

细数线程池的10个坑
电子说
描述
前言
日常开发中,为了更好管理线程资源,减少创建线程和销毁线程的资源损耗,我们会使用线程池来执行一些异步任务。但是线程池使用不当,就可能会引发生产事故。今天跟大家聊聊线程池的10个坑。大家看完肯定会有帮助的~
线程池默认使用无界队列,任务过多导致OOM
线程创建过多,导致OOM
共享线程池,次要逻辑拖垮主要逻辑
线程池拒绝策略的坑
Spring内部线程池的坑
使用线程池时,没有自定义命名
线程池参数设置不合理
线程池异常处理的坑
使用完线程池忘记关闭
ThreadLocal与线程池搭配,线程复用,导致信息错乱。
1.线程池默认使用无界队列,任务过多导致OOM
JDK开发者提供了线程池的实现类,我们基于Executors组件,就可以快速创建一个线程池 。日常工作中,一些小伙伴为了开发效率,反手就用Executors新建个线程池。写出类似以下的代码:
public class NewFixedTest {
public static void main(String[] args) {
ExecutorService executor = Executors.newFixedThreadPool(10);
for (int i = 0; i < Integer.MAX_VALUE; i++) {
executor.execute(() -> {
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
//do nothing
}
});
}
}
}
使用newFixedThreadPool创建的线程池,是会有坑的,它默认是无界的阻塞队列,如果任务过多,会导致OOM问题。运行一下以上代码,出现了OOM。
Exception in thread "main" java.lang.OutOfMemoryError: GC overhead limit exceeded at java.util.concurrent.LinkedBlockingQueue.offer(LinkedBlockingQueue.java:416) at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1371) at com.example.dto.NewFixedTest.main(NewFixedTest.java:14)
这是因为newFixedThreadPool使用了无界的阻塞队列的LinkedBlockingQueue,如果线程获取一个任务后,任务的执行时间比较长(比如,上面demo代码设置了10秒),会导致队列的任务越积越多,导致机器内存使用不停飙升, 最终出现OOM。
看下newFixedThreadPool的相关源码,是可以看到一个无界的阻塞队列的,如下:
//阻塞队列是LinkedBlockingQueue,并且是使用的是无参构造函数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue());
}
//无参构造函数,默认最大容量是Integer.MAX_VALUE,相当于无界的阻塞队列的了
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
因此,工作中,建议大家自定义线程池 ,并使用指定长度的阻塞队列 。
2. 线程池创建线程过多,导致OOM
有些小伙伴说,既然Executors组件创建出的线程池newFixedThreadPool,使用的是无界队列,可能会导致OOM。那么,Executors组件还可以创建别的线程池,如newCachedThreadPool,我们用它也不行嘛?
我们可以看下newCachedThreadPool的构造函数:
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue());
}
它的最大线程数是Integer.MAX_VALUE。大家应该意识到使用它,可能会引发什么问题了吧。没错,如果创建了大量的线程也有可能引发OOM!
笔者在以前公司,遇到这么一个OOM问题:一个第三方提供的包,是直接使用new Thread实现多线程的。在某个夜深人静的夜晚,我们的监控系统报警了。。。这个相关的业务请求瞬间特别多,监控系统告警OOM了。
所以我们使用线程池的时候,还要当心线程创建过多,导致OOM问题。大家尽量不要使用newCachedThreadPool,并且如果自定义线程池时,要注意一下最大线程数。
3. 共享线程池,次要逻辑拖垮主要逻辑
要避免所有的业务逻辑共享一个线程池。比如你用线程池A来做登录异步通知,又用线程池A来做对账。如下图:
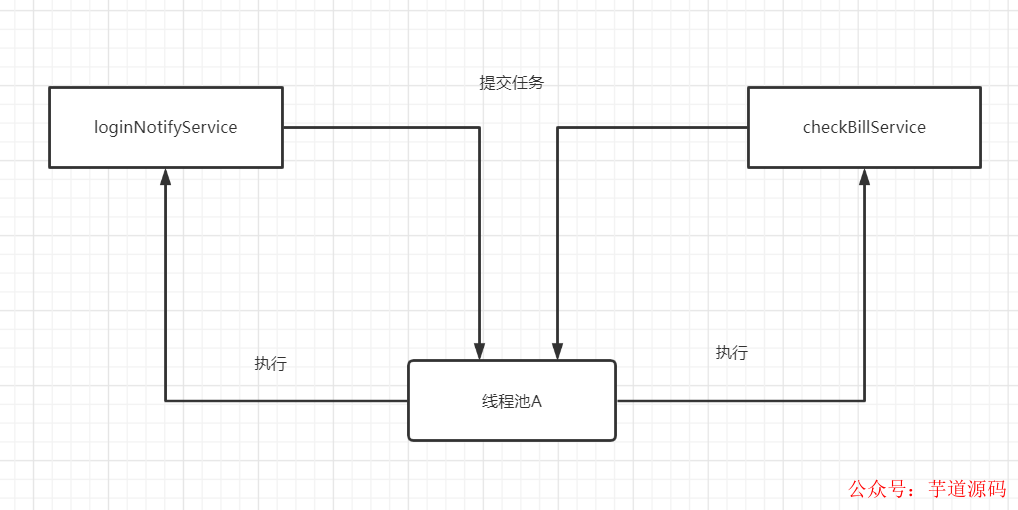
如果对账任务checkBillService响应时间过慢,会占据大量的线程池资源,可能直接导致没有足够的线程资源去执行loginNotifyService的任务,最后影响登录。就这样,因为一个次要服务,影响到重要的登录接口,显然这是绝对不允许的。因此,我们不能将所有的业务一锅炖,都共享一个线程池,因为这样做,风险太高了,犹如所有鸡蛋放到一个篮子里。应当做线程池隔离 !
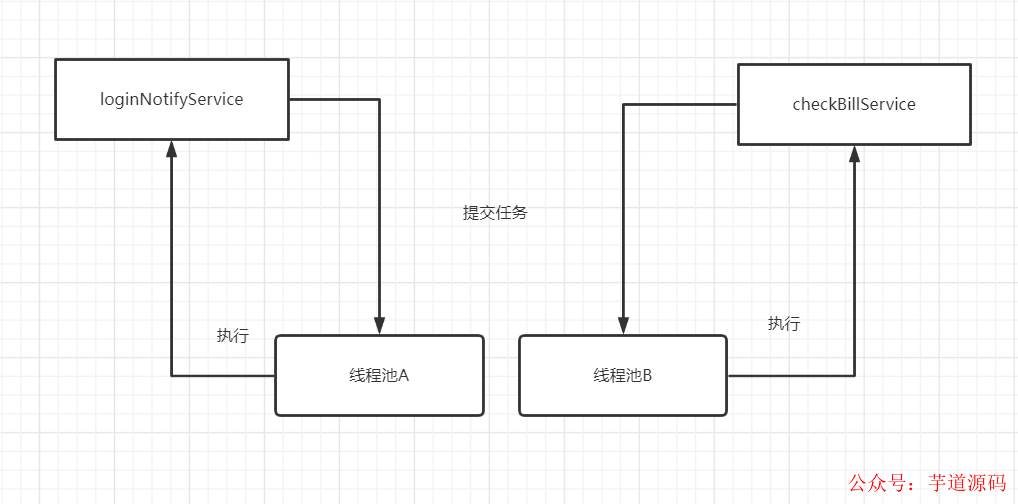
4. 线程池拒绝策略的坑,使用不当导致阻塞
我们知道线程池主要有四种拒绝策略,如下:
AbortPolicy: 丢弃任务并抛出RejectedExecutionException异常。(默认拒绝策略)
DiscardPolicy:丢弃任务,但是不抛出异常。
DiscardOldestPolicy:丢弃队列最前面的任务,然后重新尝试执行任务。
CallerRunsPolicy:由调用方线程处理该任务。
如果线程池拒绝策略设置不合理,就容易有坑。我们把拒绝策略设置为DiscardPolicy或DiscardOldestPolicy并且在被拒绝的任务,Future对象调用get()方法,那么调用线程会一直被阻塞。
我们来看个demo:
public class DiscardThreadPoolTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
// 一个核心线程,队列最大为1,最大线程数也是1.拒绝策略是DiscardPolicy
ThreadPoolExecutor executorService = new ThreadPoolExecutor(1, 1, 1L, TimeUnit.MINUTES,
new ArrayBlockingQueue<>(1), new ThreadPoolExecutor.DiscardPolicy());
Future f1 = executorService.submit(()-> {
System.out.println("提交任务1");
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Future f2 = executorService.submit(()->{
System.out.println("提交任务2");
});
Future f3 = executorService.submit(()->{
System.out.println("提交任务3");
});
System.out.println("任务1完成 " + f1.get());// 等待任务1执行完毕
System.out.println("任务2完成" + f2.get());// 等待任务2执行完毕
System.out.println("任务3完成" + f3.get());// 等待任务3执行完毕
executorService.shutdown();// 关闭线程池,阻塞直到所有任务执行完毕
}
}
运行结果:一直在运行中。。。
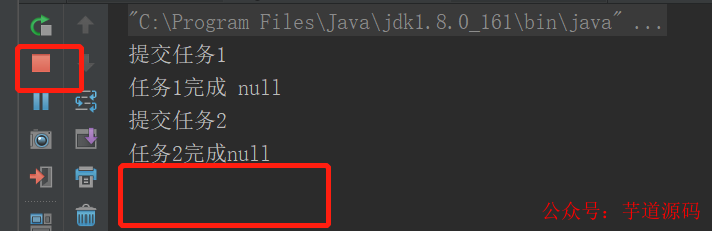
这是因为DiscardPolicy拒绝策略,是什么都没做,源码如下:
public static class DiscardPolicy implements RejectedExecutionHandler {
/**
* Creates a {@code DiscardPolicy}.
*/
public DiscardPolicy() { }
/**
* Does nothing, which has the effect of discarding task r.
*/
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
}
}
我们再来看看线程池 submit 的方法:
public Future submit(Runnable task) {
if (task == null) throw new NullPointerException();
//把Runnable任务包装为Future对象
RunnableFuture ftask = newTaskFor(task, null);
//执行任务
execute(ftask);
//返回Future对象
return ftask;
}
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; //Future的初始化状态是New
}
我们再来看看Future的get() 方法
//状态大于COMPLETING,才会返回,要不然都会阻塞等待
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)
s = awaitDone(false, 0L);
return report(s);
}
FutureTask的状态枚举
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
阻塞的真相水落石出啦,FutureTask的状态大于COMPLETING才会返回,要不然都会一直阻塞等待 。又因为拒绝策略啥没做,没有修改FutureTask的状态,因此FutureTask的状态一直是NEW,所以它不会返回,会一直等待。
这个问题,可以使用别的拒绝策略,比如CallerRunsPolicy,它让主线程去执行拒绝的任务,会更新FutureTask状态。如果确实想用DiscardPolicy,则需要重写DiscardPolicy的拒绝策略。
温馨提示 ,日常开发中,使用 Future.get() 时,尽量使用带超时时间的 ,因为它是阻塞的。
future.get(1, TimeUnit.SECONDS);
难道使用别的拒绝策略,就万无一失了嘛? 不是的,如果使用CallerRunsPolicy拒绝策略,它表示拒绝的任务给调用方线程用,如果这是主线程,那会不会可能也导致主线程阻塞 呢?总结起来,大家日常开发的时候,多一份心眼吧,多一点思考吧。
5. Spring内部线程池的坑
工作中,个别开发者,为了快速开发,喜欢直接用spring的@Async,来执行异步任务。
@Async
public void testAsync() throws InterruptedException {
System.out.println("处理异步任务");
TimeUnit.SECONDS.sleep(new Random().nextInt(100));
}
Spring内部线程池,其实是SimpleAsyncTaskExecutor,这玩意有点坑,它不会复用线程的 ,它的设计初衷就是执行大量的短时间的任务。有兴趣的小伙伴,可以去看看它的源码:
/**
* {@link TaskExecutor} implementation that fires up a new Thread for each task,
* executing it asynchronously.
*
* Supports limiting concurrent threads through the "concurrencyLimit"
* bean property. By default, the number of concurrent threads is unlimited.
*
*
NOTE: This implementation does not reuse threads! Consider a
* thread-pooling TaskExecutor implementation instead, in particular for
* executing a large number of short-lived tasks.
*
* @author Juergen Hoeller
* @since 2.0
* @see #setConcurrencyLimit
* @see SyncTaskExecutor
* @see org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor
* @see org.springframework.scheduling.commonj.WorkManagerTaskExecutor
*/
@SuppressWarnings("serial")
public class SimpleAsyncTaskExecutor extends CustomizableThreadCreator implements AsyncListenableTaskExecutor, Serializable {
......
}
也就是说来了一个请求,就会新建一个线程!大家使用spring的@Async时,要避开这个坑,自己再定义一个线程池。正例如下:
@Bean(name = "threadPoolTaskExecutor")
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor executor=new ThreadPoolTaskExecutor();
executor.setCorePoolSize(5);
executor.setMaxPoolSize(10);
executor.setThreadNamePrefix("tianluo-%d");
// 其他参数设置
return new ThreadPoolTaskExecutor();
}
6. 使用线程池时,没有自定义命名
使用线程池时,如果没有给线程池一个有意义的名称,将不好排查回溯问题。这不算一个坑吧,只能说给以后排查埋坑 ,哈哈。我还是单独把它放出来算一个点,因为个人觉得这个还是比较重要的。反例如下:
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue(20));
executorOne.execute(()->{
System.out.println("关注:芋道源码");
throw new NullPointerException();
});
}
}
运行结果:
Exception in thread "pool-1-thread-1" java.lang.NullPointerException at com.example.dto.ThreadTest.lambda$main$0(ThreadTest.java:17) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)
可以发现,默认打印的线程池名字是pool-1-thread-1,如果排查问题起来,并不友好。因此建议大家给自己线程池自定义个容易识别的名字。其实用CustomizableThreadFactory即可,正例如下:
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue(20),new CustomizableThreadFactory("Tianluo-Thread-pool"));
executorOne.execute(()->{
System.out.println("关注:芋道源码");
throw new NullPointerException();
});
}
}
7. 线程池参数设置不合理
线程池最容易出坑的地方,就是线程参数设置不合理。比如核心线程设置多少合理,最大线程池设置多少合理等等。当然,这块不是乱设置的,需要结合具体业务 。
比如线程池如何调优,如何确认最佳线程数?
最佳线程数目 = ((线程等待时间+线程CPU时间)/线程CPU时间 )* CPU数目
我们的服务器CPU核数为8核,一个任务线程cpu耗时为20ms,线程等待(网络IO、磁盘IO)耗时80ms,那最佳线程数目:( 80 + 20 )/20 * 8 = 40。也就是设置 40个线程数最佳。
8. 线程池异常处理的坑
我们来看段代码:
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue(20),new CustomizableThreadFactory("Tianluo-Thread-pool"));
for (int i = 0; i < 5; i++) {
executorOne.submit(()->{
System.out.println("current thread name" + Thread.currentThread().getName());
Object object = null;
System.out.print("result# " + object.toString());
});
}
}
}
按道理,运行这块代码应该抛空指针异常 才是的,对吧。但是,运行结果却是这样的;
current thread nameTianluo-Thread-pool1 current thread nameTianluo-Thread-pool2 current thread nameTianluo-Thread-pool3 current thread nameTianluo-Thread-pool4 current thread nameTianluo-Thread-pool5
这是因为使用submit提交任务,不会把异常直接这样抛出来。大家有兴趣的话,可以去看看源码。可以改为execute方法执行,当然最好就是try...catch捕获,如下:
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue(20),new CustomizableThreadFactory("Tianluo-Thread-pool"));
for (int i = 0; i < 5; i++) {
executorOne.submit(()->{
System.out.println("current thread name" + Thread.currentThread().getName());
try {
Object object = null;
System.out.print("result# " + object.toString());
}catch (Exception e){
System.out.println("异常了"+e);
}
});
}
}
}
其实,我们还可以为工作者线程设置UncaughtExceptionHandler,在uncaughtException方法中处理异常。大家知道这个坑就好啦。
9. 线程池使用完毕后,忘记关闭
如果线程池使用完,忘记关闭的话,有可能会导致内存泄露 问题。所以,大家使用完线程池后,记得关闭一下。同时,线程池最好也设计成单例模式,给它一个好的命名,以方便排查问题。
public class ThreadTest {
public static void main(String[] args) throws Exception {
ThreadPoolExecutor executorOne = new ThreadPoolExecutor(5, 5, 1,
TimeUnit.MINUTES, new ArrayBlockingQueue(20), new CustomizableThreadFactory("Tianluo-Thread-pool"));
executorOne.execute(() -> {
System.out.println("关注:芋道源码");
});
//关闭线程池
executorOne.shutdown();
}
}
10. ThreadLocal与线程池搭配,线程复用,导致信息错乱。
使用ThreadLocal缓存信息,如果配合线程池一起,有可能出现信息错乱的情况。先看下一下例子:
private static final ThreadLocalcurrentUser = ThreadLocal.withInitial(() -> null); @GetMapping("wrong") public Map wrong(@RequestParam("userId") Integer userId) { //设置用户信息之前先查询一次ThreadLocal中的用户信息 String before = Thread.currentThread().getName() + ":" + currentUser.get(); //设置用户信息到ThreadLocal currentUser.set(userId); //设置用户信息之后再查询一次ThreadLocal中的用户信息 String after = Thread.currentThread().getName() + ":" + currentUser.get(); //汇总输出两次查询结果 Map result = new HashMap(); result.put("before", before); result.put("after", after); return result; }
按理说,每次获取的before应该都是null,但是呢,程序运行在 Tomcat 中,执行程序的线程是Tomcat的工作线程,而Tomcat的工作线程是基于线程池 的。
线程池会重用固定的几个线程 ,一旦线程重用,那么很可能首次从 ThreadLocal 获取的值是之前其他用户的请求遗留的值。这时,ThreadLocal 中的用户信息就是其他用户的信息。
把tomcat的工作线程设置为1
server.tomcat.max-threads=1
用户1,请求过来,会有以下结果,符合预期:
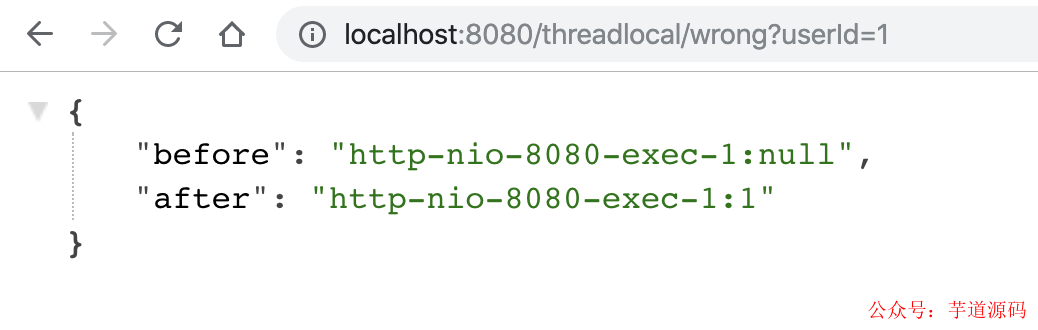
用户2请求过来,会有以下结果,「不符合预期」:
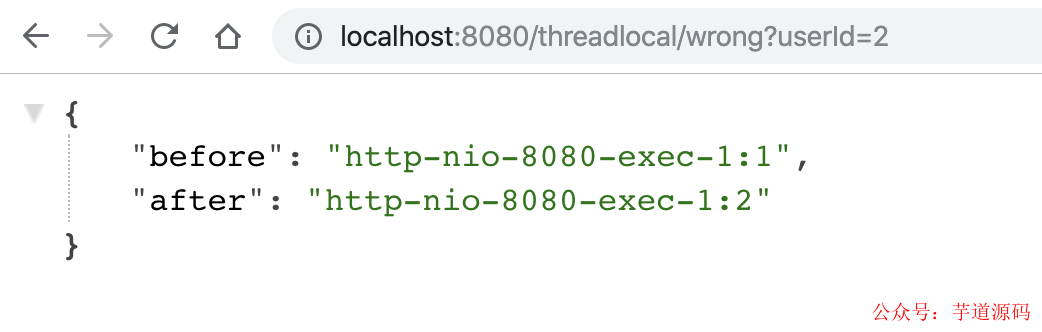
因此,使用类似 ThreadLocal 工具来存放一些数据时,需要特别注意在代码运行完后,显式地去清空设置的数据,正例如下:
@GetMapping("right")
public Map right(@RequestParam("userId") Integer userId) {
String before = Thread.currentThread().getName() + ":" + currentUser.get();
currentUser.set(userId);
try {
String after = Thread.currentThread().getName() + ":" + currentUser.get();
Map result = new HashMap();
result.put("before", before);
result.put("after", after);
return result;
} finally {
//在finally代码块中删除ThreadLocal中的数据,确保数据不串
currentUser.remove();
}
}
审核编辑:刘清
-
什么是动态线程池?动态线程池的简单实现思路2024-02-28 1849
-
线程池七大核心参数执行顺序2023-12-04 2153
-
线程池基本概念与原理2023-11-10 1828
-
Spring 的线程池应用2023-10-13 1625
-
Java中的线程池包括哪些2023-10-11 1651
-
线程池的两个思考2023-09-30 3868
-
线程池的线程怎么释放2023-07-31 2897
-
Java线程池核心原理2023-04-21 1785
-
多线程之线程池2023-02-28 1914
-
基于Nacos的简单动态化线程池实现2023-01-06 1548
-
线程池是如何实现的2022-02-28 1577
-
如何正确关闭线程池2021-09-29 10808
-
java自带的线程池方法2017-09-27 898
全部0条评论

快来发表一下你的评论吧 !
