

芯片设计里的Multi-Bit FF探究
EDA/IC设计
描述
在现代的芯片设计里边,工程师在优化功耗和面积上无所不有其极,这里讨论的multi-bit FF 就是其中的一种方法或者称之为一种流程。
MBIT FF vs signle bit FF
Multi-bit顾名思义就是将通常单bit的FF,封装为一个多bit的FF,下面一起来看一下他们之间的异同:
- 单bit的asyn-clear scan-FF
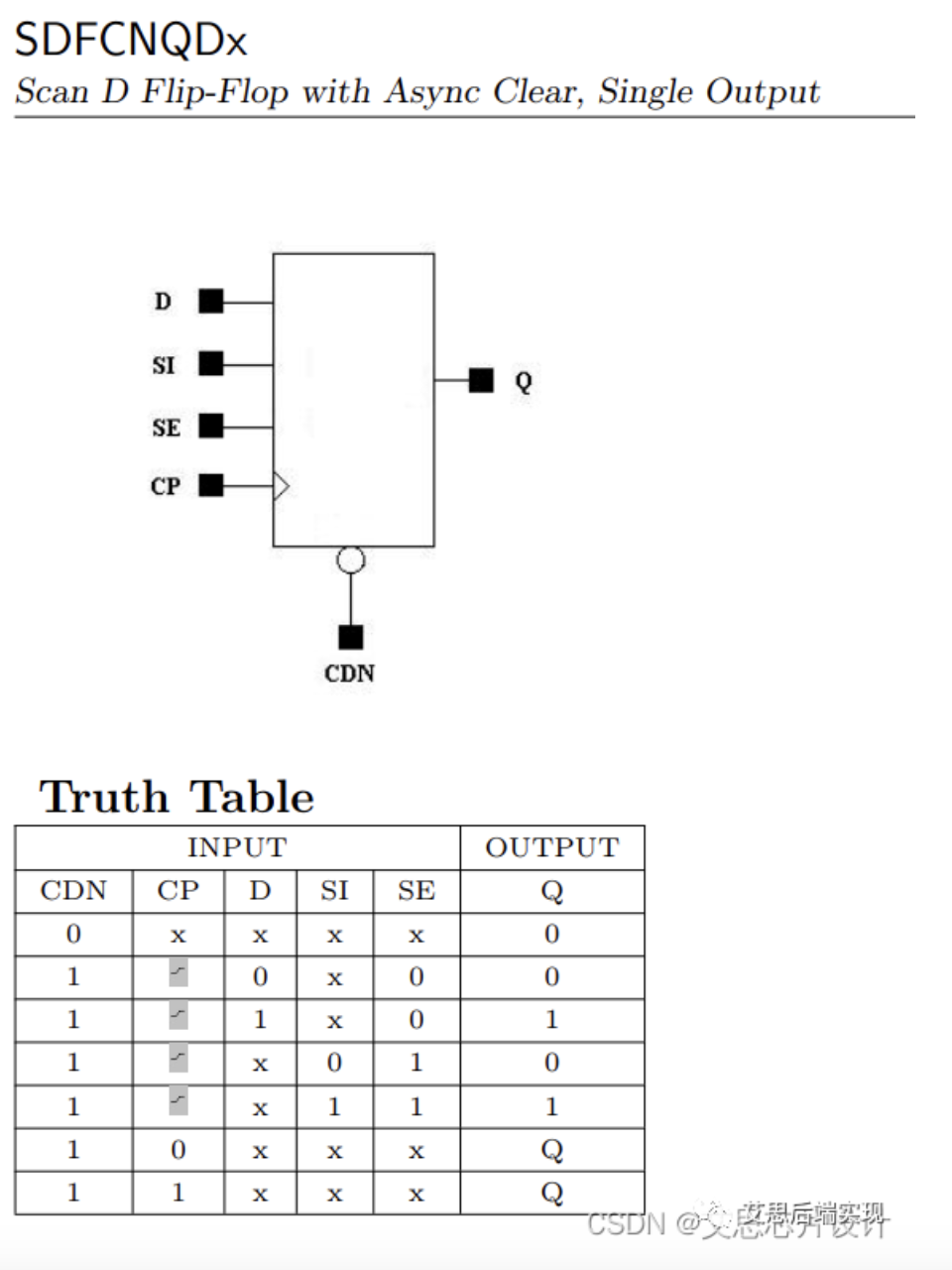
针对这种单bit的asyn-clear scan-FF,vendor提供了几种多bit的asyn-clear scan-FF,
-
multi-bit2 asyn-clear scan-FF
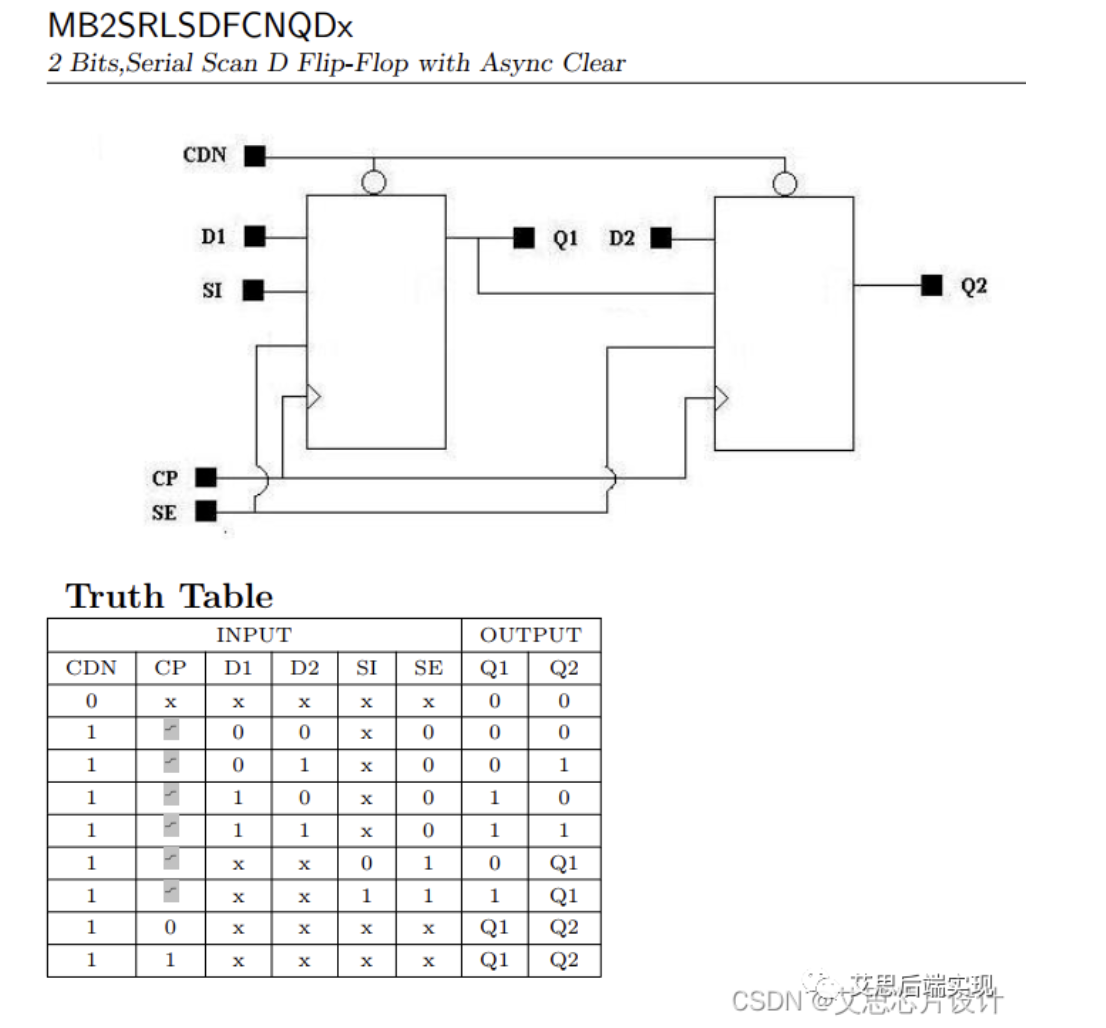
-
multi-bit4 asyn-clear scan-FF
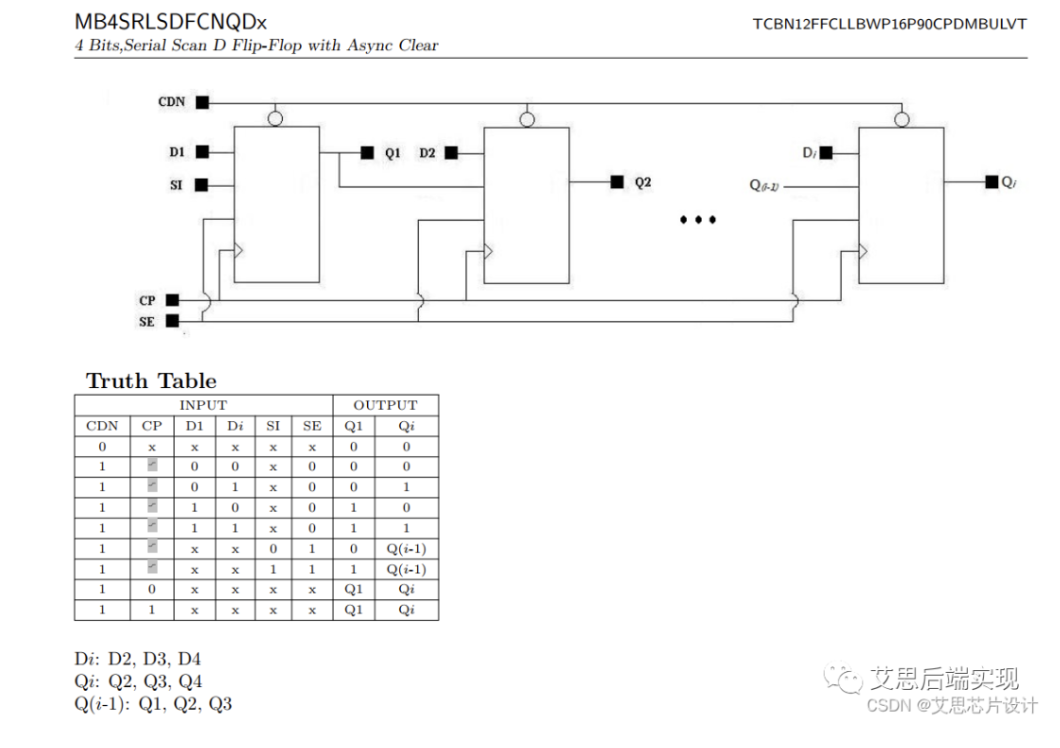
-
multi-bit6 asyn-clear scan-FF
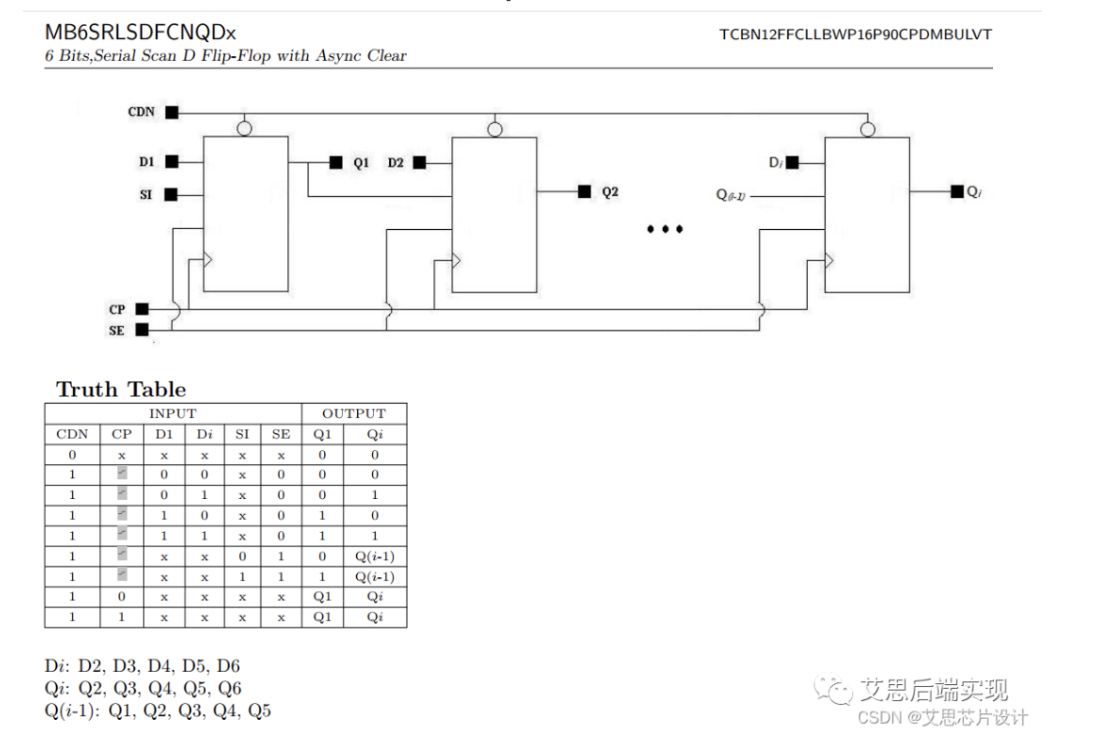
-
multi-bit8 asyn-clear scan-FF
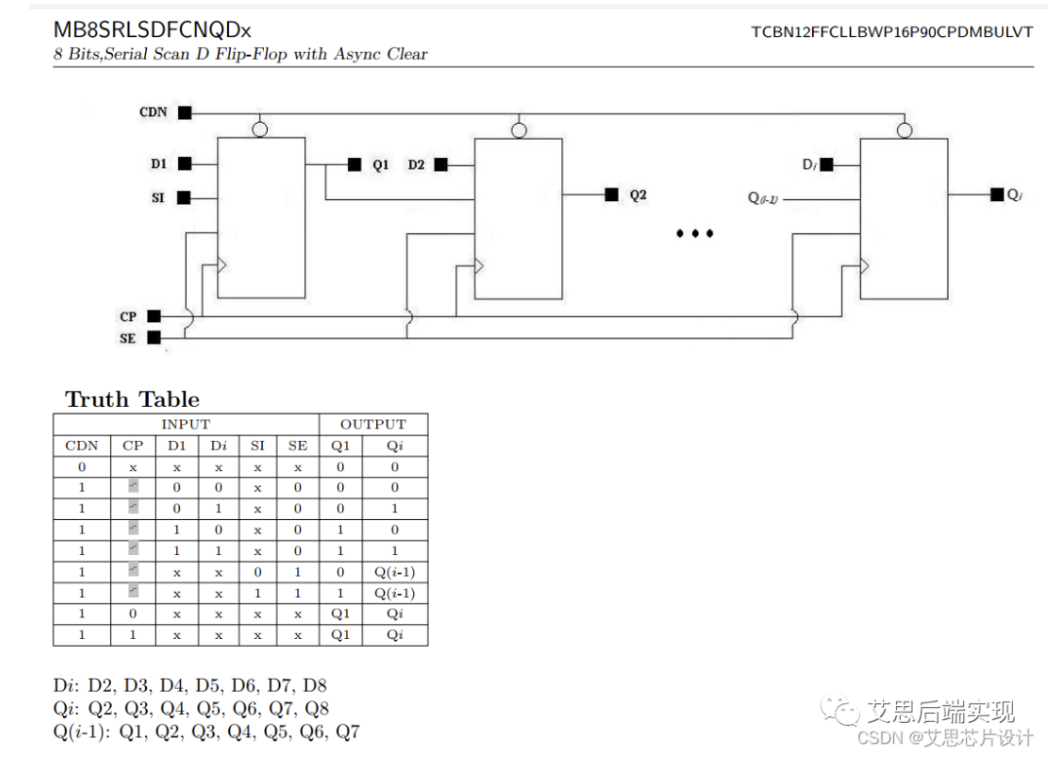




从cell的原理图上看,multi-bit和signle-bit的区别很小,可以简单理解为将多个signle-bit的FF并排放到了一起,对于scan chain,也天然的安装顺序连接到一起,简单总结如下

可以看到,这里会有三类pin是共享关系
- clock pin
- clean/reset pin
- SI/SE pin
所以:由于scan是后插入的,这个对于multi-bit的封装不敏感外,当且仅当某一组FF在功能上的clock和reset-clear是共享driver的时候,这一组FF才可以被二次封装成为multi-bit FF
MBIT的优势
由于MBIT对一些common pin的共享机制,由此带来的优势有:
- 基于共享机制,晶体管级别的面积优化
- common pin的使用,减少layout连线损耗
- clock tree的leaf变少,降低clock tree长度和功耗
在cell级别,以T12工艺为例,同样功能(Scan D Flip-Flop with Async Clear, drive strenth: X1)的signle bit和MBIT的比较如下(PS:用多个单bit 直接搭建多bit 结构进行功耗面积的比对)

如果将signle bit 例化多次进行横比,MBIT大体上都会在面积上:7.4% ~ 12.96% 的提高幅度,功耗上:-3.93% ~ 7.32% 左右的提升
在了解了multi-bit的机理后,这里需要一起梳理一下multi-bit的流程。
MBIT的流程
RTL 阶段对MBIT的推进
在读入RTL之前,DC里边通过配置 hdlin参数:hdlin_infer_multibit 来对管理multi-bit的RTL阶段的识别,

上述三种方式,仅仅影响RTL mapping阶段的multi-bit的识别和创建,言下之意:只对第一个compile_ultra (mapping)的结果有影响。
这里推荐的方案是:** default_none**
- 如果使用never:这个会完全忽略前端设计人员的意图,可能会丢失directives的信息传递
- 如果使用default_all:这个会导致DC 会有一些自己研判的方法,会将multi-bit进行自己研判的替换,这里不会丢失设计者的directives,但是可能会对一些总线或者二维数组进行替换,这里会导致两类问题
- timing:在第一圈compile_ultra的时候,timing信息并非完整,此时进行multi-bit的替换,势必会导致后续时需优化的障碍。过早打包可能还需要二次拆包
- register的命名行为。如果RTL是这样的二维数组定义
reg \\[7:0\\] mem\\[255:0\\]
正常情况下,DC会把这类二位数组mapping成:
mem\\_reg\\[255\\]\\[7\\]
mem\\_reg\\[255\\]\\[6\\]
......
mem\\_reg\\[255\\]\\[0\\]
......
mem\\_reg\\[0\\]\\[7\\]
mem\\_reg\\[0\\]\\[6\\]
......
mem\\_reg\\[0\\]\\[0\\]
如果,这个时候如果使用了default_all,DC analyze会对此类数组格式进行multi-bit封装,最终DC compile_ultra生成的instance名字会变得比较奇怪,如下:
\\# use 4bit register bank
mem\\_reg\\[255\\]\\[7:4\\]
......
mem\\_reg\\[255\\]\\[3:0\\]
......
mem\\_reg\\[0\\]\\[7:4\\]
......
mem\\_reg\\[0\\]\\[3:0\\]
这种命名方式会给formal带来一些的障碍,也有可能带来潜在的timing 隐患
小结: 在RTL解析阶段,把RTL directives和hdlin_infer_multibit =default_none结合使用,既尊重原著意思,也可以实现比较可控的multi-bit 替换。如果设计人员不确定哪些一定或者一定不需要去做multi-bit 替换,这里依然使用hdlin_infer_multibit =default_none,这样在第一个RTL步骤,就之后对于RTL 设计人员的需求,在RTL 分析时进行multi-bit 绑定,但是并不一定会产生替换,前提是timing和控制都能满足要求。
R2G里的MBIT的流程
从上面的描述可以看到,MBIT的替换主要是为了面积/功耗收益的同时,时序不受影响(不出violation)。所以在physical aware 的DCT完成后,进行替换,是比较合适的时机:
- mapping和逻辑优化基本完成:ICG的影响已经带入,MBIT的控制共享比较清晰
- 由于是physical aware的DCT,时序信息也基本清楚,这里整体进行MBIT替换可以最大限度的利用MBIT的优势,如果后期(APR)有时序压力,可以使用de-banking来进行降解MBIT,也是有二次操作空间
compile_ultra可以根据需求进行MBIT替换,但是需要遵循下列规则:

基于上述原理,用户可以使用下面的简单流程在综合里边进行MBIT的替换

对MBIT操作的核心命令是:identify_register_banks,这个命令在第一步compile_ultra完成后,可以对DCT/DCG里的FF进行MBIT替换,除过cell之间的相同clock和控制位,identify_register_banks命令会将物理位置相近的FF进行MBIT替换,所以,从S家的R2G策略上将,为了保持良好的继承性,用户需要使用DCG流程+ ICC/ICC2 DEF flow(read_def + place_opt -skip_initial_placement)来完成MBIT的替换应用。只有这样才能把DCG替换FF的物理优势继承下来
当然,用户也可以在ICC/ICC2 进行MBIT的替换,但是由于替换策略都是类似的,也是一定要有cell的初始布局后,才能进行替换,基本流程如下:

这里的流程近似可以看作把place_opt进行了拆分,在第一步coarse placement 后,加入了MBIT的替换,用户需要手动sorce 这个 脚本(和identify_register_banks类似的用法)进行MBIT替换,而后再继续执行place_opt剩余的步骤。
无论是在synthesis还是layout阶段,MBIT替换的方式主要是基于两点:
- timing
- 物理位置
只有在timing 有余量,并且物理位置接近的register,才会触发工具的MBIT替换动作,这样可以最大限度的降低对当前数据库的影响,同时也能利用起MBIT的面积和功耗优势
DC 中 MBIT 替换实例
以DCG为例,在第一步compile_ultra完成后,使用identify_register_banks进行MBIT 替换
- 替换前:

- 替换后:可以看到,新创建的MBIT位于原始两个single bit的中间


命令运行日志:

这里会打印:
- single bit cell 删除信息
- MBIT pin 连接信息
可以看到 这里的CLK/RB 等控制信号都是需要 同源的,工具也有内建的防错机制,如果目标single bit的控制端有不同,会以PSYN-1203 的告警进行打印,确保功能不被影响:

注:用户可以通过set_multibit_option 来控制compile_ultra 命令的行为,这样在综合增量优化步骤里边,工具可以根据set_multibit_option配置的情形,来做banking和de-banking的操作。
MBIT的命名和管脚映射
工具是通过 identify_register_banks 产生MBIT的替换脚本,对于总线,通常是按照升序的策略进行命名的,当然,由于这个是后处理脚本,用户也可以自己进行修改,但是通常没必要改变默认行为,以免对后续formal产生影响。简单命令如下:

对于合成后的MBIT cell,对应的Q输出,也是沿用升序的方式:
A\\[0\\].Q - > MBIT\\_A\\[0\\]\\_\\_A\\[1\\]\\_\\_A\\[2\\]\\_\\_A\\[3\\].Q1
A\\[1\\].Q - > MBIT\\_A\\[0\\]\\_\\_A\\[1\\]\\_\\_A\\[2\\]\\_\\_A\\[3\\].Q2
A\\[2\\].Q - > MBIT\\_A\\[0\\]\\_\\_A\\[1\\]\\_\\_A\\[2\\]\\_\\_A\\[3\\].Q3
A\\[3\\].Q - > MBIT\\_A\\[0\\]\\_\\_A\\[1\\]\\_\\_A\\[2\\]\\_\\_A\\[3\\].Q4
MBIT通过这样的命名方式,对于后续的formal mapping和gate-sim等工作是有一定帮助的。
-
音频转换芯片DP7344兼容CS4344双通道24位DA转换器技术资料2025-06-25 3156
-
纳祥科技NX6802,一款24bit、192KHz的差分输出数模转出4通道DAC2025-02-05 1326
-
立体声数模转换芯片GC4344的性能有哪些?2023-12-06 1833
-
GC4344 是一款立体声数模转换芯片,24位DAC2023-11-06 2596
-
芯片设计里的Multi-Bit FF方法讨论2023-05-08 3631
-
DP7344 192K 双通道24位DA转换器芯片2023-03-30 1074
-
低功耗设计之multi-bit cell技术简介2023-02-12 7056
-
DP4344音频转换芯片ACD/DAC完全兼容CS4344音频解码2023-02-06 2862
-
Multi-bit Flip Flop(MBFF)修复技巧2022-11-09 5065
-
立体声数模转换芯片MS4344规格书2022-01-14 1483
-
瑞盟MS5281D-24bit/192KHz双通道差分音频数模转换芯片-颂扬恒(瑞盟一级代理)2021-12-29 855
-
24bit,192KHz 双通道数模转换电路(MS4344)2021-01-10 1522
-
GC4344 24位音频DAC 24位音频数模转换芯片 CS4344替代料GC43442020-04-21 3509
全部0条评论

快来发表一下你的评论吧 !
