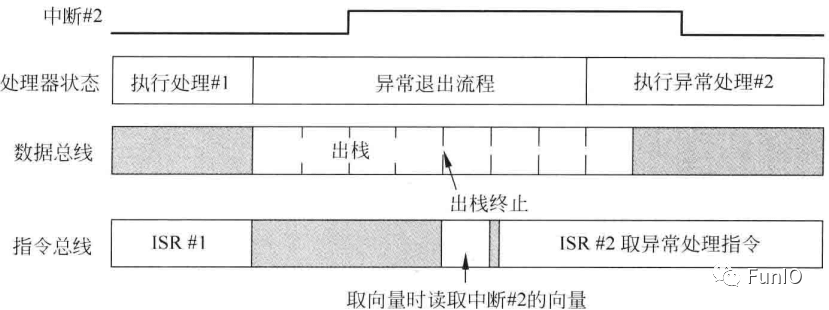
图7.12 出栈抢占行为
7.3.5 惰性压栈
惰性压栈是和浮点单元寄存器压栈相关的一种特性。
8 OS支持特性
8.1 影子栈指针
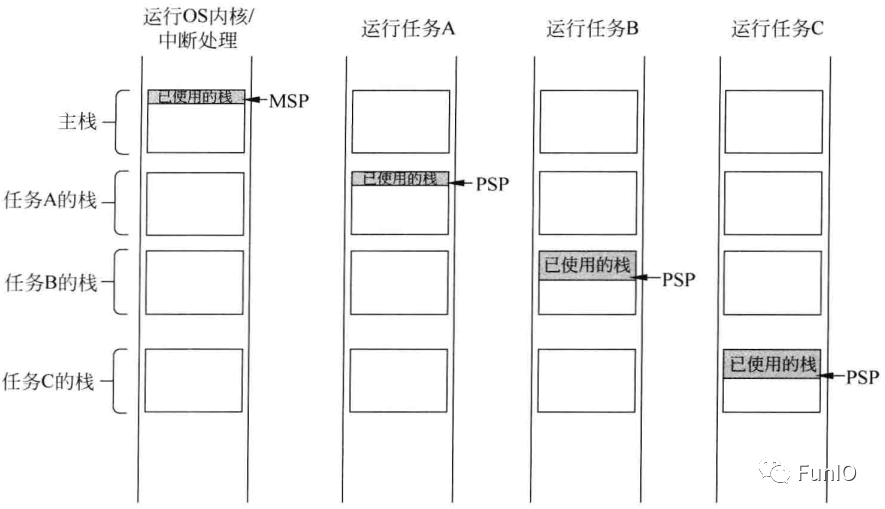
图8.1 每个任务的栈和其他的相独立
8.2 SVC异常
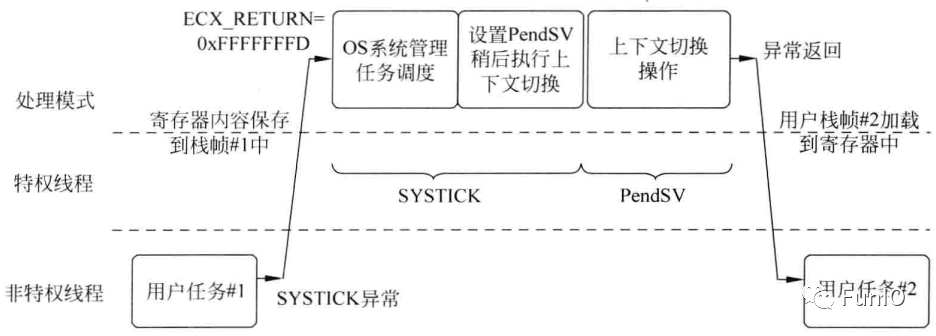
图8.2 上下文切换简图
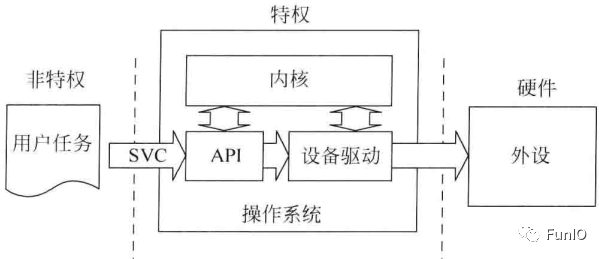
图8.3 SVC可作为OS系统服务的入口
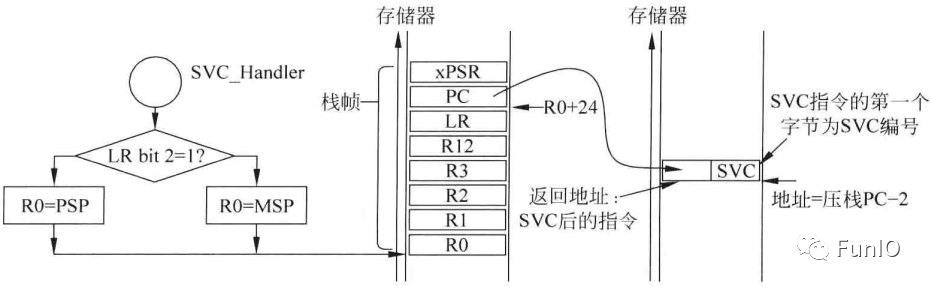
图8.4 利用汇编语言提取SVC服务编号
8.3 PendSV异常

图8.5 PendSV上下文切换示例
- 第一部分对时间要求比较高,需要快速执行,切优先级较高。它位域普通的ISR内,在ISR结束时,PendSV的挂起状态
- 第二部分包括中断服务所需的剩余处理工作,它位于PendSV处理内切具有较低的异常优先级。
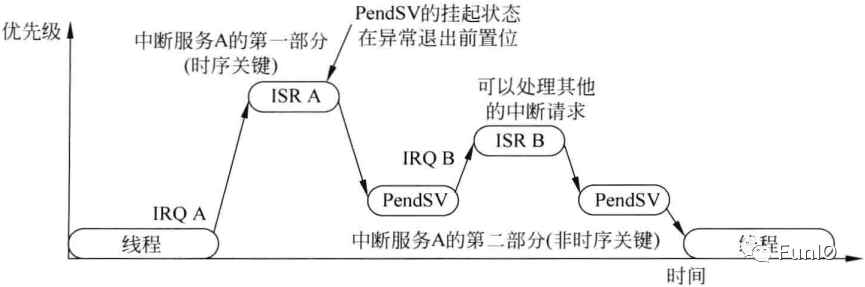
图8.6 利用PendSV将中断服务分为两部分
8.4 实际的上下文切换
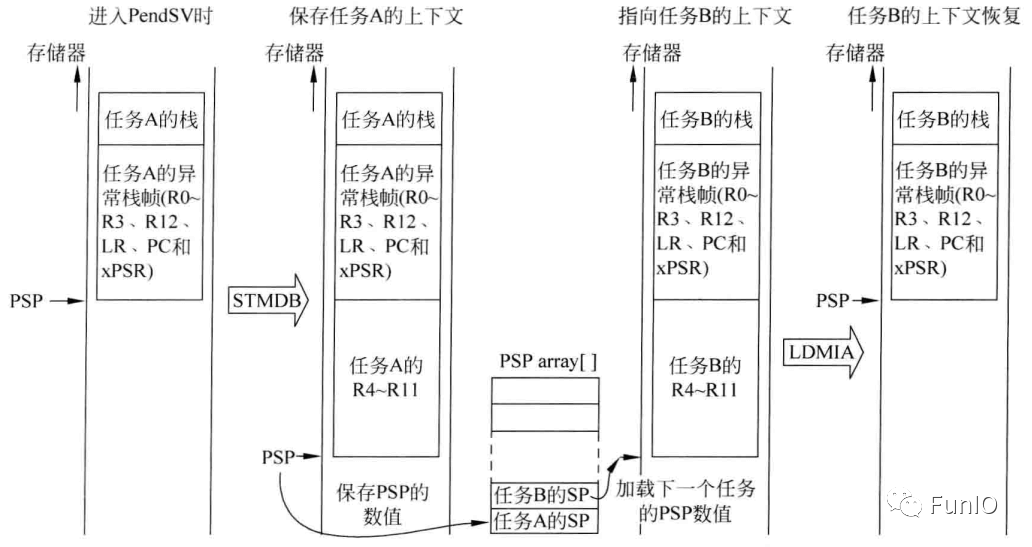
图8.7 上下文切换
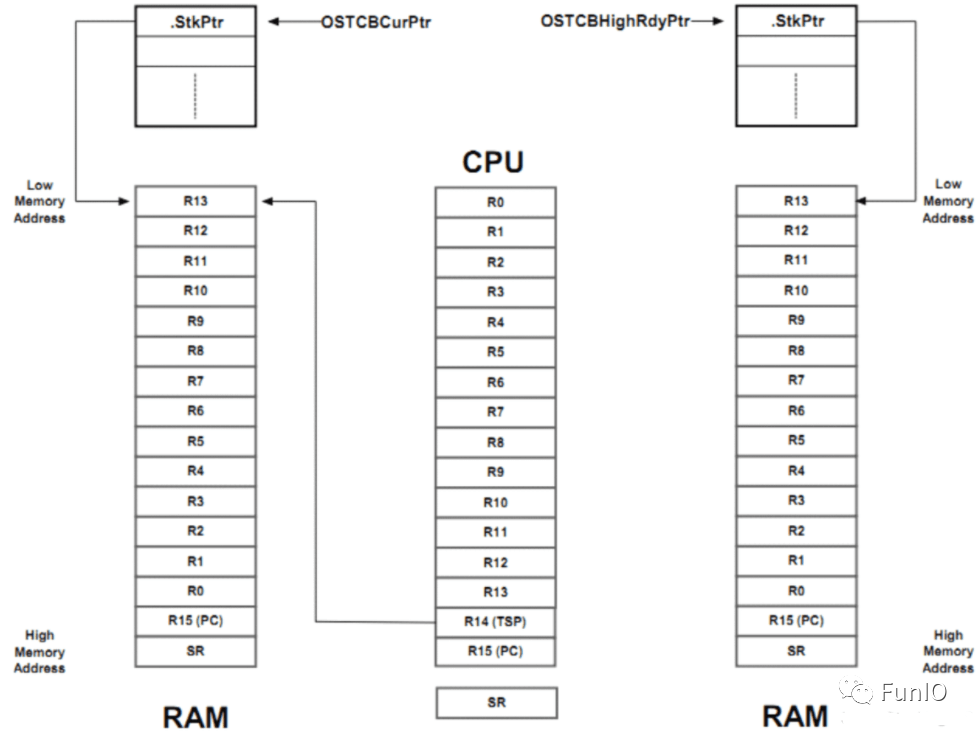
图8.8 ucos-iii中的任务切换示例
-
ARM Cortex-M4内核MCU的优势在哪里2015-02-13 25803
-
ARM Cortex-M4内核MCU相关资料下载2021-07-01 1176
-
内核CPU 32位ARM Cortex-M4内核+FPU2021-08-20 1399
-
基于ARM Cortex-M4内核的新型数字信号控制器2010-06-19 2215
-
内核之争升级 Cortex-M4成为主战场2011-12-02 3029
-
STM32F4xxx的CORTEX-M4内核编程手册2017-09-22 1995
-
为何选择Cortex-M4内核2017-09-29 1137
-
为何要选择Cortex-M4内核2017-10-09 960
-
基于ARM Cortex-M4核的低功耗MCU--LPCXpresso54628详解2018-02-06 9293
-
基于ARM Cortex-M4架构的Stellaris MCU介绍2018-06-26 6835
-
介绍STM32F4在Cortex-M4内核和Cortex-M3内核方面的优势2018-07-03 15706
-
Cortex-M4处理器教程之Cortex-M4培训课件免费下载2018-11-23 1934
-
ARM Cortex-M4内核MCU2021-10-26 1456
-
cortex-M4与cortex-A7内核启动流程分析2021-12-01 1413
-
基于Arm Cortex-M4 32位RISC内核的STM32G473简介2022-05-25 7698
全部0条评论

快来发表一下你的评论吧 !
