

基于纯视觉的感知方法
描述
背景 近年来,基于纯视觉的感知方法由于其较高的信噪比和较低的成本,在自动驾驶领域占有重要地位。其中,鸟瞰图(BEV)感知已成为主流的方法。在以视觉为中心的自动驾驶任务中,BEV表示学习是指将周围多个摄像头的连续帧作为输入,然后将像平面视角转换为鸟瞰图视角,在得到的鸟瞰图特征上执行诸如三维目标检测、地图视图语义分割和运动预测等感知任务。 BEV感知性能的提高取决于如何快速且精准地获取道路和物体特征表示。图1中展示了现有的两类基于不同交互机制的BEV感知管道:(a)后交互和(b)中间交互。后交互管道[1]在每个相机视角上独立地进行感知,然后将感知结果在时间和空间上融合到一个统一的BEV特征空间中。中间交互管道[2,3,4]是最近使用得最广泛的方案,它将所有的相机视角图像耦合输入到网络中,通过网络将它们转换到BEV空间,然后直接输出结果。中间交互管道中的特征提取、空间转换和BEV空间的学习都有一个明确的顺序。
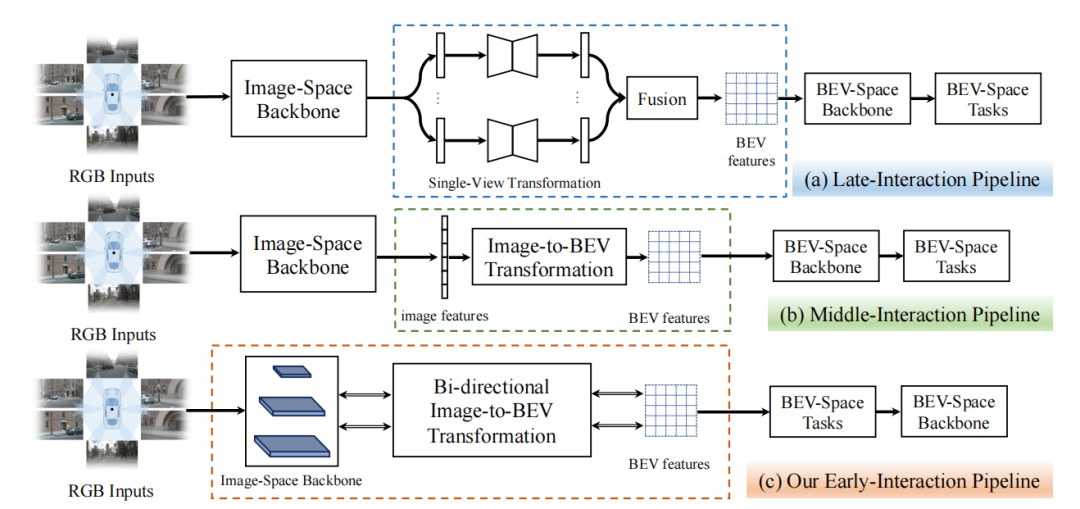
图1:后交互、中间交互和我们提出的前置交互框架示意图 基于视觉的BEV感知的核心挑战是从仿射视角(Perspective View, PV)向鸟瞰图视角(BEV)的转换。然而,利用现有的两种交互策略将PV转换到BEV仍然存在许多问题:(1) 图像空间backbone只依次提取不同分辨率的图像特征,而没有融合任何跨分辨率的信息;(2) 现有的交互策略中核心模块的计算量主要由图像空间backbone占据,但它不包含任何BEV空间信息,导致大量的计算并没有执行PV到BEV转换这一关键任务;(3) 后交互策略和中间交互策略的前向处理中的信息流是单向的,信息从图像空间流到BEV空间,而BEV空间中的信息并没有有效地影响图像空间中的特征。为了解决这些问题,我们提出了一种新的基于Transformer的双向前置交互框架,以有效地将多尺度图像特征聚合成更好的BEV特征表示,并执行BEV语义分割任务。 与现有的两种策略相比,我们提出的前置交互方法具有明显的优势。首先,我们提出的双向前置交互方法可以融合全局上下文信息和局部细节,从而能够向BEV空间传递更丰富的语义信息。其次,我们提出PV到BEV的转换不仅可以是图像特征提取后,而且可以在提取过程中进行逐步转换,于是,通过我们提出的双向交叉注意力机制,信息流可以隐式地进行双向交互,从而对齐PV和BEV中的特征。此外,我们的方法可以将跨空间对齐学习扩散到整个框架中,即图像网络学习不仅可以学习到良好的特征表示,而且可以起到跨空间对齐的作用。 方法
整体框架
BAEFormer的整体框架如图2所示,总共包含两个部分:(1)双向前置交互编码器,用于提取图像特征并将其从PV转换为BEV;(2)将低分辨率BEV特征上采样到高分辨率BEV特征的解码器,用于执行下游任务。
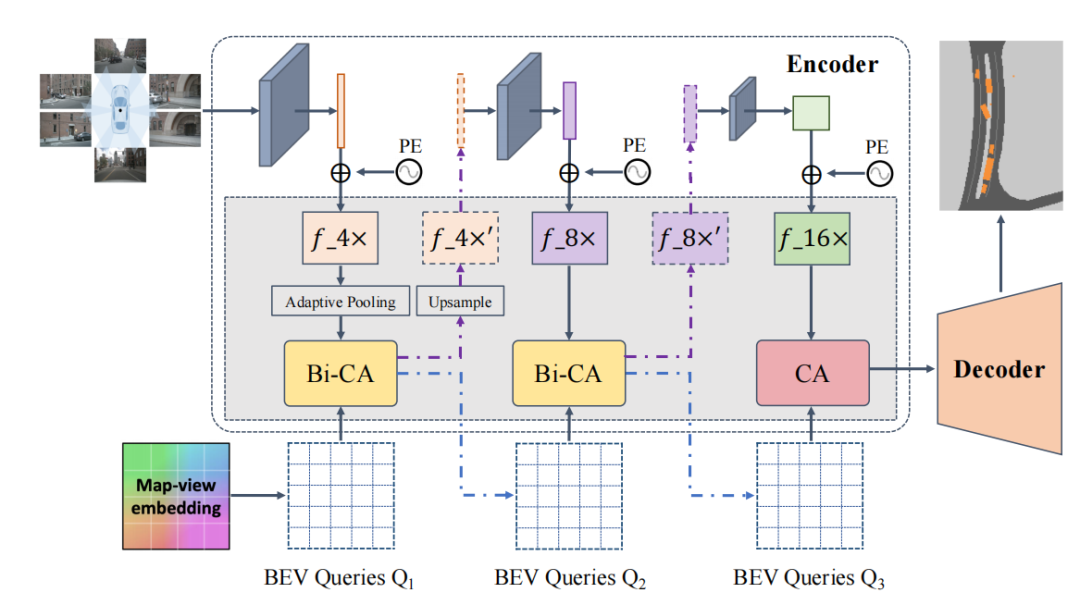
图2:BAEFormer整体框架图
前置交互
对于前置交互模块,我们使用EfficientNet[5]的预训练模型来提取环视图像的特征,特征提取器包含三层,分别提取图像的4x,8x,16x分辨率的特征。4x分辨率的特征首先被提取出来,通过一个降采样模块之后和BEV特征进行交互得到更新之后的4x分辨率特征,将更新之后的4x特征上采样,并作为特征提取器的下一层的输入来提取8x分辨率特征。以此类推,我们得到更新之后的8x特征并作为特征提取器最后一层的输入,由此得到16x图像特征。我们的多尺度前置交互方法可以充分利用分层预训练的模型来整合多尺度图像特征。同时,BEV的空间信息可以流入主干网络,使前置交互主干网络承担了部分异质空间对齐的功能。
双向交叉注意力
如图3中所示,我们提出的双向交叉注意力模型包含两个分支,一个用于多视图图像特征的精细化,另一个用于BEV特征的精细化。 首先,N个环视图像特征首先被编码为查询特征,键特征和值特征,其中c表示特征维度,h和w分别表示特征的高和宽。相似的,BEV特征编码也被转换为查询特征,键特征和值特征。于是图像特征和BEV特征的交叉注意力可以表示为: 整个Transformer模块就可以使用下式计算: 其中, 和 表示第l层的输入, 和 表示第l层的输出。LN(∙)表示层归一化操作,MLP(∙)表示有2个全连接层和一个非线性层的多层感知机模块,MHBiCA(∙)表示拥有多头交叉注意力机制的BiCA(∙)模块。
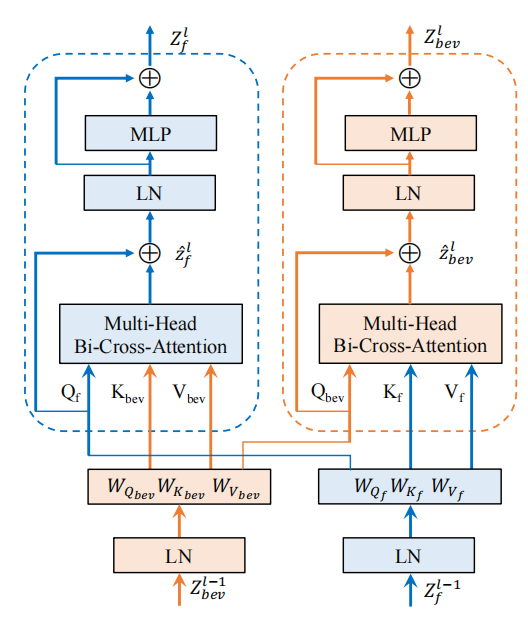
图3:双向交叉注意力框架图 实验结果 表1展示了BAEFormer方法和之前的方法在两种设置下的性能、参数和推理速度的对比结果。可以看出,BAEFormer在使用相同输入分辨率(224x480)的设置下,在精度上超过了现有的实时方法。同时,虽然先前的BEVFormer[2]实现了高性能,但它非常耗时,模型参数高达68.1M。我们的BAEFormer在大输入图像分辨率(504x1056)下的运行速度比BEVFormer快12倍,而参数量大约是它的1/12。
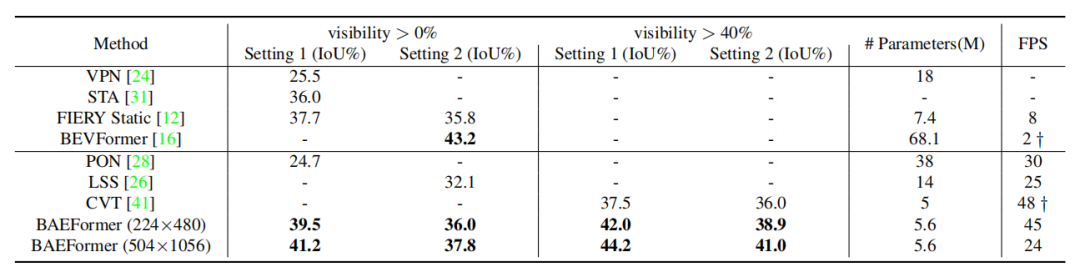
表1:nuScenes数据集上车辆类别的语义分割结果
消融实验
表2展示了我们在nuScenes数据集上对车辆类别进行的不同交互方式的消融实验。实验结果表明,我们的BAEFormer方法可以将双向交叉注意力机制和前置交互方式充分地结合以得到更好的BEV特征表示。
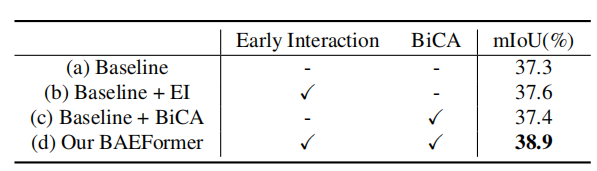
表2:不同交互方式的消融实验 表3展示了具有不同输入分辨率和图像特征尺度的模型的mIoU性能和内存使用情况。结果说明,使用多尺度特征可以带来更好的性能;增大输入图像分辨率可以提高性能,但会带来显存的剧增;我们发现,如(j)-(n)所示,在交互过程中,输入图像的分辨率对最终的精度没有太大的影响;因此我们可以在提高输入图像分辨率来提升性能的同时,通过对交互时的图像特征进行降采样来保证计算量是可控的。
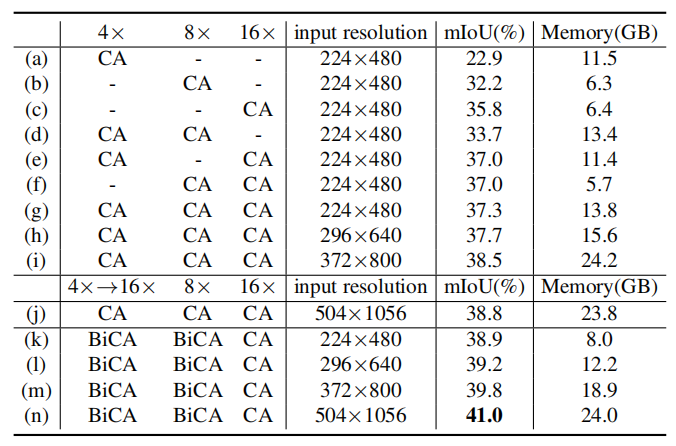
表3: 不同输入分辨率和不同图像特征尺度的组合
可视化结果
图4展示了BEV下的可视化结果,可以看出BAEFormer对比baseline模型,不仅对于近处物体漏检(红色圈)的数目有效减少,且对于远处物体(绿色圈)也能进行有效的感知,进一步说明了我们方法的感知能力具有一定的优势。
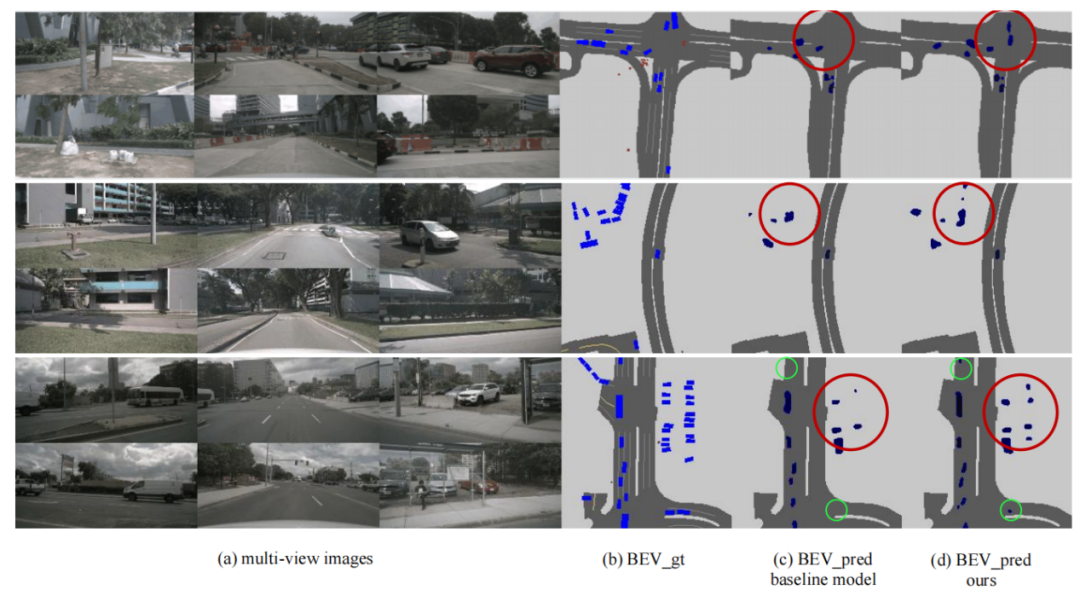
图4:不同模型的可视化结果对比 结论 在本文中,我们提出了一种称为BAEFormer的BEV语义分割新框架,采用双向交叉注意力机制,通过对图像特征空间和 BEV 特征空间中的信息流施加双向约束来建立改进的跨空间对齐,同时利用前置交互方法来合并跨尺度信息,并实现更精细的语义表示。实验结果表明,BAEFormer在保持实时推理速度的同时能够提高BEV语义分割的性能。 点击“阅读原文”,下载论文获取更多信息。
责任编辑:彭菁
-
有谁是做认知无线电频谱感知方向的吗2014-09-11 2661
-
人类视觉感知方式对VR的挑战2019-07-29 3039
-
智能感知方案怎么帮助实现安全的自动驾驶?2019-07-31 3306
-
认知无线电中基于循环平稳特征的频谱感知方法2012-03-16 767
-
智能机器人多传感器融合感知方法2016-09-20 1340
-
一种基于智能终端的环境与接近度感知方法2017-11-16 958
-
基于信道历史状态信息的频谱感知方法2018-01-15 855
-
新的工业应用智能感知方案2020-07-03 1284
-
基于双向前置交互Transformer的BEV语义分割方法2023-06-15 1205
-
4分钟了解吸顶灯具智能感知方案测试方法2021-12-01 2507
-
人工智能技术解密——机器视觉技术及应用2023-07-07 1327
-
自动驾驶中激光雷达和视觉感知的区别2023-08-08 2566
-
激光雷达与纯视觉方案,哪个才是自动驾驶最优选?2024-09-29 2325
-
为什么光照对纯视觉自动驾驶影响较大?2026-03-09 1212
-
纯视觉自动驾驶如何在夜晚感知场景?2026-04-22 339
全部0条评论

快来发表一下你的评论吧 !
