

大语言模型中的常用评估指标
电子说
描述
大语言模型中的常用评估指标
EM
EM 是 exact match 的简称,所以就很好理解,em 表示预测值和答案是否完全一样。
def calc_em_score(answers, prediction): em = 0 for ans in answers: # 删掉标点符号 ans_ = remove_punctuation(ans) prediction_ = remove_punctuation(prediction) if ans_ == prediction_: # 只有在预测和答案完全一样时 em 值为1,否则为0 em = 1 break return em
F1
分别计算准确率和召回率, F1 是准确率和召回率的调和平均数。
def calc_f1_score(answers, prediction): f1_scores = [] for ans in answers: # 分词后的答案,分词方法参见附录2 ans_segs = mixed_segmentation(ans, rm_punc=True) # 分词后的预测 prediction_segs = mixed_segmentation(prediction, rm_punc=True) # 计算答案和预测之间的最长公共子序列,参见附录1 lcs, lcs_len = find_lcs(ans_segs, prediction_segs) if lcs_len == 0: f1_scores.append(0) continue # 准确率和 lcs_len/len(prediction_segs) 成正比 precision = 1.0*lcs_len/len(prediction_segs) # 召回率和 lcs_len/len(ans_segs) 成正比 recall = 1.0*lcs_len/len(ans_segs) # 准确率和召回率的调和平均数 f1 = (2*precision*recall)/(precision+recall) f1_scores.append(f1) return max(f1_scores)
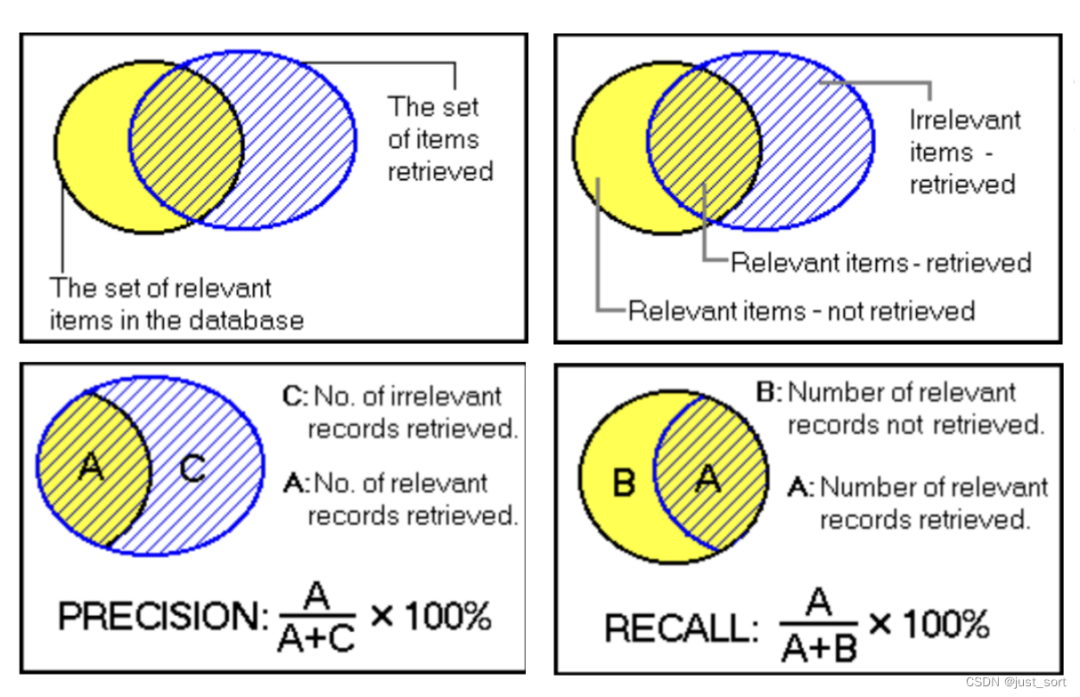
对于准确率和召回率增加下了解。看一个例子,如下图所示,方框代表全集,黄色圈代表正确结果集合,斜纹圈代表返回的预测结果。这样就构成了如下几个部分:
在这里插入图片描述
方框代表全集;
黄色圈代表正确结果集合;
斜纹圈代表返回的预测结果,也叫召回结果;
A 代表正确的、召回的部分,也叫 True Positive(TP);
C代表错误的、召回的部分,也叫 False Positive (FP);
B代表错误的、没召回的部分,也叫 False Negative (FN);
方框之内、两个圆圈之外的部分,代表正确的、没召回的部分,叫 True Negative (FN);
这时再来看 F1 的计算,就更直观了:

在这里插入图片描述
precision 代表着召回结果中的正确比例,评估的是召回的准确性;recall 代表正确召回结果占完整结果的比例,考虑的是召回的完整性;F1 既考虑了正确性,又考虑了完整性。
Accuracy 和 Accuracy norm
有了上面对 TP、FP、TN、FN 的定义,这里可以直接给出 Accuracy 的计算公式:
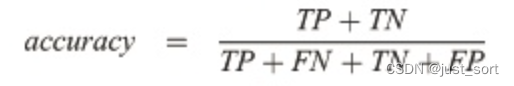
在这里插入图片描述
可以看出 accuracy 代表正确的(正确的、召回的部分 + 正确的、没召回的部分)比例。适合于离散的结果、分类任务,比如选择题。
但是看 lm-evaluation-harness 中的 accuracy 又不完全遵循上面的定义:
def process_results(self, doc, results):
gold = doc["gold"]
# 分数最高的作为预测结果和目标答案做对比
acc = 1.0 if np.argmax(results) == gold else 0.0
# 考虑选项长度
completion_len = np.array([float(len(i)) for i in doc["choices"]])
acc_norm = 1.0 if np.argmax(results / completion_len) == gold else 0.0
return {
"acc": acc,
"acc_norm": acc_norm,
}
lm-evaluation-harness 在计算acc时,先用模型为每个选项计算出的分数(例如,对数似然值)中,选出其中最大的作为预测结果。如果预测结果对应的选项索引和真实的正确选项索引相同,那么 accuracy 就是 1,否则为0;
Accuracy norm(归一化准确率),这个指标在计算过程中,会对模型计算出的每个选项的分数进行归一化。归一化的方法是将每个选项的分数除以选项的长度(字符数)。这样就得到了一个考虑了选项长度影响的新的分数列表。根据这个新的分数选取最大的分数的选项作为答案。
Perplexity 困惑度
困惑度(perplexity)的基本思想是:模型对于一个测试集中的句子,计算这个句子中词组合出现的概率,概率越高,困惑度越低,模型性能就证明是越好。
1、一个句子的概率,有如下定义,x 代表一个字符,它们组合在一起构成一个句子,句子的概率就等于词的概率相乘:

在这里插入图片描述
unigram 对应只考虑一个词出现概率的算法,相当于词出现概率相互独立;
bigram 对应条件概率考虑连续的两个词的概率;
而 trigram 对应条件概率考虑连续的三个词的概率。
2、困惑度的计算:
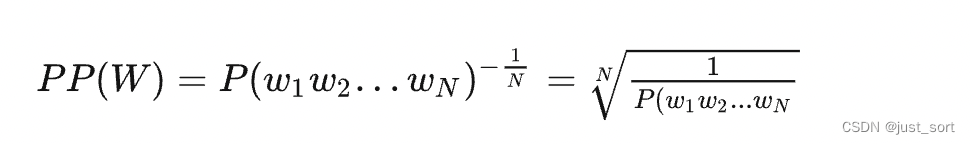
在这里插入图片描述
# 输入一个句子 sentence # 输入模型算出的 uni_gram_dict【unigram,单词的概率表】和 bi_gram_dict【bigram,两个词的概率表】 # 返回困惑度 def perplexity(sentence, uni_gram_dict, bi_gram_dict): # 分词 sentence_cut = list(jieba.cut(sentence)) # 句子长度 sentence_len = len(sentence_cut) # 词汇量 V = len(uni_gram_dict p=1 # 概率初始值 k=0.5 # ngram 的平滑值,平滑方法:Add-k Smoothing (k<1) for i in range(sentence_len-1): two_word = "".join(sentence_cut[i:i+2]) # (bi_gram_dict.get(two_word,0)+k)/(uni_gram_dict.get(sentence_cut[i],0) 即两个词的条件概率 p *=(bi_gram_dict.get(two_word,0)+k)/(uni_gram_dict.get(sentence_cut[i],0)+k*V) # p 是 sentence 的概率 # 返回困惑度 return pow(1/p, 1/sentence_len)
所以对一个句子的困惑度就是该模型得出的句子出现的概率的倒数,再考虑句子长度对该倒数做一个几何平均数。
对于一个正确的句子,如果模型得出的困惑度越低,代表模型性能越好。
进一步参考资料
概述NLP中的指标
附录
附录1、最长公共子序列
# 最长公共子序列 def find_lcs(s1, s2): # 申请一个二维矩阵,维度为 len(s1) + 1 和 len(s2) + 1 # m[i + 1][j + 1] 表示 s2[i] 和 s2[i] 位置对齐时,前面的以对齐位置为终点的最长公共子序列长度 m = [[0 for i in range(len(s2)+1)] for j in range(len(s1)+1)] mmax = 0 p = 0 for i in range(len(s1)): for j in range(len(s2)): # 动态规划算法:以 s2[i] 和 s2[j] 位置对齐时, # 如果 s1[i] 不等于 s2[j],以对齐位置为终点的最长公共子序列长度为0, # 如果 s1[i] 等于 s2[j],以对齐位置为终点的最长公共子序列长度为 # 以 s2[i - 1] 和 s2[j - 1] 位置对齐和为终点的最长公共子序列长度加1 if s1[i] == s2[j]: m[i+1][j+1] = m[i][j]+1 if m[i+1][j+1] > mmax: mmax=m[i+1][j+1] p=i+1 # 返回最长的公共子序列和其长度 return s1[p-mmax:p], mmax
附录2、分词
# 考虑英文和数字的分词 # 例子: tvb电视台已于2006年买下播映权 -> # ['tvb', '电', '视', '台', '已', '于', '2006', '年', '买', '下', '播', '映', '权'] def mixed_segmentation(in_str, rm_punc=False): in_str = str(in_str).lower().strip() segs_out = [] # store english and number, every element is a char temp_str = "" sp_char = ['-',':','_','*','^','/','\','~','`','+','=', ',','。',':','?','!','“','”',';','’','《','》','……','·','、', '「','」','(',')','-','~','『','』'] for char in in_str: if rm_punc and char in sp_char: continue if re.search(r'[u4e00-u9fa5]', char) or char in sp_char: if temp_str != "": ss = nltk.word_tokenize(temp_str) segs_out.extend(ss) temp_str = "" segs_out.append(char) else: temp_str += char #handling last part if temp_str != "": ss = nltk.word_tokenize(temp_str) segs_out.extend(ss) return segs_out
-
【《大语言模型应用指南》阅读体验】+ 基础知识学习2024-08-02 3248
-
【大语言模型:原理与工程实践】大语言模型的评测2024-05-07 1728
-
【大语言模型:原理与工程实践】核心技术综述2024-05-05 1064
-
【大语言模型:原理与工程实践】揭开大语言模型的面纱2024-05-04 789
-
大模型在战略评估系统中的应用有哪些2024-04-24 708
-
机器学习模型评估指标2023-09-06 2075
-
清华大学大语言模型综合性能评估报告发布!哪个模型更优秀?2023-08-10 2123
-
分类模型评估指标汇总2020-12-10 1286
-
机器学习模型评估的11个指标2020-05-04 4075
-
机器学习算法常用指标汇总2019-02-13 5840
-
使用单值评估指标进行优化2018-12-12 2130
-
自然语言处理常用模型解析2017-12-28 6416
-
网络安全评估指标优化模型2017-11-21 560
全部0条评论

快来发表一下你的评论吧 !
