

多片FPGA原型的两种分割方式介绍
可编程逻辑
描述
综合工具的任务是将SoC设计映射到可用的FPGA资源中。自动化程度越高,构建基于FPGA的原型的过程就越容易、越快。
SoC设计到FPGA原型设计的三个“定律”:
法则1:SoC规模一般大于单个FPGA规模(SoC的规模一般比较大)
法则2:SoC速率比FPGA速率更快(FPGA虽快但不及SoC快)
法则3:SoC设计方法和FPGA设计方法是有些不一致的(需要移植)
这些“定律”的会带来如下挑战:
a) 设计可能需要分割到多片FPGA系统;
b) 该设计可能无法以全SoC速度运行;
c) 为了使FPGA就绪,设计可能需要一些代码的返工移植工作。
诚然,这些挑战确实比较大,有时会被打破,例如,一些SoC设计确实只需要一个FPGA来原型,从而打破了第一条法律。然而,这三条定律很好地提醒了使用基于FPGA的原型时需要克服的主要问题,以及为FPGA做好设计准备所需的步骤。
综合方法
执行原型设计的最重要原因之一是与其他验证方法(如Simulation)相比,实现尽可能高的性能;然而,综合结果如果不够完美会危及这一目标。为了实现更快的运行时间,一些合成工具允许使用快速通过的低工作量综合,或者减少综合目标是很有吸引力的,正是为了这种权衡。然而,在某些设计块中,为了满足原型的总体性能目标,必须获得最佳的综合结果。综合工具有许多特性,通常对原型开发人员有益。其中包括:
快速综合:一种操作模式,其中综合工具忽略一些完全优化的机会,以便更快地完成综合。通过这种方式,以FPGA性能为代价,可以使运行时间比正常速度快2到3倍。如果综合运行时间以小时为单位,那么这种快速模式将在原型项目期间节省许多天或数周的等待时间。快速合成运行时在最初的分区和实现试验中也很有用,因为只需要估计设计大小和粗略的性能。
增量综合:在这种操作模式中,设计被视为每个FPGA内的块或子树。综合工具维护每个子树的历史版本,并可以注意到新的RTL更改是否影响每个子树。如果增量综合识别出子树没有改变,那么它将避免重新综合,而是使用该子树的历史版本,从而节省大量时间。增量综合引擎的决策作为放置约束被前向注释到后端布局布线工具,以便保持先前的逻辑映射和布局。考虑使用增量综合可以显著减少从小型设计变更到FPGA板上最终实现设计的周转时间。
物理综合:一种针对物理实现优化综合的功能,其中工具考虑了实际的路由延迟,并产生逻辑布局约束,供布局布线工具使用。该特征通常为设计产生更快和更准确的定时闭合。这似乎与我们对上述快速综合的考虑相矛盾,但通常情况下,原型中的一个特定FPGA难以达到全速,因此选择性地使用物理综合是一种使FPGA能够更快地完成定时关闭的方式。
尽管FPGA容量已根据摩尔定律增加,但SoC设计本身的尺寸和复杂性也有所增加,因此SoC设计通常仍大于当今最大的FPGA设备。因此,原型设计的第一定律越来越在多数情况下显得正确,那么FPGA原型设计者面临的任务是将SoC设计划分为多个更小的FPGA器件。
RTL级别的分区
当在综合之前对设计进行分区时,输入格式是SoC设计的RTL。分割的任务是从总体设计树中创建FPGA大小的子设计的过程,可以在一定程度上实现自动化。下图显示了RTL分割工具流程中的步骤。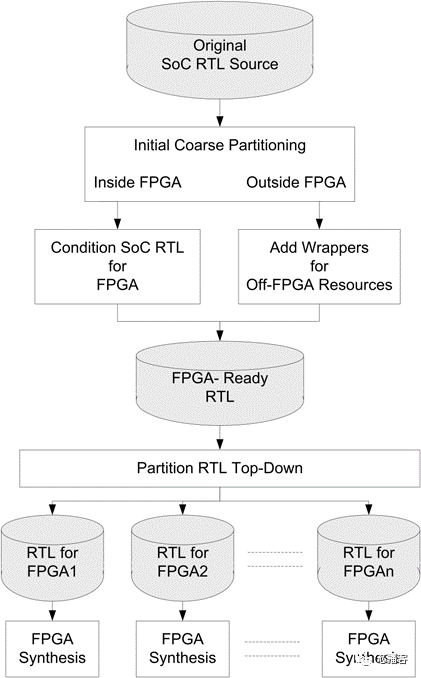
该流程通常是自上而下执行的,这要求分区工具和它们运行的工作站具有容纳整个SoC设计的能力,其数据量可达千兆字节。因此,工具效率和运行时间可能成为重要因素,需要考虑从RTL更改到新版本的设计分区并在原型板上运行。
最初,RTL分割方法要求在整个设计中进行编译和合成,这可能会导致运行时间过长,并需要大量的服务器资源。然而,在所有FPGA上并行执行FPGA综合,这需要分割工具对每个FPGA的最终结果进行估计,以便推断每个设备上IO的时序预算。好处是,通过并行运行多个综合工具,总运行时间大大提高。每次RTL更改和bug修复的周转时间都会相应减少,特别是在使用增量综合布局布线技术的情况下。
这种流动的缺点是它实际上是一种双通道流动。为了进行正确的分割,需要了解每个RTL模块所需的最终FPGA资源。如果可能的话,如果定时驱动分区是我们的目标,那么每个模块边界的时序知识也会很有用。这种对资源和时间的准确了解只能来自综合(或者最好来自地点和路线)。因此,在将结果反馈给分区器之前,我们需要提前跳过并预运行综合。为了估计资源和时间,综合以快速通过自动模式运行。因此,尽管是两程流程,但实际上预合成似乎是单程流程中的额外“估计”步骤。
自顶向下的RTL分割功能最强大的情况是性能,特别是FPGA间性能至关重要。通过自上而下的工作和使用系统级约束,RTL分割允许同时在多个FPGA之间对时间进行预算和约束。该合成还更能够考虑板级延迟和引脚复用,以便在各自的流中正确地约束各个FPGA。
综合后网表级别分割
下图显示了单个模块如何被合成并分别映射到FPGA元件中,从而产生大量的门级网表。网表被组合成一个层次结构,然后重新分组为FPGA大小可以容纳的规模。同时,为FPGA调整网表(例如,将门控时钟更改为启用),并为将在外部建模的模块(例如,RAM)创建包装器。
网表分割的主要优点是,只有那些已更改的RTL源文件才被重新合成,而其他RTL文件的结果不会被更改。综合生成的网表并进行分区结果也很可能是可重用的,除非模块边界已经改变。这有助于更容易的自动化和作为流编写脚本。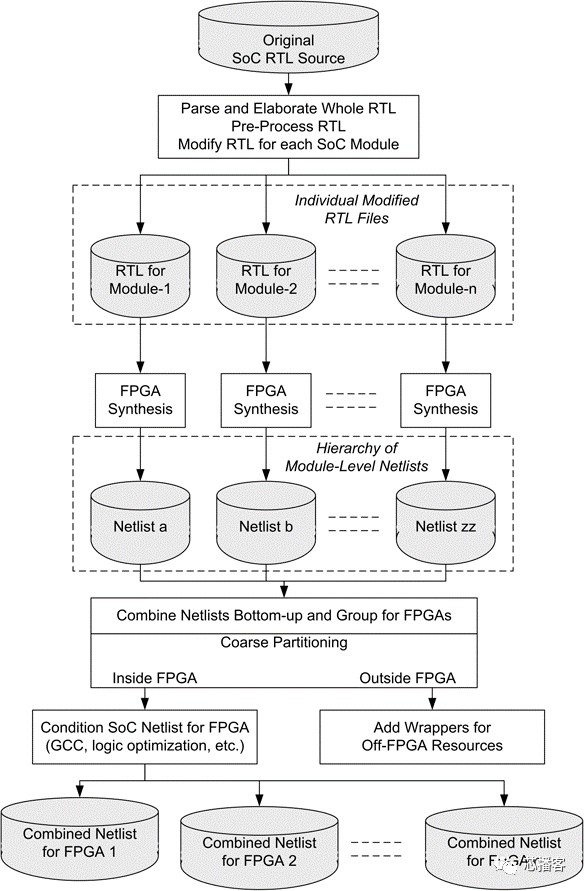
审核编辑:刘清
-
一文掌握多片FPGA的多路复用2023-06-06 2492
-
正确认识原型验证多片FPGA自动分割工具2023-05-23 1209
-
如何将这些SoC的逻辑功能原型正确的移植到多片FPGA中?2023-05-10 849
-
FPGA原型系统装配文件:Assign Traces介绍2023-05-08 1069
-
FPGA原型验证系统中复制功能模块的作用2023-05-04 1695
-
简述FPGA原型验证系统中复制功能模块的作用2023-04-25 2880
-
MIMXRT并口连接外围器件的两种方式2023-01-09 2403
-
在MATLAB/simulink中建模时的两种不同实现方式2022-09-15 3340
-
浅谈集成FPGA的两种方式:eFPGA(SoC)& cFPGA(SiP)2021-08-16 8933
-
求大神分享基于FPGA的DDFS与DDWS的两种实现方式2021-04-30 1487
-
两种线路板分割的方式及多层线路板具体分割方法2020-07-25 7221
-
Wincc如何与PLC进行通讯两种常用的方式介绍2019-02-17 32138
-
SOPC设计中的两种片上总线分析2011-12-15 1884
全部0条评论

快来发表一下你的评论吧 !
