

如何确定合适的存储系统 存储的关键瓶颈是什么
存储技术
描述
当下科技行业be like...
据说现在的科技公司,不是在抢GPU,就是在往抢GPU的路上……此前4月,特斯拉CEO马斯克就购买了1万块GPU,他还称公司将继续大量购买英伟达的GPU。
在国内,近日也有报道称,字节跳动今年向英伟达订购了超过10亿美元的GPU,仅字节一家公司今年的订单,可能已接近英伟达去年在国内销售的商用GPU总和。
而在企业这边,为了“珍惜”来之不易的GPU,IT人员也在快马加鞭,他们希望能让GPU时刻忙碌,从而确保投资回报。不过有的企业可能会发现,GPU数量增加了,但GPU闲置却越来越严重。
原因何在?
别让存储成为你的关键瓶颈
如果说HPC的历史教会了我们什么的话,那就是不能以牺牲存储和网络为代价,过分关注计算。如果存储无法以良好的性能及时将数据传输到计算单元,那么即使你手握世界上最多的GPU,也无法将其转化为效率。
IT分析公司 Small World Big Data 的分析师 Mike Matchett 表示,有些模型足够小,可以在内存(RAM)中执行,从而将更多的注意力放在计算上。但如今像ChatGPT这样的大模型,需要数十亿个节点,无法保存在内存中,因为成本太高。
“你无法在内存中存放数十亿个节点,存储变得更加重要。”Matchett 说。
一般而言,无论是怎样的用例,在模型训练的过程中都有四个共同点:
训练模型
推理应用
数据存储
加速计算
而在这些要素中,数据存储在规划过程中往往容易被忽视。
因为在创建和部署模型时,大多数的要求是迅速通过POC或测试环境,从而尽快开展模型训练,数据存储需求并不是优先考虑的。
然而,挑战在于训练或推理部署可能持续数月或数年时间。许多公司在这段时间里迅速扩大了模型规模,而基础设施也必须扩展以适应不断增长的模型和数据集。
谷歌此前公布的数百万ML训练工作负载的研究报告表明,工作负载平均花费30%的训练时间在输入数据的管道上。虽然过去的一些研究工作侧重于通过优化GPU来加速训练,但在优化数据管道的各个部分方面仍然面临许多挑战。
确定合适的存储系统
当你有了非常强大的算力后,真正的瓶颈变成了你能以多快的速度将数据输入计算,从而得到结果。
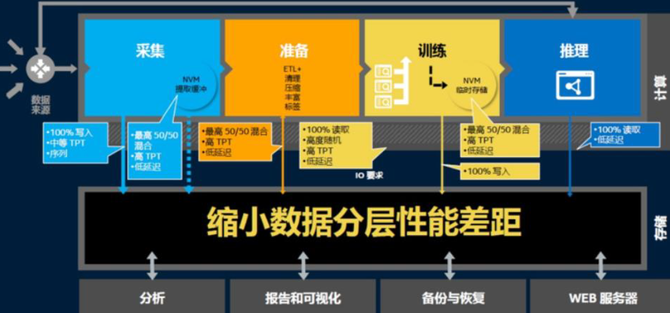
特别是数据存储和管理方面的挑战,需要对数据增长进行规划,这样你就可以在前进的过程中不断获取数据的价值,特别是当你开始更高级的用例,如深度学习和神经网络,这对存储的能力、性能和规模提出了更高的要求。具体而言:
可扩展性
机器学习需要组织处理大量数据,而且数据量越大,模型的准确性相对也越高,这意味着企业每天必须收集和存储越来越多的数据。而当存储无法扩展时,数据密集型工作负载会产生瓶颈,这会限制性能并导致昂贵的GPU闲置。
灵活性
灵活利用多种协议支持(包括NFS、SMB、HTTP、FTP、HDFS和S3),以确保满足不同系统的需求,而不仅仅是单一类型的环境。
延迟
I/O的延迟对于构建和使用模型很重要,因为数据会被多次读取和重读。减少I/O延迟可以将模型的训练时间缩短数天或数月。更快的模型开发直接转化为更大的业务优势。
吞吐量
当然,存储系统的吞吐量对于高效的模型训练也至关重要。训练过程使用大量数据,通常以每小时TB为单位。
并行访问
为了实现高吞吐量,训练模型会将活动拆分为多个并行任务。这通常意味着机器学习算法会同时从多个进程(可能在多个物理服务器上)访问相同的文件。存储系统必须能够在不影响性能的情况下应对并发需求。
首屈一指横向扩展NAS存储为模型训练提供动力
凭借低延迟、高吞吐量和大规模并行I/O的卓越能力,戴尔PowerScale是GPU加速计算的理想存储补充。
PowerScale能够有效地压缩训练和测试多字节数据集的分析模型所需的时间。在PowerScale全闪存存储中,带宽增加了18倍,从而消除了I/O瓶颈,并且可以添加到现有的Isilon集群中,以加速和释放大量非结构化数据的价值。
此外,PowerScale的多协议访问能力,为企业运行工作负载提供了无限灵活性,这些工作负载既可以使用一种协议存储数据,也能够使用另一种协议访问数据。

具体而言,PowerScale平台的强大功能、灵活性、可扩展性和企业级功能可帮助您应对挑战:
●以高达2.7倍的性能加速创新,加快模型训练周期。
●利用企业级功能、高性能、并发性和可扩展性消除I/O瓶颈,提供更快的模型训练和验证,提高模型精度,改善数据科学生产力,并使计算投资回报率(ROI)最大化。
●通过在单个集群中高达119PB的有效存储容量,以更深的高分辨率数据集提高模型的准确性。
●利用灵活的部署和网络弹性,使您能够从小规模开始,独立扩展计算和存储,以实现大规模部署,并提供强大的数据保护和安全选项。
●通过灵活的就地分析和预先验证的解决方案,提高数据科学的生产力,以实现更快的、低风险的部署。
●经验证的设计基于同类最佳技术,包括 NVIDIA GPU加速和带有NVIDIA DGX系统的参考架构。
PowerScale的高性能、高并发性能可满足机器学习从数据采集、数据准备、模型训练和模型推理各阶段对存储性能的要求;加上其搭载的OneFS操作系统,使所有节点能够在同一OneFS驱动的集群中无缝运行,并具有性能管理、数据管理、安全和数据保护等企业级功能,能更快帮助企业完成模型的训练和验证。
编辑:黄飞
-
基于SD卡的驾驶行为再现存储系统设计2009-05-17 2726
-
网络存储系统可生存性量化评估2010-04-24 2350
-
如何利用FPGA的设计微型数字存储系统?2019-08-01 984
-
什么是云存储?云存储系统的结构是如何构成的?2021-06-02 2987
-
存储系统的层次结构2021-07-29 2269
-
存储系统的层次结构是怎样的?2021-11-02 2484
-
基于FPGA的微型数字存储系统设计2009-11-04 1211
-
数字射频存储系统关键技术仿真研究2009-11-10 1120
-
基于EVMS的带外虚拟存储系统结构2011-05-18 1058
-
基于闪存的图像存储系统设计2016-09-22 750
-
NetApp_E5600_存储系统2016-12-28 963
-
NetApp_E2700_存储系统2016-12-29 1037
-
高分辨航拍相机实时图像存储系统的关键技术pdf下载2018-02-27 973
-
探讨AI在存储中的应用和对存储系统的改进2018-10-24 5541
-
中科曙光基于区块链存储应用的智能高效的专属存储系统—区块链存储系统ChainStor2020-12-31 15031
全部0条评论

快来发表一下你的评论吧 !
