

用于神经场SLAM的矢量化对象建图
描述
vMAP 是一种基于神经场的对象级密集 SLAM 系统,可根据 RGB-D 输入流实时自动构建对象级场景模型。每个对象都由一个单独的 MLP 神经场模型表示,无需 3D 先验即可实现高效、无懈可击的对象建模。该系统可以在单个场景中优化多达 50 个单独的对象,与之前的神经场 SLAM 系统相比,可以显着提高场景级和对象级的重建质量。
摘要
我们提出了 vMAP,一种使用神经场表示的对象级密集 SLAM 系统。每个对象都由一个小型 MLP 表示,无需 3D 先验即可实现高效、无懈可击的对象建模。
当 RGB-D 相机在没有先验信息的情况下浏览场景时,vMAP 会即时检测对象实例,并将它们动态添加到其地图中。具体来说,由于矢量化训练的强大功能,vMAP 可以在单个场景中优化多达 50 个单独的对象,具有 5Hz 地图更新的极其高效的训练速度。与之前的神经场 SLAM 系统相比,我们通过实验证明了场景级和对象级重建质量的显着提高。
每个对象都由一个单独的 MLP 神经场模型表示,所有对象都通过矢量化训练并行优化。我们不使用 3D 形状先验,但 MLP 表示鼓励对象重建是无懈可击的和完整的,即使对象在输入图像中被部分观察到或被严重遮挡。例如,在 Replica 的这个例子中,请参见相互遮挡的扶手椅、沙发和垫子的单独重建。
1.介绍
对于机器人和其他交互式视觉应用程序,对象级模型在语义上可以说是最佳的,场景实体以分离的、可组合的方式表示,而且还能有效地将资源集中在环境中的重要内容上
构建对象级建图系统的关键问题是,为了对场景中的对象进行分割、分类和重建,需要了解什么级别的先验信息。如果没有可用的 3D 物体先验,那么通常只能重建物体的直接观察部分,从而导致孔洞和缺失部分 [4, 46]。先验对象信息,如 CAD 模型或类别级形状空间模型,可以从局部视图估计完整的对象形状,但仅限于这些模型可用的场景中的对象子集
在本文中,我们提出了一种新方法,适用于没有可用的 3D 先验但仍然经常在逼真的实时场景扫描中启用水密对象重建的情况。我们的系统 vMAP 建立在神经场作为实时场景表示 [31] 显示的吸引人的属性的基础上,具有高效和完整的形状表示,但现在重建每个对象的单独微型 MLP 模型。我们工作的关键技术贡献是表明大量独立的 MLP 对象模型可以在实时操作期间通过矢量化训练在单个 GPU 上同时有效地优化
我们表明,与在整个场景的单个神经场模型中使用相似数量的权重相比,我们可以通过单独建模对象来实现更加准确和完整的场景重建。我们的实时系统在计算和内存方面都非常高效,并且我们展示了具有多达 50 个对象的场景可以在多个独立对象网络中以每个对象 40KB 的学习参数进行建图
我们还展示了我们的分离对象表示的灵活性,可以使用新的对象配置重新组合场景。对模拟和真实世界的数据集进行了广泛的实验,展示了最先进的场景级和对象级重建性能
2.相关工作
这项工作是在建立实时场景表示的一系列努力之后进行的,这些实时场景表示被分解为明确的刚性对象,并有望实现灵活高效的场景表示,甚至可以表示不断变化的场景。不同的系统采用不同类型的表示和先验知识水平,从 CAD 模型 [28],通过类别级形状模型 [10,11,32,36] 到没有先验形状知识,尽管在这种情况下只有可见部分物体可以被重建 [15, 27, 38]
神经场 SLAM
神经场最近被广泛用作整个场景的高效、准确和灵活的表示 [16、17、19、22]。为了将这些表示应用于实时 SLAM 系统,iMAP [31] 首次展示了一个简单的 MLP 网络,借助 RGB-D 传感器的深度测量进行增量训练,可以实时表示房间尺度的 3D 场景。时间。iMAP 的一些最有趣的特性是它倾向于产生无懈可击的重建,甚至经常似是而非地完成物体未被观察到的背面。当添加语义输出通道时,神经场的这些相干特性尤其显露出来,如在 SemanticNeRF [43] 和 iLabel [44] 中,并且被发现继承了相干性。为了使隐式表示更具可扩展性和效率,一组隐式 SLAM 系统 [25、35、40、45、48] 将神经场与传统的体积表示融合在一起。
带有神经场的对象表示
然而,从这些神经场方法中获取单个对象表示很困难,因为网络参数与特定场景区域之间的对应关系很复杂且难以确定。为了解决这个问题,DeRF [23] 在空间上分解了一个场景,并将较小的网络专用于每个分解的部分。同样,Kilo-NeRF [24] 将场景分成数千个体积部分,每个部分由一个微型 MLP 表示,并与自定义 CUDA 内核并行训练它们以加速 NeRF。与 KiloNeRF 不同,vMAP 将场景分解为具有语义意义的对象。
为了表示多个对象,ObjectNeRF [39] 和 ObjSDF [37] 将预先计算的实例掩码作为可学习对象激活代码上的附加输入和条件对象表示。但是这些方法仍然是离线训练的,并且将对象表示与主场景网络纠缠在一起,因此它们需要在训练过程中使用所有对象代码优化网络权重,并推断整个网络以获得所需对象的形状。这与单独建模对象的 vMAP 形成对比,并且能够停止和恢复对任何对象的训练而没有任何对象间干扰
最近与我们的工作最相似的工作是使用神经域 MLP 的吸引人的特性来表示单个对象。[5] 中的分析明确评估了使用过拟合神经隐式网络作为图形的 3D 形状表示,考虑到它们应该被认真对待。[1] 中的工作进一步推进了这一分析,显示了对象表示如何受到不同观察条件的影响,尽管使用混合 Instant NGP 而不是单一的 MLP 表示,因此尚不清楚是否会丢失某些对象的一致性属性。最后,CodeNeRF 系统 [9] 训练了一个以可学习对象代码为条件的 NeRF,再次证明了神经场的吸引人的属性来表示单个对象
我们在论文中以这项工作为基础,但首次表明构成整个场景的许多单独的神经场模型可以在实时系统中同时训练,从而准确有效地表示多对象场景
3. vMAP:具有矢量化训练的高效对象建图系统
3.1.系统总览
我们首先介绍了我们通过高效矢量化训练进行对象级建图的详细设计(第 3.2 节),然后解释了我们改进的像素采样和表面渲染训练策略(第 3.3 节)。最后,我们展示了如何使用这些学习到的对象模型来重构和渲染新场景(第 3.4 节)。我们的训练和渲染管道的概述如图 2 所示
3.2.矢量化对象级建图
对象初始化和关联
首先,每个帧都与密集标记的对象掩码相关联。这些对象掩码要么直接在数据集中提供,要么使用现成的 2D 实例分割网络进行预测。由于那些预测的对象掩码在不同帧之间没有时间一致性,我们基于两个标准在前一帧和当前实时帧之间执行对象关联:i)语义一致性:当前帧中的对象被预测为与前一帧相同的语义类, ii) 空间一致性:当前帧中的对象在空间上与先前帧中的对象接近,这是通过它们的 3D 对象边界的平均 IoU 来衡量的。当满足这两个标准时,我们假设它们是相同的对象实例并用相同的对象模型表示它们。否则,它们是不同的对象实例,我们初始化一个新的对象模型并将其附加到模型堆栈
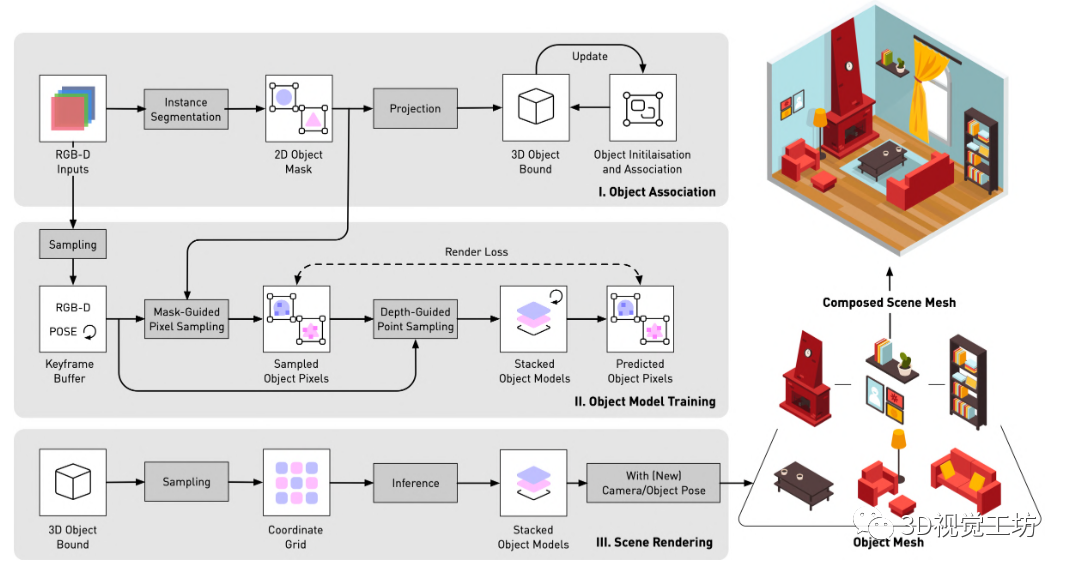
图 2. vMAP 训练和渲染流水线概览
对于帧中的每个对象,我们估计其 3D 对象受其 3D 点云的约束,并通过其深度图和相机姿势进行参数化。相机跟踪由现成的跟踪系统在外部提供,我们发现与联合优化位姿和几何形状相比,它更加准确和稳健。如果我们在新帧中检测到相同的对象实例,我们将其 3D 点云从先前帧合并到当前帧并重新估计其 3D 对象边界。因此,这些对象边界会随着更多的观察而动态更新和细化。
对象监督
我们仅对 2D 对象边界框内的像素应用对象级监督,以实现最大的训练效率。对于对象掩码内的那些像素,我们鼓励对象辐射场被占用,并用深度和颜色损失来监督它们。否则我们鼓励物体辐射场为空
每个对象实例从其自己独立的关键帧缓冲区中采样训练像素。因此,我们可以灵活地停止或恢复任何对象的训练,而对象之间没有训练干扰。
Vectorised Training 用多个小型网络表示神经场可以导致有效的训练,如先前的工作 [24] 所示。在 vMAP 中,所有对象模型都具有相同的设计,除了我们用稍大的网络表示的背景对象。因此,我们能够利用 PyTorch [8] 中高度优化的矢量化操作,将这些小对象模型堆叠在一起进行矢量化训练。由于多个对象模型是同时批处理和训练的,而不是按顺序进行的,我们优化了可用 GPU 资源的使用。我们表明,矢量化训练是系统的基本设计元素,可以显着提高训练速度,这将在第 4.3 节中进一步讨论
3.3.神经隐式建图
深度引导采样
仅在 RGB 数据上训练的神经场不能保证建模准确的对象几何形状,因为它们是针对外观而不是几何形状进行优化的。为了获得几何上更精确的对象模型,我们受益于 RGB-D 传感器提供的深度图,为学习 3D 体积的密度场提供了强大的先验知识。具体来说,我们沿着每条射线对 Ns 和 Nc 点进行采样,其中 Ns 点的采样具有以表面 ts 为中心的正态分布(来自深度图),具有较小的 dσ 方差,Nc 点在相机 tn(近边界)和表面 ts,采用分层采样方法。当深度测量无效时,表面 ts 将替换为远界 tf 。在数学上,我们有:
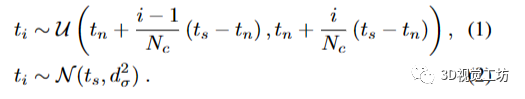
我们选择dσ = 3厘米,这在我们的实施中效果很好。我们观察到,在靠近表面训练更多的点有助于引导物体模型迅速专注于准确表示物体几何。
由于我们更关注3D表面重建而不是2D渲染,因此在网络输入中省略了视角方向,并且使用二进制指示器(没有透明物体)来建模物体的可见性。与UniSURF [21]具有类似的动机,我们将3D点xi的占用概率参数化为oθ (xi) → [0, 1],其中oθ是一个连续的占用场。因此,沿射线r的点xi的终止概率变为Ti = o (xi) Qj
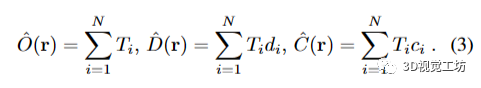
训练目标 对于每个对象k,我们仅在该对象的2D边界框内采样训练像素,用Rk表示,并且仅针对其2D对象掩码内的像素优化深度和颜色,用Mk表示。注意,Mk ⊂ Rk始终成立。对象k的深度、颜色和占用损失定义如下:
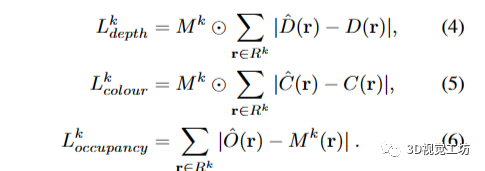
然后,整体的训练目标对所有K个对象进行损失累积:
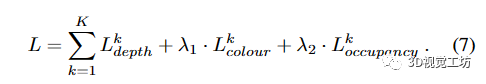
我们选择损失权重λ1 = 5和λ2 = 10,我们在实验中发现这些权重效果很好。
3.4. 组合式场景渲染
由于vMAP在纯粹的解耦表示空间中表示对象,我们可以通过在其估计的3D对象边界内查询来获得每个3D对象,并轻松地进行操作。对于2D新视图合成,我们使用Ray-Box Intersection算法[14]来计算每个对象的近距离和远距离边界,然后在每条射线上对渲染深度进行排序,实现对遮挡的场景级渲染。这种解耦表示还打开了其他类型的细粒度对象级操作,例如通过在解耦的预训练特征场上进行条件变形物体的形状或纹理[20, 42],这被视为一个有趣的未来方向。
4.实验
我们对各种不同的数据集对vMAP进行了全面评估,其中包括模拟和真实世界的序列,有的有地面真实物体的掩码和姿态,有的没有。对于所有数据集,我们在2D和3D场景级别和对象级别的渲染上定性地将我们的系统与之前最先进的SLAM框架进行了比较。我们还在具有地面真实网格的数据集中进行了定量比较。更多结果请参阅我们附带的补充材料。
4.1. 实验设置
数据集 我们在Replica [29]、ScanNet [3]和TUM RGB-D [6]上进行了评估。每个数据集包含具有不同质量的对象掩码、深度和姿态测量的序列。此外,我们还展示了vMAP在由Azure Kinect RGB-D相机记录的复杂真实世界中的性能。这些数据集的概述如表1所示。
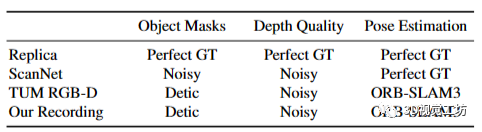
表1. 我们评估的数据集概述
具有完美地面真实信息的数据集代表了我们系统的上限性能。我们预期vMAP在真实世界环境中的性能可以通过与更好的实例分割和姿态估计框架相结合而进一步提高。
实施细节 我们在一台桌面PC上进行所有实验,配备3.60 GHz的i7-11700K CPU和一张Nvidia RTX 3090 GPU。我们选择实例分割检测器为Detic [47],在开放词汇LVIS数据集 [7]上进行预训练,该数据集包含1000多个对象类别。我们选择姿态估计框架为ORB-SLAM3 [2],因为它具有快速和准确的跟踪性能。我们使用来自ORB-SLAM3的最新估计不断更新关键帧的姿态。
我们对所有数据集应用了相同的超参数集。我们的对象和背景模型都使用了4层MLP,每层的隐藏大小分别为32(对象)和128(背景)。对于对象/背景,我们选择每25/50帧一个关键帧,每个训练步骤使用120/1200条射线,每条射线有10个点。场景中的对象数量通常在20到70个之间,其中对象数量最多的Replica和ScanNet场景中,平均每个场景有50个对象。
指标
按照之前的研究[31, 48]的惯例,我们采用准确度(Accuracy)、完整度(Completion)和完整度比率(Completion Ratio)作为3D场景级别重建的度量指标。此外,我们注意到这样的场景级别指标在重建墙壁和地板等大型物体方面存在严重偏差。因此,我们还提供了对象级别的这些指标,通过对每个场景中所有对象的指标进行平均计算。
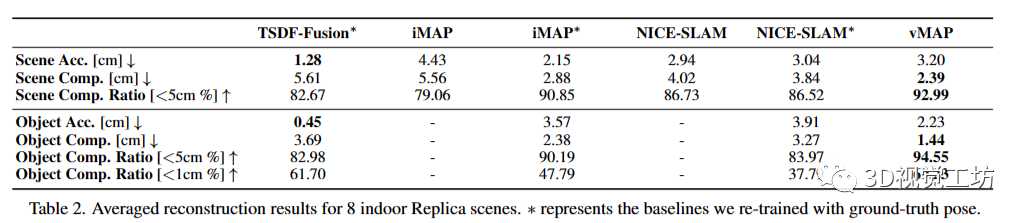

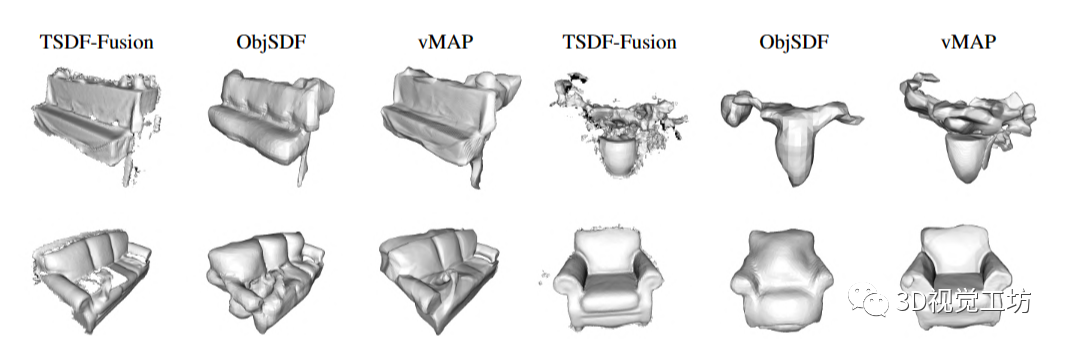
图4. 使用vMAP与TSDF-Fusion和ObjSDF进行对象重建的可视化比较。请注意,来自ObjSDF的所有对象重建都需要更长的离线训练时间。ObjSDF提供的所有对象网格由原始作者提供。

图5. 在选择的ScanNet序列中,展示了NICE-SLAM∗(左)和vMAP(右)的场景重建可视化结果。对于感兴趣的区域进行了放大显示。NICE-SLAM∗使用了地面真实姿态进行重新训练。
4.2. 场景和物体重建评估
在Replica数据集上的结果
我们在8个Replica场景上进行了实验,使用[31]提供的渲染轨迹,每个场景包含2000个RGB-D帧。表2显示了这些Replica室内序列中的平均定量重建结果。对于场景级别的重建,我们与TSDF-Fusion [46]、iMAP [31]和NICE-SLAM [48]进行了比较。为了隔离重建效果,我们还提供了这些基线方法在使用地面真实姿态重新训练后的结果(标记为∗),以便进行公平比较。具体而言,iMAP∗被实现为vMAP的一种特殊情况,将整个场景视为一个物体实例。对于物体级别的重建,我们比较了在使用地面真实姿态进行训练的基线方法。
vMAP通过物体级别的表示具有显著的优势,能够重建微小物体和具有细节的物体。值得注意的是,对于物体级别的完整性,vMAP相比于iMAP和NICE-SLAM实现了50-70%的改进。图3展示了4个选定的Replica序列的场景重建结果,其中用彩色框标出了感兴趣的区域。关于2D新视角渲染的定量结果将在补充材料中提供。
在ScanNet上的结果
为了在更具挑战性的环境中进行评估,我们在ScanNet [3]上进行了实验,该数据集由真实场景组成,具有更多噪声的地面真实深度图和物体掩码。我们选择了ObjSDF [37]选择的一段ScanNet序列,并与TSDF-Fusion和ObjSDF进行了物体级别的重建比较,与使用地面真实姿态重新训练的NICE-SLAM进行了场景级别的重建比较。与ObjSDF不同,vMAP和TSDF-Fusion都是在具有深度信息的在线环境中运行,而不是像ObjSDF那样从预先选择的没有深度信息的图像进行更长时间的离线训练。如图4所示,我们可以看到vMAP生成的物体几何结构比TSDF-Fusion更连贯;而比ObjSDF具有更细致的细节,尽管训练时间要短得多。并且一致地,如图5所示,与NICE-SLAM相比,我们可以看到vMAP生成的物体边界和纹理更加清晰。
在TUM RGB-D上的结果
我们在真实世界中捕获的TUM RGB-D序列上进行了评估,使用了一个现成的预训练实例分割网络[47]预测的物体掩码和由ORB-SLAM3[2]估计的位姿。由于我们的物体检测器没有时空一致性,我们发现同一个物体偶尔会被检测为两个不同的实例,这导致了一些重构伪影。例如,图6中显示的物体“globe”在某些帧中也被检测为“balloon”,导致最终物体重构中的“分割”伪影。总体而言,与TSDF-Fusion相比,vMAP仍然可以对场景中大多数物体进行更连贯的重构,并具有逼真的孔洞填充能力。然而,我们承认,由于缺乏普遍的3D先验知识,我们的系统无法完成完整的视野之外区域(例如椅子的背部)的重构。
虽然我们的工作更注重地图绘制性能而不是位姿估计,但我们也按照[31,48]报告了Tab. 3中的ATE RMSE,通过联合优化相机位姿和地图。我们可以观察到,由于重构和跟踪质量通常高度相互依赖,vMAP实现了卓越的性能。然而,与ORB-SLAM相比存在明显的性能差距。因此,我们直接选择ORB-SLAM作为我们的外部跟踪系统,这导致了更快的训练速度、更清晰的实现和更高的跟踪质量。
对于实时运行的Azure Kinect RGB-D相机,在桌面场景上展示了vMAP的重构结果。如图7所示,vMAP能够生成来自不同类别的一系列逼真的、无缺陷的物体网格。
4.3. 性能分析
在本节中,我们比较了针对vMAP系统的不同训练策略和架构设计选择。为了简单起见,所有实验都在Replica Room-0序列上进行,使用我们的默认训练超参数。
内存和运行时间
我们在表4和图9中将vMAP与iMAP和NICE-SLAM进行了内存使用和运行时间的比较,所有方法都是使用了地面真实姿态进行训练,并使用各自方法中列出的默认训练超参数,以进行公平比较。具体而言,我们报告了整个序列的运行时间和每帧训练的建图时间,使用完全相同的硬件条件。我们可以看到,vMAP具有高度的内存效率,参数数量少于1M。我们想强调的是,vMAP在重构质量上取得了更好的表现,并且运行速度明显快于iMAP和NICE-SLAM,分别提高了1.5倍和4倍的训练速度(约5Hz)。
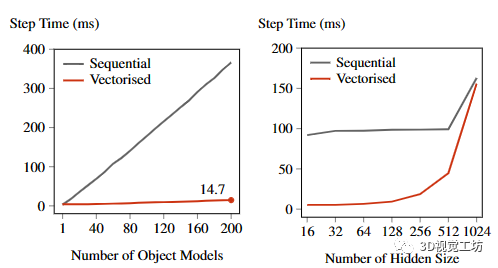
图 8. 与使用 for 循环的标准顺序操作相比,矢量化操作能够实现极快的训练速度。
向量化与顺序训练
我们通过使用向量化和顺序操作(for循环)来对训练速度进行了分析,针对不同数量的对象和不同物体模型的大小。在图8中,我们可以看到,向量化训练大大提高了优化速度,尤其是当我们有大量物体时。而且,使用向量化训练时,即使在训练多达200个物体时,每个优化步骤也不超过15毫秒。此外,向量化训练在各种模型大小范围内也是稳定的,这表明如果需要,我们可以训练更大尺寸的物体模型,而额外的训练时间非常小。如预期的那样,当我们达到硬件的内存限制时,向量化训练和for循环将最终具有相似的训练速度。
为了并行训练多个模型,我们最初尝试的方法是为每个对象生成一个进程。然而,由于每个进程的CUDA内存开销,我们只能生成非常有限数量的进程,这严重限制了对象的数量。
对象模型容量
由于向量化训练在对象模型设计方面对训练速度几乎没有影响,我们还研究了不同对象模型大小对对象级重建质量的影响。我们通过改变每个MLP层的隐藏层大小来尝试不同的对象模型大小。在图9中,我们可以看到从隐藏层大小为16开始,对象级性能开始饱和,进一步增加模型大小几乎没有改善或没有改善。这表明对象级表示具有高度可压缩性,并且可以通过很少的参数高效准确地参数化。
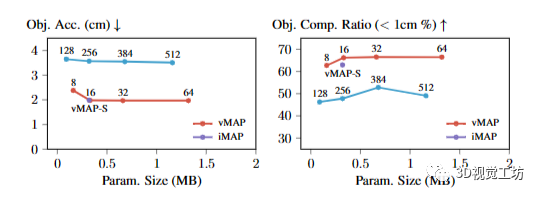
图9. 对象级重建与模型参数(由网络隐藏大小表示)的比较。vMAP比iMAP更紧凑,性能从隐藏大小为16开始饱和。
堆叠的MLP vs. 共享的MLP
除了通过单个独立的MLP表示每个对象之外,我们还探索了共享MLP的设计,将多对象建图视为多任务学习问题[26, 33]。在这种设计中,每个对象还与一个可学习的潜在编码相关联,这个潜在编码被视为网络的条件输入,并与网络权重一起进行联合优化。尽管我们尝试了多个多任务学习体系结构[12, 18],但早期实验(在图9中标记为vMAP-S)显示,这种共享的MLP设计在重建质量上略有下降,并且与堆叠的MLP相比,没有明显的训练速度改进,尤其是在采用向量化训练的情况下,我们发现共享的MLP设计可能导致不良的训练性质:i)由于网络权重和所有对象的潜在编码在共享的表示空间中交织在一起,共享的MLP需要与所有对象的潜在编码一起进行优化。ii)共享的MLP容量在训练过程中是固定的,因此表示空间可能不足以处理日益增加的对象数量。这凸显了解耦的对象表示空间的优势,这是vMAP系统的一个关键设计元素。
5.结论
我们提出了vMAP,一个实时的基于对象级别的地图生成系统,采用简单而紧凑的神经隐式表示。通过将3D场景分解为一批小型独立MLP表示的有意义实例,该系统以高效而灵活的方式建模3D场景,实现场景重组、独立跟踪和感兴趣对象的持续更新。除了更准确、更紧凑的以对象为中心的3D重建,我们的系统还能够预测每个对象的合理闭合表面,即使在部分遮挡的情况下也能如此。
局限性和未来工作
我们当前的系统依赖于现成的实例掩码检测器,这些实例掩码不一定具有时空一致性。虽然通过数据关联和多视图监督部分减轻了歧义,但合理的全局约束将更好地解决这个问题。由于对象是独立建模的,动态对象可以持续跟踪和重建,以支持下游任务,例如机器人操控。为了将我们的系统扩展为单目稠密地图生成系统,可以进一步整合深度估计网络或更高效的神经渲染方法。
审核编辑:刘清
-
让机器人完美建图的SLAM 3.0到底是何方神圣?2019-01-21 6011
-
什么是CAD矢量化?2020-03-06 2474
-
使用SVE对HACCmk进行矢量化的案例研究2022-11-08 3822
-
RealView编译工具NEON矢量化编译器指南2023-08-12 572
-
一种优化的鞋样图像矢量化方法2009-08-13 608
-
MAPGIS矢量化技巧步骤详解2010-10-21 1415
-
阿郎“零接触矢量化”技术实现宽带服务提速2012-10-17 1387
-
英特尔Advisor的矢量化工作流程2018-11-01 5001
-
第2部分:高级代码矢量化和优化2020-05-31 3335
-
使用线程和矢量化将串行代码转换为并行2018-11-07 3814
-
矢量化的优点和数据大小的影响2018-11-15 7279
-
矢量化数据并行性的程序方面的作用2018-11-06 3094
-
矢量化或性能模具:调整最新的AVX SIMD指令2018-11-05 5112
-
一种全新的视角去理解和处理地图矢量化的任务2023-06-27 2097
-
基于矢量化场景表征的端到端自动驾驶算法框架2023-08-31 2396
全部0条评论

快来发表一下你的评论吧 !
