

支持向量机(兵(车)王问题MATLAB程序)
电子说
描述
一、下载LIBSVM工具包
首先将LIBSVM工具包下载至SVM EXAMPLE的目录下。
图片来源:中国慕课大学《机器学习概论》
然后将LIBSVM的路径加载至MATLAB的路径中,以使MATLAB可找到LIBSVM工具包中所有与MATLAB有接口的函数(个人理解:经过此步骤后,MATLAB可以调用LIBSVM工具包中的函数)。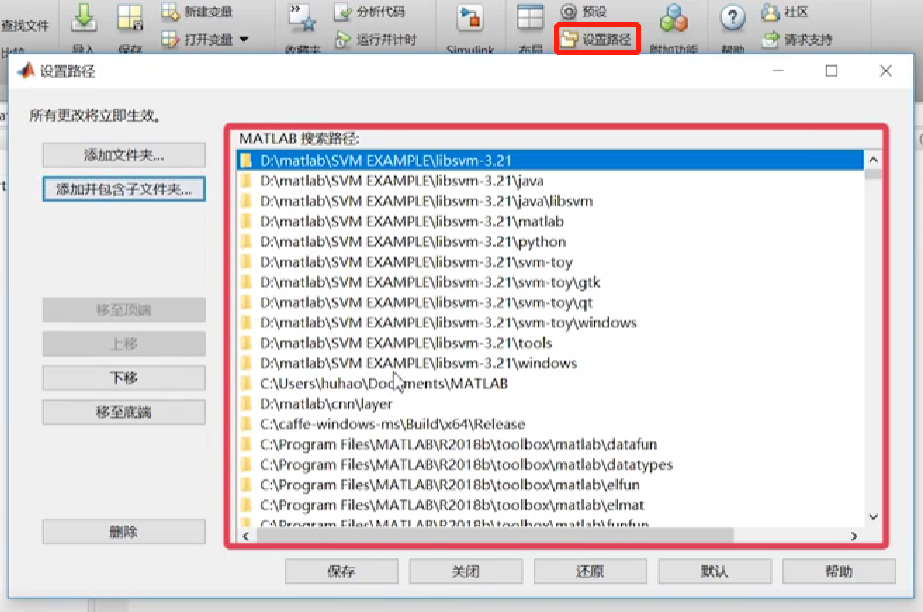
图片来源:中国慕课大学《机器学习概论》
二、数据预处理
处理兵(车)王问题的MATLAB程序文件名称为:testSVMChessLibSVM.m。该MATLAB程序采用读文件的方式获取数据,并将六维数据(六维数据表示三个棋子的位置)存储于xapp中,一维数据(一维数据表示某一情况下,兵(车)王问题返回结果)存储于yapp中。 
图片来源:中国慕课大学《机器学习概论》
获取数据后,首先需所有28056个数据顺序打乱,再将5000个数据作为训练集,将23056个数据作为测试集,以保证训练集和测试集的选择完全随机。之后将训练集和测试集归一化。 

图片来源:中国慕课大学《机器学习概论》
该MATLAB程序选择的核函数是RBF核函数(高斯径向基函数核),并根据LIBSVM网站,将超参数c的取值范围选定为2-5~215,超参数g(gamma,gamma代表RBF核函数中1/σ2的值)取值范围选定为2-15~23。
三、确定超参数c和g的值
在上述超参数c和g的取值范围内遍历所有c和g的组合,寻找识别率最大的c和g组合的机器学习模型。
为估计识别率,需要在5000个训练集中选取部分数据作为估计识别率的数据。所选取估计识别率的数据不能与训练机器学习模型的数据相同,否则会导致过拟合(OVERFITTING),从而导致估计识别率高于实际识别率。估计识别率的数据与训练机器学习模型的数据相同类似于学生考试的题目与日常练习题目相同,若学生考试的题目与日常练习题目相同,则学生的考试成绩将偏高。
为充分利用训练集数据,机器学习模型训练常采用交叉验证的方式估计识别率。在该MATLAB程序中,训练集数据被等分为5份,每份1000个数据,分别以A、B、C、D、E标号,然后进行下述训练和估计:
(1)采用A、B、C、D训练,采用E估计识别率;
(2)采用A、B、C、E训练,采用D估计识别率;
(3)采用A、B、D、E训练,采用C估计识别率;
(4)采用A、C、D、E训练,采用B估计识别率;
(5)采用B、C、D、E训练,采用A估计识别率; 最后将五个识别率取平均值,得出总识别率,该过程被称为五折交叉验证(5-fold cross validation),LIBSVM工具包中“-v 5”表示五折交叉验证。 
图片来源:中国慕课大学《机器学习概论》
交叉验证在训练数据数量不变的情况下,保证采用更多的数据训练和估计识别率,从而估计出更准确的识别率。交叉验证的劣势是增加模型训练的时间。
交叉验证的形式之一是留一法(LEAVE-ONE-OUT),即每次采用一个数据估计识别率,剩余数据均参与训练。留一法常被用于训练数据较少且需要精确估计识别率的情况。
在该MATLAB程序中,共包含两次交叉验证,第一次交叉验证初步确定超参数c和g的组合,第二次交叉验证更精确地确定超参数c和g的组合。
四、训练机器学习模型
在确定超参数c和g的组合后,使用该超参数c和g的组合和5000个训练样本得出最终的机器学习模型,图一为所得出的机器学习模型的参数,其中,“nr_class:2”表示此机器学习模型是二分类模型,“totalSV:220”表示此机器学习模型具有220个支持向量,“rho:39.9485”表示b的值为39.9485。

图一,图片来源:中国慕课大学《机器学习概论》
最后,采用测试集的数据测试模型,得出识别率为99.61%。
审核编辑:刘清
-
#硬声创作季 人工智能入门课程:16. [2.11.1]--支持向量机(兵王问题程序设计)Mr_haohao 2022-09-21
-
四种支持向量机用于函数拟合与模式识别的Matlab示例程序2012-03-13 29118
-
基于支持向量机的分类问题2017-04-03 3011
-
特征加权支持向量机2009-11-21 660
-
基于改进支持向量机的货币识别研究2009-12-14 636
-
基于支持向量机(SVM)的工业过程辨识2012-03-30 1059
-
基于支持向量机的图书馆借阅量预测_王丽华2017-03-16 939
-
MATLAB的循环向量化编程方法的详细资料研究2019-08-28 1651
-
OpenCV机器学习SVM支持向量机的分类程序免费下载2019-10-09 1688
-
什么是支持向量机 什么是支持向量2020-01-28 23311
-
支持向量机网络搜索优化应用程序下载2021-04-20 1294
-
支持向量机(原问题和对偶问题)2023-05-25 2783
-
支持向量机(兵王问题描述)2023-06-09 3656
-
支持向量机(兵(车)王问题程序设计)2023-06-12 1316
-
使用MATLAB的支持向量机解决方案2025-10-21 1019
全部0条评论

快来发表一下你的评论吧 !
