

SDNLAB技术分享:Ceph在云英的实践
通信网络
描述
Ceph是最近开源系统中很火的一个项目,基于Sage Weil的一片博士论文发展而来的一个分布式文件系统,可提供PB级,动态可扩展,数据安全可靠的存储服务。Ceph提供分布式存储服务包括:块存储RBD,对象存储RADOSGW和CephFS三种,基本覆盖了绝大部分企业对存储的需求,所以越来越多企业加入到使用Ceph的行列。在国内也有越来越多的个人和企业参与到Ceph的研发中,贡献自己的力量。
首先,我们来看下Ceph系统的整体架构:
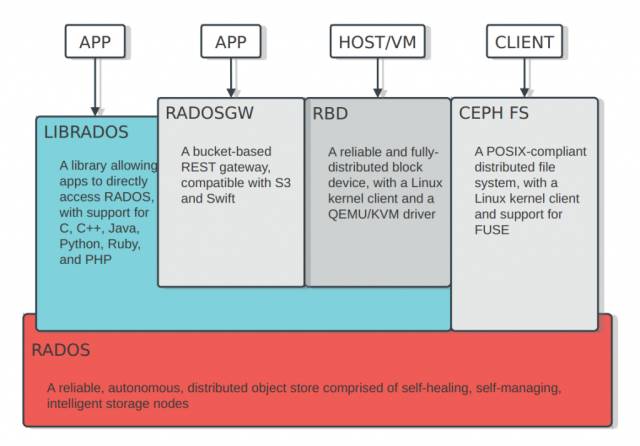
如上图所示,有如下几部分:
1). RADOS: Ceph的核心模块,提供固定大小的Object存储
2). LIBRADOS: RADOS的library,提供C, C++, Java, Python, Ruby, PHP的API访问RADOS
3). RADOSGW: Rados GateWay,基于bucket策略,提供一个兼容S3和Swift的的REST gateway
4). RBD: 提供可靠的分布式块存储服务,结合Openstack,应用非常之广
5). CEPH FS:提供POSIX协议的文件系统服务
从上面可以看出,RADOS是Ceph的核心,它主要由MDS + OSD组成,下图描述的即是一个个笑脸(object)如何存储到OSDs中:
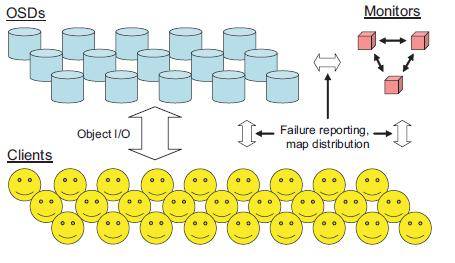
Client端会跟Monitors通信,获取Cluster Maps信息,然后通过固定的算法算出每个Object存储的OSD位置,直接与OSD通信,写入Object数据。
这里Ceph的一大优势很好的体现出来:无需元数据服务器节点,所有都是“无需查表,算算就好”!
前面我们提到了Ceph是一个动态可扩展,数据安全可靠的存储服务,现在我们逐一来讨论下Ceph作为一个分布式系统必须的三种特性:
1). 高扩展性
针对集群的扩容需求,Ceph支持OSD和Monitor集群的动态可扩容,并通过两层Map机制[(pool, object) -> (pool, PG) -> OSD set)来有效的隔离了集群扩容对上层client的影响,提供了很好的扩展性。这样我们可以利用大量的低配置设备轻松的搭建出PB甚至EB级的存储系统。
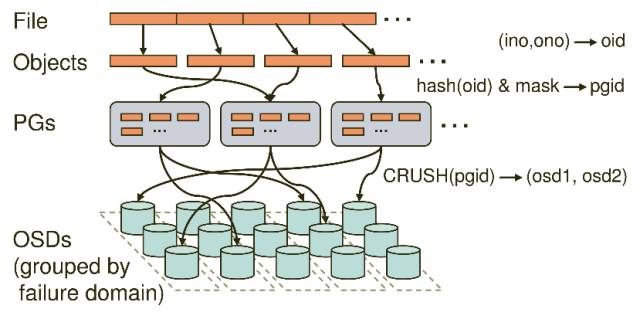
上图描述了Client段的一个File如何经过多层的映射,写入到OSDs中的,也正是这多层映射和CRUSH算法,保证了Ceph的高扩展行。在PG数不变的情况下,底层OSD的扩展对Client端是完全透明的。
2). 高可靠性
针对数据的安全可靠,Ceph会在集群中存储同一数据的多个副本(或者其他类型的冗余,例如erasure code),来保证在某些设备故障后,用户存入的数据还可用,针对用户不同的高可用需求,Ceph可以很方便的设置Pool的数据冗余规则,另外通过Ceph Crushmap,用户也可以方便的设置各个备份之间存储位置的逻辑关系,比如达到多个副本跨机房、跨机架、跨机器等目的,提高集群的数据可靠性。
另外Ceph能自动探测到OSD/Monitor/MDS的故障,并自行恢复,有效减少了单设备节点的稳定性对集群的影响。
下图是Ceph中一个写IO的流程,保证数据的强一致性:
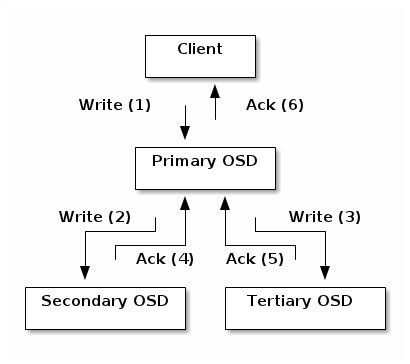
从图中可以明显的看出,Ceph的写会由Client发给Primary OSD,由Primary OSD发送副本给Replica OSD上,而只有所有的副本都写完成后,写IO才算完成,保证了数据的一致性和高可靠性。
3). 高性能
Ceph中通过文件切分和CRUSH算法,保证数据chunk分布基本均衡,同时Ceph的无元数据信息的设计(CephFS除外),保证了Client可以根据cluster map,通过固定算法确定数据的位置信息,避免了单个元数据节点的性能瓶颈,可以提供非常高的并行化IO性能。
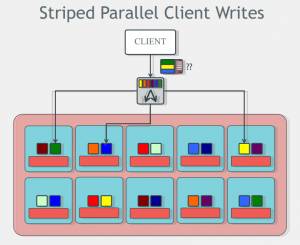
如上图所示,Client端数据经过切分为Objects后,可以同时与多个OSDs交互,写入数据。
前面大致介绍了Ceph系统的原理和架构,那我们为什么选择Ceph呢?
对比现有的一些其他的分布式存储系统,Ceph有如下优点:
1). 完全的开源系统
2). 能提供块存储,对象存储和文件系统存储的统一架构
3). 设计理念先进,是个高扩展,高可用,高性能的分布式文件系统
4). 与Openstack完美结合,社区支持好
5). Ceph社区活跃度很大
总之,作为一个比较完善的分布式存储系统,Ceph能满足绝大多数企业的存储需求,同时它也提供了足够多的配置选项,给用户根据需求定制化自己的存储系统。
上面大致介绍了Ceph的原理架构和设计理念,下面我们来介绍下Ceph在云英的具体实践,给大家一个真实的感受。
首先说一下云英,云英的全称是北京云英传奇技术有限公司。我们是一家专注于为创客和行业客户提供云计算服务的公司,我们提供的有公有云和私有云服务,包括IAAS和PAAS层产品,网址为:www.cloudin.cn
在云计算的技术上我们选择了openstack + ceph的架构,基于之上实现了我们自己的逻辑和特色功能,包括云监控,自动化运维,RDS等服务。针对这么多应用,绝大部分服务的数据都依靠Ceph系统提供可靠的存储服务,在应用实践中,针对我们自己的系统架构和机房部署,我们对Ceph也进行了部分调优和优化,达到了我们的应用需求。
下面我们来介绍下Ceph存储在云英的应用,大致可以分为如下几种:
- RBD块存储服务
- CephFS提供服务器间数据共享
- RADOSGW提供对象存储服务
- Ceph的性能测试
- Ceph的优化
- Ceph的监控
首先我们先介绍下第一项。
- RBD块存储服务
我们的块存储服务主要给Openstack组件使用,分为如下几类:
- Glance镜像存储
- Nova instance数据存储
- Cinder volume存储
- Backup服务
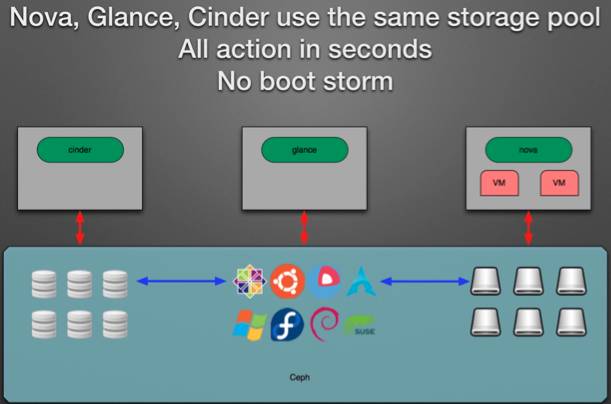
应用中,把Openstack的Glance组件image和Nova instance数据一起存储到Ceph集群中,可以很好的避免Openstack创建虚拟机时的image复制,并且利用Ceph RBD的snapshot功能,基本可以实现秒级创建Nova instance。
同样利用RBD的snapshot功能,可以有效的减少Cinder Volume,Nova instance的备份创建时间和空间占用。
另外因为Ceph底层是一个共享存储,所以基于此可以便利的实现Nova instance的热迁移功能,缩短了虚拟机热迁移导致的服务停顿时间。
整个应用场景如下图所示,Ceph作为了一个统一存储,对Openstack各个组件提供服务:
- CephFS提供服务器间数据共享
CephFS是基于Rados实现的PB级分布式文件系统,这里引入了一个新的组件MDS(Meta Data Server),它主要为兼容POSIX文件系统提供元数据,如目录和文件元数据。同时,MDS会将元数据也存在RADOS(Ceph Cluster)中。元数据存储在RADOS中后,元数据本身也达到了并行化,大大加强了文件操作的速度。需要注意的是MDS并不会直接为Client提供文件数据,而只是为Client提供元数据的操作。
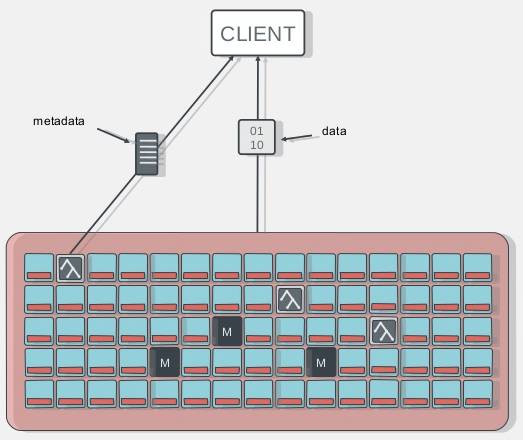
在我们的生产环境中,遇到过服务器间共享数据的需求。之前的思路可以通过NFS来实现,现在基于CephFS,可以轻松的满足需求。虽说我们用的版本Hammer中,Ceph官方没说CephFS完善到可用于生产环境,但也是经过大规模测试后的版本,据说在雅虎也有大规模使用的集群,另外我们共享的数据对可靠性没那么大要求,IO量也不是很大,所以CephFS已经能很好的满足我们的需求了。
最近Ceph发布的JEWEL版本是官方声称的第一个CephFS稳定版本,如果对CephFS有强烈需求的话,可以部署最新的JEWEL版本。
另外部署中最好使用单MDS的方式,虽说Ceph支持MDS集群和很多很酷的特性,比如负载均衡,动态子树迁移,故障恢复等,但MDS集群还不是Ceph官方的推荐。
- RADOSGW提供对象存储服务
RadosGW是基于Librados之上实现的,它主要提供兼容S3、Swfit的RESTful接口。同时RadosGW提供了Bucket的命名空间(类似于文件夹)和账户支持,并且具备用于账单目的使用记录。相对的,它增加了Http协议的负载。
RadosGW使得Ceph Cluster有了分布式对象存储的能力,如上面提到的Amazon S3和Swift等。企业也可以直接使用其作为数据存储或备份等用途。
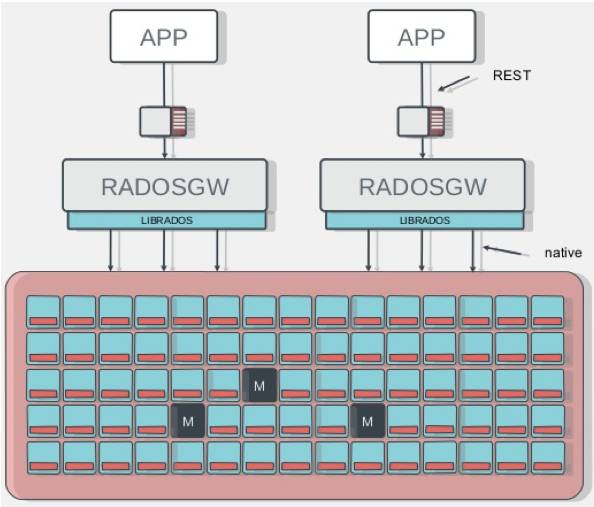
RADOSGW在云英主要应用于以下两方面:
1). RDS的数据备份存储
RDS服务是云英提供的一项的MySQL服务,我们保证了MySQL的高可用和性能,用户只需创建自己的RDS服务即可使用,而不用麻烦的自己搭建MySQL服务并配置其高可用等特性。
在RDS服务中,用户会有创建MySQL备份的需求,而这种备份是最适合对象存储的,我们自己实现了RDS的S3备份接口,把RDS的备份数据上传到兼容S3的RADOSGW中。这样使用统一的Ceph系统,我们就不需要再搭建一套Swift对象存储系统了,简化了公司的运维成本。
2). 对象存储服务
Object Storage Service是很重要的一项存储服务,越来越多的应用都开始使用便利的对象存储来存储数据。Openstack源生的对象存储服务系统是Swift,对比Ceph,Swift可以便利的搭建部署,但它也有自己的劣势,我们也不想同时维护两套存储系统,所以我们就选择RADOSGW提供兼容S3和Swift的对象存储服务。
- Ceph的性能测试
为了做到心中有数,我们需要在现有硬件配置条件下,测试Ceph的性能,看是否满足我们的期望。
结合网上的参考,Ceph性能测试可分为如下几类:
1). RADOS性能测试
rados bench 命令
rados load-gen 命令
2). rbd块设备性能测试
rbd bench-write 命令
3). fio工具测试:
fio + rbd ioengine 测试
fio + libaio 测试
在云英的应用中,Ceph主要提供的是rbd块设备,所以经过评估,我们选择了比较贴合实际应用的方式,使用fio + libaio的测试方法来测试虚拟机中云硬盘的性能。
为此我们写了一系列的测试脚本来自动化测试和分析测试结果,结合Ceph的参数优化,给出实际的性能参考。
当然,测试并不是一帆风顺的,测试中的我们也会遇到一些问题,也会做一些调整,这里分享下常见的几个注意事项:
1). 云硬盘需要先dd一遍后再测试
2). 每轮测试前清空虚拟机的缓存数据
3). 每轮测试前清空物理服务器的缓存数据
4). 每轮测试中通过iostat命令搜集磁盘负载数据
5). 测试获取顺序读写的bandwidth和随机读写的iops
6). 独占系统,防止产生干扰
7). 每轮测试后分析测试数据,找到系统评价和优化可能性
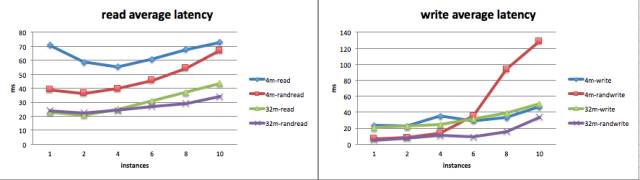
测试统计结果样本如下:
device: /dev/rbd1
ioengine: libaio size: 1000 runtime: 300
models: randread randwrite
mixread: 50
blocks: 4
iodepth: 2
numjobs: 1
processes: 1 2 4
rate: , ratemin:
rate_iops: 100, rate_iops_min:
host: 10.10.0.12 10.10.0.13 10.10.0.14 10.10.0.15
hosts,model,mixread,bs,iodepth,numjobs,r-bw(KB/s),r-iops,r-avglat(msec),w-bw(KB/s),w-iops,w-avglat(msec)
1,randread,/,4,2,1,1329.03,331,24.13,0,0,0
1,randwrite,/,4,2,1,0,0,0,1437.01,356,15.14
2,randread,/,4,2,1,3187.00,792,2.41,0,0,0
2,randwrite,/,4,2,1,0,0,0,3175.73,792,13.54
4,randread,/,4,2,1,6399.24,1591,1.72,0,0,0
4,randwrite,/,4,2,1,0,0,0,6344.70,1582,15.95
上述测试结果可以方便的导出到excel,制作成表格进行分析对比:
- Ceph的优化
我们前面说过,Ceph提供了很多的配置参数来允许用户订制自己的分布式存储系统,在赋予用户这个便利性的同时,也意味着如果用户想获取自己系统的最大性能时,必须自己进行分析调优。
Ceph是一个复杂的系统,官方的默认配置能保证系统基本运行,但是不能贴合用户实际需求,达到最大化用户物理系统性能的要求。虽说现在也已经有了一些朋友分享Ceph的配置参考和调优,但对每个用户来说都不是拿来主义。他们只是提供了一种优化的参考,具体的效果如何还需要用户贴合自己的实际测试结果来调整。
对于云英来说,我们的物理机配置是相当前卫的,用于Ceph系统的物理机硬件配置大致如下:
1). 200G+内存
2). 32核Intel Xeon处理器
3). 1:3的SSD和SATA配比,SSD分区做Journal,SATA盘做OSD
3). PCIE的存储卡提供超高性能存储Pool
4). 万兆网卡提供Ceph的Cluster Network通信
5). 千兆网卡提供Ceph的Public Network通信
参考网上朋友的Ceph配置和调优参数后,结合我们的经验和测试分析,我们做了适合自己的独特优化,对比各种调优项前后,很好的达到我们的要求。
依据我们的经验,可以在以下几个方面做Ceph的性能调优:
1). BIOS设置:
开启CPU的Hyper-Threading
关闭CPU节能
关闭NUMA
2). Linux参数调优
CPU设置为performance模式
调整内核的pid_max限制
调整SATA/SSD IO Scheduler
调整磁盘的read_ahead_kb大小
3). XFS相关
xfs mkfs options
xfs mount options
4). filestore调整
filestore fd cache size
filestore omap header cache size
filestore queue相关参数
filestore wbthrottle相关参数
object size
5). journal
性能高的SSD分区做journal
journal size > 5G
journal queue
6). osd相关
osd上PG总数限制
osd op threads
osd recovery threads
7). crushmap优化
给osd划分合理的pools
故障域切分,降低数据丢失概率
- Ceph的监控
对于一个大型系统来说,完善的监控很重要,我们不可能时刻靠人工来发现系统的问题。
针对Ceph系统,我们调研了很多种方案,主要有如下几种:
1). Ceph官方的Calamari(已一年多没有提交)
2). Intel的VSM
3). Ceph-Dash
4). Inkscope
5). 定制化的Diamond + Grafana
6). Ceph Collectd + Grafana
最后选择了适合我们的,方便我们扩展的一种。即:Diamond + Graphite + Grafana,下面介绍一下这些组件:
1). Diamond是一个客户端性能收集工具,Python编写,易与扩展。
2). Graphite是一个Python编写的企业级开源监控工具,采用django框架。
3). Grafana是功能齐全的度量仪表盘和图形编辑器,支持Graphite,InfluxDB和OpenTSDB。
部署后,我们可以在Grafana的前端订制我们自己的监控项,类似下图:
另外,Ceph进程的监控,集群状态的监控,我们通过自己写的脚本,完美的集成到Zabbix系统,实现了Ceph系统有问题的实时通知。
我们的脚本监控主要有如下几个方面:
1). Ceph状态和空间使用率的监控
2). OSD状态的监控和自动拉起
3). Monitor状态的监控和自动拉起
4). PG状态的监控和报警
5). Slow Requests的监控和报警
总之,Ceph是一个大型的完善的分布式系统,对它的研究和优化是一个持续的过程。
审核编辑:郭婷
-
云英谷科技亮相ICDT 2026国际显示技术大会2026-04-08 942
-
云英谷科技邀您相约ICDT 2026国际显示技术大会2026-04-02 503
-
基于DPU的Ceph存储解决方案2024-07-15 2759
-
请问怎样使用cephadm部署ceph集群呢?2024-01-16 3324
-
Ceph是什么?Ceph的统一存储方案简析2022-10-08 2127
-
基于全HDD aarch64服务器的Ceph性能调优实践总结2022-07-05 3712
-
docker-ceph在Docker容器中安装Ceph2022-05-13 1089
-
autobuild-ceph远程部署Ceph及自动构建Ceph2022-05-05 692
-
ceph-zabbix监控Ceph集群文件系统2022-04-26 785
-
ceph-cookbook Ceph的安装配置和管理2022-04-19 576
-
原生的ceph-iSCSI接入方式存在性能瓶颈2021-07-01 5028
-
如何快速认识Ceph/CephFS,最简单的方式就是快速应用它2019-09-20 6222
-
Ceph分布式存储中遇到的问题和解决办法2018-10-20 4831
全部0条评论

快来发表一下你的评论吧 !
