

能遵循instruction的句向量模型
描述
1 简介
句向量技术是将连续的文本转化为固定长度的稠密向量,将句子映射到同一个向量空间中,从而应用到各种下游任务,例如分类,聚类,排序,检索,句子相似度判别,总结等任务,一种优异的句向量技术可以明显提升诸多下游任务的性能。关于如何利用语言模型输出文本的句向量,在21年底的时候写过一篇基于Bert的句向量文章,里面介绍了诸多种基于encoder-only的Bert相关方法Bert系列之句向量生成。
但是之前的句向量技术,泛化能力相对有限,当迁移到新任务或者新领域后,总需要进一步的训练才能保证效果。最近发现了一种新的句向量技术,在输入中加入跟任务跟领域相关的instruction,来指导语言模型生成适配下游任务的句向量,而不需要进行额外的训练,在MTEB榜单的表现可以媲美openai最新的text-embedding-ada-002模型。为了更好地理解Instructor,在这里梳理了Instructor的一个技术演化过程,从Sentence-T5到GTR,再到Instructor,这几种模型都在MTEB榜单上有不错的表现,有兴趣的读者可以自行查询。
2 Sentence-T5
Encoder-decoder结构的T5虽然在seq2seq的任务中表现优异,但是如何从T5中获取合适的句向量依旧未知。于是就有研究尝试了几种从T5中获取句向量的方式,具体如图所示,
a) Encoder-only first,利用T5 最后一层encoder第一个token的特征输出作为句向量。不同于Bert,T5模型没有CLS 的token。所以拿第一个token的输出来当句向量看起来就不靠谱。
b) Encoder-only mean,利用T5最后一层encoder所有token的特征输出平均值作为句向量。
c) Encoder-Decoder first,利用T5最后一层decoder的第一个token的输出作为句向量。为了获得这个token的输出,需要将input文本输入encoder,还需要将代表start的token喂给decoder。
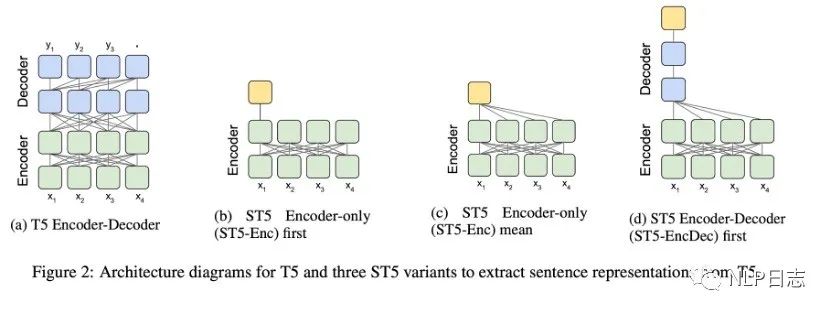
图2: T5模型结构跟3种句向量变体
利用的前面提及的几种句向量变种可以获得固定长度的句子表征,在加上一个全连接层跟Normalization层就可以得到归一化的句向量。训练采用的是双塔模型结构,但是左右两边共用同一个模型跟参数。
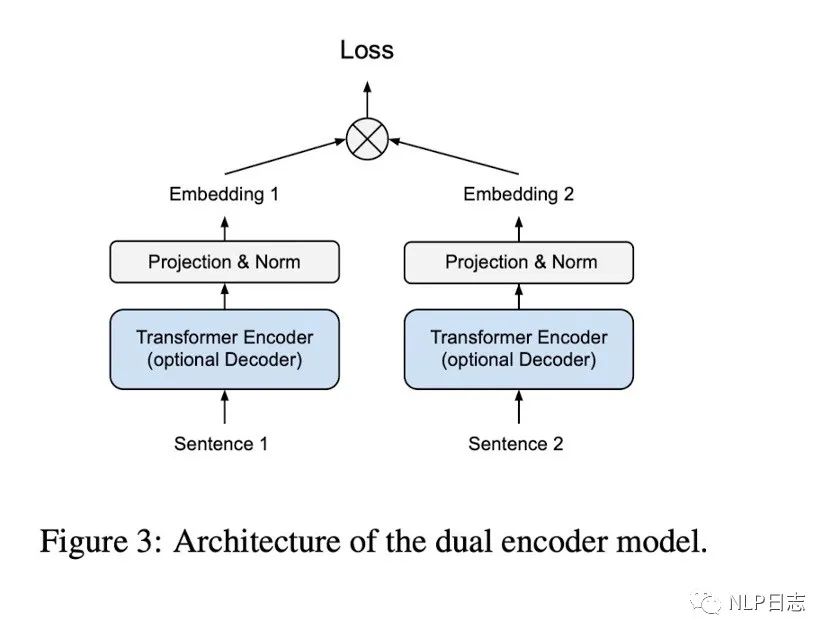
图3: dual encoder结构
训练方法采用的是常见的对比学习,同一个batch内,希望同个instance(sentence1, sentence2)的两个相关句子之间的距离足够接近(分子部分),不同instance里的不相关句子之间的距离足够疏远。如果同个instance还有强不相关的sentence,也希望不相关的句子之间距离足够疏远。同时了,为了研究增加额外训练数据的影响,采用了两阶段的训练方式,第一个阶段现在通用领域的问答数据训练(Community QA),第二阶段才在人工标注的数据(NLI)训练。
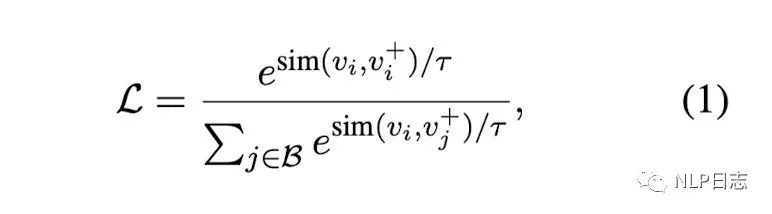
图4: 损失函数
部分实验结论
a) T5 Encoder-only mean的效果明显优于BERT系列,大部分数据集上也优于其余两种T5句向量变体,在更多数据上finetune能给模型带来巨大的提升,从而解决模型T5的句向量坍塌问题。(作者猜测encoder-decoder结构里,encoder更倾向于生成通用性的表征,更具泛化能力,而decoder更聚焦于针对下游任务优化。
b) 在大部分任务上,增加T5模型的规模可以进一步提升性能。
c) 除此之外,还发现了实验中训练过程使用了巨大的batch size,第一阶段的batch size是2048,第二阶段的batch size是512,远超simcse实验中的最佳参数配置64。
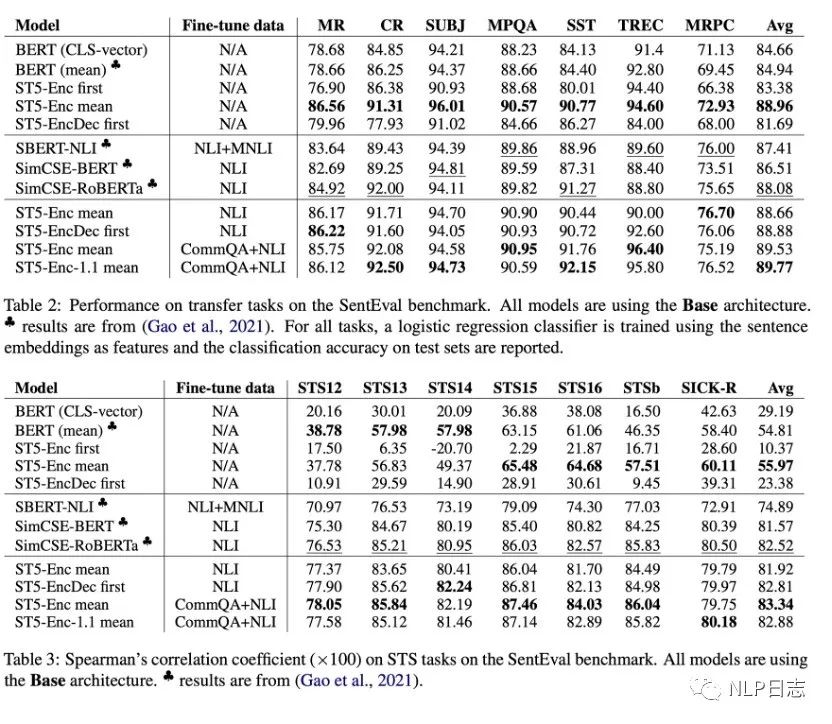
图5: Sentence T5实验效果对比
3 GTR
还是sentence T5的那批人,发现T5的encoder-only mean产生的句向量效果还不错后,就继续在这上面做进一步研究,进一步探索这种句向量模型在检索任务上的迁移能力。模型没变,训练数据把第二阶段换成了另外的检索相关的数据集,MS Macro(Bing的搜索数据)跟Natural Questions(常用于检索的问答数据集)。
训练方法虽然还是用的对比学习,但是具体计算过程跟simcse有所差异,由于每一个instance都包含(query, pos, neg),pos跟neg分别是query对应的相关文档positive跟强不相关文档hard negative,对应的对比学习的损失由两部分,
a) 同一个instance里的query跟pos是正样本,query跟同个batch里的所有neg之间都是负样本。
b) 同一个instance里的pos跟query是正样本,pos跟同个batch里其他instance的query之间都是负样本。
部分实验结论
a) 随着模型规模的增加,在领域外的性能提升明显,换言之,更大的模型具有更强大的泛化能力。同时,也发现GTR对于数据的利用非常高效,在MS Macro数据集上只使用10%的数据也能达到很不错的效果。
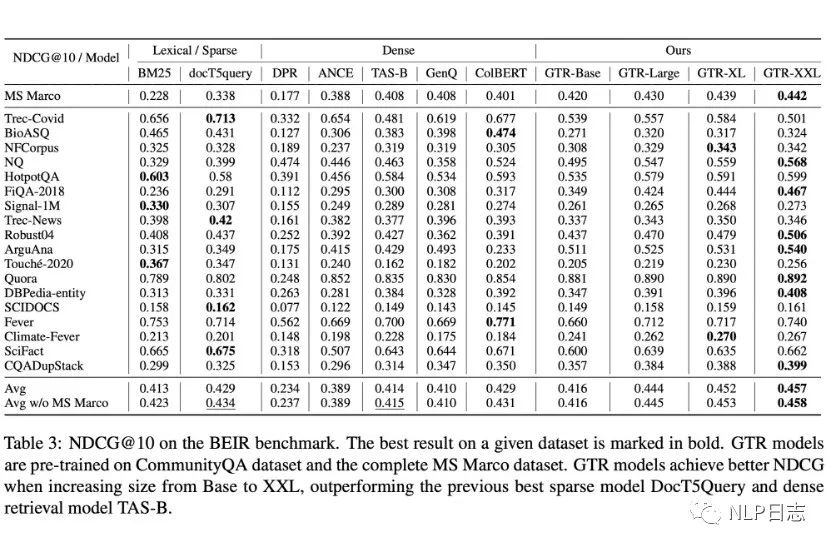
图6: GTR在BEIR榜的表现
b) 做完两阶段训练的GTR强于只做第一阶段或者第二阶段训练的模型,在领域内跟领域外的表现都比较一致,随着模型规模增加也有一定的提升,同时也说明了第二阶段的高质量数据对于模型的帮助。
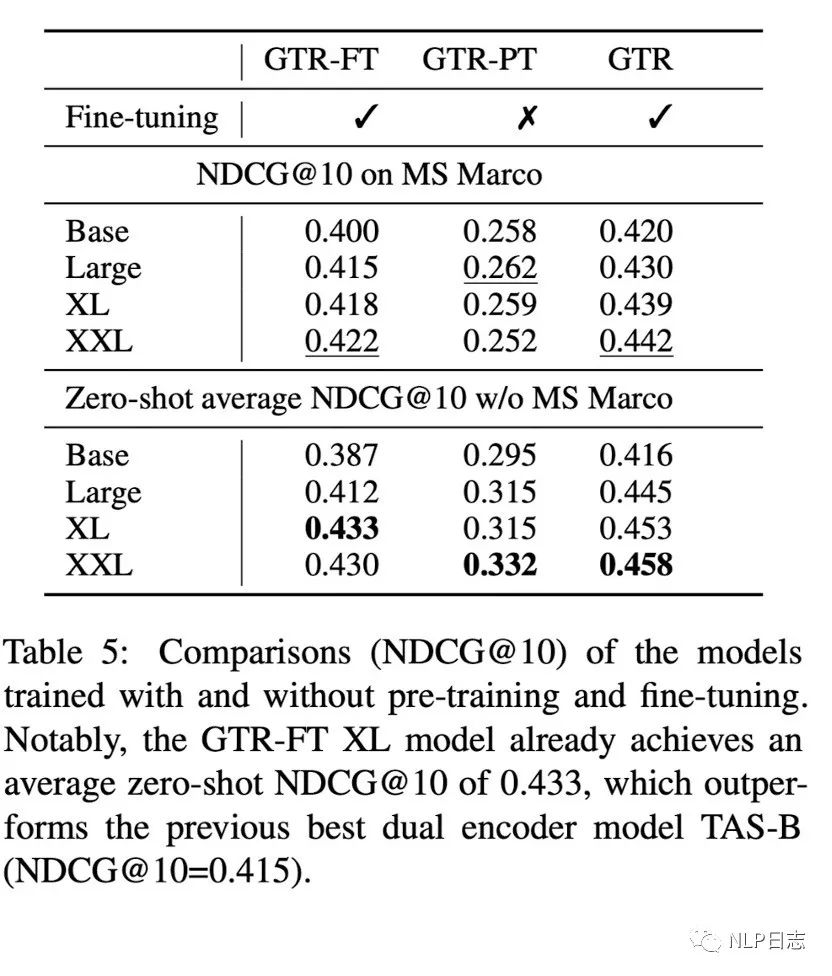
图7: 不同训练阶段的GTR效果对比(GTR- FT跟GTR- PT分别是只进行第二阶段跟第一阶段训练的模型)
c) 随着模型规模的增加,召回的文档长度也有增加的趋势。
d) 依旧巨大的batch size,两个阶段的训练batch size都是2048。
4 Instructor
目前的大模型,在给定instruction后会按照指令生成相应的内容,那么对于句向量模型而言,同样一句话,可以通过给定模型不同的instruction,让模型生成适合下游任务的句向量嘛?instructor就实现了这个设想。
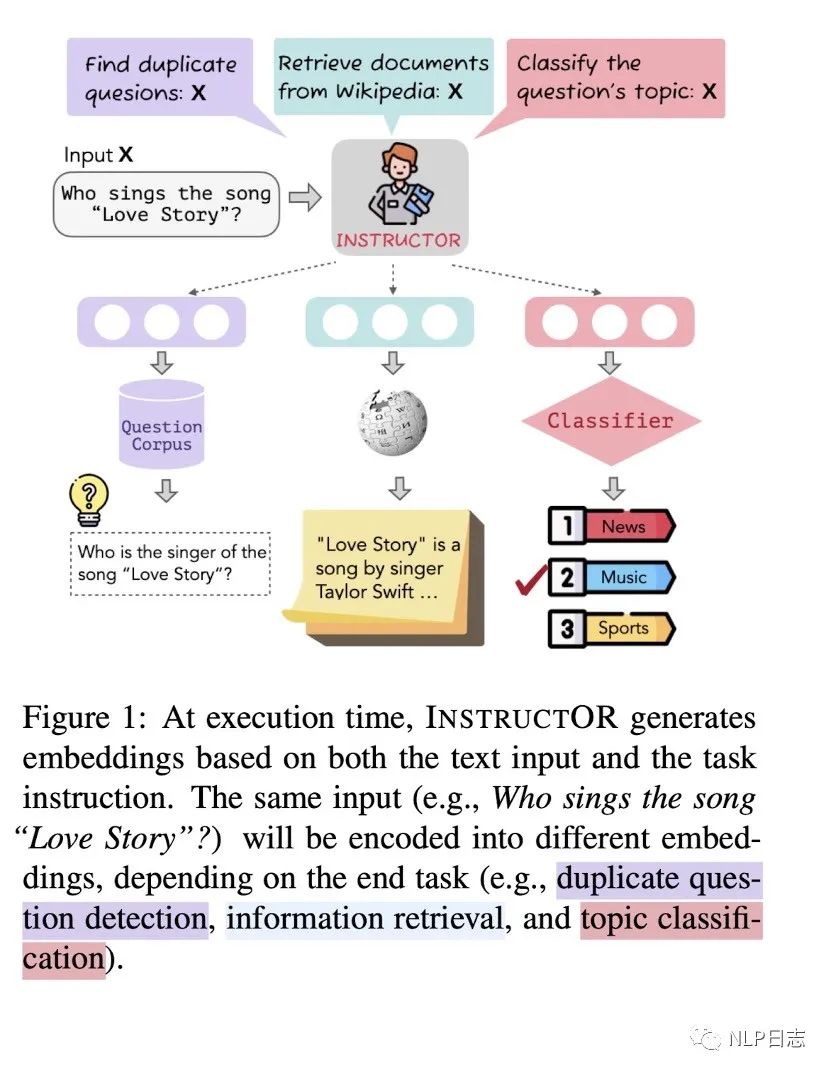
图8: Instructor
Instructor采用了前面的GTR作为初始模型,训练方法也依旧保持,只是原本的模型接受文本作为输入,instructor同时接受instruction跟文本作为输入,从而生成符合指令的句向量
Instructor的训练数据是一个数据集集合MEDI,里面包含330个来自SuperNaturalInstructions的数据集跟30个现存的用于句向量训练的数据集。每个数据集都包括对应的instruction,数据集中的每个instance都是如下格式,
Instance = {“query”: [instruction_1, sentence_1],
“pos”:[instruction_2, sentence_2],
“neg”:[Instruction_2, sentence_3]}
如果是类似句子相似度的对称类任务,那就只有一个instruction,示例中的instruction_1跟instruction_2就是同一个,如果是类似检索的非对称任务,那么query跟doc都各有一个instruction,instruction_1跟instruction_2就是两个不同的instruction。Sentence_2表示是跟sentence_1相关的文本,而sentence_3则是不相关的文本。
通过这种数据集构造,可以保证每个instance都有自身的hard negative,以及同个batch内其他instance充当简单负样本。在训练过程过程,为了提高难度,会保证同个batch里所有instance都来自于同个数据集。
部分结论如下:
a) Instructor在三个榜单的平均表现最佳,在多个不同任务上的呈现出强大的通用能力。
b) 加上instruction的模型训练,让模型在对称类任务跟非对称类任务上都取得明显提升。
c) 训练数据加入了330来自SUPERNATURALINSTRUCTION数据集的多个instruction使得模型具备处理不同类型跟风格的instruction的能力,帮助模型更好的能泛化到新领域。同时,instruction的内容越详细丰富,instructor效果越好。
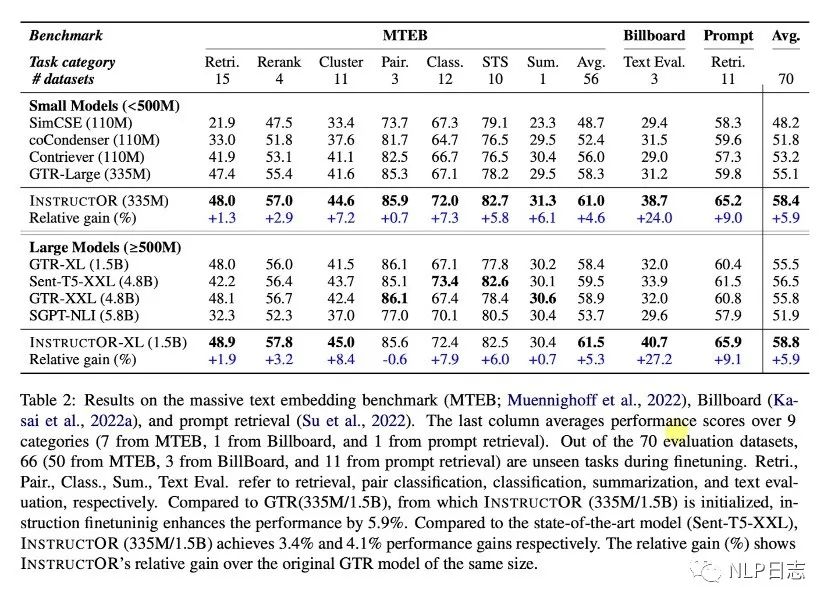
图9:三个榜单的模型表现比较
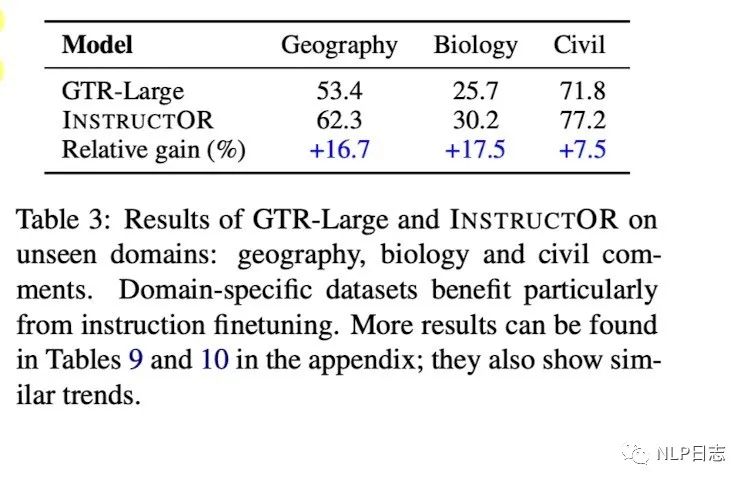
图10: instructor在新领域的表现
5 总结
instruction的引入,使得句向量模型能更好地迁移到新的任务跟领域,而不需要额外的训练。从Instructor的演化进程,不难看出从encoder-deocder模型中选择Encoder-only mean方法,生成的句向量效果明显优于Bert系列的方案,猜测这是由于其中的encoder更倾向于生成更通用的特征,而不是针对下游任务。同时也可以看到虽然还是沿用的对比学习方案,但是训练数据也逐渐从之前的(query,pos)pair对转换为(query, pos, neg)的三元组,通过设置较大的batch,既能保证训练难度,也能保证训练效率。
Instructor看起来还是蛮吸引人的,不由联想到语言模型的instruction tuning工作,有点异曲同工之意。本文提及的这三种方案是循序渐进的,虽然模型都已经开源,但遗憾的是都不支持中文。最近也看到一个中文的句向量开源方案,采用跟instructor类似的训练思路。
审核编辑:刘清
-
科技云报到:大模型时代下,向量数据库的野望2024-10-14 1035
-
大模型卷价格,向量数据库“卷”什么?2024-05-23 3106
-
大模型如何快速构建指令遵循数据集?2023-06-27 4454
-
如何构建词向量模型?2021-11-10 1269
-
构建词向量模型相关资料分享2021-09-17 1294
-
介绍支持向量机与决策树集成等模型的应用2021-09-01 1356
-
基于支持向量机的压力传感器校正模型2021-03-24 1282
-
如何使用智能支持向量机的回归模型进行金融数据的预测2018-12-20 2190
-
基于支持向量回归机的三维回归模型2018-01-25 1389
-
支持向量机的故障预测模型2017-12-29 1234
-
基于支持向量回归的交易模型的稳健性策略2017-12-05 788
-
什么是KNI/Instruction Issue/Instr2010-02-04 555
-
智能N维向量的空间模型2009-03-25 785
全部0条评论

快来发表一下你的评论吧 !
