

多波束相控阵接收机混合波束成型功耗优势的定量分析
描述
本文对模拟、数字和混合波束成型架构的能效比进行了比较,并针对接收相控阵开发了这三种架构的功耗的详细方程模型。该模型清楚说明了各种器件对总功耗的贡献,以及功耗如何随阵列的各种参数而变化。对不同阵列架构的功耗/波束带宽积的比较表明,对于具有大量元件的毫米波相控阵,混合方法具有优势。
简介
本文比较了不同波束成型方法,重点关注这些方法创建多个同时波束的能力和能效比。相控阵在现代雷达和通信系统中发挥着越来越重要的作用,这使人们对提高系统性能和效率重新产生了兴趣。数十年来,数字波束成型(DBF)及其与传统模拟方法相比的优势已广为人知,但与数字信号处理相关的各种挑战阻碍了它的应用。随着特征尺寸的不断缩小以及由此带来的计算能力的指数级增长,我们看到,现在大家普遍有兴趣采用数字相控阵。虽然DBF具有许多吸引人的特性,但更高的功耗和成本仍然是一个问题。混合波束成型方法具有出色的能效比,可能适合于许多应用。
模拟与数字波束成型
波束成型的核心是延迟和求和运算,它可以发生在模拟域或数字域中。根据延迟或相移在信号链中应用的位置,模拟波束成型又可以分为多个子类别。本文仅考虑射频波束成型。如图1a所示,来自天线元件的信号经过加权和合并,产生一个波束,然后由混频器和信号链其余部分加以处理,这就是相控阵的传统实现方式。
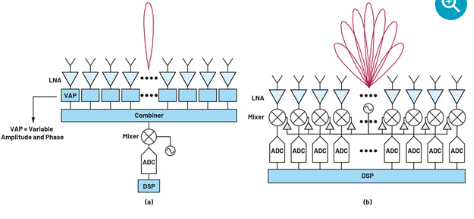
图1. (a) 模拟和 (b) 数字波束成型架构的比较。
这种架构的缺点之一是难以创建大量同时波束。现在,为了创建多个波束,每个元件的信号需要先分离,再独立地延迟和求和。为此所需的可变幅度和相位(VAP)模块的数量与元件数量和波束数量成正比。VAP模块以及网络的分路和合并需要占用很大的面积,而且除了几个波束之外,网络分路和合并造成的不断增加的面积要求和复杂性使得实现多个同时模拟波束变得不切实际。对于平面阵列,不断增加的面积还使得难以将电子器件安装在元件间距所决定的网格内。此外,更为根本的是,每次分路时,信噪比(SNR)都会降低,而且本底噪声限制了信号可以分路的次数,超过此次数,信号就会淹没在本底噪声中。
而使用DBF的话,创建多个同时波束相对较容易。如图1b所示,每个元件的信号都被独立数字化,然后在数字域中进行波束成型操作。一旦进入数字域,就可以在不损失保真度的情况下创建信号的副本,然后将信号的新副本延迟并求和以创建新波束。这可以根据需要重复多次,理论上可产生无限数量的波束。实践中,数字信号处理及相关功耗和成本不是无限的,这会限制波束数量或波束带宽积。此外,DBF中的波束数量可以随时重新配置,这是模拟技术无法做到的。DBF还支持更好的校准和自适应归零。所有这些优点使得DBF对通信和雷达系统中的各种相控阵应用非常有吸引力。但是,所有这些好处都是以增加成本和功耗为代价的。基带DBF需要为每个元件配备一个ADC和一个混频器,而模拟波束成型只需要为每个波束配备相关器件。器件数量的增加会显著提高功耗和成本,尤其是对于大型阵列。此外,DBF中的波束成型发生在基带,混频器和ADC会受到每个元件的广阔视场中存在的任何信号的影响,因此需要有足够的动态范围来处理可能的干扰。对于模拟波束成型,混频器和ADC享有空间滤波的好处,因此动态范围要求可以放宽。在分配高频LO信号的同时保持相位相干性,也是DBF实现方案的一个挑战,而且会增加功耗。
数字波束成型的计算需求是总体功耗的一个重要贡献因素。DSP须处理的数据量与元件数量、波束数量和信号的瞬时带宽成正比。
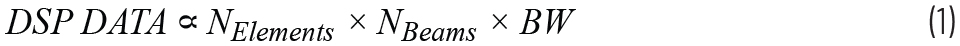
对于在毫米波频率运行的大型阵列,信号带宽通常很大,数据负载可能高得像天文数字。例如,对于一个具有500 MHz带宽和8位ADC的1024元件阵列,DSP需要处理每波束每秒大约8 Tb的数据。移动和处理如此大量的数据需要消耗相当多的电力。就计算负载而言,这相当于为每个波束每秒执行大约4×1012次乘法运算。对于全信号带宽的多个波束,所需的计算能力超出了当今的DSP硬件的能力范围。在典型实现中,波束带宽积保持不变,若增加波束数量,总带宽将在各波束之间分配。数字信号处理通常以分布式方式进行,以便能够应对大量数据。但这通常需要权衡各种因素,如波束成型灵活性、功耗、延迟等。除了处理能力之外,各种DSP模块的高速输入/输出数据接口也会消耗大量电力。
混合波束成型
顾名思义,混合波束成型是模拟和数字波束成型技术的结合,在两者之间提供了一个中间地带。做法之一是将阵列划分为更小的子阵列,并在子阵列内执行模拟波束成型。如果子阵列中的元件数量相对较少,则产生的波束相对较宽,如图2所示。每个子阵列可以被认为是具有某种定向辐射图的超级元件。然后使用来自子阵列的信号执行数字波束成型,产生对应于阵列全孔径的高增益窄波束。采用这种方法时,与全数字波束成型相比,混频器和ADC的数量以及数据处理负载的大小减少的幅度等于子阵列的大小,因此成本和功耗显著节省。对于32×32元件阵列,若子阵列为2×2大小,则将产生256个子阵列,其半功率波束宽度(HPBW)为50.8°或0.61立体弧度。使用来自256个子阵列的信号,可以利用DBF在合乎实际的范围内创建尽可能多的波束。对应于全孔径的HPBW为3.2°或0.0024 sr。然后,在每个子阵列的波束内可以创建大约254个数字波束,它们相互之间不会明显重叠。与全DBF相比,这种方法的一个限制是所有数字波束都将包含在子阵列方向图的视场内。子阵列模拟波束当然也可以进行控制,但在一个时间点,模拟波束宽度会限制最终波束的指向。
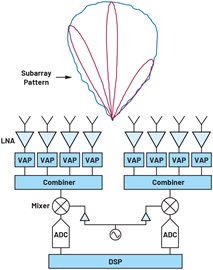
图2. 混合波束成型。
子阵列方向图通常很宽,这对于许多应用来说可能是一个可以接受的折衷方案。对于其他需要更大灵活性的应用而言,可以创建多个独立的模拟波束来解决此问题。这将需要在RF前端使用更多VAP模块,但与全DBF相比,仍然可以减少ADC和混频器的数量。如图3所示,可以创建两个模拟波束以实现更大的覆盖范围,同时仍能将混频器、ADC和产生的数据流的数量减少两倍。
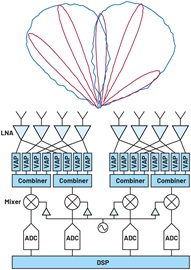
图3. 多个模拟波束的混合波束成型。
与DBF相比,混合波束成型还会导致旁瓣退化。当远离模拟波束中心扫描数字波束时,相位控制的混合性会引入相位误差。子阵列内元件之间的相位变化由模拟波束控制确定,无论数字扫描角度如何都保持固定。对于给定的扫描角度,数字控制只能将适当的相位应用于子阵列的中心;当从中心向子阵列边缘移动时,相位误差会增加。这导致整个阵列出现周期性相位误差,从而降低波束增益并产生准旁瓣和栅瓣。这些影响随着扫描角度的增大而增加,与纯模拟或数字架构相比,这是混合波束成型的一个缺点。让误差变成非周期性可以改善旁瓣和栅瓣的退化,这可以通过混合子阵列大小、方向和位置来实现。
能效比
本节从接收相控阵的角度比较模拟、数字和混合波束成型的能效比。模拟、数字和混合波束成型的功耗模型分别由公式2、3、4给出。表1列出了各种符号的含义以及它们在后续分析中的假定值。
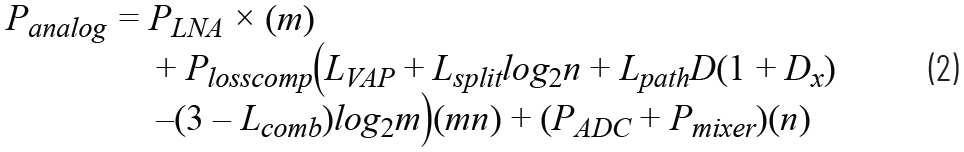
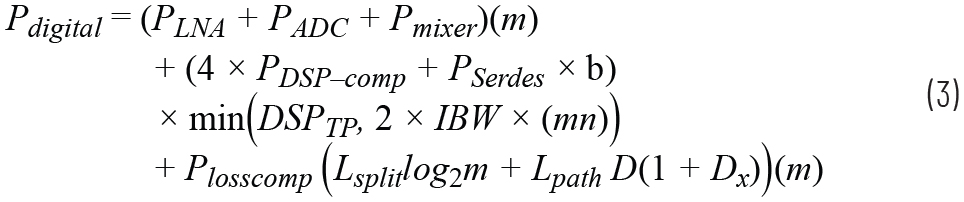
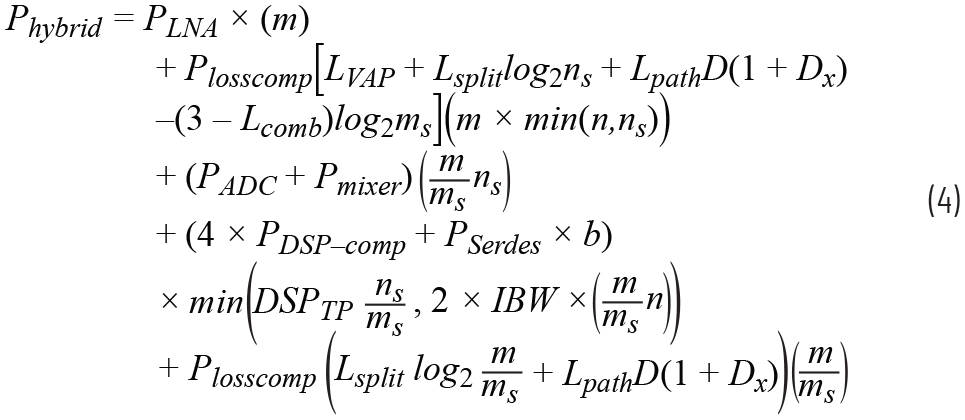
| 符号 | 含义 | 值 | 参考文献 |
|
PLNA |
LNA功耗 |
15 mW/实例 |
1 |
|
Plosscomp |
补偿RF/LO路径中各种损耗的功率 |
1.5 mW/dB | 1 |
|
Pmixer |
混频器/LO放大器功耗 |
40 mW/实例 | 2 |
|
PADC |
ADC功耗;8位,1 GSPS |
5 mW/实例 | 3, 4 |
|
b |
ADC位数 | 8 | |
|
PDSP-comp |
用于波束成型计算的DSP功率 |
1.25 mW/GMAC | 5 |
| PSerdes |
用于I/O的DSP功率 |
10 mW/Gbps | 6 |
|
LVAP |
无源增益和相位控制造成的损耗 | 10 dB | 7 |
|
Lsplit |
用于ABF的功率分路器的损耗 | 4 dB | |
|
Lcomb |
用于ABF的功率合成器的损耗 |
1 dB |
|
|
Lpath |
每单位长度的RF/LO布线损耗 | 0.05 dB/mm | 8 |
| D | 阵列的长度/宽度 | 155 mm | |
|
Ds |
子阵列的长度/宽度 |
15 mm | |
|
Dx |
用于RF信号布线和合成的附加长度系数 | 0.25 | |
| m |
元件数量 |
1024 | |
|
ms |
子阵列中的元件数量 | 16 | |
|
n |
波束数量 |
— |
|
|
ns |
混合波束成型中的模拟波束数量 |
4 | |
|
IBW |
信号的瞬时带宽 | 500 MHz | |
|
DSPTP |
用于DBF的DSP的最大吞吐速率 | 8 TSPS |
关于功耗模型的一些关键点如下:
假设混频器处的射频信号功率对于所有三种波束成型架构都相同。
在一些公开文献中,有人认为对于DBF,由于ADC的量化噪声对SNR的影响有所降低(降幅等于阵列因子),因此与模拟波束成型相比,所需的位数可以减少。然而,在DBF中,ADC也需要具有更高的动态范围,因为它们不享有空间滤波的好处,而且需要处理各元件辐射图的视场中存在的所有干扰。考虑到这一点,本模型假设ADC的位数在所有情况中都相同。
对于DBF,波束带宽积受DSP处理能力的限制,这一点在变量DSPTP中考虑。对于混合情况,最大处理能力随着功耗的降低而成比例降低。
DBF的DSP功耗有两个部分——计算和I/O。每次复数乘法需要四次实数乘法和累加(MAC)运算,基于 "Assessing Trends in Performance per Watt for Signal Processing Applications" (信号处理应用的每瓦性能趋势评估)一文5,MAC运算的功耗计算结果为大约1.25 mW/GMAC。在这种情况下,I/O消耗了大部分DSP功率,根据 "A 56-Gb/s PAM4 Wireline Transceiver Using a 32-Way Time-Interleaved SAR ADC in 16-nm FinFET" (16 nm FinFET中使用32路时间交错SAR ADC的56 Gbps PAM4有线收发器)一文6,其估计值为10 mW/Gbps。对于需要更密集计算的更复杂波束成型方法,功耗比的偏斜会更小,但DSP总功耗会增加。此外,此模型中的I/O功耗假设基于最低数据传输。根据DBF架构,I/O的功耗可能更高。
ADC和DSP计算的功耗与位数呈指数关系。因此,可以通过减少位数来大幅降低这些功耗数值。另一方面,作为最大贡献因素的DSP I/O功耗随位数的变化不是那么剧烈。
布线损耗(Lpath)通过合并硅IC和低损耗PCB上的GCPW传输线的损耗来计算。对于片内传输线,假设损耗为0.4 dB/mm,而对于PCB走线8,损耗取为0.025 dB/mm。另外,据估计,5%的线路是在芯片上,其余是在PCB上。模拟波束成型考虑射频合并相关的布线损耗,而数字波束成型考虑LO分配网络的损耗。
对于混合模型,假设每个波束对应于阵列的全孔径。
功耗与波束数量的依赖关系如图4所示。对于模拟情况,改变波束数量需要更改设计,而在DBF中,波束数量可以随时改变,设计则保持不变。对于混合情况,考虑具有固定数量模拟波束(ns)的单一设计。另外假设,当波束数量小于ns时,未使用路径中的放大器关断。
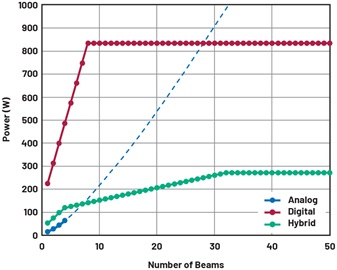
图4. 模拟、数字和混合(具有四个模拟波束)波束成型架构的功耗与波束数量的关系对于模拟情况,超过四个波束时曲线显示为虚线,表示使用模拟技术难以实现更多波束。对于数字和混合情况,一旦达到DSP的容量,每个波束的功率和带宽就变得恒定。
对于单个波束,由于额外混频器、LO放大器和ADC的开销,数字实现方案会消耗更多功率。对于数字情况,功耗增加的速率取决于聚合数据速率的增加情况;对于模拟情况,功耗增加的速率与补偿分路和附加VAP模块造成的损耗所需的功率有关。由于上述网络分路和合并的复杂性,使用模拟波束成型实现大量波束是不切实际的,超过四个波束的虚线反映了这一事实。对于DBF,一旦达到最大DSP容量,功耗便不再增加。超过这一点之后,若增加波束数量,则每个波束的带宽会减少。在功耗方面,DBF与ABF不相上下,有大量波束时功耗更少。与DBF相比,混合方法显著降低了功耗开销和斜率,并更快地达到盈亏平衡点。
图5显示了每波束带宽积的功耗,并比较了三种波束成型情况的能效比。可以看出,模拟波束成型始终更有效率。混合方法从两个极端之间的某个位置开始,随着波束数量增加而变得与模拟情况相当。
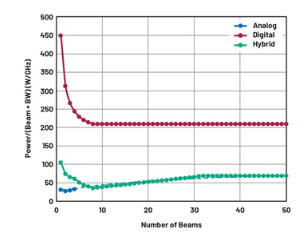
图5. 比较模拟、数字和混合波束成型架构的能效比。
结论
本文介绍的比较和功耗模型仅适用于接收(Rx)相控阵。对于发射情况,一些基本假设将会改变,全DBF架构的功耗增加可能不那么严重。即使对于接收情况,三种架构之间的差异在很大程度上也取决于公式2至4中所示的参数。对于表1中未给出的参数值,图表之间的差异将会变化。但可以肯定地说,混合方法可让许多应用大幅节省功耗,同时保留数字波束成型的大部分优势。如前所述,采用混合路线有缺点,但对于许多应用而言,这些不足可以被节省的功耗所抵消。
审核编辑:郭婷
-
雷达模拟波束成形和数字波束成形的区别2023-10-13 8628
-
混合波束赋形接收机动态范围—从理论到实践2023-06-14 1671
-
多波束相控阵接收机混合波束成形功率优势的定量分析2022-12-14 5601
-
混合波束成形接收机动态范围理论实践2022-12-13 2309
-
混合波束赋形系统的接收机动态范围分析2022-10-31 2653
-
多波束相控阵天线的应用优势2022-05-06 11398
-
解析相控阵三种波束成型架构2022-02-14 7403
-
用于毫米波5G基础设施的波束成型器前端和上下变频芯片2021-11-18 4018
-
图解—相控阵雷达——波束扫描技术2020-05-23 25630
-
怎么设计基于FPGA多波束成像的声纳系统?2019-10-09 3448
-
【模拟对话】相控阵波束成形IC简化天线设计2019-10-01 3713
-
嵌入式定量分析系统的原理是什么?2019-08-15 1413
-
相控阵天线通道误差对波束形成有什么影响2019-06-13 2146
-
基于FPGA多波束成像的声纳系统设计2017-11-18 5052
全部0条评论

快来发表一下你的评论吧 !
