

NUS&深大提出VisorGPT:为可控文本图像生成定制空间条件
描述

代码:https://github.com/Sierkinhane/VisorGPT
论文:https://arxiv.org/abs/2305.13777
论文简介
可控扩散模型如ControlNet、T2I-Adapter和GLIGEN等可通过额外添加的空间条件如人体姿态、目标框来控制生成图像中内容的具体布局。使用从已有的图像中提取的人体姿态、目标框或者数据集中的标注作为空间限制条件,上述方法已经获得了非常好的可控图像生成效果。那么如何更友好、方便地获得空间限制条件?或者说如何自定义空间条件用于可控图像生成呢?例如自定义空间条件中物体的类别、大小、数量、以及表示形式(目标框、关键点、和实例掩码)。
本文将空间条件中物体的形状、位置以及它们之间的关系等性质总结为视觉先验(Visual Prior),并使用Transformer Decoder以Generative Pre-Training的方式来建模上述视觉先验。因此,我们可以从学习好的先验中通过Prompt从多个层面,例如表示形式(目标框、关键点、实例掩码)、物体类别、大小和数量,来采样空间限制条件。我们设想,随着可控扩散模型生成能力的提升,以此可以针对性地生成图像用于特定场景下的数据补充,例如拥挤场景下的人体姿态估计和目标检测。
方法介绍
表1 训练数据
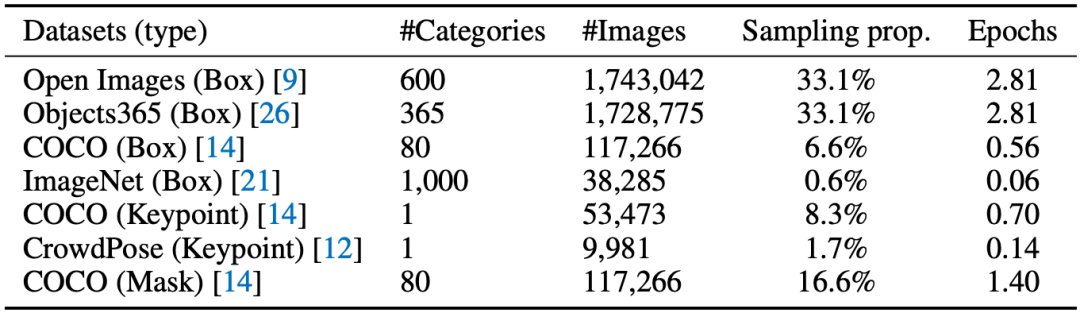
本文从当前公开的数据集中整理收集了七种数据,如表1所示。为了以Generative Pre-Training的方式学习视觉先验并且添加序列输出的可定制功能,本文提出以下两种Prompt模板:

使用上述模板可以将表1中训练数据中每一张图片的标注格式化成一个序列x。在训练过程中,我们使用BPE算法将每个序列x编码成tokens={u1,u2,…,u3},并通过极大化似然来学习视觉先验,如下式:
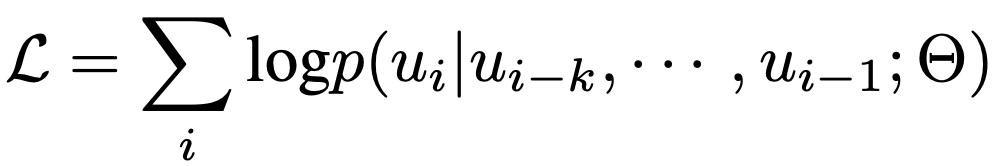
最后,我们可以从上述方式学习获得的模型中定制序列输出,如下图所示。
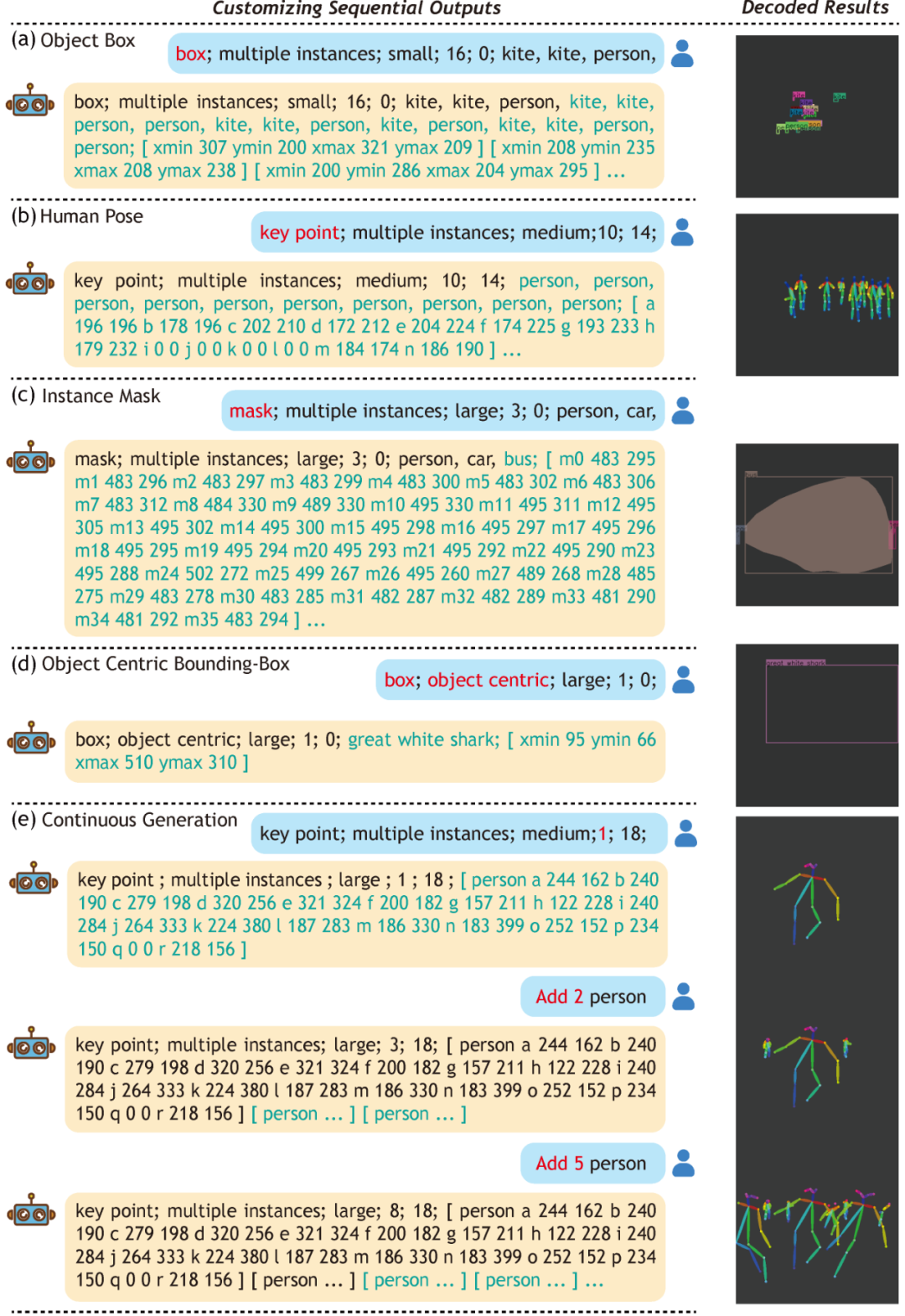
图1 定制序列输出
效果展示



-
基于扩散模型的图像生成过程2023-07-17 4140
-
一种有效的文本图像二值化方法2009-06-11 774
-
基于相容粗集的二值文本图像数字水印方法2009-08-12 1200
-
基于灰度直方图和谱聚类的文本图像二值化方法2009-10-29 673
-
基于多小波变换的文本图像文种识别2011-08-15 835
-
基于岭回归的稀疏编码文本图像复原方法2017-11-28 868
-
基于Hash函数的文本图像脆弱水印算法2017-12-04 890
-
如何去解决文本到图像生成的跨模态对比损失问题?2021-06-15 3634
-
Labview&SQLSever如何自动生成查询语句2021-09-29 712
-
复旦&微软提出OmniVL:首个统一图像、视频、文本的基础预训练模型2022-12-14 1456
-
如何区分Java中的&和&&2023-02-24 2280
-
微软提出Control-GPT:用GPT-4实现可控文本到图像生成!2023-06-05 1552
-
基于文本到图像模型的可控文本到视频生成2023-06-14 1735
-
NUS&;amp;深大提出VisorGPT:为可控文本图像生成定制空间条件2023-09-26 1114
-
能力再次提升! 迅为RK3588/RK3568开发板&核心板新增定制分区镜像2024-11-06 2064
全部0条评论

快来发表一下你的评论吧 !
