

小样本学习领域的未来发展方向
描述
什么是小样本学习?它与弱监督学习等问题有何差异?其核心问题是什么?来自港科大和第四范式的这篇综述论文提供了解答。
数据是机器学习领域的重要资源,在数据缺少的情况下如何训练模型呢?小样本学习是其中一个解决方案。来自香港科技大学和第四范式的研究人员综述了该领域的研究发展,并提出了未来的研究方向。 这篇综述论文已被 ACM Computing Surveys 接收,作者还建立了 GitHub repo,用于更新该领域的发展。
论文地址:https://arxiv.org/pdf/1904.05046.pdf
GitHub 地址:https://github.com/tata1661/FewShotPapers
机器学习在数据密集型应用中取得了很大成功,但在面临小数据集的情况下往往捉襟见肘。近期出现的小样本学习(Few-Shot Learning,FSL)方法旨在解决该问题。FSL 利用先验知识,能够快速泛化至仅包含少量具备监督信息的样本的新任务中。 这篇论文对 FSL 方法进行了综述。首先,该论文给出了 FSL 的正式定义,并厘清了它与相关机器学习问题(弱监督学习、不平衡学习、迁移学习和元学习)的关联和差异。然后指出 FSL 的核心问题,即经验风险最小化方法不可靠。 基于各个方法利用先验知识处理核心问题的方式,该研究将 FSL 方法分为三大类:
数据:利用先验知识增强监督信号;
模型:利用先验知识缩小假设空间的大小;
算法:利用先验知识更改给定假设空间中对最优假设的搜索。
最后,这篇文章提出了 FSL 的未来研究方向:FSL 问题设置、技术、应用和理论。 论文概览 该综述论文所覆盖的主题见下图:
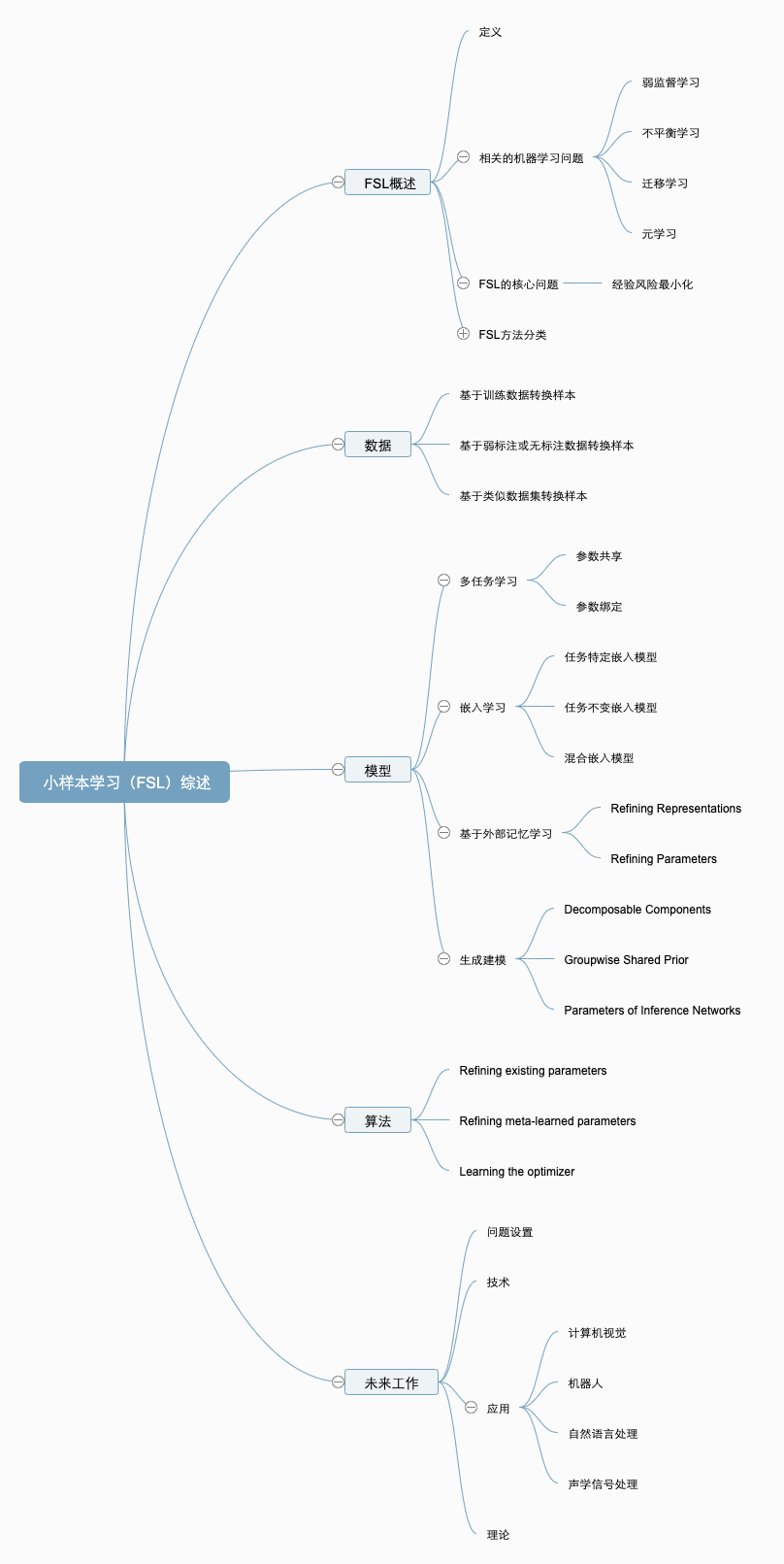
我们选取介绍了该综述论文中的部分内容,详情参见原论文。 什么是小样本学习? FSL 是机器学习的子领域。 我们先来看机器学习的定义: 计算机程序基于与任务 T 相关的经验 E 学习,并得到性能改进(性能度量指标为 P)。

基于此,该研究将 FSL 定义为: 小样本学习是一类机器学习问题,其经验 E 中仅包含有限数量的监督信息。
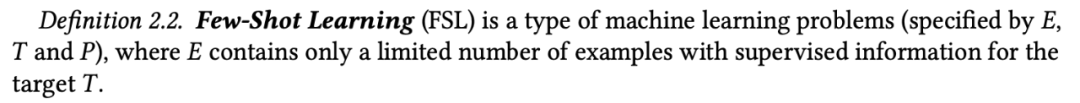
下图对比了具备充足训练样本和少量训练样本的学习算法:

FSL 方法分类 根据先验知识的利用方式,FSL 方法可分为三类:
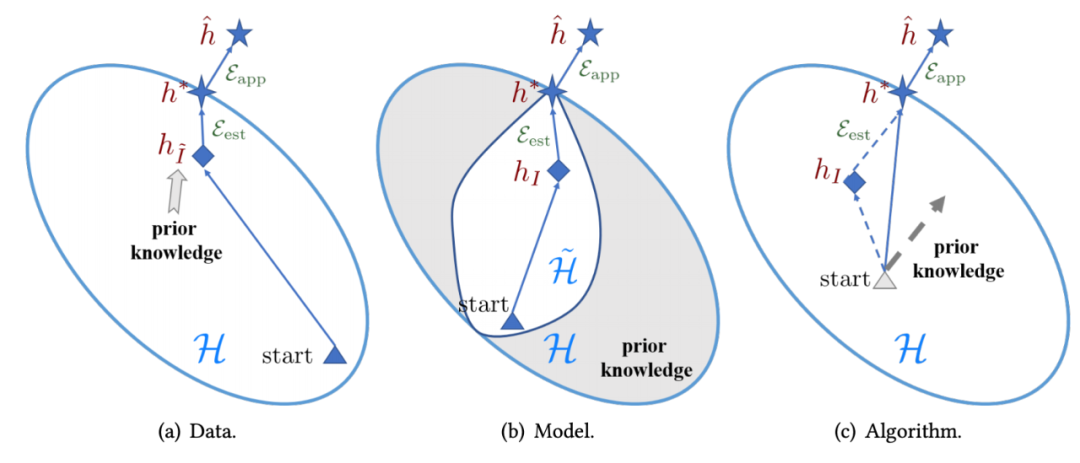
FSL 方法解决少样本问题的不同角度。 基于此,该研究将现有的 FSL 方法纳入此框架,得到如下分类体系:
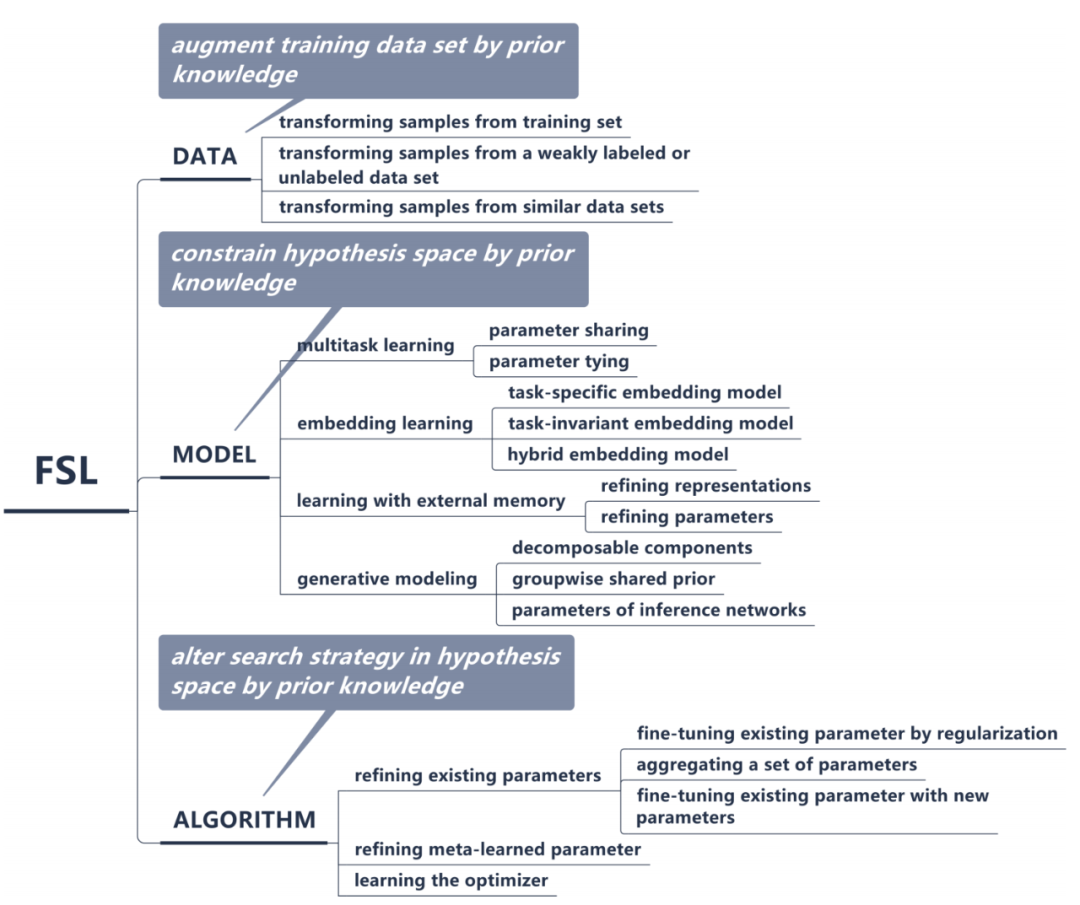
数据 此类 FSL 方法利用先验知识增强数据 D_train,从而扩充监督信息,利用充足数据来实现可靠的经验风险最小化。
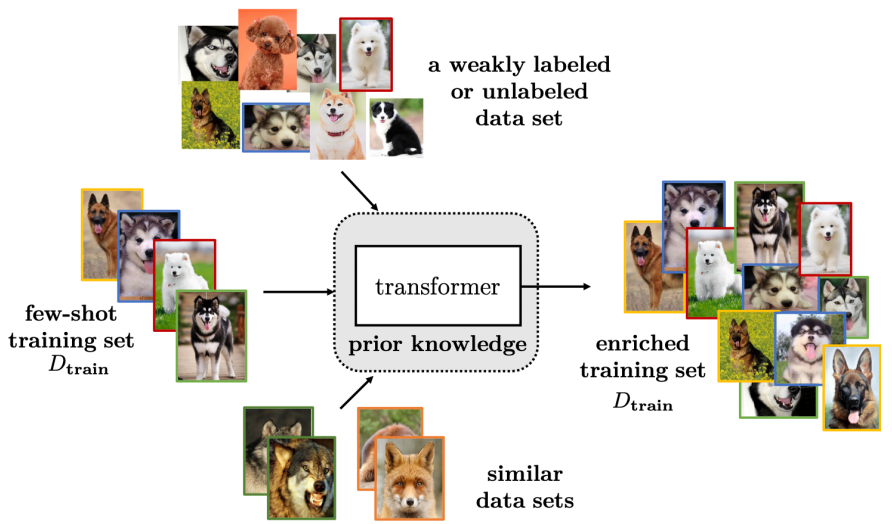
如上图所示,根据增强数据的来源,这类 FSL 方法可分为以下三个类别:
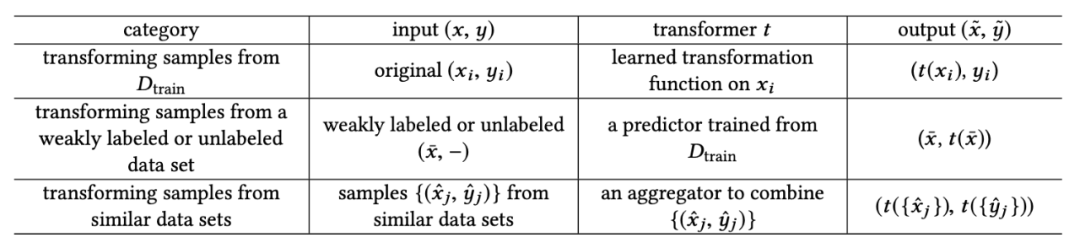
模型 基于所用先验知识的类型,这类方法可分为如下四个类别:
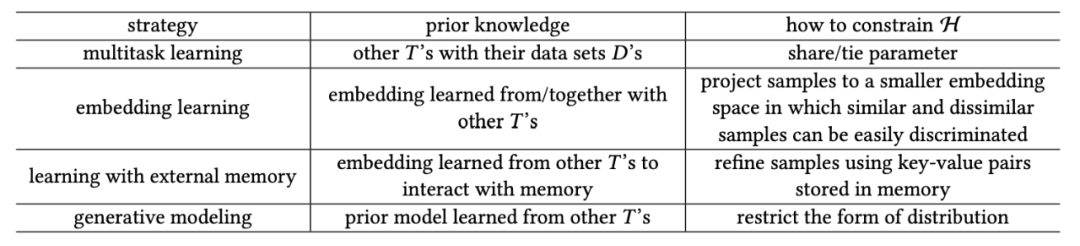
算法 根据先验知识对搜索策略的影响,此类方法可分为三个类别:

文章最后从问题设置、技术、应用和理论四个层面探讨了小样本学习领域的未来发展方向。
责任编辑:彭菁
-
LED灯条未来的发展方向2011-03-29 4225
-
嵌入式领域的职业发展方向怎么样?2015-09-22 3826
-
FPGA学习方法及发展方向2015-11-24 8147
-
学习嵌入式的优势和发展方向2018-07-30 4607
-
单片机的原理是什么?未来如何发展?2021-04-20 1958
-
嵌入式系统开源软件的现状及未来的发展方向2021-04-28 3068
-
学习C语言未来的发展方向是怎样的?2021-11-11 3178
-
答疑解惑探讨小样本学习的最新进展2020-05-12 5041
-
深度学习:小样本学习下的多标签分类问题初探2021-01-07 8603
-
融合零样本学习和小样本学习的弱监督学习方法综述2022-02-09 3272
-
一种基于伪标签半监督学习的小样本调制识别算法2022-02-10 1537
-
人工智能(chatGPT)未来发展方向2023-06-29 2146
-
电梯智能传感系统的应用前景和未来发展方向?2023-09-18 1700
-
DC电源模块的未来发展方向与挑战2024-01-29 1371
-
MES未来可能的发展方向2024-02-28 469
全部0条评论

快来发表一下你的评论吧 !
