

ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
描述
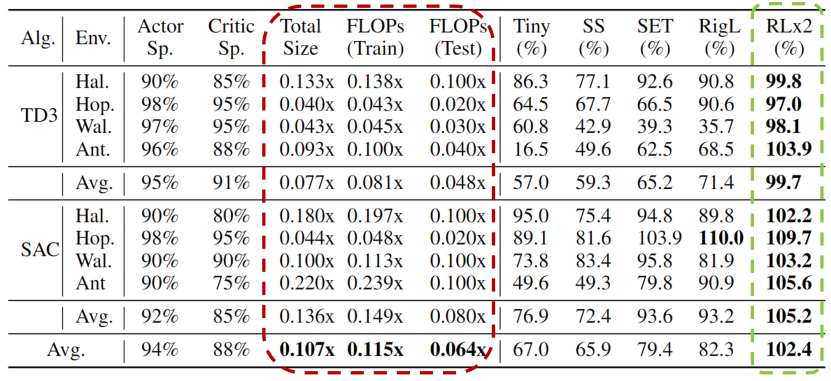
深度强化学习模型的训练通常需要很高的计算成本,因此对深度强化学习模型进行稀疏化处理具有加快训练速度和拓展模型部署的巨大潜力。然而现有的生成小型模型的方法主要基于知识蒸馏,即通过迭代训练稠密网络,训练过程仍需要大量的计算资源。另外,由于强化学习自举训练的复杂性,训练过程中全程进行稀疏训练在深度强化学习领域尚未得到充分的研究。 清华大学黄隆波团队提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),可适用于多种离策略强化学习算法。它采用基于梯度的拓扑演化原则,能够完全基于稀疏网络训练稀疏深度强化学习模型。RLx2 引入了一种延迟多步差分目标机制,配合动态容量的回放缓冲区,实现了在稀疏模型中的稳健值学习和高效拓扑探索。在多个 MuJoCo 基准任务中,RLx2 达到了最先进的稀疏训练性能,显示出 7.5 倍至 20 倍的模型压缩,而仅有不到 3% 的性能降低,并且在训练和推理中分别减少了高达 20 倍和 50 倍的浮点运算数。大模型时代,模型压缩和加速显得尤为重要。传统监督学习可通过稀疏神经网络实现模型压缩和加速,那么同样需要大量计算开销的强化学习任务可以基于稀疏网络进行训练吗?本文提出了一种强化学习专用稀疏训练框架,可以节省至多 95% 的训练开销。

- 论文主页:https://arxiv.org/abs/2205.15043
- 论文代码:https://github.com/tyq1024/RLx2
图:基于强化学习的 AlphaGo-Zero 在围棋游戏中击败了已有的围棋 AI 和人类专家 高昂的资源消耗限制了深度强化学习在资源受限设备上的训练和部署。为了解决这一问题,作者引入了稀疏神经网络。稀疏神经网络最初在深度监督学习中提出,展示出了对深度强化学习模型压缩和训练加速的巨大潜力。在深度监督学习中,SET [Mocanu et al. 2018] 和 RigL [Evci et al. 2020] 等常用的基于网络结构演化的动态稀疏训练(Dynamic sparse training - DST)框架可以从头开始训练一个 90% 稀疏的神经网络,而不会出现性能下降。
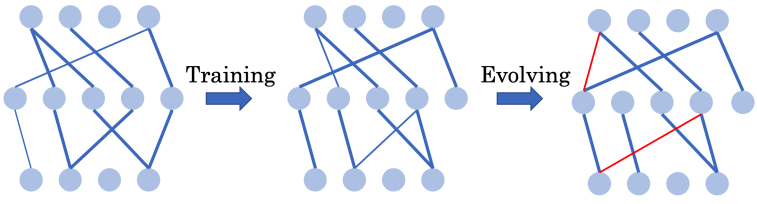
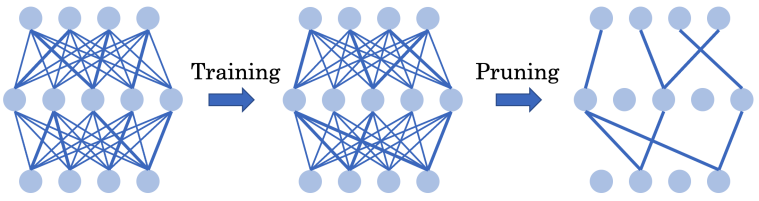
能否通过全程使用超稀疏网络从头训练出高效的深度强化学习智能体?
方法 清华大学黄隆波团队对这一问题给出了肯定的答案,并提出了一种强化学习专用的动态稀疏训练框架,“Rigged Reinforcement Learning Lottery”(RLx2),用于离策略强化学习(Off-policy RL)。这是第一个在深度强化学习领域以 90% 以上稀疏度进行全程稀疏训练,并且仅有微小性能损失的算法框架。RLx2 受到了在监督学习中基于梯度的拓扑演化的动态稀疏训练方法 RigL [Evci et al. 2020] 的启发。然而,直接应用 RigL 无法实现高稀疏度,因为稀疏的深度强化学习模型由于假设空间有限而导致价值估计不可靠,进而干扰了网络结构的拓扑演化。 因此,RLx2 引入了延迟多步差分目标(Delayed multi-step TD target)机制和动态容量回放缓冲区(Dynamic capacity buffer),以实现稳健的价值学习(Value learning)。这两个新组件解决了稀疏拓扑下的价值估计问题,并与基于 RigL 的拓扑演化准则一起实现了出色的稀疏训练性能。为了阐明设计 RLx2 的动机,作者以一个简单的 MuJoCo 控制任务 InvertedPendulum-v2 为例,对四种使用不同价值学习和网络拓扑更新方案的稀疏训练方法进行了比较。
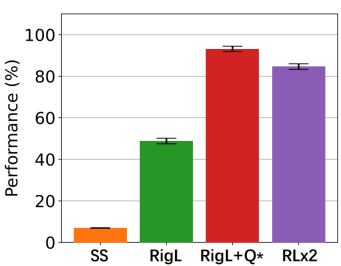
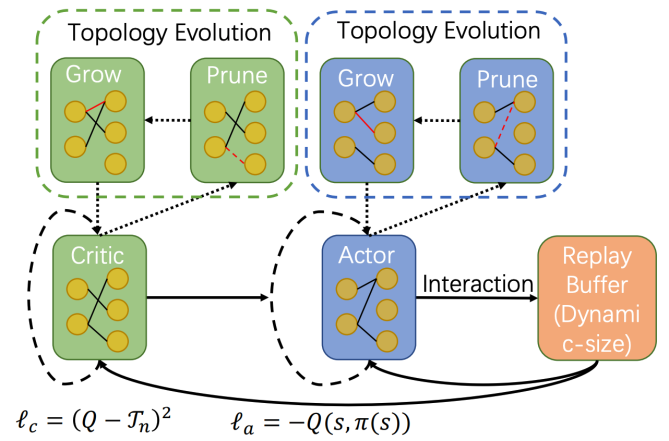
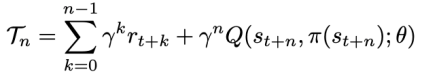

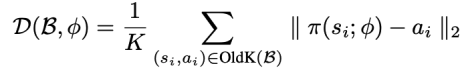
原文标题:ICLR 2023 Spotlight|节省95%训练开销,清华黄隆波团队提出强化学习专用稀疏训练框架RLx2
文章出处:【微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- 物联网
-
C++强化训练2012-08-17 4617
-
深度强化学习实战2021-01-10 2952
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28850
-
基于TensorFlow的开源强化学习框架 Dopamine2018-08-31 5565
-
Google强化学习框架,要满足哪三大特性2018-09-03 3562
-
如何构建强化学习模型来训练无人车算法2018-11-12 5725
-
AI能在单台计算机训练 深度强化学习对处理尤为苛刻2020-07-29 1002
-
虚拟乒乓球手的强化学习模仿训练方法2021-05-12 1248
-
基于强化学习的虚拟场景角色乒乓球训练2021-06-27 1213
-
深度学习框架区分训练还是推理吗2023-08-17 2515
-
视觉深度学习迁移学习训练框架Torchvision介绍2023-09-22 2265
-
什么是强化学习2023-10-30 5911
-
详解RAD端到端强化学习后训练范式2025-02-25 1512
-
强化学习会让自动驾驶模型学习更快吗?2026-01-31 989
-
基于恩智浦RL4MCU框架在MCU上进行深度强化学习训练2026-06-15 174
全部0条评论

快来发表一下你的评论吧 !
