

Armv9核心A710、A715和A510微架构解读
处理器/DSP
描述
1、引言
在上一篇文章“从A76到A78——在变化中学习Arm微架构”中,我们了解了Arm处理器微架构的基本组成,介绍了Armv8架构最后几代经典处理器架构。现在,Arm公司已经在2021年3月推出了其最新的Armv9架构系列处理器,距上一代Armv8系列架构发布相隔了整整10年时间。新一代的Armv9产品,不但会带来更强大的计算性能,在安全、AI等领域也带来了全新的设计。可以说,Armv9系列继承了Armv8架构的优势,同时也为Arm公司的下一个十年拉开了帷幕。本文将着重介绍基于Armv9架构的A710、A715、A510等处理器架构,让大家了解Armv9架构和Armv8架构的差异。
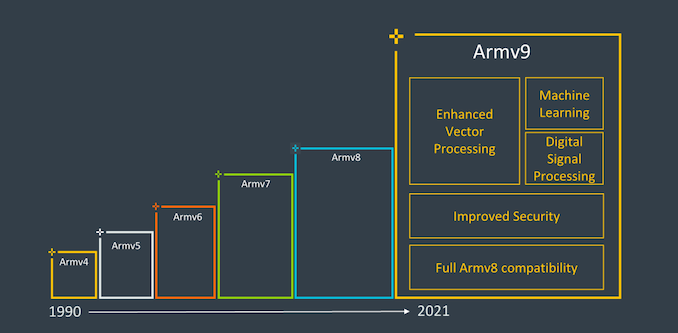
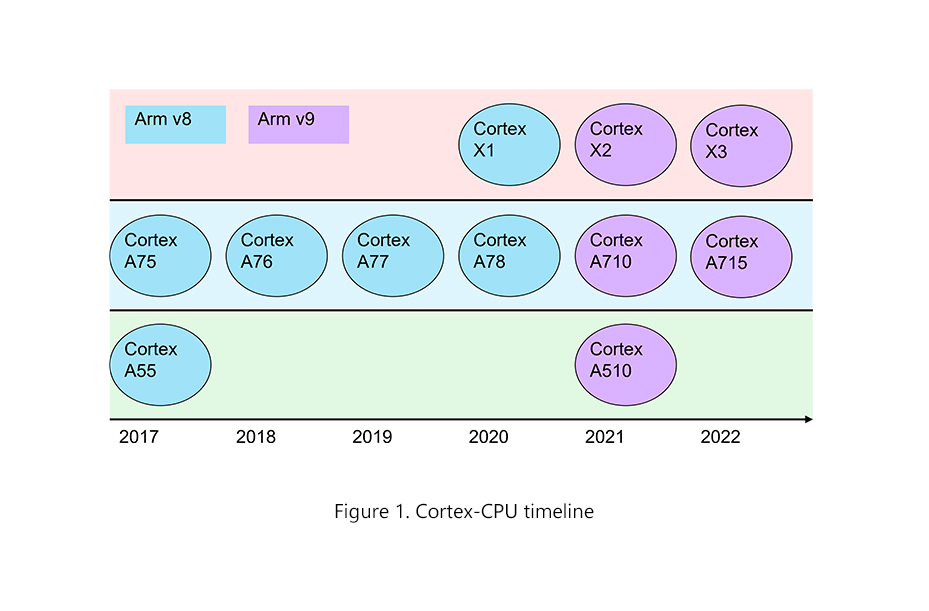
2、Arm的Cortex-X定制CPU计划
在介绍Armv9系列前,我们先看一下ARM的Cortex-X定制CPU计划。Cortex-X方案先于Armv9发布,在Arm发布A78时,同时也发布了Cortex-X1这一颗性能强大的CPU,后续大家习惯称之为超级大核。从此,旗舰处理器的架构从4+4(4大+4小)逐步变成了1+3+4(1超大+3大+4小)架构。Cortex-X计划不但带来了如X1这样的超级大核心设计,也允许厂商参与定制Cortex-X系列的核心设计。X系列超级大核心相比A系列大核心,拥有更大的芯片面积,同时支持更多的发射和解码能力,还增加了缓存和ROB空间等,图中Arm宣称X1相比A78的性能提升超过30%。后续计划专门写一篇文章介绍Cortex-X的系列处理器。

3、64bit应用生态
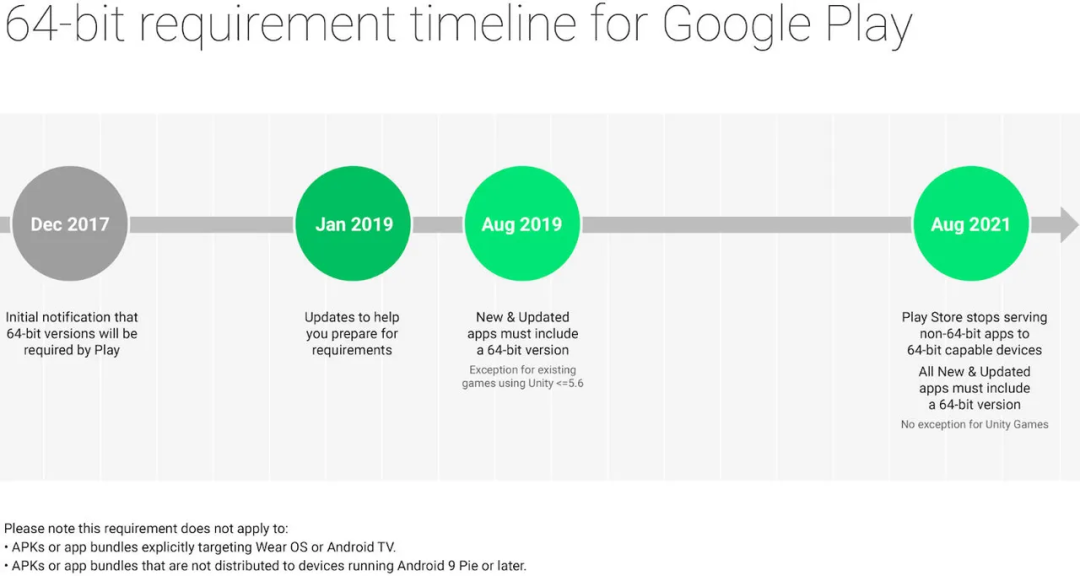
32bit和64bit应用兼容问题已经历经多年讨论,主流的苹果和安卓平台都明确表示要切换到64bit以提供更大的应用访问空间和支持处理器的最新特性。苹果公司在2017年的iOS11中就强制要求开发者切换到64bit应用,谷歌公司则要求安卓开发者在2021年将上传的应用完全切换到64bit。但是,由于安卓系统的开放性,应用商店的多样性,且开发者可以自由安装应用,市场上的应用商店的存量应用更新64bit的速度较慢,直到2021年的Armv9处理器,我们明确看到了存量32bit应用对于使用的影响。
2021年,Armv9第一代的A510处理器和Cortex-X2处理器不支持运行32bit应用,但是A710处理器是可以支持的,所以采用X2+A710+A510的处理器(例如骁龙8Gen1)只支持在3颗A710中运行32bit应用,运行32bit应用时存在高耗电和卡顿的风险。
2022年,Armv9第二代的A510r处理器增加了32bit应用支持,但是Cortex-X3和A715处理器不支持运行32bit处理器,所以如果采用X3+A715+A510r(1+3+4)的处理器(例如天玑9200)只支持在4颗A510r小核运行32bit应用,运行32bit应用会有严重的卡顿风险(MTK也提供了对应的优化方案)。相信高通也提前预判到了这个风险,在2022年的骁龙8Gen2设计中,采用了X3+A715+A710+A510r(1+2+2+3)的架构,提供了2颗兼容32bit的A710大核心,从另一个角度消解了大核心无法运行32bit应用的风险。
希望安卓和Arm可以在2023年实现纯64bit的计划。
4、SVE2扩展指令集
Armv9和Armv8在核心指令集上变化不大,依然采用AArch64。Arm自v7开始推出的NEON指令集作为向量扩展指令,可以大幅度提高多媒体运行的效率,无疑是非常成功的,这次Armv9给大家带来了全新的SVE2(Scalable Vector Extension 2)扩展指令集。
SVE2是基于SVE的扩展,实际上SVE在2016年就有发布,SVE2在2019年也专门对外进行过发布。我们在了解处理器微架构的执行单元时,可以看到浮点运算单元中提供了多种SIMD的运算模块。SVE2有三个特点,一是基于SVE指令集的扩展,二是提升了扩展性,三是支持更多类型任务的矢量化运算。举个例子,NEON指令是固定的128bits,SVE2指令则可以从128bits到扩展到最大2048bits。

虽然扩展指令集听起来很香,实际使用起来并不是在编译器中打开编译开关就可以高枕无忧的,编译器虽然提供了一些基础能力,可将一些固定计算逻辑转换成扩展指令集,但若想要充分利用扩展指令集的能力,还是需要开发者充分学习扩展指令集的能力,通过专用的编程语法(Intrinsics )甚至去写扩展指令集的专用汇编,通过合理的逻辑排序组合,充分利用指令集的优势,才能获得最佳的效果。
5、聊聊Arm的产品代号
A710的产品代号叫做Matterhorn(马特洪峰),海拔4478米,阿尔卑斯山系最著名的山脉之一。
A715的产品代号叫做Makalu(马卡鲁峰)海拔8463米,属于喜马拉雅山脉,是世界第五高峰。
A510的产品代号叫做Klein(克莱因),CK里面的K就是这个单词。
A715的下一代产品代号叫做Hunter(猎人),Hunter下一代产品代号叫做Chaberton。
A510的下一代产品代号则叫做Hayes(海因斯)。
有时候我不禁联想,Matterhorn和Makalu两座高山,可能代表着工程师想挑战的高度吧!
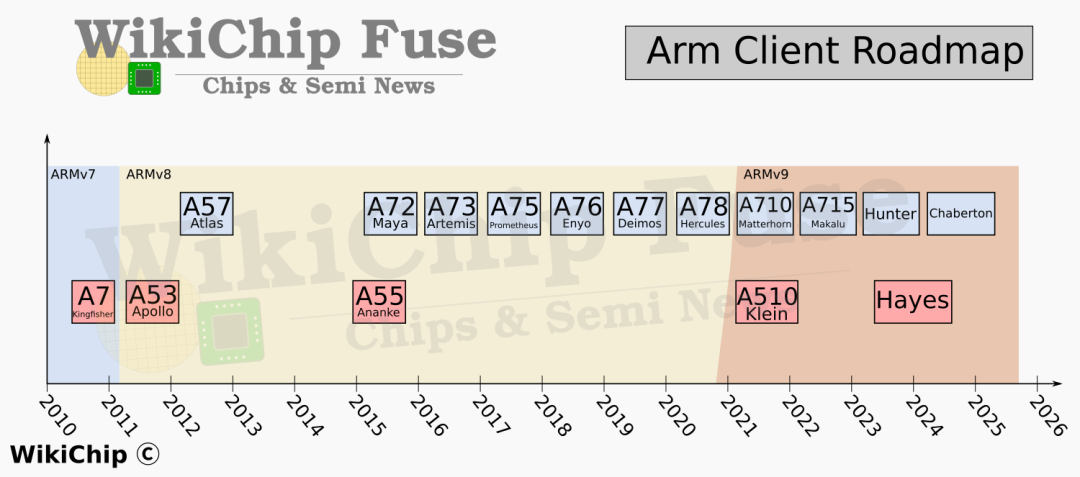
ARM处理器路线图
6、A710和A715微架构介绍
6.1 A78回顾
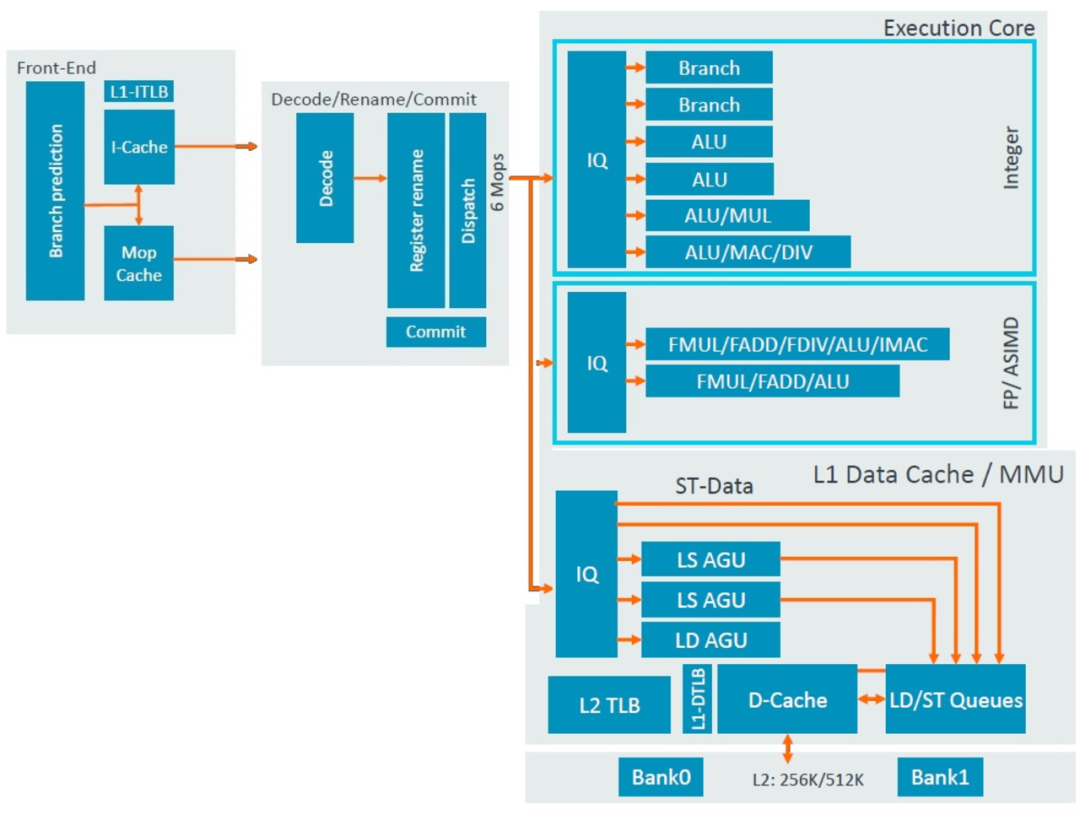
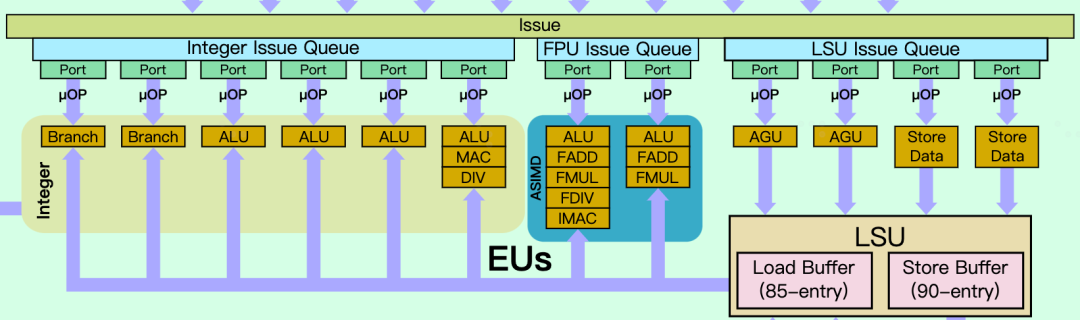
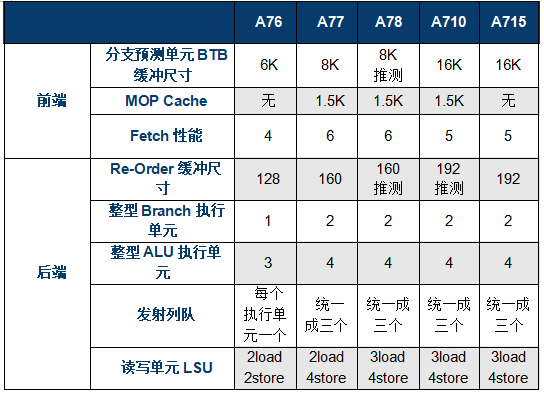
文章都写了一半了,终于到聊到正题了?还没有!因为A710是基于A78微架构优化而来,我们先要先回顾一下A78。这里和大家快速回顾下A78的微架构,4路decode,加上Mop Cache可以一次最多提供6路Mops指令进入执行单元,整数执行单元提供2个Branch,4个ALU,浮点单元提供2个FPU,存储单元提供2个LS AGU,1个LD AGU和2个ST-Data通路。
6.2 A710和A715简介
A710是Armv9家族的第一颗大核心,A710也是第一次正式引入了SVE2扩展指令集,A710没有放弃32bit的支持,可以同时兼容32bit和64bit应用。
A715是Armv9家族的第二颗大核心,值得注意的是核心序号只加了5,难道Arm觉得还达不到A720的预期?我们后续揭晓。A715相比A710最大的变化是轻装上阵,抛弃了32bit的支持,让设计师可以更加聚焦设计一款纯64bit的核心。
6.3 A710能效

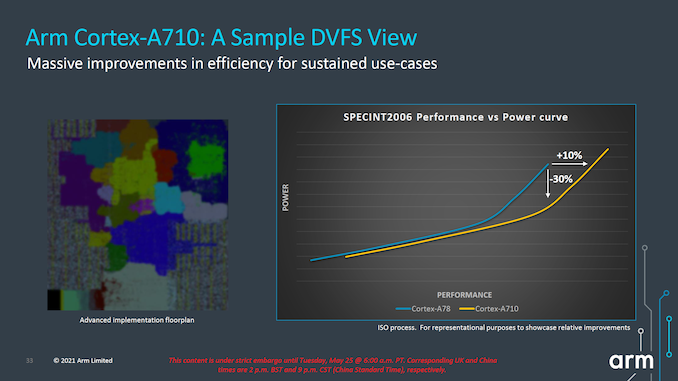
Arm在A710这一代产品希望重点优化能效。根据Arm提供的性能功耗曲线数据,A710依然是一颗高能效比的核心,相比A78在同样的能耗下性能可以提升约10%,同样的性能条件下功耗可以降低约30%,需要注意2点,第一是这个数据是在高频率区间取得的,低频率区间的能效曲线和A78较为接近;第二是性能的提升是在L3缓存增加情况下得出的,缓存增大理论也贡献了一部分性能得分。
可惜A710的出生似乎有些生不逢时,大家寄予厚望的采用了A710的第一代产品高通骁龙8Gen1处理器,由于采用了三星工艺代工,整体能效表现一般,直到高通公司第二年将工艺切换TSMC并量产了骁龙8+Gen1芯片,整体芯片能效有了明显提升,才发挥出了A710应有的实力。
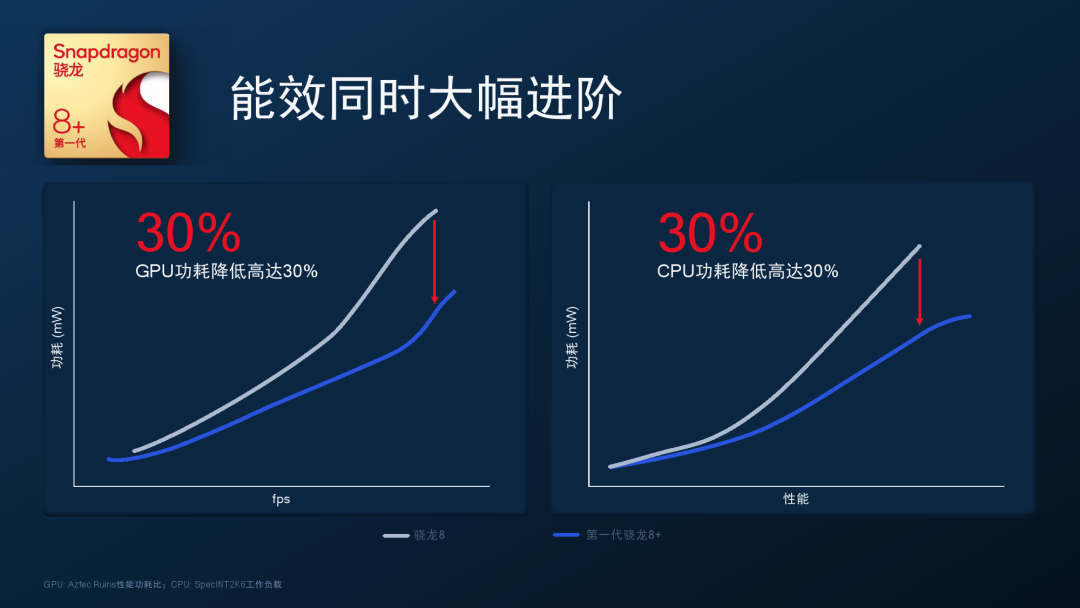
骁龙8+Gen1和8Gen1能效对比数据
6.4 A710架构设计

A710在前端设计部分上和A78差异不大,同样提供了1.5K的MOP cache,提供了可动态配置3264KB的L1缓存和可动态配置256512KB的L2缓存。Arm在A710上的优化点是提升了分支预测的能力,将关键的分支预测结构体容量空间翻了一番,此外L1的TLB容量也翻了一倍。
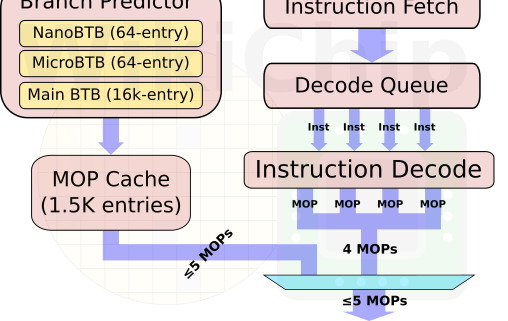

A710微架构的一个关键的修改在指令分发Dispatch模块,该模块发生了一些有趣的变化,大家还记得A77新引入MOP cache时就是4路decode和6路dispatch,A78同样继承如此,到了A710上Arm将其减少到了5路dispatch。减少一条通路意味着可以节省芯片电路和面积,另一方向性能上也难免会有一定的损失。为了弥补这个损失,Arm宣称做了一系列基于MOP cache的优化,并将分支预测到分支执行的流水线缩减到10个时钟周期,从而达成宣称的能效优化指标。

目前网络上A710的资料并不多,特别缺乏后端设计部分的详细资料,根据推测后端设计和A78比差异不大,推测ROB应该会增加,推测访存LSU的单元和A78没有明显变化,后续我们可以在A715上再次论证。
Arm还提到A710通过优化数据预取(prefetcher)来提升性能和能效,减少CPU的数据预取次数,可以减少对于DSU的访问参数,同业也可以降低对于DRAM的访问次数,从图中数据看,相比A78,A710在DSU和DRAM的访问上都有明显改善。
简单总结下,A710相比A78的设计仅相隔了一年,并不是一个准备多年的全新架构升级,在A78的基础上,A710保留了32bit的支持,优化了流水线和数据预取能力,前端分支预测和指令通路是最明显的变化。这次Armv9架构升级涉及到X2、A710和A510三款核心,相比之下X2和A510的变化更多,我们后续会详细分析。
6.5 A715能效

目前最新的Arm大核心是A715,从官方数据中我们可以看出A715这一代的目标并不是以提升性能为主,同样功耗下性能只提升了5%,或许这也是被叫做A715的一个原因。在能效方面,相同性能下可以降低20%的功耗。
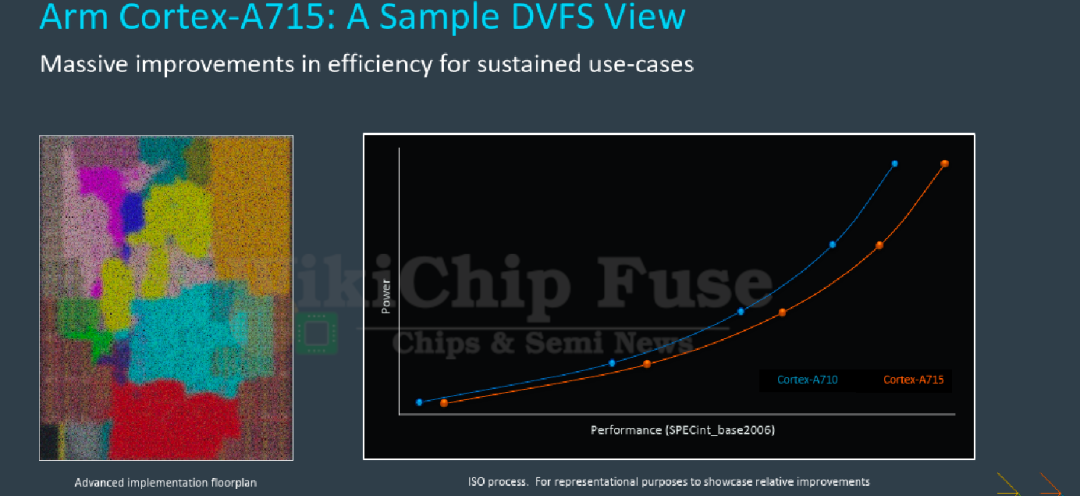
再来看一下DVFS曲线,A715的曲线和A710比较接近,同样功耗下性能有小幅度提升。后续这几代Arm大核心微架构上都不会有像A75、A76那样大幅变化,基本是保持A715对A710这样的稳定功耗优化,性能小幅度提升。
从数据上看,A715整体的能效优化幅度不高,可以认为A715是A710的一个小改款。结合微架构分析整体看,Arm需要一颗更经济的核心来支撑整个产品线以及平衡性能和功耗。
6.6 A715架构设计
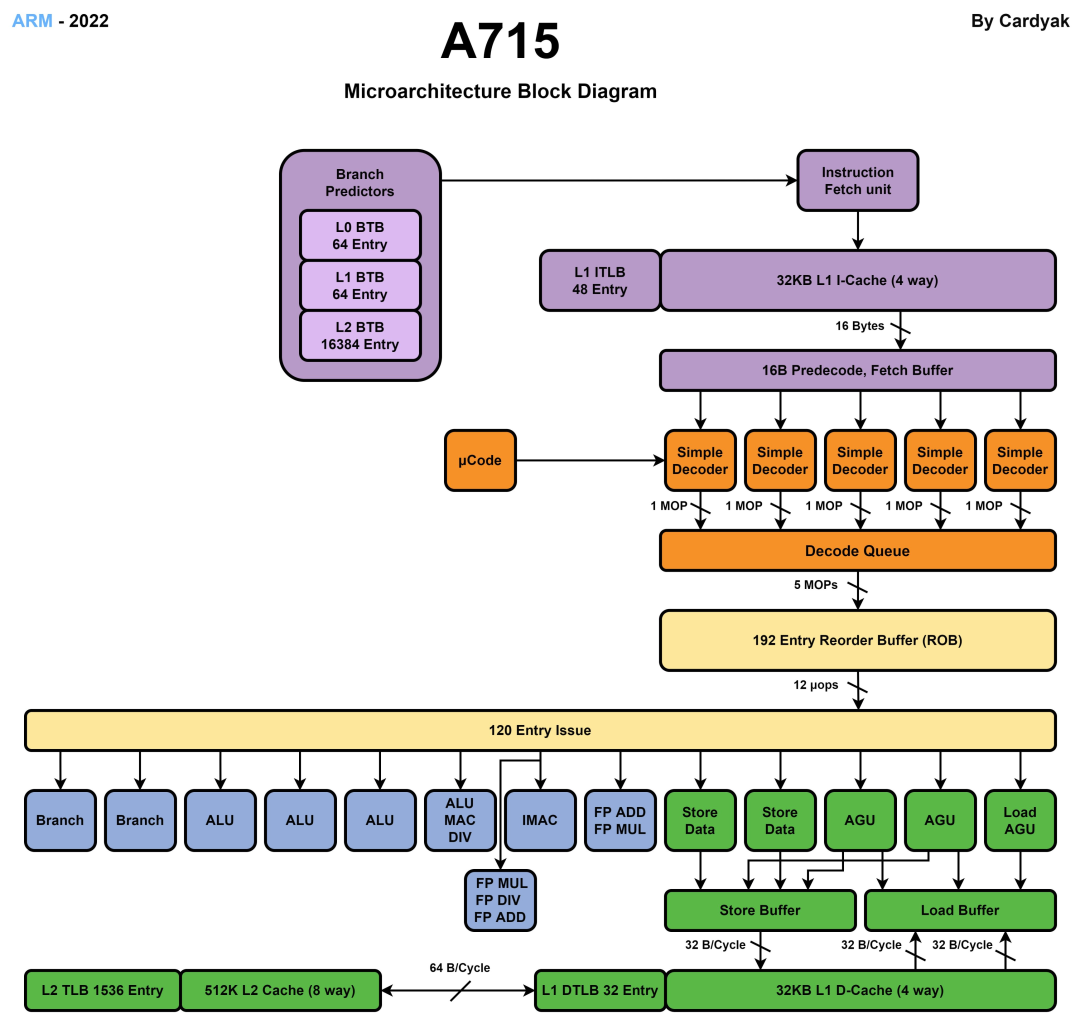
很幸运,网络有高手(Cardyak)放出了A715的微架构图,我们可以借此一窥A77到A715的变化。

A715的前端分支预测能力有了进一步提升,Arm在Armv9上很重视分支预测能力,每一代都有一些优化。A710相比A78提升了分支预测能力,这次A715进一步优化,以提升IPC和能效。细节上,A715将Direction Predictor的容量提升了一倍,从而进一步提升分支预测的准确性。A715每个周期支持预测2个分支,比A710多支持了条件分支的预测能力。此外,在分支预测方案上,Arm传统支持0级和2级预测模型,这次A715将2级预测模型拆分成3级,增加了一个faster turnaroud功能,在发现预测错误时可以快速返回,提升分支预测效率。最后是访问指令缓存(Icache)方面,A715将指令缓存的查找带宽也提升了一倍,从而支持更好的访问指令缓存的效率。
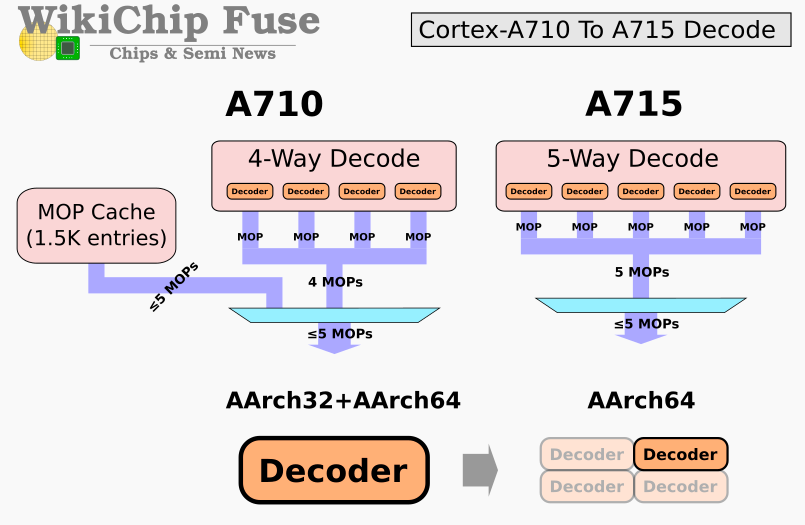

解码模块依然是Armv9重点优化的部分,也是A715变化最大的模块。在A715上有一个关键的修改,Arm出于成本考虑,将自A77开始加入的MOP cache模块移除了。MOP cache可以缓存一些常用的核心指令,降低从L1取指令的负担,但是Arm宣称可以通过其他优化方法,进一步提升性能和能效。第一点,A715是一颗纯64bit的大核心,凭借这一点,可以节省原来为了兼容32bit而增加的晶体管电路;第二是A715上增加了一路decode通路,从4通路提升到5通路,在A710之后Dispatch也改成了5通路,A715这一代Fetch和Dispatch到后端模块的通道正好对齐都是5通路,可以发挥最高的效率;第三是采用了小尺寸的decoder,将原来A710的统一大尺寸decoder拆分成4个小尺寸的decoder,便于分配资源和节省能耗;最后是A715提升了复杂指令(NEONSVESVE2)的吞吐率,让它们可以快速发送到对应的执行单元。
在ROB重排序缓冲方面,A715提供了192个entry,相比A77的160个entry提升了20%,和A77至A715的性能提升可以匹配上。执行单元的Issue entry还是120个,这个大小自A76开始就没有变化。在执行单元上,A715相比A710和A78都没有明显变化,还是2个Branch,4个ALU,浮点单元提供2个FPU,存储单元提供2个LS AGU,1个LD AGU和2个ST-Data通路,看来Arm认为这块的设计非常合理不需要改变。

在存储单元上,A715增大了Load Replay队列尺寸,可以提供更多的数据预取和L2访问机会。此外A715提供了2倍的Data Cache Banks,可以支持更多同步读写数据,降低并发冲突从而降低能耗。A715的L2的TLB entry增大了50%,达到了1.5K个entry,提升了数据预取的准确性,也可以降低内存的访问,进而提升综合性能。
6.7 小结
阶段总结下,A715相比A710的微架构修改较大,A715取消了32bit的支持,取消了MOP cache,优化了分支预测、指令单元和存储单元,统一了指令通路数量,还提出了小decoder的模型。目前A715已经在高通骁龙8Gen2,MTK天玑9200等产品成功应用,搭配最新的4nm工艺,性能和能效表现可圈可点。
7、A510微架构介绍
7.1 A510简介
我们并没有花很多篇幅去介绍A55这颗处理器,因为A55实在是“久经沙场”,伴随着A75登场,历经A75-A78四代产品。到Armv9时代,Arm认为必须更新一下A5x系列的小核心产品线了,于是我们看到了最新的A510系列小核心处理器。
21年Arm更新了A510产品线,22年Arm又做了小幅度优化,更新了A510r产品线。由于Arm维持了每年迭代的产品快速更新策略,进入Armv9后一年需要更新X2、A710和A510三款产品,难免造成资源分散。例如对于32bit的支持问题上,A710支持32bit,X2和A510不支持,但是在22年更新的A510r第二代产品,又加入了32bit的支持。
7.2 A510能效

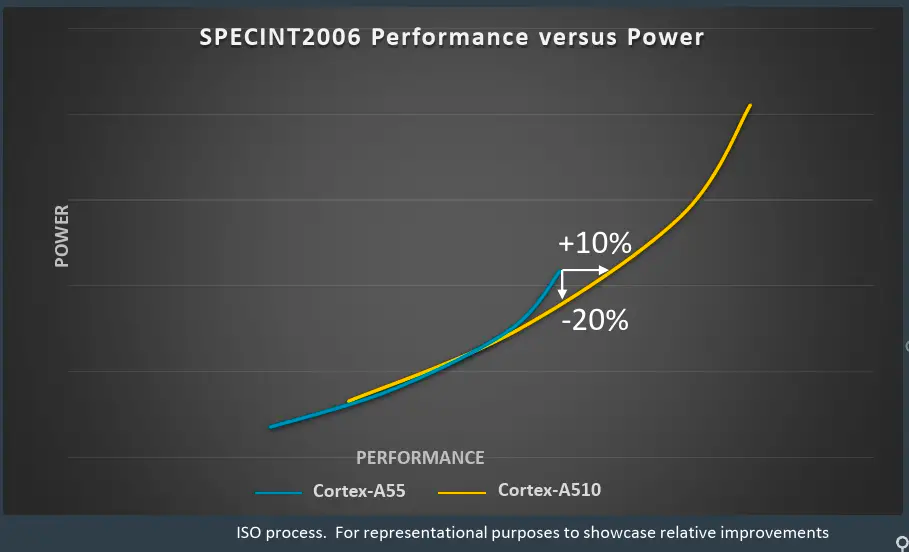
官方数据显示A510可以提升35%的性能,能效优化20%,ML性能是以前A55的3倍。从能效曲线看,性能提升35%都是保守的,后续的架构分析也可以支撑这一说法,但是能效的20%优化要加限定词,限定在A55高频率段区间比较合理,因为整体的功耗和性能提升成正比,简单说就是A510的极限性能和极限功耗都增加了。
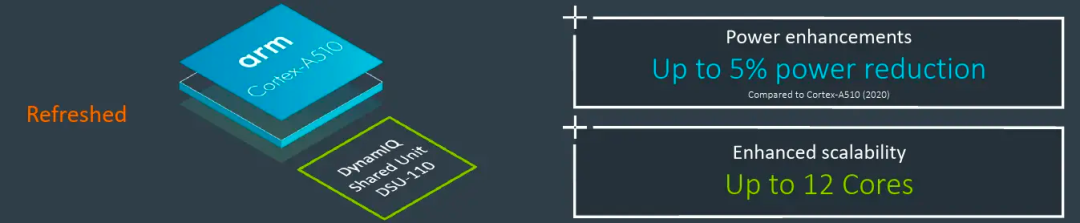
对于A510的能效,Arm也提出后续会不断优化,例如A510r重新设计了一些电路,宣称可以提升5%的能效。下一代的Hayes也会继续优化能效。为什么A510的性能提升,能效没有进一步提升呢?在后面的架构设计部分大家应该可以得出一些推论。
7.3 A510架构设计
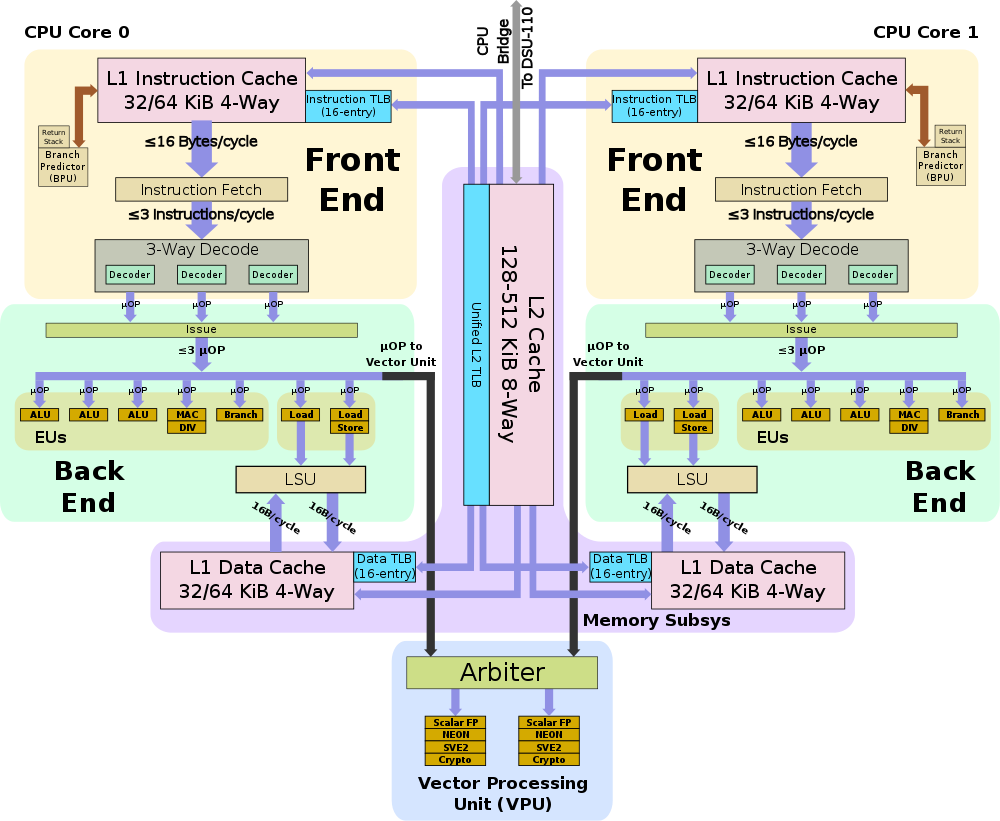
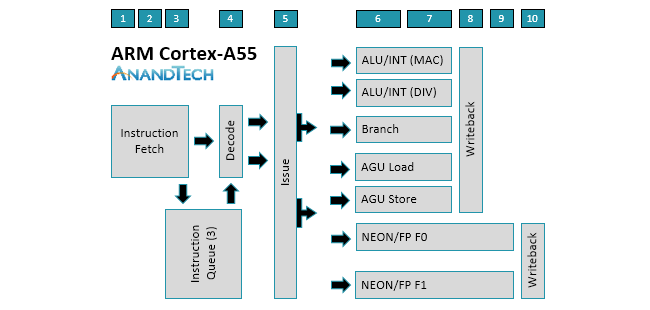
上面是A510的微架构图和A55的架构简图,从图中可以看到A510相比A710的大核心设计,确实有很多简化的地方,但是相比A55还是有明显增强的。
A510和A55一样,是一颗不支持乱序执行(OoO-Out of oder)的核心,不支持OoO意味着没有重排序缓冲(ROB)模块,可以节省芯片面积,缺点则是无法充分填充和利用流水线,指令执行的效率较低。
此外,第一代的A510不支持32bit应用,第二年Arm在A510r上,又把32bit应用的支持加回来了。
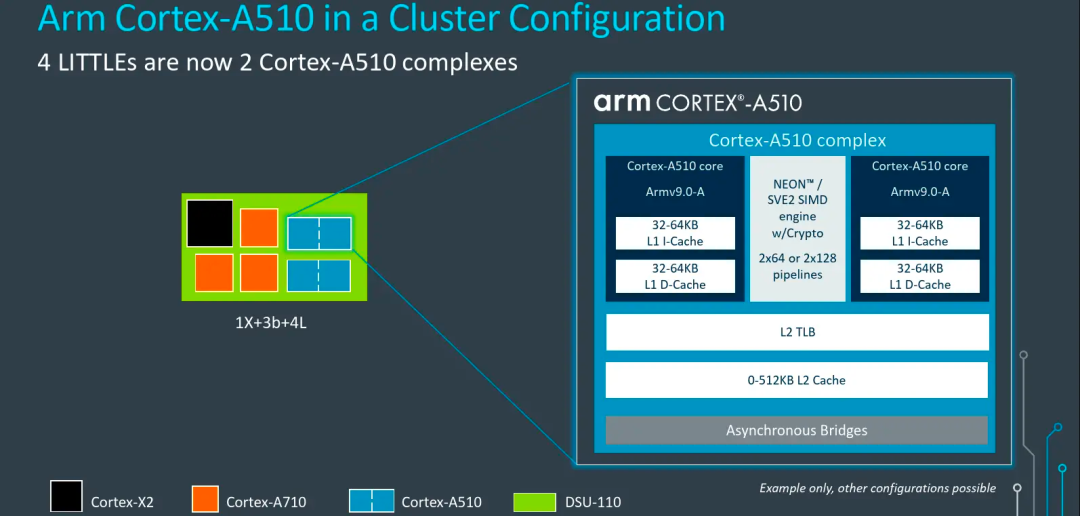
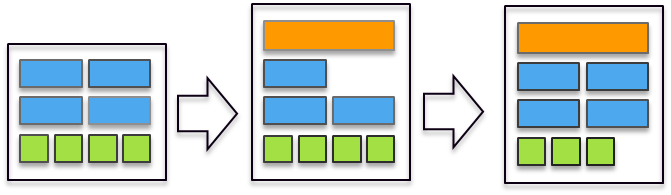
A510为了进一步优化芯片面积,采用了拼接核心设计,如图中所示,两颗A510被封装在一起,共享L2缓存、L2 TLB等模块。这种硬件设计对于软件调度器的设计提供了优化思路,因为共享L2,在2颗共享核心之间调度的效率会高于跨L2,所以软件在选择任务迁移时,如果还是移动到小核心执行,应当优先去选择共享L2的那个CPU去执行,效率会最高。
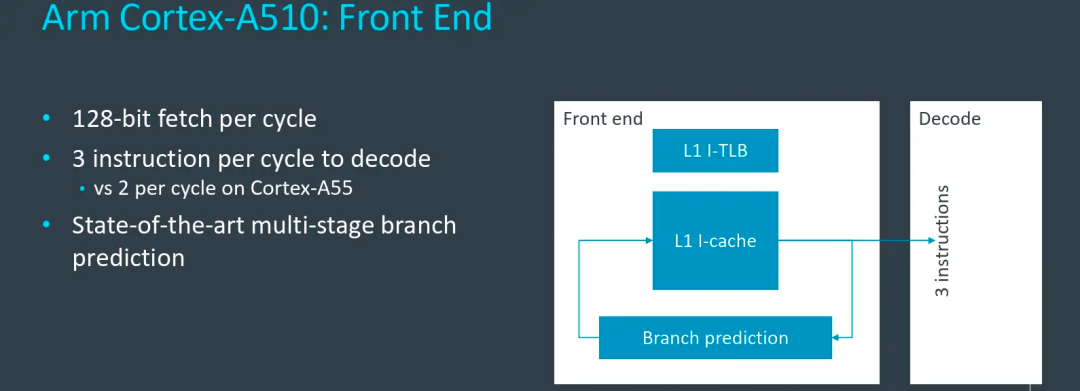
在前端设计上,A510相比A55最大的改变是将2宽度流水线拓展到了3宽度,如指令Fetch能力从2提升到3,等于增加了一条通路,这也是A510同频率性能可以提升的关键影响因素。此外,A55每个周期可以fetch 64-bit,A510每时钟周期则可以fetch128-bit指令。同时,A510还借鉴了Armv9系列架构的分支预测方案设计,相比A55可以提供更为准确的分支预测能力,减少流水线的损失。
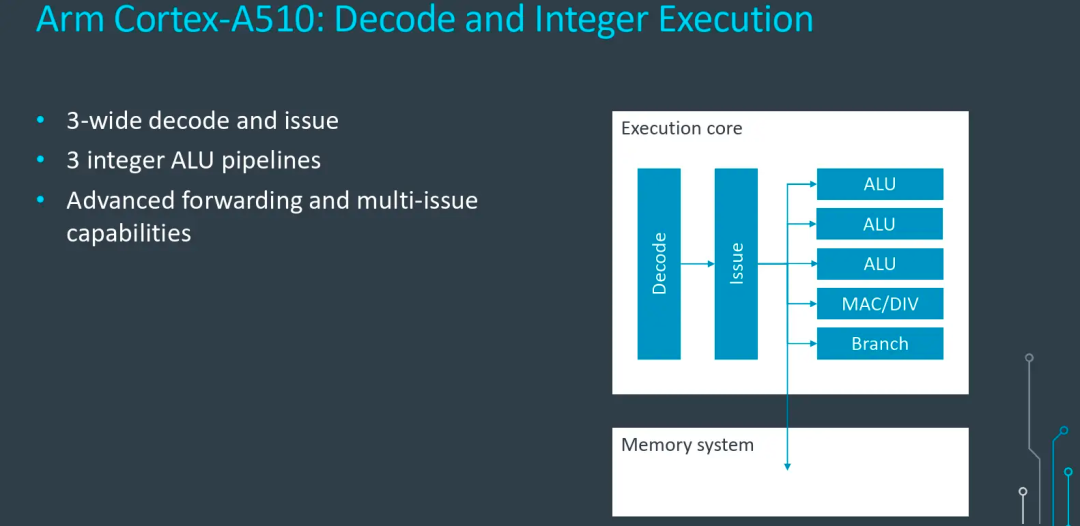
A510相比A55的通路增加是完整的,在指令Fetch模块后,指令Decode和Issue模块的通路也从2增加到3,提升了50%。
运算单元部分,小核心仅有1个Branch单元没有变化,ALU数量(含MAC、DIV)从2提升到4,也提升了50%。FPU(又叫做VPU)被挪到了2个核心共享,虽然无法直接对比,根据Arm提供的数据看FP也有50%的性能提升。
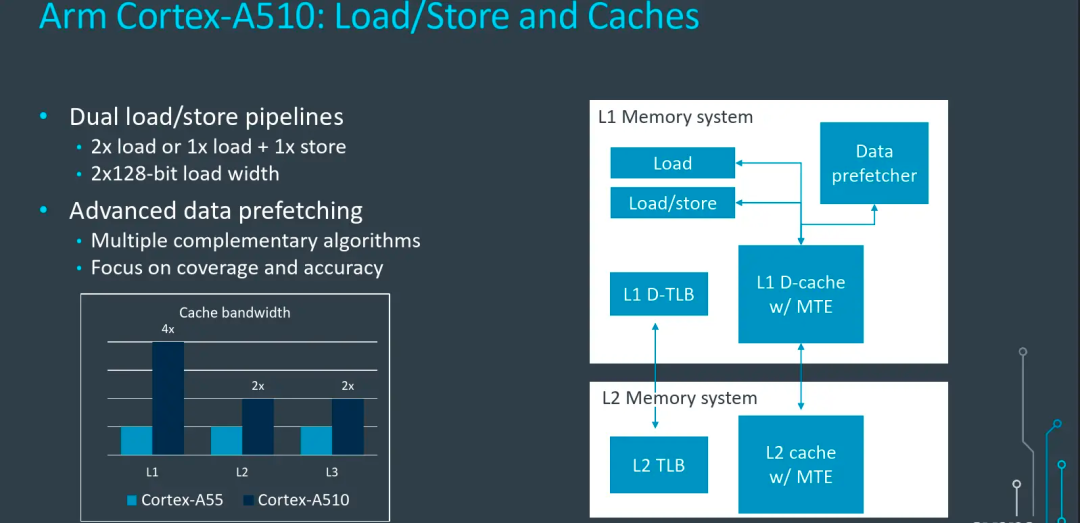
存储模块上,A510相比A55也有明显提升,A55提供了1个Load和1个Store通路,A510虽然还是2通路,但是一个支持Load,另一个同时支持Load和Store,Load能力有提升。同时,Load带宽从A55的64bit提升到128bit,如图中显示L1带宽可以提升4倍,L2和L3分别也提升了2倍。此外,Data Prefetcher模块也引入了Armv9的系列优化,可以提升数据预取准确性。
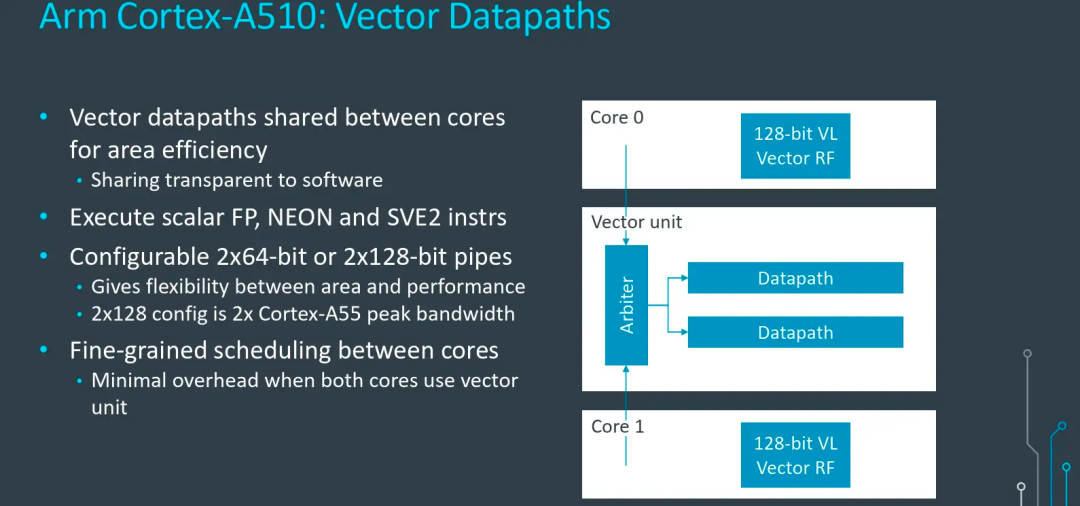
最后,A510的两个核心还共享了矢量运算单元(VPU),用于处理Scalar FP、NEON、SVE2等指令,Arm期望通过这种设计进一步优化小核心的面积,优化能效。
7.4 小结
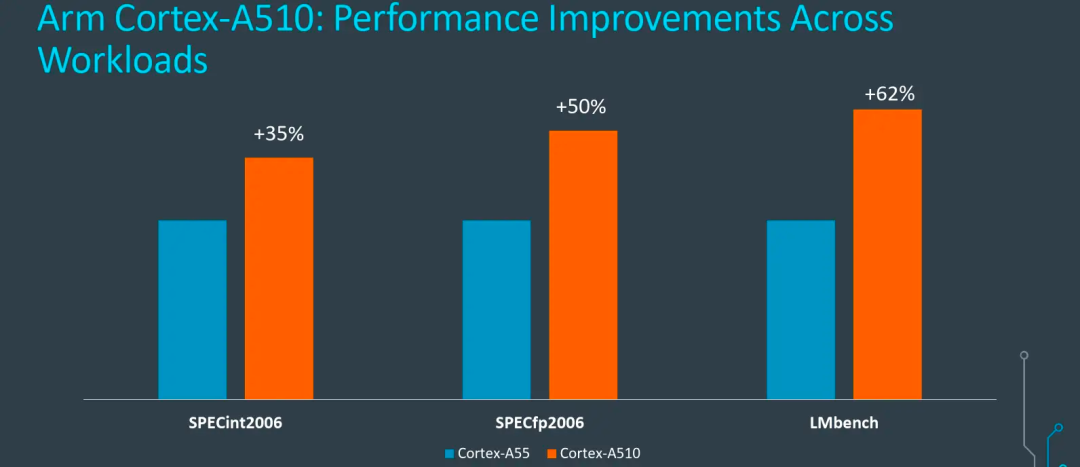
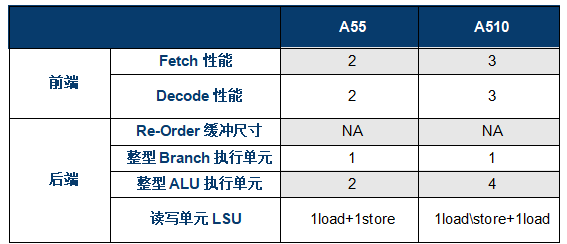
相隔4年,Arm终于更新了A5x系列小核心,看完后还是感觉有点不够过瘾,意犹未尽的感觉。虽然A510相比A55,不论在整数、浮点还是存储性能上都有明显的提升(见上图),但是整体处理器的能效并没有明显的改善,究其根因,这次A510的升级,并没有引入OoO乱序执行等大核心的先进特性,而是基于A55的架构上通过增加通路和运算模块达成的性能提升,总体能效改善不够明显。
A510的这次升级,也导致终端厂商在实际产品开发中,针对A510的小核心的处理需要更加谨慎,例如尽可能利用和A55性能接近的区间,获取最大能效收益,在软件调度时需要考虑2个共享核心内优先调度以获取最低的开销等等。
相信Arm公司对于A5x会持续迭代优化,在后续的A510r和Hayes等产品中,Arm也是提出了不断优化能效的目标。
8、总结
通过本篇文章我们了解了Armv9的大核心A710、A715和小核心A510的微架构设计,以及进入Armv9时代后Arm推进的超级大核心Cortex-X定制计划、SVE2指令集,并讨论了Arm对于32bit和64bit兼容的态度,希望Arm可以持续迭代Armv9系列架构,推动移动处理器持续高速发展,不断提升用户的移动终端体验。由于篇幅限制,本文没有深入讨论超级大核心Cortex-X系列处理器,计划在后续的文章中补完这部分。
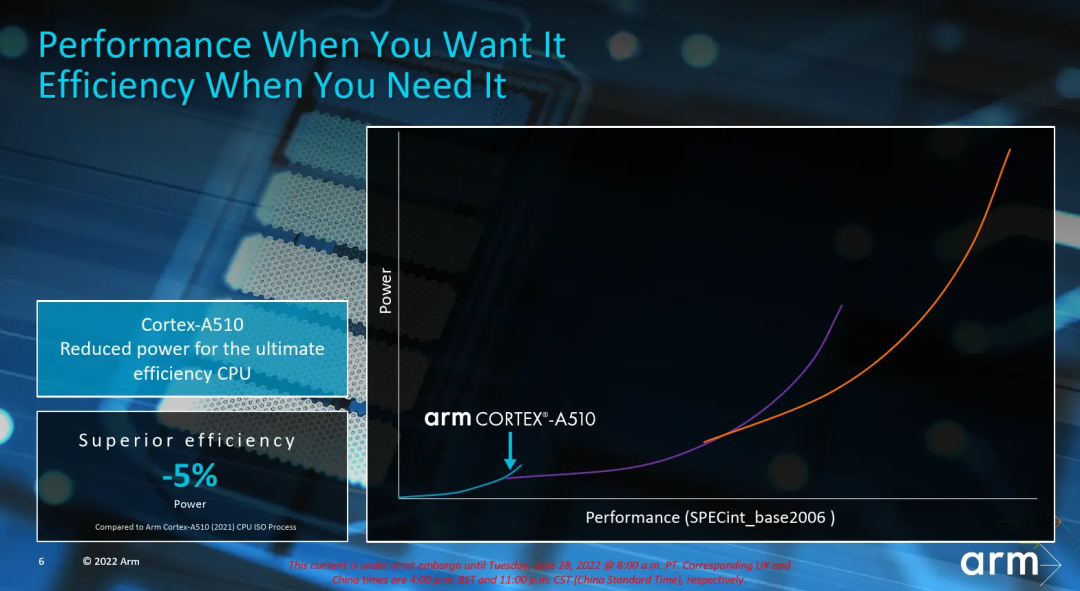
最后补个彩蛋,看Armv9三系列能效曲线图,小核心迭代速度较慢,逐渐无法满足日益增长的性能需求,由于小核心不支持乱序执行等特性,导致高频率区间能效反而不如大核心A715和A710(见图中箭头位置),在Armv9时代我们可以看到已经有厂商开始改变传统的1+3+4的架构。例如高通骁龙8Gen2芯片,将1+3+4的架构改成1+4+3的架构,减少一颗小核心,增加一颗大核心。这是一个很关键的变化,新架构的出现意味着更多的可能性,并且从实际测试数据看,性能有收益,跑分达130w+,能效方面8Gen2相比8+Gen1也有了进一步的改善。从8Gen2的处理器架构变化可以看出,芯片厂商也在走出多年不变的1+3+4八核心架构模式,希望以后有机会看到更多有意思的芯片架构设计组合。
编辑:黄飞
-
Arm微架构学习—开启Armv9时代2023-11-27 3803
-
ARM Cortex-A710核心技术参考手册2023-08-25 1081
-
Arm Cortex‑A510核心加密扩展技术参考手册2023-08-17 860
-
Arm Cortex‑A510核心软件优化指南2023-08-11 720
-
ARM Cortex-A715核心软件优化指南2023-08-10 880
-
ARM Cortex-A715核心加密扩展技术参考手册2023-08-09 573
-
Arm微架构之Armv9时代2023-02-06 10745
-
Cortex-A715的功耗性能都有哪些呢2022-11-09 2192
-
推荐一款平价安卓平板电脑:帅酷A7102013-04-20 3714
-
富士数码相机 FinePix A400/A503/A510中2009-12-02 1283
-
佳能(Canon) DIGITAL IXUS A710 IS2009-11-27 997
全部0条评论

快来发表一下你的评论吧 !
