

中文信息处理实验室提出工具学习新框架ToolAlpaca
描述
如何让小规模语言模型像 GPT-4 一样使用任意工具是一个非常有价值的研究课题。中国科学院软件研究所中文信息处理实验室提出了一种语言模型的工具学习新框架,该框架利用基于大模型的多智能体模拟交互策略,可以自动生成多样化的工具使用数据集,并使用生成的数据集对小模型进行微调。论文的实验验证了仅需要使用三千多个多样化的工具调用实例,就能够使小型模型获得与极大规模模型相媲美的通用工具使用能力。
具体来说,本文的核心工作包括:
1. 提出一种基于大模型的多智能体模拟交互策略,用于生成工具使用数据集。这种方法能在最小化人工干预的前提下,生成大量且多样化的工具使用数据集;
2. 开源了一个涵盖超过400个工具,三千多条实例的模拟工具使用数据集,为探索通用工具使用能力奠定了基础;
3. 通过实验,验证了在多样化工具使用数据集上进行微调,能够使小型模型获得与极大规模模型相媲美的通用工具使用能力。
论文:ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases
数据:https://github.com/tangqiaoyu/ToolAlpaca
背景工具的使用在人类进化史上占据了重要的地位,对于语言模型来说,这一点同样适用。当语言模型能够熟练运用各种工具,它们就能突破自身的局限,获取最新的信息,帮助用户利用各种服务,并提升回答的精确性。 如今,OpenAI 的 GPT-4 已经可以通过插件的形式接入和使用各种第三方工具,同时这类超大型的语言模型支持通过仅给定配置文件的情况下,以即插即用的方式使用之前模型训练过程中未见过的工具,这一泛化性的工具使用能力大大丰富了模型调动资源解决复杂问题的手段。然而,对于较小的语言模型,例如 Moss、ToolLLaMA 等,它们使用工具的能力仍然来源于在特定工具的数据集上进行监督学习。这使得这些模型的工具使用能力受限于在训练过程中接触过的工具,尚未真正获得通用的工具使用能力。上述的对比引出了研究人员所关注的一个核心研究问题,即是否有可能让较小规模的语言模型也具备有泛化地使用各种不同的、未见过的工具的能力,进而让它们能够更好地与更广泛的工具进行交互,从而提升模型利用现实世界的资源解决问题的手段。
ToolAlpaca:通用工具使用能力学习新框架
受 Alpaca 通过微调让小模型学会通用指令遵循启发,中文信息处理实验室的研究人员探索了通过在通用工具使用数据集上微调较小规模的语言模型,让它们获得通用工具使用能力。实现上述能力的一个核心难点在于需要构建一个多样化的工具使用数据集。然而,由于工具使用涉及复杂的多方交互,现今仍然缺乏公开可用的多样化工具使用数据集。为了解决这个挑战,研究人员提出通过多智能体模拟交互的方式生成工具使用数据集。这种方法充分利用大模型强大的文本生成能力,在几乎不需要任何人工干预的情况下构建一个多样化且真实的数据集。我们从构建多样化工具集开始,之后利用多智能体模拟生成工具使用数据集,最后基于此训练出拥有通用工具使用能力的 ToolAlpaca 模型。
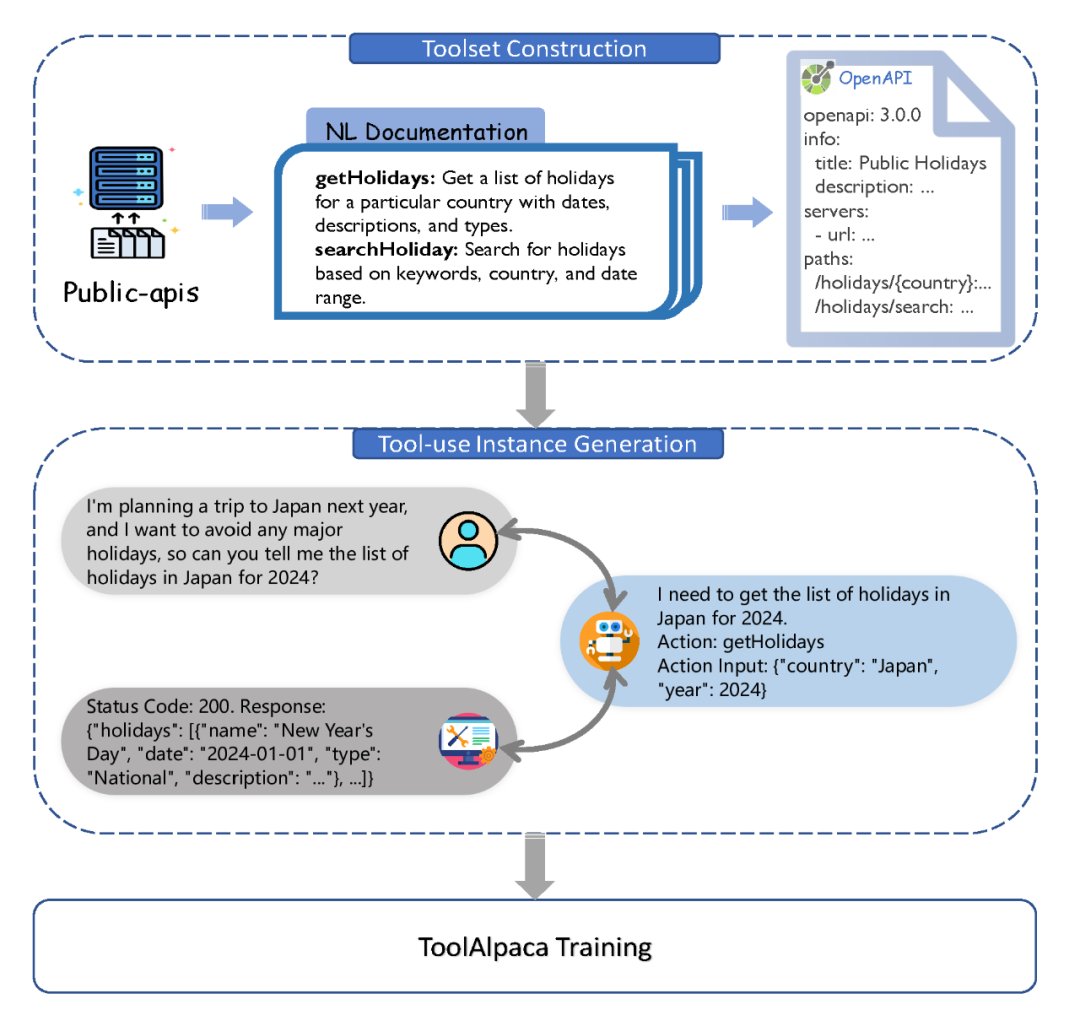
工具集构建:我们首先从开源仓库 public-apis 中获取工具的名称和简短描述作为初始信息,之后利用大语言模型通过 prompt 的方式将其扩展成自然语言形式的文档,描述工具提供的每一个函数及其对应的输入。为了让信息更为精细和结构化,我们进一步将这些自然语言文档扩展为遵循 OpenAPI 规范的文档,详尽描绘了每个函数的细节。结构化文档的使用不仅使我们的工具集更为细致和完备,同时也方便了我们的工具集与其他工具(如 ChatGPT 现有的 Plugin 等)进行兼容。下图为一个名为 Public Holidays 工具的示例。

工具使用实例生成:尽管我们已经构建了大规模且多样化的工具集,但构建工具使用数据集仍然是一项富有挑战性的任务。首先,由于工具集是由大模型生成的,要根据工具集文档构造如此大量的真实工具,需要大量的编程和数据收集工作,几乎不可能实现;其次,工具集本身包含了从通用到专用的各种领域的工具,使得构造与工具相关的初始指令是困难的。为此,我们提出了一种多智能体模拟交互的策略来生成工具使用数据。我们利用大模型分别模拟用户、AI 助手、工具执行器这三个智能体,通过他们之间的交互来生成丰富且实用的工具使用数据。
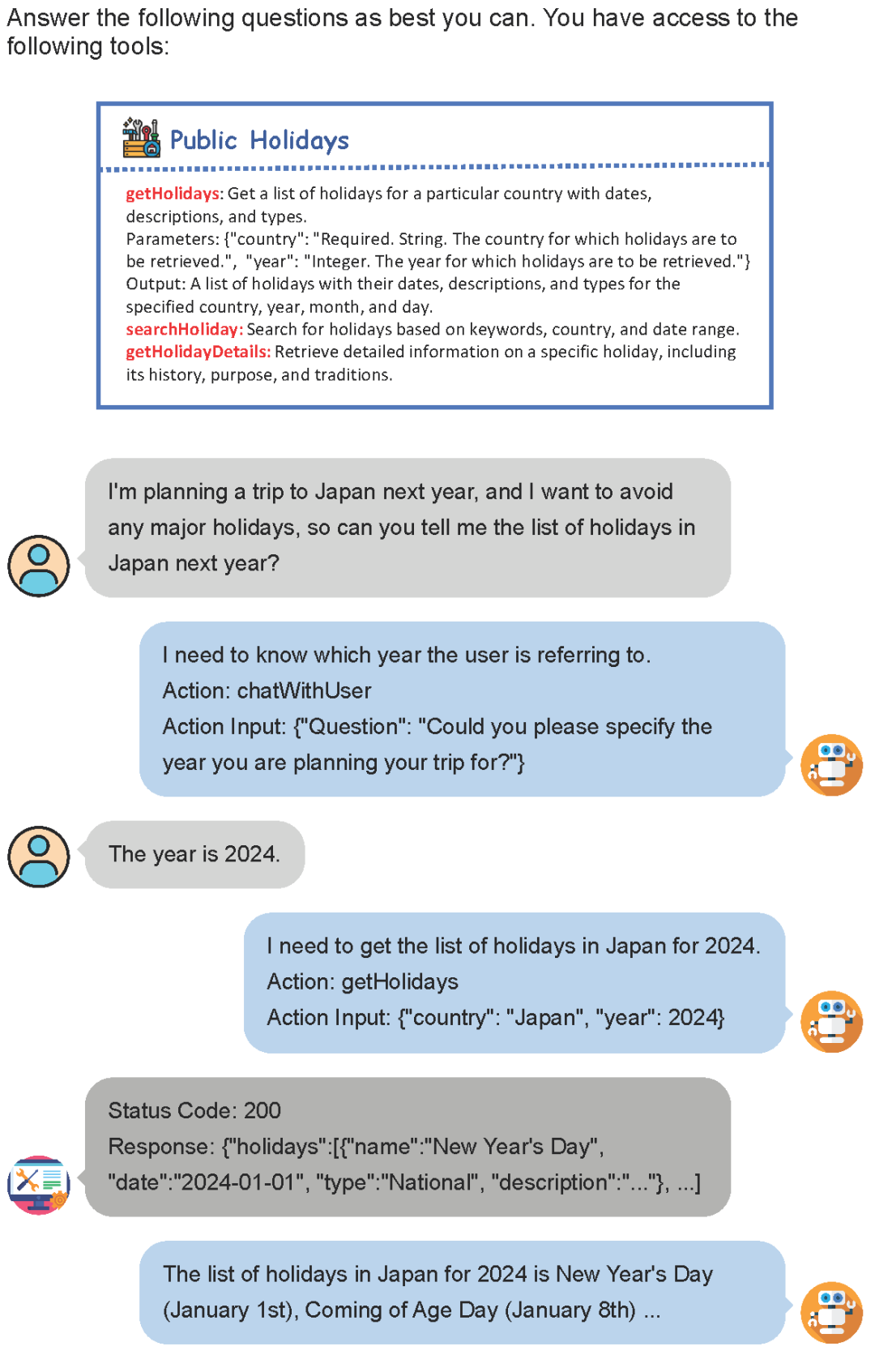
如上图所示,用户发起最初的指令,并通过简单的交互提供更多必要的信息。工具执行器则利用结构化文档作为提示,借助大模型来模拟工具的执行过程,从而产生相应的反馈。而AI助手则充当两者之间的桥梁,它帮助用户调用各种工具以解决问题,并最终对整个交互过程进行总结,返回给用户最终的响应结果。通过这三个智能体的交互,我们成功构建了一套能贴近真实场景需求的工具使用数据集。
ToolAlpaca 模型训练与测试:我们使用生成的数据集对 Vicuna 模型进行微调,以此得到最终的 ToolAlpaca 模型。在测试阶段,ToolAlpaca 将担任 AI 助手的角色,同时用户和工具执行器的角色仍由大模型扮演。
实验
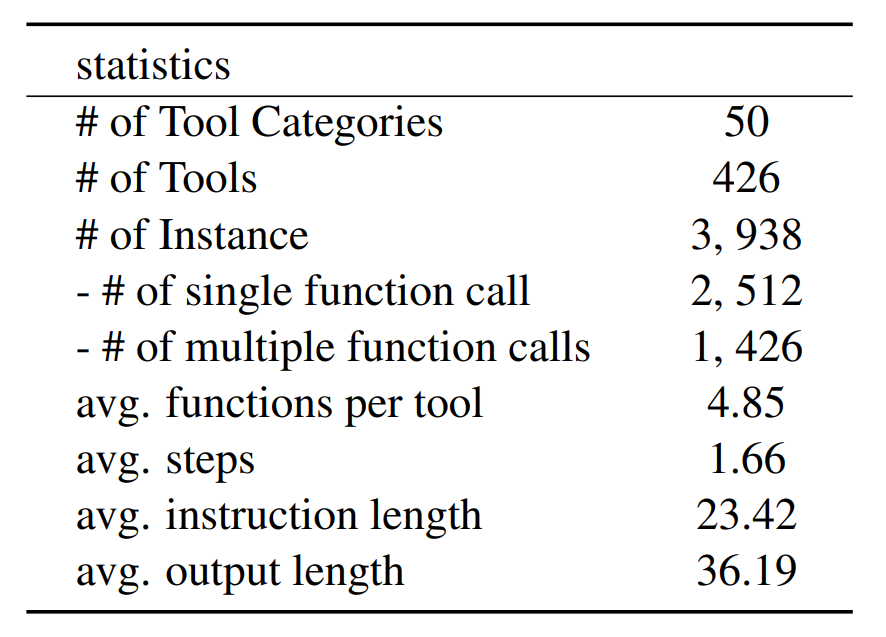
最终,我们利用 ChatGPT 和 GPT-3.5 构造了一个包含超过400个工具、3900多条工具使用实例的模拟数据集,数据集基本统计信息如下图所示。
之后,我们在Vicuna 模型上进行微调,得到 ToolAlpaca 模型。为了评估模型的泛化性能,我们在10种未包含在训练集中的工具上构造了含有100条数据的测试集,并通过人工评价对模型的工具调用过程和整体性能进行了评估。评测结果如下图所示。
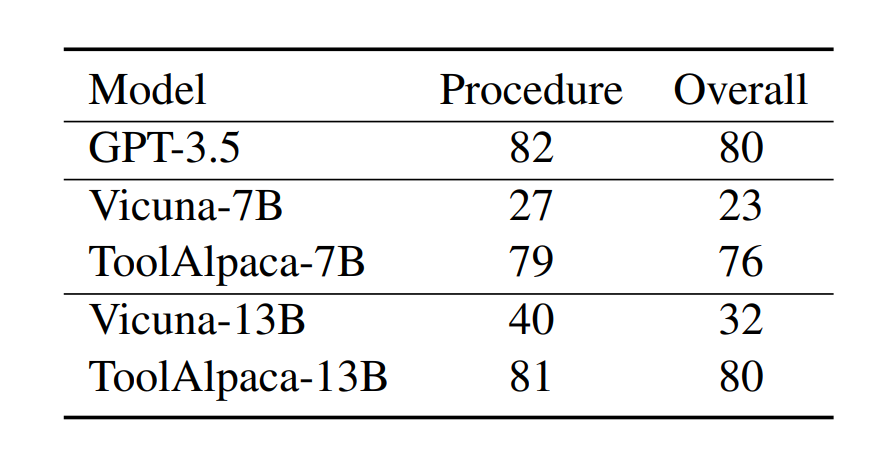
实验结果表明,无论是7B还是13B的模型,经过在 ToolAlpaca 数据集上的训练后,其性能都有了显著的提升。值得注意的是,ToolAlpaca 在测试集上的整体性能已经接近于 GPT-3.5 的表现。这些实验结果验证了我们构建数据集的有效性,同时也回答了我们最开始提出的问题:通过在多样化的工具使用数据集上微调,可以让小模型获得通用的工具使用能力。
-
[原创]认证与实验室2009-10-29 3463
-
NI信号处理实验室2014-07-31 2757
-
实验室整体解决方案是什么?2014-08-11 2728
-
智慧实验室解决方案(LoRa)2018-02-25 3083
-
KGB知识图谱引擎助力NLPIR中文信息处理2018-11-09 1822
-
智慧实验室教学管理系统平台开发设计案例2019-12-09 2559
-
系统控制与信息处理实验室 精选资料分享2021-07-19 1046
-
lims实验室管理系统是什么?实验室信息管理系统介绍!2021-11-03 17843
-
实验室lims系统解决方案2021-11-04 3114
-
实验室设计指南2008-11-09 2098
-
网络虚拟实验室及实现方法2011-07-04 992
-
易云维®实验室智能管理系统构建更适合现代医疗实验室的信息化管理体系2023-06-27 1591
-
什么是智慧实验室综合管理平台?2023-08-22 2495
-
实验室信息管理系统 LIMS 优势2024-10-28 1950
全部0条评论

快来发表一下你的评论吧 !
