

经典多目标跟踪算法DeepSORT的基本原理和实现
描述
作者| 杨亦诚
经典多目标跟踪算法DeepSORT的基本原理和实现
OpenVINO
目标检测 vs 目标跟踪
在开始介绍DeepSORT的原理之前呢,我们先来了解下目标检测,和目标跟踪之间的区别:
· 目标检测:在目标检测任务中,我们需要利用AI模型识别出单张画面中,物体的位置和类别信息,每一帧画面之间检测结果相对独立,没有依赖关系。这也意味着目标检测算法可以被应用于单张图片的检测,也可以用于视频中每一帧画面的检测。
· 目标跟踪:而目标跟踪则是在目标检测的基础上加入的跟踪机制,他需要追踪视频中同一物体在不同时刻的位置信息,因此他需要判断相邻帧之间的被检测到对象是否是同一个物体,并且为同一物体分配唯一的编号ID,用来区别不同的目标对象。
例如下面短跑运动员比赛的例子中,目标检测任务只需要识别到画面中所有人体的位置即可,而目标跟踪任务则需要区分画面中相同的对象和不同对象。
Deep SORT
DeepSORT的前身是SORT算法,SORT算法是由目标检测器以及跟踪器所构成,其跟踪器的核心是卡尔曼滤波算法和匈牙利算法。利用卡尔曼滤波算法预测检测框在下一帧的状态,将该状态与下一帧的检测结果利用匈牙利算法进行匹配,实现追踪。一旦物体受到遮挡或者其他原因没有被检测到,卡尔曼滤波预测的状态信息将无法和检测结果进行匹配,该追踪片段将会提前结束。
而DeepSORT则引入了深度学习中的重识别算法来提取被检测物体(检测框物体中)的外观特征(低维向量表示),在每次(每帧)检测+追踪后,进行一次物体外观特征的提取并保存。后面每执行一步时,都要执行一次当前帧被检测物体外观特征与之前存储的外观特征的相似度计算,依次来避免遇到漏检的情况,将失去身份ID的情况,可以说DeepSORT不光使用了物体的速度和方向趋势来对目标进行跟踪,同时也利用物体的外观特征巩固对是否为同一物体的判断。
这里我们可以将DeepSORT跟踪算法归纳为以下几个步骤:
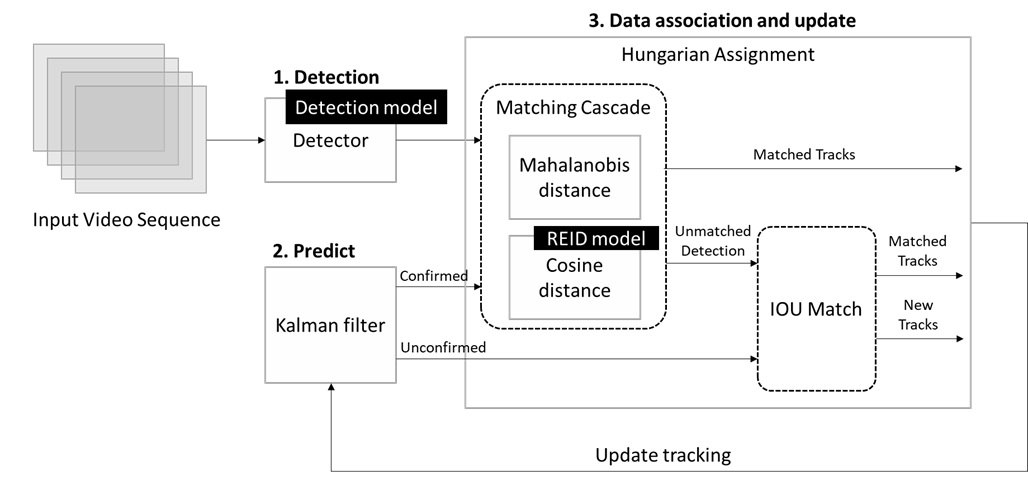
图:DeepSORT方法流程图
1. 目标检测
使用常规的目标检测模型,对单帧画面进行识别,并过滤出待跟踪对象,例如这个任务中我们的跟踪对象为人体,那其他被检测到的对象,例如桌子,椅子将被全部丢弃。
2. 目标预测
在这一步中,我们将使用卡尔曼滤波算法。基于当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。预测结果分为确认态(confirmed),和不确认态(unconfirmed),新产生的Tracks是不确认态的;不确认态的Tracks必须要和Detections连续匹配一定的次数才可以转化成确认态。确认态的Tracks必须和Detections连续适配一定次数才会被删除。
3. 数据关联和更新
接下来需要把检测到的物体和预测的物体进行关联, 此处DeepSORT将使用匈牙利算法,并根据不同的代价函数来寻找最大匹配。如果卡尔曼滤波输出确认态的预测结果,DeepSORT将采用马氏距离加余弦距离的级联方法对相关信息进行关联,通过马氏距离我们可以获取运动物体在两个不同状态的距离信息,如果某次关联的马氏距离小于指定的阈值,则设置运动状态的关联成功,但是DeepSORT不仅看框与框之间的距离,还要看框内的表观特征才能更好的进行关联匹配,所以DeepSORT还引入了表观特征余弦距离度量,这里会使用一个重识别模型来获取不同物体的特征向量,然后再通过余弦距离构建代价函数,计算预测对象与检测对象的相似度。这两个代价函数结果都尽量的小,框也接近、特征也接近的话,就认为两个预测框中是同一个东西。
DeepSORT之所以引入这样的级联方法,是因为如果在运动状态变化比较剧烈的场景下,基于目标状态之间的关联很可能是不可靠的(举个例子,当一个人在跑步时,如果相机是静止的或者与人的运动方向相反,那么相机中的人在每帧之间的运动状态就会差异较大),在这样的情况下,运动的不确定性变高,先验状态与目标检测之间的匹配差异较大,而弥补这个缺陷的方法就是使用特征相似距离关联;但是在目标运动状态变化并不剧烈的情况下,这时候帧与帧之间,马氏距离就成为了很好的数据关联度量的选择。
数据关联的第二步则是计算不确认态下的预测框和未被上一步级联方法匹配检测框的IOU交并比,DeepSORT使用匈牙利算法寻找最大匹配的IOU结果,如果预测框和检测框的IOU低于阈值,我们将删除两者的关联性。
最后利用当前帧的关联结果更新预测器中所有被分配ID的跟踪对象状态。
Deep SORT任务实现
接下来我们来看DeepSORT的基本实现,这里我们可以直接使用DeepSORT作者提供的跟踪器对象模块实现卡尔曼滤波算法预测以及匈牙利算法匹配等多种功能,开发者可以直接替换其中目标检测模型与重识别模型,并修改最大匹配次数等参数,以提升在目标场景下的识别跟踪准确性。推理部分使用OpenVINO做为推理引擎。这里有几个关键的模块:
1. 模型初始化
本次任务中会使用两个深度学习模型,都是来自于OpenVINO官方的Open Model Zoo模型仓库。这里可以提前定义一个通用的OpenVINO的模型类来对这两个模型进行初始化,并设置他的预测推理函数。由于目标检测任务的输出数量往往不固定,同时我们又需要利用重识别模型为每一个目标检测任务的输出构建特征向量,因此为了提升模型的执行效率,我们将重识别模型的batachsize初始化为“-1”,以动态匹配不断变化的目标数量。
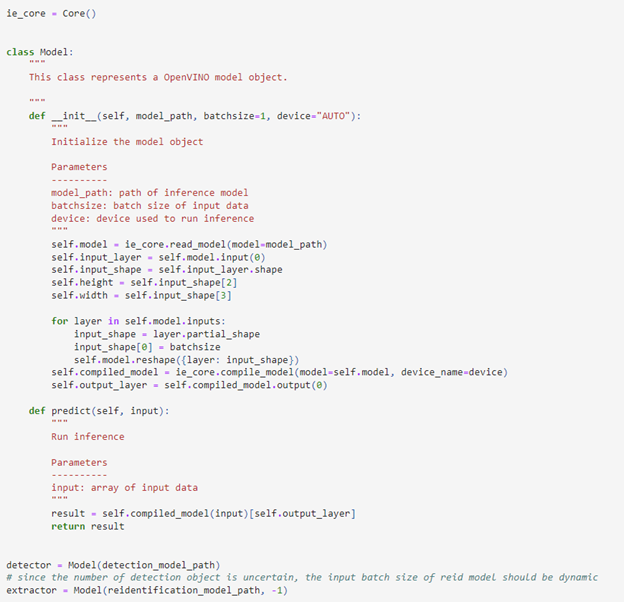
图:OpenVINO模型对象
2. 余弦距离
本次任务采用余弦距离作为匹配算法的代价函数之一,因此我们需要首先定义余弦距离的计算方法(如下图所示),其中x1,x2分别为重识别模型输出的特征向量。

图:余弦距离计算方法
接下来我们可以测试下这个方案的效果,我们将两个不同人体对象的图片进行特征向量化后,将模型输出的结果直接送入余弦距离模块中,计算相关性的置信度,可以看到当两张图片属于同一对象的情况下,置信度较高,两个图片不属于同一对象的情况下置信度就会低于阈值。
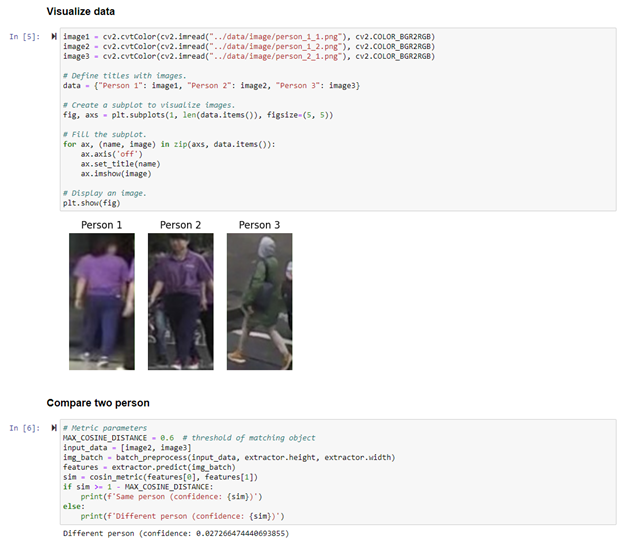
图:不同人体对象余弦距离计算结果
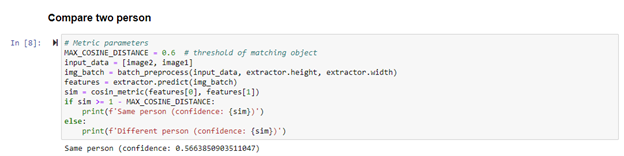
图:相同人体对象余弦距离计算结果
3. Tracker跟踪器
Tracker是DeepSORT方法的核心对象,在具体调用方法里,第一步先要定义一个Tracker对象,并声明关键参数里,例如考虑到内存占用情况,我们需要定义NN_BUDGET,用于限制同屏中最大跟踪对象的数量,同时使用cosine最大余弦距离作为代价函数,并且指定IOU和余弦距离的阈值,以及max_age描述最大多少次无匹配会删除追踪对象, n_init描述确认状态需要的最少匹配次数。
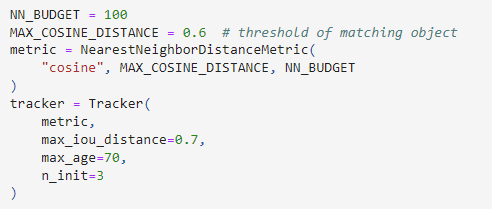
图:Tracker跟踪器初始化方法
然后进入到主函数部分,在开始track任务之前,会先将目标检测模型和重识别模型的输出结果打包成Detection对象,一起送入Tracker中进行匹配,当目标对象转化为确认状态后,可以从Tracker对象中获取每一个目标的唯一ID用于在原始画面中进行标注。

图:调用跟踪器的预算和update关联方法
4. 最终实现效果
在完成主函数定义后,我们可以给他输入一段视频流,或者使用身边的网络摄像头获取实时影像进行验证。完整代码和示例使用方法可以参考这个notebook:
https://github.com/OpenVINOtoolkit/OpenVINO_notebooks/tree/main/notebooks/407-person-tracking-webcam。
可以看到DeepSORT方法非常精确的识别并跟踪了画面中每一个人体对象的位置,并且在仅在普通酷睿系列的CPU上就可以实现60FPS左右的流畅表现。
小结
本文分享多目标跟踪算法的经典算法DeepSORT,它是一个两阶段的算法,作为SORT 的升级版,它整合了外观信息 (appearance information) 从而提高 SORT 的性能,这使得我们在遇到较长时间的遮挡时,也能够正常跟踪目标,并有效减少 ID 转换的发生次数。
审核编辑:汤梓红
-
视频跟踪目标跟踪算法简介(上海凯视力成信息科技有限...2013-09-29 5807
-
基于QT+OpenCv的目标跟踪算法实现2018-09-21 5433
-
PID算法基本原理及其执行流程2021-12-21 1273
-
视频图像动态跟踪算法的设计与实现2010-11-16 692
-
多传感器多目标跟踪的JPDA算法2012-02-03 1121
-
改进霍夫森林框架的多目标跟踪算法2017-12-14 821
-
简单粗暴的多对象目标跟踪神器–DeepSort2020-12-08 2033
-
如何更好地实现视频多目标轨迹的连续跟踪?2021-04-07 1387
-
基于卷积特征的多伯努利视频多目标跟踪算法2021-05-12 1116
-
最常见的目标跟踪算法2022-09-14 4066
-
基于MobileNet的多目标跟踪深度学习算法2022-11-09 2303
-
经典多目标跟踪算法DeepSORT的基本原理和实现2023-04-23 4617
-
基于DeepSORT YOLOv4的目标跟踪2023-06-27 947
-
目标跟踪初探(DeepSORT)2023-08-07 2126
-
多目标跟踪算法总结归纳2024-04-28 4660
全部0条评论

快来发表一下你的评论吧 !
