

通用处理器的历史和发展 通用处理器是否可行?
处理器/DSP
描述
编者按
随着ChatGPT的火爆,AGI(Artificial General Intelligence,通用人工智能)逐渐看到了爆发的曙光。短短一个月的时间,所有的巨头都快速反应,在AGI领域“重金投入,不计代价”。
AGI是基于大模型的通用智能;相对的,之前的各种基于中小模型的、用于特定应用场景的智能可以称之为专用智能。
那么,我们可以回归到一个大家经常讨论的话题:向左(专用)还是向右(通用)?在芯片领域,大家针对特定的场景开发了很多专用的芯片。是否可以类似AGI的发展,开发足够通用的芯片,既能够覆盖几乎所有场景,还能够功能和性能极度强大?
1 AGI发展综述
1.1 AGI的概念
AGI通用人工智能,也称强人工智能(Strong AI),指的是具备与人类同等甚至超越人类的智能,能表现出正常人类所具有的所有智能行为。
ChatGPT是大模型发展量变到质变的结果,ChatGPT具备了一定的AGI能力。随着ChatGPT的成功,AGI已经成为全球竞争的焦点。
与基于大模型发展的AGI对应的,传统的基于中小模型的人工智能,也可以称为弱人工智能。它聚焦某个相对具体的业务方面,采用相对中小参数规模的模型,中小规模的数据集,然后实现相对确定、相对简单的人工智能场景应用。
1.2 AGI特征之一:涌现
“涌现”,并不是一个新概念。凯文·凯利在他的《失控》中就提到了“涌现”,这里的“涌现”,指的是众多个体的集合会涌现出超越个体特征的某些更高级的特征。
在大模型领域,“涌现”指的是,当模型参数突破某个规模时,性能显著提升,并且表现出让人惊艳的、意想不到的能力,比如语言理解能力、生成能力、逻辑推理能力等等。
对外行(比如作者自己)来说,涌现能力,可以简单的用“量变引起质变”来解释:随着模型参数的不断增加,终于突破了某个临界值,从而引起了质的变化,让大模型产生了许多更加强大的、新的能力。
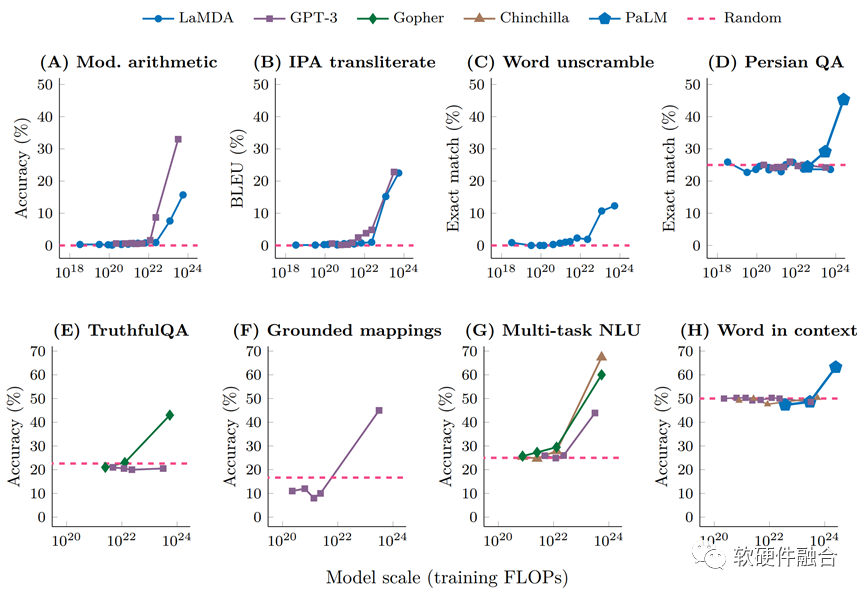
如果想详细了解大模型“涌现”能力的详细分析,可以参阅谷歌的论文《Emergent Abilities of Large Language Models》。
当然,目前,大模型发展还是非常新的领域,对“涌现”能力的看法,也有不同的声音。例如斯坦福大学的研究者对大语言模型“涌现”能力的说法提出了质疑,认为其是人为选择度量方式的结果。详见论文《Are Emergent Abilities of Large Language Models a Mirage?》。
1.3 AGI特征之二:多模态
每一种信息的来源或者形式,都可以称为一种模态。例如,人有触觉、听觉、视觉等;信息的媒介有文字、图像、语音、视频等;各种类型的传感器,如摄像头、雷达、激光雷达等。多模态,顾名思义,即从多个模态表达或感知事物。而多模态机器学习,指的是从多种模态的数据中学习并且提升自身的算法。
传统的中小规模AI模型,基本都是单模态的。比如专门研究语言识别、视频分析、图形识别以及文本分析等单个模态的算法模型。
基于Transformer的chatGPT出现之后,之后的AI大模型基本上都逐渐实现了对多模态的支持:
首先,可以通过文本、图像、语音、视频等多模态的数据学习;
并且,基于其中一个模态学习到的能力,可以应用在另一个模态的推理;
此外,不同模态数据学习到的能力还会融合,形成一些超出单个模态学习能力的新的能力。
多模态的划分是我们人为进行划分的,多种模态的数据里包含的信息,都可以被AGI统一理解,并转换成模型的能力。在中小模型中,我们人为割裂了很多信息,从而限制的AI算法的智能能力(此外,模型的参数规模和模型架构,也对智能能力有很大影响)。
1.4 AGI特征之三:通用性
从2012年深度学习走入我们的视野,用于各类特定应用场景的AI模型就如雨后春笋般的出现。比如车牌识别、人脸识别、语音识别等等,也包括一些综合性的场景,比如自动驾驶、元宇宙场景等。每个场景都有不同的模型,并且同一个场景,还有很多公司开发的各种算法和架构各异的模型。可以说,这一时期的AI模型,是极度碎片化的。
而从GPT开始,让大家看到了通用AI的曙光。最理想的AI模型:可以输入任何形式、任何场景的训练数据,可以学习到几乎“所有”的能力,可以做任何需要做的决策。当然,最关键的,基于大模型的AGI的智能能力远高于传统的用于特定场合的AI中小模型。
完全通用的AI出现以后,一方面我们可以推而广之,实现AGI+各种场景;另一方面,由于算法逐渐确定,也给了AI加速持续优化的空间,从而可以持续不断的优化AI算力。算力持续提升,反过来又会推动模型向更大规模参数演进升级。
2 专用和通用的关系
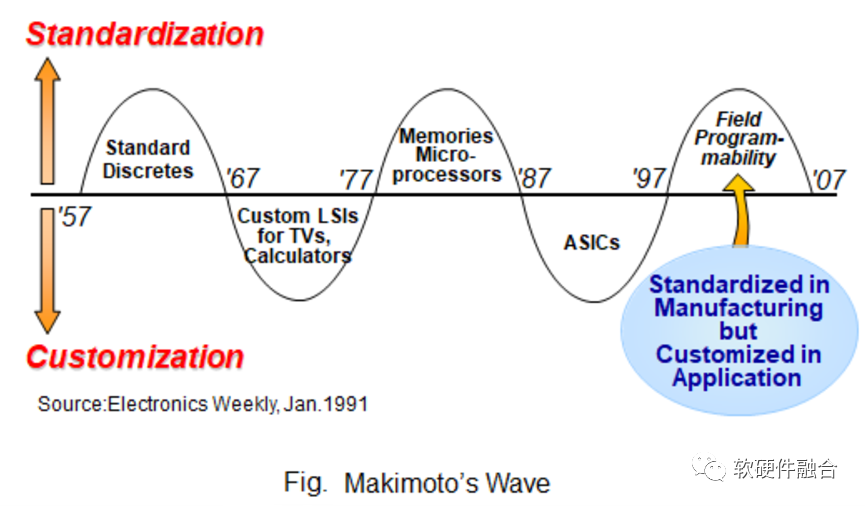
牧本波动(Makimoto's Wave)是一个与摩尔定律类似的电子行业发展规律,它认为集成电路有规律的在“通用”和“专用”之间变化,循环周期大约为10年。也因此,芯片行业的很多人认为,“通用”和“专用”是对等的,是一个天平的两边。设计研发的产品,偏向通用或偏向专用,是基于客户场景需求,对产品实现的权衡。
但从AGI的发展来看,基于大模型的AGI和传统的基于中小模型的专用人工智能相比,并不是对等的两端左右权衡的问题,而是从低级智能升级到高级智能的问题。我们再用这个观点重新来审视一下计算芯片的发展历史:
专用集成电路ASIC是贯穿集成电路发展的一直存在的一种芯片架构形态;
在CPU出现之前,几乎所有的芯片都是ASIC;但在CPU出现之后,CPU迅速的取得了芯片的主导地位;CPU的ISA包含的是加减乘除等最基本的指令,也因此CPU是完全通用的处理器。
GPU最开始的定位是专用的图形处理器;自从GPU改造成了定位并行计算平台的GP-GPU之后,辅以帮助用户开发的CUDA的加持,从而成就了GPU在异构时代的王者地位。
随着系统复杂度的增加,不同客户系统的差异性和客户系统的快速迭代,ASIC架构的芯片,越来越不适合。行业逐渐兴起了DSA的浪潮,DSA可以理解成ASIC向通用可编程能力的一个回调,DSA是具有一定编程能力的ASIC。ASIC面向具体场景和固化的业务逻辑,而DSA则面向一个领域的多种场景,其业务逻辑部分可编程。即便如此,在AI这种对性能极度敏感的场景,相比GPU,AI-DSA都不够成功,本质原因就在于AI场景快速变化,但AI-DSA芯片迭代周期过长。
从长期发展的角度看,专用芯片的发展,是在给通用芯片探路。通用芯片,会从各类专用计算中析取出更加本质的足够通用的计算指令或事务,然后把之融合到通用芯片的设计中去。比如:
CPU完全通用,但性能较弱,所以就通过向量和张量等协处理器的方式,实现硬件加速和性能提升。
CPU的加速能力有限,于是出现了GPU。GPU是通用并行加速平台。GPU仍然不是性能最高的加速方式,也因此,出现了Tensor Core加速的方式。
Tensor Core的方式,仍然没有完全释放计算的性能。于是,完全独立的DSA处理器出现。
智能手机是通用和专用的一个经典案例:在智能手机出现之前,各种各样的手持设备,琳琅满目;智能手机出现之后,这些功能专用的设备,就逐渐消失在历史长河中。
通用和专用,并不是,供设计者权衡的,对等的两个方面;从专用到通用,是低级到高级的过程。短期来看,通用和专用是交替前行;但从更长期的发展来看,专用是暂时的,通用是永恒的。
3 通用处理器是否可行?
CPU是通用的处理器,但随着摩尔定律失效,CPU已经难堪大用。于是,又开始了一轮专用芯片设计的大潮:2017年,图灵奖获得者John Hennessy和David Patterson就提出“体系结构的黄金年代”,认为未来一定时期,是专有处理器DSA发展的重大机会。
但这5-6年的实践证明,以DSA为代表的专用芯片黄金年代的成色不足。反而在AI大模型的加持之下,成就了通用GPU的黄金年代。
当然,GPU也并不完美:GPU的性能即将,如CPU一样,到达上限。目前,支持GPT大模型的GPU集群需要上万颗GPU处理器,一方面整个集群的效率低下,另一方面集群的建设和运行成本都非常的高昂。
是否可以设计更加优化的处理器,既具有通用处理器的特征,尽可能的“放之四海而皆准”,又可以更高效率更高性能?这里我们给一些观点:
我们可以把计算机上运行的系统拆分为若干个工作任务,如一些软件进程或相近软件进程的组合可以看做是一个工作任务;
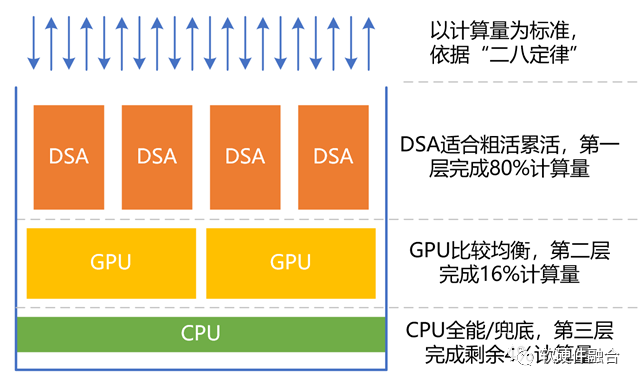
广泛存在的二八定律:系统中的工作任务,并不是完全随机的,很多工作业务是相对确定的,比如虚拟化、网络、存储、安全、数据库、文件系统,甚至人工智能推理,等等;并且,即使应用层的比较随机的计算任务,仍然会包含大量确定性的计算成分,例如一些应用包含安全、视频图形处理、人工智能等相对确定的计算部分。
我们把处理器(引擎)按照性能效率和灵活性能力,简单的分为三个类型:CPU、GPU和DSA。
类似“塔防游戏”,依据二八定律,把80%的计算任务交给DSA完成,把16%的工作任务交给GPU来完成,CPU负责剩余4%的其他工作。CPU很重要的工作是兜底。
依据性能/灵活性的特征,匹配到最合适的处理器计算引擎,可以在实现足够通用的情况下,实现最极致的性能。
4 通用处理器的历史和发展
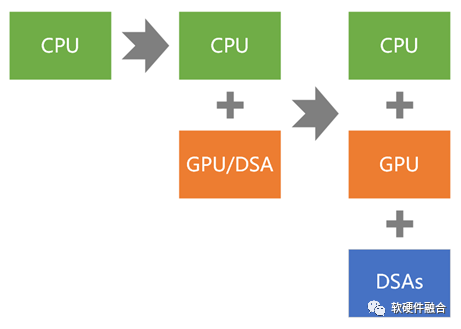
如果我们以通用计算为准,计算架构的演进,可以简单的划分为三个阶段,即从同构走向超异构,再持续不断的走向超异构:
第一代通用计算:CPU同构。
第二代通用计算:CPU+GPU异构。
第三代(新一代)通用计算:CPU+GPU+DSAs的超异构。
4.1 第一代通用计算:CPU同构
Intel发明了CPU,这是第一代的通用计算。第一代通用计算,成就了Intel在2000前后持续近30年的霸主地位。
CPU标量计算的性能非常弱,也因此,CPU逐渐引入向量指令集处理的AVX协处理器以及矩阵指令集的AMX协处理器等复杂指令集,不断的优化CPU的性能和计算效率,不断的拓展CPU的生存空间。
4.2 第二代通用计算:CPU+GPU异构
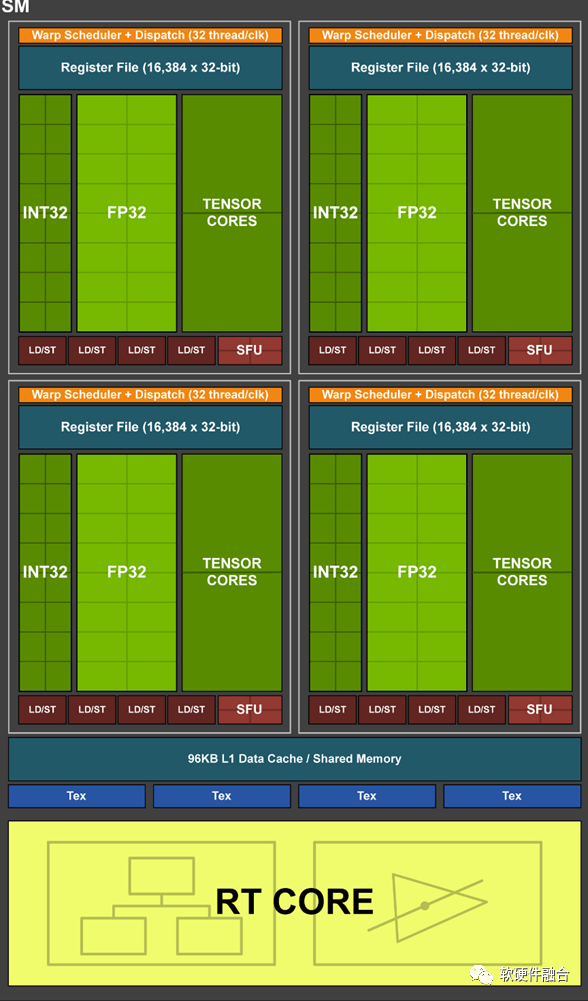
CPU协处理器的做法,本身受CPU原有架构的约束,其性能存在上限。在一些相对较小规模的加速计算场景,勉强可用。但在AI等大规模加速计算场景,因为其性能上限较低并且性能效率不高,不是很合适。因此,需要完全独立的、更加重量的加速处理器。
GPU是通用并行计算平台,是最典型的加速处理器。GPU计算需要有Host CPU来控制和协同,因此具体的实现形态是CPU+GPU的异构计算架构。
NVIDIA发明了GP-GPU,以及提供了CUDA框架,促进了第二代通用计算的广泛应用。随着AI深度学习和大模型的发展,GPU成为最炙手可热的硬件平台,也成就了NVIDIA万亿市值(超过Intel、AMD和高通等芯片巨头的市值总和)。
当然,GPU内部的数以千计的CUDA core,本质上是更高效的CPU小核,因此,其性能效率仍然存在上升的空间。于是,NVIDIA开发了Tensor加速核心来进一步优化张量计算的性能和效率。
4.3 第三代(面向未来的)通用计算:CPU+GPU+DSAs超异构
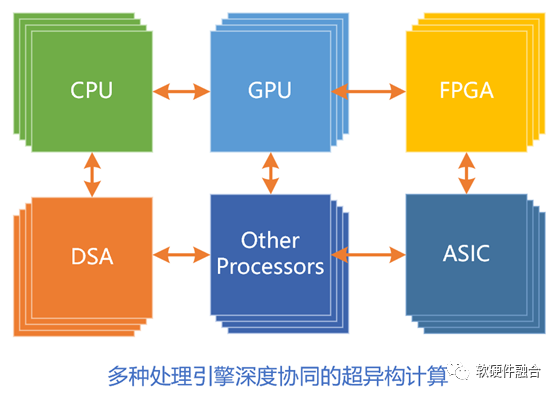
技术发展,永无止境。第三代通用计算,即多种异构融合的超异构计算,面向未来更大算力需求场景的挑战:
首先,有三个层次的独立处理引擎。即CPU、GPU和DSA。(相应的,第一代CPU只有一个,第二代异构计算有两个。)
多种加速处理引擎,都是和CPU组成CPU+XPU的异构计算架构。
超异构不是简单的多种异构计算的集成,而是多种异构计算系统的,从软件到硬件层次的,深度融合。
超异构计算,要想成功,必须要实现足够好的通用性。如果不考虑通用性,超异构架构里的相比以往更多的计算引擎,会使得架构碎片化问题更加严重。软件人员无所适从,超异构就不会成功。
编辑:黄飞
-
多屏一云应用兴起 通用处理器发展势不可当2013-01-25 1290
-
DSP处理器与通用处理器的比较2021-09-03 2099
-
将DSP和ML功能融合到低功耗通用处理器中2023-08-23 508
-
多媒体应用处理器的原理和应用2009-12-01 710
-
什么是通用处理器2010-01-12 5286
-
流水线操作,应用处理器,应用处理器的结构和原理是什么?2010-03-26 1468
-
高性能通用处理器中的漏电功耗优化2011-09-26 763
-
寒武纪科技将发布深度学习专用处理器2017-10-11 1386
-
Tachyum的4 Exaflops AI培训系统基于Tachyum Prodigy通用处理器芯片2020-09-10 2756
-
应用处理器芯片行业科普2022-01-25 960
-
什么是专用处理器?专用处理器的设计方法和工具介绍2023-07-17 2445
-
航芯通用处理器BOOT下载工具使用说明_v12022-09-02 852
-
burster波司特通用处理器控制器维修-控制器功率放大器故障检修2023-11-24 1594
-
100%自主研发!龙芯中科新一代通用处理器发布2023-12-01 2191
-
走进北大 | 算能RISC-V通用处理器设计成功开课2024-12-06 1885
全部0条评论

快来发表一下你的评论吧 !
