

号称「碾压」LLaMA的Falcon实测得分仅49.08,HuggingFace决定重写排行榜代码
描述
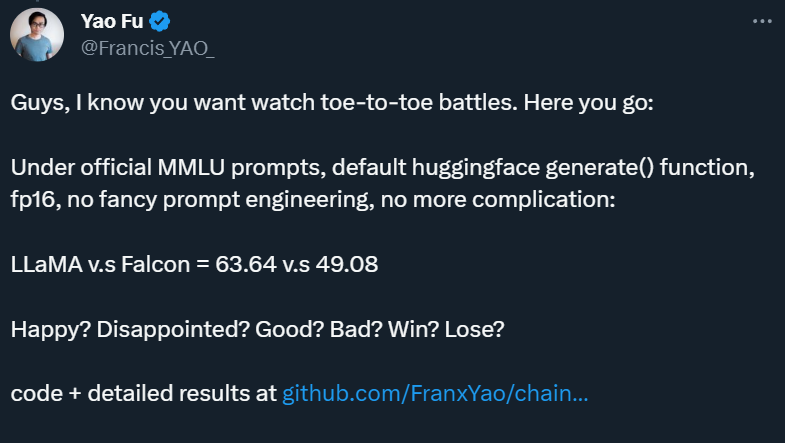
LLaMA v.s. Falcon = 63.64 v.s. 49.08。评估结果表明,LLaMA 并未被「碾压」。
作为开源模型界的扛把子,LLaMA 一直备受瞩目。
这是一组由 Meta 开源的大型语言模型,共有 7B、13B、33B、65B 四种版本。其中,LLaMA-13B 在大多数数据集上超过了 GPT-3(175B),LLaMA-65B 达到了和 Chinchilla-70B、PaLM-540B 相当的水平。
自 2 月份发布以来,开源社区一直在 LLaMA 的基础上进行二创,先后推出了 Alpaca、Vicuna 等多个「羊驼」大模型,生物学羊驼属的英文单词都快被用光了。
不过,也有人对 LLaMA 发起了挑战。5 月底,阿联酋阿布扎比的技术创新研究所(TII)开源了一个 400 亿参数的因果解码器模型「Falcon-40B」,该模型在 RefinedWeb 的 1 万亿个 token 上进行了训练,并使用精选数据集增强。刚一发布,「Falcon-40B」就冲上了 Huggingface 的 OpenLLM 排行榜首位,「碾压」了参数规模 1.5 倍的「LLaMA-65B」,也优于 MPT、RedPajama 和 StableLM 等开源大模型。

后来,Falcon-40B Instruct 版本占据了排行榜首位,Falcon-40B 则退到了第三,而 LLaMA-65B 已经掉到了第六位。
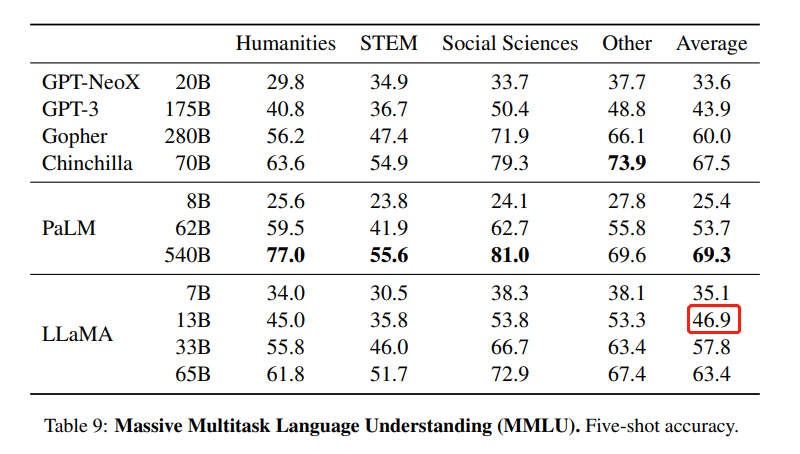
不过,仔细看过数据之后,围观者产生了疑问:为什么在 HuggingFace 的 Open LLM 排行榜上,LLaMA-65B 的 MMLU 这项分数是 48.8,明显低于官方数据 63.4?
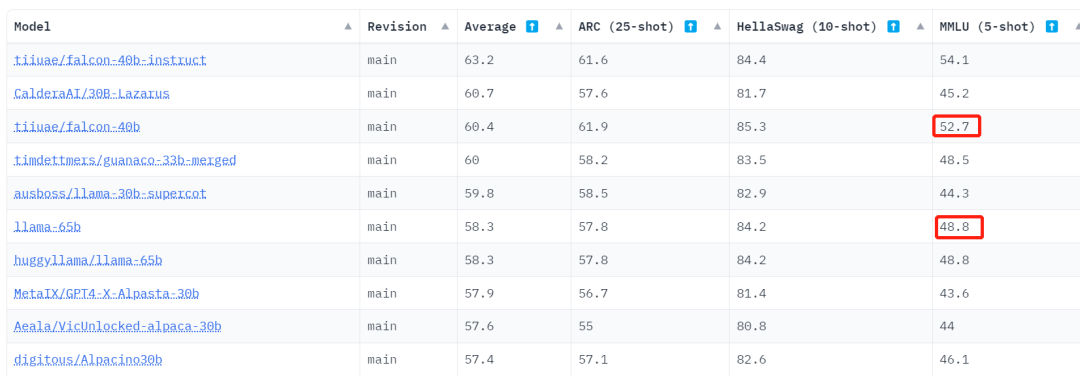
HuggingFace 的 Open LLM 排行榜。地址:https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
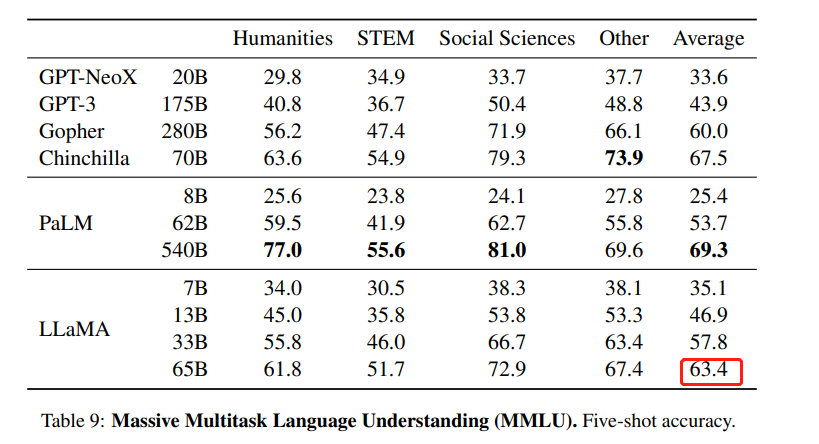
LLaMA 论文中的 MMLU 数据。MMLU 是 Massive Multitask Language Understanding 的缩写,是一个基准数据集,旨在通过仅在零样本和少样本设置下评估模型来衡量预训练期间获取的知识。它由一系列学术科目中类似考试的问题组成,用于测试模型对于世界理解的能力。
还有人表示,在测 Falcon-40B 时,他们也复现不了排行榜上的分数。
面对这样的争议,Karpathy 等大牛选择了谨慎观望。
爱丁堡大学博士生符尧等则选择自己测一遍。
简而言之,他们在 Chain-of-thought Hub 上重新写了开源的 LLaMA eval 代码,然后在同样的设定下,用官方 prompt,fp16,HF 默认代码,公平比较了 Falcon 和 LLaMA 在 MMLU 上的表现。
「没有花哨的 prompt 工程和解码,一切都是在默认设置下进行的。」符尧在推文中写道。
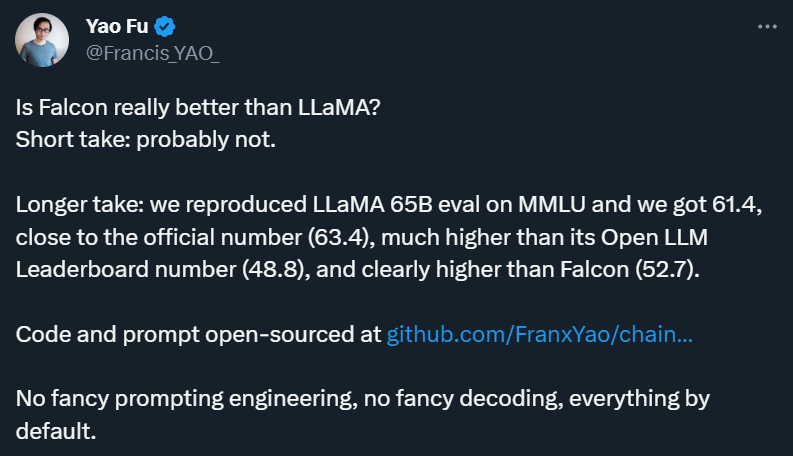
6 月 8 日,他们公布了第一批结果:LLaMA 65B 的 MMLU 得分为 61.4,比较接近官方数字(63.4),明显高于其 Open LLM Leaderboard 分数 48.8,且远高于 Falcon-40B 的 Leaderboard 分数 52.7。
初步来看,「你大爷还是你大爷」。不过,这还不是 LLaMA 65B 的真实实力。在 6 月 10 日凌晨公布的第二波结果中,符尧解释说,他们在第一波测评中发现了一个「long prompt」引起的 bug,这个 bug 导致 LLaMA 在高中欧洲历史和高中美国历史上得到 0 分。在修复了这个 bug 后,LLaMA 得分变成了 63.64,与论文中报道的数字基本相同。

公平起见,使用相同的脚本,他们也测出了 Falcon-40B 的得分:49.08,低于 Leaderboard 分数 52.7,只比 LLaMA 13B 好一点。
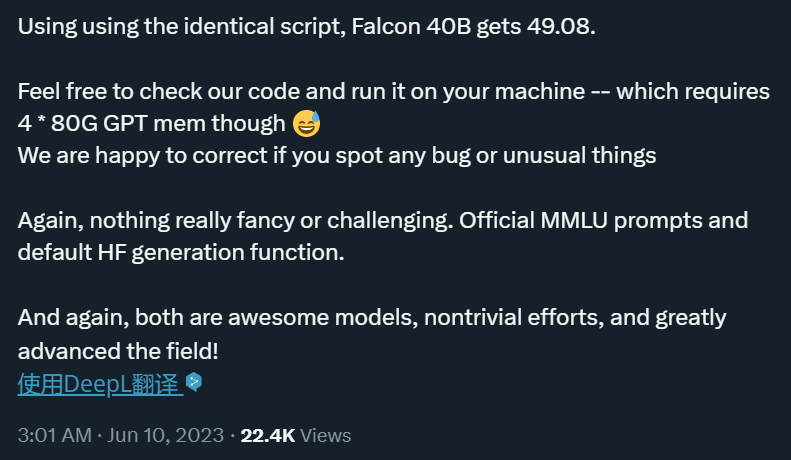
由此,这次所谓的「碾压」事件彻底反转。
符尧团队的这一尝试也吸引了 HuggingFace 研究科学家 Nathan Lambert 的注意,后者决定重写 Open LLM Leaderboard 的代码。
不过,符尧专门指出,他们不打算在 LLaMA 和 Falcon 之间挑起战争:「两者都是伟大的开源模型,并为该领域做出了重大贡献!Falcon 还具有更简单的许可证优势,这也赋予了它强大的潜力!」
为了方便大家检查代码和开源结果,符尧公布了相关地址:https://github.com/FranxYao/chain-of-thought-hub/tree/main/MMLU
如果在检查后有新的发现,欢迎在评论区留言。
-
HarmonyOS开发案例:【排行榜页面】2024-04-30 2907
-
中国IC设计公司排行榜2008-05-26 9303
-
2013年2月份编程软件排行榜,LabVIEWTop27,进步很大。2012-11-06 9469
-
资料下载总排行榜2013-03-05 3159
-
各种排行榜汇总贴!!!!!2013-07-30 18966
-
2014年4月方案公司出货量排行榜2014-06-23 3035
-
2014年10月 TIOBE 编程语言排行榜发布2014-12-08 3260
-
小米放出“手机电量排行榜” 为续航神机Max 2造势2017-06-03 8575
-
MapReduce框架音乐排行榜案例2019-10-16 3733
-
求职必知独角兽公司排行榜2020-06-18 3772
-
2019年2月编程语言排行榜分享2020-07-14 3721
-
2020年最新主板型号排行榜 精选资料推荐2021-07-26 8978
-
华为荣获手机推荐度排行榜第一2021-01-21 3595
-
小米斩获2020年手机推荐度排行榜前三2021-01-22 2402
-
开源大模型Falcon(猎鹰) 180B发布 1800亿参数2023-09-18 2657
全部0条评论

快来发表一下你的评论吧 !
