

走向实用的AI编解码阐述
人工智能
描述
-01-
AI编解码的意义与挑战

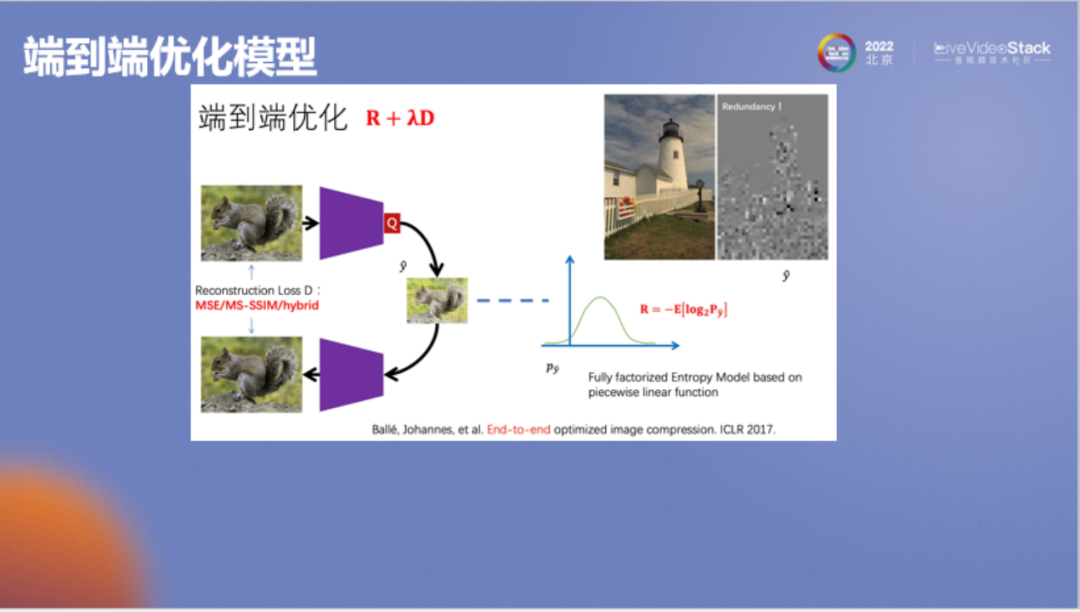
以上是高通总结的关于AI编解码优势的一张示意图。其中相当多的优势来自于端到端优化这一特性,它的压缩率比较好,可以对任意分布的数据做专门优化,可以针对任意更符合主观质量的、更符合下游任务的损失函数进行优化。
另一方面,由于它是用神经网络实现的,那便可以在人工智能的大潮中进行复用,例如复用各种推理硬件和算法。还有一个好处是权重比较容易更新,传统编解码算法在做成硬件后很难进行修改,但对于基于神经网络的AI编解码算法,它的权重是可以进行修改的,这是一个很大的优势。

接下来介绍个人认为对AI编解码器较为重要的六个评价维度,第一是率失真性能和主观质量,它主要和压缩率有关;第二是复杂度,它与延时、计算量和显存的要求还有功耗、吞吐率等因素有关;第三是跨平台解码,在手机、CPU、GPU上互相编解码不应该出错;第四是对下游AI任务训练和推理的影响,对测试或推理的影响类似于现在比较热门的面向机器视觉的编解码,在训练方面大家会比较关注用AI压缩的数据是否会对神经网络的训练效果产生影响;第五是泛化与特化能力,有时我们希望它可以泛化,使用同一个模型可以压缩不同数据,有时我们希望它可以特异化,例如在压缩遥感或者医学类数据时,可以构造专门的模型使对应数据的压缩率更高;最后则是转码稳定性,这也是一个有意思的问题,包括传统算法和AI算法间的互编互解,例如将JPEG二次压缩再解码,过程中是否有性能损失。
-02-
提升RD性能与解码速度

接下来介绍如何提升RD性能和解码速度,图中的白色文字为前人所做的一些早期经典研究成果。第一篇为纽约大学的论文,模型成果第一次在PSNR上超过JPEG 2000。第三篇论文的模型成果首次在PSNR上超过BPG,BPG对应H.265的帧内压缩技术,但解码速度下降了约60倍。
我们的工作自此开始展开,具体表述为下面的黄字部分。首先我们于2021年构造了棋盘格上下文模型,消除了60倍复杂度,又于2022年对模型进行了一些新的改进。
以上是纽约大学在ICLR上发表的论文,它是一个简单的变分自编码器(Variational Auto-Encoders)。它首先将图像变到一个特征域进行概率估计,然后用熵编码对特征进行压缩。该模型是2017年的研究成果,当时已经超过了JPEG 2000。

论文作者在加入谷歌后构造了一个新的尺度超先验模型(Scale Hyperprior)。它的思想是:在压缩神经网络特征时我们实际使用的是独立假设,由于它是一个很高维的向量,所以不能使用联合概率密度分布。该模型通过引入先验Z使得要压缩的特征Y变为条件独立,因而可以使用概率密度估计和熵编码算法将特征Y压缩得更小。该模型中特征Y和先验Z的码率之和比2017年论文中Y的码率更小,这是通过引入更精准的数学建模带来的提升。
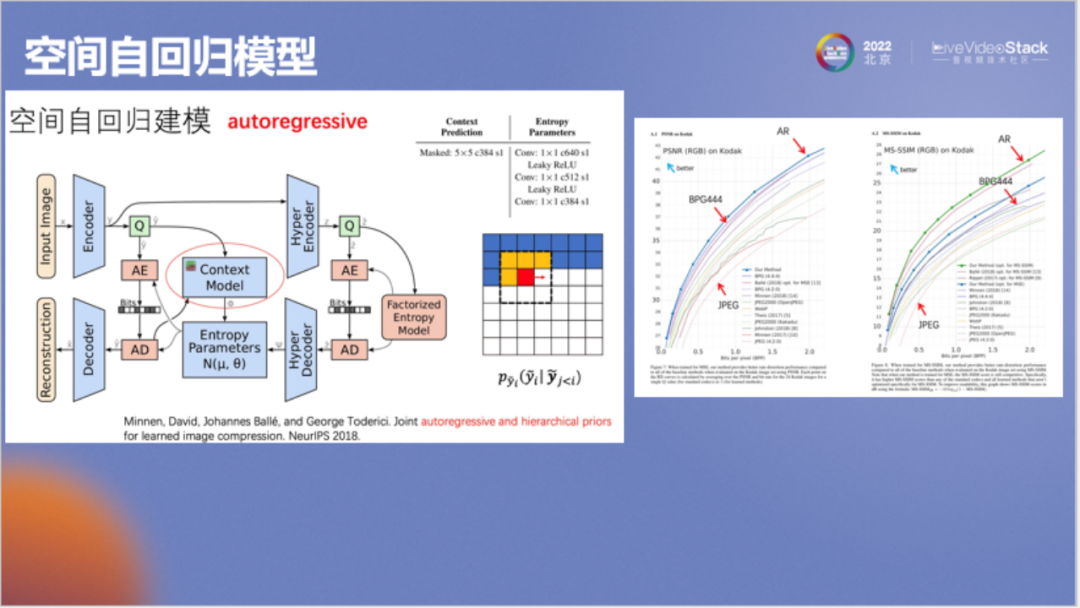
谷歌接着又对模型做了进一步改进,即前面提到的空间自回归模型(autoregressive),它的思想是:在压缩码字Y时我们并不能做到独立压缩,如在压缩左侧方格图中的红色像素时,需一并考虑周边的黄色像素结果,这与传统算法中的帧内预测相似,被称为自回归。模型效果如右图所示,其成果第一次超过了BPG,非常有代表性。

接下来介绍我们的算法,刚才提到的自回归模型要逐个像素串行解码,速度相当慢。我们在此基础上提出右图所示的棋盘格模型。例如在第一次解码时,我们使用GPU来并行解码右侧方格图中所有蓝色和黄色的点,第二次解码红色和白色点,由此可通过两次解码解出整张图。按照谷歌的原方法,串行复杂度为N^2,使用棋盘格模型,串行复杂度仅为2。
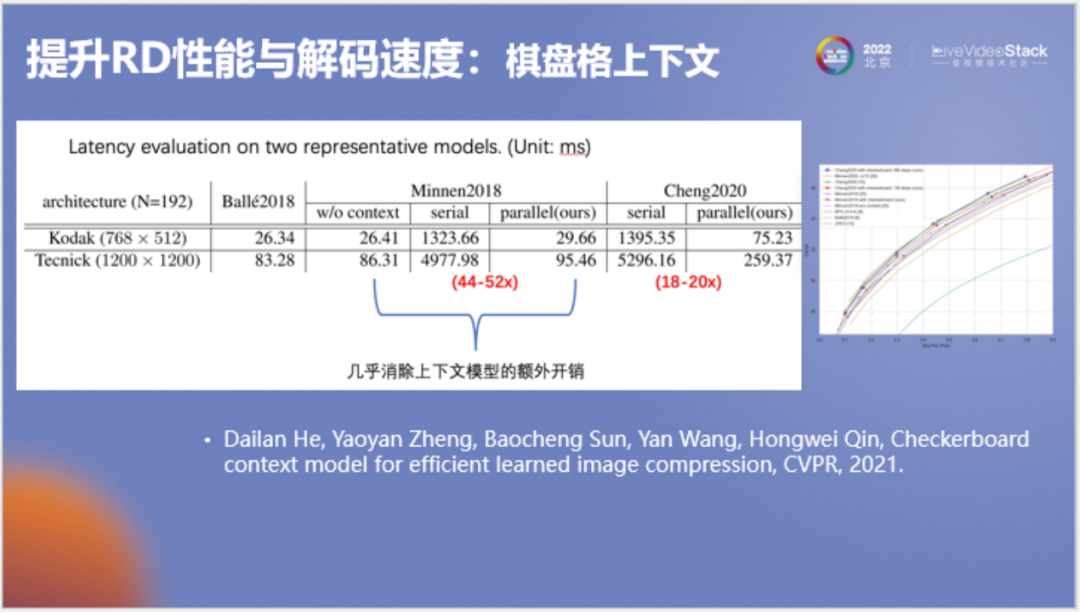
以上为测速结果,在典型模型上棋盘格模型能加速40到50倍,在变换网络较大的模型上能加速18到20倍。该研究成果发表于CVPR 2021。
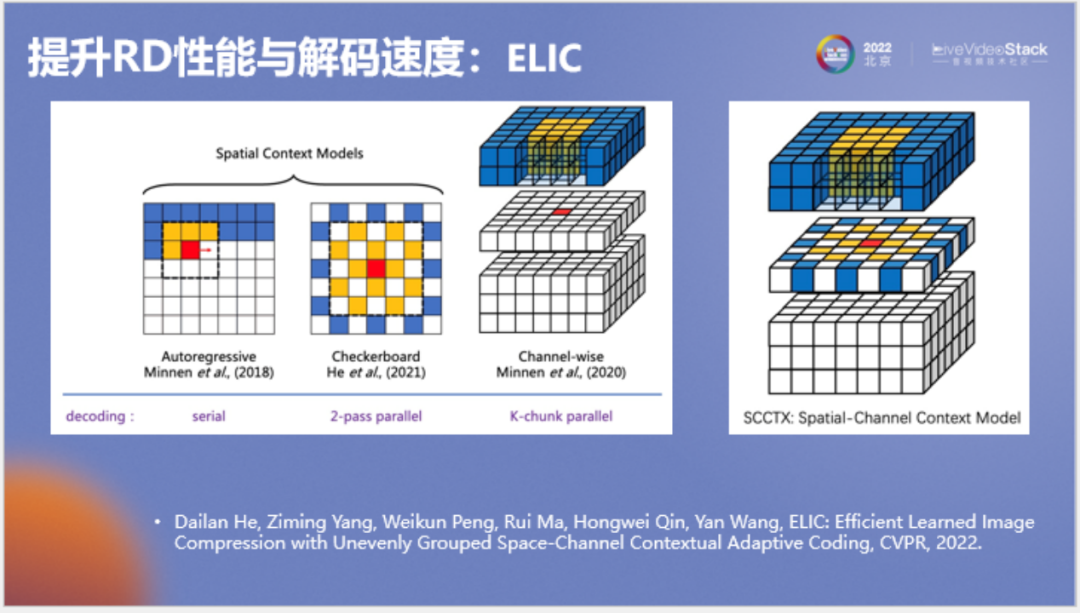
在2022年CVPR中,我们对原论文进行了改进,将谷歌的自回归模型和棋盘格模型进行了结合,成为了一种既有通道自回归、也有空间上下文的并行上下文模型,该模型取得了非常好的效果。
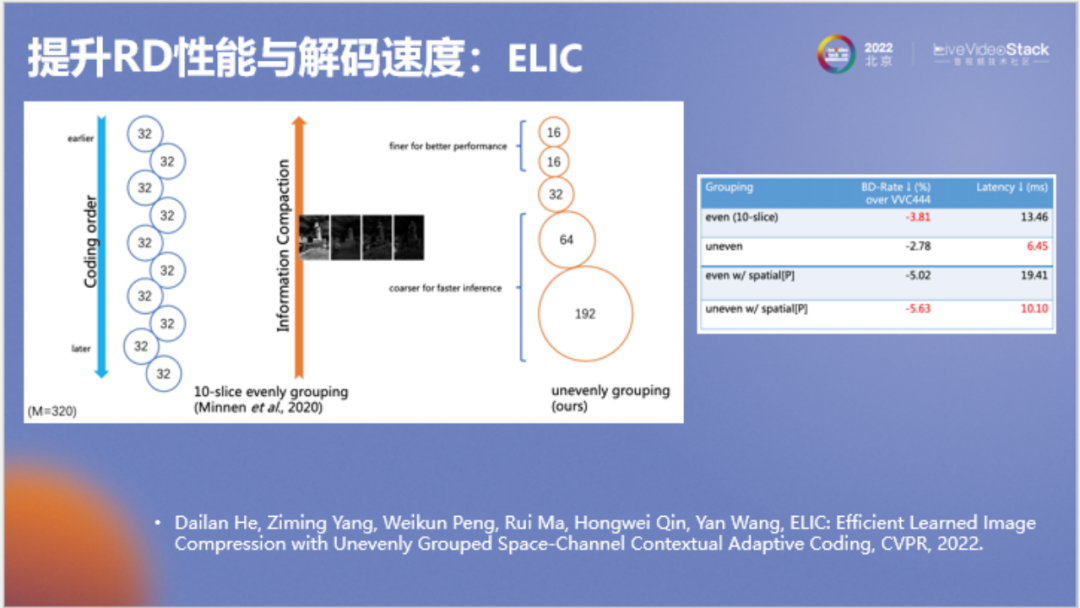
以上为对模型所做的另一项改进,即将通道划分改为非均匀划分。谷歌原模型每个通道分组都为32,需要的分组较多。我们发现实际上其中信息的分布是不对称的,只有少数信息分组比较重要。为了提高速度,我们将非重要分组进行了合并,在提高速度的同时甚至提高了压缩率。
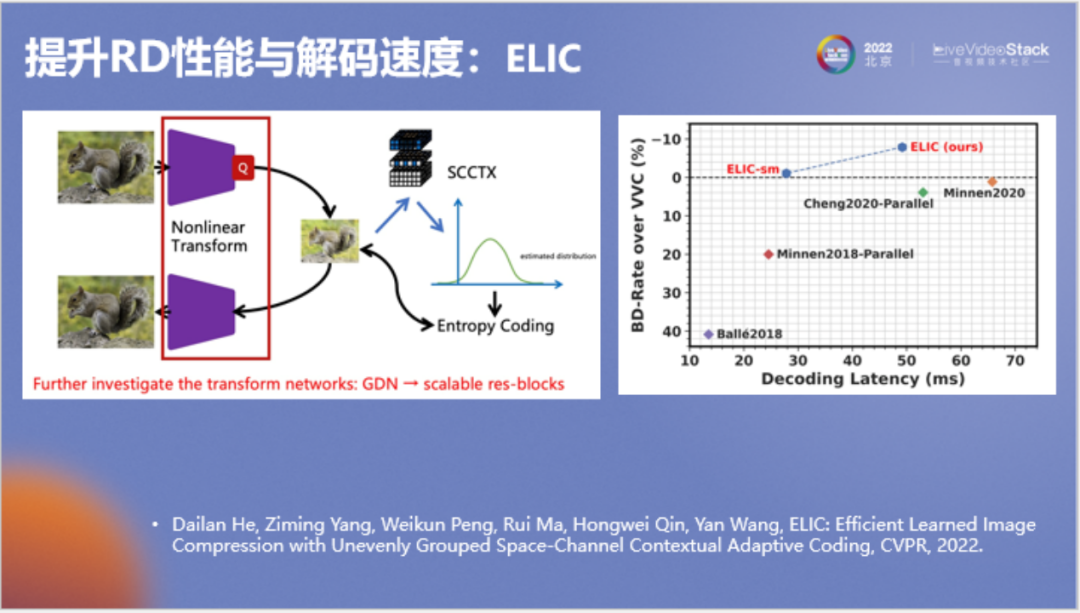
以上是我们新模型的结果,显示为红色,最终要优于VVC,并且与之前的一些网络速度相近。图表中横轴为解码速度,纵轴为压缩率。
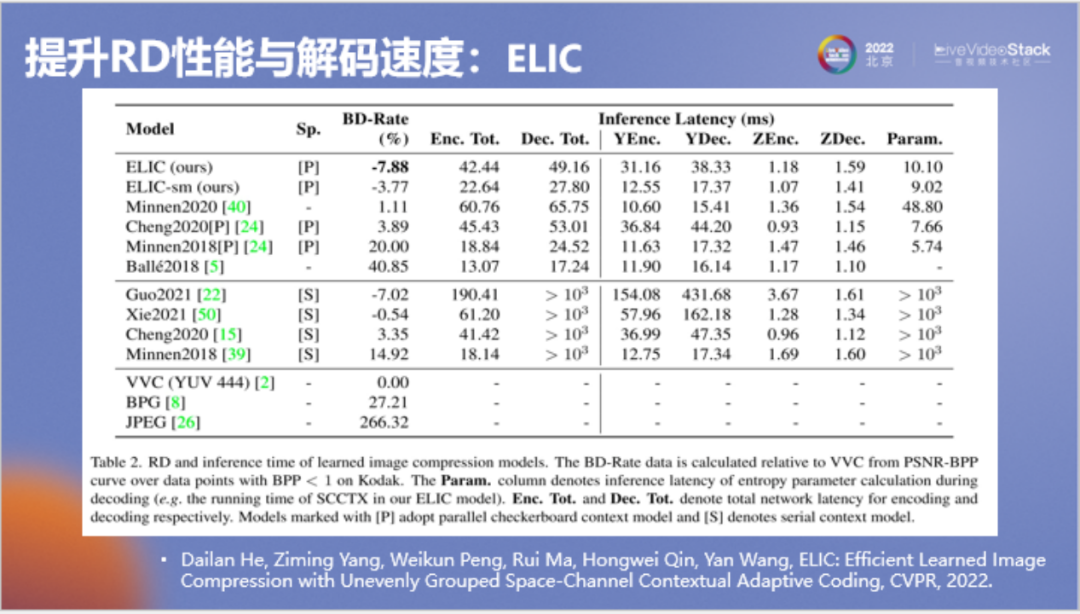
上表可以更加直观体现论文研究成果的贡献,这实际是端到端图像压缩领域的一个里程碑式的进展。可以看到所有在BD-Rate上显示为负数的优于VVC的方法,其解码速度都要大于1000,解码一张图大约要大于1秒。早期论文的解码速度都在20到50毫秒。我们的论文首次实现了BD-Rate在约-7%时,解码速度仍只有50毫秒,这是相当快的速度。

此后我们对VAE框架进行了进一步研究,VAE框架中存在均摊变分推理现象,利用这个现象引入半均摊变分推理,可以在编码时对码字进行一定更新并实现很多灵活的控制。如可以实现连续变码率,使用同一个解码器可以解不同码率的图像。可以实现任意ROI编码,还可以去权衡不同的质量评价指标,比如PSNR和LPIPS,大家知道这些指标和主观质量的相关性各有不同,权衡不同指标等于在权衡解码图像的不同特点。我们将相关方法也扩展到了端到端视频编解码上,相关成果发表在ICML 2023。

这是我们发在NeurIPS 2022上的一篇论文,端到端图像压缩领域除了调整网络结构外,其实会有比较深入的理论背景,我们对理论进行了更深入的探索,将单样本采样改为多样本采样。造成的结果是训练速度会变慢一些,但压缩和解压缩速度完全不受影响。利用这个技术我们取得了一个较明显的压缩率的提升。
-03-
提升主观质量

下面介绍一下如何提升主观质量。一般编解码器在进行设计时,优化指标为PSNR、 SSIM或VMAF。但它们与主观质量的差距都较大,实际上也不存在与主观质量绝对一致的数学指标,这给我们造成了很大困难,一般我们会选择同时优化多个数学指标来使最终的主观质量变好。

在端到端图像压缩领域一般会有两个较常见的数学指标:PSNR和MS-SSIM,我们希望设计一种模型,在其训练后使两种指标都较高,最后的主观质量更好。
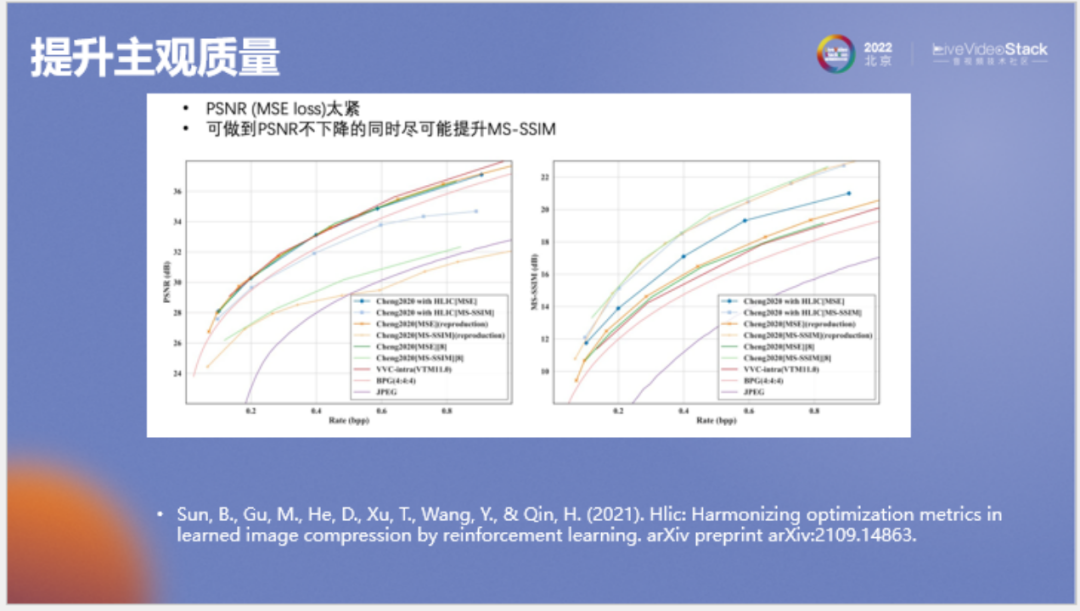
通过实验发现,我们能够做到在PSNR不下降的情况下尽可能提升SSIM指标,使主观质量得到提升。

以上为展示效果图,左上角为原图,最右侧为VVC结果。中间以SSIM标记的是使用MS-SSIM做损失函数训练的模型所优化的结果,最终会出现色偏。用MSE训练的结果在码率较低的位置(如图中水的位置)会损失纹理。使用我们的方法训练的两个模型可以较好的平衡PSNR和SSIM,不发生色偏和纹理损失。

在上图中情况是相同的,尤其在草地部分,MSE结果草地会较糊,SSIM结果草地颜色会出现偏差,而经过改进后模型的效果是较好的。

谷歌也相当重视提升主观质量这方面工作,在每年的CVPR上都会组织图像压缩竞赛,该赛事拥有比较完善的主观质量评估流程,通过众包的方式请很多人来看图,会规定图片的分辨率和与屏幕的不同距离来评估解压图像的主观质量,竞赛的组织者一般是国际上比较知名的一些厂商。

我们也参加了该赛事,使用的方法就是同时优化多个数学指标,第一个是感知损失,第二是重建损失(例如PSNR或SSIM),第三是对抗损失,第四是风格损失,其中三个损失函数都和深度学习有关。我们将四个损失函数以一种特定系数去进行组合,最后优化出来的模型在各种评价指标上都是最佳的。
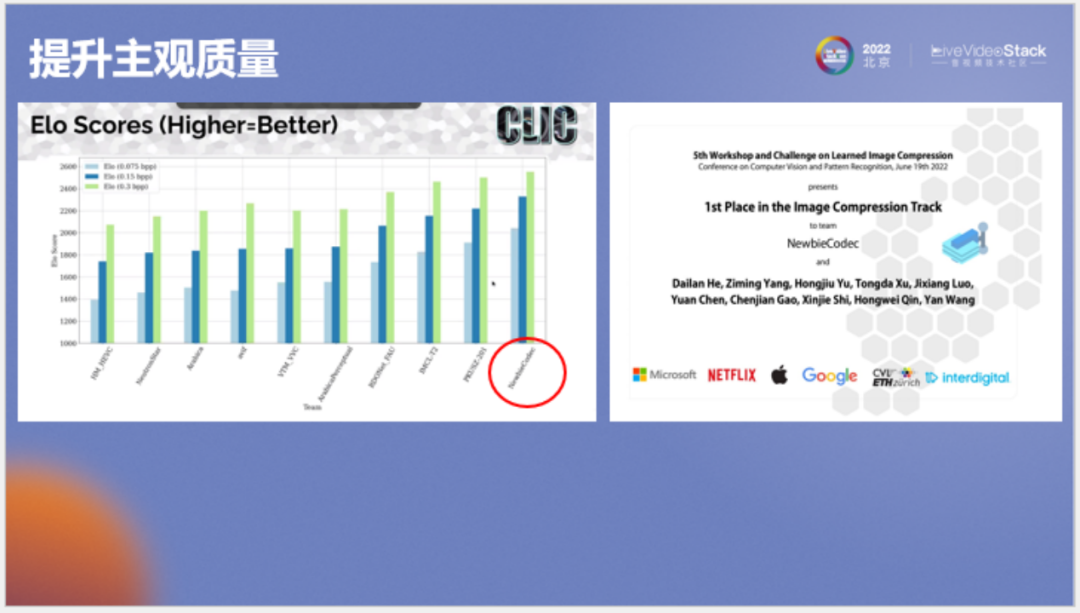
我们以该模型解压的图像参赛,最终获得了所有码点的第一名。
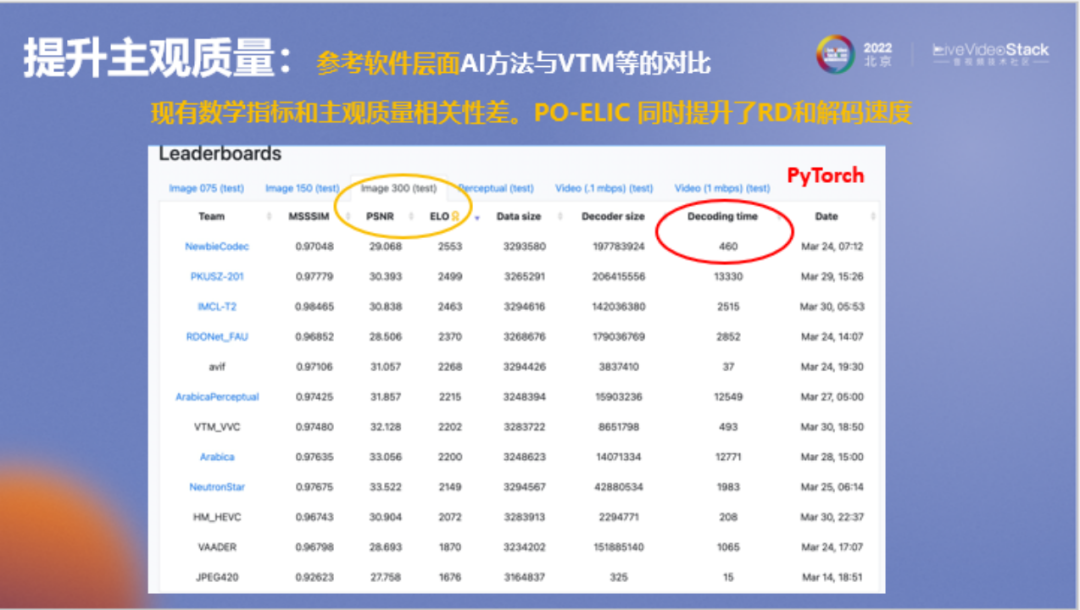
这是谷歌官网对所有方法的评测结果,首先我们关注一下主观质量和数学指标间的关系,例如PSNR,我们可以看到像avif、VVC和HEVC方法的PSNR都较高,但对应的ELO列(人眼看图的主观质量)都不太好,印证了PSNR和SSIM不代表主观质量这一结论。
另一方面,可以看到我们方法的解码速度,它是用PyTorch编写的,解码速度达到了460,VVC在谷歌测试中是493。我们的模型主观质量比VVC更好,解码速度还要更快,但比avif在解码速度上要慢一些。
不过需要注意的是,它只是参考软件层面的对比,因为这里的VVC是使用VTM进行测试,AI方法一般是使用PyTorch进行测试,所有方法都没有进行工业级的性能优化。
-04-
跨平台编码
下面讲一个看起来比较偏,但实际对编解码比较重要的问题,即跨平台解码。
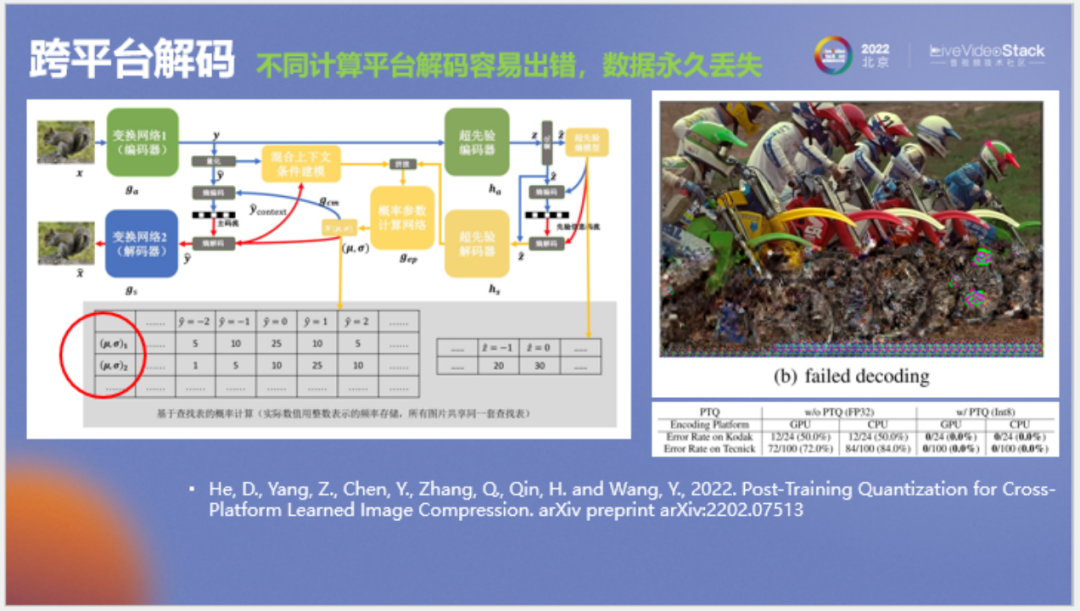
这个问题主要来自于熵编码,我们进行熵编码或算数编码时每个码字的概率不能出错,如果有任何微小的错误,后面的码点便解不出来。如上图所示,前面一直在正常解码,一旦算到某处一个像素不对,那么后面所有的解码都会出错,概率错了所有码点都解不出来。假如在压缩图片时原先使用的硬件丢失,那么图片数据也会永久消失。
这个问题的解决办法是使图片的编解码过程,尤其是熵编码的概率计算过程不管在何种硬件上(如CPU、GPU还是不同型号的NPU或DSP)计算结果都完全一致。据我所知,唯一的方法便是使用完全整数计算来实现。
首先针对概率计算有关的所有神经网络,我们均使用全整数推理,同时以使用查找表而非直接计算的方式来进行概率计算。这样所有过程都是用整数来实现的,可以确保编解码具备跨平台条件。以上工作比较细节,所以我们公开了一个比较详细的技术报告,有兴趣实现技术落地的可以参考。
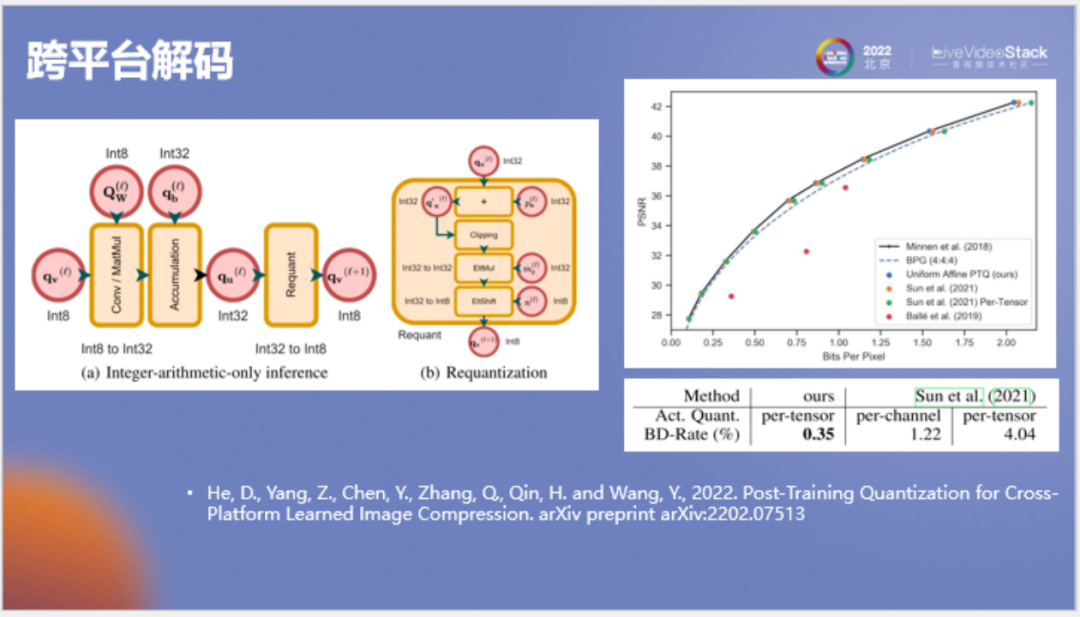
上图为性能对比,我们将新方法和之前类似的方法进行了对比,我们是首先在有上下文的图像压缩模型上实现不掉点的整数推理,而且我们的量化方案比较标准,没用对激活值进行逐个通道的分组量化,适用于常见的GPU和NPU。
-05-
优化延时与吞吐

最后关于有损压缩方面介绍一下优化延时与吞吐。优化一个AI编解码器的速度主要包括两部分工作:一是优化神经网络推理的延时,另一个是优化熵编码的延时。最后整个系统要做一个代码层面或者软件工程层面的优化。
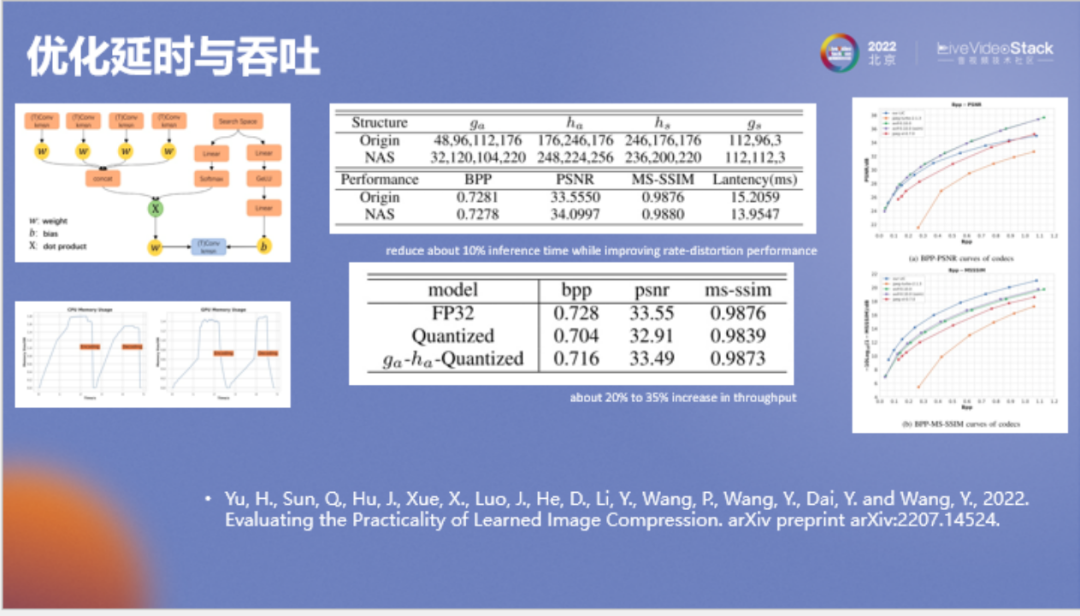
首先看一下神经网络的优化,它的方法都是比较标准的。其中一个是神经网络架构搜索(NAS),一个是模型量化。NAS提升显得较小是因为这些神经网络已经经过了人工优化。左下角是它的CPU和GPU显存占用情况。由于针对此模型我们主要调整它的主观质量,所以它的PSNR会弱一些。可以看到该模型的PSNR比avif低,但SSIM值很高。
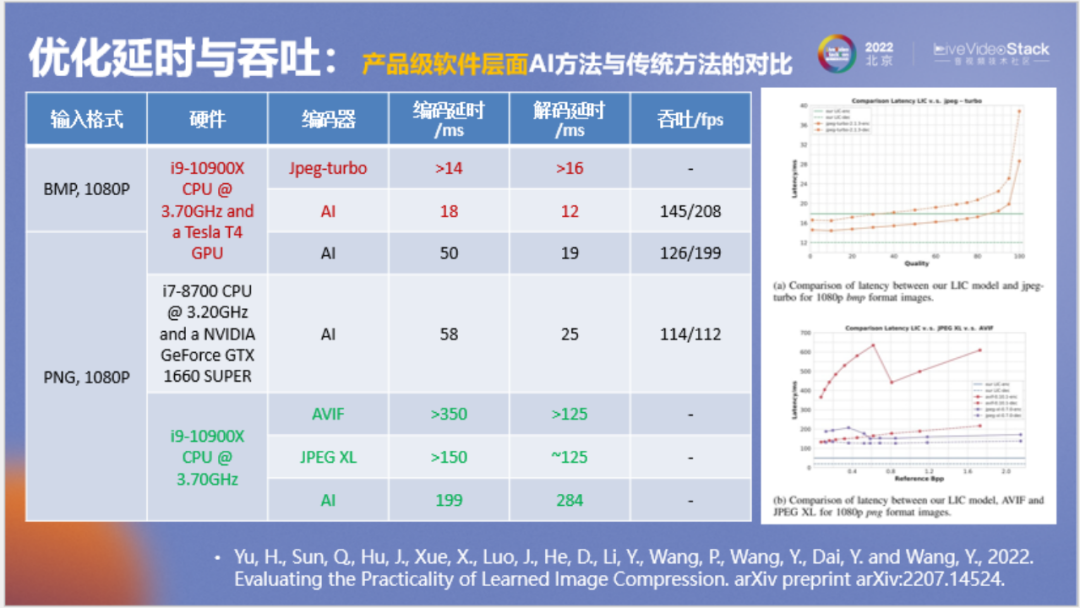
在本页我们想回答一个问题,神经网络图像压缩和传统方法相比性能有何差距?我们希望进行相对公平的对比。首先要使用相同的硬件,例如都使用CPU,以编解码延时来衡量,神经网络图像压缩和JPEG XL和avif在性能上是接近的,如果我们将avif和JPEG XL作为工业应用的发展方向,显然神经网络图像压缩也可以作为一个发展方向。
如果我们看GPU,可以发现在相同的输入条件下,神经网络方法和JPEG-turbo相比,它在编解码上并没有很大的劣势,解码还要快一些。
但这里有一个关于线程的小问题,从JPEG官网来看,它的测试也会有一些问题,就是到底采用什么样的线程数来测试这些模型,使用不同的线程数测试结果也不同。我们采用了单线程进行测试,对于传统方法采用的是默认配置,使用多线程在测吞吐时会有更大优势,具体可以参考我们的技术报告。这个结果可以作为一个参考,实际使用中应该结合运行环境进一步对线程资源进行适配。
-06-
应用拓展:JPEG无损压缩
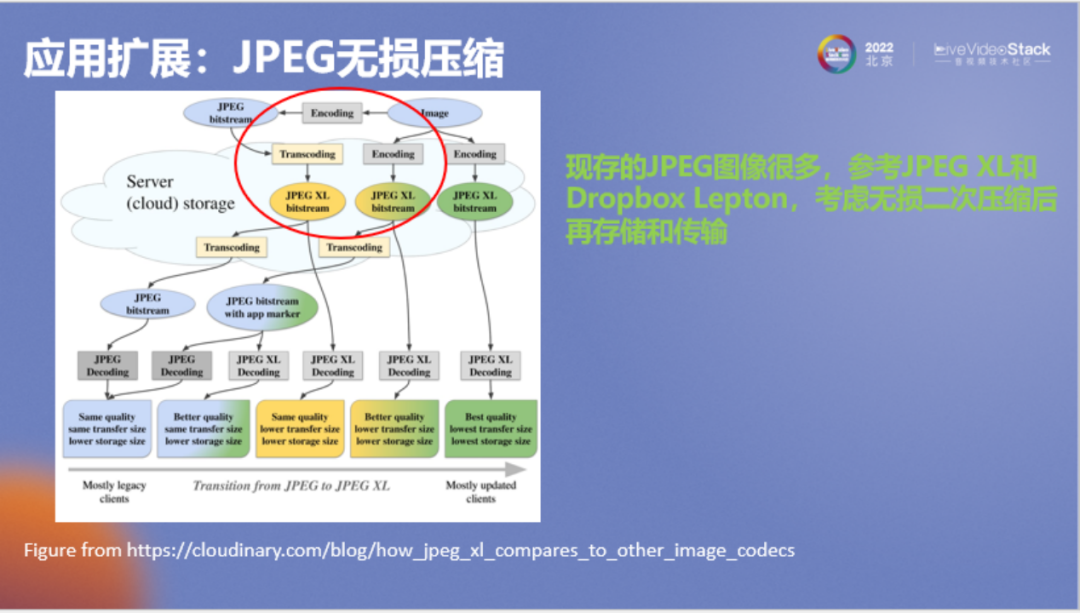
刚才介绍了有损压缩,接下来分享一个比较有意思的应用,即无损压缩。假如端到端有损压缩方法实际落地要等很长时间,那么我们现在已经有了非常多的JPEG图像,能不能考虑使用AI方法对这些图像进行无损压缩。
其实已经有人注意到这个问题,但使用的不是神经网络,例如JPEG XL或者Dropbox的Lepton,Lepton目前已经被Dropbox使用了很久,它的思想是在进行云存储时对JPEG图像进行无损二次压缩,在不改变用户数据的同时极大压缩存储量。所以它整个生态不会受到任何影响,在网络上还是以JPEG格式进行传递,但是云存储使用的是二次压缩后的码流。
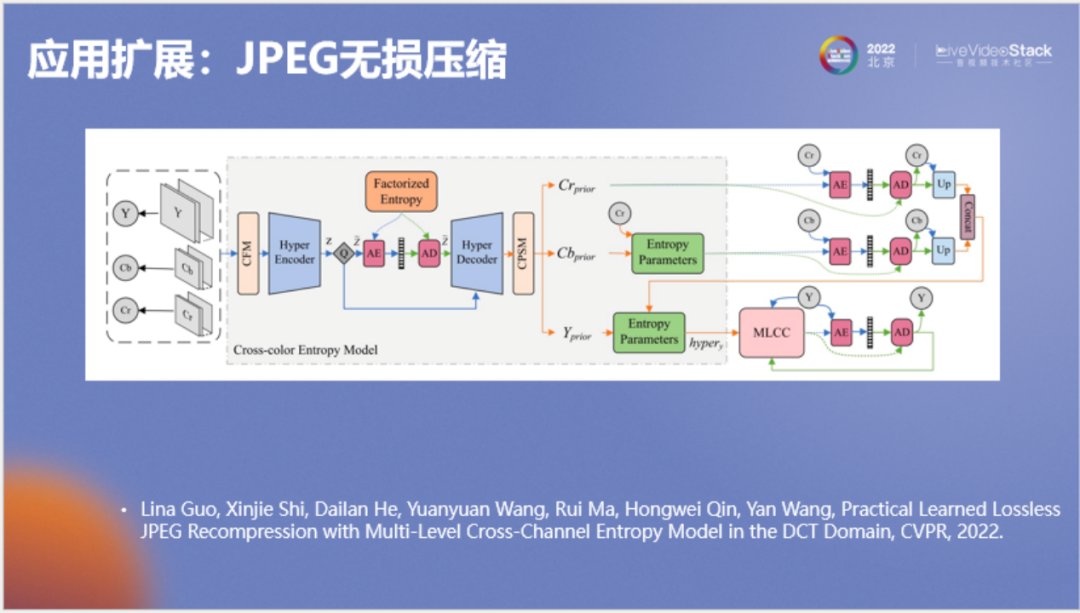
就此我们在CVPR上也发表了一篇文章,专门介绍如何使用神经网络来无损压缩JPEG图像。在这里对研究内容做一个简单介绍,首先我们将JPEG图像的三个分量(YUV或YCbCr)整合成一个引变量Z,整合后的Z涵盖了YUV之间的关联,在压缩YUV三个分量前使用Z来作为先验。Y叫作亮度分量,由于它包含的信息最多,所以我们为这个分量专门设计一个模型叫作MLCC,它的结构如下。
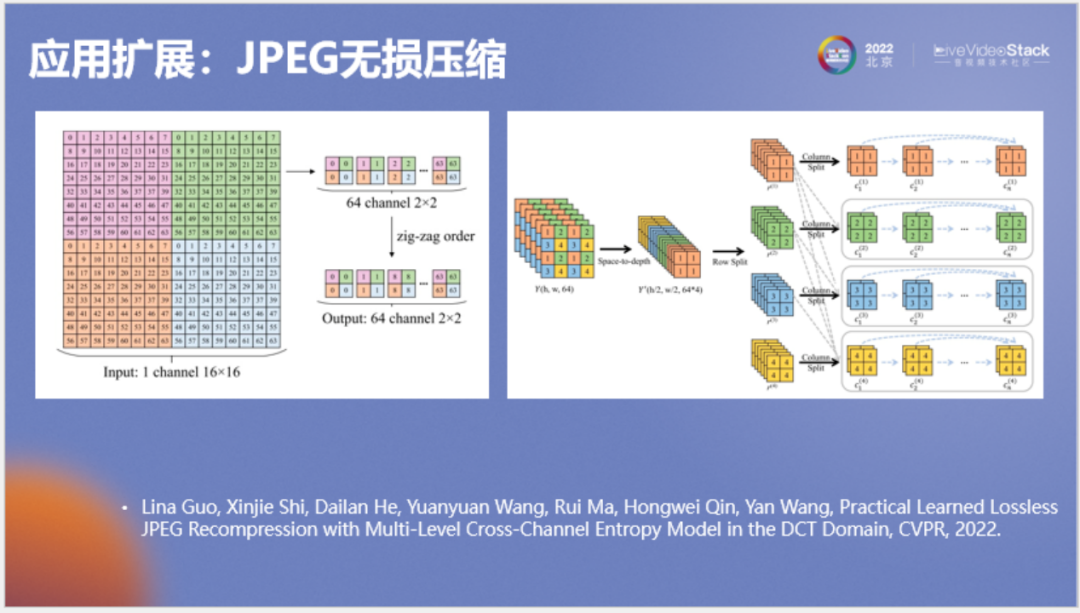
MLCC是一种比较复杂的并行自回归模型。左图中为JPEG的dct系数,我们对它进行重新排列,将相同频率排到神经网络的相同通道上得到右图,并将右图中三维长方体的行列进行展开,按照类似自回归的方式进行条件建模。它看起来很复杂,但实际执行的速度还是很快的。
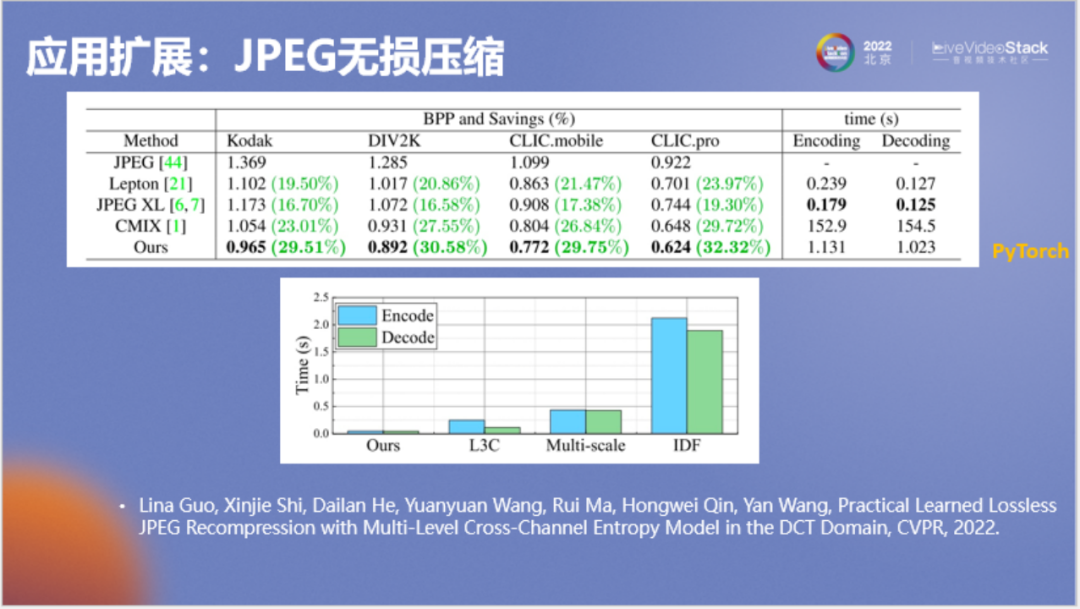
以上为测速结果,Dropbox在大规模使用的Lepton,其无损压缩率是20%左右,编码解码时间分别是0.239和0127。JPEG XL稍差,但编码稍微快一些。作为传统算法中号称最强的无损压缩器CMIX,它的压缩率能达到23%或27%,但编码和解码时间都很长,要150秒。该软件是压缩从业者为了探索无损压缩极限构造出的一套十分复杂的模型,它的算力消耗和内存消耗都非常非常大。
我们的神经网络方法压缩率可以达到29%或30%以上,优于CMIX,使用PyTorch在GPU上的编解码时间大约为1秒,比Lepton要慢约十倍。
不过我们要知道Lepton不是一个参考软件,而是一个工业软件,我们的算法作为学术上的参考软件,两者gap并不大。
我们也将神经网络方法和之前做无损压缩的一些网络结构进行了对比,可以看到本方法的编解码时间实际是比较短的。
小结

下面进行一个小结。经过刚才提到的一些优化,AI编解码方法整体上在一些场景下是可以使用的,但在我刚才提到的六个维度上还有一些持续的挑战。

本次分享的内容来自这些已经发表或公开的论文和技术报告,感谢商汤科技和清华大学的合作者。
审核编辑:刘清
-
编解码一体机相对于传统的编解码设备有哪些优势?2024-01-31 2588
-
为什么需要视频编码,它的原理又是什么?#视频编解码面包车 2022-07-29
-
初识红外编解码2021-08-16 1597
-
Hi3521DV200 H.265编解码2021-07-22 2496
-
BCH编解码器在NAND Flash主控中的研究与优化2021-03-17 1074
-
FFMPEG视频编解码流程 H.264硬件编解码实现2018-04-03 19942
-
分析了各主流编解码器的优势与不足,并对编解码器的选择给出建议2018-02-06 16205
-
通信接口——编解码2017-09-04 1088
-
RS编解码的FPGA实现-说明2016-05-04 864
-
音频编解码器技术2012-02-03 5963
-
基于CPLD的HDB3码编解码电路的设计2010-02-24 911
-
基于CPLD的卷积码编解码器的设计2009-08-10 3440
-
什么是音频编解码器?2009-05-03 4624
-
频域相位编解码OCDMA系统2009-02-28 1414
全部0条评论

快来发表一下你的评论吧 !
