

【专栏精选】嵌入式开发极致性能优化案例
描述
做电子发烧友技术探索官,分享你的原创电子行业文章!
本期为大家带来一篇嵌入式开发性能优化案例,感兴趣的小伙伴可以关注作者一起学习哦~
本期推
荐
专栏作者:嵌入式USB开发(点击查看作者主页)
介绍:本专栏介绍嵌入式USB开发,理论结合实践,不单纯讲USB协议,而是以具体的实例进行讲解。
前言
我们之前进行了TFT刷屏测试确认了基本功能。刷屏速度是决定GUI显示帧率最根本的一环,只有优化到极致的刷屏速度,才能有基础实现更好效果的GUI。本篇就进行刷屏的优化,其实其思想是通用的,对于其他代码也可以参考。
1. 减少if条件判断
if等条件判断会导致分支处理,一方面会增加指令,尤其是跳转指令一般执行时间比一般指令长,另外也会影响流水线和cache。
if(Data&0x80)
LCD_SDA_SET; //输出数据
else LCD_SDA_CLR;改为串行操作
#define LCD_SDA_SET_VAL(val) LCD_CTRLB->BSRR=val;LCD_CTRLB->BRR=val^LCD_SDA
2. 使用寄存器变量
频繁操作的局部变量尽量使用寄存器进行缓存,避免反复从内存去加载,寄存器直接操作速度快很多。
register unsigned int data;3. 空间换时间 8次for循环改为 直接8次操作
其实在memcpy等处理中也是类似操作,比如连续8次读写组合一起,再循环。以减少for判断次数,也利于内部cache流水线处理,有一些cpu还有burst处理,这也是有利的。
inline void SPI_WriteDataF(unsigned char Data)
{
#if 0
unsigned char i=0;
for(i=8;i>0;i--)
{
if(Data&0x80)
LCD_SDA_SET; //输出数据
else LCD_SDA_CLR;
LCD_SCL_CLR;
LCD_SCL_SET;
Data<<=1;
}
#else
//LCD_SDA_LOCK;
register unsigned int data = (Data & 0x80) << 0;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x40) << 1;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x20) << 2;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x10) << 3;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x08) << 4;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x04) << 5;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x02) << 6;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
data = (Data & 0x01) << 7;
LCD_SDA_SET_VAL(data);
LCD_SCL_CLR;
LCD_SCL_SET;
//LCD_SDA_UNLOCK;
#endif
}4. 使用内联函数减少函数跳转时间
inline void SPI_WriteDataF(unsigned char Data)函数跳转需要时间,减少函数调用即可节约时间,尤其频繁调用的函数效果明显,但是可能增加存储空间。
5. 减少for循环嵌套 双重for嵌套改为一层for
For嵌套导致多重循环嵌套判断,浪费时间,顺序执行一般是优于分支处理的。
void Lcd_ClearF(unsigned int Color) //刷新全屏
{
unsigned int i,m;
Lcd_SetRegion(0,0,X_MAX_PIXEL-1,Y_MAX_PIXEL-1);
Lcd_WriteIndex(0x2C);
for(i=0;i
{
LCD_CS_CLR;
LCD_RS_SET;
SPI_WriteDataF(Color>>8); //写入高8位数据
SPI_WriteDataF(Color); //写入低8位数据
LCD_CS_SET;
}
}6. 减少函数调用层级
函数调用影响流水线,并且需要额外的上下文处理时间
Lcd_ClearF中直接调用SPI_WriteDataF不再调用函数LCD_WriteData_16Bit
7. 使用汇编进行优化
这个实际看情况建议先用其他方式进行优化,因为人工编写汇编代码不一定比编译器编写的好,除非非常熟悉汇编并且有明确的优化方向。
8. 速度测试
循环刷屏使用定时器记录执行多次刷屏的时间,代码见附件。
9. 编译器速度优化选项
编译器-Ofast优化
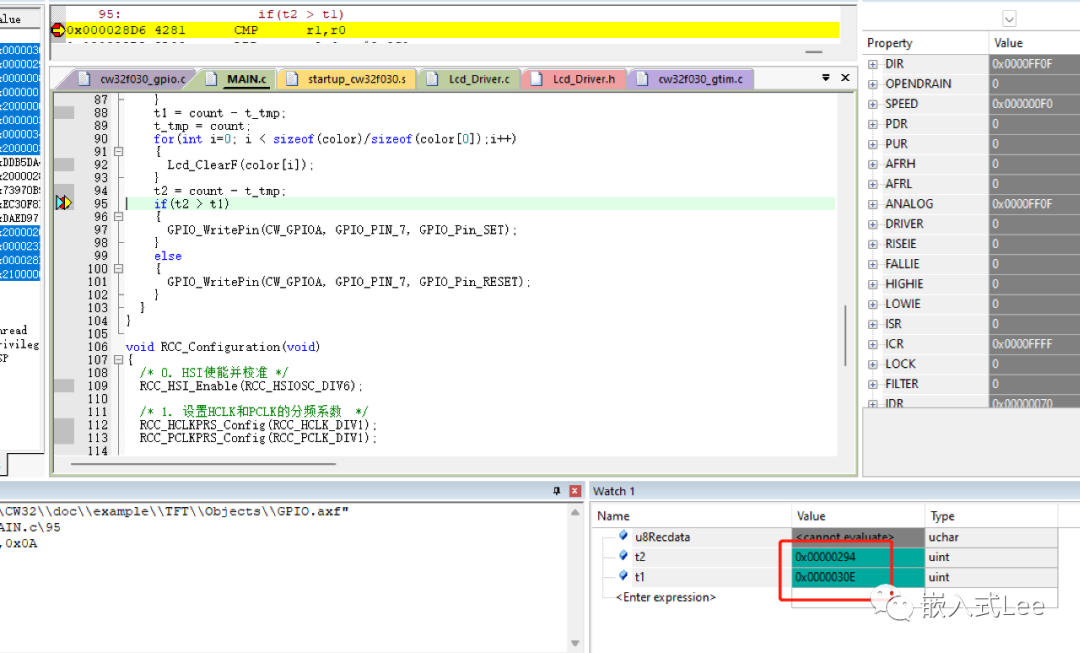
执行时间分别是
660ms,782ms
我们优化后的代码快15.6%
编译器-O2优化
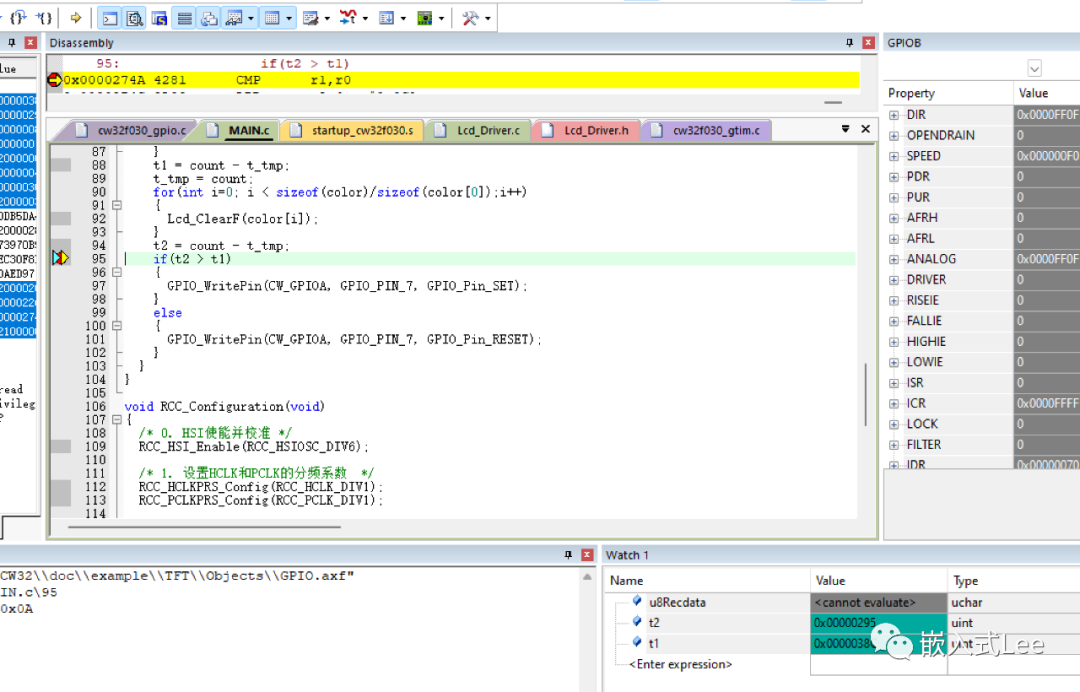
执行时间分别是661ms,908ms
我们优化后的代码快快27.2%
- 从上可以看出不管用什么编译器优化,经过上面方式人工优化后的代码都不差不多,660和661,说明编译器已经无法对我们优化后的代码再进行优化
- 说明我们人工优化的代码不使用编译器优化也有很好的速度性能。
- 不同的编译器优化对原来的代码影响较大-ofast执行时间从908变为了782。
- 哪怕是采用-ofsat编译器优化,我们人工优化的代码依然还有比编译器优化的代码快15.6%,所以编译器优化无法替代人工优化。
- 只有从设计角度去优化,避免依赖编译器优化才是根本方案。
总结
1.优化应该从设计上去优化而不是依赖编译器,应该先找大头,优先设计原理,算法上去优化,最后采取进行汇编等底层的优化,后者成本大效果不明显不具备可移植性等,前者成本小效果明显,不依赖于编译器。
2.建议寄存器名字和手册对应比如gpio的io锁定寄存器,头文件中是LOCK 手册里是LCKR
2.对于IO操作最好设置LOCK ODR寄存器,这样可以指定bit直接写值而其他位不修改,而不需要if else判断分别配置BRR 和BSRR,可以直接操作ODR寄存器,进一步优化速度。
原文地址:https://www.elecfans.com/d/2101849.html
版权说明:
本内容为作者发布至电子发烧友平台原创文章,相关创作版权归原作者所有,如未经作者授权,禁止转载!


更多热点文章阅读
采用先进成熟工艺和自主产权体系结构,紫光同创FPGA开发板入门指导
嵌入式Linux开发秘籍!工程师大佬亲历分享项目样例
RK3568!四核64位ARMv8.2A架构,汇聚编译源码及实战样例
尺寸仅有21mm*51mm,板边采用邮票孔设计,合宙 Air105 核心板开发总结
基于Cortex-M3内核的32位微控制器,STM32项目实战分享!
原文标题:【专栏精选】嵌入式开发极致性能优化案例
文章出处:【微信公众号:电子发烧友论坛】欢迎添加关注!文章转载请注明出处。
-
嵌入式开发蜂鸣器代码2022-03-29 1960
-
python做嵌入式开发_Python和嵌入式的区别是什么?可以做嵌入式开发吗?2021-11-02 2344
-
嵌入式开发资料免费分享2021-10-21 2164
-
嵌入式开发前景怎么样?嵌入式开发有哪些优势?2021-10-20 1315
-
嵌入式开发(一):嵌入式开发新手入门2021-10-14 4046
-
嵌入式开发的产品有哪些_嵌入式开发的流程2020-08-31 12192
-
嵌入式开发好学吗_嵌入式开发职业发展方向是什么2018-05-18 10534
-
学嵌入式开发入门_学嵌入式开发需要看哪些书籍2018-04-04 42802
-
关于嵌入式开发杂谈2017-10-31 1351
-
如何简化嵌入式开发项目2017-10-24 1182
-
嵌入式开发之旅笔记2017-09-08 1159
-
嵌入式开发2011-12-20 4086
-
基于ARM的嵌入式开发2009-10-04 2078
-
嵌入式开发圣经2006-03-25 1825
全部0条评论

快来发表一下你的评论吧 !
