

Microsoft Editor是怎样实现零COGS的?
描述
编者按:Microsoft Editor 是一款人工智能写作辅助工具,其中的语法检查器(grammar checker)功能不仅可以帮助不同水平、领域的用户在写作过程中检查语法错误,还可以对错误进行解释并给出正确的修改建议。神经语法检查器模型是这款提供了强大拼写检查和语法纠正服务的 Microsoft Editor 背后的关键技术,该模型采用了微软亚洲研究院创新的 Aggressive Decoding 算法,并借助高性能 ONNX Runtime(ORT) 进行加速,使服务器端的模型推理速度提升了200%,在不损失模型预测质量的情况下,节省了三分之二的成本。神经语法检查器模型还使用了微软亚洲研究院前沿的客户端 seq2seq 建模技术 EdgeFormer,构建了性能优异的轻量级生成语言模型,结合部署中的模型和系统优化,该技术可赋能用户在设备上的部署,从而实现零销货成本(zero-COGS,zero-cost-of-goods-sold)的目标。本文编译自微软研究院博客 “Achieving Zero-COGS with Microsoft Editor Neural Grammar Checker”。
自上世纪70年代以来,语法检查器(grammar checker)所依赖的技术已经取得了显著的发展,最初的第一代工具只是基于简单的模式匹配(pattern matching)。1997年,一个标志性的事件发生了,当时 Microsoft Word 97 引入了一个基于成熟的自然语言处理系统(Heidorn, 2000)的语法检查器,以支持更复杂的错误检测和修改,并提高了准确率。2020年,语法检查器再次实现关键性突破,微软推出了神经语法检查器(neural grammar checker),通过利用深度神经网络和全新的流畅度提升学习和推理机制,神经语法检查器在 CoNLL-2014 和 JFLEG 基准数据集上均取得了 SOTA 结果[1,2]。2022年,微软发布了高度优化后的 Microsoft Editor 神经语法检查器,并将其集成到 Word Win32、Word Online、Outlook Online 和 Editor Browser Extension 中。
如今 Microsoft Editor 版本中的神经语法检查器模型主要采用了微软亚洲研究院创新的 Aggressive Decoding 算法,而且借助高性能 ONNX Runtime(ORT)进行加速,可以使服务器端模型的推理速度提升200%,在不损失模型预测质量的情况下,节省了三分之二的成本。此外,该神经语法检查器模型还使用微软亚洲研究院前沿的客户端 seq2seq 建模技术 EdgeFormer,构建了性能优异的轻量级生成语言模型,结合部署过程中设备开销感知的模型和系统优化,该技术满足交付要求,赋能用户设备上的部署,最终实现了零销货成本(zero-COGS, zero-cost-of-goods-sold)的目标。
不仅如此,Microsoft Editor 中的神经语法检查器模型在转换为客户端模型后,还有三个优势:
1. 提升隐私性。客户端模型在用户设备本地运行,无需向远程服务器发送任何个人数据。
2. 增强可用性。客户端模型可以离线运行,不受网络连接、带宽或服务器容量的限制。
3. 降低成本、提高可扩展性。客户端模型运行在用户设备上,省去了服务器执行所需的所有计算,从而可以服务更多客户。
另外,Microsoft Editor 还使用了 GPT-3.5 模型来生成高质量的训练数据来识别和移除低质量的训练示例,从而提升模型的性能。
Aggressive Decoding 算法具有巨大价值,它不仅适用于 Microsoft Editor 这样对响应时间、请求频率和准确度都有很高要求的应用场景,还可以拓展到更多功能模块,如文本重写、文本摘要等。Aggressive Decoding 算法让我们能够在保证模型预测质量不受损的同时更快地服务更多的客户,降低服务成本并提高产品的竞争力和影响力, 这一创新技术也将在未来的客户端模型研发中发挥重要作用。
陈思清
微软首席应用科学家

Aggressive Decoding:首个在seq2seq任务上无损加速的高效解码算法
Microsoft Editor 中的人工智能语法检查器主要基于 Transformer 模型,并采用了微软亚洲研究院在语法纠错方面的创新技术[1,2,3]。与大多数 seq2seq 任务一样,Microsoft Editor 此前的模型使用了自回归解码来进行高质量的语法校正。然而,传统的自回归解码效率很低,尤其是由于低计算并行性,导致模型无法充分利用现代计算设备(CPU、GPU),从而使得模型服务成本过高,并且难以快速扩展到更多终端(Web/桌面)。
为了降低服务成本,微软亚洲研究院的研究员们提出了创新的解码算法 Aggressive Decoding[3]。与之前以牺牲预测质量为代价来加速推理的方法不同,Aggressive Decoding 是首个应用在 seq2seq 任务(如语法检查和句子重写)上达到无损加速的高效解码算法。它直接将输入作为目标输出,并且并行验证它们,而不是像传统的自回归解码那样逐个顺序解码。因此,这一算法可以充分发挥现代计算设备(如带有 GPU 的 PC)强大的并行计算能力,极大地提升解码速度,能够在不牺牲质量的前提下以低廉的成本处理来自全球用户(每年)数万亿次的请求。

图1:Aggressive Decoding 的工作原理
如图1所示,如果模型在 Aggressive Decoding 过程中发现了一个分歧点,那么算法将舍弃分歧点后的所有预测,并使用传统的逐个自回归解码重新解码。如果在逐个重新解码时发现了输出和输入之间存在唯一的后缀匹配(图1中蓝色点线突出显示的建议),那算法会通过把输入的匹配字符(token)之后的字符(图1中用橙色虚线突出显示的部分)复制到解码器的输入中并假设它们是相同的,从而切换回 Aggressive Decoding。通过这种方式,Aggressive Decoding 可以确保生成的字符与自回归贪婪解码一致,但解码步骤大幅减少,显著提高了解码效率。
我们在做模型推理加速算法研究时最重要的考虑就是无损,因为在实际应用中,模型生成质量是排在第一位的,以损失质量来换取更小的开销会严重影响用户体验。为此,我们提出了 Aggressive Decoding 算法,它利用了语法纠错任务的一个重要特性,即输入与输出高度相似,将整个计算过程(pipeline)高度并行化,充分利用 GPU 在并行计算上的优势,在生成质量无损的前提下实现大幅加速的效果。
葛涛
微软亚洲研究院高级研究员
离线+在线评估结果:Aggressive Decoding可显著降低COGS
离线评估:研究员们在语法校正和其他文本重写任务如文本简化中,采用了一个6+6标准的 Transformer 及深度编码器和浅层解码器的 Transformer 来测试 Aggressive Decoding。结果表明 Aggressive Decoding 可以在没有质量损失的情况下大幅提升速度。
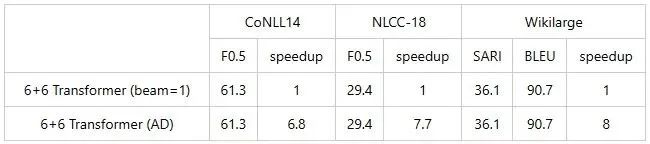
表1:6+6标准 Transformer 测试结果

表2:深度编码器和浅层解码器的 Transformer 的测试结果
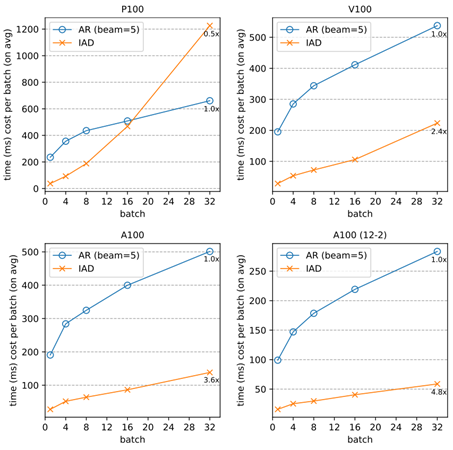
图2:Aggressive Decoding 算法在更强大的并行计算设备上的运行效果更好
在线评估:研究员们还在 Marian 服务器模型和使用 ONNX Runtime 的 Aggressive Decoding 的同等服务器模型之间进行了 A/B 实验。结果如图3所示,与在 CPU 中使用传统自回归解码的 Marian 运行时相比,后者在 p50 延迟上有超过2倍的提升,在 p95 和 p99 延迟上有超过3倍的提升。此外,与之前的自回归解码相比,后者提供了更高的效率稳定性。这种显著的推理时间加速,将服务器端的 COGS 降低了三分之二。
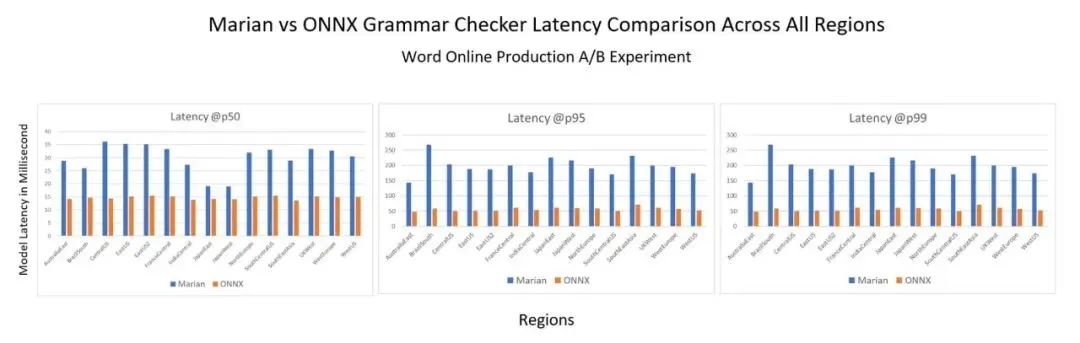
图3:所有区域 Marian 和 ONNX 语法检查器延迟对比
离线和在线评估都验证了 Aggressive Decoding 能够在不降低模型预测质量的情况下显著减少 COGS。基于此,研究员们将 Aggressive Decoding 也应用到了更通用的 seq2seq 任务中[4]。Aggressive Decoding 的高效率和无损质量特性,或将使其成为 seq2seq 任务高效解码的标准范式,在降低 seq2seq 模型部署成本中起到重要作用。
ONNX Runtime加速语法检查器
ONNX Runtime 是微软开发的高性能引擎,它可在各种硬件平台上加速人工智能模型。许多基于机器学习的微软产品都利用 ONNX Runtime 来加速推理性能。为了进一步降低推理延迟,ORT 团队的研发人员们首先将 PyTorch 版的 Aggressive Decoding 语法检查器,通过 PyTorch-ONNX 导出器导出为 ONNX 格式,再使用 ONNX Runtime 进行推理。ONNX Runtime 支持 Transformer 的特定优化以及 INT8 量化,这不仅实现了 Transformer 在 CPU 上的性能加速,同时还可以缩减模型大小。该端到端解决方案使用了多项前沿技术,以实现高效地运行这个先进的语法检查器模型。
ONNX Runtime 是一个具有很好延展性的跨硬件模型加速引擎,可以支持不同的应用场景。为了最高效运行 Aggressive Decoding 这一创新解码算法,我们对 PyTorch 导出器和 ONNX Runtime 做了一系列提升,最终让这一先进的语法检查器模型以最高性能运行。
宁琼
微软首席产品主管
PyTorch 提供了一个内置函数,可以轻松地将 PyTorch 模型导出为 ONNX 格式。为了支持语法检查模型的独特架构,研发人员们在导出器里实现了复杂嵌套控制流导出到 ONNX,并扩展了官方 ONNX 规范来支持序列数据类型和运算符,以表示更复杂的场景,例如自回归搜索算法。这样就不需要单独导出模型编码器和解码器组件,再使用序列生成逻辑将它们串联在一起。由于 PyTorch-ONNX 导出器和 ONNX Runtime 支持序列数据类型和运算符,所以原模型可以导出成单一的一个包括编码器、解码器和序列生成的 ONNX 模型,这既带来了高效的计算,又简化了推理逻辑。此外,PyTorch ONNX 导出器的 shape type inference 组件也得到了增强,从而可以得到符合更严格的 ONNX shape type 约束下的有效的 ONNX 模型。
在语法检查器模型中引入的 Aggressive Decoding 算法最初是在 Fairseq 中实现的。为了使其与 ONNX 兼容以便于导出,研发人员们在 HuggingFace 中重新实现了 Aggressive Decoding 算法。在深入实施时,研发人员们发现 ONNX 标准运算符集不直接支持某些组件(例如分叉检测器)。目前有两种方法可以将不支持的运算符导出到 ONNX 并在 ONNX Runtime 中运行:1. 利用 ONNX 已有的基本运算符组建一个具有等效语义的图;2. 在 ONNX Runtime 中实现一个更高效的自定义运算符。ONNX Runtime 自定义运算符功能允许用户实现自己的运算符,以便灵活地在 ONNX Runtime 中运行。用户可以权衡实现成本和推理性能来选择合适的方法。考虑到本模型组件的复杂性,标准 ONNX 运算符的组合可能会带来性能瓶颈。因此,研发人员们选择在 ONNX Runtime 中实现自定义运算符。
ONNX Runtime 支持 Transformer 的优化和量化,这在 CPU 和 GPU 上都能提升性能。此外,ONNX Runtime 针对语法检查器模型进一步增强了编码器 attention 以及解码器 reshape 图算融合。支持该模型的另一大挑战是多个模型子图,而 ONNX Runtime Transformer 优化器和量化工具对此也实现了子图融合。ONNX Runtime 量化压缩已被应用于整个模型,进一步改善了吞吐量和延迟。
GPT-3.5助力模型实现质的飞跃
为了进一步提高生产中模型的精度和召回率,研究员们使用了强大的 GPT-3.5 作为教师模型。具体而言,GPT-3.5 模型通过以下两种方式来帮助提高结果:
训练数据增强:通过对 GPT-3.5 模型进行微调,使其为大量未标注的文本生成标签。所获得的高质量标注,可以用作增强训练数据来提高模型性能。
训练数据清理:利用 GPT-3.5 强大的零样本和少样本学习能力来区分高质量和低质量的训练示例。然后,通过 GPT-3.5 模型重新对已识别的低质量示例生成标注,从而产生更干净、更高质量的训练集,直接增强模型性能。
EdgeFormer:用于客户端seq2seq建模的成本效益参数化
近年来,客户端设备的计算能力大大增加,使得利用深度神经网络来实现最终的零销货成本成为可能。然而,在这些设备上运行生成式语言模型仍然是一个很大的挑战,因为这些模型的内存效率必须受到严格的控制。在涉及生成式语言模型时,自然语言理解中用于神经网络的传统压缩方法往往不适用。
图4:使用深度神经网络来实现零销货成本
(zero-COGS)
运行在客户端的语法模型应该具有很高的效率(例如延迟在100ms内),这个问题已经由 Aggressive Decoding 解决了。此外,客户端模型还必须具有高效的内存(例如占用的空间在50MB以内),这是强大的 Transformer 模型(通常超过5000万个参数)在客户端设备上运行的主要瓶颈。
为了应对这一挑战,微软亚洲研究院的研究员们引入了前沿的客户端 seq2seq 建模技术 EdgeFormer[6],用于构建性能优异的轻量级生成语言模型,让模型可以在用户的计算机上轻松运行。
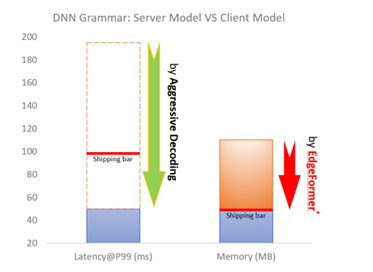
图5:DNN 语法:服务器模型 VS 客户端模型
EdgeFormer 有两个原则,主要是为了参数化的成本效益:
有利于编码器的参数化
负载均衡参数化
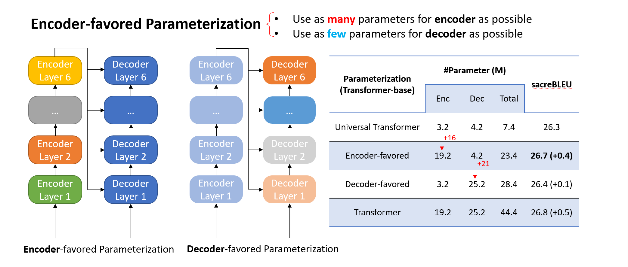
图6:有利于编码器的参数化
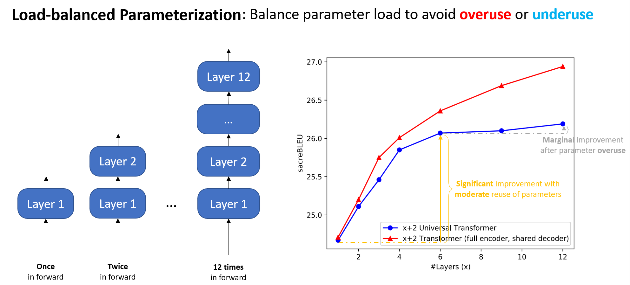
图7:负载均衡参数化
遵循上述具有成本效益参数化的原则而设计的 EdgeFormer,使得每个参数都能发挥最大潜力,即使客户端设备存在严格的计算和内存限制,也能获得有竞争力的结果。
在 EdgeFormer 的基础上,研究员们进一步提出了 EdgeLM——EdgeFormer 的预训练版本,这是第一个在设备上公开可用的预训练 seq2seq 模型,可以让 seq2seq 任务的微调变得更容易,进而获得好的结果。EdgeLM 作为语法客户端模型的基础模型,实现了零销货成本,与服务器端模型相比,该模型以最小的质量损失实现了超过5倍的模型压缩。
微软亚洲研究院异构计算组致力于以全栈协同设计的思想,构建深度学习模型到实际设备部署之间的桥梁。以 Microsoft Editor 为例,我们与算法、产品和 AI 框架团队深度合作,通过系统和硬件感知的模型优化和压缩,以及针对不同硬件的推理系统和运算符优化等,使模型开销能够满足实际设备运行的要求,为未来将更多微软产品的 AI 服务部署到设备端铺平了道路。
曹婷
微软亚洲研究院高级研究员
降低推理成本,赋能客户端部署
客户端设备的模型部署对硬件使用有严格的要求,如内存和磁盘使用量等,以避免干扰其他的应用程序。由于 ONNX Runtime 是一个轻量级的引擎并提供全面客户端推理解决方案(如 ONNX Runtime 量化和 ONNX Runtime 扩展),所以其在设备部署方面也具有明显的优势。此外,为了在保持服务质量的前提下满足交付要求,微软亚洲研究院引入了一系列优化技术,包括系统感知的模型优化、模型元数据简化、延迟参数加载以及定制量化策略。基于 EdgeFormer 建模,这些系统优化可以进一步将内存成本降低2.7倍,而不会降低模型性能,最终赋能模型在客户端设备的部署。
系统感知的模型优化。由于模型在推理系统中被表示为数据流图,因此该模型的主要内存成本来自于生成的许多子图。如图8所示,PyTorch 代码中的每个分支被映射为一个子图。所以,需要通过优化模型实现来减少分支指令的使用率。这其中尤为重要的是,因为波束搜索包含更多的分支指令,研究员们利用了贪婪搜索作为解码器搜索算法,从而将内存成本降低了38%。
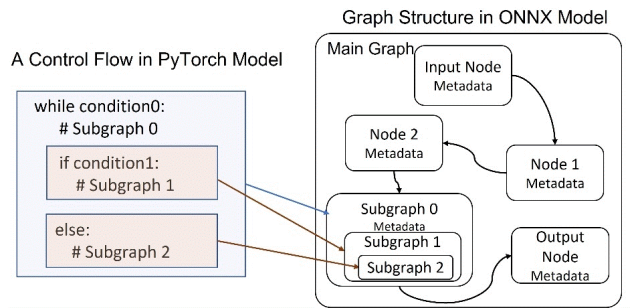
图8:PyTorch 模型和 ONNX 模型图的映射
模型元数据简化。如图8所示,模型包含大量消耗内存的元数据,如节点名称和类型、输入和输出以及参数等。为了降低成本,研究员们需要简化元数据,只保留推理所需的基本信息,例如,节点名称从一个长字符串简化为一个索引。此外,研究员们也优化了 ONNX Runtime 模型图的实现,对所有子图只保留一个元数据副本,而不是在每次生成子图时复制所有可用的元数据。
延迟模型权重加载。当前的模型文件包含模型图和权重,并在模型初始化期间将它们一起加载到内存中。然而,这会增加内存使用量,如图9所示,这是因为在模型图解析和转换过程中会重复复制权重。为了避免这种情况,研究员们提出将模型图和权重分别保存成独立的文件,并将该方法在 ONNX Runtime 加以实现。通过该方法,在初始化期间,只有模型图被加载到内存中进行实际解析和转换,而权重仍然留在磁盘上,通过文件映射只把权重文件指针(pointer)保留在内存中,实际的权重到内存的加载将被推迟到模型推理之时。该技术可将峰值内存成本降低50%。
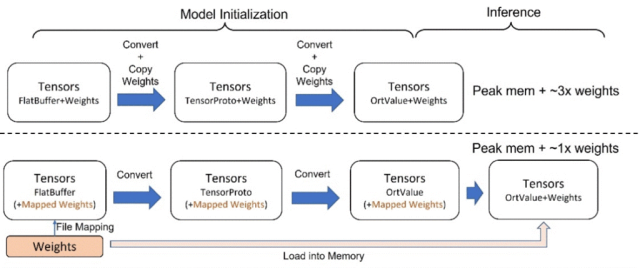
图9:对比现有的模型图和权重同时加载(虚线上),以及模型初始化期间通过文件映射实现的延迟权重加载(虚线下)
ONNX Runtime 量化和扩展。量化是众所周知的模型压缩技术,它在牺牲模型精度的同时,带来了性能加速和模型缩减。ONNXRuntime 量化提供了多种微调选择,使其能够应用定制的量化策略。研发人员们为 EdgeFormer 模型定制了最优量化策略,以减少量化对精度的影响,具体包括训练后、动态和 UINT8 量化,以及 per-channel 和既有所有运算符量化策略。Onnxruntime-extensions 提供了一组 ONNX Runtime 定制运算符,以支持视觉、文本和自然语言处理模型的常见预处理和后处理运算符。利用这一工具,研发人员们将模型的预处理和后处理,例如标记化(tokenization)、字符串操作等,都集成到一个独立的 ONNX 模型文件中,从而提高性能、简化部署、减少内存使用率并提供更好的可移植性。
这些创新成果只是微软亚洲研究院为降低生成式语言模型的销货成本而做出的长期努力中的第一个里程碑。这些方法并不局限于加速神经语法检查器,它可以很容易地应用在抽象摘要、翻译或搜索引擎等广泛的场景中,从而加速降低大语言模型的销货成本[5,8]。在人工智能的未来发展中,这些创新对微软乃至对整个行业都将至关重要。
相关链接:
ONNX Runtime
https://onnxruntime.ai
EdgeFormer
https://www.microsoft.com/en-us/research/publication/edgeformer-a-parameter-efficient-transformer-for-on-device-seq2seq-generation/
EdgeLM
https://github.com/microsoft/unilm/tree/master/edgelm
ONNX Runtime 量化
https://onnxruntime.ai/docs/performance/model-optimizations/quantization.html
Onnxruntime-extensions
https://github.com/microsoft/onnxruntime-extensions
参考文献:
[1] Tao Ge, Furu Wei, Ming Zhou: Fluency Boost Learning and Inference for Neural Grammatical Error Correction. In ACL 2018.
[2] Tao Ge, Furu Wei, Ming Zhou: Reaching Human-level Performance in Automatic Grammatical Error Correction: An Empirical Study.
https://arxiv.org/abs/1807.01270
[3] Xin Sun, Tao Ge, Shuming Ma, Jingjing Li, Furu Wei, Houfeng Wang: A Unified Strategy for Multilingual Grammatical Error Correction with Pre-trained Cross-lingual Language Model. In IJCAI 2022.
[4] Xin Sun, Tao Ge, Furu Wei, Houfeng Wang: Instantaneous Grammatical Error Correction with Shallow Aggressive Decoding. In ACL 2021.
[5] Tao Ge, Heming Xia, Xin Sun, Si-Qing Chen, Furu Wei: Lossless Acceleration for Seq2seq Generation with Aggressive Decoding.
https://arxiv.org/pdf/2205.10350.pdf
[6] Tao Ge, Si-Qing Chen, Furu Wei: EdgeFormer: A Parameter-efficient Transformer for On-device Seq2seq Generation. In EMNLP 2022.
[7] Heidorn, George. “Intelligent Writing Assistance.” Handbook of Natural Language Processing. Robert Dale, Hermann L. Moisl, and H. L. Somers, editors. New York: Marcel Dekker, 2000: 181-207.
[8] Nan Yang, Tao Ge, Liang Wang, Binxing Jiao, Daxin Jiang, Linjun Yang, Rangan Majumder, Furu Wei: Inference with Reference: Lossless Acceleration of Large Language Models.
https://arxiv.org/abs/2304.04487
关注微软科技视频号
了解更多科技前沿资讯
- 相关推荐
- 热点推荐
- 微软
-
变了!再也不是以前的Microsoft 365了!2023-04-12 1860
-
使用PSpice_Model_Editor建模.zip2022-12-30 788
-
Tiny-editor基于Ace的在线代码编辑器2022-05-24 916
-
这个过零检测可以实现两个方向的过零检测不?工作原理是怎样的2022-04-01 13084
-
请问Altium中from to editor飞线怎样关闭不显示出来?2019-07-11 2108
-
Acme DWG Editor编辑器应用程序免费下载2019-05-20 1319
-
ISE FPGA Editor的编辑的问题2016-05-16 4709
-
Foxit PDF Editor.exe2014-04-03 884
-
allegro pcb editor规则设置类别优先顺序2011-11-22 6544
-
基于Microsoft .NET Framework的OPC2009-05-25 928
-
Parameters Editor,USB-CDROM量产工2009-04-21 1984
-
Applied Microsoft .NET Framewo2009-01-08 1446
全部0条评论

快来发表一下你的评论吧 !
