

如何使用分布式存储系统促进AI模型训练
人工智能
描述
在处理小型数据集和简单算法时,传统的机器学习模型可以存储在独立机器或本地硬盘驱动器上。然而,随着深度学习的发展,团队在处理更大的数据集和更复杂的算法时越来越多地遇到存储瓶颈。
这凸显了分布式存储在人工智能(AI)领域的重要性。JuiceFS 是一个开源、高性能的分布式文件系统,为这个问题提供了解决方案。
在本文中,我们将讨论 AI 团队面临的挑战,JuiceFS 如何加速模型训练,以及加速模型训练的常见策略。
AI 团队经常遇到以下挑战:
大型数据集:随着数据和模型大小的增长,独立存储无法满足应用程序需求。因此,分布式存储解决方案成为解决这些问题的必要条件。
完整存档历史数据集:在某些情况下,每天都会生成大量新数据集,并且必须作为历史数据存档。这在自动驾驶领域尤其重要,因为道路测试车辆收集的数据(如雷达和摄像头数据)是公司的宝贵资产。在这些情况下,独立存储被证明是不够的,因此分布式存储成为必要的考虑因素。
小文件和非结构化数据过多:传统的分布式文件系统难以管理大量小文件,导致元数据存储负担沉重。这对于视觉模型尤其成问题。为了解决这个问题,我们需要一个针对存储小文件进行优化的分布式存储系统。这确保了高效的上层训练任务和大量小文件的轻松管理。
用于培训框架的 POSIX 接口:在模型开发的初始阶段,算法科学家通常依靠本地资源进行研究和数据访问。但是,当扩展到分布式存储以满足更大的训练需求时,原始代码通常需要最少的修改。因此,分布式存储系统应支持 POSIX 接口,以最大程度地兼容在本地环境中开发的代码。
共享公共数据集和数据隔离:在某些领域,例如计算机视觉,权威的公共数据集需要在公司内的不同团队之间共享。为了促进团队之间的数据共享,这些数据集通常集成并存储在共享存储解决方案中,以避免不必要的数据重复和冗余。
基于云的训练中的数据 I/O 效率低:基于云的模型训练通常使用对象存储作为存储-计算分离架构的基础存储。但是,对象存储的读写性能不佳可能会导致训练期间出现重大瓶颈。
JuiceFS 如何帮助提高模型训练效率
什么是果汁FS?
JuiceFS 是一个开源、云原生的分布式文件系统,兼容 POSIX、HDFS 和 S3 API。JuiceFS 采用解耦架构,将元数据存储在元数据引擎中,并将文件数据上传到对象存储,提供高性价比、高弹性的存储解决方案。
JuiceFS 的用户遍布 20 多个国家,包括人工智能、互联网、汽车、电信、金融科技等行业的龙头企业。
模型训练场景中 JuiceFS 的架构。
JuiceFS 在模型训练场景中的架构由三个组件组成:
元数据引擎:任何数据库,如 Redis 或 MySQL,都可以用作元数据引擎。用户可以根据自己的需求做出选择。
对象存储:您可以使用公有云或自托管提供的任何受支持的对象存储服务。
果汁FS客户端:要像访问本地硬盘一样访问 JuiceFS 文件系统,用户需要将其挂载在每个 GPU 和计算节点上。
底层存储依赖于对象存储中的原始数据,每个计算节点都有一些本地缓存,包括元数据和数据缓存。
JuiceFS 设计允许在每个计算节点上多级本地缓存:
第一级:基于内存的缓存
第二级:基于磁盘的缓存
对象存储仅在缓存渗透时访问。
对于独立模型,在第一轮训练中,训练集或数据集通常不会命中缓存。但是,从第二轮开始,有了足够的缓存资源,几乎不需要访问对象存储。这可以加速数据 I/O。
JuiceFS 中的读写缓存流程
我们之前比较了使用或不使用缓存来训练访问对象存储时的效率。结果表明,JuiceFS 的元数据缓存和数据缓存,与对象存储相比,平均性能提升了 4 倍以上,性能提升了近 7 倍。
下图显示了在 JuiceFS 中读写缓存的过程:
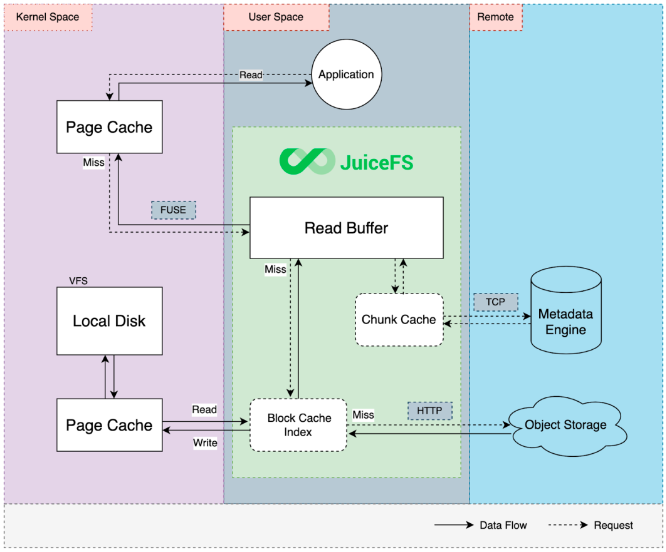
JuiceFS 的读写缓存流程
对于上图中的“块缓存”,块是 JuiceFS 中的一个逻辑概念。每个文件分为多个 64 MB 的块,以提高大文件的读取性能。这些信息缓存在 JuiceFS 进程的内存中,以加速元数据访问效率。
JuiceFS 中的读缓存流程:
1. 应用程序(可以是 AI 模型训练应用程序,也可以是任何启动读取请求的应用程序)发送请求。
2. 请求进入左侧的内核空间。内核检查请求的数据在内核页面缓存中是否可用。如果没有,请求会回到用户空间中的 JuiceFS 进程,该进程处理所有读写请求。
默认情况下,JuiceFS 在内存中维护一个读取缓冲区。当请求无法从缓冲区检索数据时,JuiceFS 会访问块缓存索引,这是一个基于本地磁盘的缓存目录。JuiceFS 将文件划分为 4 MB 块进行存储,因此缓存粒度也是 4 MB。
例如,当客户端访问文件的一部分时,它仅将与该部分数据对应的 4 MB 块缓存到本地缓存目录,而不是整个文件。这是 JuiceFS 与其他文件系统或缓存系统的显著区别。
3. 块缓存索引在本地缓存目录中快速定位文件块。如果找到文件块,JuiceFS 会从本地磁盘读取,进入内核空间,并将数据返回给 JuiceFS 进程,再将数据返回给应用。
4. 读取本地磁盘数据后,也会缓存在内核页面缓存中。这是因为如果不使用直接 I/O,Linux 系统会默认将数据存储在内核页面缓存中。内核页面缓存可加快缓存访问速度。如果第一个请求命中并返回数据,则请求不会通过用户空间 (FUSE) 层中的文件系统进入用户空间进程。如果没有,JuiceFS 客户端会通过缓存目录来获取这些数据。如果在本地找不到,则会将网络请求发送到对象存储,然后提取数据并将其返回到应用程序。
5. 当 JuiceFS 从对象存储下载数据时,数据会异步写入本地缓存目录。这可确保下次访问同一块时,可以在本地缓存中命中该块,而无需再次从对象存储中检索它。
与数据缓存不同,元数据缓存时间更短。为了确保强一致性,默认情况下不缓存 Open 操作。考虑到元数据流量较低,其对整体 I/O 性能的影响很小。但是,在小文件密集型场景中,元数据的开销也占据了一定的比例。
为什么AI模型训练太慢?
当你使用 JuiceFS 进行模型训练时,性能是你应该考虑的关键因素,因为它直接影响训练过程的速度。有几个因素可能会影响 JuiceFS 的培训效率:
元数据引擎
元数据引擎(如 Redis、TiKV 或 MySQL)的选择会在处理小文件时显著影响性能。一般来说,Redis 比其他数据库快 3-5 倍。如果元数据请求速度较慢,请尝试使用更快的数据库作为元数据引擎。
对象存储
对象存储会影响数据存储访问的性能和吞吐量。公有云对象存储服务提供稳定的性能。如果您使用自建对象存储(例如 Ceph 或 MinIO),则可以优化组件以提高性能和吞吐量。
本地磁盘
缓存目录存储的位置对整体读取性能有重大影响。在高缓存命中率的情况下,缓存磁盘的 I/O 效率会影响整体 I/O 效率。因此,您必须考虑存储类型、存储介质、磁盘容量和数据集大小等因素。
网络带宽
第一轮训练后,如果数据集不足以在本地完全缓存,网络带宽或资源消耗会影响数据访问效率。在云中,不同的机器型号具有不同的网卡带宽。这也会影响数据访问速度和效率。
内存大小
内存大小会影响内核页缓存的大小。当有足够的内存时,剩余的可用内存可以作为 JuiceFS 的数据缓存。这可以进一步加快数据访问速度。
但是,当可用内存很少时,您需要通过本地磁盘获取数据访问权限。这会导致访问开销增加。此外,在内核模式和用户模式之间切换会影响性能,例如系统调用的上下文切换开销。
如何排查 JuiceFS 中的问题
JuiceFS 提供了许多工具来优化性能和诊断问题。
工具#1:命令juicefs profile
您可以运行该命令来分析访问日志以进行性能优化。挂载每个文件系统后,都会生成访问日志。但是,访问日志不会实时保存,仅在查看时显示。juicefs profile
与查看原始访问日志相比,该命令聚合信息并执行滑动窗口数据统计信息,按响应时间从高到低对请求进行排序。这有助于您专注于响应时间较慢的请求,进一步分析请求与元数据引擎或对象存储之间的关系。juicefs profile
工具#2:命令juicefs stats
该命令从宏观角度收集监视数据并实时显示。它监控当前挂载点的 CPU 使用率、内存使用率、内存中的缓冲区使用率、FUSE 读/写请求、元数据请求和对象存储延迟。通过这些详细的监控指标,可以轻松查看和分析模型训练期间的潜在瓶颈或性能问题。juicefs stats
其他工具
JuiceFS 还提供了 CPU 和堆分析的性能分析工具:
CPU 分析工具分析了 JuiceFS 进程执行速度的瓶颈,适合熟悉源代码的用户。
堆分析工具会分析内存使用情况,尤其是在 JuiceFS 进程占用大量内存时。有必要使用堆分析工具来确定哪些函数或数据结构消耗了大量内存。
加速AI模型训练的常用方法
元数据缓存优化
您可以通过两种方式优化元数据缓存,如下所示。
调整内核元数据缓存的超时
参数 、 和对应于不同类型的元数据:--attr-cache--entry-cache--dir-entry-cache
attr表示文件属性,例如大小、修改时间和访问时间。
entry表示 Linux 中的文件和相关属性。
dir-entry表示目录及其包含的文件。
这些参数分别控制元数据缓存的超时。
为了保证数据的一致性,这些参数的默认超时值仅为1秒。在模型训练场景中,不会修改原始数据。因此,可以将这些参数的超时时间延长到几天甚至一周。请注意,元数据缓存无法主动失效,只能在超时期限到期后刷新。
优化 JuiceFS 客户端的用户级元数据缓存
打开文件时,元数据引擎通常会检索最新的文件属性以确保强一致性。但是,由于通常不会修改模型训练数据,因此可以启用该参数,并且可以设置超时以避免每次打开同一文件时重复访问元数据引擎。
此外,该参数控制缓存文件的最大数量。默认值为 10,000,这意味着最近打开的 10,000 个文件的元数据最多将缓存在内存中。可以根据数据集中的文件数调整此值。
数据缓存优化
JuiceFS 数据缓存包括内核页面缓存和本地数据缓存:
内核页面缓存不能通过参数调整。因此,在计算节点上预留足够的空闲内存,以便 JuiceFS 能够充分利用它。如果计算节点上的资源紧张,JuiceFS 不会在内核中缓存数据。
本地数据缓存可由用户控制,缓存参数可根据具体场景进行调整。
调整缓存大小,默认值为 100 GB,这足以满足大多数方案的需求。但是,对于占用特别大的存储空间的数据集,需要适当调整缓存大小。否则 100 GB 的缓存空间可能会很快被填满,使得 JuiceFS 无法缓存更多数据。
另一个可以与之一起使用的参数是 。它确定缓存磁盘上的可用空间量。默认值为 0.1,它允许将最多 90% 的磁盘空间用于缓存数据。
JuiceFS 也支持同时使用多个缓存盘。建议尽可能使用所有可用磁盘。数据将通过轮询均匀分布到多个磁盘,实现负载均衡,最大化多个磁盘的存储优势。
缓存预热
为了提高训练效率,您可以使用缓存预热来加速训练任务。JuiceFS 支持在客户端预热元数据缓存和本地数据缓存。该命令会提前构建缓存,以便在训练任务开始时缓存可用,从而提高效率。
增加缓冲区大小
缓冲区大小也会影响读取性能。默认情况下,缓冲区大小为 300 MB。但在高通量训练场景中,这可能还不够。您可以根据训练节点的内存资源调整缓冲区大小。
一般来说,缓冲区大小越大,读取性能越好。但不要将值设置得太大,尤其是在最大内存有限的容器环境中。有必要根据实际工作负载设置缓冲区大小,并找到一个相对合理的值。可以使用本文前面介绍的命令实时监视缓冲区使用情况。
审核编辑:郭婷
-
AI Ceph 分布式存储教程资料大模型学习资料20262026-05-01 226
-
完结9章 AI训练师 入门与实战 教程资料20262026-05-28 47
-
分布式存储架构:第三节 分布式文件模型 #分布式架构 #分布式存储系统 #分布式系统 #硬声创作季学习硬声知识 2022-10-21
-
存储分布式系统中如何从CAP转到PACELC2018-06-10 3178
-
关于腾讯的开源分布式存储系统DCache2019-08-01 2534
-
盘点分布式存储系统的主流框架2020-08-06 3275
-
分布式文件存储系统GFS的基础知识2020-08-25 6967
-
常见的分布式存储系统有哪些类型2020-11-09 29997
-
分布式存储系统联合解决方案的优势是什么2021-01-22 2857
-
分布式存储系统与纠删码技术背景2021-06-01 3681
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 4237
-
黑龙江电力高性能WDS分布式存储系统解决方案2024-07-01 1463
-
基于分布式存储系统医疗影像数据存储解决方案2024-09-14 2044
-
WDS分布式存储系统软件助力电信工程海量数据存储项目2024-11-11 1240
-
Ceph分布式存储系统解析2025-07-14 1531
全部0条评论

快来发表一下你的评论吧 !
