

数据中心到数据中心的复制流程
描述
每家公司都需要为所有重要系统制定灾难恢复计划。从像在某个容器中运行的单个进程这样的小单元到最大的分布式架构都是如此。特别是对于数据库,这通常涉及容错、冗余、定期备份和应急计划的混合。数据存储越大,制定好的策略就越困难。
因此,希望能够在一个数据中心运行分布式数据库,并以某种方式将所有事务复制到另一个数据中心。通常,事务日志通过网络传送,以便在另一个数据中心的另一个相同系统中复制所有内容。一些分布式数据存储具有对多数据中心感知的内置支持,并且可以以全自动方式在数据中心之间复制。
ArangoDB3.3通过引入多数据中心支持向前迈出了进化的一步,即数据中心到数据中心的复制。我们的解决方案是异步的,并且可以扩展到任意集群大小,前提是您的数据中心之间的网络链接有足够的带宽。它是容错的,没有单点故障,并且包含许多用于在生产场景中监控的指标。
它能做什么
此功能允许您在两个不同的数据中心A和B中运行两个ArangoDB集群,并设置从A到B的异步复制。这意味着数据中心A中的集群A可以照常用于读取和写入操作,所有更改为数据通过网络复制到数据中心B中的另一个集群B。复制是异步的,也就是说,更改会在短暂的延迟后出现在另一端,通常在几秒钟内。
在数据中心A发生灾难(例如网络连接完全中断)的情况下,可以快速停止复制并开始使用数据中心B中的集群B作为集群A的替代品。稍后,当灾难结束时,可以要么使用集群A作为集群B的异步副本,要么切换回A并继续复制到集群A。
挑战
在本节中,我们不想让您厌烦技术细节,我们将在适当的时候发布一份白皮书。相反,我们想强调这种方法的挑战,并概述我们为克服这些挑战而采取的措施。
单个ArangoDB集群是一个具有良好水平可扩展性的分布式系统。数据容量和查询性能(读取和写入)都与使用的服务器数量呈线性关系。自动分片导致数据的实际更改同时发生在所有服务器的各处。特别是,这意味着——按照设计——没有一个地方可以建立所有变化的总顺序。也就是说,我们正在处理大量数据同时发生更新的分布式混乱。变化率可能会有很大差异,我们将不得不处理大量的写入突发。
同时,ArangoDB集群是容错的。例如,如果数据中心中的单个服务器发生故障,ArangoDB集群可以轻松容忍这种损失,并且假设用户已将复制因子设置为至少2,既不会丢失任何数据,也不会损失可用性. 系统只需切换到使用另一台服务器,重新分配数据并继续前进,而不会影响查询性能。因此,任何适当的复制解决方案都必须满足集群A中的这些透明故障转移。
另一方面,安全问题和防火墙维护意味着我们不能轻易地让许多不同的进程与另一个数据中心中的许多不同进程通信,但同样,我们也不能轻易地通过两个进程之间的单个网络连接的瓶颈移动所有更新在不同的数据中心。
显然,整个复制系统是分布式系统的分布式系统,因此必须具有可扩展性和容错性,没有单点故障。
所有这些挑战都决定并影响了我们解决方案的设计。
怎么运行的
在数据中心A中,ArangoDB集群A照常运行,无需修改其代码库和API,并提供其通常的负载。同样,在数据中心B中,第二个ArangoDB集群B已部署,但最初处于空闲状态。
在这两个数据中心中,我们部署了一个Kafka消息代理,这是一个标准的高性能和容错队列系统,能够在其消息队列中缓冲大量数据。单个队列在Kafka中称为“主题”。这些主题可能会从其他数据中心消费。Kafka有一定的保证,因此在出现网络问题、个别中断等情况时,不会丢失任何消息,并且远程数据中心将始终保持一致的状态。
此外,在每个数据中心,都有几个名为“ArangoDBSyncMaster”的程序实例。在每个数据中心,SyncMasters选举一个领导者,该领导者与另一个数据中心的SyncMaster对话以组织复制。“组织”在这里意味着它计划必须在两个数据中心中执行的单个任务以进行复制。本质上,必须复制元信息,例如存在哪些数据库、集合和用户,以及分片集合中的实际数据。
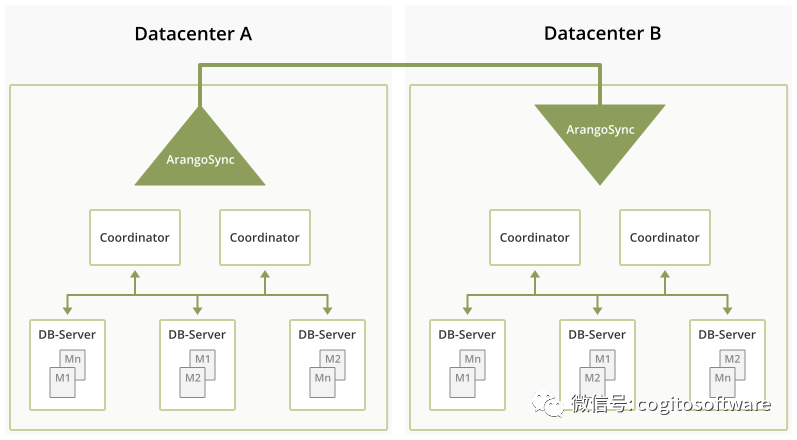
在每个数据中心,领先的SyncMaster指挥一小群SyncWorker,它们执行实际的复制任务。例如,对于一个集合的每个分片,在数据中心A中有一个“发送分片”任务,在数据中心B有一个“接收分片”任务,所有这些分片都由SyncMaster分配给某个SyncWorker。
这些任务负责初始增量同步阶段(运行我们在ArangoDB中已有的现有分片同步协议),以及后期更新阶段,其中对分片的所有更新都复制到另一个数据中心(使用WALtailing in数据中心A)。
数据流如下:它从ArangoDB集群的某个DBserver开始,到达数据中心A中的一个SyncWorker,然后进入数据中心A中的Kafka。从那里它将被写入它的数据中心B的SyncWorker使用进入数据中心B中的协调器。显然,有一些控制消息以相反的方向流动。这些控制消息将由数据中心A从数据中心B的Kafka服务器中获取。
这对管理员来说意味着,在初始部署后,只需告诉数据中心B中的SyncMaster它应该开始跟随数据中心A中的集群A,就可以使用一个命令设置异步复制。从那时起,一切都是全自动的,所有数据库、集合、用户和权限都会自动复制到另一个数据中心。显然,有监控和配置工具,但本质上就是这样。
限制
这是迈向多数据中心意识的第一步,因此自然会受到限制。首先,复制是异步的,所以它总是落后于DatacenterA中的实际事件。通常情况下,连接性好,写入速率小于跨数据中心链路的容量,这个延迟非常小. 然而,应该注意,在复制突然停止并手动切换到集群B的情况下,一些最近写入的更新可能会丢失。
整个设置是手动配置的,并在两个数据中心之间工作。此阶段不允许写入副本集群。然而,一个副本集群可以同时是另一个数据中心的源,一个源集群可以有多个副本。也就是说,您可以形成数据中心树。
最后,关闭复制并开始使用副本到目前为止是一项手动操作,需要管理员做出决定和采取行动。
责任编辑:彭菁
-
#mpo极性 #数据中心mpojf_51241005 2024-04-07
-
数据中心机房的建设流程是怎样的?2021-11-15 2702
-
什么是数据中心2021-09-15 2353
-
如何去提高数据中心的运营效率呢2021-09-09 1562
-
模块化数据中心的主要组成部分2021-09-08 2160
-
数据中心是什么2021-07-12 2175
-
数据中心太耗电怎么办2021-06-30 1796
-
大数据和物联网是如何影响数据中心的?2021-05-21 1845
-
数据中心布线之有源光缆2020-08-22 2126
-
未来数据中心与光模块发展假设2020-08-07 3048
-
数据中心光互联解决方案2020-07-03 3342
-
数据中心的建设也看重风水2019-08-07 3217
-
走向绿色数据中心的7种手段2018-08-16 2481
-
数据中心子系统的组成2011-11-11 5886
全部0条评论

快来发表一下你的评论吧 !
